😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔笔记来自B站UP主Ele实验室的《小白也能听懂的人工智能原理》。
🔔本文讲解一元一次函数感知器:如何描述直觉,一起卷起来叭!
目录
- 一、如何评估误差?
- 二、概率和统计
- 三、如何挪动到最低点?
- 四、代码实现
一、如何评估误差?
你可能会想:
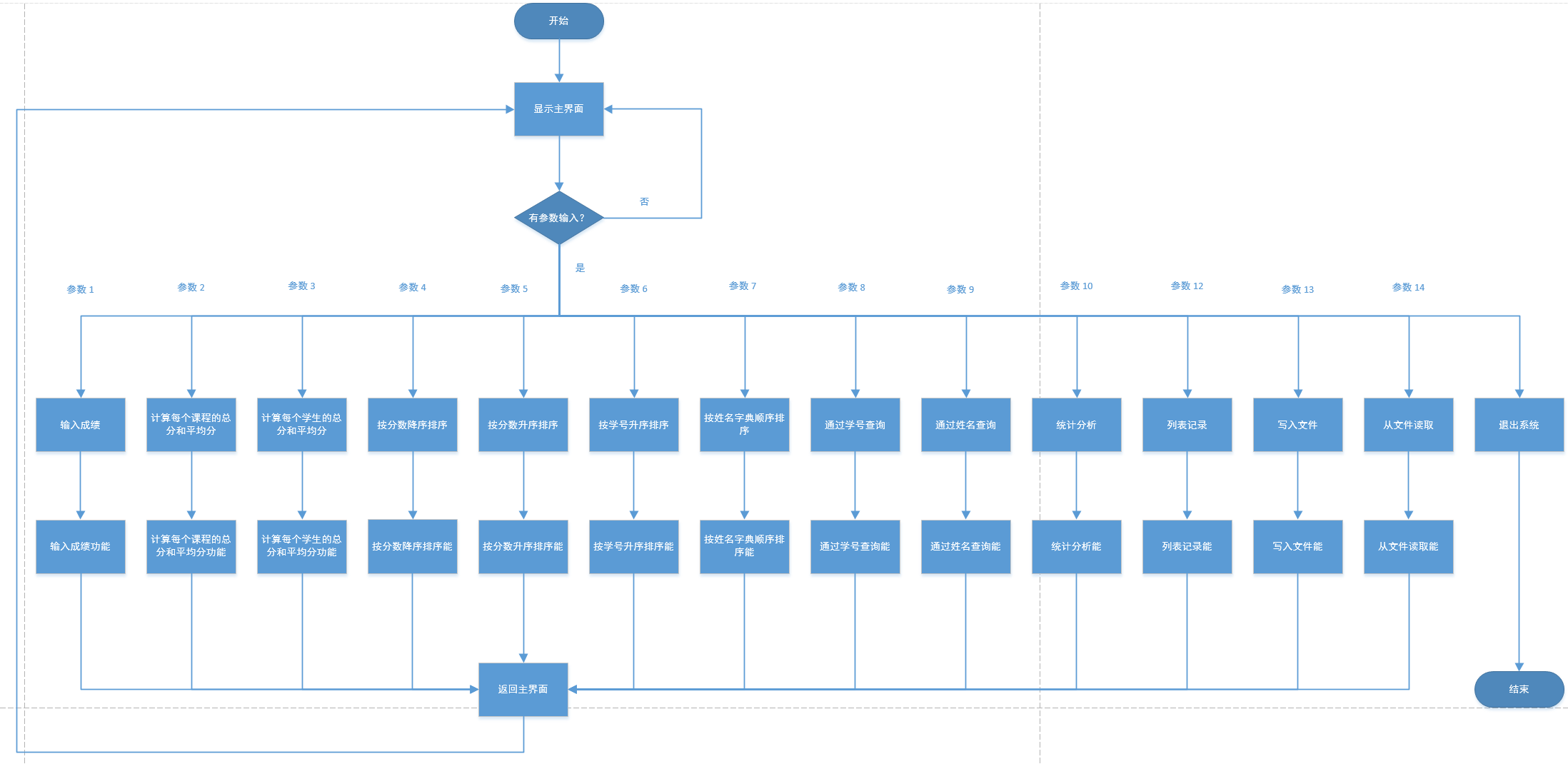
1、通过差值来评价误差 => 正负会抵消误差
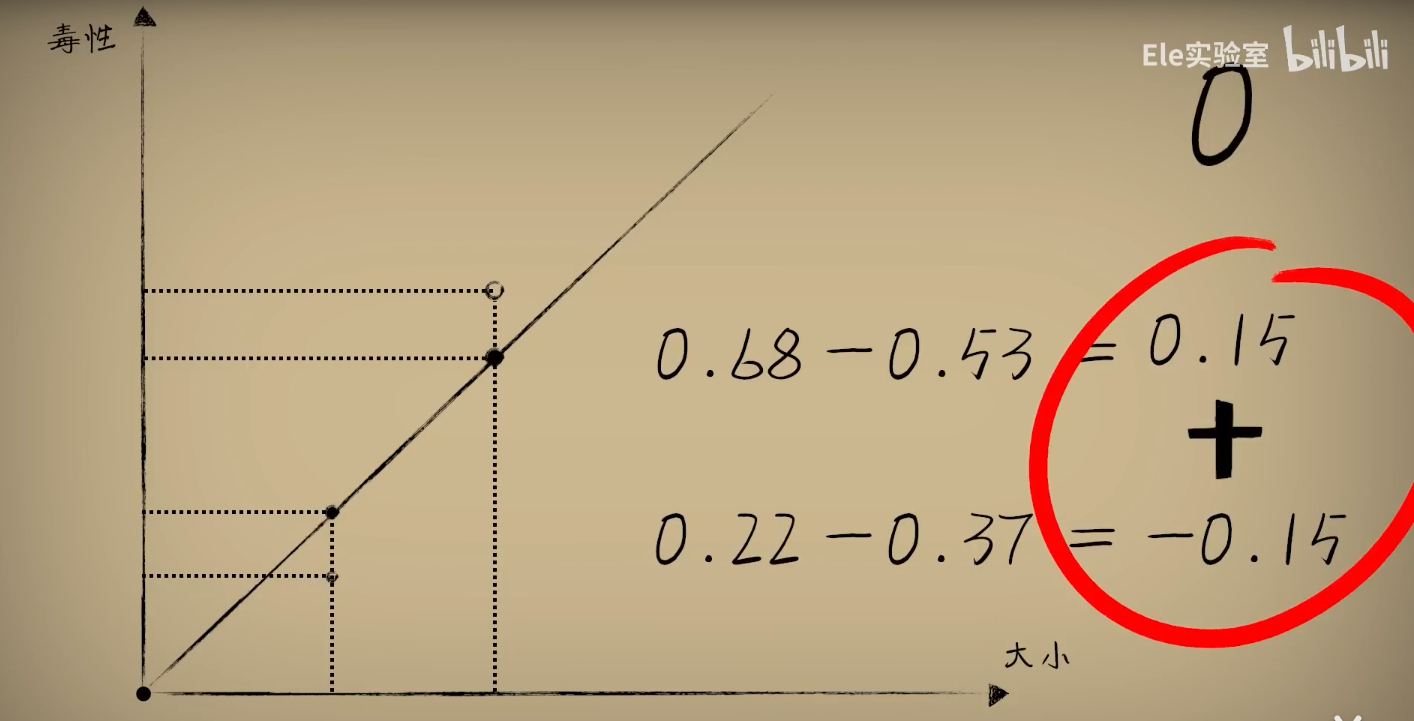
2、机智如你,想到用绝对差 => 代码不好处理
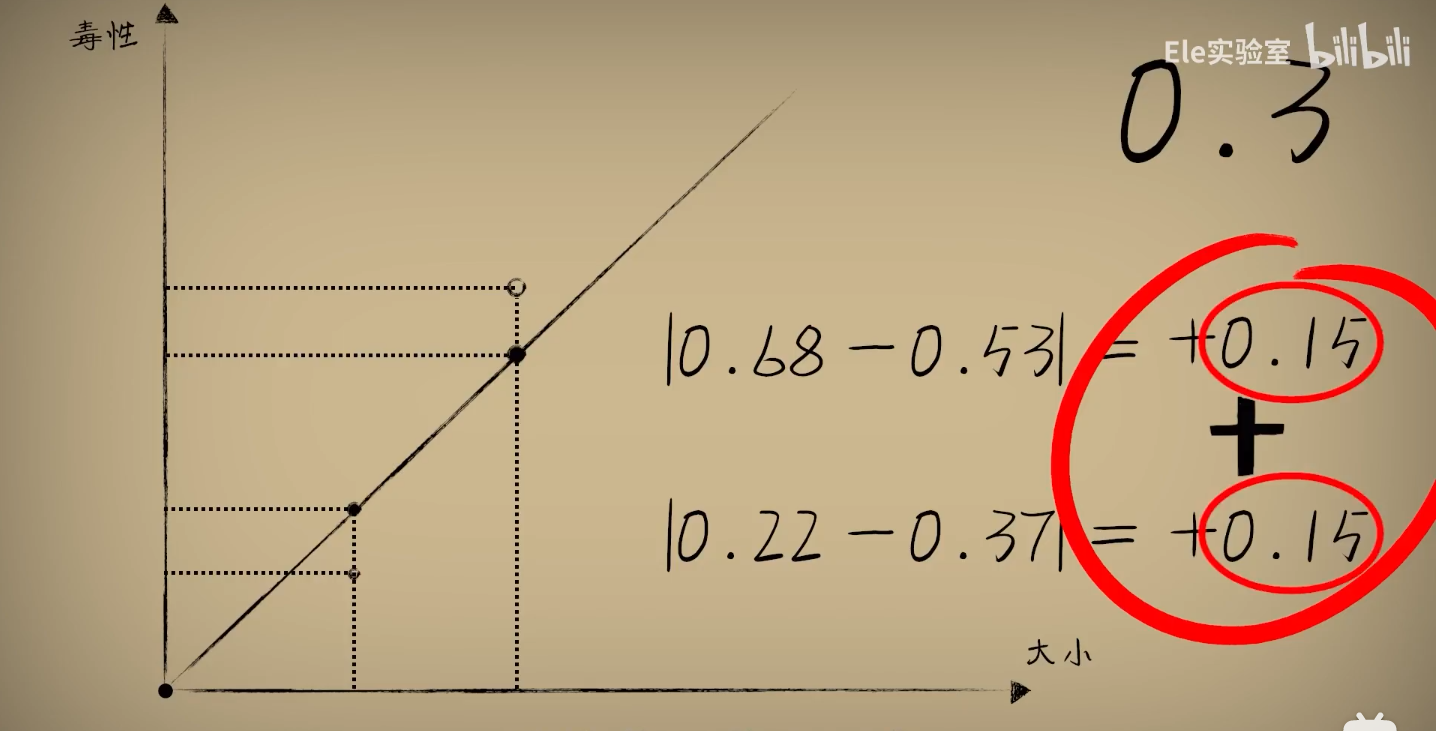
3、使用平方误差,平方误差越小就说明偏离的事实就越小,小蓝的思考就越接近真相

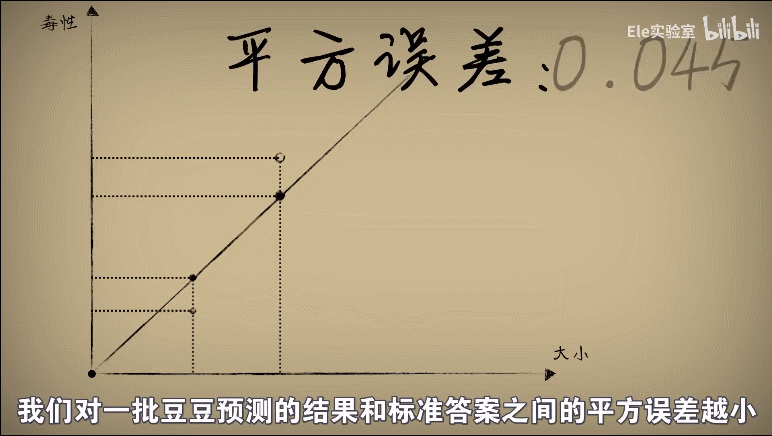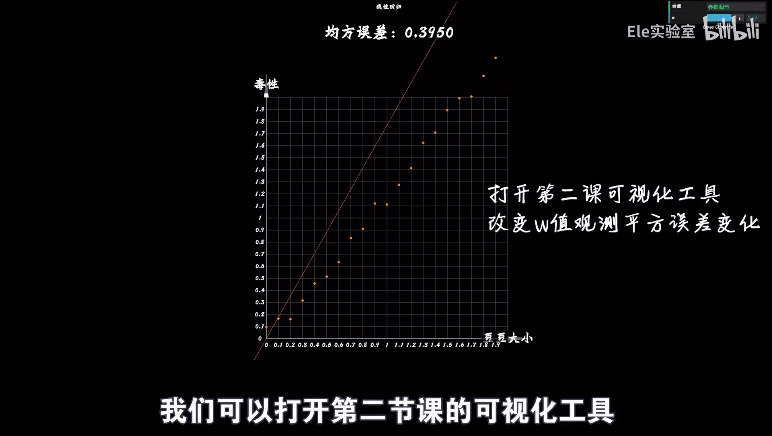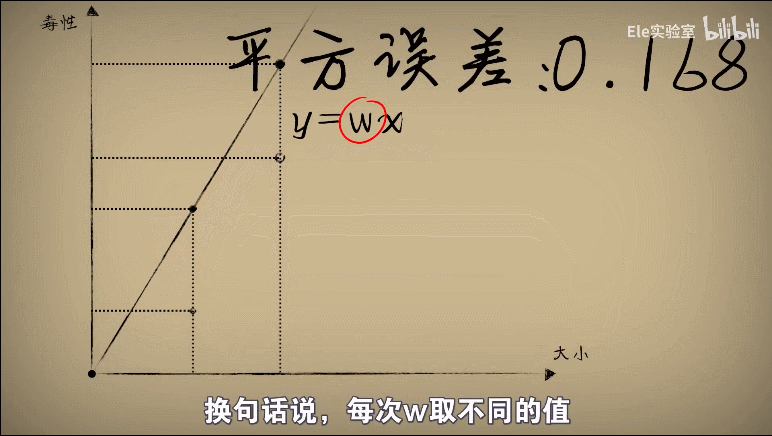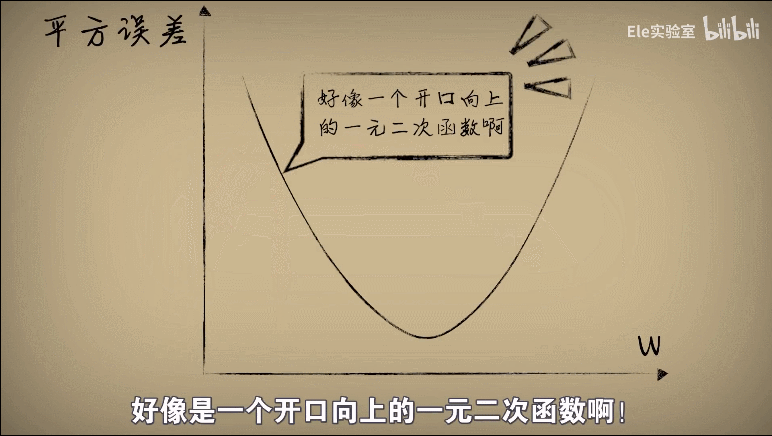
于是我们将w和平方误差的关系画出来,发现图像是一个开口向上的一元二次方程
数学证明:
研究一组豆豆太复杂,我们先研究一个豆豆的误差:
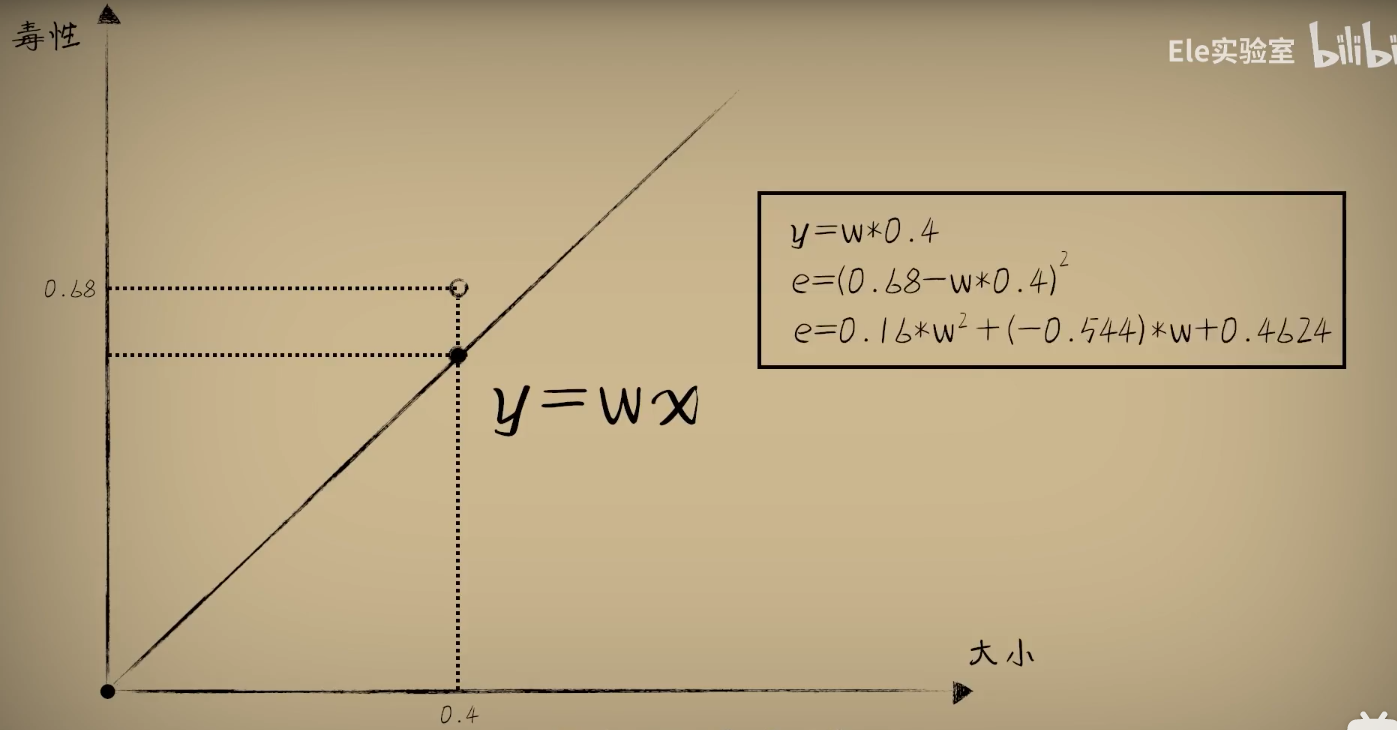
一个豆豆的误差和w之间的关系确实是一元二次函数,那么如果是一组豆豆的误差会是怎样的呢?
我们继续分析:

我们发现:整体豆豆的误差就是将单个豆豆的误差加起来然后求平均值

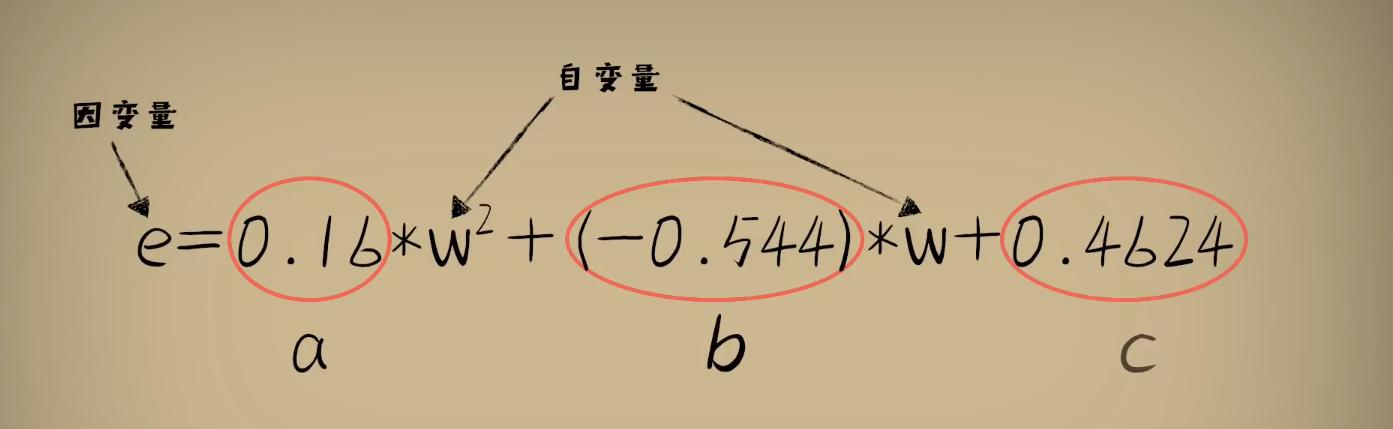
整理公式发现误差e和w之间的关系仍然是一个标准开口向上的一元二次函数(a,b,c都是固定的值)
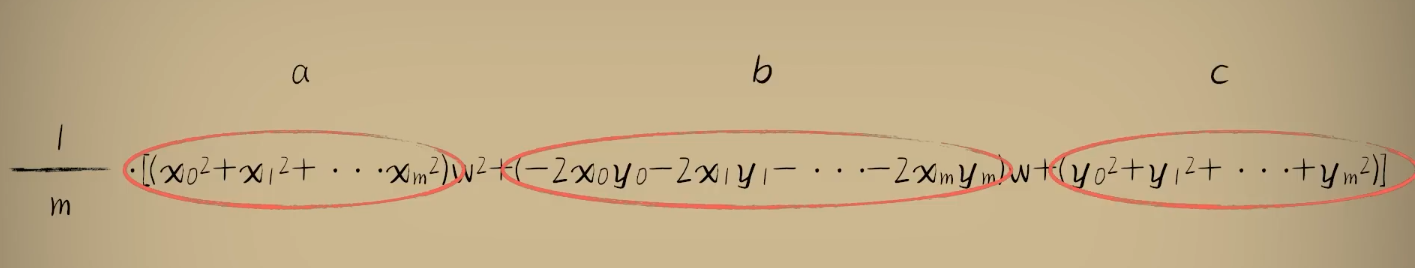

均方误差:将所有误差值累加起来,然后求平均值,这就是预测函数在整体样本上的误差
二、概率和统计
事物出现的频率收敛于它的概率
以下概念通过豆豆的栗子讲解:
回归分析:
一开始我们猜想一个w,然后统计出大量的数据(大小和毒性), 去评估我们的w合不合适,这个过程在数理统计里面称为:回归分析
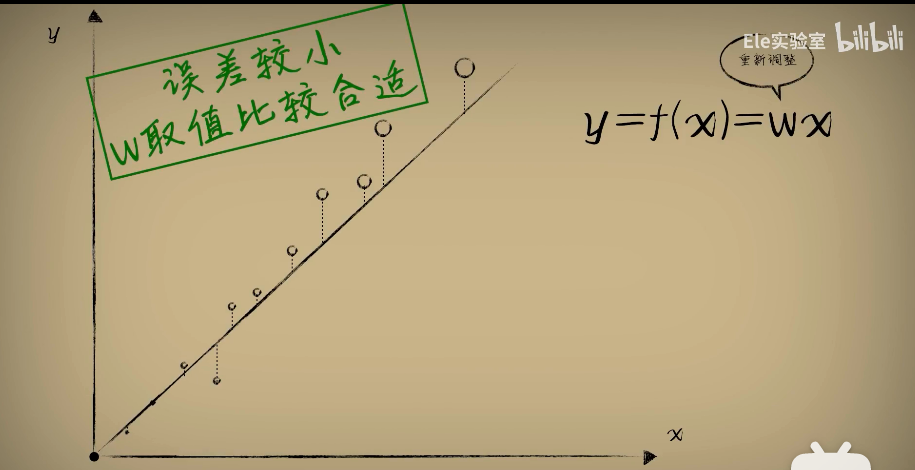
最小二乘法:
而我们评估的标准是"均方误差",并试图让他最小,也就是回归分析的最小二乘法

代价函数:
代价函数(Cost Function) ——当参数w取不同值时,对环境中的问题数据预测时产生不同的误差error。反过来,利用代价函数最低点的w值,把它放回到预测函数中,这时候预测函数也就很好的完成了对数据的拟合。
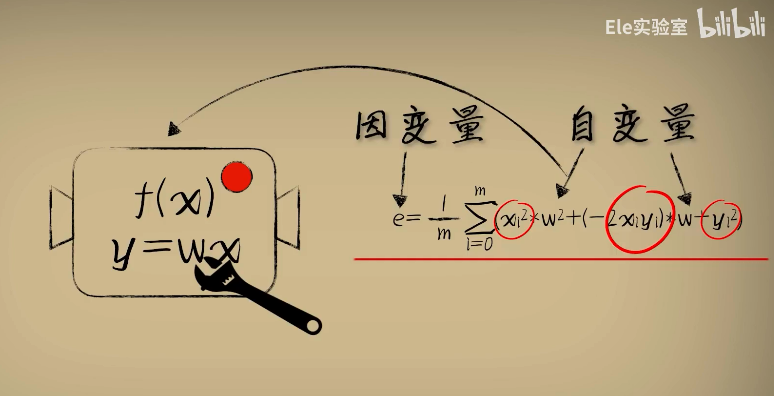
此时此刻,如果我们把函数看作处理问题的机器,那么事情从原先的机器输入数据,得到结果变成了用很多观察的数据去评估这个函数机器到底在不在行。
原先的自变量x和因变量y变成了从环境中观测到的大量已知数,而我们把w是作为自变量,误差e作为因变量,也就形成一个新的函数叫做代价函数。
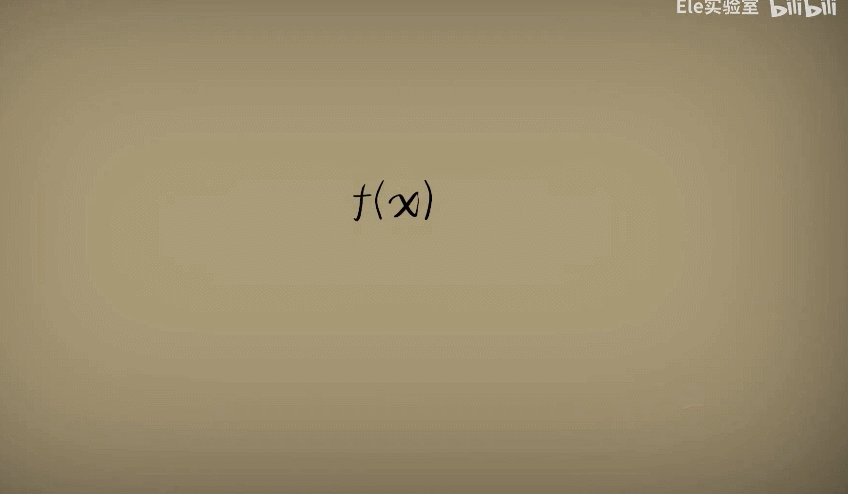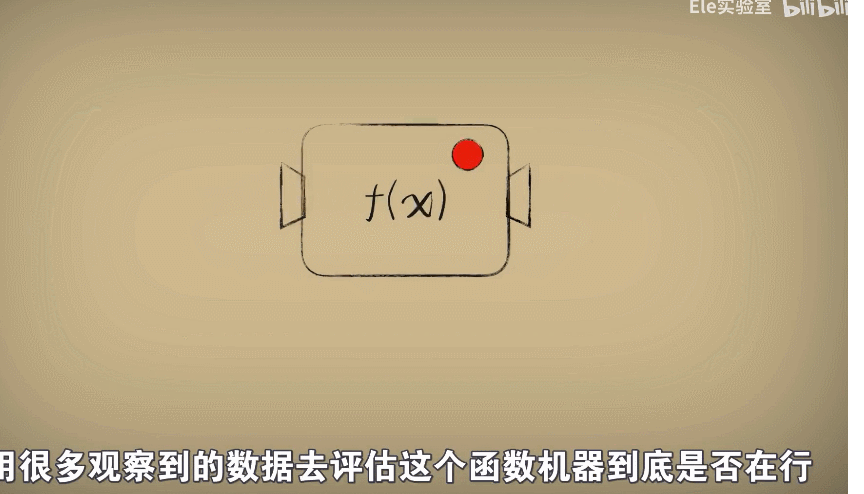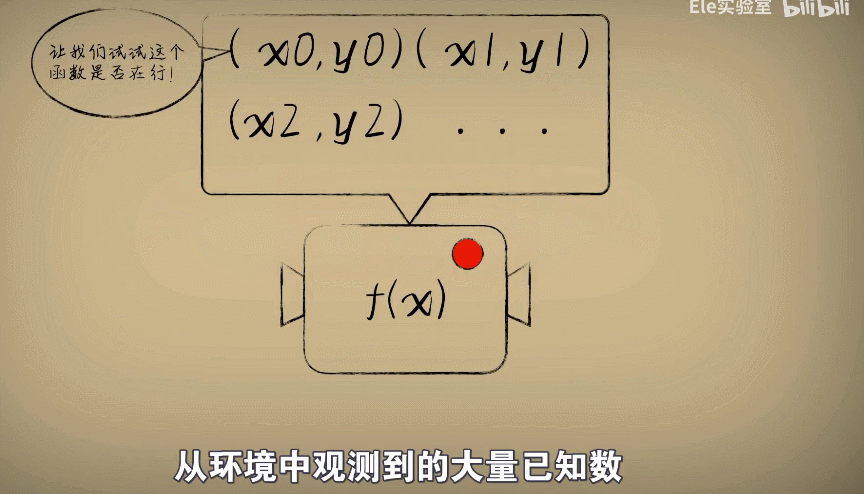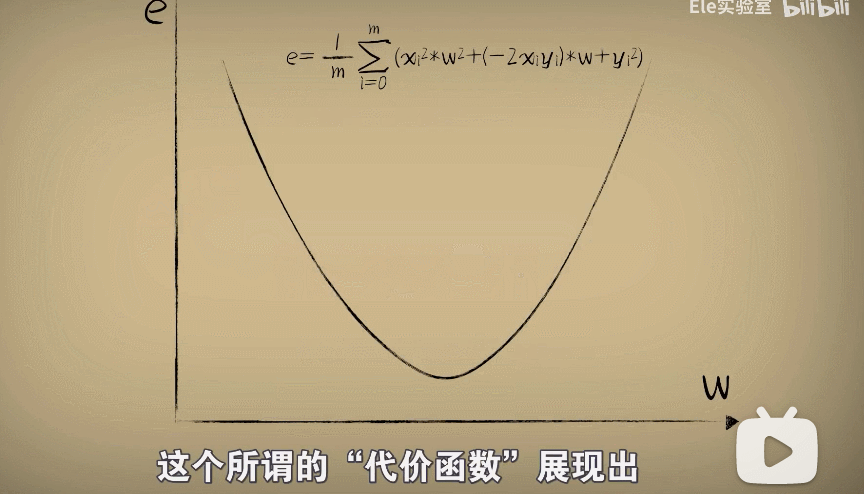
这个所谓的"代价函数"展现出,当参数w取不同值的时候,对于环境中的问题数据预测时产生的不同误差。
而利用这个"代价函数"的最低点的w值,把它放回到预测函数,这时候预测函数也就很好完成了对数据的拟合。
注意:
在预测函数中w作为参数,x是作为自变量输入,y作为因变量输出
这是我们最终要得到预测函数问题的函数
而在研究函数的时候,x和y都是观测统计出来的已知数,成为了代价函数的已知参数部分
而w成为了自变量,误差代价e是因变量
这是我们用来分析并改进预测函数的辅助函数
三、如何挪动到最低点?
那当然是:求最低点w_min(二次函数的最低点,-b/2a)
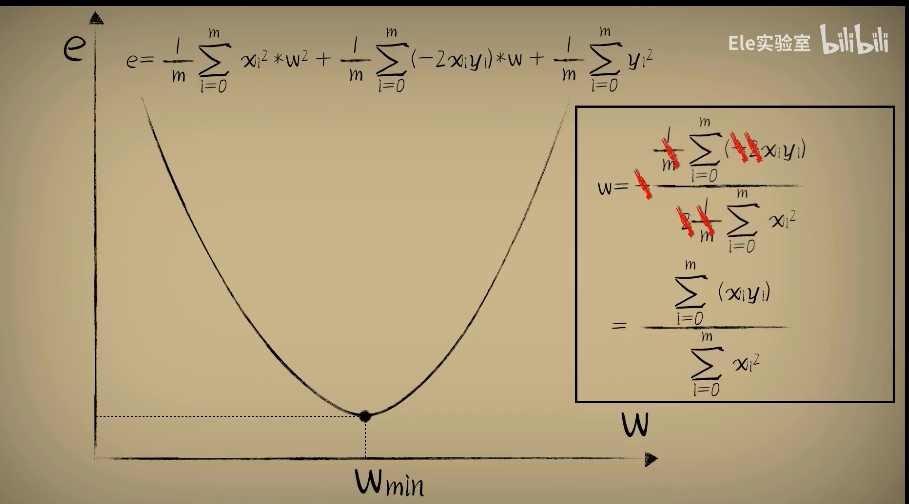
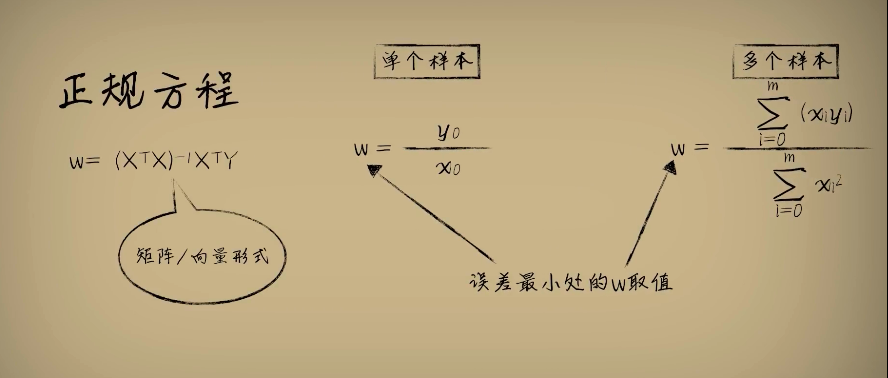
正规方程:
这种一次性求解出让误差最小的W取值的方法,我们称为正规方程
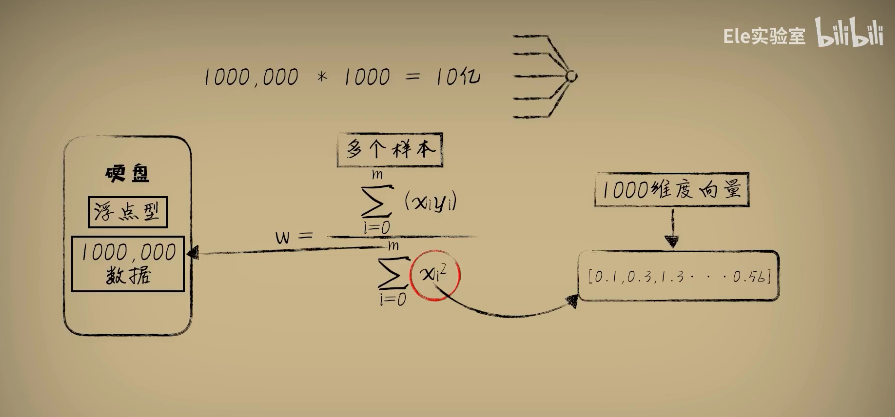
如果数据量不大的话,这很合适。不过实际应用中输入x往往不会是一个特征数值,更一般的情况是一个特征向量,比如1000个维度,那么运算次数就是10亿次,而在现代神经网络中为了加快运算的速度一般都会采用并行计算的方式,也就是一次性把它们都算出来。
四、代码实现
豆豆数据集模拟:dataset.py
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = [1.2*x+np.random.rand()/10 for x in xs]
return xs,ys
代价函数分析:code_function.py
import dataset
import matplotlib.pyplot as plt
import numpy as np
# 豆豆数量m
m = 100
xs, ys = dataset.get_beans(m)
# 配置图像
plt.title("Size-Toxicity Function", fontsize=12)
plt.xlabel("Bean Size")
plt.ylabel("Toxicity")
plt.scatter(xs, ys)
w = 0.1
y_pre = w * xs
plt.plot(xs, y_pre)
plt.show()
# 绘制代价函数的图像(w和方差e的图像)
es = []
ws = np.arange(0, 3, 0.1)
for w in ws:
y_pre = w * xs
# 平方误差、求和、平均得到误差
e = (1 / m) * np.sum((ys - y_pre) ** 2)
es.append(e)
plt.title("Cost Function", fontsize=12)
plt.xlabel("w")
plt.ylabel("e")
plt.plot(ws, es)
plt.show()
# 用抛物线顶点坐标求解最低点的w
w_min = np.sum(xs * ys) / np.sum(xs ** 2)
print("最小点的w:" + str(w_min))
# 把最低点的W值带回预测函数中,看看效果
y_pre = w_min * xs
plt.title("Size-Toxicity Function", fontsize=12)
plt.xlabel("Bean Size")
plt.ylabel("Toxicity")
plt.scatter(xs, ys)
plt.plot(xs, y_pre)
plt.show()
实验结果:
W调整前:
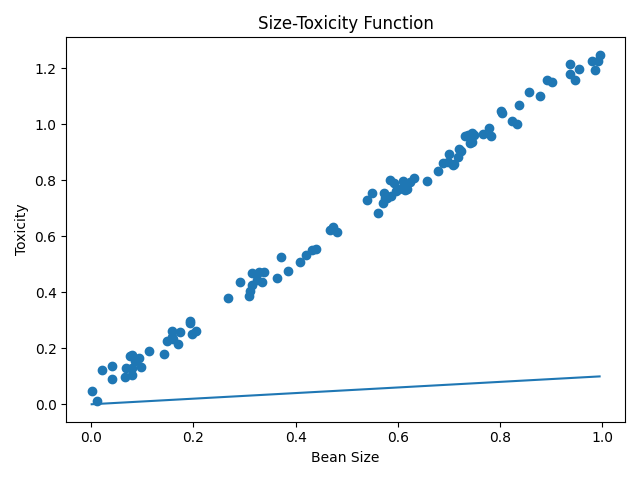
代价函数图:
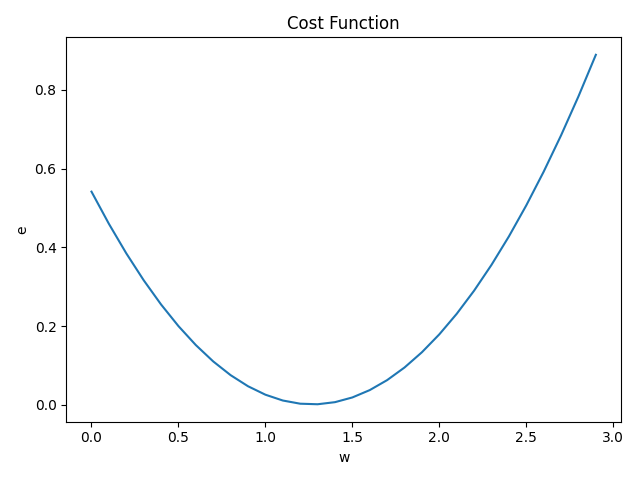
W调整后:
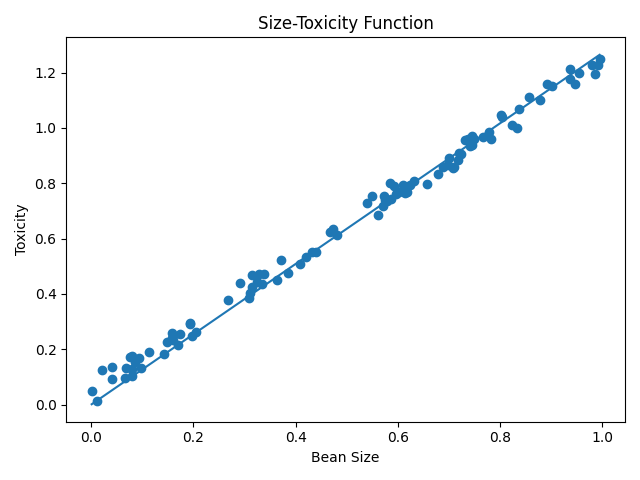
相关代码仓库链接,欢迎Star:传送门

![[oeasy]python0037_字符画艺术_asciiview_自制小动物_imagick_asciiart](https://img-blog.csdnimg.cn/img_convert/26fff52e9d8d9dd0b3543f9e1a270c2c.png)