文章目录
- 一、环境配置
- 二、准备数据
- 三、搭建网络结构
- 四、开始训练
- 五、查看训练结果
- 六、总结
- 2.3 ⭐`torch.utils.data.DataLoader()`参数详解
- 6.1 `print()`常用的三种输出格式
- 6.2 修改网络结构,观察训练结果
- 6.2.1 增加pool2、conv6、bn6,test_accuracy=82.5%
- 6.2.2 去掉pool2,保留conv6、bn6,增加conv7、bn7,test_accuracy=84.4%
- 6.2.3 继续增加conv8、bn8、conv9、bn9,test_accuracy=87.2%
- 6.2.4 继续增加conv10、bn10、conv11、bn11,test_accuracy=82.1%
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制

- 本周的代码相对于上周增加指定图片预测与保存并加载模型这个两个模块,在学习这个两知识点后,时间有余的同学请自由探索更佳的模型结构以提升模型是识别准确率,模型的搭建是深度学习程度的重点。
一、环境配置
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
import sys
from datetime import datetime
print("---------------------1.配置环境------------------")
print("Start time: ", datetime.today())
print("Pytorch version: " + torch.__version__)
print("Python version: " + sys.version)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

二、准备数据
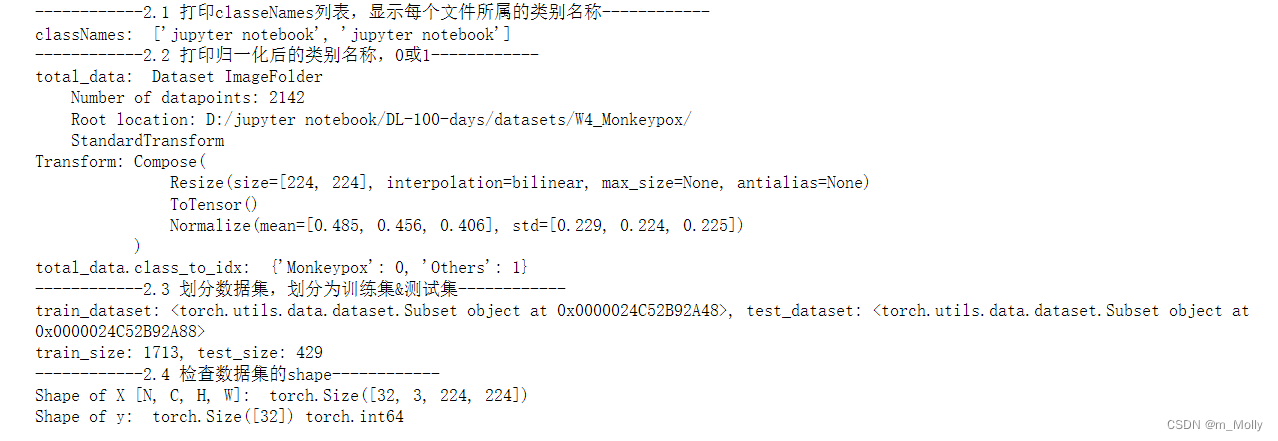
2.1 打印
classeNames列表,显示每个文件所属的类别名称
2.2 打印归一化后的类别名称,0或1
2.3 划分数据集,划分为训练集&测试集,torch.utils.data.DataLoader()参数详解
2.4 检查数据集的shape
- 第一步:使用
pathlib.Path()函数将字符串类型的文件夹路径转换为pathlib.Path对象。 - 第二步:使用
glob()方法获取data_dir路径下的所有文件路径,并以列表形式存储在data_paths中。 - 第三步:通过
split()函数对data_paths中的每个文件路径执行分割操作,获得各个文件所属的类别名称,并存储在classNames中 - 第四步:打印
classNames列表,显示每个文件所属的类别名称。
import os,PIL,random,pathlib
print("------------2.1 打印classeNames列表,显示每个文件所属的类别名称------------")
total_datadir= './4-data/'
data_dir = pathlib.Path(total_datadir)
data_paths = list(total_datadir.glob('*'))
classNames = [str(path).split("\\")[1] for path in data_paths]
print("classNames: ", classNames)
print("------------2.2 打印归一化后的类别名称,0或1------------")
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
print("total_data: ", total_data)
print("total_data.class_to_idx: ", total_data.class_to_idx)
print("------------2.3 划分数据集,划分为训练集&测试集------------")
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print( f"train_dataset: {train_dataset}, test_dataset: {test_dataset}")
print( f"train_size: {train_size}, test_size: {test_size}")
print("------------2.4 检查数据集的shape------------")
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
三、搭建网络结构
print("------------3 搭建简单CNN网络------------")
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(classNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model

四、开始训练
4.1 设置超参数
4.2 编写训练函数
4.3 编写测试函数
4.4 开始正式训练,epochs==20
print("------------4.1 设置超参数------------")
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
print("------------4.2 编写训练函数------------")
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
print("------------4.3 编写测试函数------------")
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
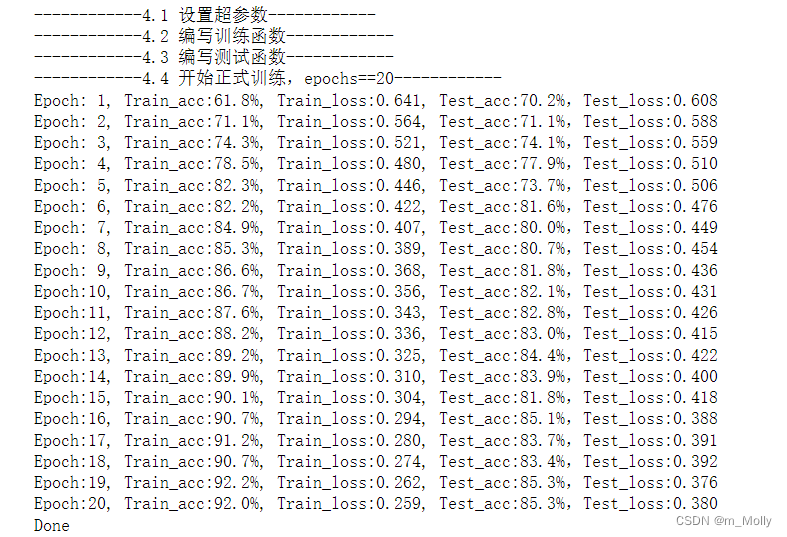
print("------------4.4 开始正式训练,epochs==20------------")
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
五、查看训练结果
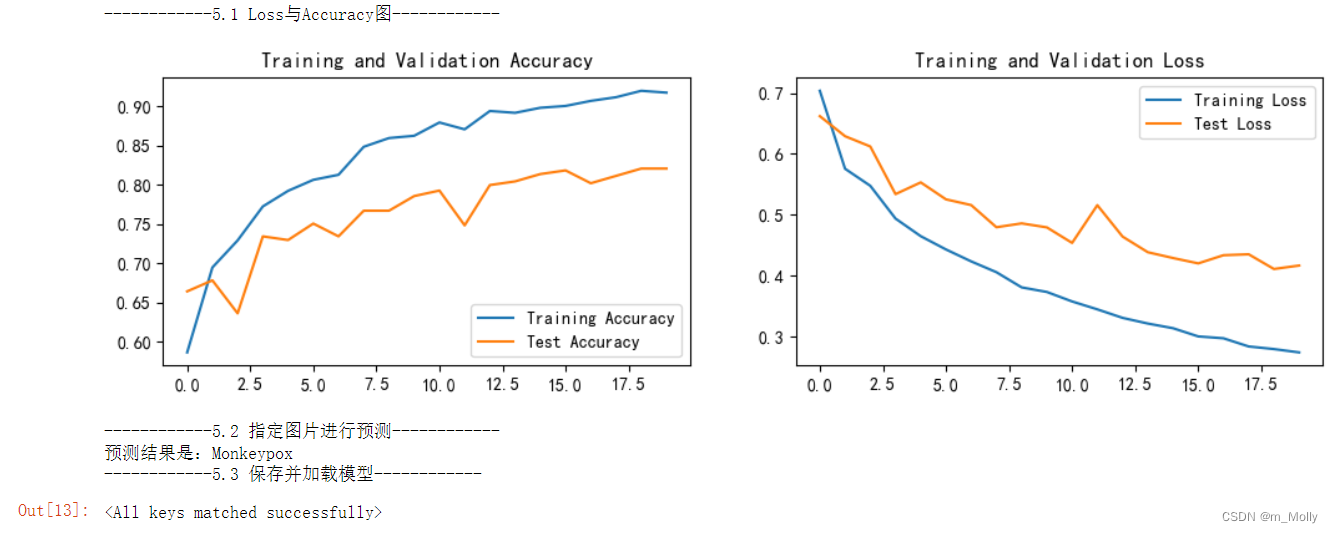
5.1 Loss与Accuracy图
5.2 指定图片进行预测
5.3 保存并加载模型
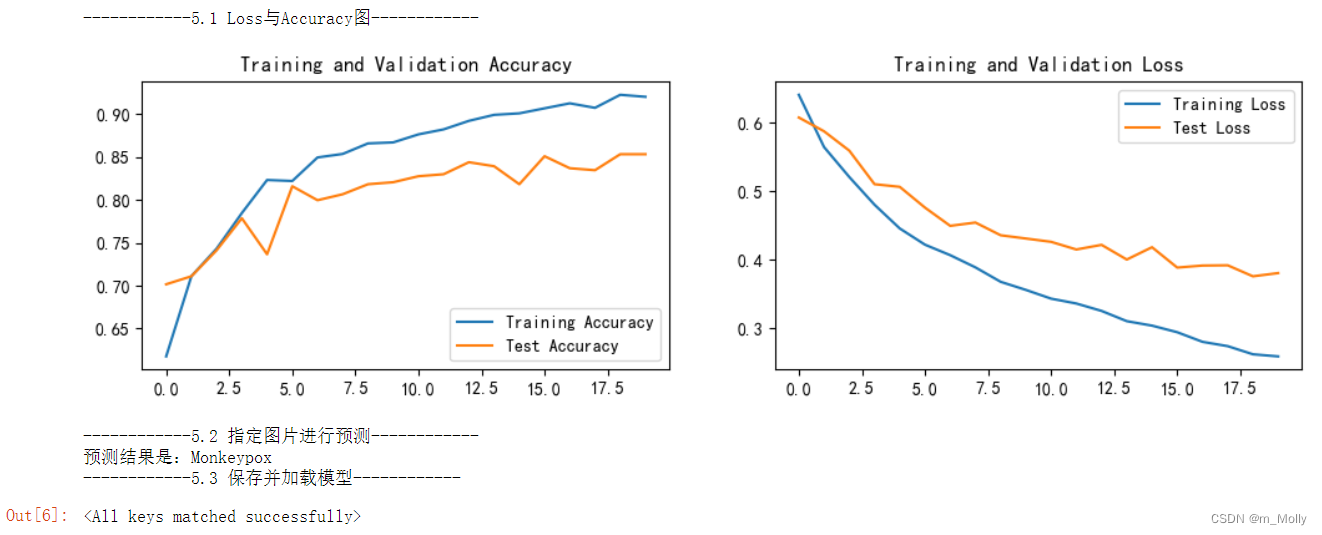
print("------------5.1 Loss与Accuracy图------------")
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
print("------------5.2 指定图片进行预测------------")
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
# plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_,pred = torch.max(output,1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./4-data/Monkeypox/M01_01_00.jpg',
model=model,
transform=train_transforms,
classes=classes)
print("------------5.3 保存并加载模型------------")
# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
六、总结
2.3 ⭐torch.utils.data.DataLoader()参数详解
torch.utils.data.DataLoader是PyTorch中用于加载和管理数据的一个实用工具类。它允许你以小批次的方式迭代你的数据集,这对于训练神经网络和其他机器学习任务非常有用。DataLoader构造函数接受多个参数,下面是一些常用的参数及其解释:
dataset(必需参数):这是你的数据集对象,通常是torch.utils.data.Dataset的子类,它包含了你的数据样本。batch_size(可选参数):指定每个小批次中包含的样本数。默认值为1。shuffle(可选参数):如果设置为True,则在每个epoch开始时对数据进行洗牌,以随机打乱样本的顺序。这对于训练数据的随机性很重要,以避免模型学习到数据的顺序性。默认值为False。num_workers(可选参数):用于数据加载的子进程数量。通常,将其设置为大于 0 的值可以加>快数据加载速度,特别是当数据集很大时。默认值为 0,表示在主进程中加载数据。pin_memory(可选参数):如果设置为True,则数据加载到 GPU 时会将数据存储在 CUDA 的锁页内存中,这可以加速数据传输到 GPU。默认值为 False。drop_last(可选参数):如果设置为True,则在最后一个小批次可能包含样本数小于batch_size时,丢弃该小批次。这在某些情况下很有用,以确保所有小批次具有相同的大小。默认值为 False。timeout(可选参数):如果设置为正整数,它定义了每个子进程在等待数据加载器传递数据时的超时时间(以秒为单位),这可以用于避免子进程卡住的情况。默认值为 0,表示没有超时限制。worker_init_fn(可选参数):一个可选的函数,用于初始化每个子进程的状态。这对于设置每个子进程的随机种子或其他初始化操作很有用。
6.1 print()常用的三种输出格式
-
- 带格式输出,
{0}是指输出的第0个元素,同理{1}为第1个元素,{2}为第2个… 可以不按顺序排列
print( "Hello {0}, I'm {2}, I,m {1} year old".format("world", age, name) )
- 带格式输出,
-
- 使用类型输出,指定输出类型
print( "I am %s, today is %d year"%(name, year) )
- 使用类型输出,指定输出类型
-
f字符串,{}中为元素,是.format的简化形式
print( f"Today is {year}")
6.2 修改网络结构,观察训练结果
6.2.1 增加pool2、conv6、bn6,test_accuracy=82.5%

训练结果如下:
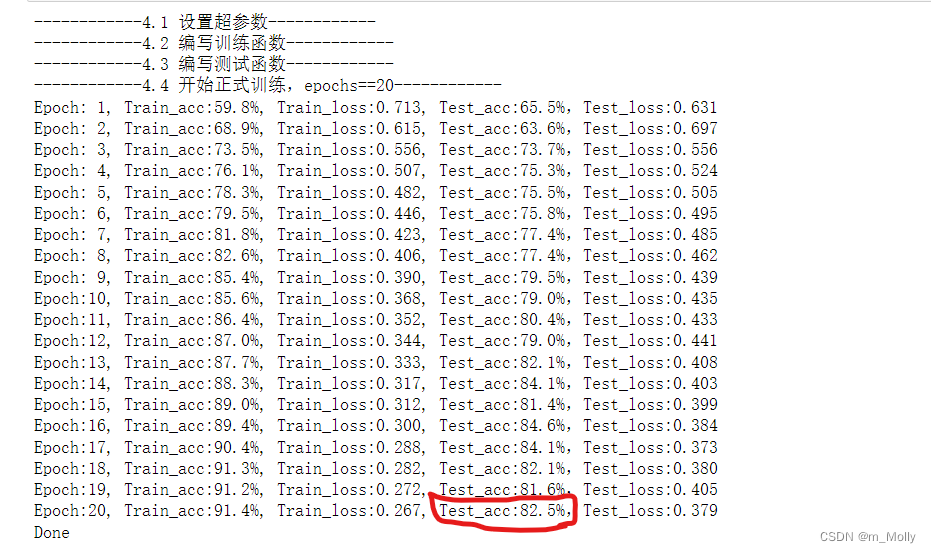
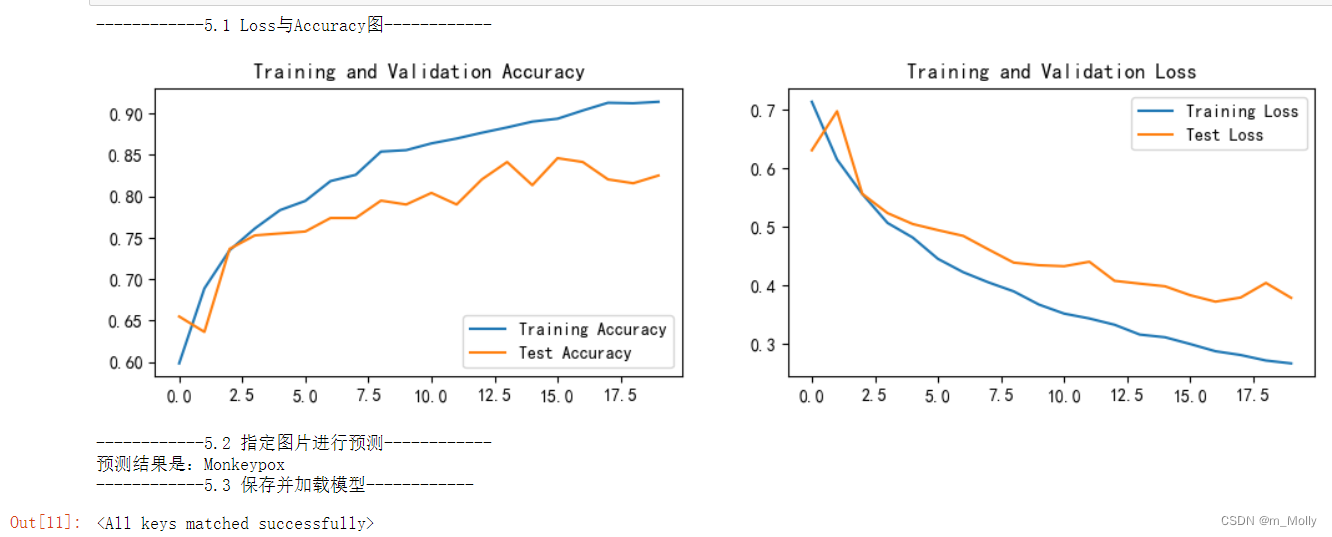
训练结果表明:修改网络结构之后,test_accuracy反而从85.3%降低到82.5%,说明此次修改结构不能提升test_accuracy的值。
6.2.2 去掉pool2,保留conv6、bn6,增加conv7、bn7,test_accuracy=84.4%

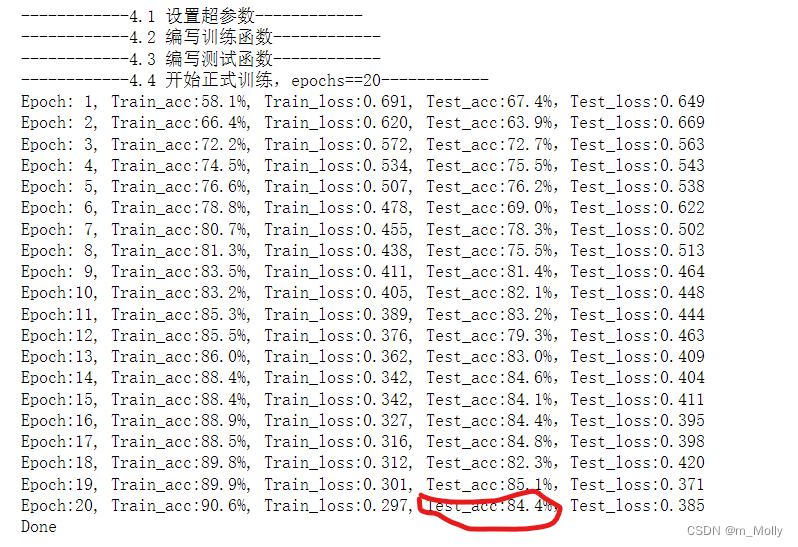
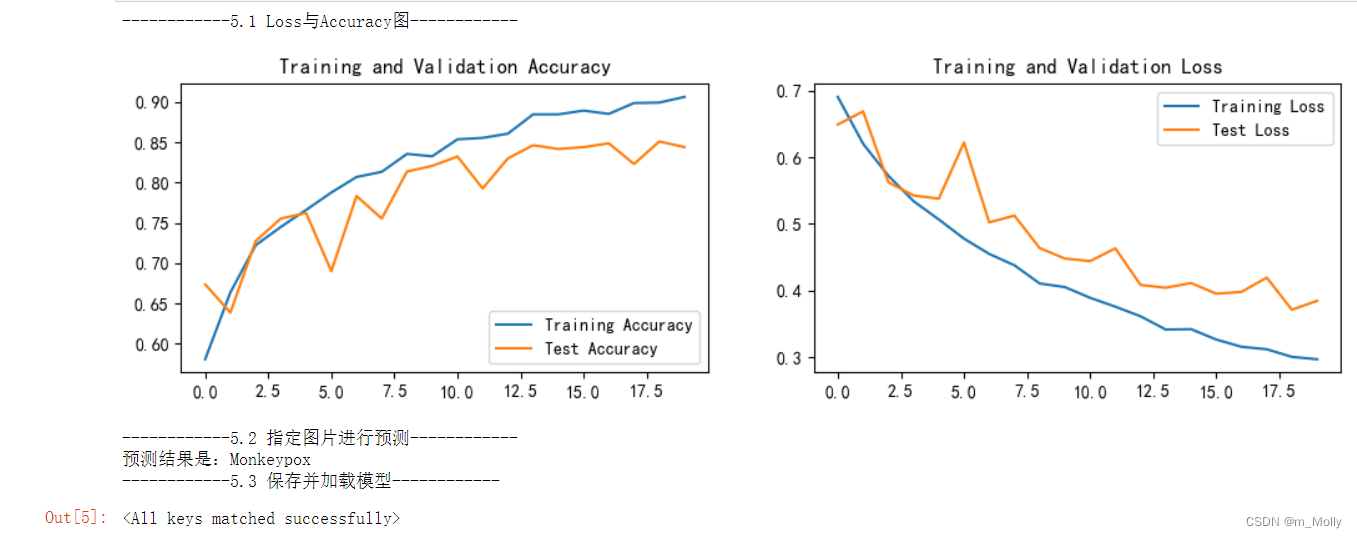
训练结果表明:与6.2.1的修改方法相比,test_accuracy从82.5%提升到84.4%。
6.2.3 继续增加conv8、bn8、conv9、bn9,test_accuracy=87.2%

训练情况如下:
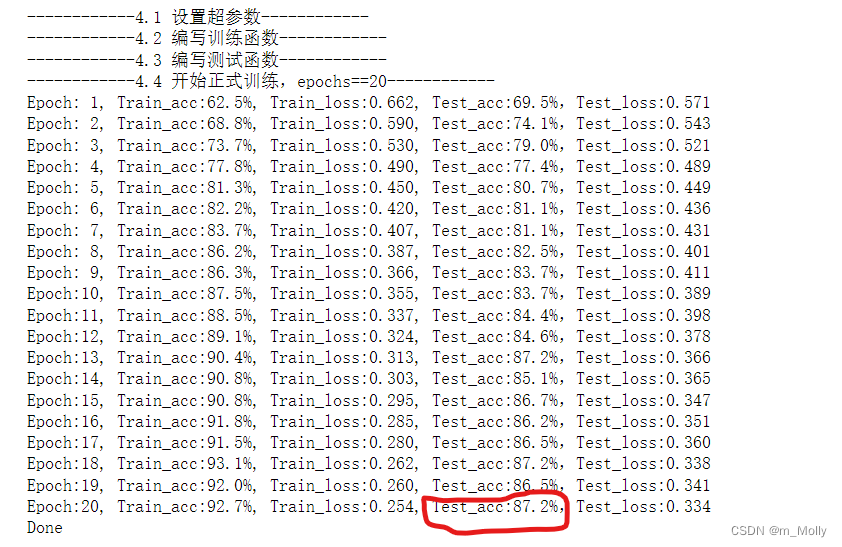
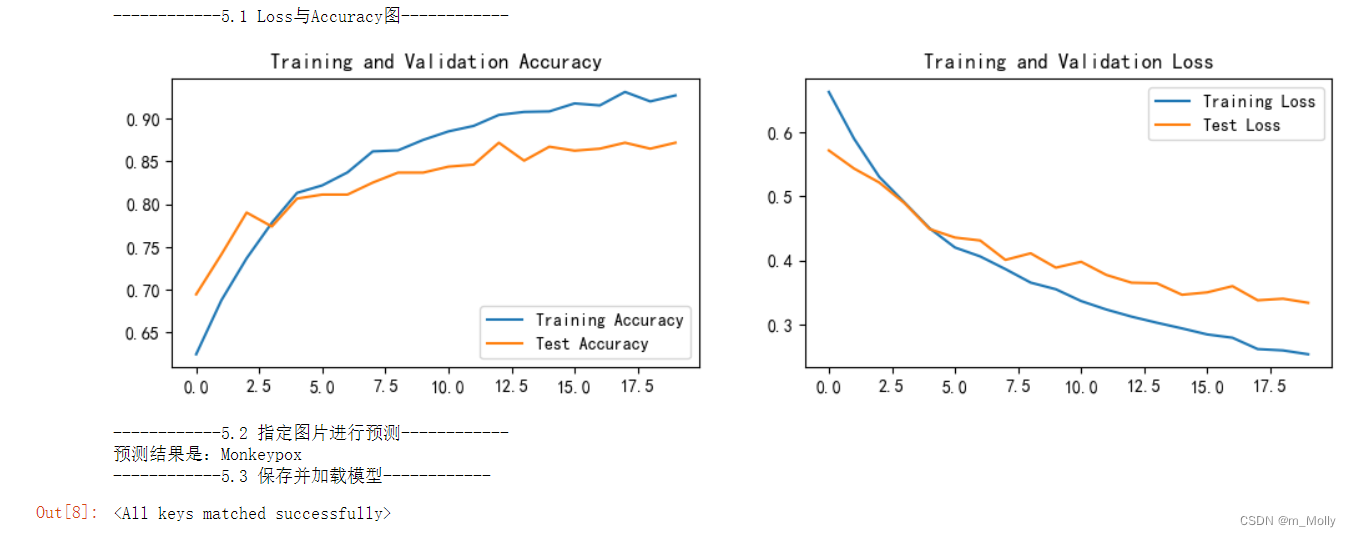
训练结果表明:与6.2.2的修改方法相比,test_accuracy从84.4%提升到87.2%。
6.2.4 继续增加conv10、bn10、conv11、bn11,test_accuracy=82.1%

训练情况如下:
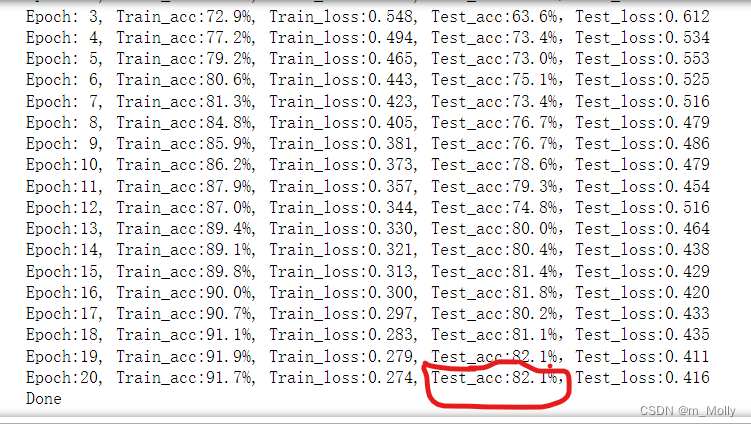
训练结果表明:与6.2.3的修改方法相比,test_accuracy从87.2%降低到82.1%。
综合上述4次修改,可以得出的结论是:适当增加conv、bn层可以有效提升test_accuracy,最好的效果是第三次修改,test_accuracy的值达到了87.2%。