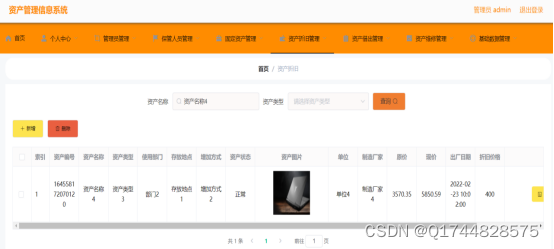
如何解决大模型的「幻觉」问题?
- 如何解决大模型的「幻觉」问题?
- 幻觉产生原因?
- 模型原因
- 数据层面
- 幻觉怎么评估?
- Reference-based(基于参考信息)
- 基于模型的输入、预先定义的目标输出
- 基于模型的输入
- Reference-Free(无参考信息)
- 基于IE(信息抽取)
- 基于QA(问题回答)
- 基于NLI(自然语言推理)
- 基于Factualness Classification Metric(使用一个度量标准)
- 人工评估
- GPT 自动评估
- 幻觉解决方案?
- 幻觉修正
- 幻觉缓解
- 幻觉相关研究
如何解决大模型的「幻觉」问题?
在大型语言模型中,「幻觉」是指模型生成不符合现实或上下文的信息。
这些信息可能与输入内容直接冲突,或者在没有足够证据支持的情况下创造出无法验证的事实。
幻觉产生原因?
模型原因
-
模型结构:较弱的backbone如 RNN,可能导致严重的幻觉问题。
-
解码算法:使用不确定性较高的采样算法如 top-p,会诱导 LLMs 出现更严重的幻觉问题。
解码算法,是指在语言模型生成文本时,如何从模型提供的可能的词汇中选择下一个词的方法。
这就像是在写作时,每次选择下一个词语的过程。
使用不确定性较高的采样算法,可以理解为写作时故意加入一些随机性。
就像一个作家决定掷骰子来决定他的下一个句子会说些什么,这种方式有时可以让文本更有创意,但也更可能让内容变得没有逻辑或者不真实。
-
暴露偏差:训练和测试阶段不匹配的问题可能导致 LLMs 出现幻觉,特别是生成很长的内容
暴露偏差,是一个发生在训练模型时的问题。
可以把它想象成一个学生在学校里只练习了选择题,但考试时却是问答题。
因为学生没有被教授如何回答问答题,他可能就会在考试时遇到困难。
同理,如果在训练语言模型时给它的任务和它在实际使用时的任务不一样,它生成的文本可能就会出现问题,特别是当要生成很长的内容时,这种不匹配的问题就会更明显。
-
参数知识:在预训练阶段学习的错误知识,将会产生严重的幻觉问题
参数知识指的是,语言模型在学习阶段(预训练阶段)所获取的信息和知识。
如果在这个阶段,模型学习到了错误的信息,比如错误的事实或者不正确的写作方式,那么它生成的文本就可能会包含很多错误,就像一个学生在考试前复习了错误的资料,考试时就会写出很多错误的答案。
比如问 GPT 3 + 2 = 4,是错的(经典美国小学生错误),这种错误一多,GPT就觉得是正确的。
数据层面
训练数据收集过程中,爬虫检索的数据可能包含虚假信息,从而让模型记忆了错误的知识。
过多的重复信息,也可能导致模型的知识记忆出现偏差,导致幻觉。
网络上的数据,主观的信息特别多,不清洗用不了。
幻觉怎么评估?
幻觉评估是指,评估和量化模型,在生成文本时,产生的不真实或不准确内容的频率和严重性。
具体的评估方法可以分为:
- 基于参考信息(Reference-based)
- 无参考信息(Reference-free)
Reference-based(基于参考信息)
这类方法依赖于与生成文本相关的参考信息,以评估模型的输出。
使用一些已知的、正确的文本作为参考,以此来评估和比较模型生成的文本。
基于模型的输入、预先定义的目标输出
使用一些统计学指标(如ROUGE、BLEU)来评估模型输出和目标参考信息(通常是正确的文本)之间的相似度。
这个目标输出通常是人类生成的文本,它被视为正确的回答。
例如,在一个摘要任务中,模型生成的摘要会与一个人类编写的摘要进行比较。
基于模型的输入
这种方法仅仅依靠模型的输入信息来评估生成的文本。
它不需要一个预定义的目标输出作为参考,而是评估模型输出的文本是否符合输入条件。
这在那些输出可以有多种正确形式的任务中特别有用。
例如,当生成一个故事或解释一个概念时,可能有多种准确和有信息量的方式来表达同一个概念。
可以使用 Knowledge F1 分数来衡量生成内容中知识点的准确性。
Reference-Free(无参考信息)
不依赖于任何预先定义的正确文本。这种评估方法直接分析生成文本的质量,无需将其与任何参考文本进行比较。
这些方法特别适用于那些难以获得或定义“正确答案”的场景,或者当希望评估模型是否能够独立生成高质量内容时。
例如,评估模型是否能够创建事实上准确的新闻报道,即使没有可用的参考新闻报道来比较。
基于IE(信息抽取)
将知识限定为可以用三元组(人物 - 出生地 - 城市)形式表达的关系和事件。
利用额外的信息抽取模型来提取这些知识点,然后使用另一个模型对这些信息进行验证。
问题:
- 可能存在IE模型的错误传播问题,信息抽取模型并不完美,有时会提取错误的信息
- 知识被限定在三元组形式(太过简化),不足以完全捕捉复杂的信息或关系
基于QA(问题回答)
这个过程大致可以分为三步:
-
生成问题和答案对:首先使用一个 大语言模型 来回答一个问题。然后,用另一个 问题生成模型 根据这个答案来创造一个新的问题。这样,就得到了一对问题和答案。
-
使用源信息回答问题:接着,模型会尝试用一些已知的信息来回答第一步中生成的问题。
-
比较答案:最后,通过比较第一步中生成的答案和第二步中模型给出的答案,来评估模型是否准确。
问题:这个方法可能会有两个主要问题。
- 首先,如果QA或QG模型本身有误,这些错误就会影响整个过程
- 其次,由于源信息不可能包含所有知识,所以对于某些问题,模型可能无法给出准确的答案
基于NLI(自然语言推理)
这个方法通过判断一个给定的信息(称为源信息)是否能够,支撑或包含生成的文本(即模型产生的内容)来工作。
问题:使用现成的NLI模型来检查事实可能不太准确。
这个方法只能检查源信息能否支持生成的文本,但不能评估那些需要更广泛世界知识的内容。
此外,这种方法是基于整个句子的,可能无法进行更细致的检查。
而且,幻觉问题(即模型产生的不真实内容),能否从源信息推断出来的问题并不完全相同。
基于Factualness Classification Metric(使用一个度量标准)
-
创建数据集:首先,需要准备一批数据,这些数据包括了真实(factual)和虚假(illusory,也就是“幻觉”)的信息。这些数据被用来表示什么是正确的信息,什么又是错误或虚构的信息。
-
训练模型:接着,使用这批数据来训练一个机器学习模型。这个模型的目的是学会区分真实和虚假的信息。它通过分析数据中的特征,学习判断信息的真实性。
-
评估新文本:一旦模型被训练好,就可以用它来评估新生成的文本。这个过程涉及到将新文本输入到模型中,模型会根据它所学到的,判断这些文本是更倾向于真实信息还是虚假信息。
这个方法是通过训练一个专门的模型来自动判断文本信息的真实性。
它可以帮助识别那些可能误导或不准确的内容,从而提高信息的质量和可信度。
人工评估
直接由专业的评估人员,评估生成文本的质量,这通常被认为是最可靠的方法,但也是成本最高的。
GPT 自动评估
在某些情况下使用经过训练的语言模型(如GPT-4)来辅助评估。
问题:但是GPT4也存在着严重的幻觉问题,即使经过retrival-augment,检索回来的 人工评估 信息也有可能是错误的。

上图介绍的是一个自动评估GPT模型性能的框架。
这个评估过程大致如下:
-
准备数据集:首先需要有一个预先定义好的数据集,它包含了各种类型的问题和对应的标准答案。这些数据通常是以JSON格式存储的,就像图中给出的示例那样。
-
设置评估环境:使用图中提供的用户界面,需要ChatGPT API Key。这是因为评估过程需要通过API与ChatGPT模型进行交互,以获得其对问题的回答。
-
选择问题进行评估:从数据集中选择特定的问题类型或者所有问题进行评估。
-
运行评估:系统会自动使用ChatGPT模型来回答选定的问题,并将模型的回答与标准答案进行比较。
-
计算评分:评估系统会根据模型的回答和标准答案的一致性来给出分数。在图中提到,如果一个回答部分正确,可能会得到0.5分的评分。
-
分析结果:评分结果可以帮助你了解GPT模型在不同类型的问题上的表现,哪些做得好,哪些需要改进。
-
改进模型:根据评估结果,你可以调整和优化你的模型,比如重新训练,调整参数,或者引入新的数据以提高准确性。
-
使用工具和脚本:图中提供的GitHub链接是自动评估的工具和脚本。
幻觉解决方案?
幻觉修正
arXiv.org 上相关论文研究:
- 人在回路的幻觉消除:利用人类的输入来指导模型,减少错误信息的生成。
- 利用多智能体辩论显著提升LM的事实性和推理能力:通过让多个AI模型相互辩论来提高生成文本的事实性和推理能力。
- 训练小模型后处理幻觉问题:使用额外的小型模型来校正主模型生成的答案。
- 通过推理时干预诱导LLM生成符合事实的答案:在模型进行推理时进行干预,以确保生成的答案是基于事实的。
- 工具增强的LLM自动纠正:使用工具来自动检测和纠正模型的错误。
- 零资源黑盒事实错误纠正:在没有额外信息的情况下纠正错误。
- 基于外部知识和自动反馈提升事实性:使用外部知识库和自动化的反馈机制来增强模型的事实性。
- 事实性增强的语言模型:开发了特别强调事实性的语言模型。
幻觉缓解
构建高质量数据集:
- 加权可信数据:在训练模型的时候,给那些来源可靠的数据(比如维基百科)更多的重视,而对那些不那么可靠的数据(比如假新闻)不予考虑。
- 筛选数据:用模型帮助我们检查数据集,找出那些可能让模型产生错误信息的数据,并将其删除。
优化模型结构:
-
融入人类偏置的设计:想象一下,如果你要制作一个能理解和处理信息的模型,你会想让它像人类那样思考。这里的建议就是在模型的设计中加入一些类似于人脑处理信息的方式。比如用图神经网络(GNN)这样的技术,它可以帮助模型更好地理解和组织复杂的信息,就像人脑那样。
-
减少生成时的随机性:想象你在写故事,但是要确保故事里的事实都是正确的。如果你让故事内容太随机,可能会出现一些不真实或不相关的部分。这个建议是说,在生成信息时,减少这种随机性或多样性,可以帮助确保模型生成的内容更加真实可靠。
-
使用检索增强:这个方法就像是在写作时查阅资料一样。通过查找和参考现有的信息和数据,模型可以更准确地生成相关的内容。这样做可以减少那些毫无根据或者不真实的“幻觉”内容的出现。
优化训练方式:
-
可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
这就像是有一个调节器,可以控制故事里虚构成分的多少。如果你想要更多基于现实的内容,就减少虚构元素;反之亦然。这样做可以更好地控制模型生成的内容,确保它既有创意又贴近现实。
-
提前规划骨架,再生成内容:先画一个简单的草图,然后再根据这个草图来完善和细化。先确定大致的结构或主题,然后再生成具体的内容,这样可以帮助模型更有组织、更准确地生成信息。
-
强化学习:这有点像训练宠物。你给模型一个任务,如果它做得好,就给它奖励;如果做得不好,就不给奖励。通过这种方式,模型学会了如何生成更准确、更少错误的内容。
-
多任务学习:这就像是让模型同时学习多种技能。比如,除了学习生成文本,它还可以学习其他任务,比如理解文本的情感。这样多方面的学习可以帮助模型更全面,更少出错。
-
后处理:这就好比是在写完文章后再进行校对。设计一个小模型,专门用来检查和修正已经生成的内容中的错误,确保最终的输出更加准确无误。
幻觉相关研究