【NeRF数据集】LLFF格式数据集处理colmap结果记录
- 1. 基于colmap的配置与运行,获取图像及其对应的相机位姿;
- 2. 使用 LLFF格式数据集制作,将匹配的位姿转化为LLFF格式;
- 3. 上传所需文件和设置配置文件,将所需文件上传至NeRF对应文件夹并设置配置文件。
1. 基于colmap的配置与运行,获取图像及其对应的相机位姿;
colmap配置见链接 处理流程大概如下:
- 按照上述链接配置colmap运行环境,使用iphone获取场景内容数作为数据,
- 再创建一个文件路径 /data/output/sift/ 再在这个文件路径中创建 x.db
mkdir /data/output/sift/
touch kf5_sift.db
4. 基于收集拍摄的视频,使用脚本处理获取照片,提取特征点 相机模型悬着 simple_pinhole
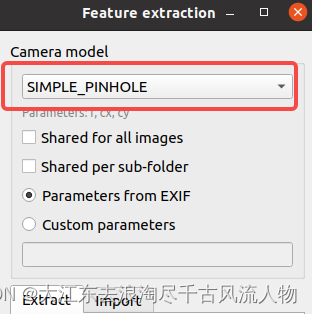
7c84d40adfc1f1889e3df40.png)
- feature matching ,然后重建选择FILE->Export all model 保存数据

好像结果还不错

2. 使用 LLFF格式数据集制作,将匹配的位姿转化为LLFF格式;
为什么要使用llff格式数据?
而不是直接输入图像数据,当然也可以,只是存在2个问题,1是收敛速度变慢,2是重建效果变差。
LLFF格式数据可以将对应图片参数、相机位姿和相机参数简洁有效地存储在一个npy文件中,以方便python读取,且NeRF模型源码拥有直接对LLFF格式数据集进行训练的配置和模块,便于研究者使用。下面将详细展示其制作流程。而上面这些数据正是colmap的输出结果,见1中导出的结果。
得到COLMAP位姿匹配数据后,我们要对每张图片的位姿信息进行格式转换,转换为LLFF格式方便Nerf模型读取。
打开LLFF脚本,打开imgs2poses.py文件,修改如下内容,改为刚才的工作目录,然后在终端运行该代码
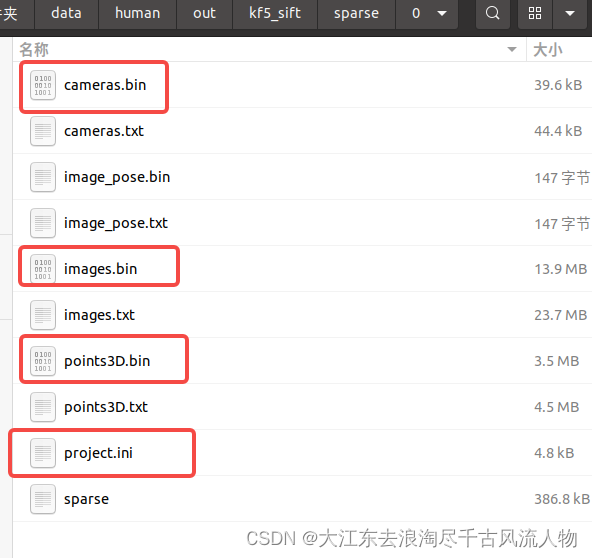
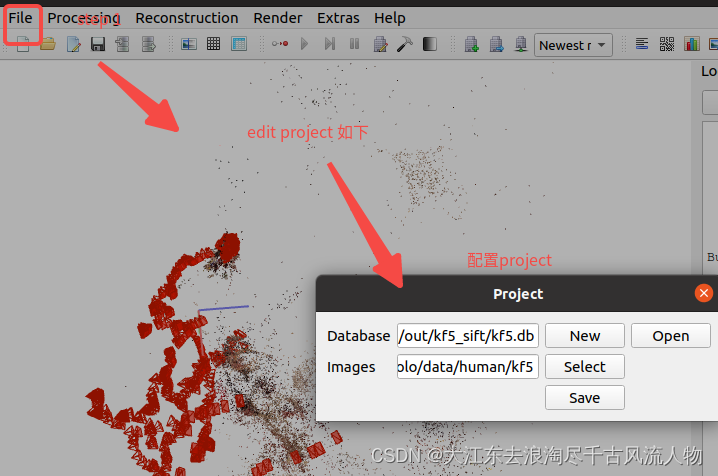
或者 File 导出 export model,新建名称为sparse保存的位置,sparse文件下的0文件作为输出结果,这里包含具体见上图
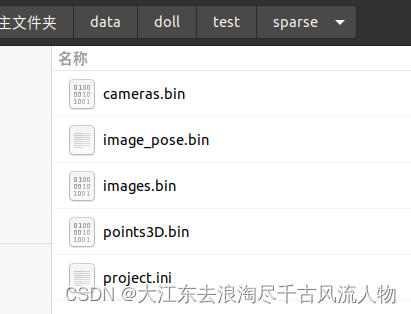
创建文件路径与名称如下:
python imgs2poses.py /home/nolo/data/human/out/kf5_sift/
官网这个原始代码存在错误,报错信息如下
ERROR: the correct camera poses for current points cannot be accessed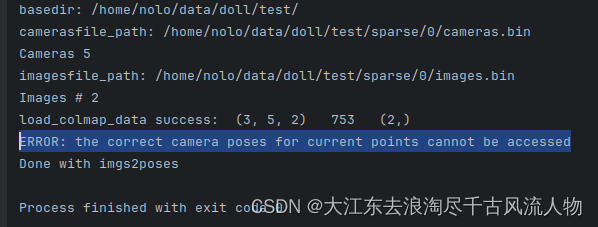
这里是匹配的位姿和图片数目不同
通常来讲,如果用于匹配的图片拍摄的比较好,是不会出现匹配不上位姿的情况,但是如果出现了,就需要手动剔除匹配不到位姿的图片,可以通过在 LLFF/llff/poses/pose_utils.py 文件的32行左右添加如下代码:
也可以在原始的代码上做如下修改:
修复后 pose_utils.py 如下:
import numpy as np
import os
import sys
import imageio
import skimage.transform
from llff.poses.colmap_wrapper import run_colmap
import llff.poses.colmap_read_model as read_model
def save_views(realdir,names):
with open(os.path.join(realdir,'view_imgs.txt'), mode='w') as f:
f.writelines('\n'.join(names))
f.close()
def load_save_pose(realdir):
# load colmap data
camerasfile = os.path.join(realdir, 'sparse/0/cameras.bin')
camdata = read_model.read_cameras_binary(camerasfile)
list_of_keys = list(camdata.keys())
cam = camdata[list_of_keys[0]]
print( 'Cameras', cam)
h, w, f = cam.height, cam.width, cam.params[0]
hwf = np.array([h,w,f]).reshape([3,1])
imagesfile = os.path.join(realdir, 'sparse/0/images.bin')
imdata = read_model.read_images_binary(imagesfile)
real_ids = [k for k in imdata]
w2c_mats = []
bottom = np.array([0,0,0,1.]).reshape([1,4])
names = [imdata[k].name for k in imdata]
print( 'Images #', len(names))
# if (len(names)< 32):
# raise ValueError(f'{realdir} only {len(names)} images register, need Re-run colmap or reset the threshold')
perm = np.argsort(names)
sort_names = [names[i] for i in perm]
save_views(realdir,sort_names)
for k in imdata:
im = imdata[k]
R = im.qvec2rotmat()
t = im.tvec.reshape([3,1])
m = np.concatenate([np.concatenate([R, t], 1), bottom], 0)
w2c_mats.append(m)
w2c_mats = np.stack(w2c_mats, 0)
c2w_mats = np.linalg.inv(w2c_mats)
poses = c2w_mats[:, :3, :4].transpose([1,2,0])
poses = np.concatenate([poses, np.tile(hwf[..., np.newaxis], [1,1,poses.shape[-1]])], 1)
points3dfile = os.path.join(realdir, 'sparse/0/points3D.bin')
pts3d = read_model.read_points3d_binary(points3dfile)
# must switch to [-u, r, -t] from [r, -u, t], NOT [r, u, -t]
poses = np.concatenate([poses[:, 1:2, :], poses[:, 0:1, :], -poses[:, 2:3, :], poses[:, 3:4, :], poses[:, 4:5, :]], 1)
# save pose
pts_arr = []
vis_arr = []
for k in pts3d:
pts_arr.append(pts3d[k].xyz)
cams = [0] * poses.shape[-1]
for ind in pts3d[k].image_ids:
if len(cams) < real_ids.index(ind):
print('ERROR: the correct camera poses for current points cannot be accessed')
return
cams[real_ids.index(ind)] = 1
vis_arr.append(cams)
pts_arr = np.array(pts_arr)
vis_arr = np.array(vis_arr)
print( 'Points', pts_arr.shape, 'Visibility', vis_arr.shape)
zvals = np.sum(-(pts_arr[:, np.newaxis, :].transpose([2,0,1]) - poses[:3, 3:4, :]) * poses[:3, 2:3, :], 0)
valid_z = zvals[vis_arr==1]
print( 'Depth stats', valid_z.min(), valid_z.max(), valid_z.mean() )
save_arr = []
for i in perm:
vis = vis_arr[:, i]
zs = zvals[:, i]
zs = zs[vis==1]
close_depth, inf_depth = np.percentile(zs, .1), np.percentile(zs, 99.9)
save_arr.append(np.concatenate([poses[..., i].ravel(), np.array([close_depth, inf_depth])], 0))
save_arr = np.array(save_arr)
np.save(os.path.join(realdir, 'poses_bounds.npy'), save_arr)
def load_colmap_data(realdir):
camerasfile = os.path.join(realdir, 'sparse/0/cameras.bin')
print("camerasfile_path:", camerasfile)
camdata = read_model.read_cameras_binary(camerasfile)
# print("camdate: ", camdata)
# cam = camdata[camdata.keys()[0]]
list_of_keys = list(camdata.keys())
cam = camdata[list_of_keys[0]]
print( 'Cameras', len(cam))
h, w, f = cam.height, cam.width, cam.params[0]
# w, h, f = factor * w, factor * h, factor * f
hwf = np.array([h,w,f]).reshape([3,1])
# print(hwf)
imagesfile = os.path.join(realdir, 'sparse/0/images.bin')
print("imagesfile_path:", imagesfile)
imdata = read_model.read_images_binary(imagesfile)
# print(imdata)
w2c_mats = []
bottom = np.array([0,0,0,1.]).reshape([1,4])
names = [imdata[k].name for k in imdata]
print( 'Images #', len(names))
perm = np.argsort(names)
for k in imdata:
im = imdata[k]
R = im.qvec2rotmat()
t = im.tvec.reshape([3,1])
m = np.concatenate([np.concatenate([R, t], 1), bottom], 0)
w2c_mats.append(m)
w2c_mats = np.stack(w2c_mats, 0)
c2w_mats = np.linalg.inv(w2c_mats)
poses = c2w_mats[:, :3, :4].transpose([1,2,0])
poses = np.concatenate([poses, np.tile(hwf[..., np.newaxis], [1,1,poses.shape[-1]])], 1)
points3dfile = os.path.join(realdir, 'sparse/0/points3D.bin')
pts3d = read_model.read_points3d_binary(points3dfile)
# must switch to [-u, r, -t] from [r, -u, t], NOT [r, u, -t]
poses = np.concatenate([poses[:, 1:2, :], poses[:, 0:1, :], -poses[:, 2:3, :], poses[:, 3:4, :], poses[:, 4:5, :]], 1)
# print("poses", poses)
# print("pts3d shape: ", pts3d.shape())
# print("perm: ",perm)
return poses, pts3d, perm
def save_poses(basedir, poses, pts3d, perm):
pts_arr = []
vis_arr = []
for k in pts3d:
pts_arr.append(pts3d[k].xyz)
cams = [0] * poses.shape[-1]
for ind in pts3d[k].image_ids:
# print("cams_len: ",len(cams))
# print("ind: ",ind)
if len(cams) < ind - 1:
print('ERROR: the correct camera poses for current points cannot be accessed')
return
cams[ind-1] = 1
vis_arr.append(cams)
pts_arr = np.array(pts_arr)
vis_arr = np.array(vis_arr)
print( 'Points', pts_arr.shape, 'Visibility', vis_arr.shape )
zvals = np.sum(-(pts_arr[:, np.newaxis, :].transpose([2,0,1]) - poses[:3, 3:4, :]) * poses[:3, 2:3, :], 0)
valid_z = zvals[vis_arr==1]
print( 'Depth stats', valid_z.min(), valid_z.max(), valid_z.mean() )
save_arr = []
for i in perm:
vis = vis_arr[:, i]
zs = zvals[:, i]
zs = zs[vis==1]
close_depth, inf_depth = np.percentile(zs, .1), np.percentile(zs, 99.9)
# print( i, close_depth, inf_depth )
save_arr.append(np.concatenate([poses[..., i].ravel(), np.array([close_depth, inf_depth])], 0))
save_arr = np.array(save_arr)
print("save_arr: ", save_arr)
np.save(os.path.join(basedir, 'poses_bounds.npy'), save_arr)
def minify_v0(basedir, factors=[], resolutions=[]):
needtoload = False
for r in factors:
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
for r in resolutions:
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
if not needtoload:
return
def downsample(imgs, f):
sh = list(imgs.shape)
sh = sh[:-3] + [sh[-3]//f, f, sh[-2]//f, f, sh[-1]]
imgs = np.reshape(imgs, sh)
imgs = np.mean(imgs, (-2, -4))
return imgs
imgdir = os.path.join(basedir, 'images')
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgs = np.stack([imageio.imread(img)/255. for img in imgs], 0)
for r in factors + resolutions:
if isinstance(r, int):
name = 'images_{}'.format(r)
else:
name = 'images_{}x{}'.format(r[1], r[0])
imgdir = os.path.join(basedir, name)
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
if isinstance(r, int):
imgs_down = downsample(imgs, r)
else:
imgs_down = skimage.transform.resize(imgs, [imgs.shape[0], r[0], r[1], imgs.shape[-1]],
order=1, mode='constant', cval=0, clip=True, preserve_range=False,
anti_aliasing=True, anti_aliasing_sigma=None)
os.makedirs(imgdir)
for i in range(imgs_down.shape[0]):
imageio.imwrite(os.path.join(imgdir, 'image{:03d}.png'.format(i)), (255*imgs_down[i]).astype(np.uint8))
def minify(basedir, factors=[], resolutions=[]):
needtoload = False
for r in factors:
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
for r in resolutions:
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
if not needtoload:
return
from shutil import copy
from subprocess import check_output
imgdir = os.path.join(basedir, 'images')
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgdir_orig = imgdir
wd = os.getcwd()
for r in factors + resolutions:
if isinstance(r, int):
name = 'images_{}'.format(r)
resizearg = '{}%'.format(int(100./r))
else:
name = 'images_{}x{}'.format(r[1], r[0])
resizearg = '{}x{}'.format(r[1], r[0])
imgdir = os.path.join(basedir, name)
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
os.makedirs(imgdir)
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
ext = imgs[0].split('.')[-1]
args = ' '.join(['mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)])
print(args)
os.chdir(imgdir)
check_output(args, shell=True)
os.chdir(wd)
if ext != 'png':
check_output('rm {}/*.{}'.format(imgdir, ext), shell=True)
print('Removed duplicates')
print('Done')
def load_data(basedir, factor=None, width=None, height=None, load_imgs=True):
poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy'))
poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1,2,0])
bds = poses_arr[:, -2:].transpose([1,0])
img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \
if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0]
sh = imageio.imread(img0).shape
sfx = ''
if factor is not None:
sfx = '_{}'.format(factor)
minify(basedir, factors=[factor])
factor = factor
elif height is not None:
factor = sh[0] / float(height)
width = int(sh[1] / factor)
minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
elif width is not None:
factor = sh[1] / float(width)
height = int(sh[0] / factor)
minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
else:
factor = 1
imgdir = os.path.join(basedir, 'images' + sfx)
if not os.path.exists(imgdir):
print( imgdir, 'does not exist, returning' )
return
imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')]
if poses.shape[-1] != len(imgfiles):
print( 'Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) )
return
sh = imageio.imread(imgfiles[0]).shape
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])
poses[2, 4, :] = poses[2, 4, :] * 1./factor
if not load_imgs:
return poses, bds
# imgs = [imageio.imread(f, ignoregamma=True)[...,:3]/255. for f in imgfiles]
def imread(f):
if f.endswith('png'):
return imageio.imread(f, ignoregamma=True)
else:
return imageio.imread(f)
imgs = imgs = [imread(f)[...,:3]/255. for f in imgfiles]
imgs = np.stack(imgs, -1)
print('Loaded image data', imgs.shape, poses[:,-1,0])
return poses, bds, imgs
def gen_poses(basedir, match_type, factors=None):
files_needed = ['{}.bin'.format(f) for f in ['cameras', 'images', 'points3D']]
if os.path.exists(os.path.join(basedir, 'sparse/0')):
files_had = os.listdir(os.path.join(basedir, 'sparse/0'))
else:
files_had = []
if not all([f in files_had for f in files_needed]):
print( 'Need to run COLMAP' )
run_colmap(basedir, match_type)
else:
print('Don\'t need to run COLMAP')
print( 'Post-colmap')
print("basedir: {}".format(basedir))
load_save_pose(basedir)
# poses, pts3d, perm = load_colmap_data(basedir)
# print('load_colmap_data success: ',poses.shape," ",pts3d.__len__()," ",perm.shape)
# save_poses(basedir, poses, pts3d, perm)
if factors is not None:
print( 'Factors:', factors)
minify(basedir, factors)
print( 'Done with imgs2poses' )
return True
imgs2poses.py
from llff.poses.pose_utils import gen_poses
import sys
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--match_type', type=str,
default='exhaustive_matcher', help='type of matcher used. Valid options: \
exhaustive_matcher sequential_matcher. Other matchers not supported at this time')
parser.add_argument('scenedir', type=str,
default='/home/nolo/data/doll/test/',
help='input scene directory')
args = parser.parse_args()
if args.match_type != 'exhaustive_matcher' and args.match_type != 'sequential_matcher':
print('ERROR: matcher type ' + args.match_type + ' is not valid. Aborting')
sys.exit()
if __name__=='__main__':
gen_poses(args.scenedir, args.match_type)
运行完成后,得到如下提示(注意红框内是之前匹配上的图片名称,这个下面会用到):
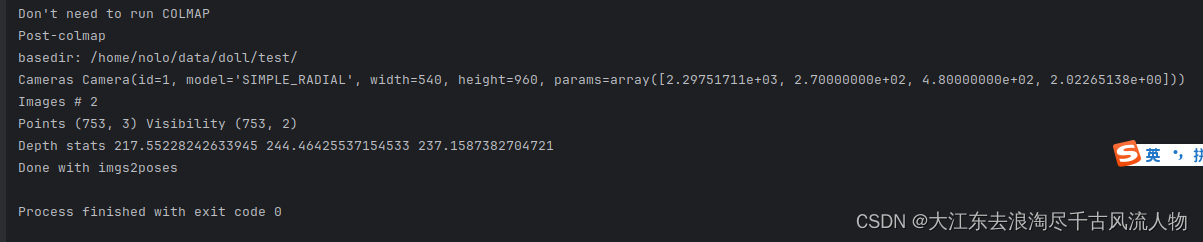
此时,工作目录下产生poses_bounds.npy文件 生成文件如下:
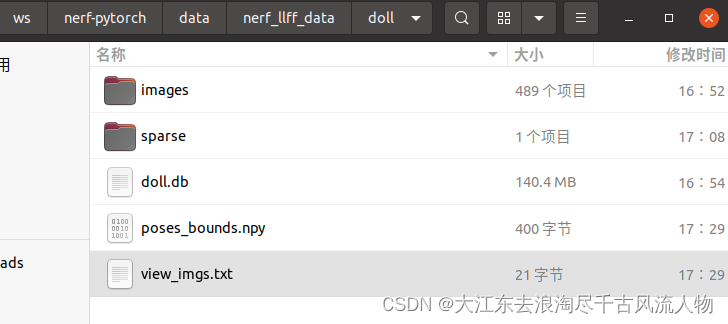
3. 上传所需文件和设置配置文件,将所需文件上传至NeRF对应文件夹并设置配置文件。
最后,需要将相关文件上传至NeRF代码的相应文件夹中。
再工程 nerf-pytorch 工程的config中添加 doll.txt 配置文件
expname = doll_test
basedir = ./logs
datadir = ./data/nerf_llff_data/doll
dataset_type = llff
factor = 8
llffhold = 8
N_rand = 1024
N_samples = 64
N_importance = 64
use_viewdirs = True
raw_noise_std = 1e0
完成数据制作!!!
配置nerf-pytorch 工程 ,开始训练!!!!
/ws/nerf-pytorch$
python run_nerf.py --config configs/doll.txt
训练结果如下:











![[DevOps-05] Jenkins实现CI/CD操作](https://img-blog.csdnimg.cn/img_convert/95844817c8aa308a57410a2e00cee9e1.png)