文章目录
- 1、URL
- 2、http协议的宏观构成
- 3、详细理解http协议
- 1、http请求
- 2、http响应
- 1、有效载荷格式
- 2、有效载荷长度
- 3、客户端要访问的资源类型
- 4、修改响应写法
- 5、处理不同的请求
- 6、跳转
- 3、请求方法(GET/POST)
- 4、HTTP状态码(实现3和4开头的)
- 5、HTTP常见Header
- 6、http的会话保持功能(Cookie)
- 4、结束
本篇很长。我计划http和https总共两篇。
HTTP可以把网页资源,文本资源,音视频资源都拿到,HTTP叫做超文本传输协议。
客户端和服务端,两者做交互,客户端把自己的东西给别人,服务端把别人的东西拿到自己本地。系统角度,这是IO操作;网络角度,这是请求(request)回复(reponse)操作;用户角度,则有上行和下行操作,上行就是把自己东西给别人,下行拿别人的东西。
网页,图片,音视频等这些都叫资源。
1、URL
要想访问服务器,需要知道服务器的IP和端口号,但实际生活中,我们更多知道的是网站的域名,用域名去访问网站,而不是知道IP地址和端口号。虽然用域名来访问一个网站,但是会有域名解析服务,会把IP地址拿出来。
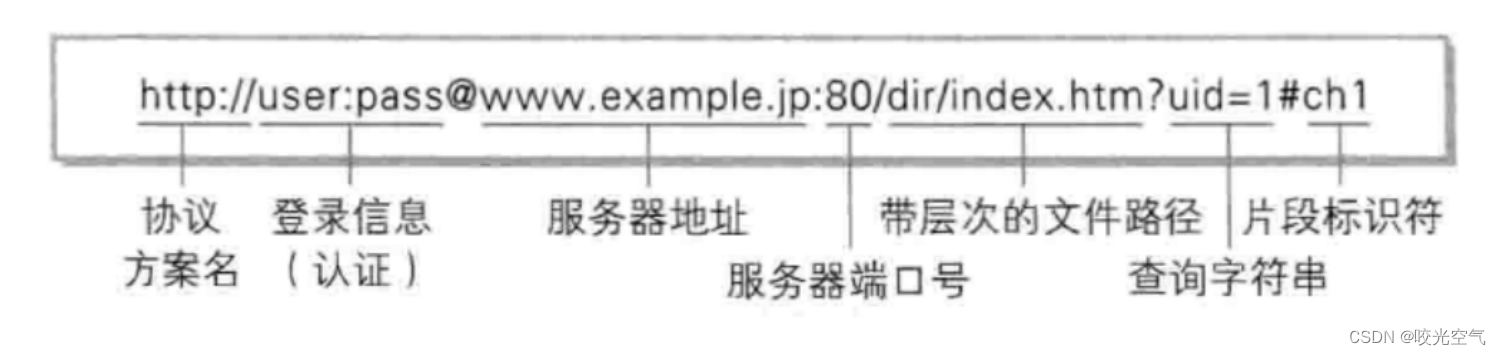
登录信息现在已经没有,//后直接接上www。之前已经知道,服务端的端口号不能随意指定,必须是众所周知且不能随意更改的,端口号和成熟的应用层协议是一一对应的,https常用的是443,http常用的是80,端口号在浏览器的底层代码中,检测哪个协议就用哪个端口号,协议名称和端口号是1对1强相关的。
到了服务器端口号时,我们就已经能访问这个网址了,但是要访问什么,得看后面带层次的文件路径,这里就是访问内容。网站内部是用Linux来创建的,斜杠就是Linux中的文件分隔符。图片中的dir是web根目录,这个根目录是web进程自己的一个目录。问号是一个分隔符,右面的是一些参数。有些写法是xx=xxx,这其实就是kv的,有多份kv就用&来分隔。井号后面的是片段标识符,这个在现在很少见,了解一下即可。
协议,域名(也就是上图中的服务器地址),端口号,资源路径,参数,这些部分就组成了URL。URL是统一资源定位符,通过URL可以访问网络中唯一一个资源(服务器地址也就是IP地址,端口号,文件路径,三个都是唯一的)。URL是我们访问网络的一个超链接。
如果搜索问号,井号,斜杠这些特殊字符,浏览器会把它们都转换成别的样式,这是url的encode编码,解决在url中出现特殊符号。比如百度搜索中,会在查询字符串wd=后面加上搜索的东西。服务端收到的就是这些经过处理后的我们输入的要搜索的东西,得到这些特殊符号后再转化回来,这就是decode操作。

不止问号,井号,还有一些符号也会做处理,比如汉字,url有自己的转码方法。
2、http协议的宏观构成
http协议是基于TCP套接字的应用层的协议。http由4部分构成(也有分成2层的,这里是全写出来)

报头的形式就是Key: Value,后面跟回车,请求报头就是多行KV结构组成的。 空行能够区分上部分和下部分。请求行和请求报头可以说成报头部分,有效载荷则是http协议的有效载荷。对于报头和载荷,http读到空行就认为是报头结束了,因为报头是多行的,读完之后就是空行部分,然后再开始载荷,这也就分离了报头和载荷;序列化反序列化就像之前所写的,序列化是把所有消息,所有请求都放到一行发送过去,反序列化则按照\r\n分出来多行。
上面是请求的http协议结构,接收请求,也就是响应的结构一样,只是名字变了,从上到下为状态行、响应报头、空行、有效载荷(各种资源,比如html/css,图片,音频、视频等)。状态行里包含协议版本、状态码、状态码描述,协议版本和请求的那个版本一样,状态码是一个数字,描述则是状态码对应的状态,比如状态码404。接收的http协议也是读到空行就认为读完了报头,就可以把报头和载荷分开。
请求的部分中的协议版本是客户端版本,接收的版本则是服务端版本,比如微信,有一些用户会不升级微信,而服务端那里已经升级了,这就出现了版本不对应的情况。为了解决这个问题,在进行请求之前,就会先检验客户端的版本,服务端暴露给客户端对应版本的http。所以服务端不是只提供最新版本的,而是客户端什么版本服务端就提供什么版本。
3、详细理解http协议
1、http请求
通过代码来向浏览器发送请求。用到上一篇中网络计算器中的err.hpp和Sock.hpp和log.hpp,Http_v1目录内创建以下文件:
err.hpp
#pragma once
enum
{
USAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR,
CONNECT_ERR,
SETSID_ERR,
OPEN_ERR
};
log.hpp
#pragma once
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cstdarg>
#include <ctime>
#include <sys/types.h>
#include <unistd.h>
const std::string filename0 = "log/tcpserver.log.Debug";
const std::string filename1 = "log/tcpserver.log.Info";
const std::string filename2 = "log/tcpserver.log.Warning";
const std::string filename3 = "log/tcpserver.log.Error";
const std::string filename4 = "log/tcpserver.log.Fatal";
const std::string filename5 = "log/tcpserver.log.Unknown";
enum
{
Debug = 0,//调试信息
Info,//正常信息
Warning,//告警,不影响运行
Error,//一般错误
Fatal,//严重错误
Unknown
};
static std::string toLevelString(int level, std::string& filename)
{
switch(level)
{
case Debug:
filename = filename0;
return "Debug";
case Info:
filename = filename1;
return "Info";
case Warning:
filename = filename2;
return "Warning";
case Error:
filename = filename3;
return "Error";
case Fatal:
filename = filename4;
return "Fatal";
default:
filename = filename5;
return "Unknown";
}
}
static std::string getTime()
{
time_t curr = time(nullptr);//拿到当前时间
struct tm *tmp = localtime(&curr);//这个结构体有对于时间单位的int变量
char buffer[128];
snprintf(buffer, sizeof(buffer), "%d-%d-%d %d:%d:%d", tmp->tm_year + 1900, tmp->tm_mon + 1, tmp->tm_mday, \
tmp->tm_hour, tmp->tm_min, tmp->tm_sec);//这些tm_的变量就是结构体中自带的,tm_year是从1900年开始算的,所以+1900
return buffer;
}
//日志格式: 日志等级 时间 pid 消息体
//logMessage(DEBUG, "hello: %d, %s", 12, s.c_str()); 12以%d形式打印, s.c_str()以%s形式打印
void logMessage(int level, const char* format, ...)//...就是可变参数,format是输出格式
{
//写入到两个缓冲区中
char logLeft[1024];//用来显示日志等级,时间,pid
std::string filename;
std::string level_string = toLevelString(level, filename);
std::string curr_time = getTime();
snprintf(logLeft, sizeof(logLeft), "[%s] [%s] [%d] ", level_string.c_str(), curr_time.c_str(), getpid());
char logRight[1024];//用来显示消息体
va_list p;
va_start(p, format);
//直接用这个接口来对format进行操作,提取信息
vsnprintf(logRight, sizeof(logRight), format, p);
va_end(p);
//打印
printf("%s%s\n", logLeft, logRight);
//format是一个字符串,里面有格式,比如%d, %c,通过这个就可以用arg来提取参数
//保存到文件中
FILE* fp = fopen(filename.c_str(), "a");
if(fp == nullptr) return ;
fprintf(fp, "%s%s\n", logLeft, logRight);
fflush(fp);
fclose(fp);
//va_list p;//char*
//下面是三个宏函数
//int a = va_arg(p, int);//根据类型提取参数
//va_start(p, format);//让p指向可变参数部分的起始地址
//va_end(p);//把p置为空, p = NULL
}
Sock.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdlib>
#include <cstring>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <unistd.h>
#include "err.hpp"
#include "log.hpp"
static const int gbacklog = 32;
static const int defaultfd = -1;
class Sock
{
public:
Sock(): _sock(defaultfd)
{}
void Socket()
{
_sock= socket(AF_INET, SOCK_STREAM, 0);
if(_sock < 0)
{
logMessage(Fatal, "socket error, code: %d, errstring: %s", errno, strerror(errno));
exit(SOCKET_ERR);
}
}
void Bind(const uint16_t& port)
{
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;
if(bind(_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
logMessage(Fatal, "bind error, code: %d, errstring: %s", errno, strerror(errno));
exit(BIND_ERR);
}
}
void Listen()
{
if(listen(_sock, gbacklog) < 0)//第二个参数维护了一个队列,发送了连接请求但是服务端没有处理的客户端,服务端开始accept后,就会出现另一个队列,就是服务端接受了请求但还没被accept的客户端
{
logMessage(Fatal, "listen error, code: %d, errstring: %s", errno, strerror(errno));
exit(LISTEN_ERR);
}
}
int Accept(std::string* clientip, uint16_t* clientport)
{
struct sockaddr_in temp;
socklen_t len = sizeof(temp);
int sock = accept(_sock, (struct sockaddr*)&temp, &len);
if(sock < 0)
{
logMessage(Warning, "accept error, code: %d, errstring: %s", errno, strerror(errno));
}
else
{
*clientip = inet_ntoa(temp.sin_addr);//这个函数就可以从结构体中拿出ip地址,转换好后返回
*clientport = ntohs(temp.sin_port);
}
return sock;
}
int Connect(const std::string& serverip, const uint16_t& serverport)//让别的客户端来连接服务端
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(serverport);
server.sin_addr.s_addr = inet_addr(serverip.c_str());
return connect(_sock, (struct sockaddr*)&server, sizeof(server));//先不打印消息
}
int Fd()
{
return _sock;
}
void Close()
{
if(_sock != defaultfd) close(_sock);
}
~Sock()
{}
private:
int _sock;
};
makefile
httpserver:main.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f httpserver
main.cc
#include "HttpServer.hpp"
#include <memory>
int main()
{
uint16_t port = 8888;
std::unique_ptr<HttpServer> tsvr(new HttpServer(port));
tsvr->InitServer();
tsvr->Start();
return 0;
}
HttpServer.hpp
#pragma once
#include <iostream>
#include <string>
static const uint16_t defaultport = 8888;
class HttpServer
{
public:
HttpServer(int port = defaultport)
:port_(port)
{}
void InitServer()
{
;
}
void Start()
{
;
}
~HttpServer() {}
private:
int port_;
};
接下来再继续写具体的实现,HttpServer.hpp文件中,说明在注释中
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>//在Start中加入多线程
#include <functional>//线程执行函数中要用到
#include "Sock.hpp"//加入套接字
static const uint16_t defaultport = 8888;
class HttpServer;
class ThreadData//线程中使用的数据类型
{
public:
ThreadData(int sock, const std::string ip, const uint16_t port, HttpServer* tsvrp)
:_sock(sock), _ip(ip), _port(port), _tsvrp(tsvrp)
{}
~ThreadData() {}
public:
int _sock;
std::string _ip;
uint16_t _port;
HttpServer* _tsvrp;
};
class HttpServer
{
public:
HttpServer(int port = defaultport)
:port_(port)
{}
void InitServer()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
}
static void* threadRoutine(void* args)//线程执行的函数,这里就是要对http进行处理,可以通过获取的套接字进行读写
{
pthread_detach(pthread_self());
ThreadData* td = static_cast<ThreadData*>(args);//安全的强转类型
}
void Start()
{
for( ; ; )//处理请求
{
std::string clientip;
uint16_t clientport;
int sock = listensock_.Accept(&clientip, &clientport);//获取客户端链接
if(sock < 0) continue;
pthread_t tid;
ThreadData* td = new ThreadData(sock, clientip, clientport, this);//需要传当前对象this,否则无法正常执行
pthread_create(&tid, nullptr, threadRoutine, td);
}
}
~HttpServer() {}
private:
int port_;
Sock listensock_;
};
这是已经做好了准备工作。开始处理
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>//在Start中加入多线程
#include <functional>//线程执行函数中要用到
#include "Sock.hpp"//加入套接字
static const uint16_t defaultport = 8888;
class HttpServer;
using func_t = std::function<std::string(const std::string&)>;//定义了一个参数对象,返回值是string类型,参数时string&,放到成员里
class ThreadData//线程中使用的数据类型
{
public:
ThreadData(int sock, const std::string ip, const uint16_t port, HttpServer* tsvrp)
:_sock(sock), _ip(ip), _port(port), _tsvrp(tsvrp)
{}
~ThreadData() {}
public:
int _sock;
std::string _ip;
uint16_t _port;
HttpServer* _tsvrp;
};
class HttpServer
{
public:
HttpServer(func_t f, int port = defaultport) :func(f), port_(port)
{}
void InitServer()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
}
void HandlerHttpRequest(int sock)
{
char buffer[4096];
std::string request;
//我们认为只要一次就能读完
ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);//-1是因为char类型,会读到\0,-1就把\0去掉
if(s > 0)
{
buffer[s] = 0;
request = buffer;
//处理报头
std::string response = func(request);
send(sock, response.c_str(), response.size(), 0);//往套接字里发送,发给客户端
}
else logMessage(Info, "client quit...");
}
static void* threadRoutine(void* args)//线程执行的函数,这里就是要对http进行处理,可以通过获取的套接字进行读写
{
pthread_detach(pthread_self());
ThreadData* td = static_cast<ThreadData*>(args);//安全的强转类型
//处理--读写
td->_tsvrp->HandlerHttpRequest(td->_sock);
close(td->_sock);
delete td;
return nullptr;
}
void Start()
{
for( ; ; )//处理请求
{
std::string clientip;
uint16_t clientport;
int sock = listensock_.Accept(&clientip, &clientport);//获取客户端链接
if(sock < 0) continue;
pthread_t tid;
ThreadData* td = new ThreadData(sock, clientip, clientport, this);//需要传当前对象this,否则无法正常执行
pthread_create(&tid, nullptr, threadRoutine, td);
}
}
~HttpServer() {}
private:
int port_;
Sock listensock_;
func_t func;
};
所以在这里:std::string response = func(request); 上层调用完函数后,也就是处理请求后会返回结果,给到response,然后走send接口。那么上层的调用就写在main.cc中
#include "HttpServer.hpp"
#include <memory>
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
return "";
}
int main()
{
uint16_t port = 8888;
std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp, port));
tsvr->InitServer();
tsvr->Start();
return 0;
}
即使返回的是空,send也可以发送。
写到这里,就可以做出实际操作了。make后,./httpserver运行起来,打开浏览器,最上方输入服务端ip地址:8888,就会发送一次http请求。不过别人那里不会有什么东西,因为我们自己还没给响应。
看一个例子

可以看到都是… : …的形式,也就是上面所写的请求报头的形式,因为main.cc的打印语句本身就有换行,所以所有报头加上一个空行才是整体的请求报头,接着下面还有一个空行,也就是结构中的空行,图中显示不明显。
第一行是请求行,有请求方法GET,URL /,以及协议版本HTTP/1.1,因为刚才用的只是ip地址和端口号,没有写要访问的路径,所以URL就只有/,如果我们要打开的网页是ip地址:端口号/a/b/c.html,那么请求行中就会显示GET /a/b/c.html HTTP/1.1,这意味着是有一个客户端想访问服务端的c.html文件,路径是/a/b/c.html。
下面的是kv结构的请求报头,Host可以直接看出来,是服务端的ip地址和端口号。Connection是这次请求的链接模式,有长链接和短链接。Cache-Control是指通信时产生的缓存的机制,表示最大缓存的生成时间,默认为0,没有缓存。Accept-Encoding表示客户端能接收的编码类型。Accept-Language表示客户端能接收的编码符号。User-Agent表示这次请求的客户端的信息。
2、http响应
telnet和postman都可以用作响应,这里不做说明。我们自己写一个简单的响应。main.cc文件中
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
//按照响应格式来写
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头不写
response += SEP;//空行
response += "hello Http";//当作有效载荷, 也就是正文部分
return response;
}
这样就可以简单响应了。
1、有效载荷格式
通常情况下,有效载荷不是一个字符串,而是网页。但不是硬编码进一个网页信息,我们需要有文件才能操作。建一个html后缀的文件
<html>
<body>
<h1>this is a test</h1>
</body>
</html>
在main.cc中
#include "HttpServer.hpp"
#include "err.hpp"
#include <memory>
const std::string SEP = "\r\n";
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
//按照响应格式来写
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头不写
response += SEP;//空行
response += "<html> <body> <h1>this is a test</h1></body></html>";//当作有效载荷, 也就是正文部分
return response;
}
int main(int argc, char* argv[])//这里就在./httpserver后自己打上端口号
{
if(argc != 2) exit(USAGE_ERR);
uint16_t port = atoi(argv[1]);
std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp, port));
tsvr->InitServer();
tsvr->Start();
return 0;
}
端口号必须是自己的云服务器接受的端口,这个在官网上看自己的主机,比如UCloud就是这样:
2、有效载荷长度
到现在为止,读到空行部分就知道报头读完了,接下来读有效载荷,但这样并不知道有效载荷有多长。有效载荷的长度在报头的中一个Key:Content-Length,它的Value就是Body的长度,也就是有效载荷的长度。响应这里做好有效载荷后,再给到客户端,客户端就需要知道有效载荷的长度,如果不知道就没法在字节流中提取。不过浏览器对此有更专业的解决办法,即使没有报头也能知道有效载荷的长度。
我们可以自己写上报头
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
//按照响应格式来写
std::string body = "<html> <body> <h1>this is a test</h1></body></html>";
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头
response += "Content-Length: " + std::to_string(body.size()) + SEP;//报头的格式,是状态行,就得加上\r\n
//空行
response += SEP;
response += body;//当作有效载荷, 也就是正文部分
return response;
}
这样的话,有的浏览器会把< html > < body >打印出来,有的则会直接打印this is a test,这就是浏览器的处理不同。
3、客户端要访问的资源类型
除了长度,有效载荷本身就是一个混合的,会包含各种资源,那么客户端就得告诉服务端需要返回的是什么资源,服务端再去做处理。这个也是报头的一个Key:Content-Type,表示Body的种类。
不论是图片还是音频,本质都是文件,且都有自己的后缀,有Content-Type表,我们见到的后缀放到Content-Type中的写法。
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
//按照响应格式来写
std::string body = "<html> <body> <h1>this is a test</h1></body></html>";
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头
response += "Content-Length: " + std::to_string(body.size()) + SEP;//报头的格式,是状态行,就得加上\r\n
response += "Cpntent-Type: text/html" + SEP;
//空行
response += SEP;
response += body;//当作有效载荷, 也就是正文部分
return response;
}
响应一下
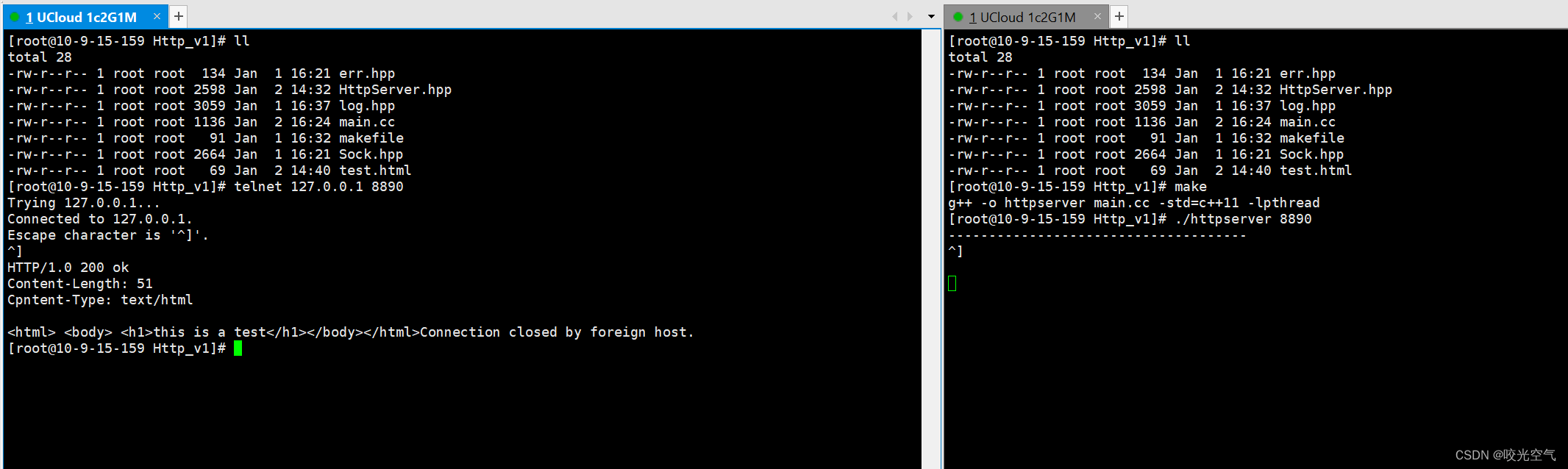
此时浏览器中上方框中输入自己云服务器的公网IP:端口号,就可以出来this is a test了,当然上面的httpserver也得在自己的云服务器上才行。
4、修改响应写法
如果写了要访问的路径是/,也就是不是具体的路径,响应的一方该如何处理?我们的body不能这样写,直接写出一个html文件的内容,对于http,需要一个专门的能够访问客户端要求的资源的地方,这里就得维护一个目录,在之前建立的Http_v1目录内再建一个目录,将要访问的资源都放在这个目录内,资源目录内再建一个index.html文件,把之前test.html的内容放到index.html中。我们再写一个头文件,里面有一个工具类,为了读完整个文件。
先看main.cc
#include "HttpServer.hpp"
#include "err.hpp"
#include "Util.hpp"
#include <memory>
const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";
std::string HandlerHttp(const std::string& request)
{
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << request << std::endl;
//资源,图片(.png, .jpg......),网页(.html, .htm),视频(.mp3)
std::string body;
Util::ReadFile(path, &body);//读出来后给到body字符串中
然后再写Util.hpp
#pragma once
#include <iostream>
#include <string>
class Util
{
public:
//一般网页文件都是文本的,但图片、视频、音频则是二进制的
static bool ReadFile(const std::string& path, std::string* fileContent)
{
//1、获取文件本身的大小
//2、调整string的空间
//3、以二进制形式读取
}
};
获取文件那里用一个函数stat,根据文件路径这个文件的stat结构体的一些属性。
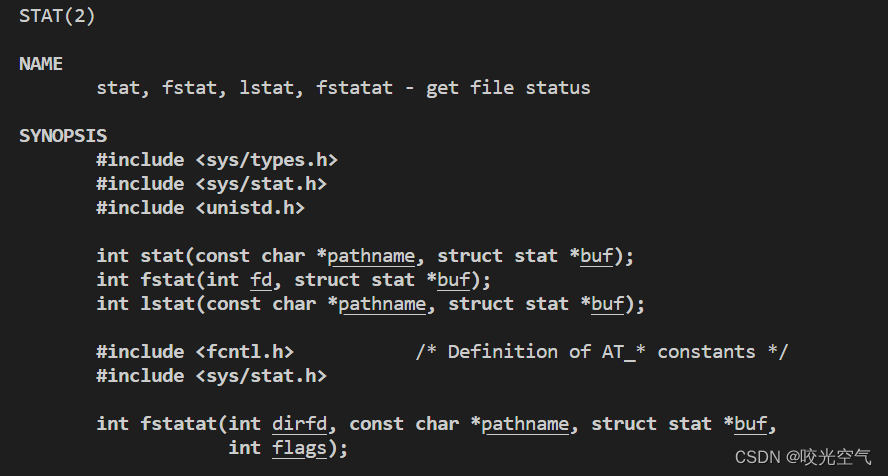
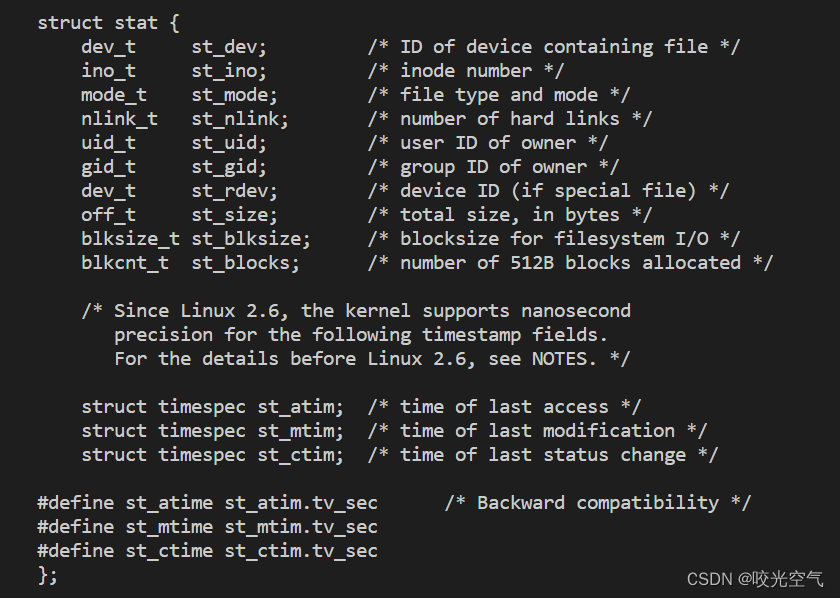
成功返回0,失败返回-1。
#pragma once
#include <iostream>
#include <string>
#include <cstdlib>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include "log.hpp"
class Util
{
public:
//一般网页文件都是文本的,但图片、视频、音频则是二进制的
static bool ReadFile(const std::string& path, std::string* fileContent)
{
//1、获取文件本身的大小
struct stat st;
int n = stat(path.c_str(), &st);
if(n < 0) return false;
int size = st.st_size;
//2、调整string的空间
fileContent->resize(size);
//3、以二进制形式读取
int fd = open(path.c_str(), O_RDONLY);//需要<fcntl.h>
if(fd < 0) return false;
//把内容读到字符串流指定的内存缓冲区的起始地址
read(fd, (char*)fileContent->c_str(), size);//当作字符串用,需要加(char*)
close(fd);
logMessage(Info, "read file %s done", path.c_str());
return true;
}
};
5、处理不同的请求
现在我们的做法是收到请求不做处理,只是打印一句this is a test。请求行中的URL是web根目录,不一定是Linux根目录。对于读到的请求要分辨出什么样的请求,然后处理请求。
在main.cc中,先对request做序列化反序列化,在对请求做出响应前做反序列化并分辨请求。
多个文件都有更改
main.cc
#include "HttpServer.hpp"
#include "err.hpp"
#include "Util.hpp"
#include <memory>
#include <vector>
const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";
class HttpRequest
{
public:
HttpRequest()
{}
void Print()
{
logMessage(Debug, "method: %s, url: %s, version: %s", method_.c_str(), url_.c_str(), httpVsersion_.c_str());
for(const auto& line : body_)
{
logMessage(Debug, "-%s", line.c_str());
}
}
~HttpRequest()
{}
public:
std::string method_;
std::string url_;
std::string httpVsersion_;
std::vector<std::string> body_;
};
HttpRequest Deserialize(std::string& message)//里面的两个函数放在Util.hpp中
{
//这里就默认这是一个完整的http请求报文
HttpRequest req;
std::string line = Util::ReadOneLine(message, SEP);
Util::ParseRequestLine(line, &req.method_, &req.url_, &req.httpVsersion_);
while(!message.empty())
{
line = Util::ReadOneLine(message, SEP);
req.body_.push_back(line);
}
return req;
}
std::string HandlerHttp(std::string& message)
{
//1、读取请求
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << message << std::endl;
//资源,图片(.png, .jpg......),网页(.html, .htm),视频(.mp3)
//2、反序列化和分析请求
HttpRequest req = Deserialize(message);
req.Print();
//3、使用请求
std::string body;
//Util::ReadFile(path, &body);//读出来后给到body字符串中
Util::ReadFile(req.url_, &body);
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头
response += "Content-Length: " + std::to_string(body.size()) + SEP;//报头的格式,是状态行,就得加上\r\n
response += "Cpntent-Type: text/html" + SEP;
//空行
response += SEP;
response += body;//当作有效载荷, 也就是正文部分
return response;
}
Util.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdlib>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <sstream>
#include "log.hpp"
class Util
{
public:
//一般网页文件都是文本的,但图片、视频、音频则是二进制的
static bool ReadFile(const std::string& path, std::string* fileContent)
{
//1、获取文件本身的大小
struct stat st;
int n = stat(path.c_str(), &st);
if(n < 0) return false;
int size = st.st_size;
//2、调整string的空间
fileContent->resize(size);
//3、以二进制形式读取
int fd = open(path.c_str(), O_RDONLY);//需要<fcntl.h>
if(fd < 0) return false;
//把内容读到字符串流指定的内存缓冲区的起始地址
read(fd, (char*)fileContent->c_str(), size);//当作字符串用,需要加(char*)
close(fd);
logMessage(Info, "read file %s done", path.c_str());
return true;
}
static std::string ReadOneLine(std::string& message, const std::string& sep)
{
auto pos = message.find(sep);
if(pos == std::string::npos) return "";
std::string s = message.substr(0, pos);
message.erase(0, pos+sep.size());
return s;
}
//形式是GET /a/b/c.ico HTTP/1.1
static bool ParseRequestLine(const std::string& line, std::string* method, std::string* url, std::string* httpVersion)
{
//stringstream对字符串有多种便利的用法
std::stringstream ss(line);
ss >> *method >> *url >> *httpVersion;
return true;
}
};
HttpServer.hpp文件中回调函数那里去掉const
using func_t = std::function<std::string(std::string&)>;
当main.cc中走到使用请求这一步时,req就是请求行的内容,它已经反序列化,都填充好各个成员了,但要访问req.url_,也就是访问路径,要从我们维护的wwwroot中访问,而不是Linux根目录。把之前的全局变量path换成这个。
//const std::string path = "./wwwroot/index.html";
const std::string webRoot = "wwwroot";//web根目录
//...
//3、使用请求
std::string body;
//Util::ReadFile(path, &body);//读出来后给到body字符串中
//Util::ReadFile(req.url_, &body);
//对于获取到的url,比如/a/b/c.html,不能让这个目录放到Linux根目录下,而是我们的wwwroot目录
std::string path = webRoot;
path += req.url_;//"wwwroot/a/b/c.html"
也可以往HttpRequest类中添加一个path_成员,构造函数里给它构造为webRoot,反序列化函数Deserialize里就写好path_,返回req,req中就有处理好的路径。
class HttpRequest
{
public:
HttpRequest():path_(webRoot)
{}
void Print()
{
logMessage(Debug, "method: %s, url: %s, version: %s", method_.c_str(), url_.c_str(), httpVsersion_.c_str());
for(const auto& line : body_)
{
logMessage(Debug, "-%s", line.c_str());
}
}
~HttpRequest()
{}
public:
std::string method_;
std::string url_;
std::string httpVsersion_;
std::vector<std::string> body_;
std::string path_;
};
HttpRequest Deserialize(std::string& message)//里面的两个函数放在Util.hpp中
{
//这里就默认这是一个完整的http请求报文
HttpRequest req;
std::string line = Util::ReadOneLine(message, SEP);
Util::ParseRequestLine(line, &req.method_, &req.url_, &req.httpVsersion_);
while(!message.empty())
{
line = Util::ReadOneLine(message, SEP);
req.body_.push_back(line);
}
req.path_ += req.url_;
return req;
}
但是如果路径就是一个/,那么添加上后,就是./wwwroot/,那这就是把这个目录所有内容都显示出来,所以这样就得限制一下。
//一般一个webserver,不做特殊说明,如果用户之间默认访问'/',不能把整站给对方
//需要添加默认首页!!而且,不能让用户访问wwwroot里面的任何一个目录本身,也可以给每一个目录都带上一个默认首页
const std::string defaultHomePage = "index.html";//我们写的就先不考虑目录内的目录,wwwroot里只有文件
//...
void Print()
{
logMessage(Debug, "method: %s, url: %s, version: %s", method_.c_str(), url_.c_str(), httpVsersion_.c_str());
for(const auto& line : body_)
{
logMessage(Debug, "-%s", line.c_str());
}
logMessage(Debug, "path: %s", path_.c_str());
}
//...
HttpRequest Deserialize(std::string& message)//里面的两个函数放在Util.hpp中
{
//这里就默认这是一个完整的http请求报文
HttpRequest req;
std::string line = Util::ReadOneLine(message, SEP);
Util::ParseRequestLine(line, &req.method_, &req.url_, &req.httpVsersion_);
while(!message.empty())
{
line = Util::ReadOneLine(message, SEP);
req.body_.push_back(line);
}
//对于获取到的url,比如/a/b/c.html,不能让这个目录放到Linux根目录下,而是我们的wwwroot目录
req.path_ += req.url_;
if(req.path_[req.path_.size() - 1] == '/') req.path_ += defaultHomePage;
return req;
}
Print函数里也添加了一个日志打印。使用请求那里就这样写
//3、使用请求
std::string body;
Util::ReadFile(req.path_, &body);//读出来后给到body字符串中
多写2个html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>测试</title>
</head>
<body>
<h1>hello file1</h1>
<h1>hello file1</h1>
<h1>hello file1</h1>
<h1>hello file1</h1>
<h1>hello file1</h1>
<h1>hello file1</h1>
<h1>hello file1</h1>
</body>
</html>
file1改成file2,总共2个html文件。做好这些工作后,我们再继续实际的处理。如果要访问图片,我们也得能加载图片。随便搜个图片
在wwwroot目录内创建一个image目录,在image目录内用wget 地址来获取图片,但有一些图片不可以获取,那就换一张。失败最下面有Bad Request,成功则是:

可以用mv命令修改图片名字

搜图片时会发现,一张网页包含很多资源,比如图片文字,每一个资源都要发起一次请求。这里只显示一点文字和图片,都放到一个html文件中,http检测到有图片就会再发一次请求。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<!--><!--上面需要加上,可以显示中文,也能正常显示我们的内容-->
<body>
<h1>this is a test</h1>
<h1>this is a test</h1>
<h1>this is a test</h1>
<h1>this is a test</h1>
<image src="/image/1.jpeg" alt="这是一张柯基图"> <!--网页中嵌入图片,显示失败就会打印alt的内容-->
</body>
</html>
回到main.cc,有效载荷的长度还是一样,获取到就可以了,不过载荷的内容因为既有文字又有图片,得改一下代码。在HttpRequest类中再加上一个表示文件后缀的成员变量,也是string类型,通过这个后缀来辨别资源。
void Print()
{
logMessage(Debug, "method: %s, url: %s, version: %s", method_.c_str(), url_.c_str(), httpVsersion_.c_str());
for(const auto& line : body_)
{
logMessage(Debug, "-%s", line.c_str());
}
logMessage(Debug, "path: %s", path_.c_str());
logMessage(Debug, "suffix_: %s", suffix_.c_str());
}
HttpRequest Deserialize(std::string& message)//里面的两个函数放在Util.hpp中
{
//这里就默认这是一个完整的http请求报文
HttpRequest req;
std::string line = Util::ReadOneLine(message, SEP);
Util::ParseRequestLine(line, &req.method_, &req.url_, &req.httpVsersion_);
while(!message.empty())
{
line = Util::ReadOneLine(message, SEP);
req.body_.push_back(line);
}
//对于获取到的url,比如/a/b/c.html,不能让这个目录放到Linux根目录下,而是我们的wwwroot目录
req.path_ += req.url_;
if(req.path_[req.path_.size() - 1] == '/') req.path_ += defaultHomePage;
auto pos = req.path_.rfind(".");//rfind是从尾开始找
if(pos == std::string::npos) req.suffix_ = ".html";
else req.suffix_ = req.path_.substr(pos);
return req;
}
std::string GetContentType(const std::string& suffix)//搜索后缀与Content-Type来找对应的写法
{
std::string constent_type = "Content-Type: ";
if(suffix == ".html" || suffix == ".htm") constent_type + "text/html";
else if(suffix == ".css") constent_type += "text/css";
else if(suffix == ".js") constent_type += "application/x-javascript";
else if(suffix == ".png") constent_type += "image/png";
else if(suffix == ".jpg") constent_type += "image/jpeg";
else if(suffix == ".jpeg") constent_type += "image/jpeg";
else {}
return constent_type + SEP;
}
std::string HandlerHttp(std::string& message)
{
//1、读取请求
//这里就已经默认request是一个完整的http请求报文
//返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << message << std::endl;
//资源,图片(.png, .jpg......),网页(.html, .htm),视频(.mp3)
//2、反序列化和分析请求
HttpRequest req = Deserialize(message);
req.Print();
//3、使用请求
std::string body;
Util::ReadFile(req.path_, &body);//读出来后给到body字符串中
//响应行
std::string response = "HTTP/1.0 200 ok" + SEP;//固定写法,这里假设200是OK的意思
//报头
response += "Content-Length: " + std::to_string(body.size()) + SEP;//报头的格式,是状态行,就得加上\r\n
response += GetContentType(req.suffix_);
//空行
response += SEP;
response += body;//当作有效载荷, 也就是正文部分
return response;
}
图片出来得慢是因为图片可能比较大,用更小的就可以了。

6、跳转
file1,file2,index三个互相跳转,用到< a href >
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>测试</title>
</head>
<body>
<h1>hello file2</h1>
<h1>hello file2</h1>
<h1>hello file2</h1>
<h1>hello file2</h1>
<h1>hello file2</h1>
<h1>hello file2</h1>
<h1>hello file2</h1>
<a href="/file1.html">file1</a>
<a href="/">返回首页</a>
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<!--上面需要加上,可以显示中文,也能正常显示我们的内容-->
<body>
<h1>test</h1>
<image src="/image/1.jpeg" alt="这是一张柯基图"><br /> <!--网页中嵌入图片,显示失败就会打印alt的内容-->
<a href="/file1.html">file1</a>
<a href="/file2.html">file2</a>
</body>
</html>
跳转本质上就是浏览器重新解释标签,再发起请求。
3、请求方法(GET/POST)
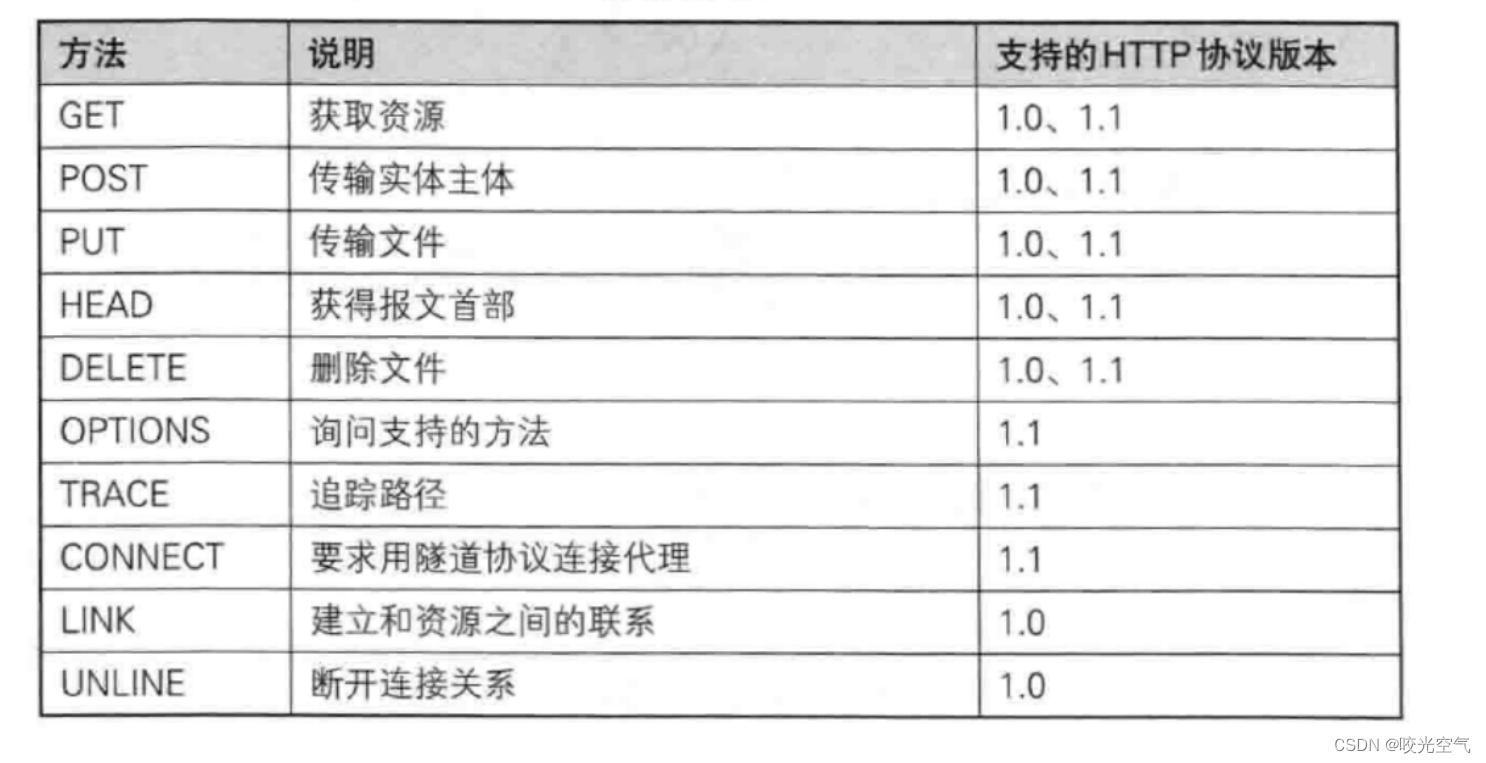
GET是最常用的,POST将个人信息提交到服务器。大多数情况都只用GET/POST,其它基本不怎么用。请求方法是浏览器客户端发起的,它会构建一个http request,携带者GET/POST。使用请求方法,整个界面也需要有交互界面,交互需要表单。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<!--上面需要加上,可以显示中文,也能正常显示我们的内容-->
<!--想让两行之间有空行,就可以一行后面加<br />,下一行单独一个<br />-->
<body>
<form action="/a/b/c.exe" , method="GET">
姓名: <input type="text" name="myname" value="name"><br />
<br />
密码: <input type="text" name="mypasswd" value="password"><br />
<br />
<input type="submit" value="提交"><br /><br />
</form>
<h1>test</h1>
<h1>test</h1>
<h1>test</h1>
<h1>test</h1>
<image src="/image/1.jpeg" alt="这是一张柯基图"><br /> <!--网页中嵌入图片,显示失败就会打印alt的内容-->
<a href="/file1.html">file1</a>
<a href="/file2.html">file2</a>
</body>
</html>
action后是要访问的资源,value是默认值,点击提交后就会下载c.exe应用程序,不过不能使用。点击提交后出现这个网址,问号后面的就是要提交给c.exe的参数。
http://106.75.12.79:3389/a/b/c.exe?myname=zyd&mypasswd=123456
GET能获取一个静态网页,也能提交参数,通过URL的方式提交。默认提交方式是GET,把method这项去掉就是默认。把密码那里的input type改成password,输入密码就变成黑点了。method可以改成POST,不过我们没有处理body,body可能没有提取完,所以就会挂掉。POST提交后的网址是:
http://106.75.12.79:3389/a/b/c.exe
POST请求提交数据的时候,是通过有效载荷,也就是正文部分提交参数的,在云服务器中,我们会看到报头后空行之下就有提交的参数。
GET不私密,因为账户密码都显示在URL上,POST比较私密一些。所有的登陆注册支付等行为,都使用POST。url一般有大小约束,正文部分理论上可以非常大。
GET/POST都不安全,POST的请求方式,软件抓取,同一局域网都可以抓取过来。
4、HTTP状态码(实现3和4开头的)
状态码表示响应请求的结果是否正确。
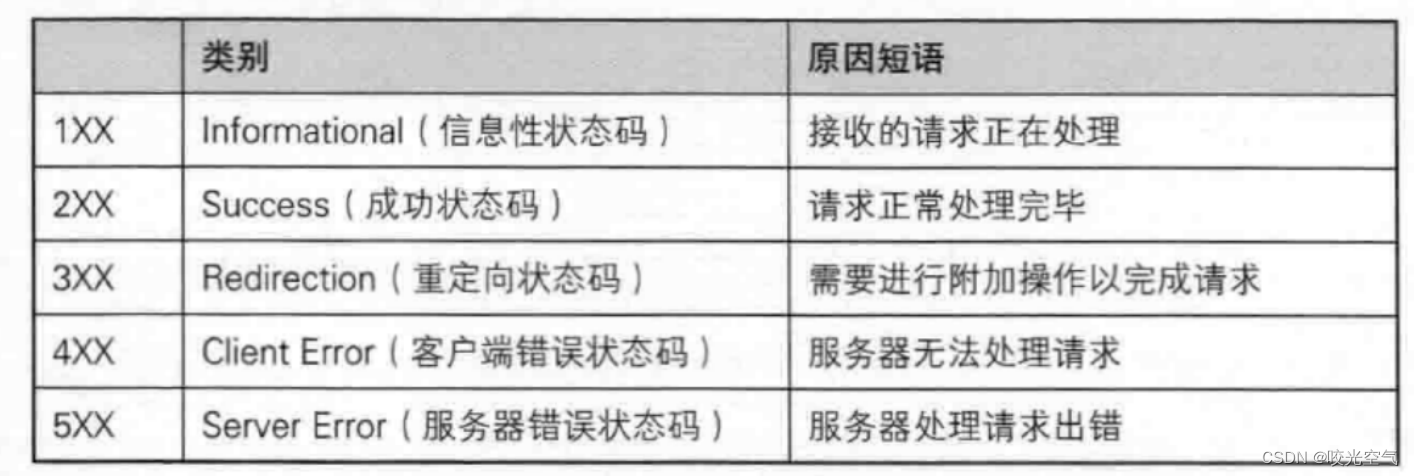
4开头的状态码是客户端的问题,客户端可以发出各种各样的请求,但并不是所有请求都得满足,所有请求服务端都必须要满足,有违规的,不合要求的请求服务端就通过状态码来通知客户端,它的请求不能实现。
我们也可以在上面的代码基础上加上一个404,找别人的cv一下:
err_404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
<style>
body {
text-align: center;
padding: 150px;
}
h1 {
font-size: 50px;
}
body {
font-size: 20px;
}
a {
color: #008080;
text-decoration: none;
}
a:hover {
color: #005F5F;
text-decoration: underline;
}
</style>
</head>
<body>
<div>
<h1>404</h1>
<p>页面未找到<br></p>
<p>
您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>
请尝试使用以下链接或者自行搜索:<br><br>
<a href="https://www.baidu.com">百度一下></a>
</p>
</div>
</body>
</html>
在main.cc中
const std::string page_404 = "./wwwroot/err_404.html";//全局
std::string HandlerHttp(std::string &message)
{
// 1、读取请求
// 这里就已经默认request是一个完整的http请求报文
// 返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << message << std::endl;
// 资源,图片(.png, .jpg......),网页(.html, .htm),视频(.mp3)
// 2、反序列化和分析请求
HttpRequest req = Deserialize(message);
req.Print();
// 3、使用请求
std::string body;
std::string response;
if (true == Util::ReadFile(req.path_, &body)) // 读出来后给到body字符串中
{
// 响应行
response = "HTTP/1.0 200 ok" + SEP; // 固定写法,这里假设200是OK的意思
// 报头
response += "Content-Length: " + std::to_string(body.size()) + SEP; // 报头的格式,是状态行,就得加上\r\n
response += GetContentType(req.suffix_);
// 空行
response += SEP;
response += body; // 当作有效载荷, 也就是正文部分
return response;
}
else
{
response = "HTTP/1.0 404 Not Found" + SEP;
Util::ReadFile(page_404, &body);
response += "Content-Length: " + std::to_string(body.size()) + SEP;
response += GetContentType(".html");
response += SEP;
response += body;
}
return response;
}
这样再请求时,可以写公网ip:端口号/路径,访问一个不存在的文件就会404。当然也可以在index.html里加上一个跳转到404的网页
<a href="/err_404.html">404文件</a>
5开头的服务器错误,服务器处理请求时错误,这个就是写服务器的时候有问题,比如进程线程时出现问题,这些很少看见,即使有也不太会出现5开头的状态码,可能会出现1开头的状态码。这样显得有些随意,是因为浏览器对于各种协议的支持并不是很好,所以即使我直接显示500 OK也行。但还是按照标准走就可以。
3开头的是重定向状态码,网上可以搜到重定向状态码的意思,301永久重定向,302、307临时重定向,307和302差不多,不过307用get来重定向。这里的重定向是指,有些服务端已经换了地址,但请求方不知道,还是向旧的服务端请求,这时候旧服务端就会告知http改了地址,http就会再次请求到新服务端。
临时和永久的区别是,临时不更改浏览器的地址信息,客户端每次都去原本的地址访问,然后再重定向到临时的地址,而永久是更改了url,更改浏览器的本地书签信息,客户端一次重定向后就一直去访问新的地址。报头location和临时重定向状态码配合使用。接下来我们实现302状态码。
HandlerHttp函数中传入message后,我们就直接重定向到qq官网,就不做其它操作了。
std::string HandlerHttp(std::string &message)
{
// 1、读取请求
// 这里就已经默认request是一个完整的http请求报文
// 返回的是一个http reponse
std::cout << "-------------------------------------" << std::endl;
std::cout << message << std::endl;
//4、重定向
std::string response = "HTTP/1.0 302 Found" + SEP;
response += "Location: https://im.qq.com/index/" + SEP;
response += SEP;
return response;
}
那么此时还是之前的步骤,运行起来后,就在浏览器输入公网ip:开放的端口号,就直接来到qq了。也可以换成301
std::string response = “HTTP/1.0 301 Moved Permanently” + SEP;
不过也没有永久重定向,改成301,用一个端口号后,Ctrl + C停止,make clean,把代码改成以前的,也还是以前的界面。
在登陆时,登录一次就会重定向到首页,每次过来都需要登录;打开某个网页也会打开别的网页,这都是临时重定向。
搜索引擎需要重定向,遇到某个资源已经换了网址,如果是永久重定向就返回新的地址,临时重定向还会每次都转一遍。
5、HTTP常见Header

6、http的会话保持功能(Cookie)
http本身是无状态的。http不会记住浏览过的网址,只会一遍遍请求。http是关于超文本传输,对于一个基于http的网站用户是否已经登录,它不去管理。但用户需要,http就有会话保持功能,但是http间接提供的。会话保持能够记录用户是否在线,并持续记录。http通过cookie和session来保持会话。
在登录时,服务器会通过http选项来向本地浏览器写入cookie信息。如果删除cookie信息就得重新登录了,登录一次又会加入cookie。
cookie原理在于,假设一个视频需要VIP,客户端请求过去就需要登录,客户端提交账户密码,服务端查找是否有这个用户,通过后就给定向到首页。
当首次认证通过后,服务器通过一些http选项,比如Set-Cookie,把用户的信息写入到http响应中,浏览器收到携带Set-Cookie的信息时,将response中相应的cookie信息在本地进行保存。保存有两种方法,内存级和文件级。之后访问同样的网站时,服务器发送给响应方的http request会包含cookie信息,不需要用户手动操作,这个是浏览器自动做的。
客户端访问每一个资源的时候,都需要认证。有了cookie,就可以不需要每次都输入。一次登录后续不需要再次登录的,基本都用了cookie技术。
恶意网站,有时候会一次性下载多个软件,软件中会有木马病毒,木马病毒就会拿用户的cookie信息,拿cookie信息去登录各个网站,比如被盗号了。如果是文件级的保存,即使关闭软件,网站也还会存在,内存级则不是。
上面所说的其实都是老方案,也不安全。在客户端和服务端之间交互时,客户端提交账户和密码,服务端不是直接存到cookie里,而是形成一个session对象,用当前用户的基本信息填充,这个session对象可以是内存或文件级的,每一个session都有唯一的id,是十或十六进制形成的序列,然后把http request Set-Cookie: session id发给客户端,客户端把session id保存到本地的cookie里,只保存session id和过期的时间,之后再登录时,http request都会携带cookie,里面有session id,服务端就去检验是否有这个id,存在就可以访问,也不需要再输入账户密码。当黑客盗取session id后,依然可以登录,但是账户密码则不会泄漏,账户密码都保存在服务端中,而服务端在国内基本是阿里腾讯华为的服务器,攻破难度不言而喻。
session id不是为了防止信息被泄漏的,即使到现在也不能解决这个问题。全球用户非常多,防范水平参差不齐,所以没办法统一做到保护信息。只能厂商自己多加防护。
服务端需要识别到底是不是用户自己登录的,识别出来还得有解决办法,比如通过检验用户位置信息,发现异地登录,可能就会强制下线,并要求输入账户和密码,因为这两个黑客拿不到,只有用户知道,或者让session id失效。当然还有很多方法,比如发送给绑定的邮箱信息,各种提醒出现在用户手机上等等。
以上就是cookie + session的解决方案。
//上面的注释掉,只用cookie,一请求就已经假如cookie,有了seesion id,内容就是1234abcd
//5、cookie && session试验
std::string response;
response += "HTTP/1.0 200 OK" + SEP;
response += "Set-Cookie: sessionid=1234abcd" + SEP;
response += SEP;
return response;
session可以看作一个类,下面偏伪代码
class Session
{
public:
Session(std::string name, std::string passwd):name_(name), passwd_(passwd)
{}
~Session()
{}
private:
std::string name_;
std::string passwd_;
uint64_t loginTime_;
int fd;
int status;
int sessionid;
};
std::unordered_map<int, Session*> sessions;
bool Login(std::string& message)
{
std::string name;
std::string passwd;
if(check(name, passwd))
{
Session* session = new Session(name, passwd);
int random = rand();
sessions.insert(std::pair<int, Session*>(random, session));
}
http response
Set-Cookie: sessionid=random;
}
std::string HandlerHttp(std::string &message)
{
//...
request->sessionid;
sessions[sessionid]->status;
}
实际上会用redis来保护所用Session。
4、结束
如果传很多图片,http就要请求多次,效率很低。http 1.0有个Connection关键字的value是keep-alive,也就是常链接,一个链接塞入多个请求。
在请求时,会打印出GET /favicon.ico HTTP/1.1,中间的favicon.ico就是在访问一个网站时,上面框中前面的小图标,比如CSDN就是一个正方形,红底白C。有这个在就会请求图标,这个可以下载一个小图标,添加上去。
http对于报头的保护并不好,用户通信时会有数据安全问题,https来解决这个问题。下一篇写https协议。
本篇gitee
结束。