一、基本信息
文档目的:标准化、规范化Hadoop在本地化环境中部署所涉及的操作和流程,以便高效、高质地落地本地化环境部署的工作。
二、安装介质
FTP服务器:
http://172.16.246.252:81/hadoopteam/cloudmanager/CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel
http://172.16.246.252:81/hadoopteam/cloudmanager/CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel.sha
http://172.16.246.252:81/hadoopteam/cloudmanager/cloudera-manager-centos7-cm5.8.2_x86_64.tar.gz
http://172.16.246.252:81/hadoopteam/cloudmanager/manifest.json
http://172.16.246.252:81/hadoopteam/cloudmanager/mysql-connector-java-5.1.49-bin.jar
http://172.16.246.252:81/hadoopteam/cloudmanager/jdk1.8.0_121.tar.gz
http://172.16.246.252:81/hadoopteam/cloudmanager/apache-kylin-2.6.4-bin-cdh57.tar.gz
http://172.16.246.252:81/hadoopteam/cloudmanager/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar
http://172.16.246.252:81/hadoopteam/cloudmanager/start-thriftserver.sh
http://172.16.246.252:81/hadoopteam/cloudmanager/stop-thriftserver.sh
http://172.16.246.252:81/hadoopteam/cloudmanager/beeline
http://172.16.246.252:81/hadoopteam/cloudmanager/load-spark-env.sh
http://172.16.246.252:81/hadoopteam/cloudmanager/hadoop-local-client.tar.gz
http://172.16.246.252:81/hadoopteam/cloudmanager/hive-local-client.tar.gz
http://172.16.246.252:81/hadoopteam/cloudmanager/spark-local-client.tar.gz
三、部署概述
先决:DBA需要提供MySQL数据库使用
部署总体步骤为:本地化集群部署CM->CM上部署大数据集群服务→CM上大数据集群HDFS开启HA→CM上大数据集群YARN开启HA→CM上部署HBase(可选)→CM上部署Kylin(可选)→CM上部署SparkSQL(可选)→开启自动重启→HDFS权限设置→客户端部署
后续:Hadoop服务需要提供给DP一些配置
先决:DBA需要提供MySQL数据库使用
- 创建scm用户(不需要创建数据库),需要有所有权限,包括建库、建账号、给账号授权的权限,密码固定,部署完可以收回
- 创建hive用户(DDL和DML权限,密码固定),创建hive库
- 创建amon用户(DDL和DML权限,密码固定),创建amon库
本地化集群部署CM
CM分为server和agent两部分
server:10.40.17.3(tx17-hadoop3)
agent:10.40.17.3、10.40.17.4、10.40.17.7、10.40.17.9、10.40.17.10
第一步:关闭防火墙
1.查看防火墙是否关闭
systemctl status firewalld.service
2.如未关闭,则:
systemctl disable firewalld.service
第二步:关闭SElinux
1.查看SElinux的状态
/usr/sbin/sestatus –v
如果SELinux status参数为enabled即为开启状态,需要进行下面的关闭操作。
2.关闭SElinux
vim /etc/selinux/config
在文档中找到SELINUX,将SELINUX的值设置为disabled,
即: SELINUX=disabled
3.在内存中关闭SElinux
setenforce 0
4.检查内存中状态
getenforce
如果日志显示结果为disabled或者permissive,说明操作已经成功。
第三步:拷贝CM所需文件到/opt/cmpackage目录下
mkdir /opt/cmpackage
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel.sha
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/cloudera-manager-centos7-cm5.8.2_x86_64.tar.gz
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/manifest.json
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/mysql-connector-java-5.1.49-bin.jar
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/jdk1.8.0_121.tar.gz
第四步:修改HOSTS
修改/etc/hosts文件,在文件中添加规划中的所有主机的IP和主机名的对应关系
vim /etc/hosts
第五步:SSH免密登录
配置server可以免密登录到agent上
1.所有主机切换到root用户执行:
ssh-keygen
2.然后按三下回车,root用户下会生成.ssh文件,里面有id_rsa.pub公钥
3.将server上的id_rsa.pub里面的公钥添加到root用户.ssh文件夹下的 authorized_keys文件中就可以了
可以采用 ssh-copy-id username@remote-server来将公钥上传到要免密登录的服务器上,如果不是默认的22端口进行登录,可以在后面加上 -p 端口号来进行上传,运行上述命令后需要输入登录账户的密码,例子如下:
ssh-copy-id root@10.40.17.4 -p 18822
完成后通过 ssh 10.40.17.4 ,检测一下。
第六步:安装JDK
tar -zxvf /opt/cmpackage/jdk1.8.0_121.tar.gz -C /usr/local/
1.配置环境变量
将解压后的jdk的目录配置到环境变量中
vim /etc/profile
2.在该文件的末尾处添加以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_121
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH
3.刷新环境变量
source /etc/profile
4.建立软链
查看是否存在此目录:
/usr/java
不存在则创建:
mkdir /usr/java
建立软连接:
ln -s /usr/local/jdk1.8.0_121 /usr/java/default
第七步:配置NTP时钟同步
将server主机作为时钟服务器,对server主机进行NTP服务器配置,其他agent服务器来同步这台服务器的时钟
server上修改:
vim /etc/ntp.conf
对该文件的内容进行以下的修改:
1、注释掉所有的restrict开头的配置
2、找到restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap,取消注释,并将其中IP和掩码修改为真实环境IP和掩码,此行配置为允许ntp客户端连接的配置
3、找到server 0.centos.pool.ntp.org iburst,并将所有server配置进行注释
4、添加下面两行内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
server启动ntp服务:
systemctl restart ntpd
agent上修改:
vim /etc/ntp.conf
对该文件进行以下内容的修改:
1、注释所有restrict和server配置
2、添加下面一行内容,需要修改以下的IP为NTP服务器的IP
server 10.40.17.3
agent上首次同步时间:
ntpdate 10.40.17.3
agent上启动ntp服务:
systemctl restart ntpd
所有主机设置(开机启动):
systemctl enable ntpd.service
第八步:安装数据库驱动
mkdir -p /usr/share/java
cp /opt/cmpackage/mysql-connector-java-5.1.49-bin.jar /usr/share/java/mysql-connector-java.jar
第九步:server上安装CDH服务
对于server的安装我们只需要以下安装介质
Cloudera Manager 安装包:cloudera-manager-centos7-cm5.8.2_x86_64.tar.gz
MySQL驱动包:mysql-connector-java-5.1.49-bin.jar
大数据离线安装库:
CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel
CDH-5.8.2-1.cdh5.8.2.p0.3-el7.parcel.sha
manifest.json
1.创建安装目录并解压安装介质
mkdir /opt/cloudera-manager
tar -zxvf /opt/cmpackage/cloudera-manager*.tar.gz -C /opt/cloudera-manager
2.创建系统用户cloudera-scm
useradd --system --home=/opt/cloudera-manager/cm-5.8.2/run/cloudera-scm-server --no-create-home --shell=/bin/false cloudera-scm
3.创建server存储目录
mkdir /var/lib/cloudera-scm-server
chown cloudera-scm:cloudera-scm /var/lib/cloudera-scm-server
4.创建hadoop离线安装包存储目录
mkdir -p /opt/cloudera/parcels
chown cloudera-scm:cloudera-scm /opt/cloudera/parcels
5.配置agent的server指向(tx17-hadoop3为server的地址)
sed -i “s/server_host=localhost/server_host=tx17-hadoop3/” /opt/cloudera-manager/cm-5.8.2/etc/cloudera-scm-agent/config.ini
6.部署CDH离线安装包
mkdir -p /opt/cloudera/parcel-repo
chown cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo
cp /opt/cmpackage/CDH-5.8.2-1.cdh5.8.2.p0.3-el7.* /opt/cloudera/parcels/
cp /opt/cmpackage/manifest.json /opt/cloudera/parcels/
cp /opt/cloudera/parcels/* /opt/cloudera/parcel-repo/
第十步:agent上安装CDH服务
在除了server服务器外的其他的服务器都要执行以下步骤进行对agent的部署。
对于agent的安装我们只需要以下的两个安装介质
Cloudera Manager 安装包:cloudera-manager-centos7-cm5.8.2_x86_64.tar.gz
MySQL驱动包:mysql-connector-java-5.1.49-bin.jar
1.创建安装目录并解压安装介质
mkdir /opt/cloudera-manager
tar -zxvf /opt/cmpackage/cloudera-manager*.tar.gz -C /opt/cloudera-manager
2.创建系统用户cloudera-scm
useradd --system --home=/opt/cloudera-manager/cm-5.8.2/run/cloudera-scm-server --no-create-home --shell=/bin/false cloudera-scm
3.创建hadoop离线安装包存储目录
mkdir -p /opt/cloudera/parcels
chown cloudera-scm:cloudera-scm /opt/cloudera/parcels
4.配置agent的server指向(tx17-hadoop3为server的地址)
sed -i “s/server_host=localhost/server_host=tx17-hadoop3/” /opt/cloudera-manager/cm-5.8.2/etc/cloudera-scm-agent/config.ini
第十一步:初始化mysql数据库
server上执行:
/opt/cloudera-manager/cm-5.8.2/share/cmf/schema/scm_prepare_database.sh mysql -h10.20.190.107 -P3308 -uroot -prootroot --scm-host 10.40.17.3 scm scm scmscm
解释说明:
-h:mysql地址
-P:mysql端口
-u:mysql账号(需要有建库并且给账号授权的权限,也就是所有权限)
-p:mysql密码
–scm-host:server地址
scm:CDH初始化数据库名
scm:CDH初始化连接数据库账号
scmscm:CDH初始化连接数据库密码
第十二步:启动服务
server:
/opt/cloudera-manager/cm-5.8.2/etc/init.d/cloudera-scm-server start
agent:
/opt/cloudera-manager/cm-5.8.2/etc/init.d/cloudera-scm-agent start
CM上部署大数据集群服务
第一步:登录网址
http://10.40.17.3:7180/
账号密码:admin admin

第二步:同意条款
勾选是的,点击继续
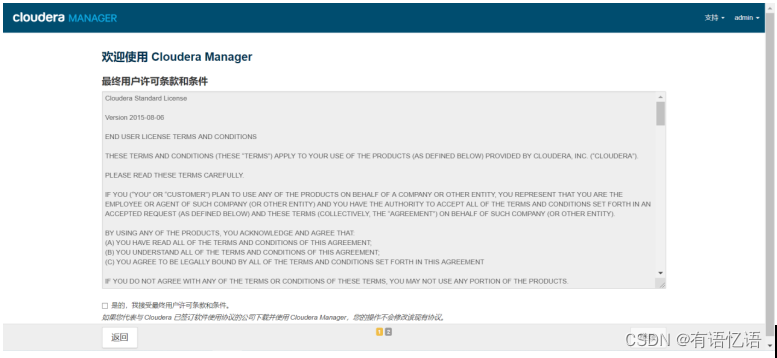
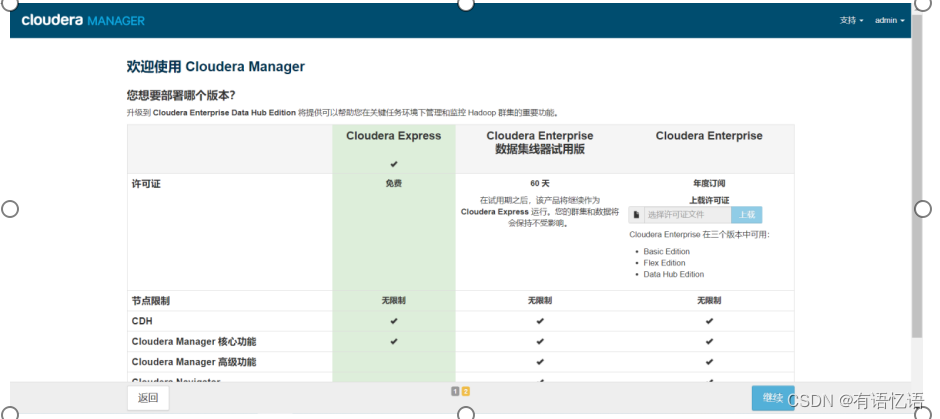
第三步:选择版本
选择免费版
第四步:感谢使用
第五步:为CDH群集安装指定主机
选择当前管理的主机,勾选所有主机
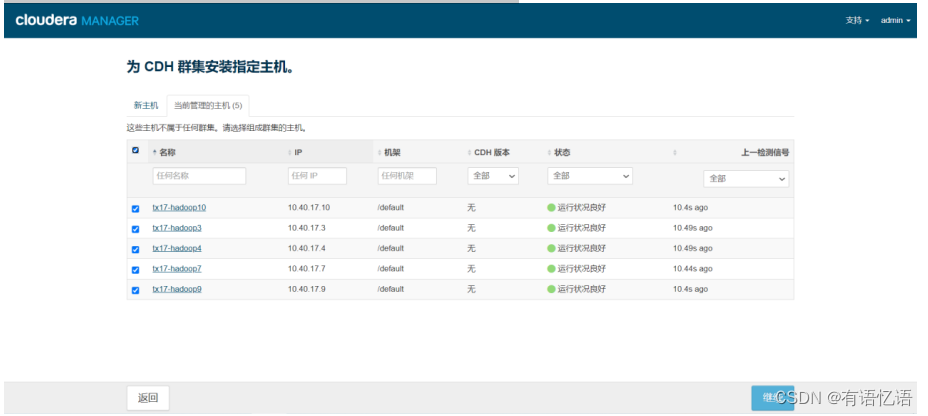
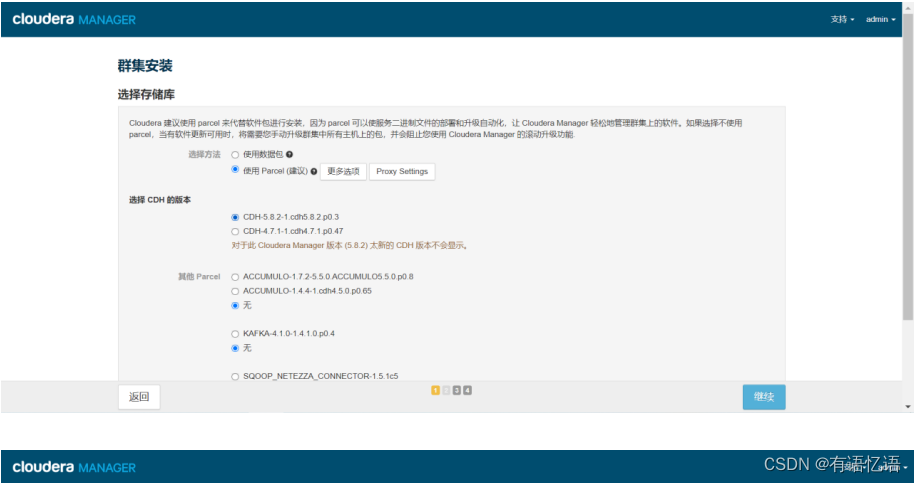
第六步:安装选定Parcel
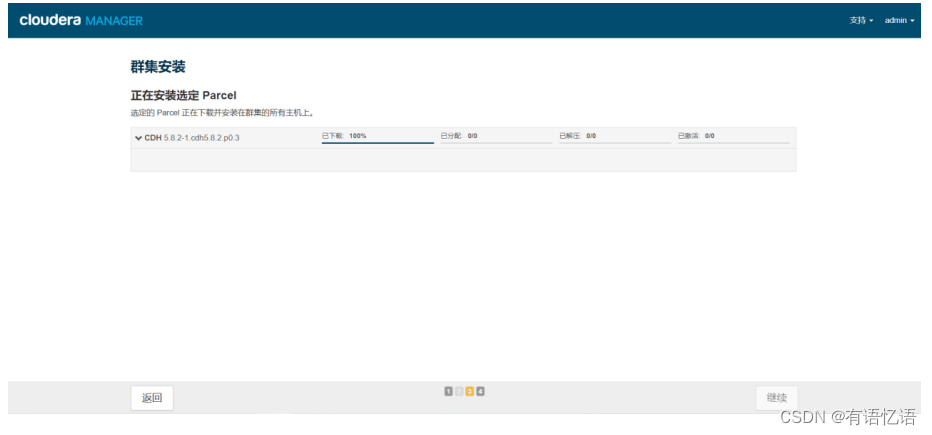
分配完成点击继续,到选择存储库界面,点击继续即可
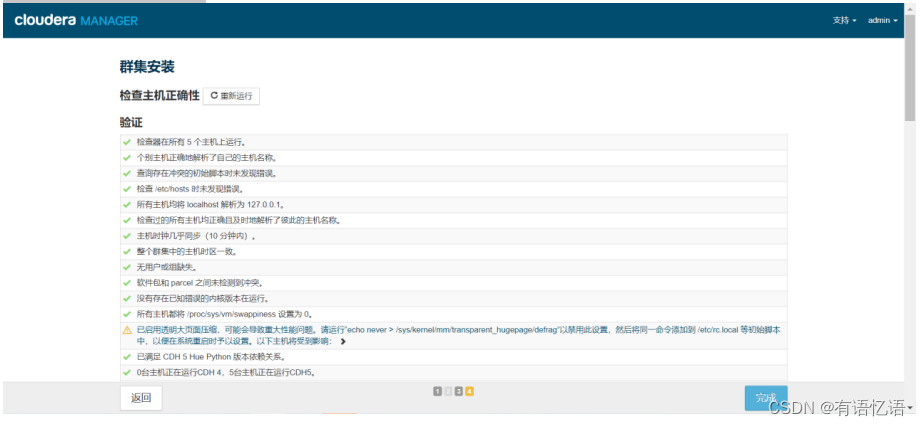
第七步:检查主机正确性
点击继续即可
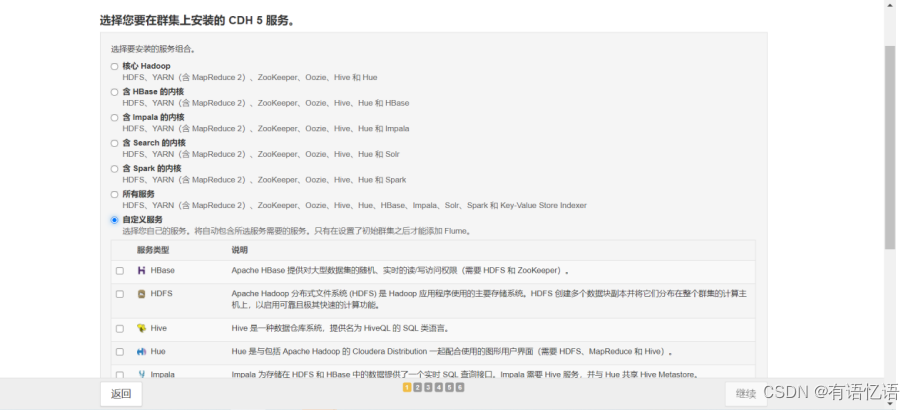
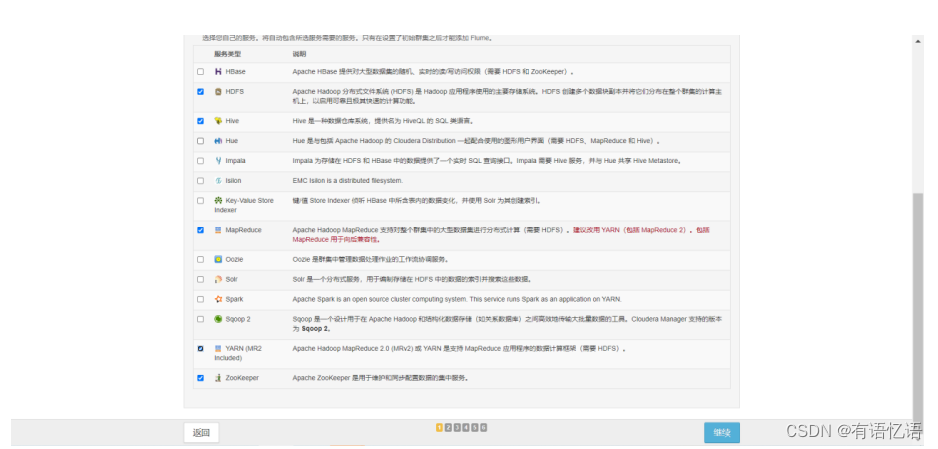
第八步:选择安装的服务
点击自定义服务,选择HDFS、Hive、YARN(MR2 Included)、ZooKeeper,点击继续
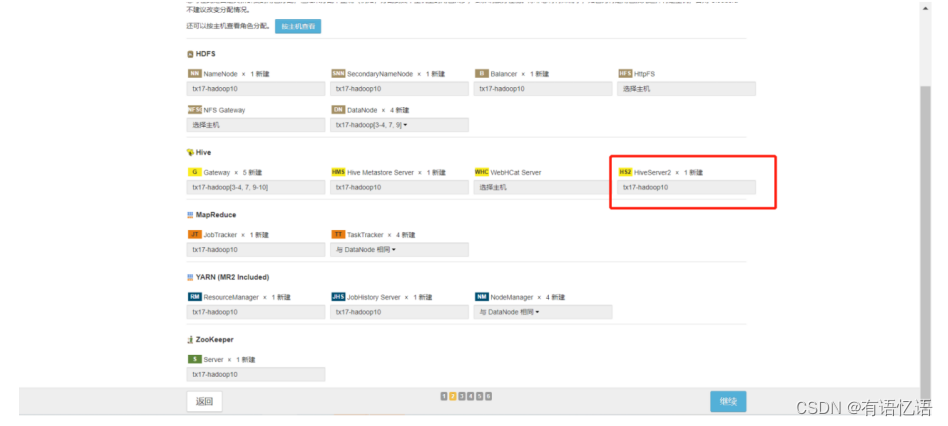
第九步:自定义角色分配
HDFS中DataNode选择所有主机,ZooKeeper中Server选择所有主机,记录下红框中HiveServer2选择的主机地址(这个地址要配置到dp中,dataplatform.biz.dal.hiveserver2.host)
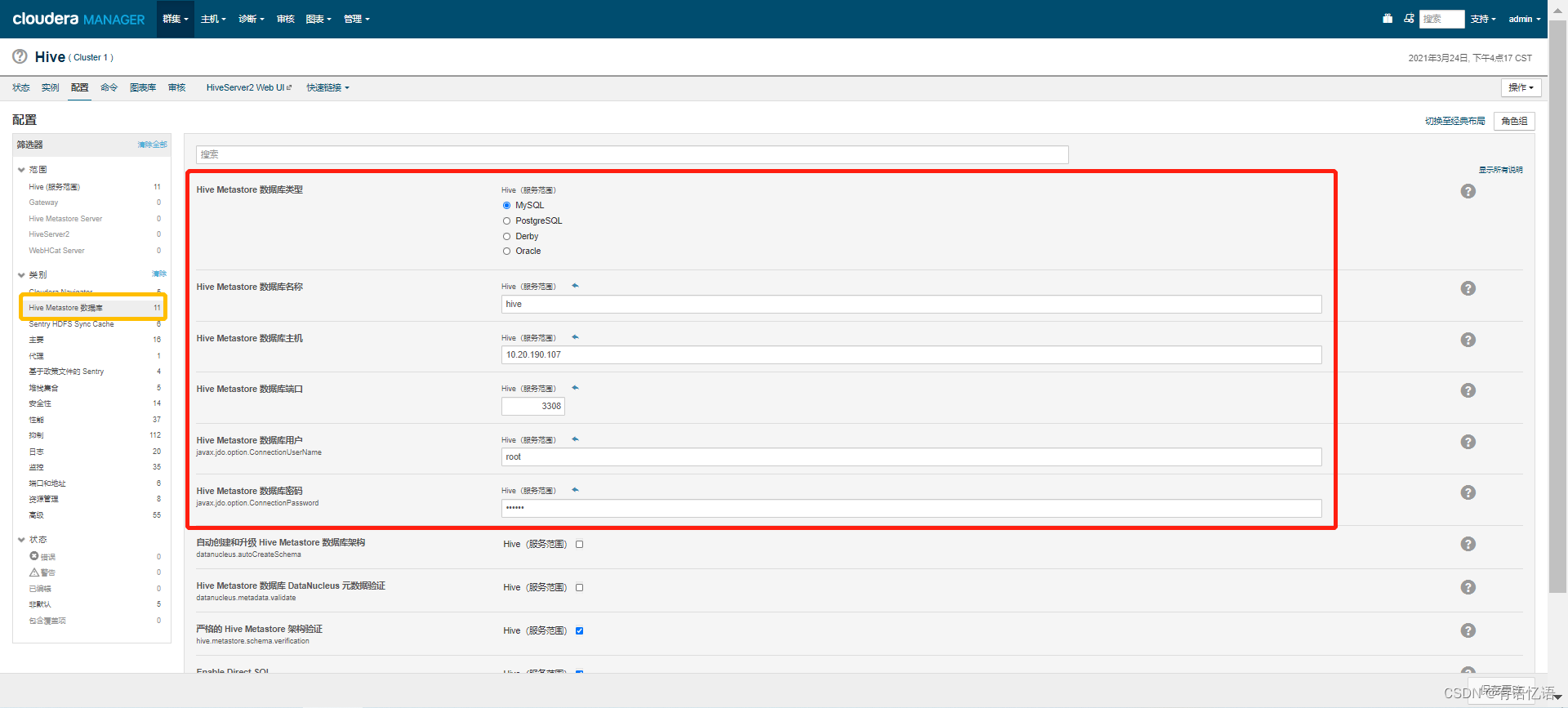
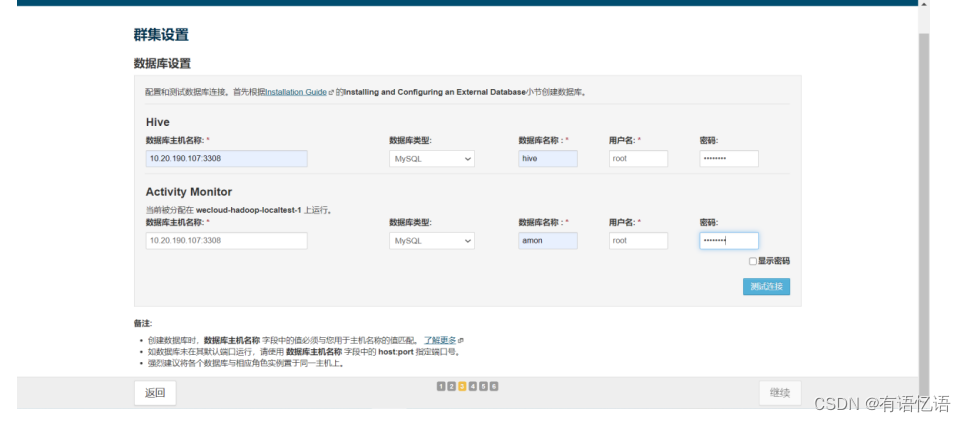
第十步:数据库设置
填写数据库配置(两个数据库hive、amon需要dba建,用户名需要有这两个库的所有权限),点击测试连接,测试通过点击继续即可,Hive的数据库地址,用户名和密码要配置到dp中(dataplatform.biz.dal.mysql.hive.url,dataplatform.biz.dal.mysql.hive.username,dataplatform.biz.dal.mysql.hive.password)
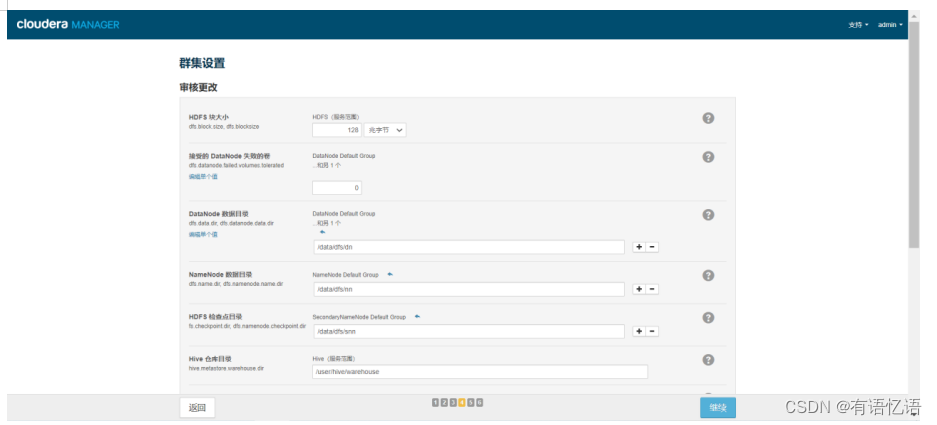
第十一步:审核更改
hive仓库目录改为/data/hive/warehouse,点击继续即可
第十二步:
运行完成点击继续即可(遇到问题看后边遇到的问题总结)
第十三步:
恭喜您!
第十四步:
每台节点上创建hive的软链
mkdir -p /usr/local/hive-current/bin/
ln -s /opt/cloudera/parcels/CDH/bin/beeline /usr/local/hive-current/bin/beeline
遇到的问题总结:
字符集的问题
修改这个sql /opt/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-1.1.0.mysql.sql中的字符集
①修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8
② 修改分区字段注解:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
③修改索引注解:
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
1.yarn jobhistory启动遇到权限不够问题
Caused by: org.apache.hadoop.security.AccessControlException: Permission denied: user=mapred, access=EXECUTE, inode=“/user”:hdfs:supergroup:drwx------
解决办法:hdfs dfs -chmod 777 /user
2.spark启动history server找不到对应的文件夹
Caused by: java.lang.IllegalArgumentException: Log directory specified does not exist: hdfs://ip:8020/user/spark/applicationHistory
解决办法:
hdfs dfs -mkdir /user/spark
hdfs dfs -mkdir /user/spark/applicationHistory
hdfs dfs -chown -R spark:spark /user/spark
3.添加服务时
由于 org.springframework.beans.factory.BeanCreationException:
Error creating bean with name ‘newServiceHandlerRegistry’ defined in class path resource
[com/cloudera/server/cmf/config/components/BeanConfiguration.class]: Instantiation of bean failed;
nested exception is org.springframework.beans.factory.BeanDefinitionStoreException:
Factory method [public com.cloudera.cmf.service.ServiceHandlerRegistry com.cloudera.server.cmf.config.components.BeanConfiguration.newServiceHandlerRegistry()] threw exception;
nested exception is java.lang.IllegalStateException: BeanFactory not initialized or already closed - call ‘refresh’ before accessing beans via the ApplicationContext 而失败
解决办法:点击重试按钮,多试几次
4.添加服务时
主机运行状况变成不良时,主机上的进程 dfs-create-dir被标记为失败
解决办法:点击重试按钮,多试几次
CM上大数据集群HDFS开启HA
HDFS开启HA
第一步:点击红框HDFS
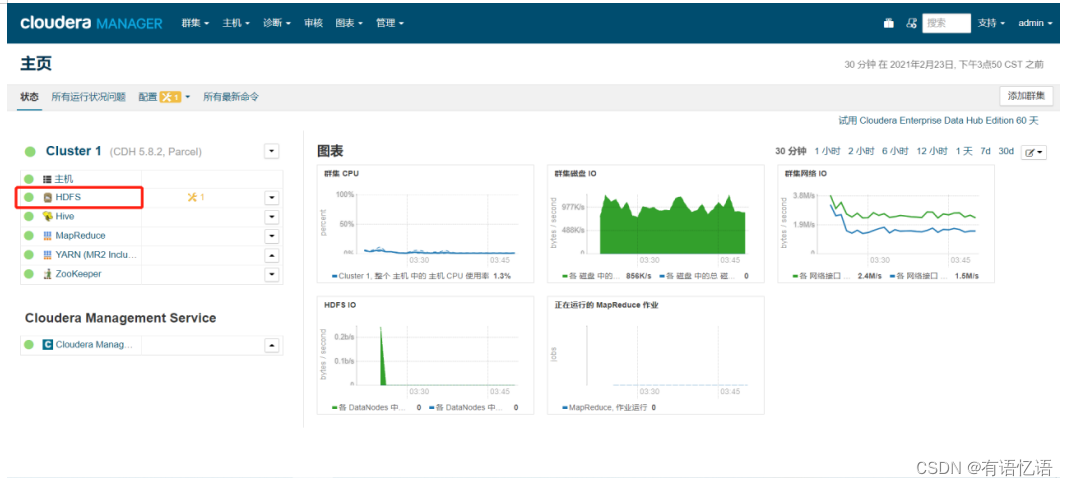
第二步:点击右侧操作按钮,点击启用High Availability
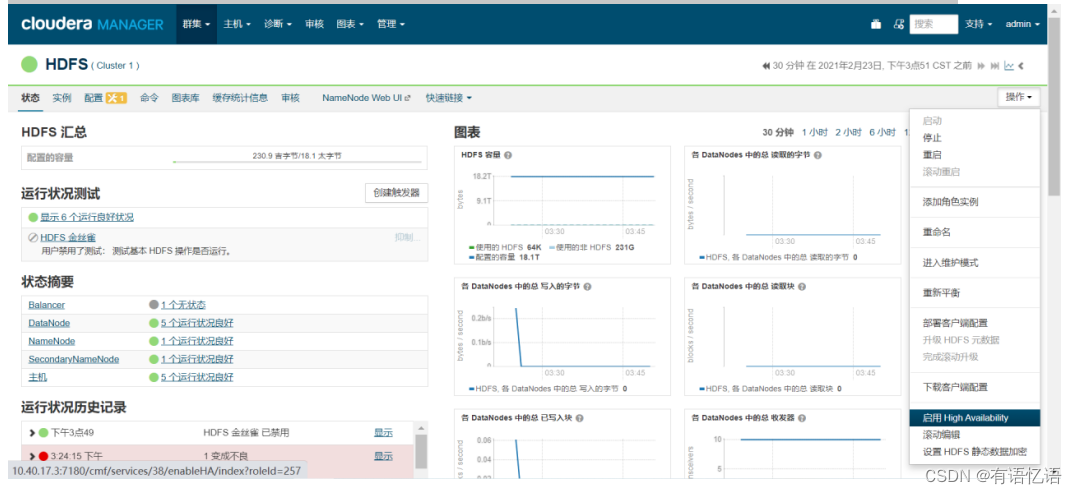
第三步:Nameservice名称改为bigdata
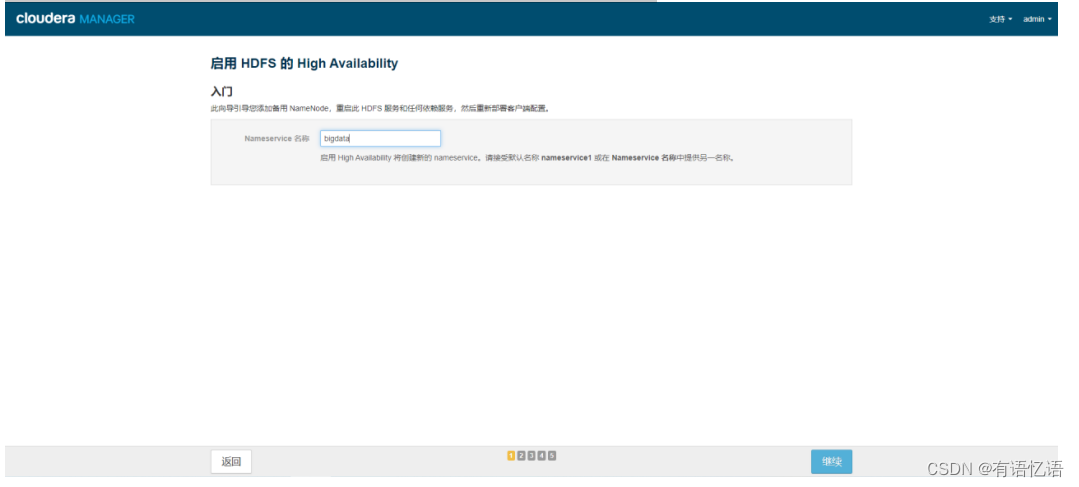
第四步:选择一台主机作为备用NameNode(一般选择和当前NameNode IP相近的主机),JournalNode主机选择三台(一般选择两个NameNode所在的主机+和NameNode IP相近的主机),两个NameNode主机地址要配置到dp中(guahao.hdfs.address1,guahao.hdfs.address2)
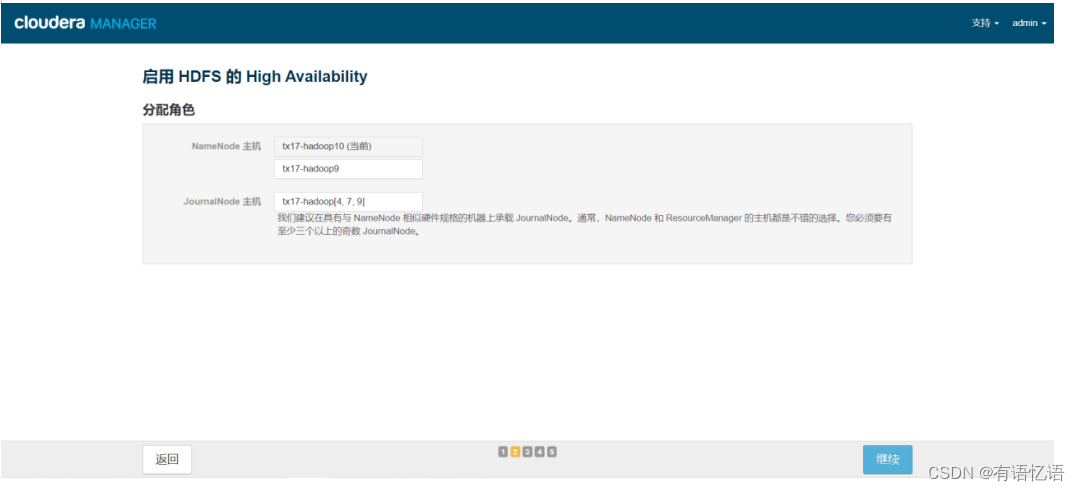
第五步:配置JournalNode编辑目录,三台都配置为/data/dfs/jn
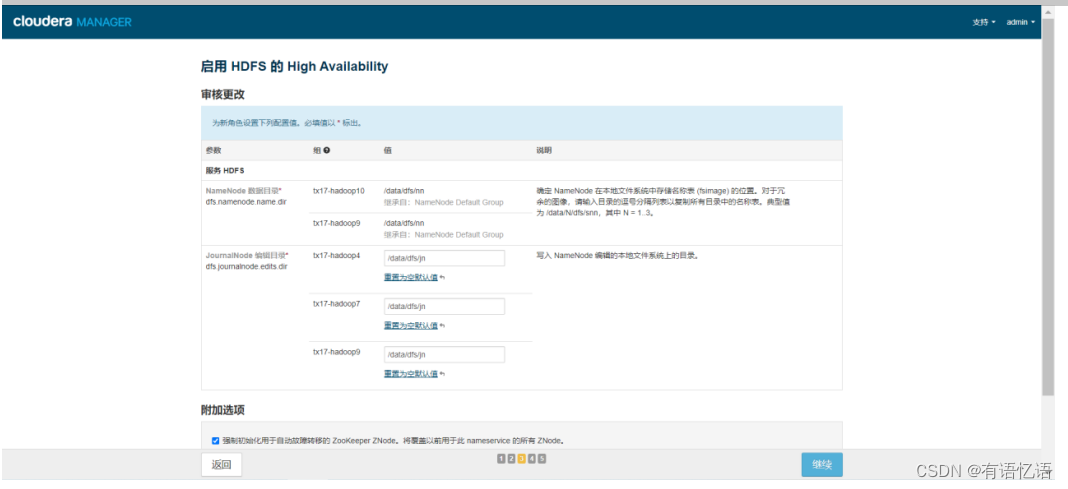
第六步:等待命令全部执行完毕
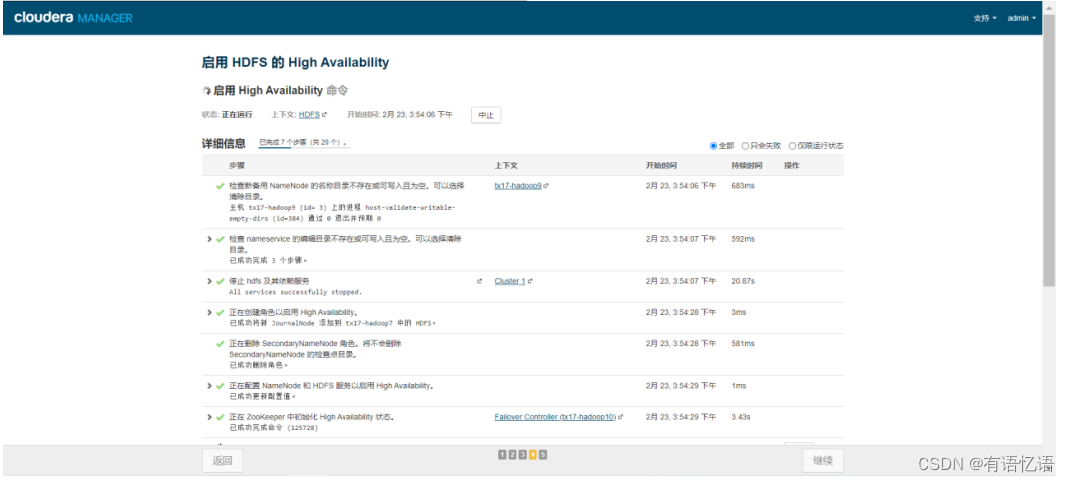
第七步:完成
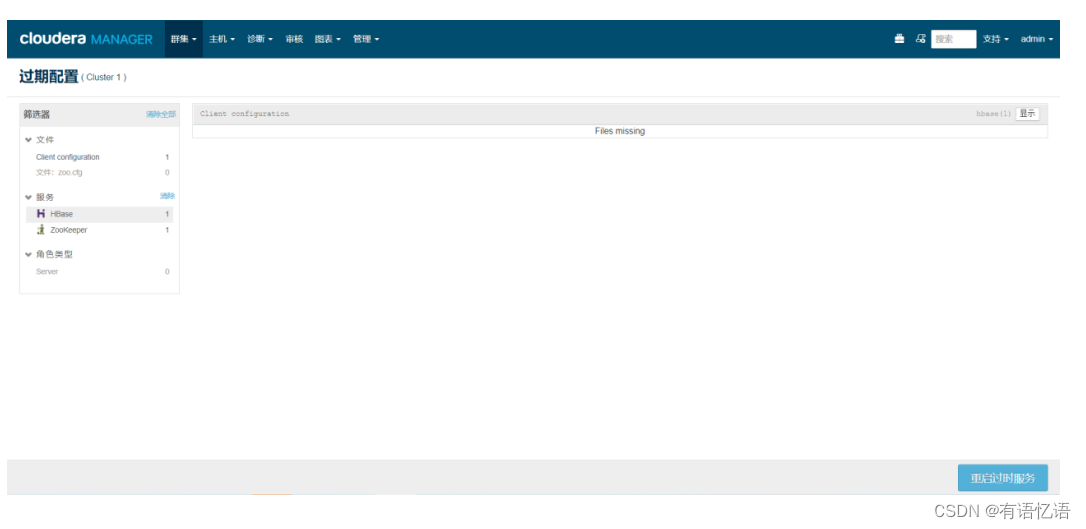
HDFS开启HA遇到问题总结:
1.第六步中可能会遇到如下图中问题:
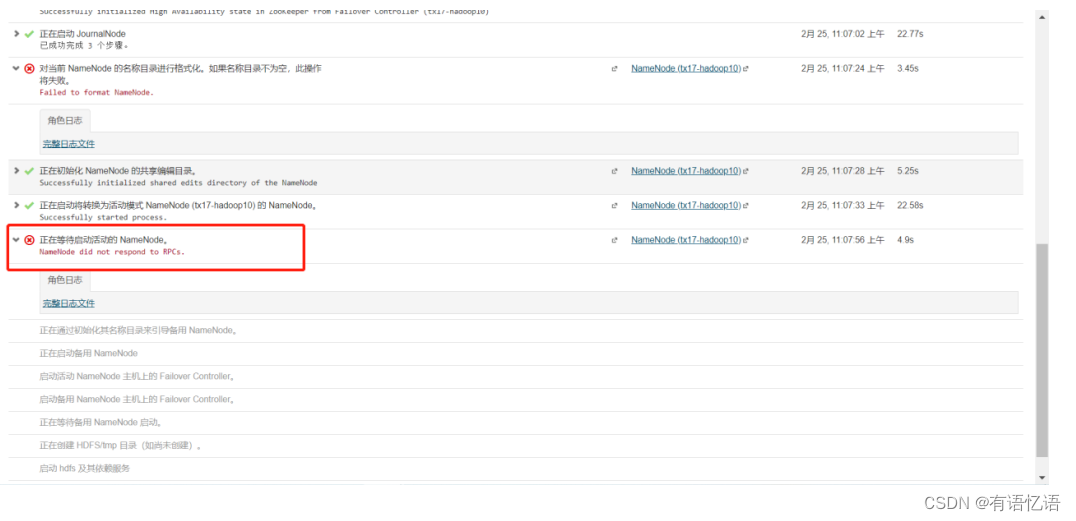
解决办法:
第一步:点击重启
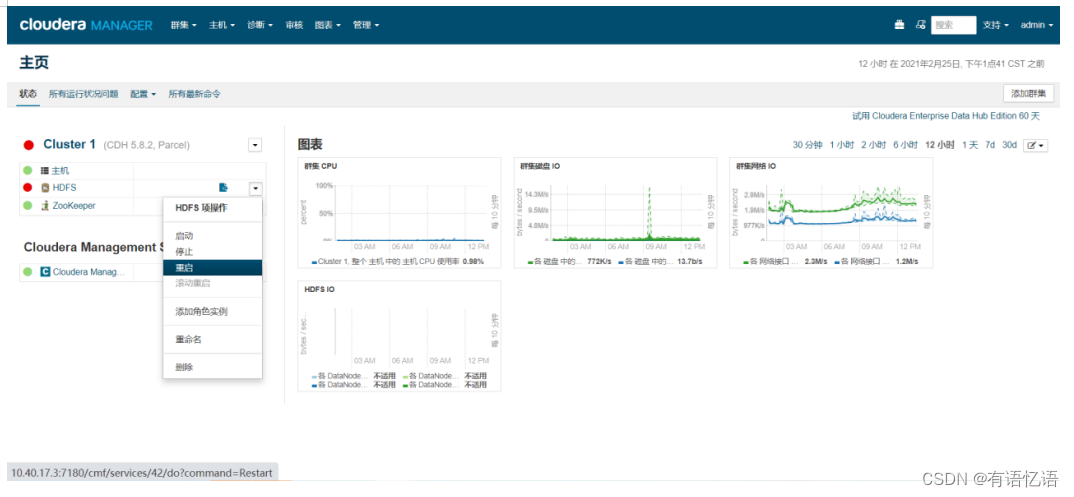
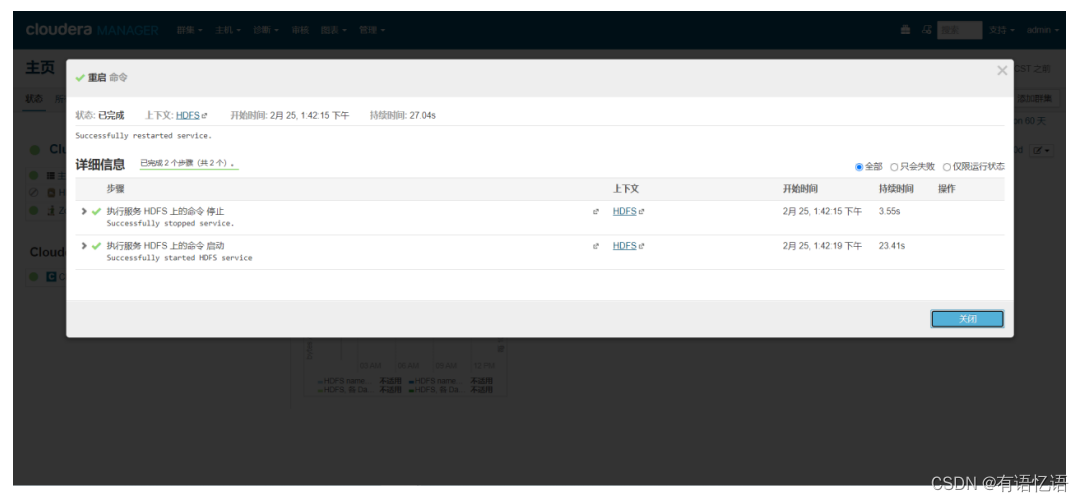
第二步:点击红框HDFS
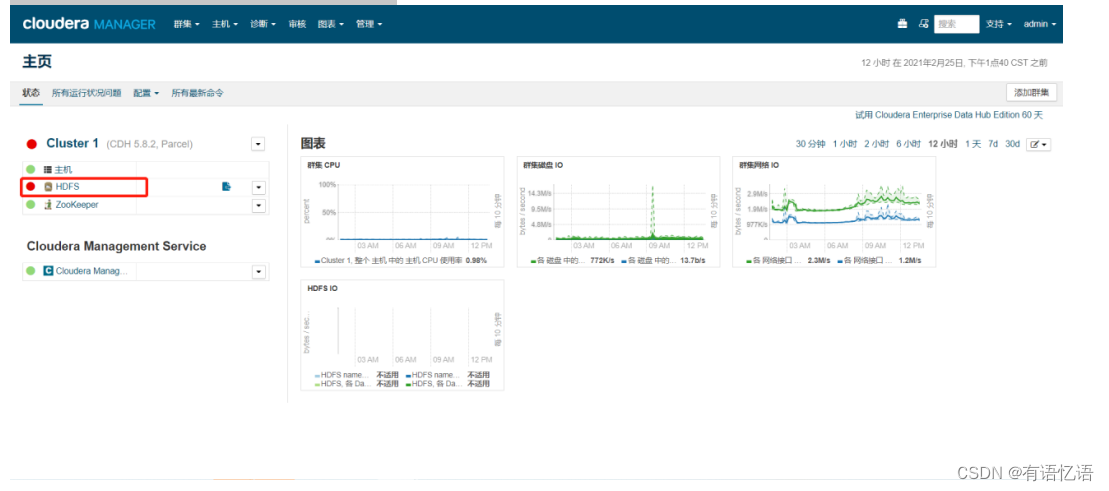
点击红框实例
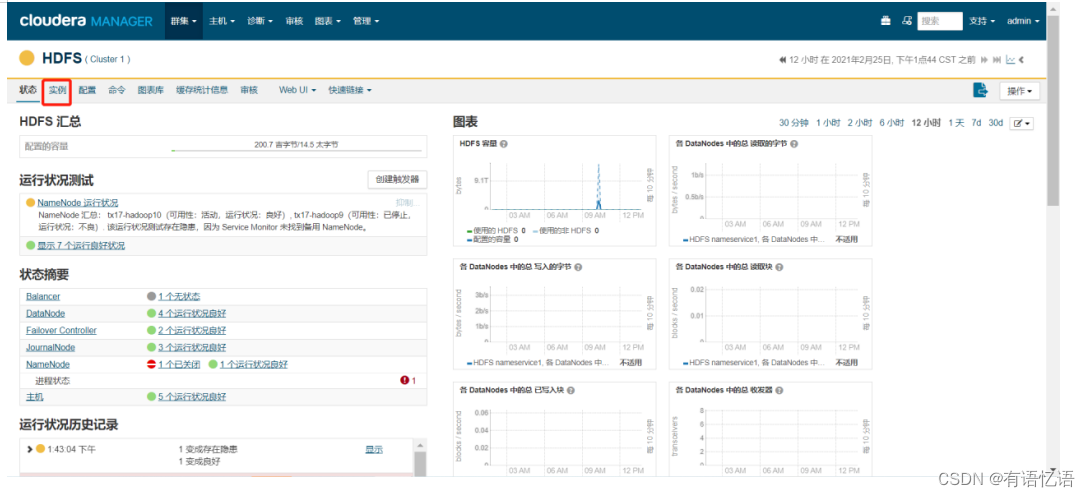
点击红框未运行的NameNode

右侧操作下拉框选择引导备用NameNode
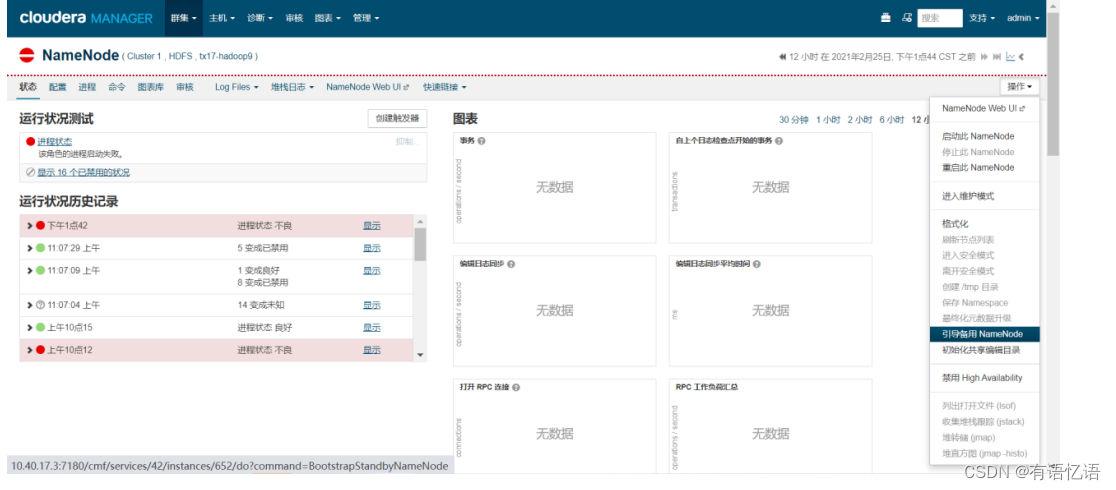
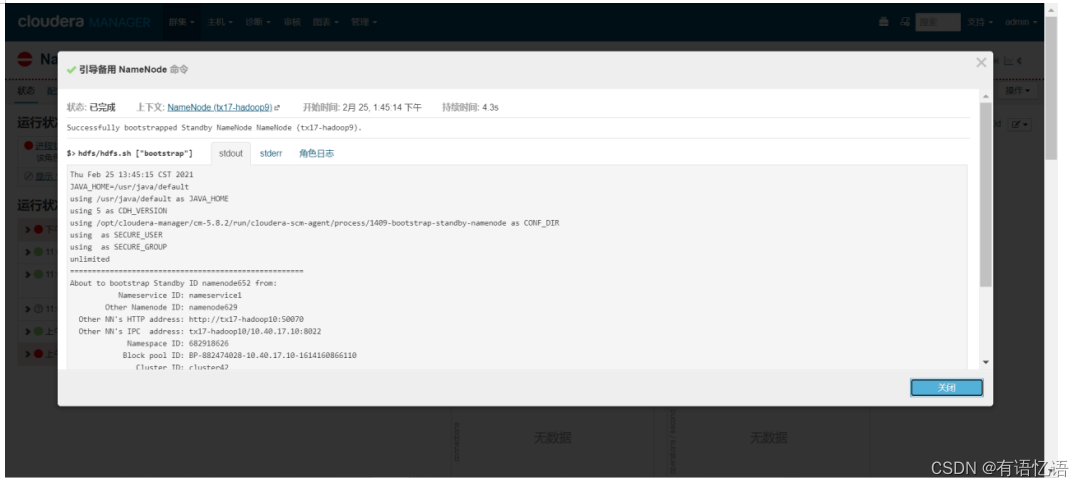
右侧操作下拉框点击重启此NameNode


第三步:点击红框按钮
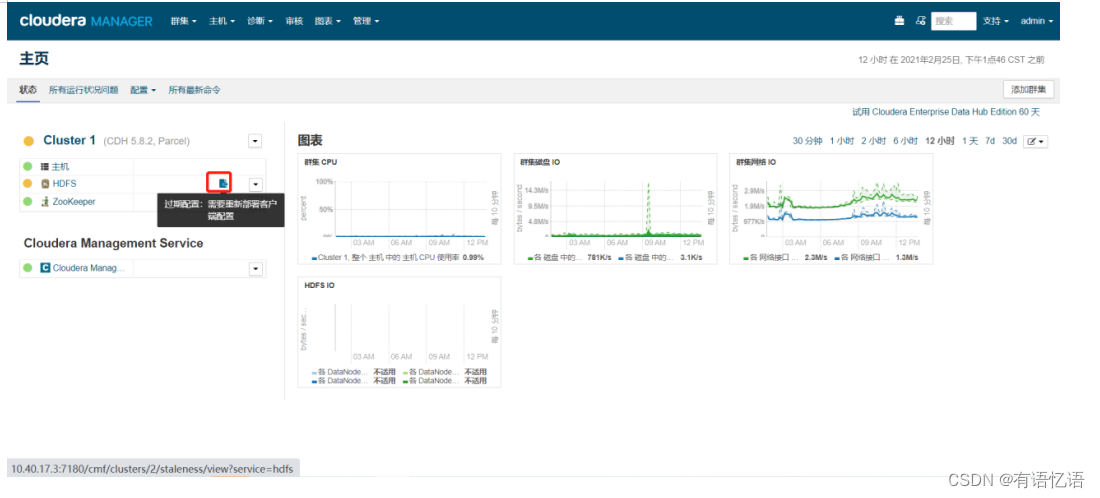
点击右下角部署客户端配置
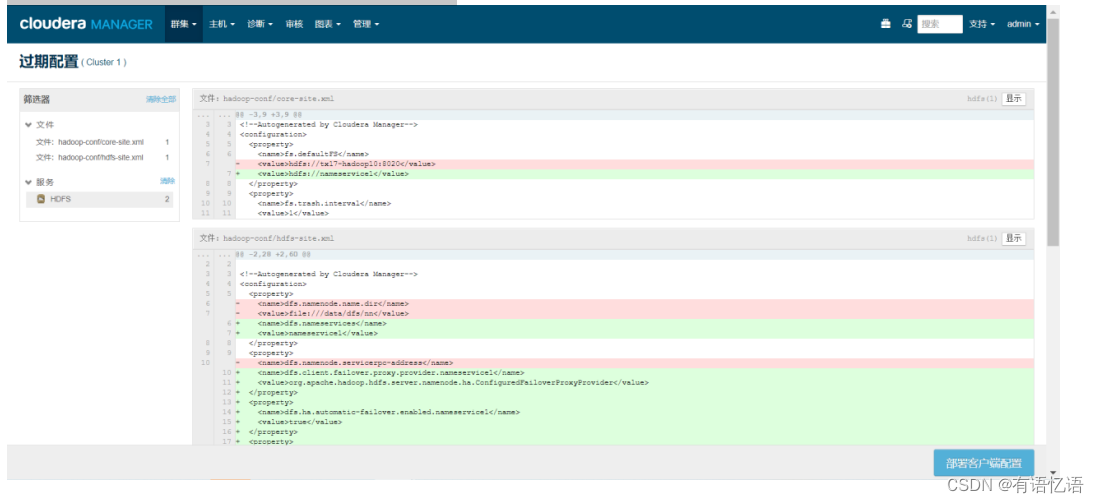
等待部署完成

CM上大数据集群YARN开启HA
第一步:点击红框YARN
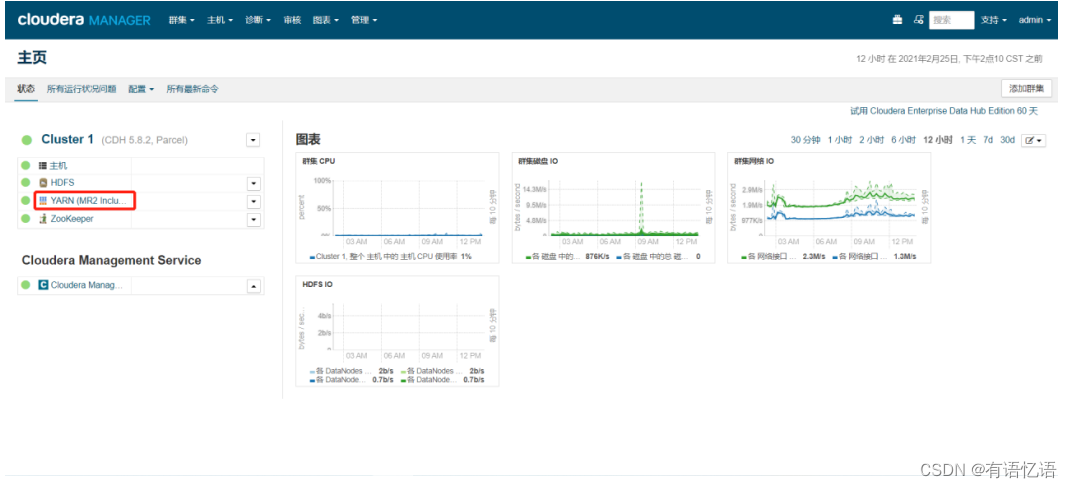
第二步:点击右侧操作下拉框启用High Availability

第三步:选择备用ResourceManager主机(一般和备用NameNode主机一致)
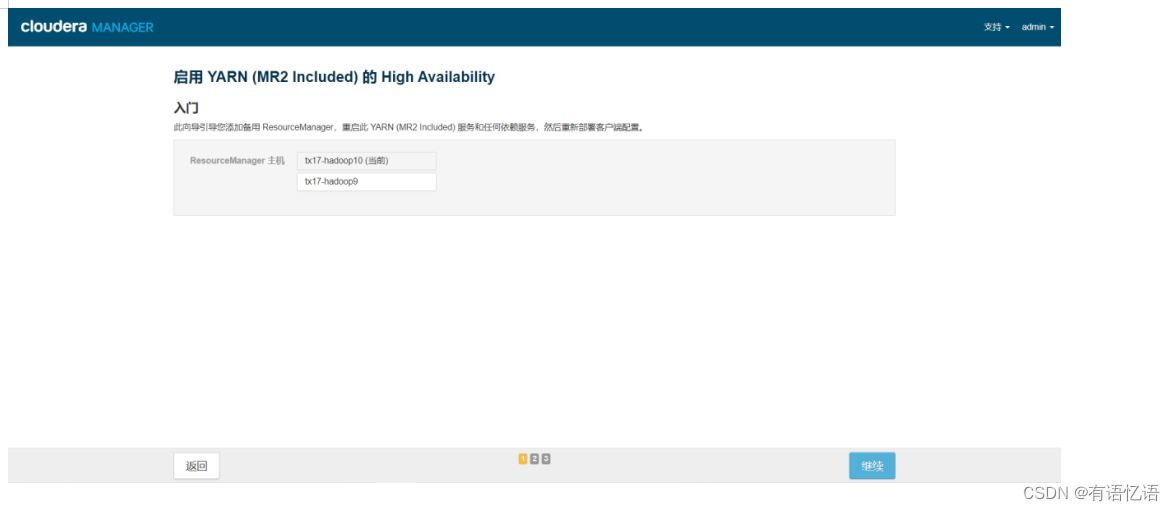
第四步:等待命令完成
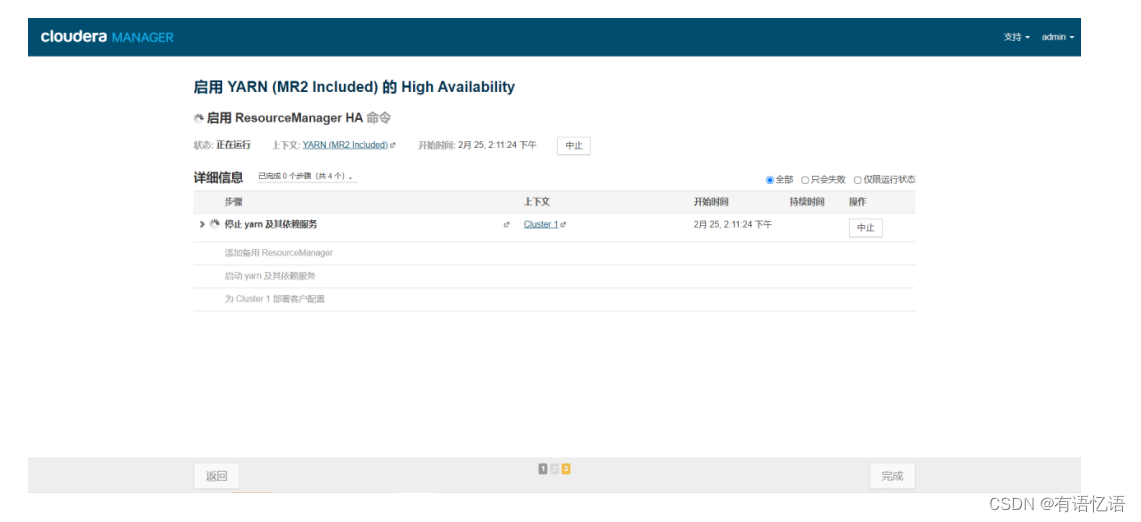
CM上部署HBase(可选)
第一步:添加服务
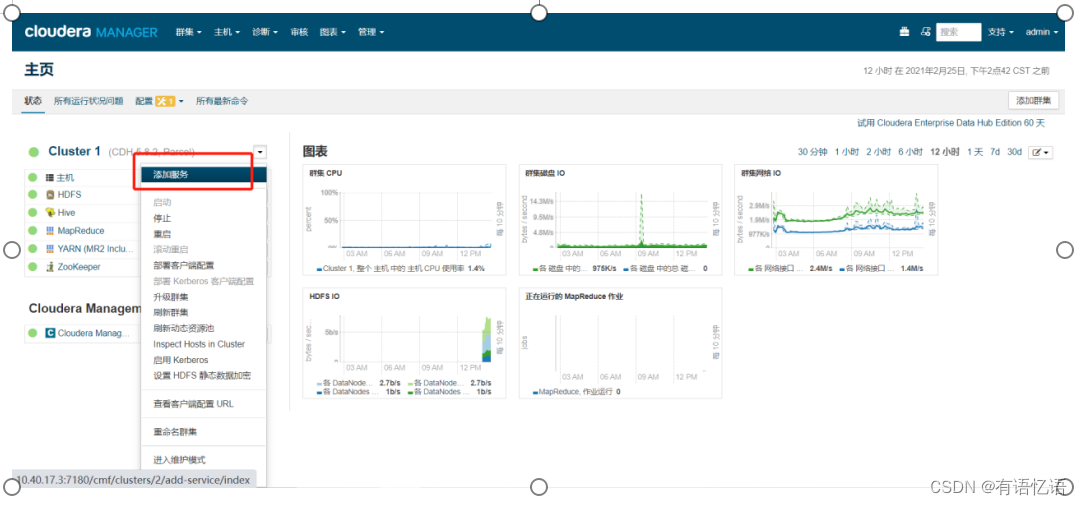
第二步:选择HBase服务
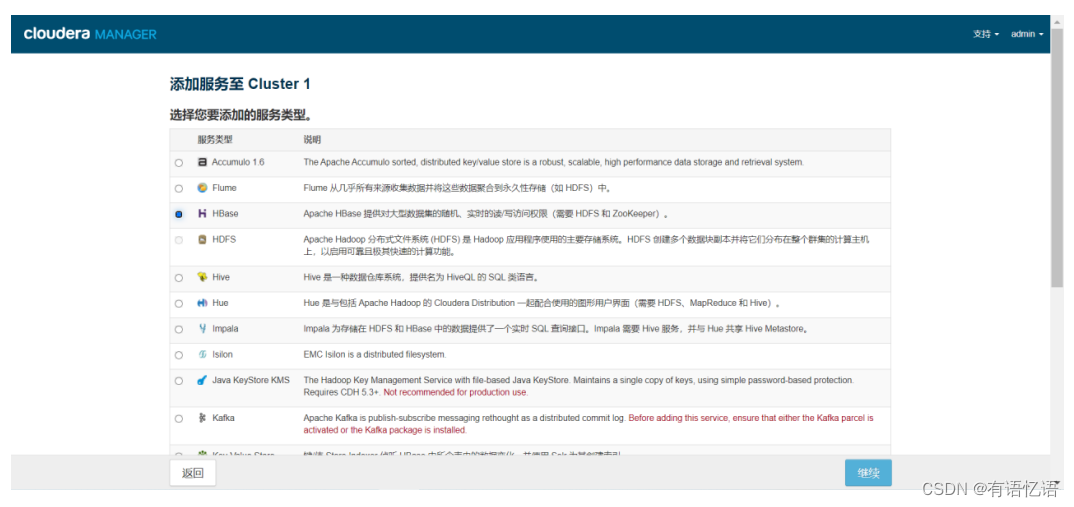
第三步:点击红框Master,选择两台Master(一般和主备NameNode一致)
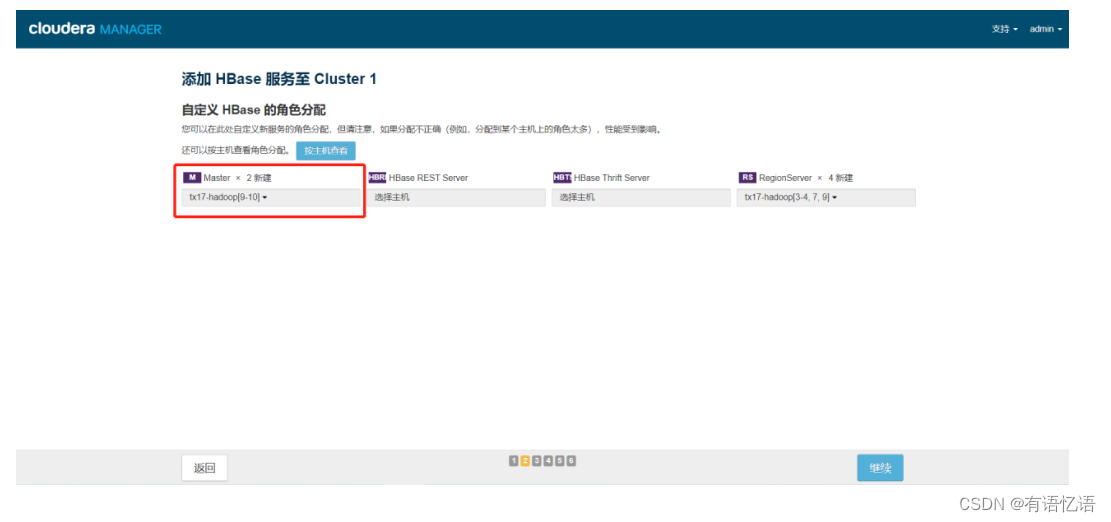
第四步:点击继续
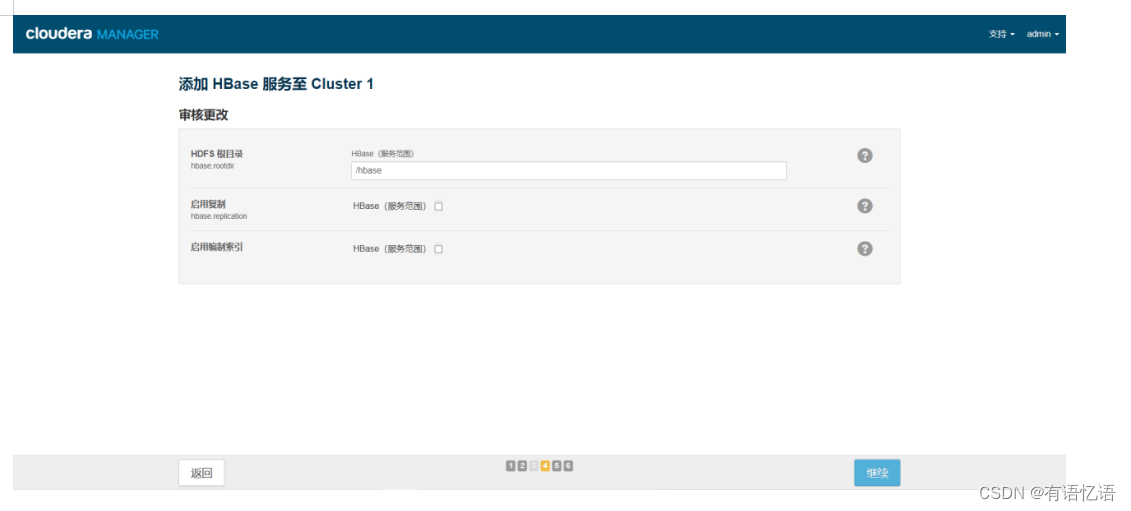
等待命令执行完成,点击继续
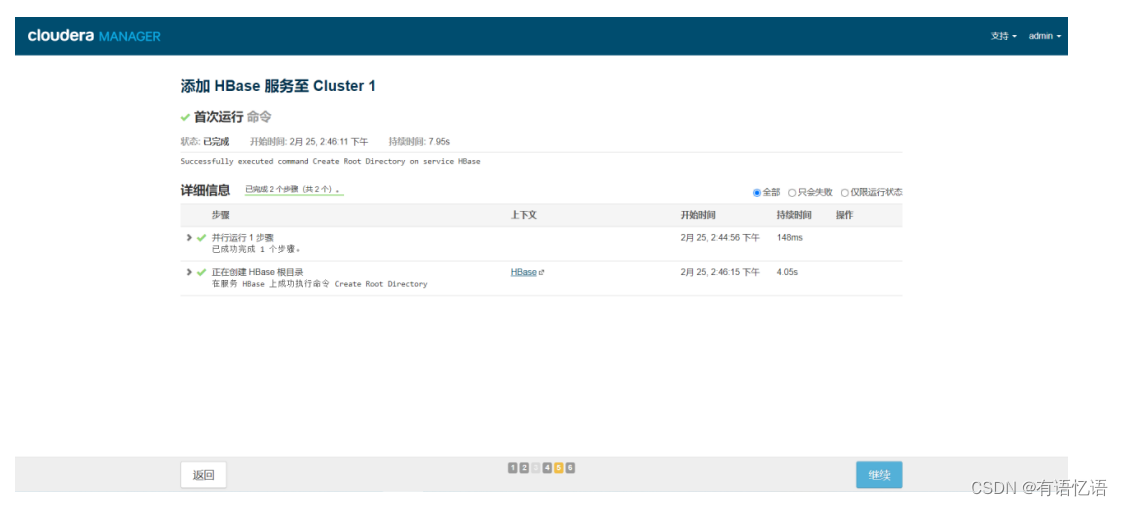
第五步:添加服务完成!

第六步:修改配置
点击红框HBase
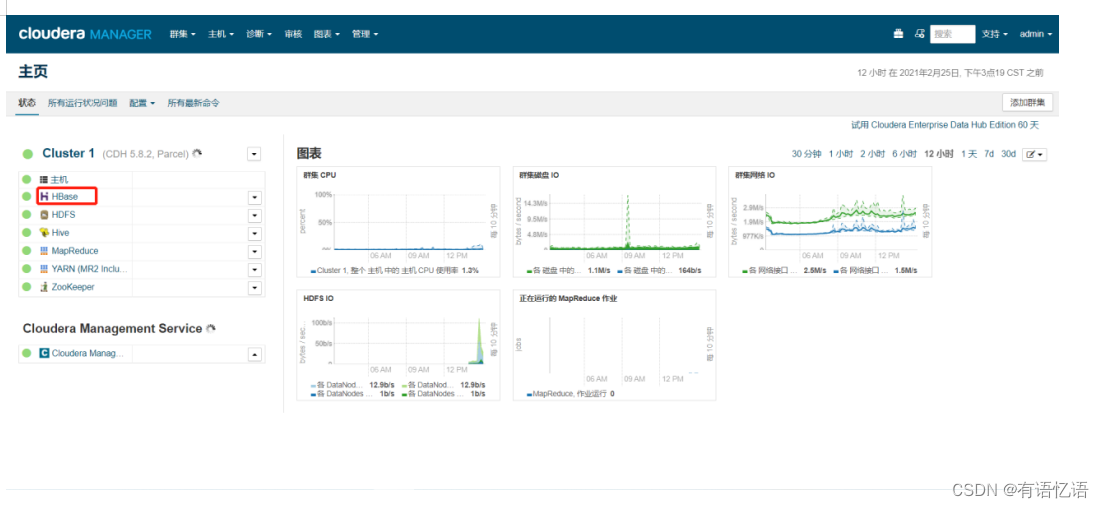
按顺序依次点击,将红框3配置改为1吉字节(注意不是兆字节),红框4配置改为4吉字节(注意不是兆字节)
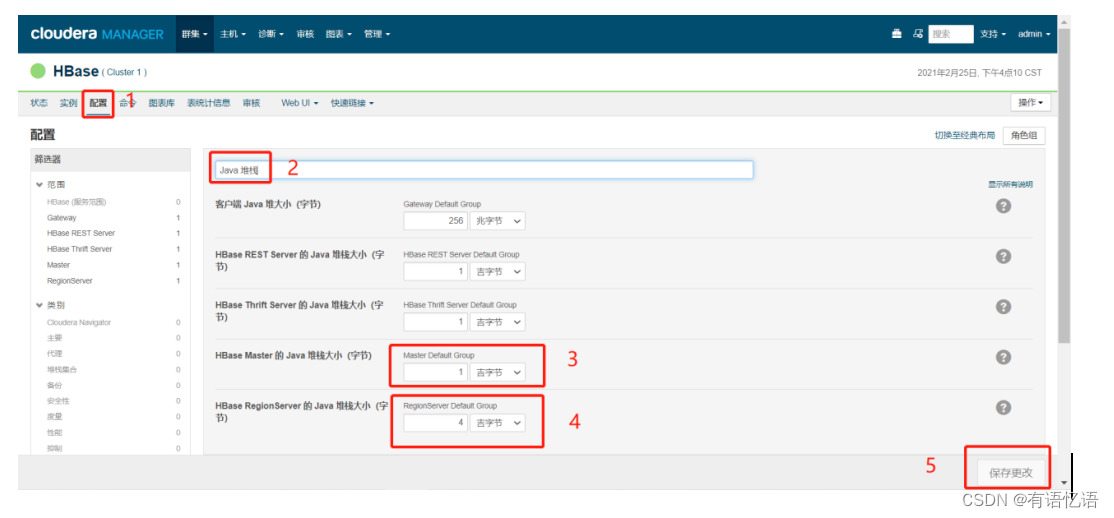
第七步:选择HBase,点击重启
等待命令完成
第八步:部署客户端配置,重启服务(如若没有红框中的标志,则可以不执行此步)
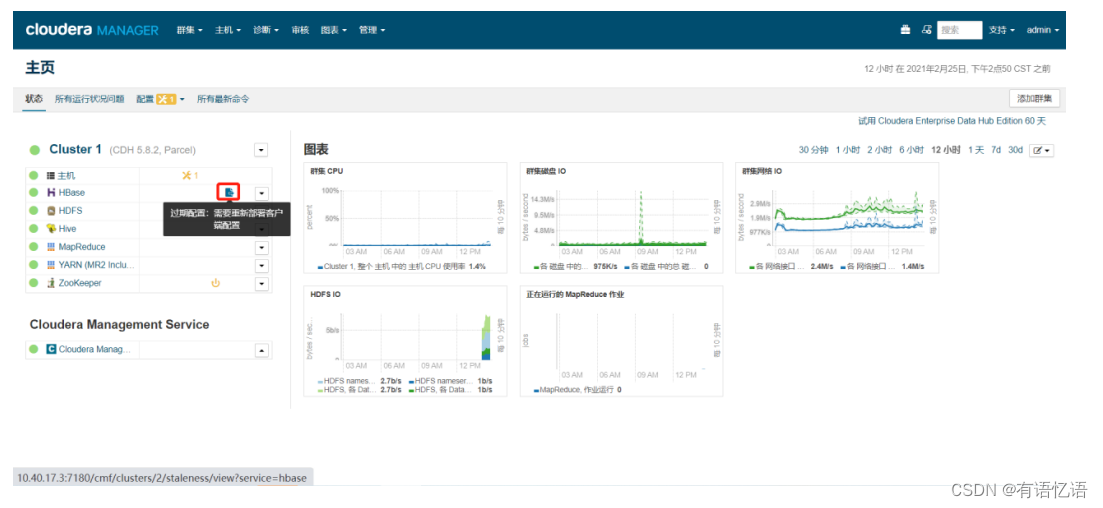
点击右下角重启过时服务
CM上部署Kylin(可选)
选择一台有部署CM agent服务的服务器安装kylin即可
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/apache-kylin-2.6.4-bin-cdh57.tar.gz
第一步:添加用户kylin
useradd kylin
第二步:hdfs上建立kylin相关目录并授权
切换到hdfs用户,然后执行命令
su - hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -mkdir /user/kylin
hdfs dfs -chown kylin /kylin
hdfs dfs -chown kylin /user/kylin
第三步:解压文件,建立软连接
tar -zxvf /opt/cmpackage/apache-kylin-2.6.4-bin-cdh57.tar.gz -C /usr/local/
chown -R kylin:kylin /usr/local/apache-kylin-2.6.4-bin
ln -s /usr/local/apache-kylin-2.6.4-bin /usr/local/kylin-current
第四步:配置变量
vim /etc/profile
最后面添加:
export KYLIN_HOME=/usr/local/kylin-current
然后:
source /etc/profile
第五步:修改启动脚本
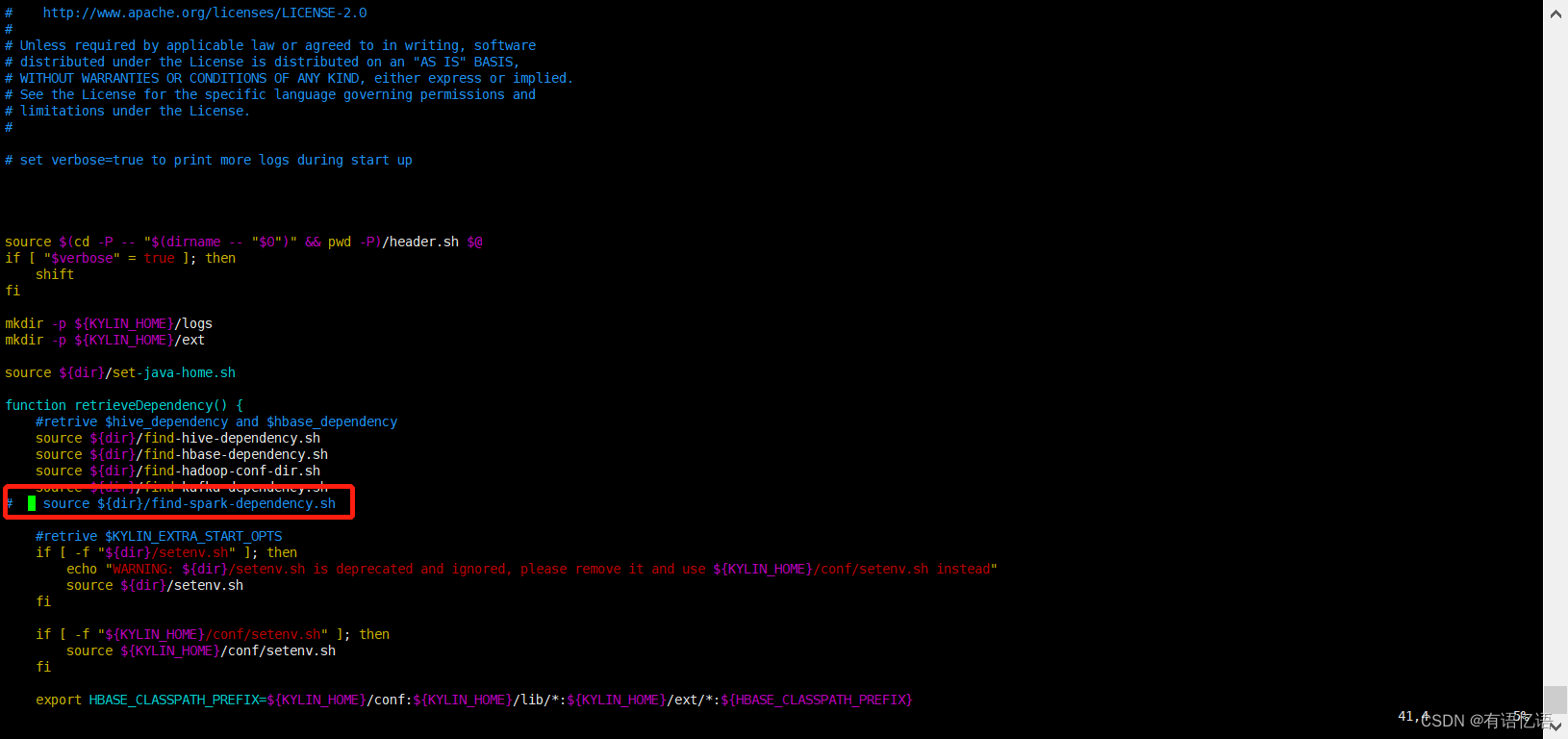
vim /usr/local/kylin-current/bin/kylin.sh
把41行 source ${dir}/find-spark-dependency.sh 注释掉(红框内容),然后保存
第六步:启动Kylin
切换到kylin用户
su - kylin
/usr/local/kylin-current/bin/kylin.sh start
第七步:Web界面登录
kylin地址(部署在哪台服务器上,ip地址换为部署服务器的ip即可)
http://10.40.17.69:7070/kylin/
账号\密码
ADMIN\KYLIN
CM上部署SparkSQL(可选)
第一步:CM上添加Spark服务
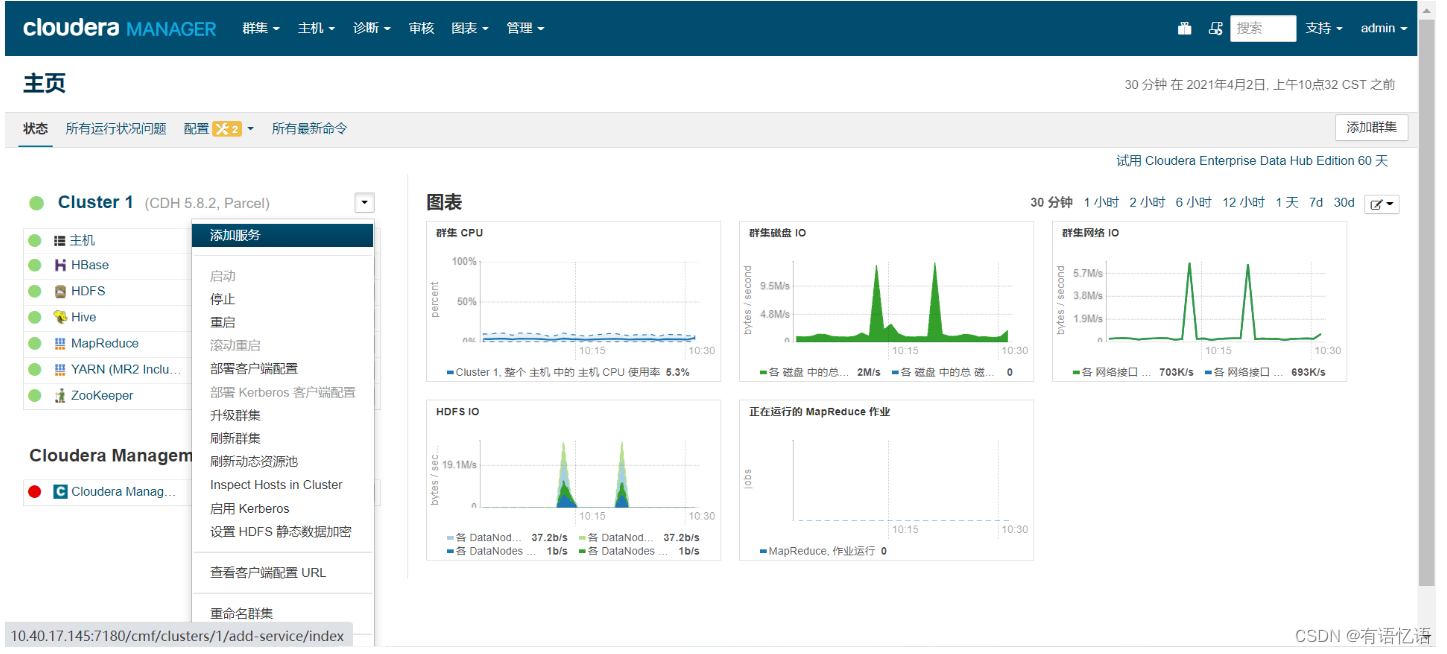
选择红框中Spark
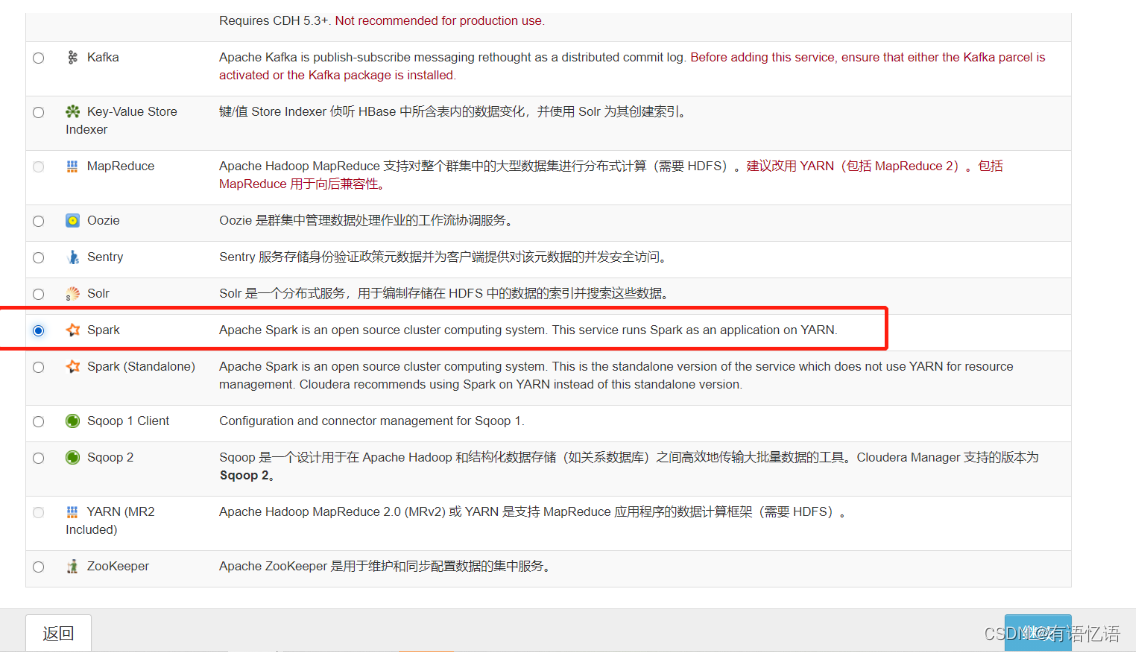
点击继续

命令执行完毕点击继续
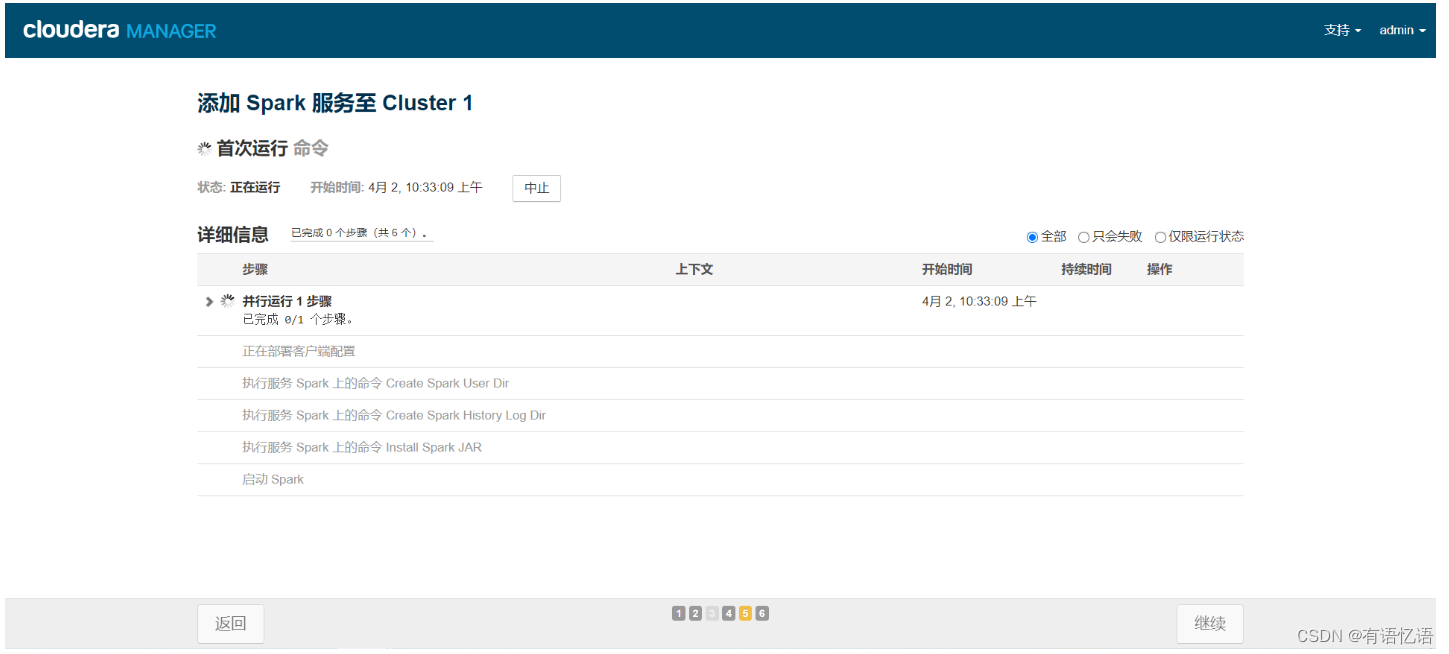
点击完成

勾选红框,点击立即重启
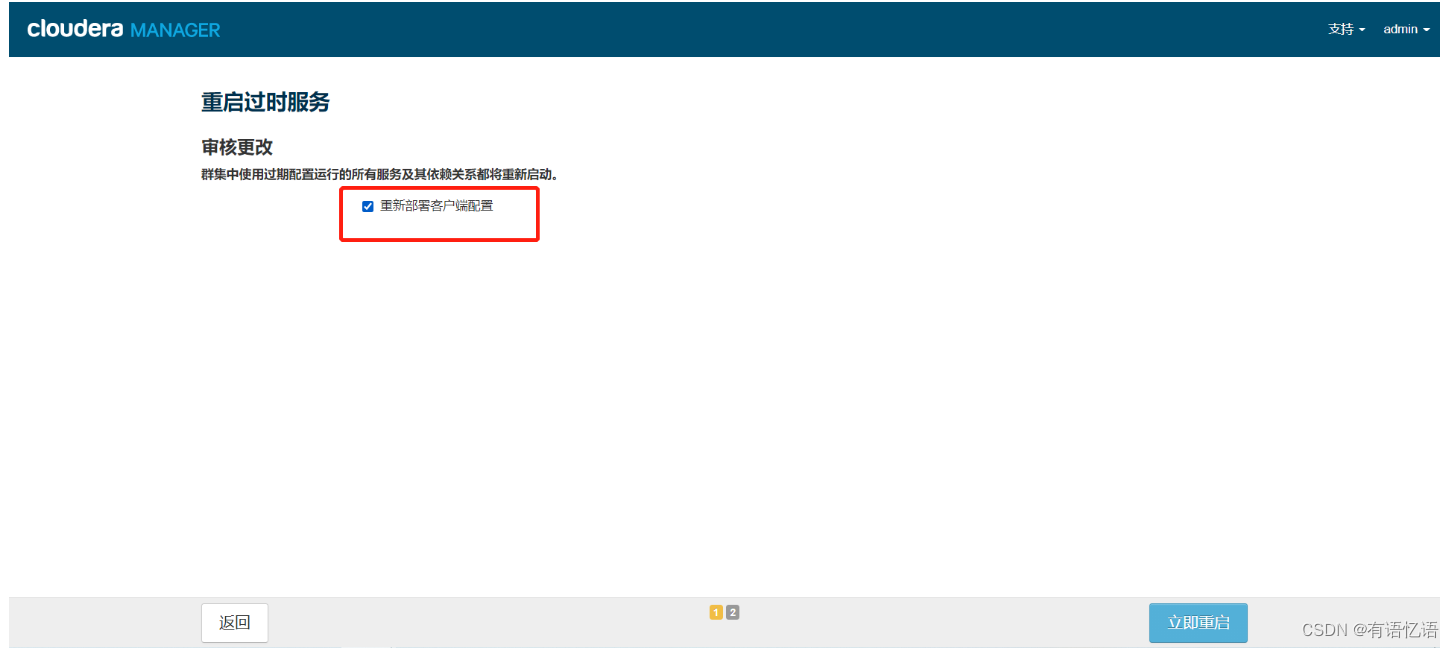
由于添加了Spark,需要重启Yarn
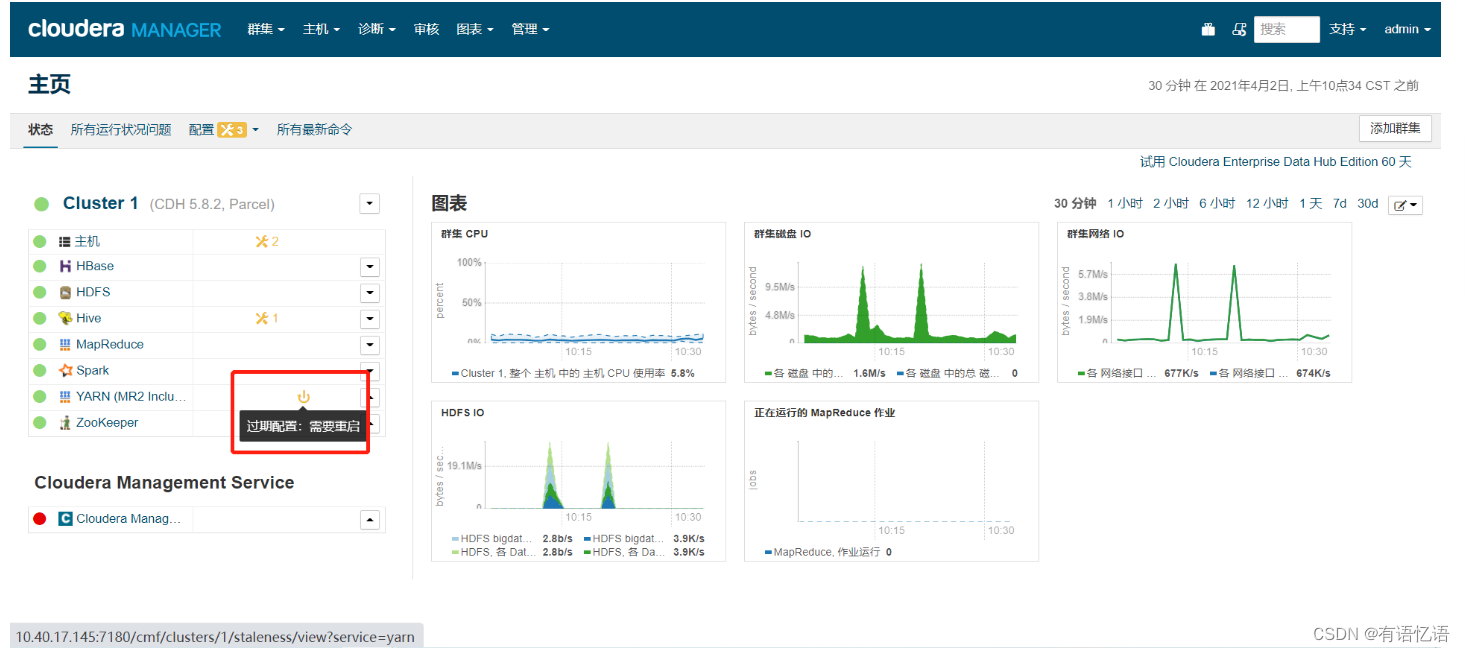
点击重启过时服务

等待Yarn重启完成
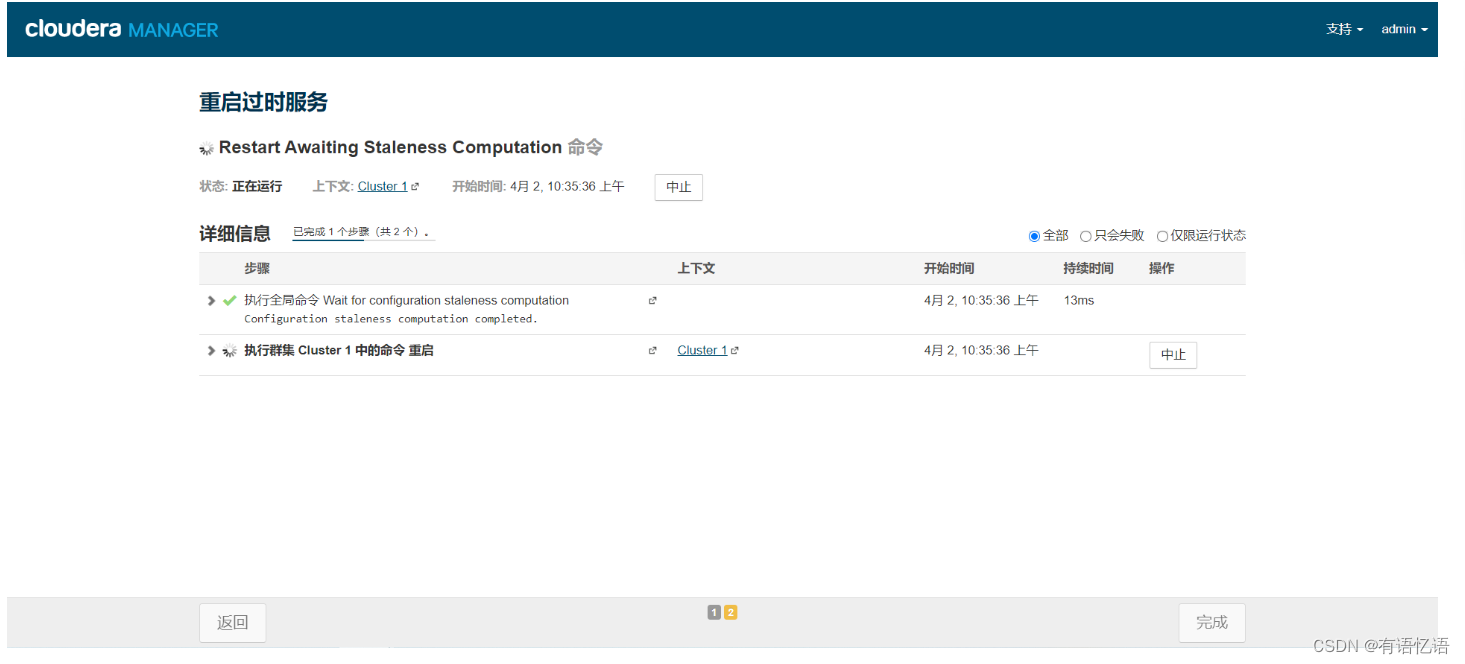
第二步:开启SparkSQL服务
选择一台有部署CM agent服务的服务器安装SparkSQL即可
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/start-thriftserver.sh
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/stop-thriftserver.sh
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/beeline
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/load-spark-env.sh
1.更改spark用户可登录权限
vim /etc/passwd
修改红框中/sbin/nologin为/bin/bash

2.拷贝文件
cp /opt/cmpackage/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar /opt/cloudera/parcels/CDH/jars/
会提示是否覆盖,按y覆盖就行
cp /opt/cmpackage/start-thriftserver.sh /opt/cloudera/parcels/CDH/lib/spark/sbin/
cp /opt/cmpackage/stop-thriftserver.sh /opt/cloudera/parcels/CDH/lib/spark/sbin/
cp /opt/cmpackage/beeline /opt/cloudera/parcels/CDH/lib/spark/bin/
cp /opt/cmpackage/load-spark-env.sh /opt/cloudera/parcels/CDH/lib/spark/bin/
会提示是否覆盖,按y覆盖就行
chmod +x /opt/cloudera/parcels/CDH/lib/spark/sbin/*thriftserver.sh
mkdir /opt/cloudera/parcels/CDH/lib/spark/logs
chown spark /opt/cloudera/parcels/CDH/lib/spark/logs
3.hdfs创建相关目录
切换到hdfs用户,然后执行命令
su - hdfs
hdfs dfs -mkdir -p /user/spark/share/lib
hdfs dfs -put /opt/cloudera/parcels/CDH/jars/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar /user/spark/share/lib
hdfs dfs -chmod 755 /user/spark/share/lib/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar
hdfs dfs -chown -R spark /user/spark
4.cloudera manager上修改spark配置
/user/spark/share/lib/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar
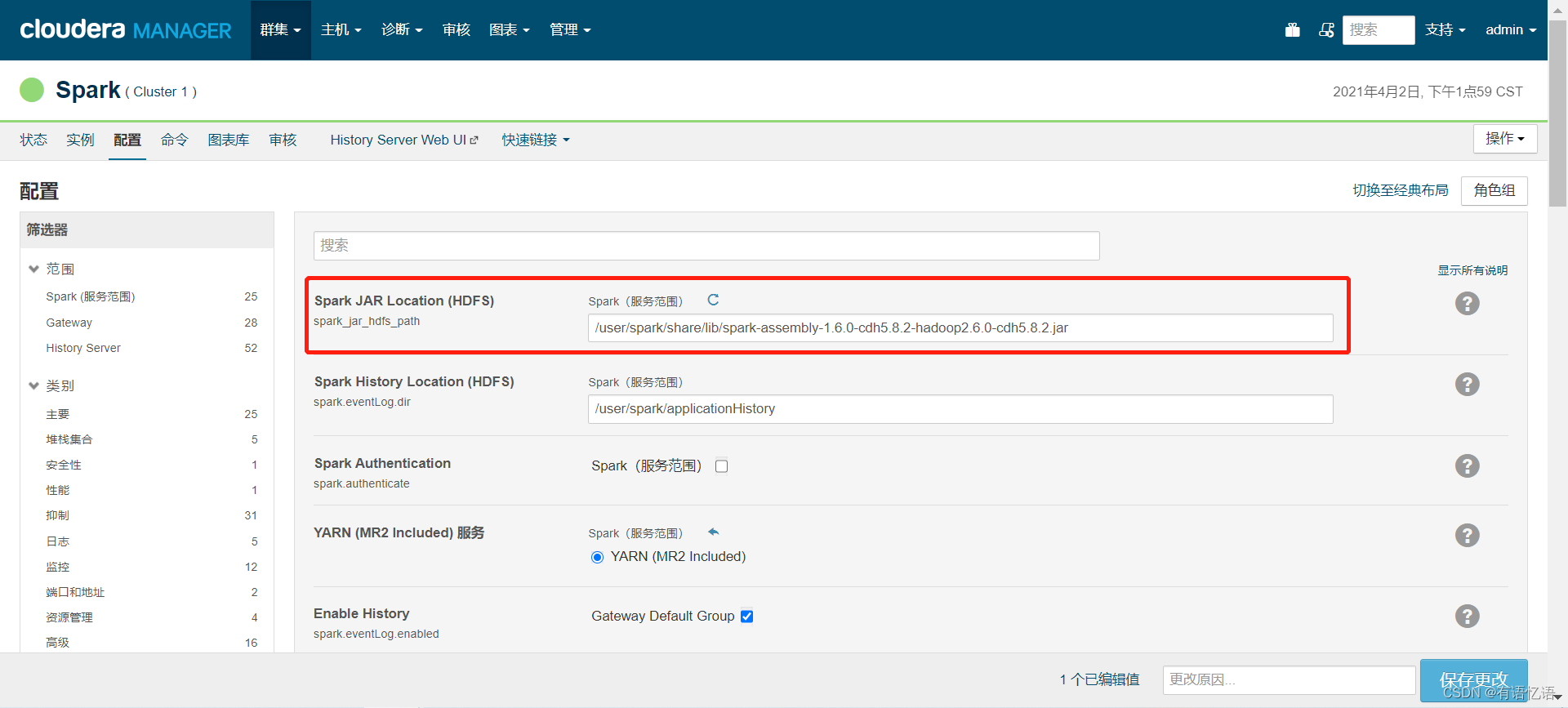
spark.yarn.jar=hdfs://bigdata:8020/user/spark/share/lib/spark-assembly-1.6.0-cdh5.8.2-hadoop2.6.0-cdh5.8.2.jar
export JAVA_HOME=/usr/local/jdk1.8.0_121
由于更改了配置文件,所以需要重启Spark服务
点击部署客户端配置,然后等待命令完成即可
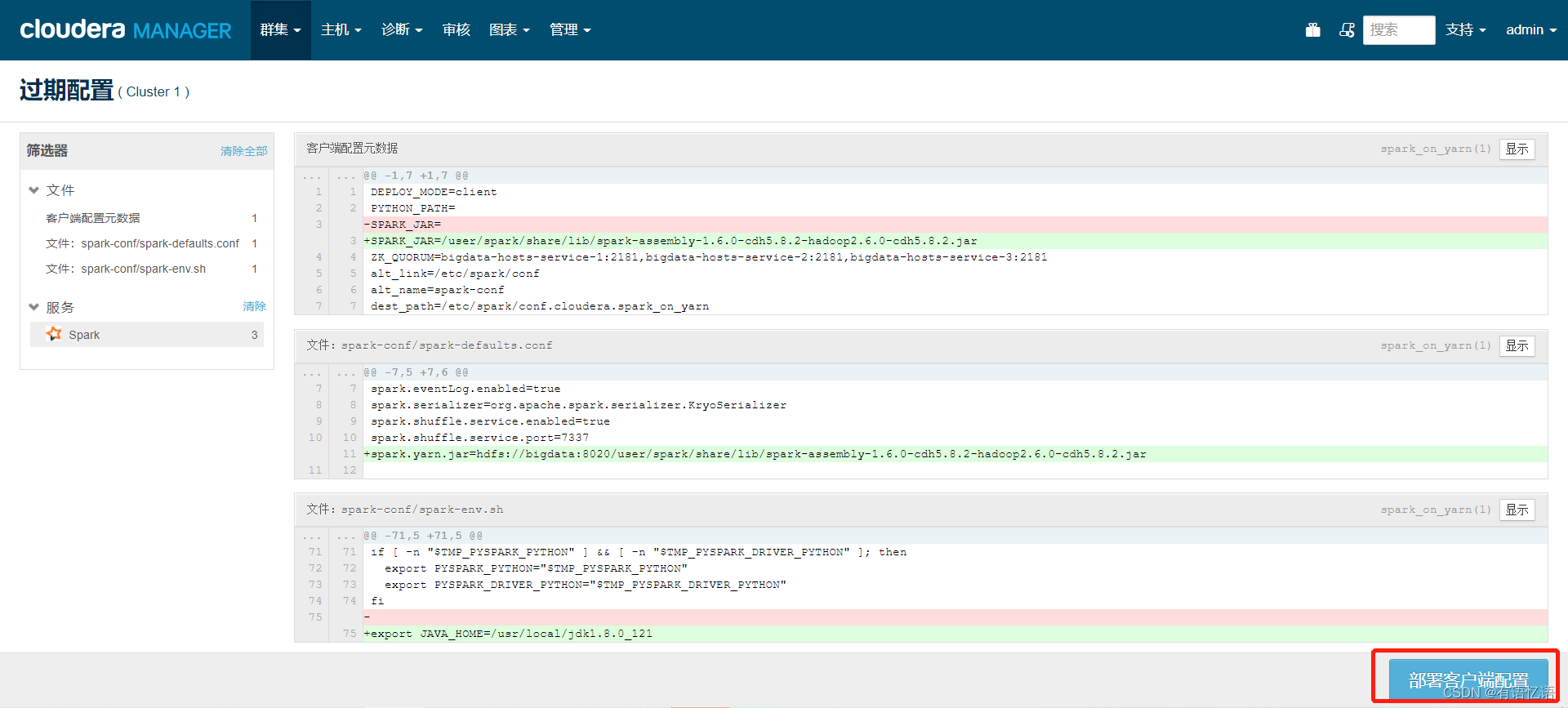
5.启动SparkSQL服务
切换到spark用户
su - spark
/opt/cloudera/parcels/CDH/lib/spark/sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10090 --queue root.wedw --master yarn --deploy-mode client
开启自动重启
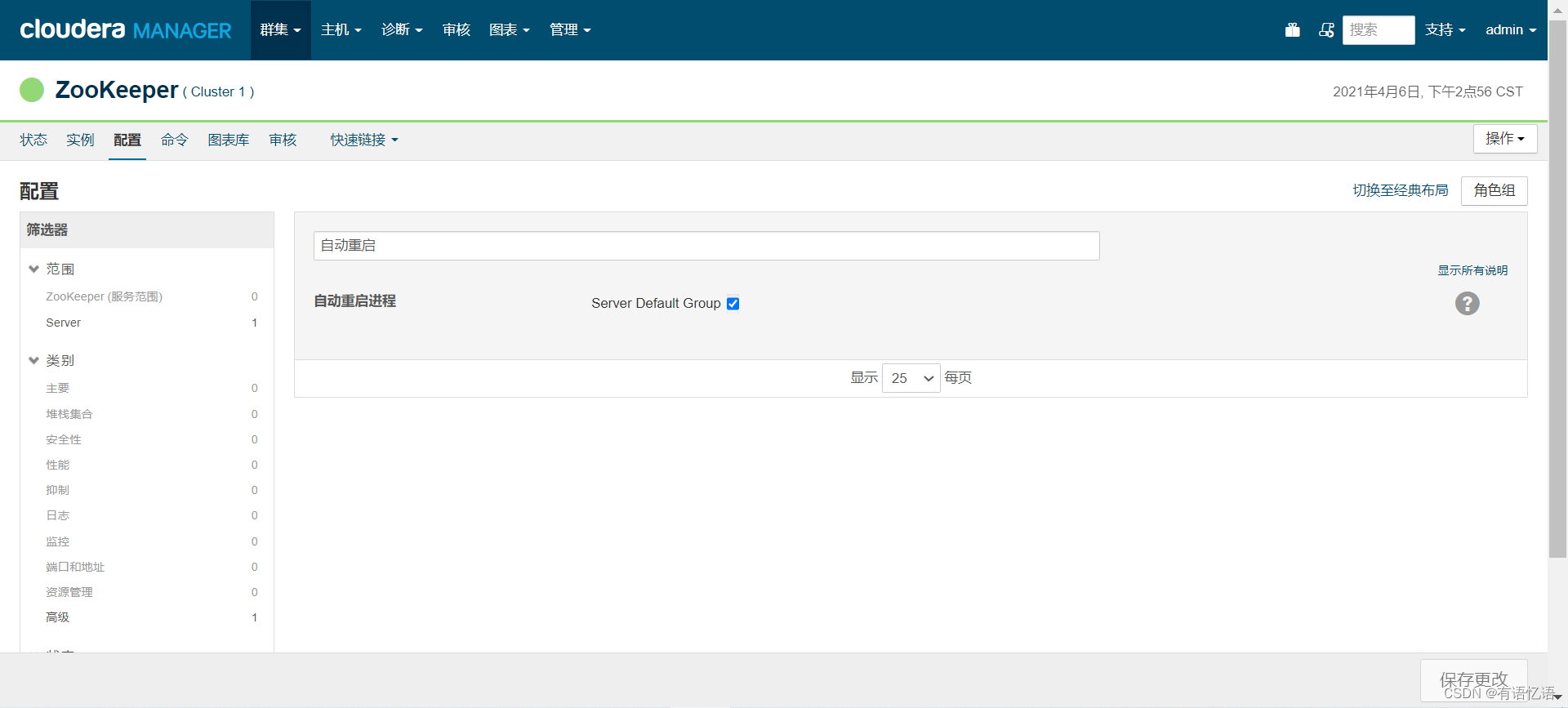
已ZooKeeper为例,其它组件开启自动重启的原理一样
点击配置,搜索自动重启,如下图所示,勾选上,然后保存更改即可
客户端部署
需要在DP、Airflow部署的服务器上部署Hadoop、Hive、Spark(可选)客户端,前提jdk已配置好,/etc/profile已配置JAVA_HOME,/etc/hosts也已配置好
一、Hadoop客户端部署
mkdir /opt/cmpackage
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/hadoop-local-client.tar.gz
tar -zxvf /opt/cmpackage/hadoop-local-client.tar.gz -C /usr/local/
ln -s /usr/local/hadoop-2.6.0-cdh5.8.2 /usr/local/hadoop-current
然后需要从cm上下载客户端配置文件(仅展示HDFS如何下载客户端配置,其它组件下载客户端配置同理),Hadoop需要下载HDFS、MapReduce、Yarn的客户端配置:
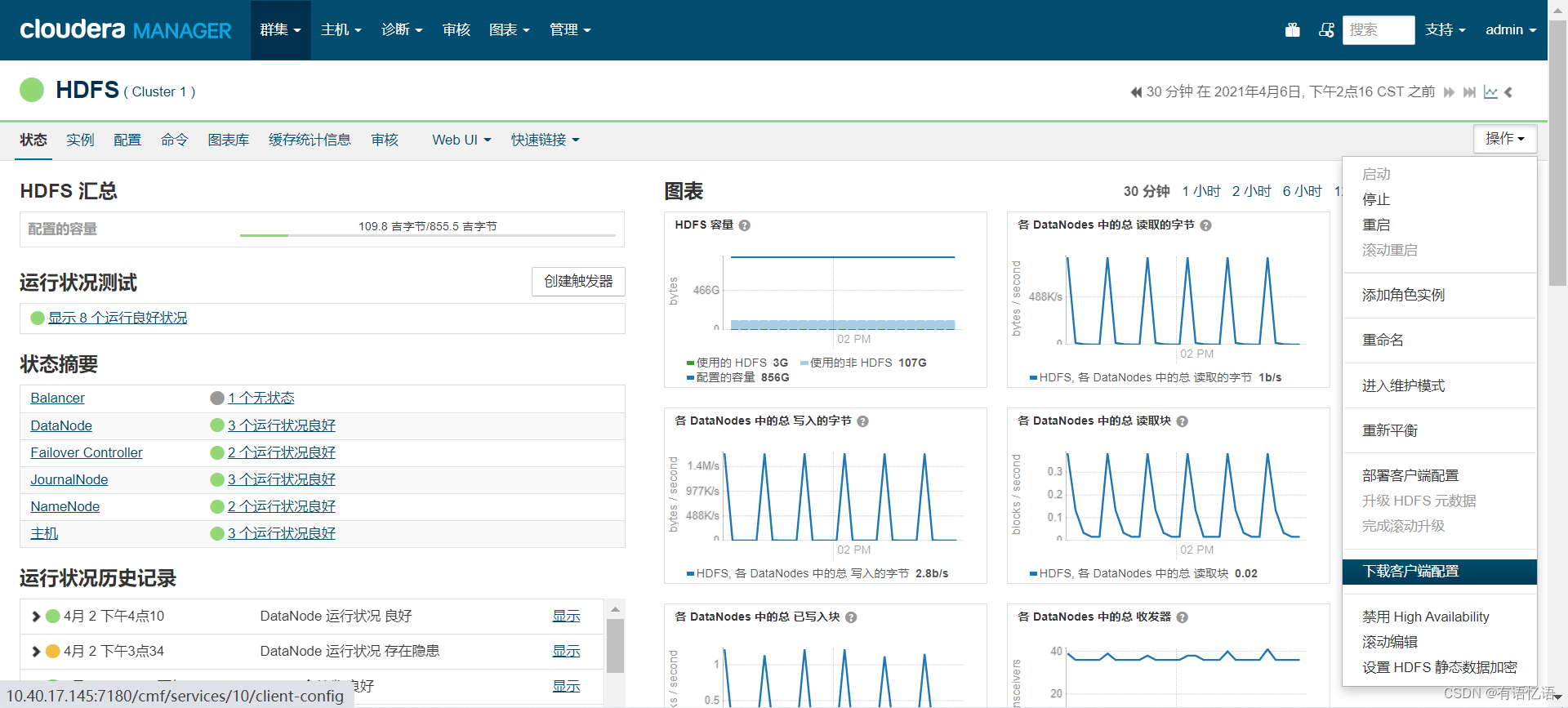
下载后会得到三个zip文件
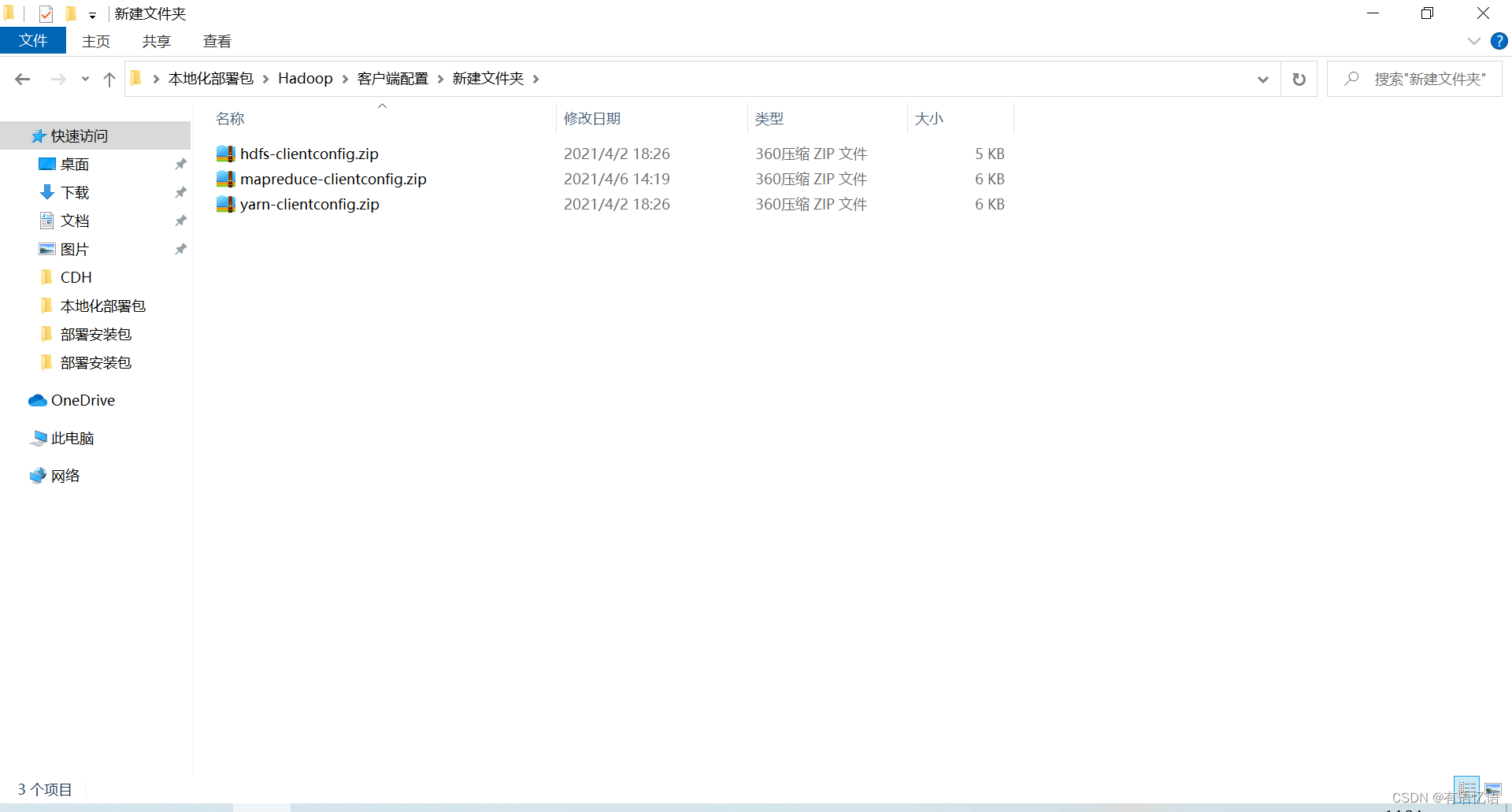
把这三个文件拷贝到服务器上/opt/cmpackage目录下,然后执行:
unzip -d /opt/cmpackage/ /opt/cmpackage/hdfs-clientconfig.zip
mv -f /opt/cmpackage/hadoop-conf/* /usr/local/hadoop-current/etc/hadoop/
rm -rf /opt/cmpackage/hadoop-conf
unzip -d /opt/cmpackage/ /opt/cmpackage/mapreduce-clientconfig.zip
mv -f /opt/cmpackage/hadoop-conf/* /usr/local/hadoop-current/etc/hadoop/
unzip -d /opt/cmpackage/ /opt/cmpackage/yarn-clientconfig.zip
mv -f /opt/cmpackage/yarn-conf/* /usr/local/hadoop-current/etc/hadoop/
二、Hive客户端部署
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/hive-local-client.tar.gz
tar -zxvf /opt/cmpackage/hive-local-client.tar.gz -C /usr/local/
ln -s /usr/local/hive-1.1.0-cdh5.8.2 /usr/local/hive-current
然后需要从cm上下载客户端配置文件,Hive需要下载Hive的客户端配置,下载好的客户端配置文件上传到/opt/cmpackage目录下,然后执行:
unzip -d /opt/cmpackage/ /opt/cmpackage/hive-clientconfig.zip
mv -f /opt/cmpackage/hive-conf/* /usr/local/hive-current/conf/
还需要配置HADOOP_HOME环境变量:
vim /etc/profile
在最下面添加此行
export HADOOP_HOME=/usr/local/hadoop-current
然后:
source /etc/profile
三、SparkSQL客户端部署(可选)
wget -P /opt/cmpackage http://172.16.246.252:81/hadoopteam/cloudmanager/spark-local-client.tar.gz
tar -zxvf /opt/cmpackage/spark-local-client.tar.gz -C /usr/local/
ln -s /usr/local/spark-1.6.0-bin-hadoop2.6 /usr/local/spark-current
环境验证
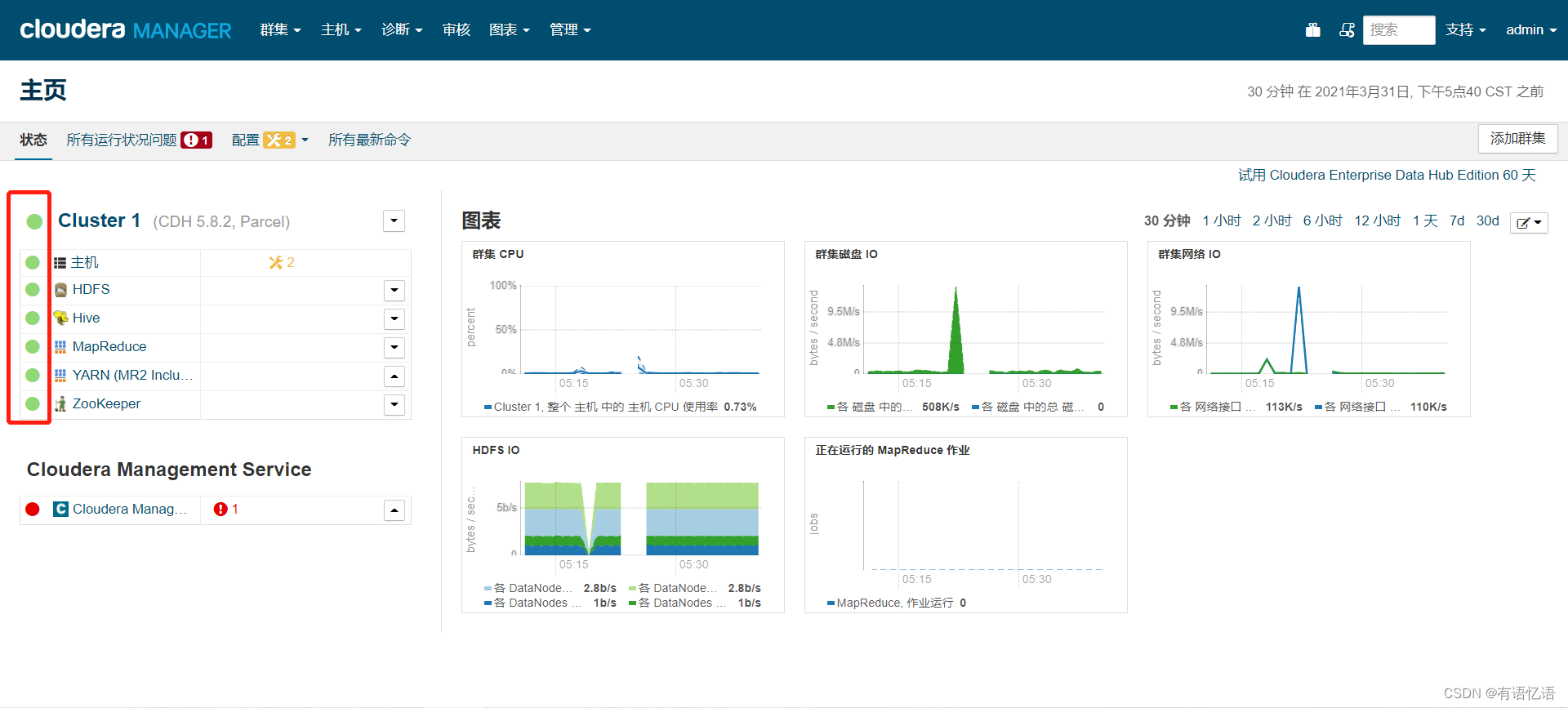
下图中红框为全绿色说明Hadoop服务部署完成,验证作业能否正常运行,需要和DP、Airflow联调
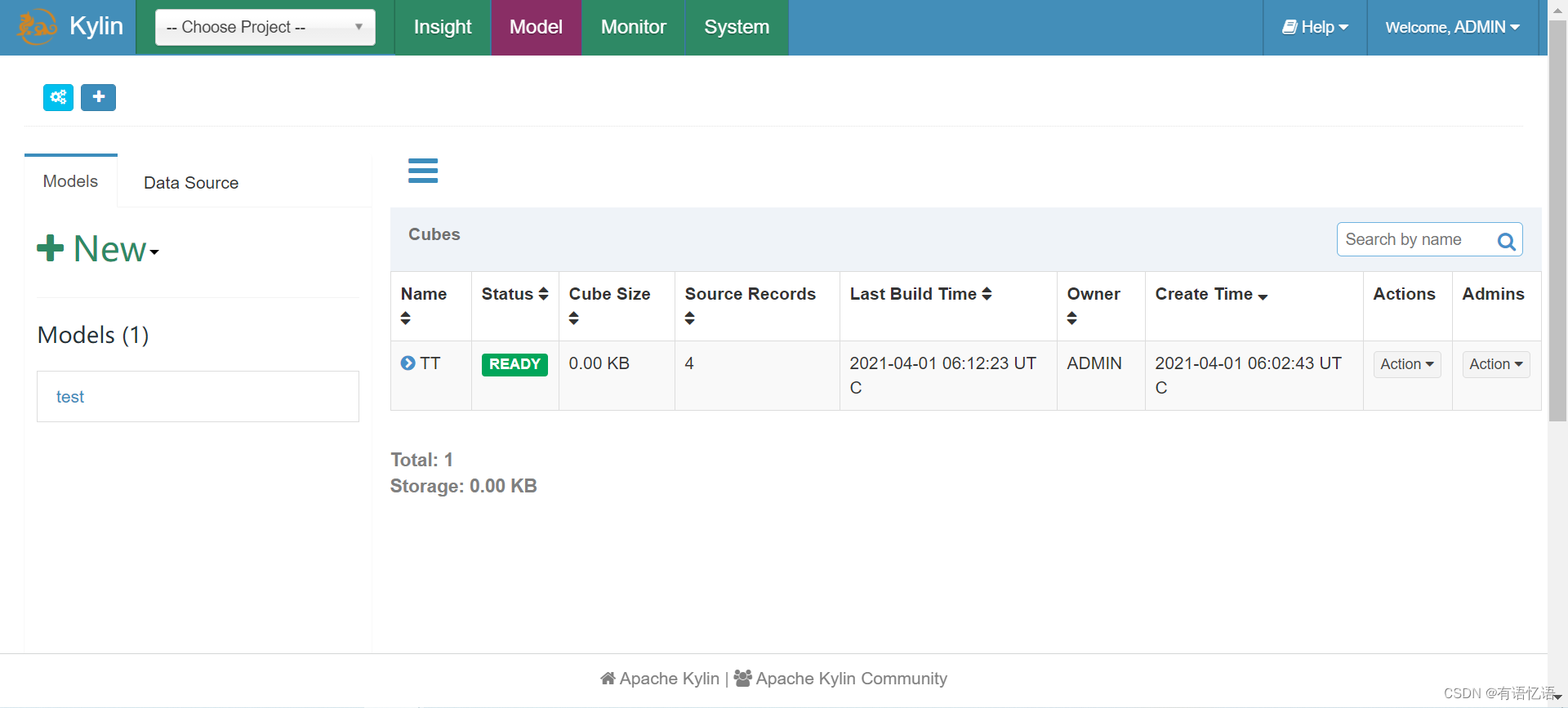
Kylin验证,登录Kylin Web界面,输入账号密码可以登录进去,即部署完成:
SparkSQL验证(10.40.17.69为部署SparkSQL服务的地址)
/opt/cloudera/parcels/CDH/lib/spark/bin/beeline -u “jdbc:hive2://10.40.17.69:10090” -n spark
show databases;

后续:Hadoop需要提供给DP的配置
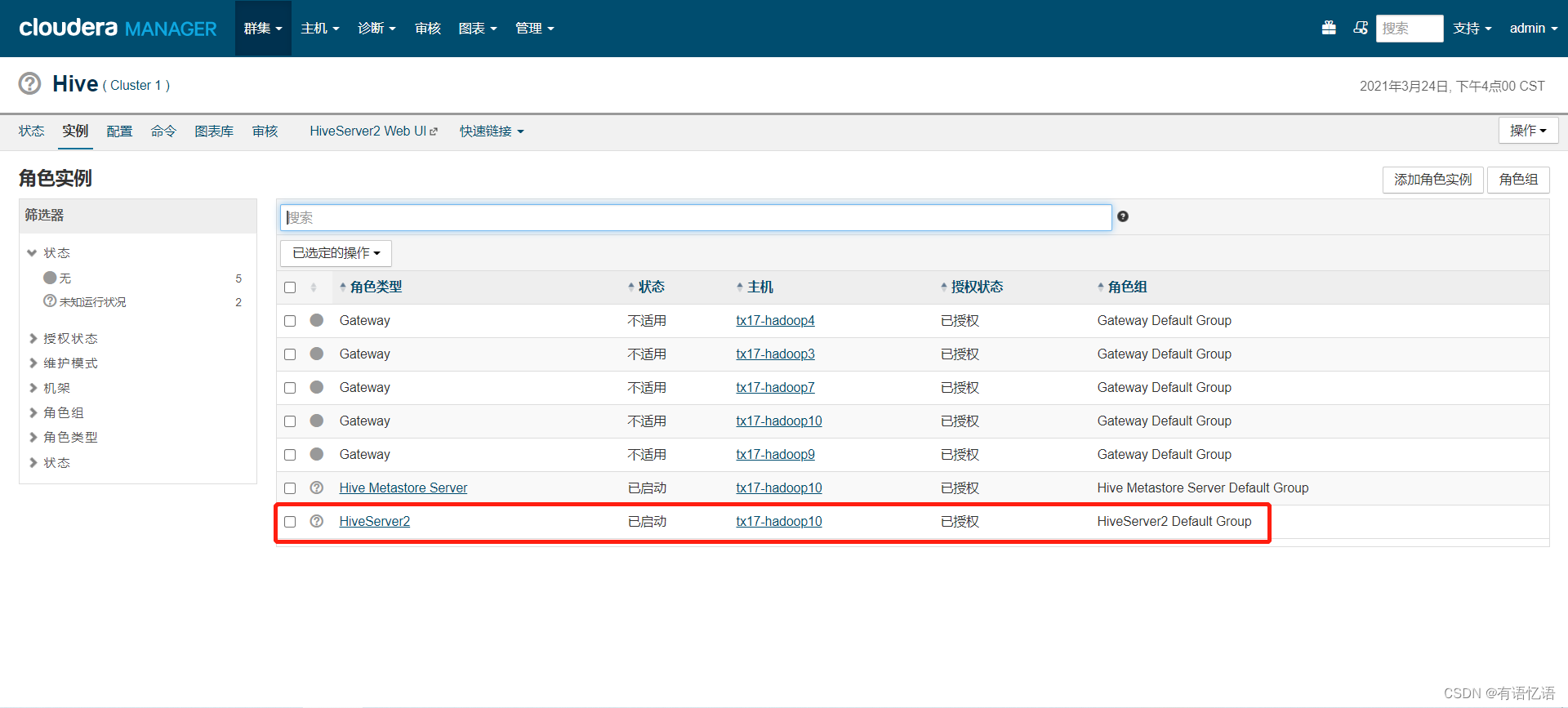
红框中为dataplatform.biz.dal.hiveserver2.host的配置地址(找到主机名对应的ip)
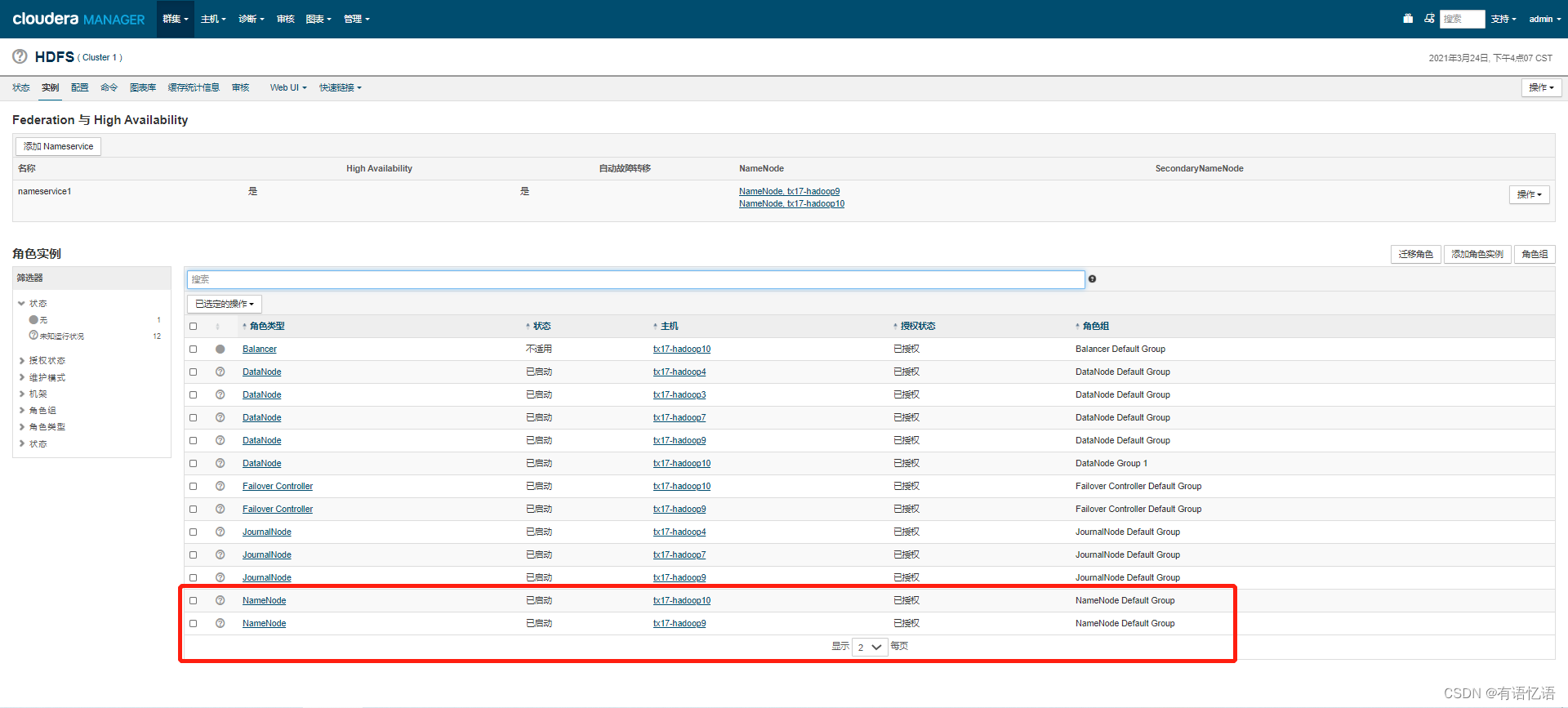
红框中为guahao.hdfs.address1,guahao.hdfs.address2(端口固定为8020,找到主机名对应的ip)
先点击黄框,红框中为
dataplatform.biz.dal.mysql.hive.url=jdbc:mysql://10.20.190.107:3308/hive?useUnicode=true&characterEncoding=utf8
dataplatform.biz.dal.mysql.hive.username=root
dataplatform.biz.dal.mysql.hive.password=root1
数据库地址,用户名和密码由DBA给出