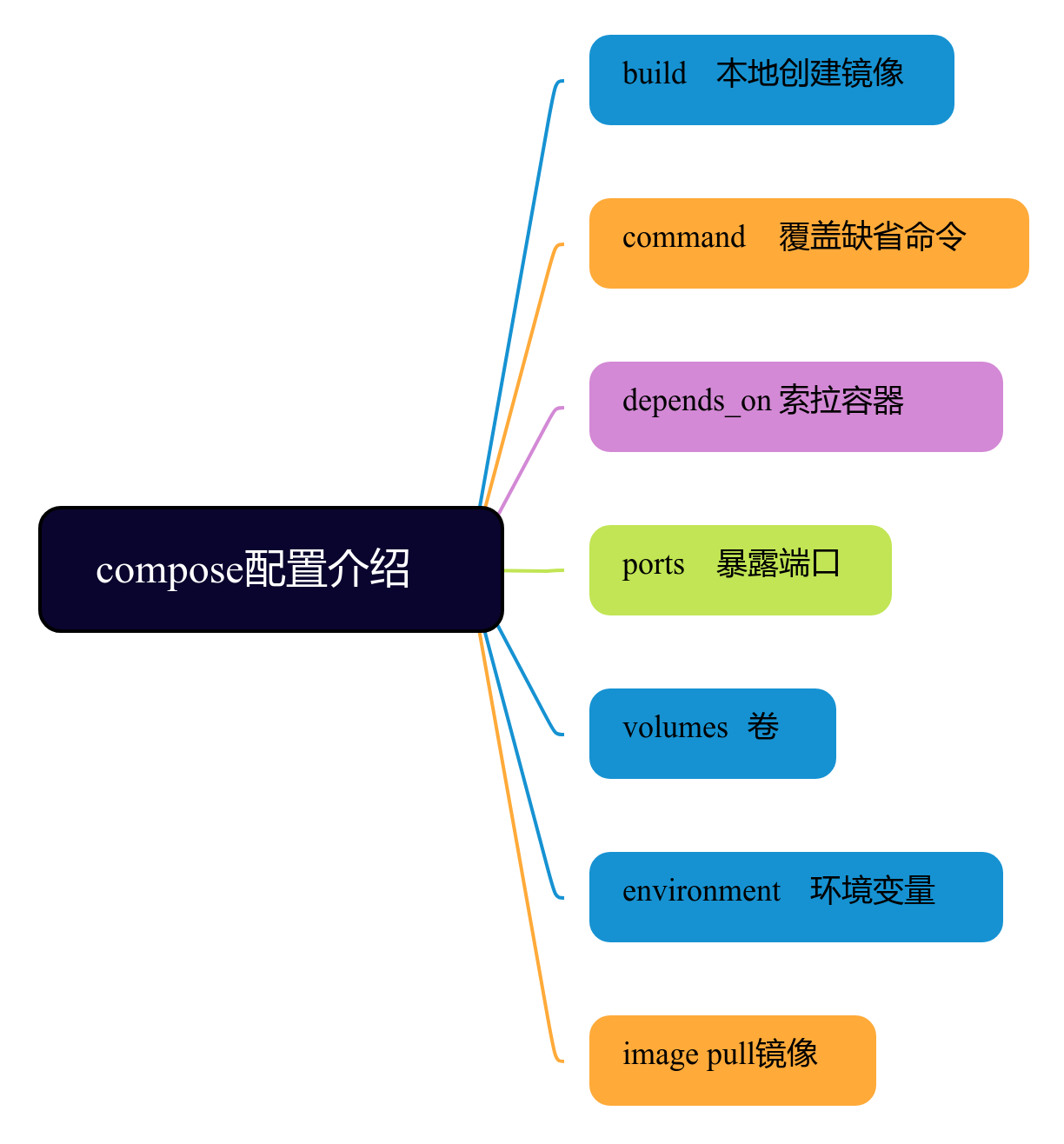
有一篇xml文档,如下:
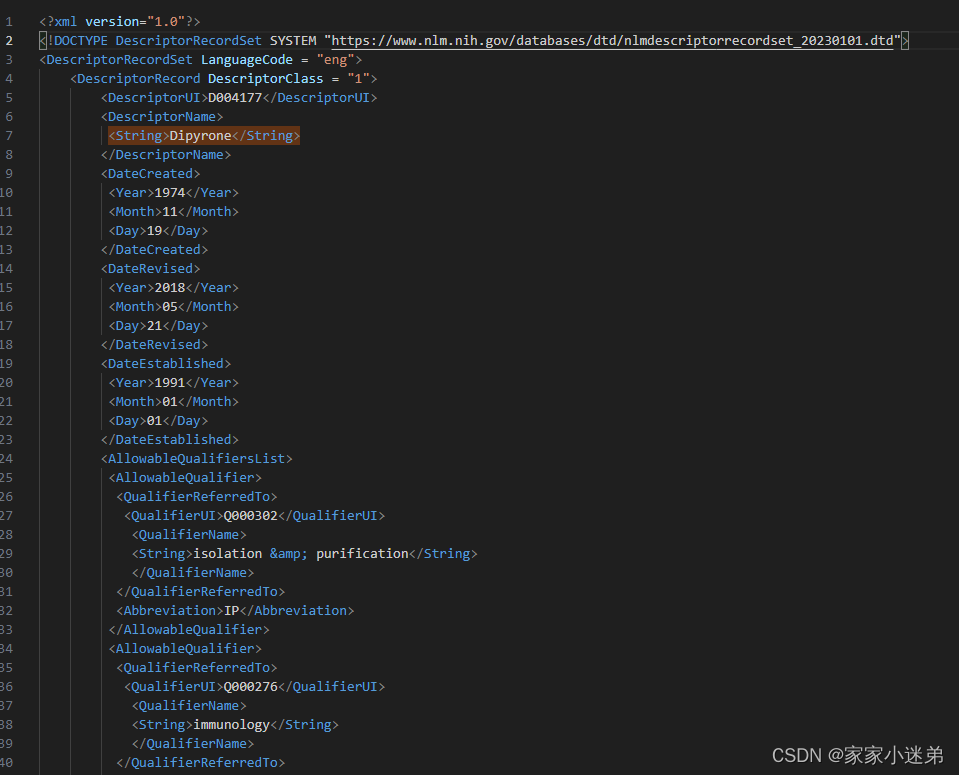
现在需要解析出其中的内容,首先需要明确的是,文档是由一个个的标签嵌套形成的,例如整个xml文件是由许多DescriptorRecord标签构成, <DescriptorRecord DescriptorClass = "1">xxxxxxxxxx</DescriptorRecord>
现在需要解析出每个DescriptorRecord 里面嵌套的xxxx各层级标签里面的内容,
导入的依赖有:
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
解析代码如下:
File file=new File("D:\\zoom\\字典相关\\desc2023\\test.xml");
SAXReader saxReader = new SAXReader();
Document doc = saxReader.read(file);
JSONObject jsonObject = XmlUtil.xmlToJson(doc.asXML());
首先将文件读取并且解析为doc,再转成JSONObject对象,
再获取DescriptorRecord标签下的内容

可以看到,整个xml文档里面,有5个DescriptorRecord嵌套,
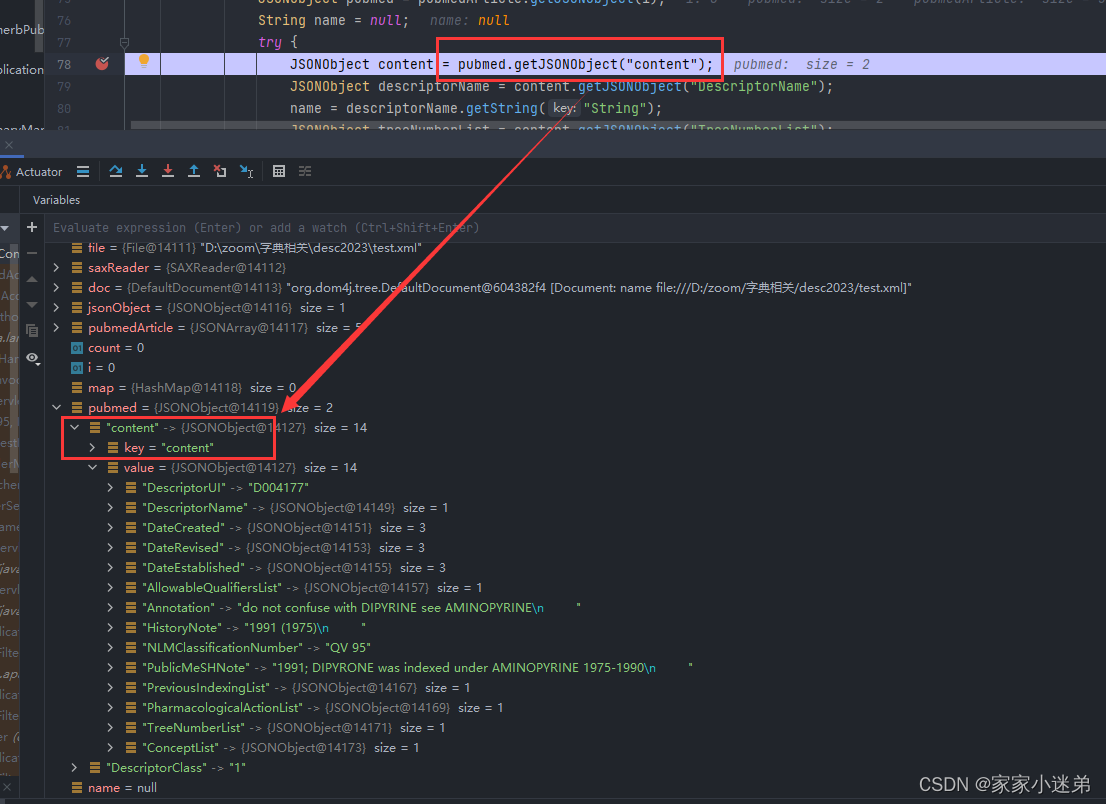
通过“content”这个key,获取下面的内容,解析出来是一个JSONObject对象,
有的时候一个标签嵌套的是一个JSONObject,有的时候是一个JSONArray,需要进行判断:if (treeNumberList.get("TreeNumber") instanceof JSONArray),
即对于treeNumberList获取key为TreeNumber是一个对象,还是一个数组,再进行取值。
在debug的时候,结合xml格式,来判断下一步是怎么取值,
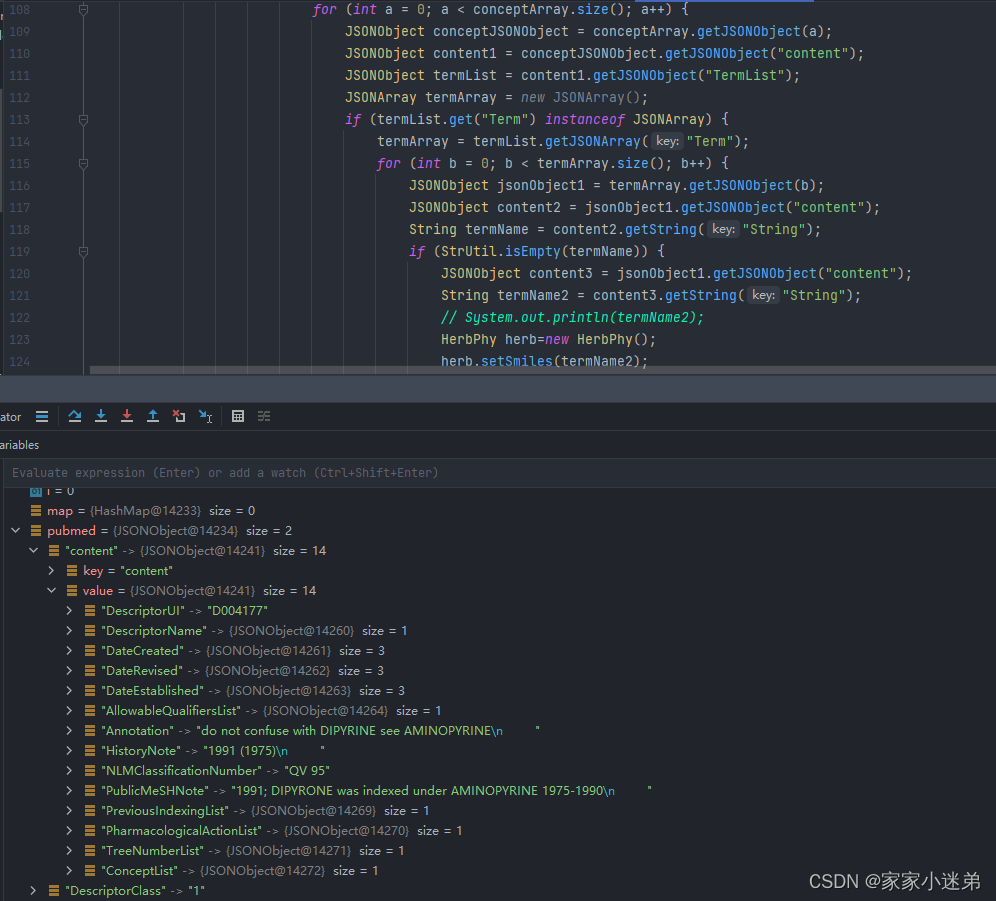
fastjson的用法如下:
获取JSONObject 对象
JSONObject content = pubmed.getJSONObject("content");
获取数组对象
JSONArray treeNumber = treeNumberList.getJSONArray("TreeNumber");
通过String这个key来取值
String termName2 = content3.getString("String");
通过Term来获取对象
termList.get("Term")