概述
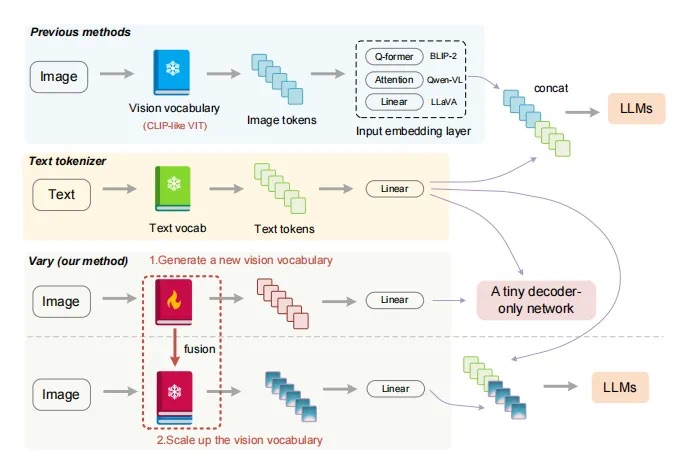
现代大型视觉语言模型(LVLMs),例如CLIP,使用一个共同的视觉词汇,以适应多样的视觉任务。然而,在处理一些需要更精细和密集视觉感知的特殊任务时,例如文档级OCR或图表理解,尤其是在非英语环境中,CLIP风格的视觉词汇表可能导致在标记化视觉知识方面效率较低,甚至可能导致词汇缺失的问题。
为了解决这些问题,旷视提出了一种名为Vary的高效且有效的LVLMs视觉词汇量扩展方法。Vary的过程分为两个关键阶段:
-
第一阶段: 设计了一个词汇表网络和一个小型的仅解码器的转换器,通过自回归生成所需的新视觉词汇表。
-
第二阶段: 通过将新的视觉词汇表与原始词汇表(CLIP)合并,扩展了vanilla(原始的)视觉词汇表。这使得LVLM能够有效地获取新特征,从而快速适应新的任务和场景。
这种方法旨在提高LVLM在特殊任务和非英语环境下的效率和适应性,避免了视觉知识标记化方面的一些问题。
与流行的BLIP-2、MiniGPT4和LLaVA相比,Vary在保持原有功能的同时,具有更出色的细粒度感知和理解能力。具体来说,Vary能够胜任新的文档解析功能(OCR或标记转换),同时在DocVQA中实现78.2%的ANLS,在MMVet中实现36.2%。
源码与安装
git clone https://github.com/Ucas-HaoranWei/Vary.git
cd Vary
安装相关软件包:
conda create -n vary python=3.10 -y
conda activate vary
pip install e .
安装 Flash-Attention:
pip install ninja
pip install flash-attn --no-build-isolation
测试
python vary/demo/run_qwen_vary.py --model-name /vary/model/path/ --image-file /an/image/file.png
Vary方法
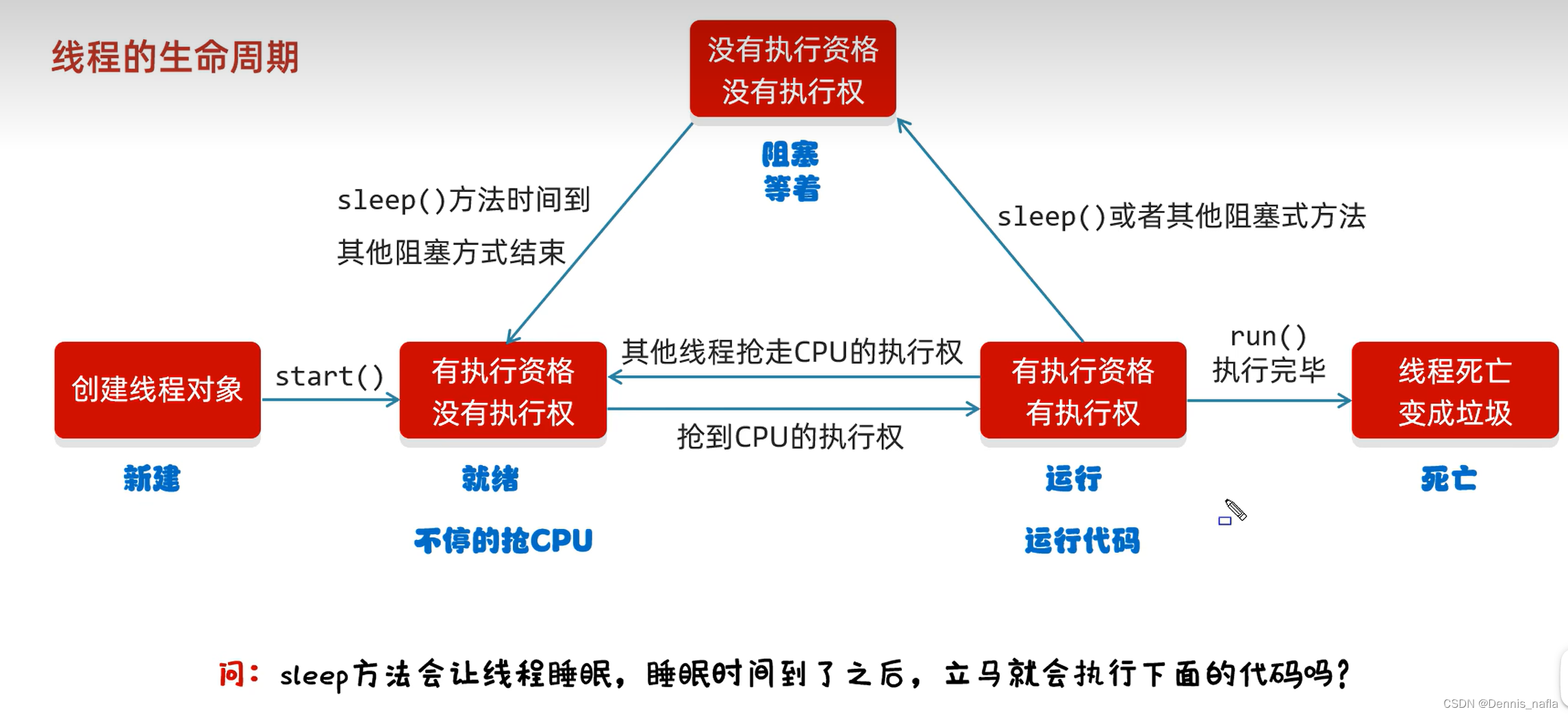
一.算法架构
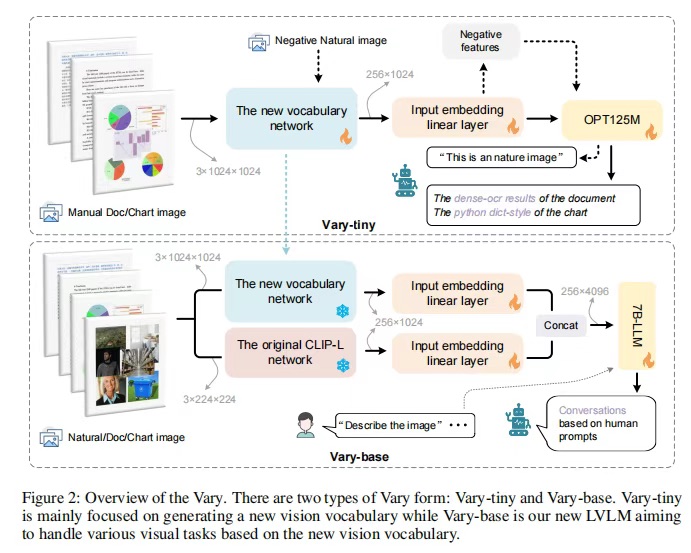
Vary方法包含两个变体:Vary-tiny和Vary-base,如下图所示。Vary-tiny被设计用于生成新的视觉词汇,而Vary-base则用于利用这些新词汇。具体而言,Vary-tiny由一个词汇网络和一个微型的OPT-125M组成。为了对齐通道尺寸,两个模块之间添加了一个线性层。Vary-tiny没有文本输入分支,因为其主要关注细粒度感知。作者期望新的视觉词汇网络在处理人工图像(例如文档和图表)时能够表现出色,以弥补CLIP的不足。同时,为了防止它在自然图像的标记中成为CLIP的噪声,作者在生成过程中使用人工文档和图表数据作为正样本,自然图像作为负样本来训练Vary-tiny。
完成上述过程后,作者提取了词汇网络并将其添加到一个大型模型中,以构建Vary-base。如图2下半部分所示,新旧词汇网络具有独立的输入嵌入层,并在LLM之前进行集成。在此阶段,冻结新旧视觉词汇网络的权重,解冻其他模块的权重。这一阶段的目标是在更大的模型中利用新的视觉词汇,以提高模型的性能和适应性。
二、视觉词汇
1.新词汇网络
在Vary中,作者使用了由SAM预训练的ViTDet图像编码器(基尺度)作为Vary新词汇网络的主要组成部分。由于SAM-base的输入分辨率为(1024×1024),而输出步幅为16,因此最后一层的特征形状为(H×W×C为64×64×256),与CLIP-L的输出(N×C为256×1024)无法对齐。为了解决这个问题,作者在SAM初始化网络的最后一层后面添加了两个卷积层,这被称为一个有效的 token 合并单元,如图3所示。
第一个卷积层的核大小为3,其目的是将7b - llm特征形状转换为32×32×512。接下来,第二个卷积层的设置与第一个相同,可以进一步将输出形状转换为16×16×1024。然后,输出特征被平展为256×1024,以对齐CLIP-VIT的图像 token 形状。这一系列操作旨在调整SAM-base输出的特征形状,以使其与CLIP-L的输出相匹配,确保新视觉词汇网络的有效集成。
2.生成短语中的数据引擎
在作者的研究中,他们选择高分辨率文档图像-文本对作为新视觉词汇预训练的主要正数据集,以验证模型在细粒度图像感知方面的能力,特别是在密集OCR任务上。由于目前尚未公开具有中英文文档的数据集,作者创建了自己的数据集。他们首先从arXiv和CC-MAIN-2021-31-PDFUNTRUNCATED等开放获取文章中收集了PDF格式的文档作为英文部分,并从互联网上的电子书中收集了中文部分。然后,使用PyMuPDF的fitz工具从每个PDF页面提取文本信息,并通过pdf2image将每个页面转换为PNG图像。在这个过程中,作者构建了1百万个中文文档和1百万个英文文档图像-文本对进行训练。
对于图表数据,作者发现当前的大型视觉语言模型(LVLMs)在图表理解方面表现不佳,特别是在处理中文图表时。因此,他们选择图表作为另一个需要"写"入新词汇表的主要知识。他们根据图表的渲染方式选择了matplotlib和pyecharts作为渲染工具。对于matplotlib风格的图表,他们构建了25万个中英文版本。对于pyecharts,分别为中文和英文创建了50万个图表。此外,作者将每个图表的文本基础真值转换为Python字典形式。图表中使用的文本,如标题、x轴和y轴,是从互联网上下载的自然语言处理(NLP)语料库中随机选择的。
为了构建负样本自然图片-文本对,以确保新引入的词汇不会产生噪声,作者从COCO数据集中提取了12万张图像,每张图像对应一个文本。这些文本从以下句子中随机抽取:“It’s a image of nature”; “这是一张自然的照片”; “这是一张自然照片”; “这是一个自然的形象”; “这是大自然的杰作。”
3.输入格式
在对Vary-tiny进行自回归训练时,作者使用了图像-文本对,其中输入格式符合流行的大型视觉语言模型(LVLMs)的规范,即图像token以前缀形式与文本token打包在一起。
具体而言,作者使用了两个特殊标记 “” 和 “”,用于指示图像标记在输入中的位置。这些标记是为了插入OPT-125M(4096个标记)的输入。在训练过程中,Vary-tiny的输出仅为文本,并将 “” 视为表示序列结束的特殊令牌(eos令牌)。
因此,每个训练实例都包含一个图像-文本对,其中图像部分由特殊标记表示,而文本部分包含文本标记和 “” 作为序列的结束标志。这种方式的训练允许Vary-tiny学习生成新的视觉词汇,以适应特定任务和场景。
三、扩大视觉词汇
1.Vary-base结构
在完成词汇网络的训练后,作者将其引入到LVLM - Var -base中。具体而言,作者将新的视觉词汇表与原始的CLIP-VIT并行化。这两个视觉词汇表都有一个单独的输入嵌入层,即一个简单的线性层。
线性层的输入通道为1024,输出通道为2048,这样确保了拼接后的图像token通道数为4096。这与LLM(Qwen-7B或Vicuna-7B)的输入通道数完全一致。这种并行化的设计允许LVLM同时处理原始CLIP-VIT的图像编码和新引入的视觉词汇网络的图像编码,从而为LVLM提供了新的特征以适应特定任务和场景。
2.扩展短语中的数据引擎
作者认为数据需要具有一定的格式,例如支持公式和表格。为了满足这个需求,他们通过LATEX(一种排版系统)渲染创建文档数据。具体步骤如下:
-
首先,作者在arXiv上收集了一些.tex源文件,这是包含LATEX代码的文档源文件。
-
然后,他们使用正则表达式提取表格、数学公式和纯文本等内容。
-
最后,重新渲染这些内容,使用pdflatex准备新的模板。为了执行批处理渲染,作者收集了10多个模板。
通过这个流程,作者创建了具有统一格式的文档数据。为了统一文本的格式,他们将每个文档页面的文本ground truth转换为mathpix markdown样式。
整个建设过程使作者得到了50万英文页面和40万中文页面。图4显示了一些示例。这样的数据集不仅包含了纯文本信息,还包括了公式和表格等复杂结构,为模型提供了更具挑战性的任务。

使用pdflatex来渲染文档,使用pyecharts/matplotlib来渲染图表。文档数据获取中/英文文本、公式和表格。图表数据包括中/英文条形、线形、饼形和复合样式。
在第1.2.2节中,作者通过批量渲染图表数据来训练新的词汇网络。然而,由于这些图表中的文本(标题、x轴值和y轴值)是随机生成的,它们之间的语义关联性较低。在词汇表生成阶段,这并不是问题,因为作者只关心新的词汇表是否能够有效地压缩视觉信息。但是在Vary-base的训练阶段,由于LLM的解冻,作者希望使用更高质量(强相关内容)的数据进行训练。
因此,在这一阶段,作者采取了不同的策略。他们使用GPT-4生成了一些图表,并利用高质量的语料库添加渲染了200,000个图表数据,以用于Vary-base的训练。这样的做法有助于提高图表中文本之间的语义关联性,使得模型在训练中能够更好地理解和捕捉图表的内容。
总的来说,训练Vary-base的过程遵循流行的大型视觉语言模型(LVLMs)的方法,如LLaVA。这包括预训练和SFT(Supervised Fine-Tuning)阶段。不同之处在于,作者冻结了所有的词汇网络,并解冻了输入嵌入层和LLM,使得它更类似于一个纯LLM的预训练设置。在SFT阶段,使用了LLaVA-80k或LLaVA-CC665k以及DocVQA和ChartQA的训练集作为微调数据集。此外,一般概念的引入也通过使用自然图像-文本对数据从LAION-COCO中随机抽取,数量为400万。
实验结果
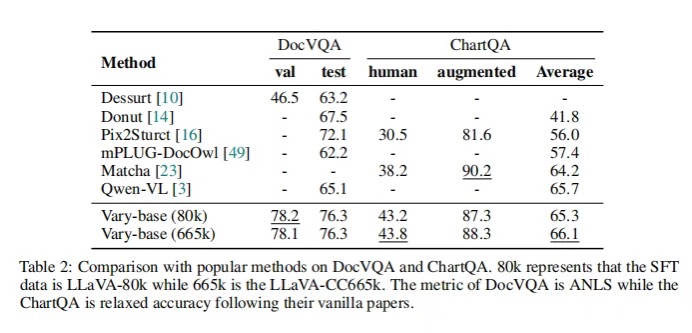
根据表2的结果,在LLaVA-80k的SFT数据上,Vary-base(以Qwen-7B为LLM)在DocVQA上取得了78.2%(测试集)和76.3%(验证集)的ANLS(Answer Normalized Levenshtein Similarity)。在使用LLaVA-665k的SFT数据的情况下,Vary-base在ChartQA上的平均性能达到了66.1%。
在这两个具有挑战性的下游任务上,Vary-base的表现与Qwen-VL相当甚至更好。这说明了所提出的视觉词汇量扩展方法在下游任务中具有很大的潜力,能够有效地提高模型性能。
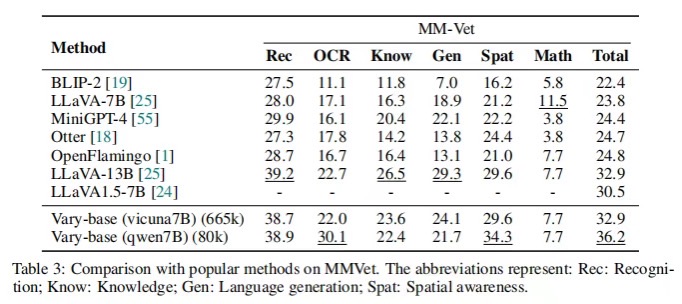
使用相同的LLM(Vicuna-7B)和SFT数据(LLaVA-CC665k),Vary相对于LLaVA-1.5提高了总度量2.4%(32.9%对30.5%),证明了Vary的数据和训练策略不会损害模型的一般能力。
此外,Vary在与Qwen-7B和LLaVA-80k的性能相比时,表现出了更高的性能,达到了36.2%。这进一步证明了Vary的视觉词汇扩展方法的有效性。
最重要的是,Vary展示了很大的潜力和极高的上限。使用Vary,多模态大模型可以直接端到端输出结果,无需冗长的管道。此外,Vary可以根据用户的提示(prompt)直接输出不同格式的结果,如LaTeX、Word、Markdown等。这使得OCR不再需要复杂的流程,而是可以更加灵活地满足不同输出格式的需求。