目录
前言
一、静态网页数据
二、网址通讯流程
1.DNS查询
2.建立连接
3.发送HTTP请求
4.服务器处理请求
5.服务器响应
6.渲染页面
7.页面交互
三、URL/POST/GET
1.URL
2.GET
形式
3.POST
形式
四.获取静态网页数据
1.requests库
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
在网站设计领域,基于纯HTML格式构建的网页通常定义为静态网页,这种类型的网页是早期网站建设的主要形式。对于网络爬虫来说,抓取静态网页中的数据相对较为简单,因为所需的所有信息都直接嵌入在网页的HTML代码里。然而,对于那些利用AJAX技术动态加载数据的网页,其数据并不总是直接出现在HTML代码中,这对爬虫的抓取工作造成了一定的难度。
在静态网页的数据抓取过程中,Requests库显示出其卓越的实用性。这个库不仅功能全面,而且操作简洁直观。本章的内容将从介绍如何安装Requests库开始,接着如何使用这个库来发送HTTP请求并获得相应内容,探讨如何通过自定义Requests的参数来适应不同的数据抓取需求。
一、静态网页数据
静态网页是互联网的基本组成部分,它们是由服务器以 HTML(超文本标记语言)形式发送到客户端(通常是浏览器)的网页。这些页面在服务器上是预先编写好的,对于所有用户来说,其内容在每次请求时都保持不变。与之相对的是动态网页,它们的内容可以根据用户的不同请求或交互而变化。

一般来说静态网页可获取到的信息有:
- 文本内容:网页上的所有文本,如文章、标题、链接描述等。
- 链接(URLs):网页上的所有超链接。
- 图像及其URL:网页上的图像以及它们的源URL。
- HTML结构信息:如各种HTML标签中的内容(div、span、p等)。
- 样式信息:例如CSS类和ID等。
- 元数据:如网页标题、描述、关键词等。
目前主流处理静态网页的工具有Python 语言的 requests 库来发送HTTP请求,并使用 BeautifulSoup 或 lxml 解析HTML内容。在浏览器中使用开发者工具可以更深入地分析网页结构和内容,按下F12即可进入开发者模式。
二、网址通讯流程
因为涉及到网址通讯流程,这里简要介绍一下网页信息传输流程更方便以后了解我们应该如何获取静态数据以及抓取信息。
当我们在浏览器中输入一个网址并访问时,发生的网络通讯流程可以分为以下几个主要步骤:
1.DNS查询
浏览器首先需要找出您要访问的网站的IP地址。它通过向DNS(域名系统)服务器发出查询来完成这一步骤。如果该地址已经在浏览器的缓存中,这一步将被跳过。
2.建立连接
一旦浏览器获得了网站的IP地址,它将尝试通过TCP(传输控制协议)建立到该地址的连接。通常这涉及到一个“三次握手”过程,确保稳定的连接建立。
3.发送HTTP请求
连接建立后,浏览器会向服务器发送一个HTTP请求。这个请求包括所请求页面的详细信息,以及客户端(即浏览器)的信息,如请求的类型(通常是GET或POST)、所需资源的路径、浏览器类型等。
4.服务器处理请求
服务器接收到请求后,会根据请求的类型和资源处理请求。如果是静态内容(如HTML页面、图片、CSS文件等),服务器通常会直接返回这些文件。对于动态内容,服务器可能会执行后端代码,如数据库查询,然后生成相应的HTML内容。
5.服务器响应
服务器处理请求后,会将响应数据(网页代码、图片、错误消息等)发送回浏览器。这通常以HTTP响应的形式发生,包括状态码(如200表示成功,404表示未找到等)和响应体。
6.渲染页面
浏览器接收到服务器的响应后,会解析和渲染页面。这包括HTML的解析、CSS样式的应用、JavaScript的执行等。这一过程中,浏览器可能还会发送额外的请求来获取页面上的其他资源(如图片、CSS文件、JavaScript文件等)。
7.页面交互
页面加载完成后,用户可以与页面进行交互,如点击链接、提交表单等。这可能会触发额外的HTTP请求和服务器响应,从而更新页面内容。通常使用HTTP的GET和POST请求最为常见,用于获取和提交数据。
从以上网页数据获取流程理解完,我们再来了解URL/POST/GET三者在浏览器网页网络通讯中代表的意义和作用,这也是一般通用的网络信息通讯规则。
三、URL/POST/GET
大家不妨在浏览器开发者模式,点击网络一栏可以查看每次网络数据交互情况,基本上都会有涉及到GET和POST,所有这里详细讲述GET和POST的具体作用和形式。

1.URL
URL想必大家都知道,诸如:https://www.csdn.net/就是一个URL,但是这里要较为详细的讲述一下URL的参数,也就是除去标准的URL后续?后面所带的参数含义。
URL参数是指在URL(统一资源定位符)中包含的一组键值对,用于向服务器传递额外的信息。它们通常出现在问号(?)之后,并使用等号(=)分隔键和值,不同键值对之间使用和号(&)分隔。这种传递参数的方式使得客户端(通常是浏览器)能够向服务器发送特定的请求,以获取或提交特定的数据。 比如https://www.csdn.net/?spm=1010.2135.3001.4476,?后面的参数就是。其中,spm是一个参数,它的值是1010.2135.3001.4476;这样,服务器就能够识别客户端的请求,并根据这些参数来执行相应的操作,比如执行搜索操作并过滤到编程相关的结果。
这里需要URL的四个特点:
-
键值对: URL参数是以键值对的形式存在的,一个键对应一个值。在上面的例子中,
q是键,python是值。 -
多个参数: URL可以包含多个参数,它们之间使用
&符号分隔。在上面的例子中,q=python和category=programming是两个不同的参数。 -
编码: 由于URL中不能包含一些特殊字符,参数的键和值通常需要进行URL编码。例如,空格可能被编码为
%20。 -
GET请求: URL参数通常与HTTP的GET请求一起使用。在GET请求中,参数会被附加到URL上,而在POST请求中,参数通常包含在请求体中。
URL参数在Web开发中被广泛使用,用于传递用户输入、筛选数据、进行搜索等各种场景。在服务端,开发人员可以通过解析URL参数来理解客户端请求的意图,并采取相应的操作。
2.GET
在浏览器与服务器之间的网络交互中,GET请求是最常用的请求类型之一,主要用于从服务器检索数据。GET主要有四种作用:
-
数据检索:GET请求的主要目的是请求服务器发送资源(如网页、图片、文件等)。它是一个“只读”请求,意味着它应该不对服务器上的数据产生任何影响。
-
简单和无副作用:GET请求被设计为安全和幂等的,这意味着重复执行相同的GET请求应该得到相同的结果,且不会对服务器的数据状态产生改变。
-
可被缓存:GET请求的结果往往可以被浏览器或服务器缓存以加速后续访问。
-
书签和分享:GET请求可以通过URL完整表达,这使得请求的资源可以通过链接共享或保存为书签。
形式
URL结构如 https://www.example.com/page,指定请求的服务器和资源路径。查询字符串:以?开始,后接一个或多个参数。每个参数由键值对组成,格式为key=value,多个参数之间用&分隔,如 ?query=search&sort=asc。
https://www.example.com/search?query=keyword&sort=ascending&page=1
上述GET请求中客户端请求服务器上的/search资源,并传递了三个参数:query(搜索关键字)、sort(排序方式)、page(页码)。
- GET请求还包括HTTP请求头部,其中可能包含浏览器类型、接受的响应格式、语言偏好等信息。
- 例如:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36。
一般用到GET的场景有:
- 检索数据:当需要从服务器获取数据时使用,如加载网页、图片、视频或任何其他类型的文件。
- 搜索查询:在搜索引擎中输入查询,提交的就是一个GET请求。
- 简单的表单提交:用于提交非敏感数据的表单,虽然不推荐(出于安全和数据长度限制的考虑)。
3.POST
它与GET请求相比,通常用于发送数据到服务器以便更新或创建资源。POST请求主要用于向服务器提交数据,通常不会被缓存。这些数据通常用于更新现有资源或创建新资源。由于POST请求将数据包含在请求体中,而不是URL中,因此它比GET请求更适合发送敏感或大量的数据。相同的POST请求如果被重复发送,可能会每次都产生不同的结果,例如在数据库中创建多个资源。
形式
请求体:
- 数据是在HTTP请求的主体中发送的,而不是在URL中。
- 数据可以采用多种格式,例如表单数据、JSON、XML等。
HTTP头部:
Content-Type头部指定了发送数据的格式,例如application/x-www-form-urlencoded(表单数据)、application/json(JSON格式)等。Content-Length头部显示数据的大小。
我们举个POST例子来看:
POST /submit-form HTTP/1.1
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
name=John&age=30&city=New York
客户端向/submit-form路径发送POST请求,请求体中包含了表单数据。
一般来说POST发送的场景有:
- 表单提交:在用户提交表单(尤其是包含敏感信息的表单,如登录凭证)时使用。
- 文件上传:在上传文件到服务器时使用。
- API交互:在与API进行交互,尤其是在创建或更新数据时使用。
POST请求因其安全性和非幂等性,被广泛用于敏感数据的传输和处理。
四.获取静态网页数据
1.requests库
Requests 是一个简单易用的 Python HTTP 库,用于发送网络请求。它是基于 urllib3 构建的,并提供了大量直观的功能来发送 HTTP/1.1 请求。它是 Python 社区中最受欢迎的 HTTP 客户端库之一。Requests主要特点有:
- 用户友好:Requests 的设计初衷是使 HTTP 请求更简单、更人性化。
- 内置功能丰富:支持从基本的 GET、POST 请求到复杂的 HTTP 功能如会话、cookie 管理等。
- 自动内容解码:自动解码来自服务器的响应。
- JSON 响应内容:内置的 JSON 解码器。
- 超时控制:轻松添加请求超时。
- 会话与 Cookie 管理:维持会话并管理 Cookies。
- SSL证书验证:可选的证书验证。
我们可以使用Requests去模拟每一次与服务端网络数据交互的过程,通过requests支持的常用函数就可以看出:
requests.get(url, params=None, **kwargs):发送一个 GET 请求到指定的 URL。requests.post(url, data=None, json=None, **kwargs):发送一个 POST 请求到指定的 URL。requests.put(url, data=None, **kwargs):发送一个 PUT 请求到指定的 URL。requests.delete(url, **kwargs):发送一个 DELETE 请求到指定的 URL。requests.head(url, **kwargs):发送一个 HEAD 请求到指定的 URL。requests.options(url, **kwargs):发送一个 OPTIONS 请求到指定的 URL。
大家可以通过跑一下我给出的demo:
import requests
r =requests.get('https://www.csdn.net/')
print("文本编码:",r.encoding)
print('响应状态码:',r.status_code)
print('字符串的方式的响应体:',r.text)但是有些网页需要对Requests的参数进行设置才能获取需要的数据,这里暂时不做展开,以后详细讲述request的时候再讲。接下来来尝试访问带有参数的url:
link = "https://blog.csdn.net/master_hunter"#定义link为目标网页地址
#定义请求头的浏览器代理,伪装成浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0'}
key_dict={'spm':'1000.2115.3001.5343'}
r = requests.get(link,headers = headers,params=key_dict)#请求网页
print('URL已经正确编码:',r.url)
print('字符串方式的响应体:\n',r.text) 可以得到: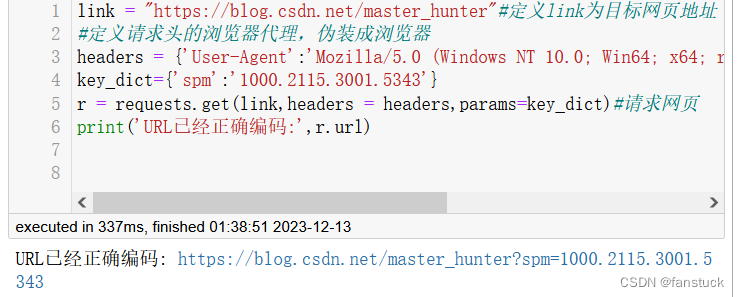
现在通过使用POST方法,客户端向服务器提交数据,我们便可以得到想要的内容:
import requests
link = "https://blog.csdn.net/master_hunter"#定义link为目标网页地址
#定义请求头的浏览器代理,伪装成浏览器
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0',
'Host':'eva2.csdn.net'
}
key_dict={'spm':'1000.2115.3001.5343'}
r=requests.post(link,headers = headers,params=key_dict)
print(r.text)大家可以自己运行一遍,这里就不作演示了。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。