作者:子苏 来源:投稿
编辑:学姐
Prompt综述论文:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing 论文作者知乎-近代自然语言处理技术发展的“第四范式”
NLP技术发展的四种范式
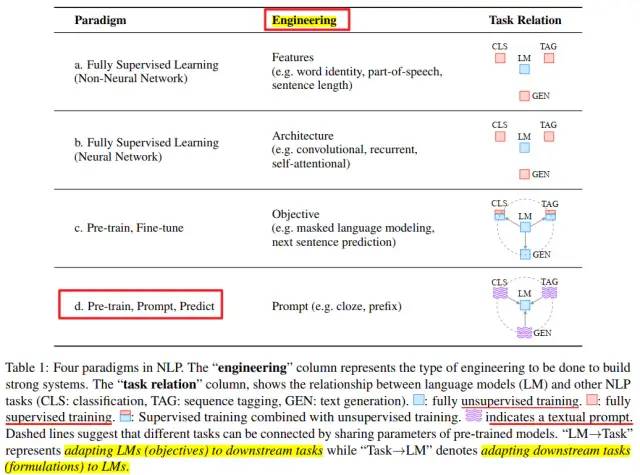
NLP发展的四种范式
范式a-b :不用手工配置模板,借助神经网络适当调参就能获得不错的结果。
范式b-c :比起排列组合各种网络结构却不一定能获得好的性能而言,探究将何种损失函数引入预训练语言模型从而更适配下游任务好像更简单。
范式c-d :随着预训练语言模型体量的不断增大,在下游任务上对其进行fine-tune的成本代价也不断上涨。因此研究学者们希望探索出更小巧轻量、普适高效的方法,Prompt就是沿着这个方向的一种尝试。在Fine-tune范式下,是预训练语言模型“迁就”各种下游任务,而在Prompt范式下,是下游任务“迁就”预训练语言模型,即通过对各种下游任务进行重构,使得它们更好地适配预训练语言模型,从而激发预训练语言模型的潜能。虽然Prompt的设计很繁琐,但它激活了很多新的研究场景,比如小样本学习。
Prompt起源
Prompt的起源可以追溯到GPT-2,T5,GPT-3等的一些研究,发现在输入样本前加入一个和任务相关的前缀,就可以提示模型接下来要输出的内容。比如在GPT-3的预测阶段,只需要在输入样本前加上Translate English to French: 就可以提示模型接下来要进行翻译任务,即完全依靠模型在预训练阶段学到的知识来进行预测,不需要在下游任务上再依靠task-specific的监督数据对模型进行fine-tune就可直接使用,一方面减少了fine-tune模型的计算和存储代价,另一方面也给样本量极度缺乏的少样本领域(zero/few-shot)带来了福音。
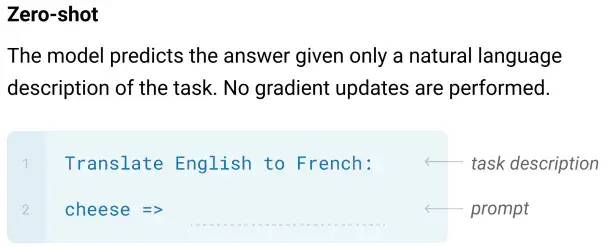
GPT-3
这种依靠提示信息(Prompt)来激发模型的内在潜能,挖掘模型在大规模预训练阶段学到的知识的做法引领了NLP领域的第四范式。人们逐渐开始思考如何更加高效地利用预训练语言模型的大量参数,如何将各种下游任务都统一到一个通用框架下,使得模型能够根据不同的提示信息进行不同的任务,从而不需要再为每个下游任务训练单独的模型。
论文发展
本文将对Prompt快速发展过程中一些重要论文的核心创新点进行简要介绍,而不会详细描述过多模型细节(欲知全貌建议直接读原论文)。
1.初立门派-PET(Pattern-Exploiting Training)
论文:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference (2020)
该论文对Prompt模式的研究进行了规范,提出了Pattern-Verbalizer的概念:
- Pattern(Prompt)函数P将输入样本x映射为完形填空的形式P(x)
- Verbalizer函数v将样本标签l映射为可填入完形填空的词v(l)
比如对于5分类任务,给定输入样本a,对应的模板函数P和标签映射函数v可为:

pattern-verbalizer
注意这里多种Prompt模板函数以及答案映射函数都是人工手动设计的。
然后利用新构建出来的P(x),v(l)对预训练模型进行fine-tune,其他更多细节不再展开,实验结果显示该方法在少样本任务上表现很好。
2.自证武功,以小博大-PET增强版
论文:It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners (PET原班人马)
GPT-3出来后显示了其在少样本学习上的惊人能力,但是其庞大的参数量也令人望而却步。而本文作者提出“小模型在少样本学习上也可以有卓越表现”,直接对标GPT-3这个庞然大物,从而奠定了PET所提范式在江湖的霸主地位,引起了各大武林人士的关注。
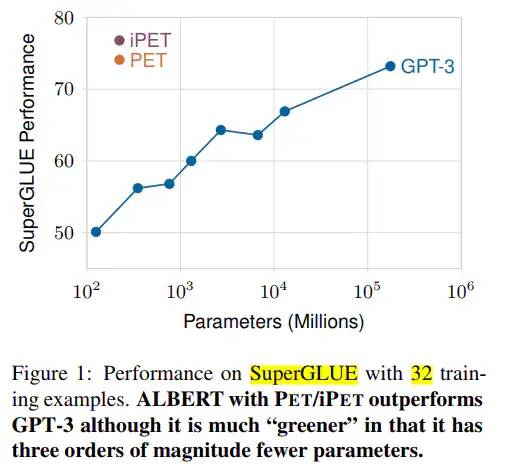
PET vs GPT-3
该文证明了PET所提范式的有效性,同时作者还分析发现设计不同的Prompt模板和标签映射函数Verbalizer对模型性能影响较大,从而引起后来人员涌入改进Prompt模板和标签映射Verbalizer构造的浪潮中。
3.百花齐放-自动构建Prompt
论文:Making Pre-trained Language Models Better Few-shot Learners
取代PET中手动构建Prompt模板和标签映射函数的过程,自动化搜索模板和标签映射,同时参考GPT-3中的in-context learning,在输入样本中加入示例(demonstrations)作为上下文,帮助模型更好地理解要做什么。

LM-BFF
实验表明,在少样本上,这种基于prompt的fine-tune效果能够明显好于标准的fine-tune,并且在样本中加入示例确实能够带来增益。
4.百花齐放-构建连续Prompt
也许未必非要构建人能理解的离散tokens式的Prompt,构建模型能够接受的连续向量式的Prompt也未尝不可。
4.1论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation
该文针对NLG(Natural Language Generation)任务,提出了构建连续的prompts。在预训练模型的每一层加上一个Prefix前缀矩阵,固定预训练模型的参数,仅训练前缀矩阵的参数,在few-shot设定下,性能超过标准的fine-tune。
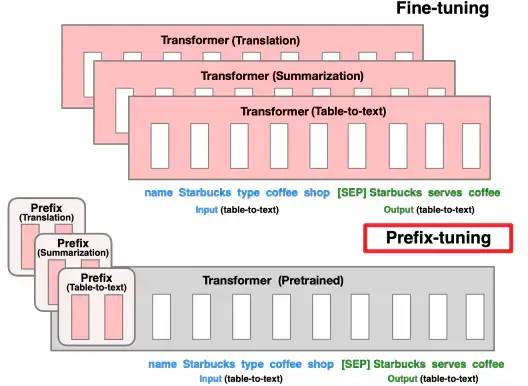
Prefix-tuning
实验结果表明,在全量数据下,prompt-based fine-tune的效果能够相当standard fine-tune;在少样本下,能够超过standard fine-tune。
4.2论文:GPT Understands, Too (P-tuning)
该文针对NLU(Natural Language Understanding)任务,也提出了构建连续的prompts。与Prefix-tuning不同的是,这里的prompts仅需要加在输入层,而不用加在网络的每一层,就可以work well。
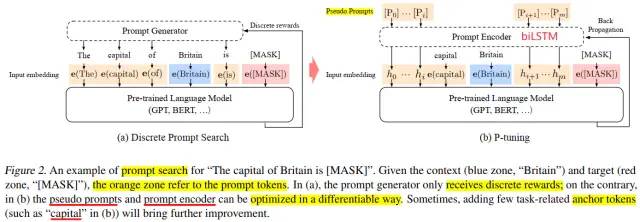
P-tuning
利用biLSTM对prompts进行Encode,然后将编码后的prompts embedding和样本x输入预训练语言模型(PLM),之后同时fine-tune prompt embeddings和pretrained model。
考虑到优化连续的prompt向量有两个问题:
- (1) 随机初始化prompts对应的权重向量hi,在优化过程中容易陷入局部最优
- (2) Prompt的tokens之间应该有一定的关联,而不是完全独立
因此作者提出先采用biLSTM作为Prompt Encoder来编码prompt向量。
具体Prompt模板设计为:
- [Prompt 1] X [Prompt 2] [MASK] for unidirectional models, e.g. GPT
- [Prompt 1] X [Prompt 2] [MASK] [Prompt 3] for bidirectional models, e.g. BERT 每个[Prompt]位置的tokens个数需要事先指定,X表示输入样本,[MASK] 表示预测目标。
实验结果表明,在全量数据下,prompt-based fine-tune的效果能够相当或超过standard fine-tune。
5.后起之秀-Prompt Tuning
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
该文提出为每个下游任务设计自己的prompt,拼接到输入样本上,然后完全freeze预训练模型的权重,仅训练prompts对应的权重参数。发现随着模型体积的增大,Prompt-tuning的效果逐渐追上标准fine-tune的效果。
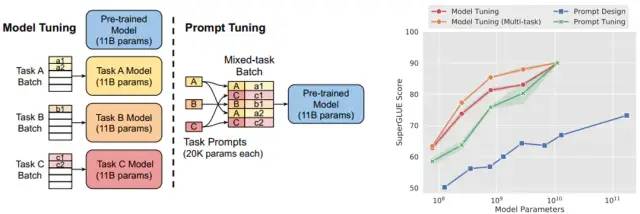
Prompt-tuning
这里Model Tuning就是指标准的fine-tune,即在下游任务上对预训练模型的参数进行更新。
总结
最后对各论文实验结果的普遍规律进行一个总结。各论文采用的fine-tune策略主要有以下三种:
- Standard Fine-tune:一般会在预训练模型的最后一层加上一个随机初始化的全连接层,引入new parameters
- Prompt-based Fine-tune:reuse预训练模型的权重参数,不引入new parameters
- Prompt Tuning:freeze预训练模型权重参数,仅训练引入的prompts的权重参数
Prompt-based Language Models:模版增强语言模型小结
2021年,Pre-train+finetune还是“新”范式吗?乘风破浪的Prompt-base methods Prompt范式第二阶段|Prefix-tuning、P-tuning、Prompt-tuning P-tuning: 自动构建模板,释放语言模型潜能 Prompt Pre-training:迈向更强大的Parameter-Efficient Prompt Tuning
论文解读+代码合集可点击卡片关注👇领取


![[Java]泛型](https://img-blog.csdnimg.cn/5c630826be8e44ad8db884e7e485696a.png)