目录
一、双向不循环链表的概念
二、链表的接口
三、链表的方法实现
(1)display方法
(2)size方法
(3)contains方法
(4)addFirst方法
(5)addLast方法
(6)addIndex方法
(7)remove方法
(8)removeAllKey方法
(9)clear方法
四、最终代码
一、双向不循环链表的概念
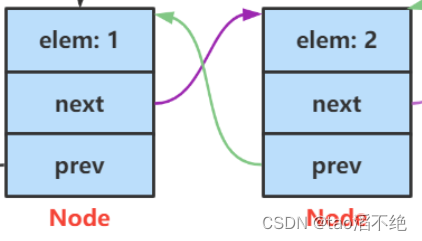
双向不循环链表中的节点有三个域,一个是存储数据的val域,一个是前驱prev域,还有一个是下个节点next域,和单向不同的就是多了一个前驱域。如图:
定义一个MyLinkedList类,这个类包含要模拟实现的方法,还有一个内部类ListNode,这个内部类就是链表的节点,代码如下:
public class MyLinkedList implements Ilist{
public ListNode head;//头结点
public ListNode last;//尾结点
static class ListNode {
int val;
ListNode next;
ListNode prev;
public ListNode(int val) {
this.val = val;
}
}
}二、链表的接口
代码如下:
public interface Ilist {
//头插法
void addFirst(int data);
//尾插法
void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
void addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
boolean contains(int key);
//删除第一次出现关键字为key的节点
void remove(int key);
//删除所有值为key的节点
void removeAllKey(int key);
//得到单链表的长度
int size();
void clear();
void display();
}三、链表的方法实现
(1)display方法
此方法是打印所有链表节点的val值,因此要遍历一遍链表的节点。代码如下:
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}(2)size方法
此方法计算链表中有多少个节点,所以也要遍历一遍链表,代码如下:
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}(3)contains方法
此方法查看是否有key值,有就返回true,没有就返回false,所以也要遍历一遍链表,代码如下:
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}(4)addFirst方法
此方法是头插方法,参数是链表的val域的值,所以调用此方法时,要创建一个节点,再把这个节点进行头插;头插时,要修改要插入节点的next域,指向原来的头结点,还有原来头结点的prev域,指向要插入的节点,最后再把头结点改为要插入的这个节点,如图:绿色箭头是修改指向
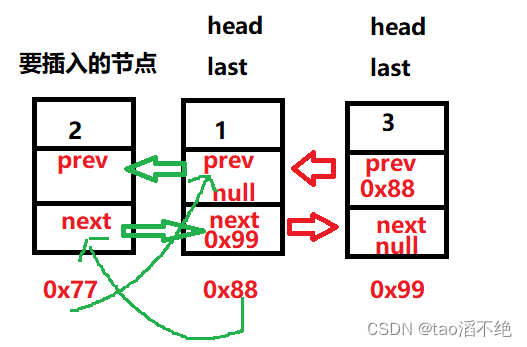 因为是新建的节点,所以这个节点的prev和next域都是null
因为是新建的节点,所以这个节点的prev和next域都是null
修改完后,如图:
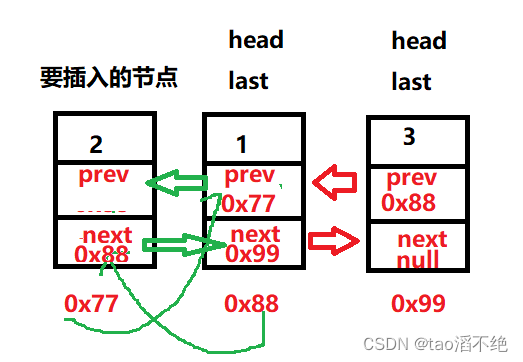
代码如下:
public void addFirst(int data) {
ListNode cur = new ListNode(data);
if(this.head == null) {
this.head = cur;
this.last = cur;
} else {
cur.next = this.head;
this.head.prev = cur;
this.head = cur;
}
}执行效果如下:

(5)addLast方法
此方法是尾插法,这里的尾插法时间复杂度是O(1),因为双向链表有一个记录尾结点的last,所以尾插的时候直接在尾结点插入要插入的节点,修改原来的尾结点的next域,要插入的节点prev修改成原来的尾结点,最后再把尾结点last修改成插入的节点,代码如下:
public void addLast(int data) {
ListNode cur = new ListNode(data);
if(last == null) {
head = cur;
last = cur;
} else {
last.next = cur;
cur.prev = last;
last = cur;
}
}
执行效果如下:
(6)addIndex方法
此方法是在指定位置插入节点,第一要检查要插入位置的index下标是否合法,不合法就抛异常,这里定义第一个节点下标为0,第二个节点下标为1,依次类推,如果要插入位置的下标是0,就是头插,如果要插入位置的下标是链表长度(size方法),就是尾插;
要插入的位置在链表中间,我们要找出指定位置的前一个节点,修改前一个节点的next域,修改成要插入的节点,还有指定位置原来的节点的prev域也要修改,修改成要插入的节点。代码如下:
public void addIndex(int index, int data) {
//检查下标是否合法
if(index < 0 || index > size()) {
throw new IndexException("下标不合法");
}
if(index == 0) {
addFirst(data);
return;
}
if (index == size()) {
addLast(data);
return;
}
ListNode cur = new ListNode(data);
ListNode prev = this.head;
int count = 0;
while (count < index - 1) {
prev = prev.next;
count++;
}
ListNode prevNext = prev.next;
prev.next = cur;
cur.prev = prev;
cur.next = prevNext;
prevNext.prev = cur;
}
//自定义异常类
public class IndexException extends RuntimeException{
public IndexException(String e) {
super(e);
}
}
执行效果如下:
(7)remove方法
此方法是移除第一个值为key的链表节点的方法,参数是就是key;要移除某一个节点,就要从头遍历一遍链表,如果没找到key值,就直接返回,不做任何操作;
这里要提前处理一些特殊情况,如果头结点的val值就是key,就要把head放在head的next域,然后判断这时候head是不是空,如果head不是空,head的prev就要修改成空,如果head是空,就要把last设为空,直接返回。
如果找到了,就要找要删除节点的前一个节点,这里会分两种情况,一种是要删除的节点后面没有节点了(尾结点),这时我们把要删除节点的前一个节点的next域改成null,last改成前一个节点;如果要删除的节点后面有节点,就要把前一个节点的next域改成要删除的节点的next,后一个的prev域改成前一个节点,代码如下:
public void remove(int key) {
if(head == null) {
return;
}
if(head.val == key) {
head = head.next;
if(head != null) {
head.prev = null;
} else {
last = null;
return;
}
}
ListNode prev = findPrev(key);
if(prev == null) {
//没有要删的元素
return;
}
ListNode cur = prev.next;
if(cur.next != null) {
prev.next = cur.next;
cur.next.prev = cur.prev;
} else {
//最后一个元素
prev.next = cur.next;//null
last = prev;
}
}
//找到要删除节点的前一个节点
private ListNode findPrev(int key) {
ListNode cur = this.head;
ListNode curNext = cur.next;
while (curNext != null) {
if(curNext.val != key) {
cur = cur.next;
curNext = curNext.next;
} else {
return cur;
}
}
return null;
}执行效果如下:

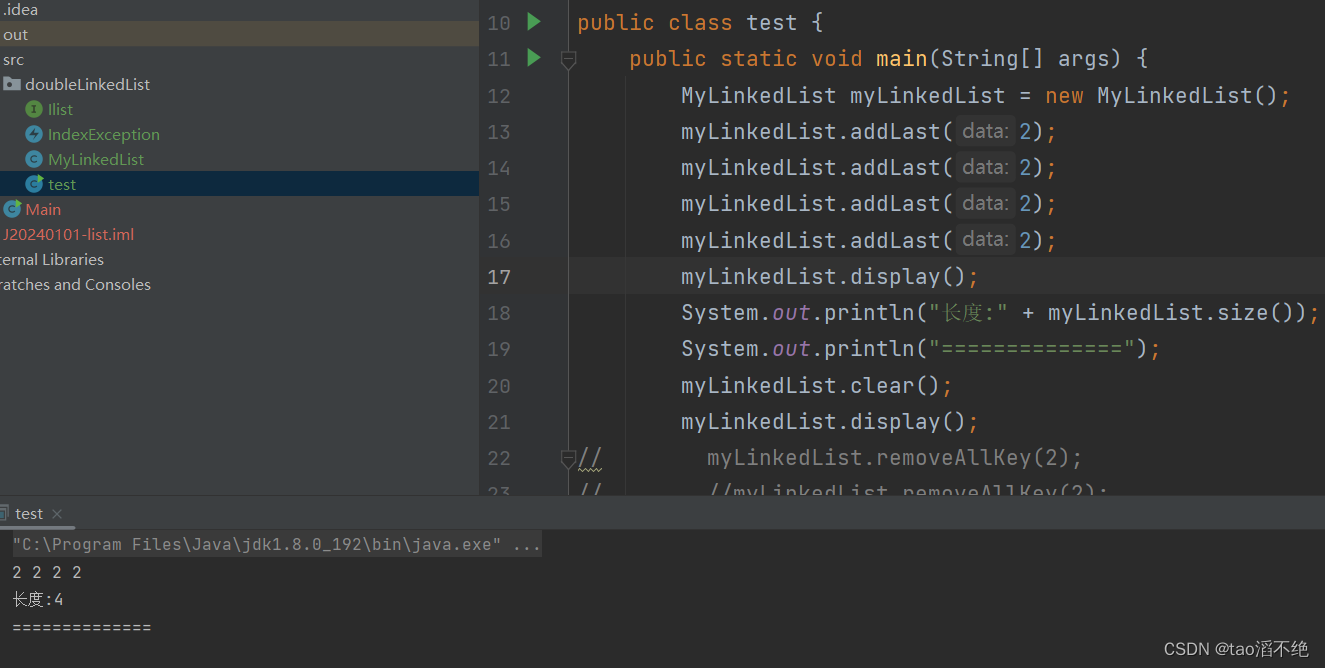
(8)removeAllKey方法
此方法是删除所有节点的val值为key的方法,所以,我们要遍历一遍链表,如果head为空的话,就直接返回,不做任何操作;
我们定义prev是头结点,cur是头结点的next节点(要删除的节点),从头到尾遍历的是cur,如果cur的val值不等于key,prev和cur都要往后走一步;如果cur的val值等于key,会分成两种情况,就是cur后面是有没有节点,如果后面有节点,prev节点的next域就要改成cur的next,cur的下一个节点的prev域要改成prev,然后cur往后走一步;如果cur后面的节点为空,就直接把prev节点的next域改成空,把last改成prev,cur还要往后走一步结束循环。
最后不要忘了头结点还没有判断,要判断头结点的val值是否和key相等,如果不相等就不做任何操作,相等就把头结点head改成头结点的next,此时的头结点的prev改成null,注意,这里修改头结点的prev,要头结点head不为空,才能执行上面的操作,不然会空指针异常。
public void removeAllKey(int key) {
if(head == null) {
return;
}
ListNode prev = this.head;
ListNode cur = this.head.next;
while (cur != null) {
if(cur.val == key) {
if(cur.next != null) {
prev.next = cur.next;
cur.next.prev = prev;
} else {
prev.next = cur.next;//null
last = prev;
}
cur = cur.next;
} else {
prev = prev.next;
cur = cur.next;
}
}
if(head.val == key) {
head = head.next;
if(head != null) {
head.prev = null;
}
}
}执行效果如下:

(9)clear方法
此方法是把链表中的所有节点中所有域都置为空,所以要遍历一遍链表,把节点prev和next域改为null,因为这里的val域类型是int,所以不用修改val域,代码如下:
public void clear() {
ListNode cur = this.head;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = null;
cur.prev = null;
cur = curNext;
}
head = null;
last = null;
}执行效果如下:
四、最终代码
public class MyLinkedList implements Ilist{
public ListNode head;//头结点
public ListNode last;//尾结点
static class ListNode {
int val;
ListNode next;
ListNode prev;
public ListNode(int val) {
this.val = val;
}
}
@Override
public void addFirst(int data) {
ListNode cur = new ListNode(data);
if(this.head == null) {
this.head = cur;
this.last = cur;
} else {
cur.next = this.head;
this.head.prev = cur;
this.head = cur;
}
}
@Override
public void addLast(int data) {
ListNode cur = new ListNode(data);
if(last == null) {
head = cur;
last = cur;
} else {
last.next = cur;
cur.prev = last;
last = cur;
}
}
@Override
public void addIndex(int index, int data) {
//检查下标是否合法
if(index < 0 || index > size()) {
throw new IndexException("下标不合法");
}
if(index == 0) {
addFirst(data);
return;
}
if (index == size()) {
addLast(data);
return;
}
ListNode cur = new ListNode(data);
ListNode prev = this.head;
int count = 0;
while (count < index - 1) {
prev = prev.next;
count++;
}
ListNode prevNext = prev.next;
prev.next = cur;
cur.prev = prev;
cur.next = prevNext;
prevNext.prev = cur;
}
@Override
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
@Override
public void remove(int key) {
if(head == null) {
return;
}
if(head.val == key) {
head = head.next;
if(head != null) {
head.prev = null;
} else {
last = null;
return;
}
}
ListNode prev = findPrev(key);
if(prev == null) {
//没有要删的元素
return;
}
ListNode cur = prev.next;
if(cur.next != null) {
prev.next = cur.next;
cur.next.prev = cur.prev;
} else {
//最后一个元素
prev.next = cur.next;//null
last = prev;
}
}
private ListNode findPrev(int key) {
ListNode cur = this.head;
ListNode curNext = cur.next;
while (curNext != null) {
if(curNext.val != key) {
cur = cur.next;
curNext = curNext.next;
} else {
return cur;
}
}
return null;
}
@Override
public void removeAllKey(int key) {
if(head == null) {
return;
}
ListNode prev = this.head;
ListNode cur = this.head.next;
while (cur != null) {
if(cur.val == key) {
if(cur.next != null) {
prev.next = cur.next;
cur.next.prev = prev;
} else {
prev.next = cur.next;//null
last = prev;
}
cur = cur.next;
} else {
prev = prev.next;
cur = cur.next;
}
}
if(head.val == key) {
head = head.next;
if(head != null) {
head.prev = null;
}
}
}
@Override
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
@Override
public void clear() {
ListNode cur = this.head;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = null;
cur.prev = null;
cur = curNext;
}
head = null;
last = null;
}
@Override
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
}
//自定义异常类
public class IndexException extends RuntimeException{
public IndexException(String e) {
super(e);
}
}


![[Redis实战]分布式锁](https://img-blog.csdnimg.cn/direct/c9a2ed94483143cb83a26cc9d9294c68.png)



![[SSD 测试 1.3] 消费级SSD全生命周期测试](https://img-blog.csdnimg.cn/direct/88279155b5c246dcad9ce33710bf1452.png)