一、分页查询优化
1. SQL语句准备
CREATE TABLE `employees` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 24 ) NOT NULL DEFAULT '' COMMENT '姓名',
`age` INT ( 11 ) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` VARCHAR ( 20 ) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY ( `id` ),
KEY `idx_name_age_position` ( `name`, `age`, `position` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 COMMENT = '员工记录表';
DROP PROCEDURE
IF
EXISTS insert_emp;
delimiter;
CREATE PROCEDURE insert_emp () BEGIN
DECLARE
i INT;
SET i = 1;
WHILE
( i <= 100000 ) DO
INSERT INTO employees ( NAME, age, position )
VALUES
( CONCAT( 'zhuge', i ), i, 'dev' );
SET i = i + 1;
END WHILE;
END;;
delimiter;
CALL insert_emp ();很多时候我们业务系统实现分页功能可能会用如下sql实现
select * from employees limit 10000,10;表示从表 employees 中取出从 10001 行开始的 10 行记录。看似只查询了 10 条记录,实际这条 SQL 是先读取 10010 条记录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据。因此要查询一张大表比较靠后的数据,执行效率 是非常低的。
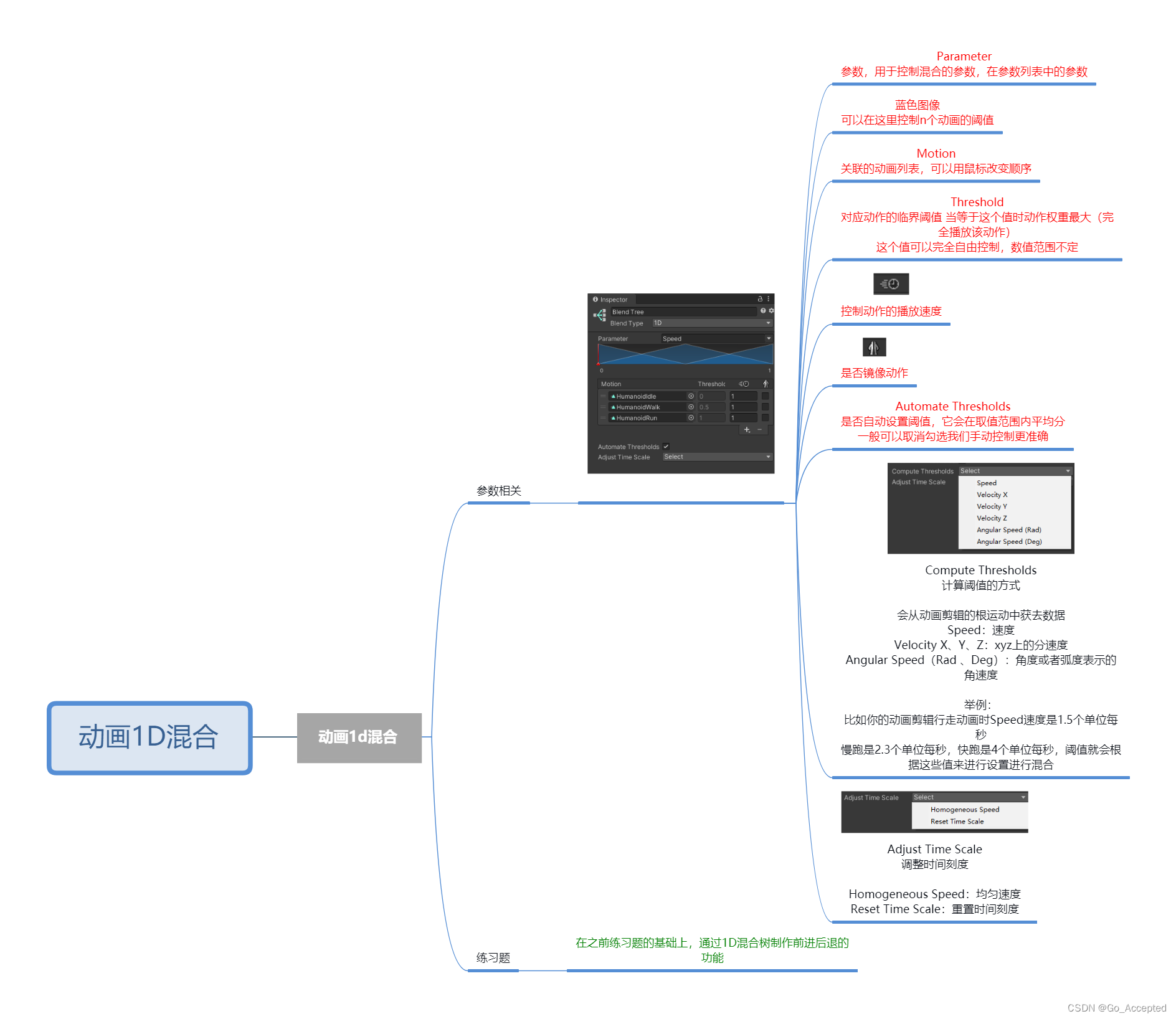
2. 常见的分页查询优化技巧
1)根据自增且连续的主键排序的分页查询
首先来看一个根据自增且连续主键排列的分页查询的例子
select * from employees limit 90000,5;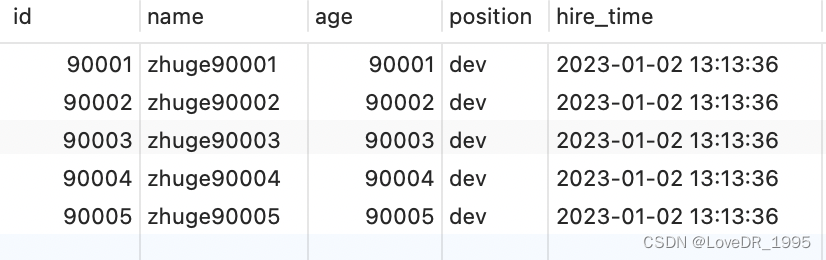
该 SQL 表示查询从第 90001开始的五行数据,没添加单独 order by,表示通过主键排序。我们再看表 employees ,因为主键是自增并且连续的,所以可以改写成按照主键去查询从第 90001开始的五行数据,如下:
select * from employees where id > 90000 limit 5;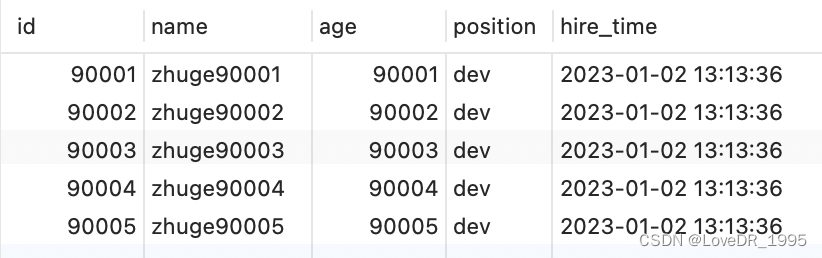 查询结果是一样的,我们再对比下执行计划。
查询结果是一样的,我们再对比下执行计划。
EXPLAIN select * from employees limit 90000,5;
EXPLAIN select * from employees where id > 90000 limit 5; 显然改写后的 SQL 走了索引,而且扫描的行数大大减少,执行效率更高。但是这条改写的SQL在很多场景并不实用,因为表中可能某些记录被删后,主键空缺导致结果不一致,如下图试验 所示(先删除一条前面的记录,这里我们直接删除第一条记录然后再测试原 SQL 和优化后的 SQL):
显然改写后的 SQL 走了索引,而且扫描的行数大大减少,执行效率更高。但是这条改写的SQL在很多场景并不实用,因为表中可能某些记录被删后,主键空缺导致结果不一致,如下图试验 所示(先删除一条前面的记录,这里我们直接删除第一条记录然后再测试原 SQL 和优化后的 SQL):
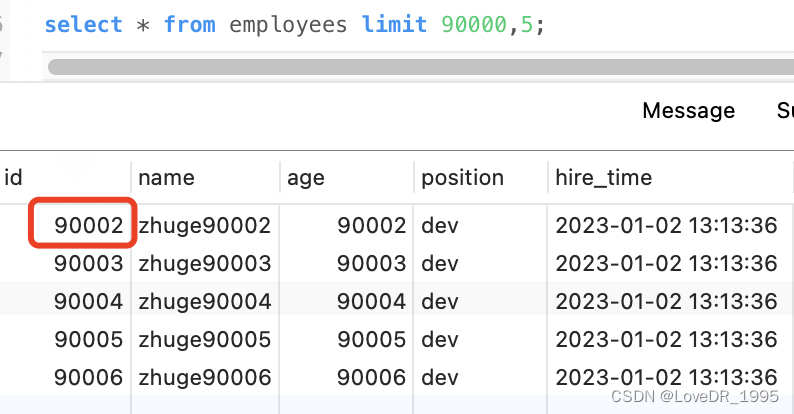
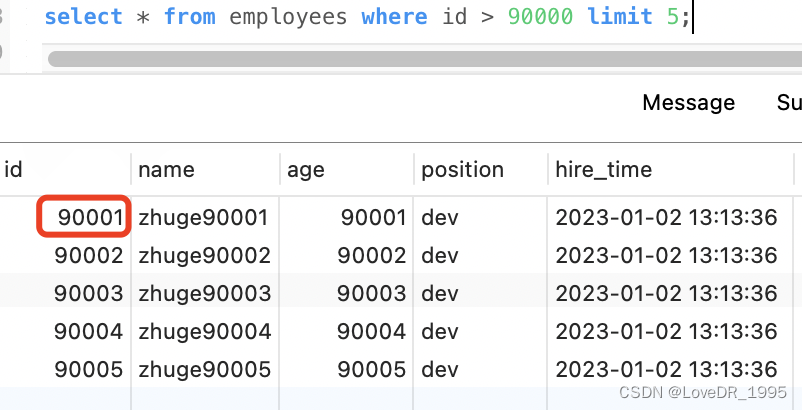
两条 SQL 的结果并不一样,因此,如果主键不连续,不能使用上面描述的优化方法。另外如果原 SQL 是 order by 非主键的字段,按照上面说的方法改写会导致两条 SQL 的结果不一致。所以这种改写得满 足以下两个条件:
- 主键自增且连续
- 结果是按照主键排序的
2)根据非主键字段排序的分页查询
再看一个根据非主键字段排序的分页查询,SQL如下:
select * from employees ORDER BY name limit 90000,5;
EXPLAIN select * from employees ORDER BY name limit 90000,5; 发现并没有使用 name 字段的索引(key 字段对应的值为 null),具体原因上节课讲过:扫描整个索引并查找到没索引 的行(可能要遍历多个索引树)的成本比扫描全表的成本更高,所以优化器放弃使用索引。 知道不走索引的原因,那么怎么优化呢?其实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录,SQL 改写如下
发现并没有使用 name 字段的索引(key 字段对应的值为 null),具体原因上节课讲过:扫描整个索引并查找到没索引 的行(可能要遍历多个索引树)的成本比扫描全表的成本更高,所以优化器放弃使用索引。 知道不走索引的原因,那么怎么优化呢?其实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录,SQL 改写如下
SELECT * FROM employees e INNER JOIN
(SELECT id FROM employees ORDER BY NAME LIMIT 90000,5) ed ON e.id=ed.id;
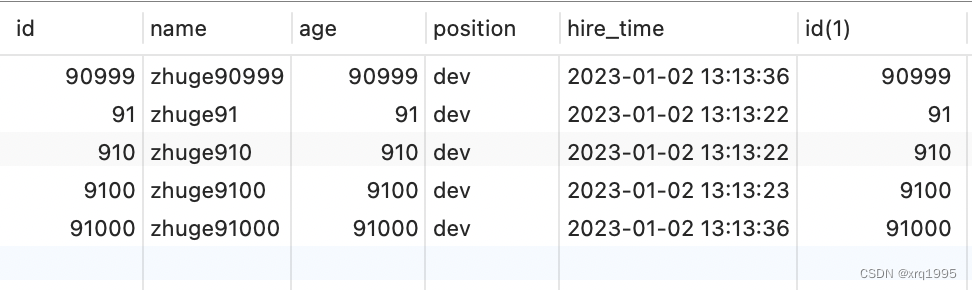 需要的结果与原 SQL 一致,执行时间减少了一半以上,我们再对比优化前后sql的执行计划:
需要的结果与原 SQL 一致,执行时间减少了一半以上,我们再对比优化前后sql的执行计划:

二、join关联查询优化
1. SQL语句准备
CREATE TABLE `t1` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`a` INT ( 11 ) DEFAULT NULL,
`b` INT ( 11 ) DEFAULT NULL,
PRIMARY KEY ( `id` ),
KEY `idx_a` ( `a` )
) ENGINE = INNODB AUTO_INCREMENT = 10001 DEFAULT CHARSET = utf8;
CREATE TABLE t2 LIKE t1;2. MySQL的表关联常见有两种算法
- Nested-Loop Join 算法
- Block Nested-Loop Join 算法
1)嵌套循环连接 Nested-Loop Join(NLJ) 算法
一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。
EXPLAIN select*from t1 inner join t2 on t1.a= t2.a;
从执行计划中可以看到这些信息:驱动表是 t2,被驱动表是 t1。先执行的就是驱动表(执行计划结果的id如果一样则按从上到下顺序执行sql);优 化器一般会优先选择小表做驱动表。所以使用 inner join 时,排在前面的表并不一定就是驱动表。 使用了 NLJ算法。一般 join 语句中,如果执行计划 Extra 中未出现 Using join buffer 则表示使用的 join 算法是 NLJ。
2)基于块的嵌套循环连接Block Nested-Loop Join(BNL)算法
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;
select * from A where id in (select id from B)
#等价于:
for(select id from B){ select * from A where A.id = B.id } select * from A where exists (select 1 from B where B.id = A.id)
#等价于:
for(select * from A){ select * from B where B.id = A.id }
#A表与B表的ID字段应建立索引3) count(*)查询优化