hadoop 集群搭建
- 更改主机名
- 映射
- 设置免密
- 同步时间
- 创建工作目录
- 下载jdk
- 安装配置Hadoop
- 修改配置文件
- 向其他节点分发配置完成的程序
- 为Hadoop添加环境变量
- 启动集群
- 初始化
- 启动集群
- web页面
- web页面:[hdfsweb页面](http://192.168.88.128:9870/)
- web页面:[yarnweb页面](http://192.168.88.128:8088/)

更改主机名
三台虚拟机都要更改
# 在node1的节点输入
hostnamectl set-hostname node1.itcast.cn
# 在node2的节点输入
hostnamectl set-hostname node2.itcast.cn
# 在node2的节点输入
hostnamectl set-hostname node3.itcast.cn
映射
在每个节点都要操作
vi /etc/hosts # 进入文件
# 在文件最后面添加以下内容
192.168.195.129 node1 node1.itcast.cn
192.168.195.130 node2 node1.itcast.cn
192.168.195.132 node3 node1.itcast.cn
设置免密
在node1上操作做
# 生成公钥(一直回车确认就可以)
ssh-keygen
# 将免密配置到各个节点
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
同步时间
每个节点都要操作
# 下载时间同步工具
yum install utpdate
# 同步时间
ntpdate ntp5.aliyun.com
创建工作目录
每个节点都要创建
# 创建数据存储,下载以及安装目录
mkdir -p /export /data
mkdir -p /export /server
mkdir -p /export /software
下载jdk
将Java压缩包jdk-8u351-linux-x64.tar.gz上传到Linux系统中的/export/server目录中(可以通过xftp我个人认为比较稳定)
# 上传成功后进行解压
tar -zxvf jdk-8u351-linux-x64.tar.gz
# 配置Java的环境变量
vi /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 重新加载环境变量
source /etc/proflie
安装配置Hadoop
将Hadoop安装文件上传到/export/server目录中
# 对压缩包进行解压
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
修改配置文件
进入Hadoop配置文件目录(/export/server/hadoop-3.3.0/etc/hadoop)并且修改以配置文件
配置hadoop-env.sh文件
export JAVA_HOME=/export/server/jdk1.8.0_351
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置core-site.xml文件
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
配置hdfs-site.xml文件
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
配置mapred-site.xml文件
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
配置yarn-site.xml文件
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置workers
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
向其他节点分发配置完成的程序
# 进入安装路径
cd /export/server
# 向node2发送配置程序
scp -r hadoop-3.3.0 root@node2:$PWD
# 向node3发送配置程序
scp -r hadoop-3.3.0 root@node3:$PWD
为Hadoop添加环境变量
# 打开环境变量文件
vim /etc/profile
#在文件最后面添加
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载环境变量
source /etc/profile
# scp给其他节点
scp /etc/profile node2:/etc/profile
scp /etc/profile node3:/etc/profile
可以在每个节点中输入Hadoop来验证时候配置成功
启动集群
初始化
不要多次执行,不然可能会启动失败,或数据丢失
hdfs namenode -format
启动集群
# 启动hdfs集群
start-dfs.sh
# 启动yarn集群
start-yarn.sh
web页面
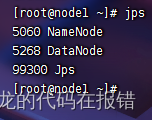
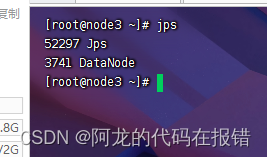
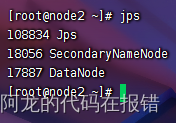
使用jps查询各个节点的进程结果如下即为启动成功
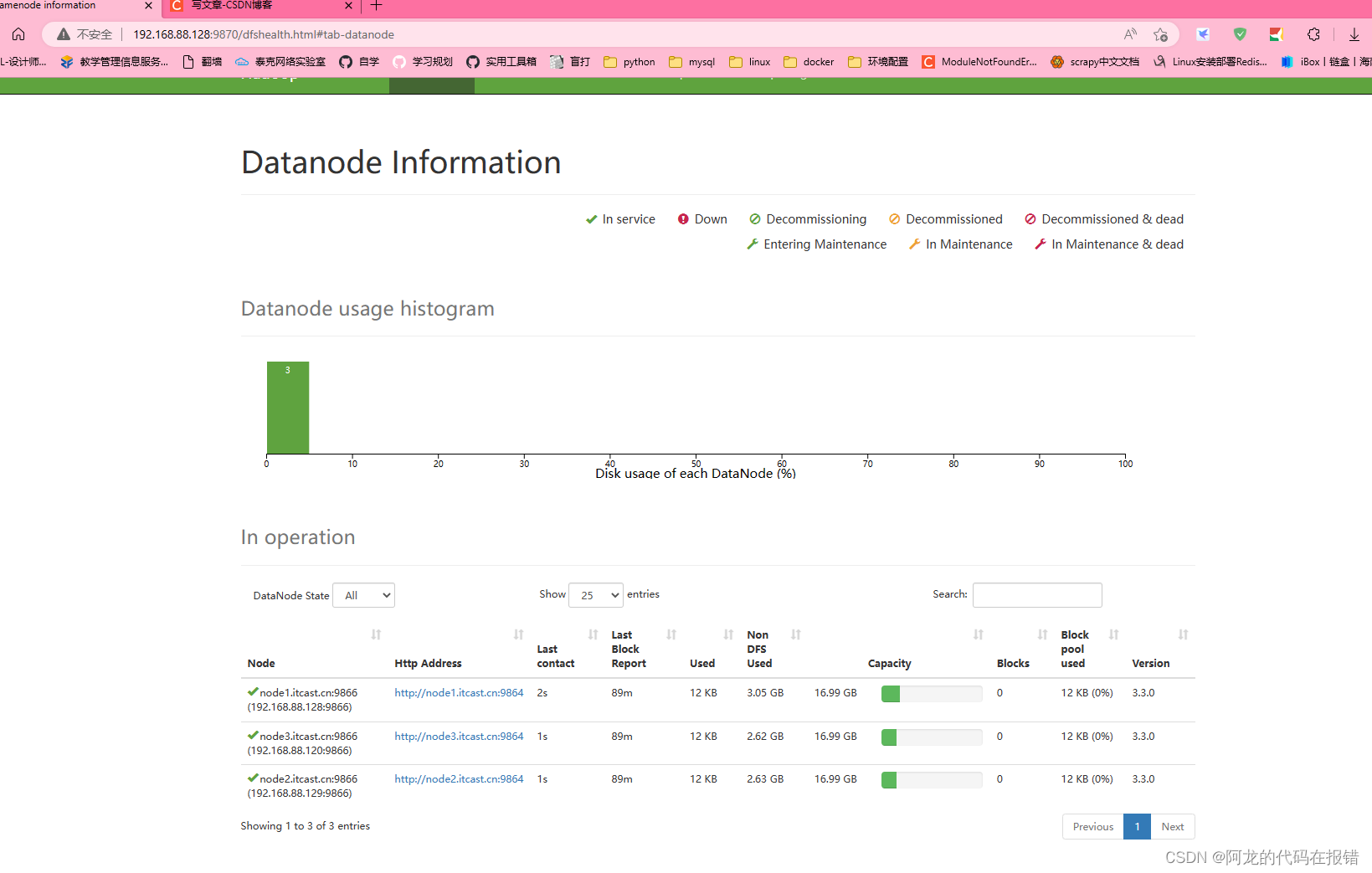
web页面:hdfsweb页面
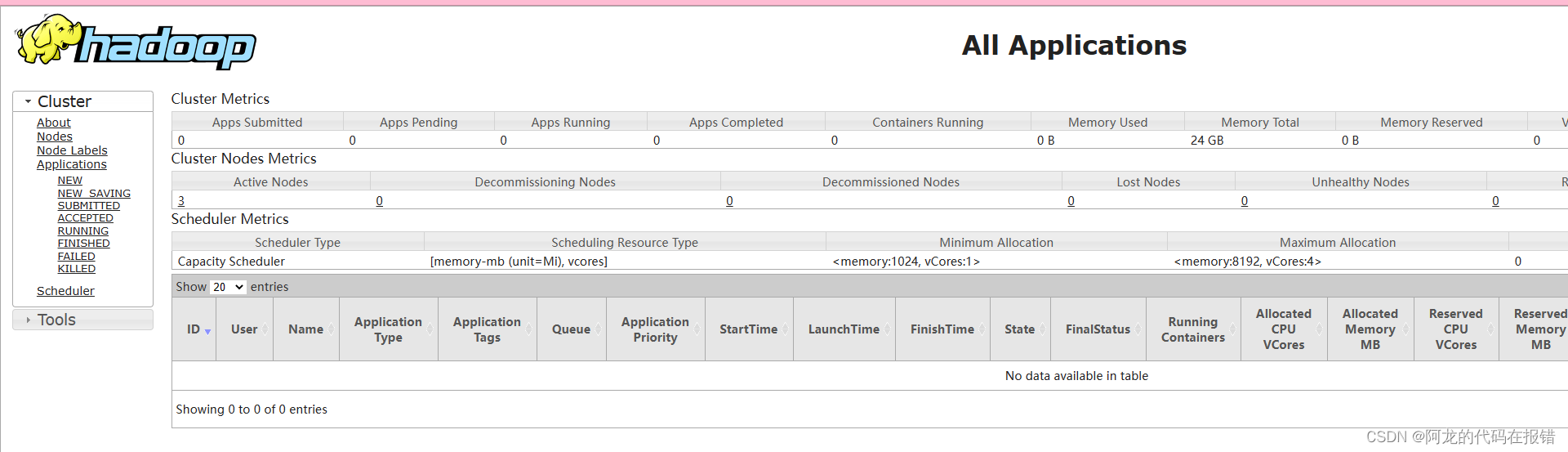
web页面:yarnweb页面
如果还有不理解的或不成功的欢迎下面评论,我把每一步的执行截图补上
愿君前程似锦,未来可期去💯,感谢您的阅读,如果对您有用希望您留下宝贵的点赞和收藏
本文章为本人学习笔记,学习网站为黑马程序员的Hadoop可以一起学习共同进步谢谢,如有请侵权联系,本人会立即删除侵权文章。