RAG结合了两个关键元素:检索和生成。它首先使用语义搜索等高级技术来浏览大量数据,包括文本、图像、音频和视频。RAG的本质在于它能够检索相关信息,然后作为下一阶段的基础。生成组件利用大型语言模型的能力,解释这些数据块,制作连贯的、类似人类的响应。与传统的生成模型相比,这个过程确保RAG系统可以提供更细致和准确的输出。

“Lost in the Middle”
在RAG中“LIM”问题相当具有挑战性。斯坦福大学和加州大学伯克利分校等大学的研究强调了这一问题,这与人们经常记住购物清单上的第一个和最后一个项目,但忘记中间的项目类似。语言模型人一样很擅长识别他们正在分析的文本的开头或结尾的信息,但他们往往会忽略中心的关键细节。
为了解决这个问题,我们一般都是用下面的方法:
1、避免使用单一知识库,对不同类型的文档只使用一个知识库可能会混淆检索模型。他们可能很难根据主题或上下文找到正确的信息。
2、使用多个矢量存储,为不同类型的文档创建单独的数据存储区域(称为矢量存储)。这有助于更有效地组织信息。
3、使用一个称为Merge retriver的工具合并来自这些不同VectorStores的数据。这有助于汇集来自不同来源的相关信息。
4、使用长上下文重新排序(LOTR)重新排序,这确保了模型对文本中间的数据给予同等的关注,而不仅仅是在开头或结尾。
通过使用上面这些技术,可以确保数据的所有部分(包括中间部分)都得到了适当的检索并用于生成响应。这些步骤有助于改进RAG系统的性能,使它们更有效地处理和解释大量不同的信息源。
LOTR(合并检索器)
本文主要介绍LOTR
LOTR: Lord of the retrivers,也称为mergerretriver,它将检索器列表作为输入,并将它们的get_relevance _documents()方法的结果合并到单个列表中。合并的结果将是与查询相关的文档列表,这些文档是被不同的检索器排序过的。
MergerRetriever类可以通过几种方式用于提高文档检索的准确性:它结合多个检索器的结果,这有助于减少结果偏差的风险。并且可以对不同检索器的结果进行排序,这有助于确保首先返回最相关的文档。

我们将以医疗/医疗保健相关的RAG为例构建回答一些保健被问题的聊天机器人。
代码
安装使用的包:
pip -q install langchain lancedb pypdf sentence-transformers openai tiktoken
在python中导入所需的包
from langchain.embeddings import HuggingFaceEmbeddings, OpenAIEmbeddings,HuggingFaceBgeEmbeddings
from langchain.document_transformers import (
EmbeddingsClusteringFilter,
EmbeddingsRedundantFilter,
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.retrievers.merger_retriever import MergerRetriever
from langchain.schema import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.vectorstores import LanceDB
import lancedb
这里我们使用openai的模型所以需要设置apikey
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxx"
对于嵌入模型,我们有3种选择
1、Huggingface BGE嵌入,这是在MTEB排行榜上排名前面的模型。
2、NeuML/pubmedbert-base-embeddings 这个模型专注于医疗相关数据。
3、Openai embedding mode 最后可以使用Openai嵌入模型来移除相同的嵌入,这个作为后续改进,本文暂不不讨论
#embedding models
medical_health_embedding = SentenceTransformerEmbeddings(
model_name="NeuML/pubmedbert-base-embeddings")
hf_bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-en",
model_kwargs={"device":"cpu"},
encode_kwargs = {'normalize_embeddings': False})
filter_embeddings = OpenAIEmbeddings()
加载文档文件
loader = PyPDFLoader("/content/AyurvedicHomeRemedies.pdf")
# pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)
text = text_splitter.split_documents(loader)
将两个不同的嵌入模型实例化,并生成两个不同的索引
# embedding 1 model - NeuML/pubmedbert-base-embeddings
db = lancedb.connect('/tmp/lancedb')
table = db.create_table("health embedding", data=[
{"vector": medical_health_embedding.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
# Initialize LanceDB retriever
db_all = LanceDB.from_documents(text, medical_health_embedding, connection=table)
## embeding 2 model -
db_multi = lancedb.connect('/tmp/lancedb')
table = db_multi.create_table("bge embedding", data=[
{"vector": hf_bge_embeddings.embed_query("Hello World"), "text": "Hello World", "id": "1"}
], mode="overwrite")
# Initialize LanceDB retriever
db_multiqa = LanceDB.from_documents(text, hf_bge_embeddings, connection=table)
保存两个retriever的输出,供后续代码调用
retriever_med = db_all.as_retriever(search_type="similarity",
search_kwargs={"k": 5, "include_metadata": True}
)
retriever_bge = db_multiqa.as_retriever(search_type="similarity",
search_kwargs={"k": 5, "include_metadata": True})
MergerRetriever(通常称为LOTR)通过以顺序的、循环的方式组合来自各种检索源的结果。它首先收集由每个检索器标识的相关文档,然后将这些文档合并到一个单一的内聚列表中。该列表显示与特定查询相关的文档并根据不同检索器确定的相关性对其进行排序。
为了提高合并列表的效率并避免重复,EmbeddingsRedundantFilter可以与附加的嵌入模型一起使用。这有助于从组合检索器中过滤掉任何重叠或重复的结果。还可以将文档分组到主题簇或相关内容的“中心”,从这些簇中选择与每个簇的中心主题最接近的文档进行最终结果。EmbeddingsClusteringFilter优化了这个聚类和选择过程,确保了结果集更有组织、更集中。
lotr = MergerRetriever(retrievers=[retriever_med, retriever_bge])
for chunks in lotr.get_relevant_documents("What is use of tulsi ?"):
print(chunks.page_content)

合并的检索器中删除冗余结果。
filter = EmbeddingsRedundantFilter(embeddings=filter_embeddings)
无论模型的体系结构是什么,当包含10个以上的检索文档时,都会有很大的性能下降。也就是说,当模型必须在长上下文中访问相关信息时,它们倾向于忽略所提供的文档。
from re import search
from langchain.document_transformers import LongContextReorder
reordering = LongContextReorder()
pipeline = DocumentCompressorPipeline(transformers=[filter, reordering])
compression_retriever_reordered = ContextualCompressionRetriever(
base_compressor=pipeline, base_retriever=lotr,search_kwargs={"k": 5, "include_metadata": True}
)
docs = compression_retriever_reordered.get_relevant_documents("What is use of tulsi ?")
print(len(docs))
print(docs[0].page_content)
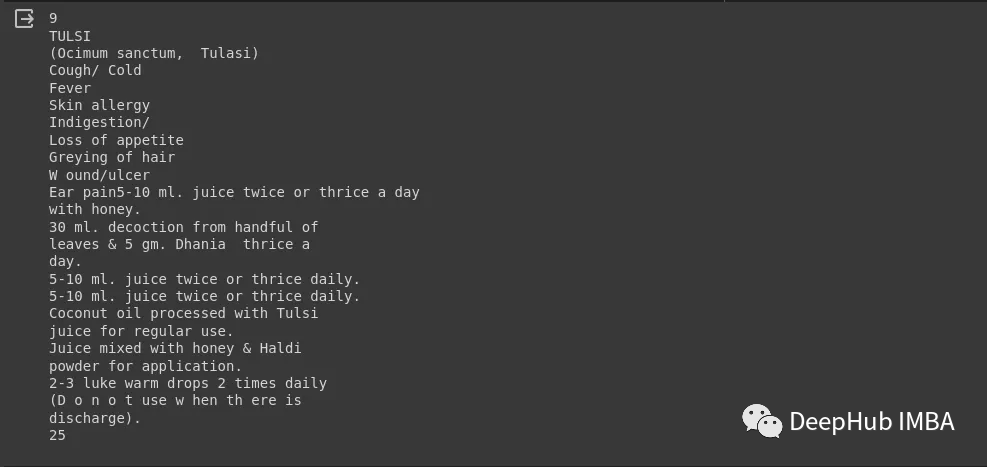
以上文档已经处理完毕了,我们开始加载LLM模型
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(openai_api_key="sk-openaiapikey")
#check our blog for using different llms https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/chatbot_using_Llama2_&_lanceDB
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever = compression_retriever_reordered,
return_source_documents = True
)
测试结果如下:
query ="What is use of tulsi?"
results = qa(query)
print(results['result'])
print(results["source_documents"])
## results
For high fever and cough, you can try the following home remedies:
1. Take 1-2 grams of Pippali (Piper longum) powder with honey twice daily.
2. Drink a warm decoction prepared from 20 ml of water and 1 gram of Laung (clove) 3-4 times daily. This can help with both dry and productive cough.
3. Take 2 grams of Elaichi (cardamom) powder with honey 2-3 times a day.
4. Drink plenty of warm fluids like herbal teas, soups, and warm water to stay hydrated and soothe the throat.
5. Gargle with warm salt water to alleviate throat discomfort.
6. Rest and get plenty of sleep to support your immune system.
Remember, these remedies are for mild conditions. If your symptoms persist or worsen, it is important to consult a doctor for proper diagnosis and treatment.
通过这种方法可以使RAG获得更好的性能
总结
为了解决LIM问题并提高检索性能,对RAG系统进行增强是非常重要的。通过设置不同的VectorStores并将它们与Merge retriver结合,以及使用LongContextReorder重新排列结果,可以减少LIM问题并使检索过程更高效。此外,在合并检索器中合并特定领域的嵌入也有着关键作用。这些步骤对于确保我们不会在检索文件的过程中遗漏重要细节至关重要。
Lost in the Middle: How Language Models Use Long Contexts 论文
https://arxiv.org/abs//2307.03172
langchain的merger_retriever实现代码:
https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/retrievers/merger_retriever.py
本文完整代码:
https://avoid.overfit.cn/post/d252399e19e5409abf9990591523c11f
作者:Akash A Desai