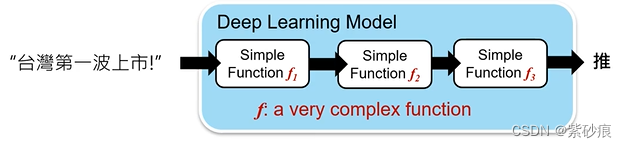
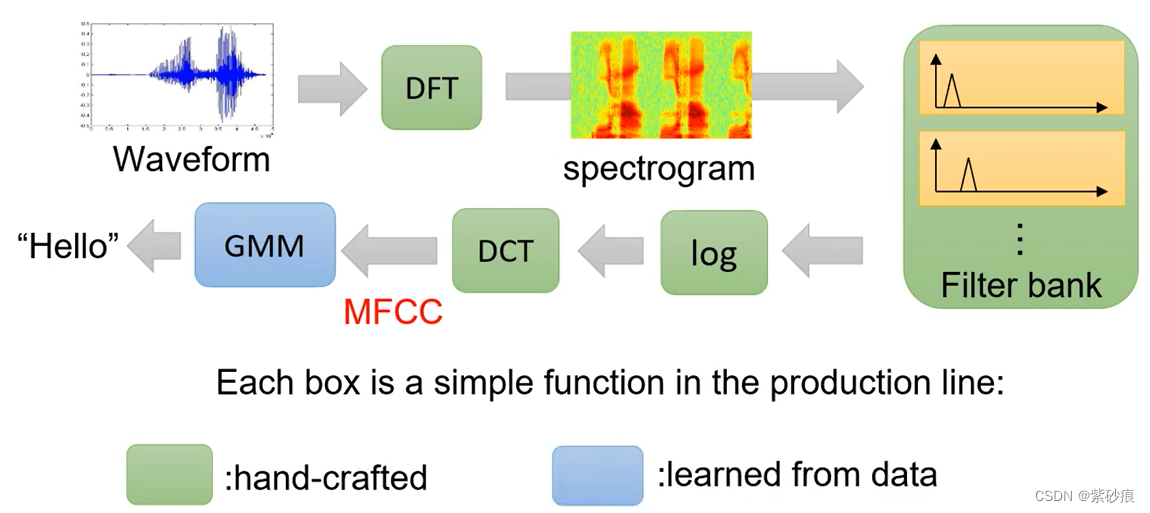
deep learning
- end-to-end training
1. 神经元
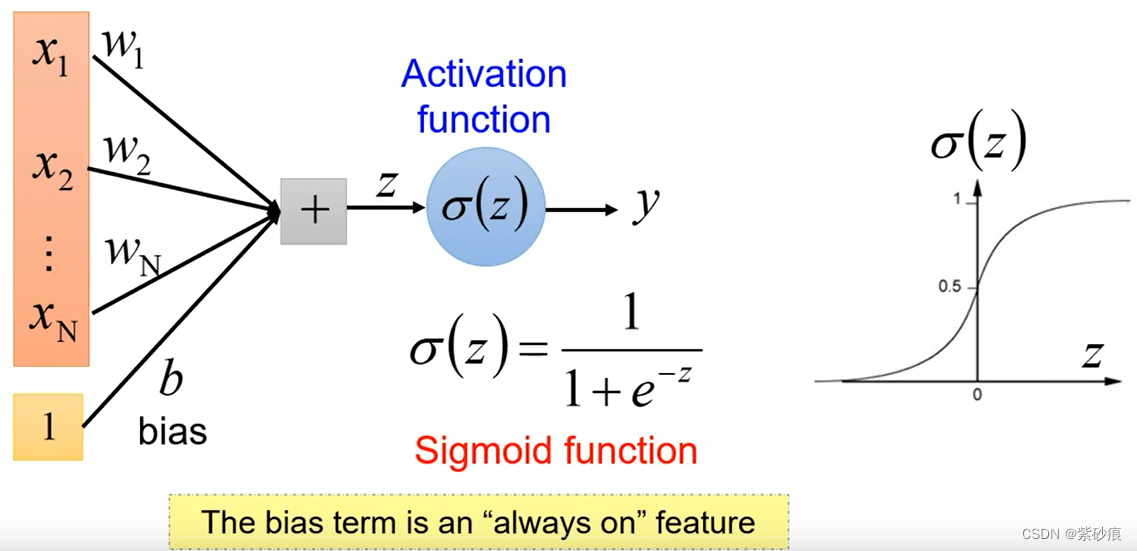
1.1 为什么需要bias?
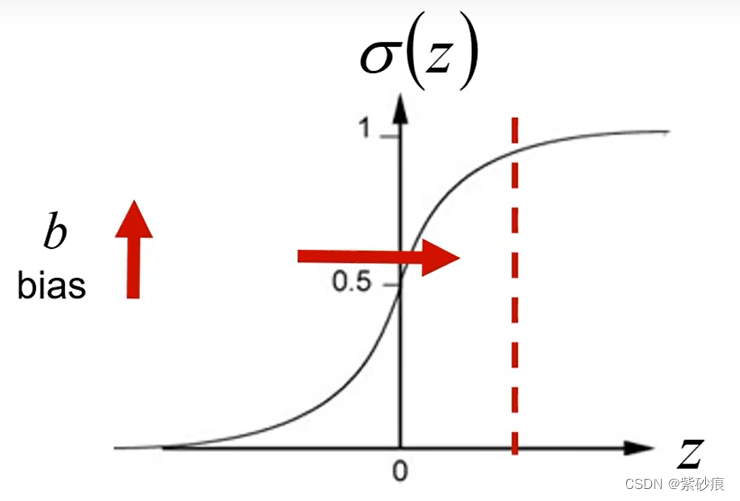
为了给对应位置一个prior,给它一个初始值,b越大, σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1越大,越趋向于1.
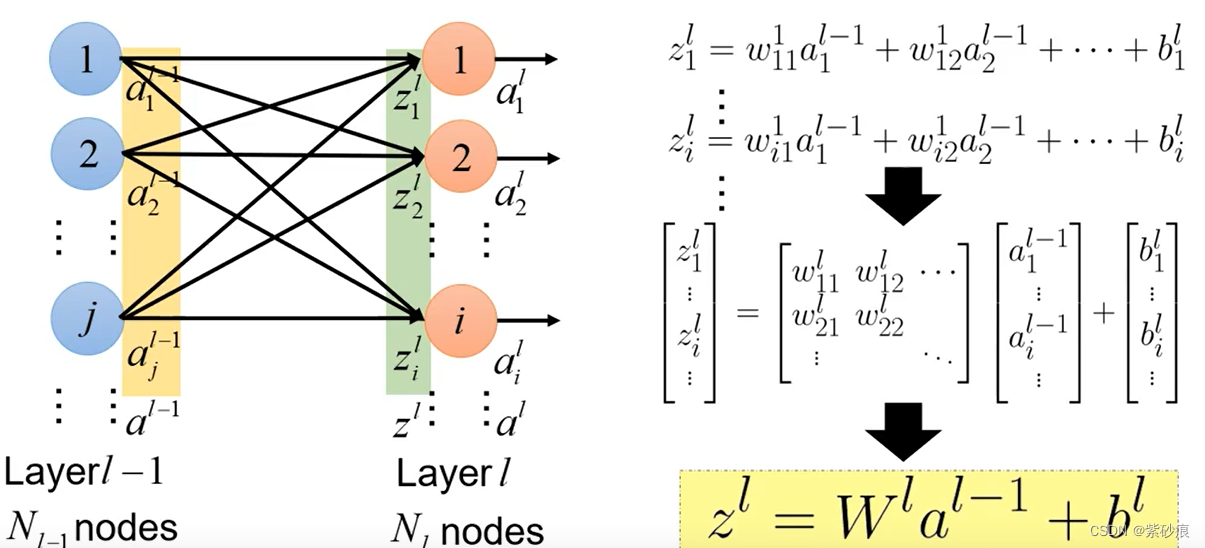
多层神经网络:
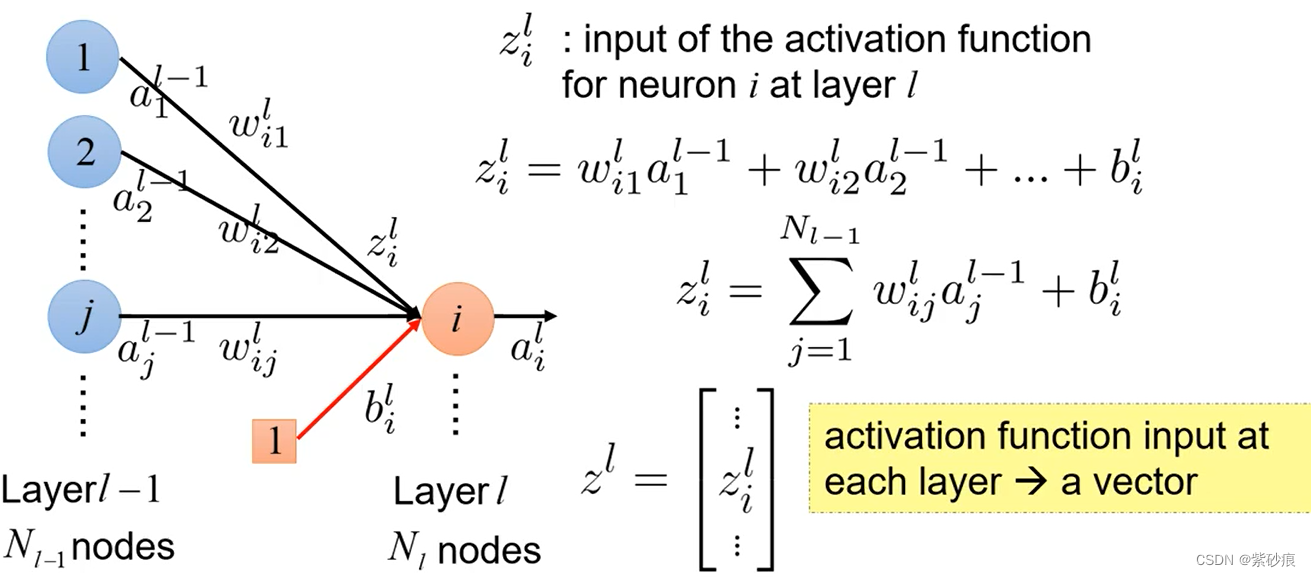
神经网络输入输出关系
3. 激活函数
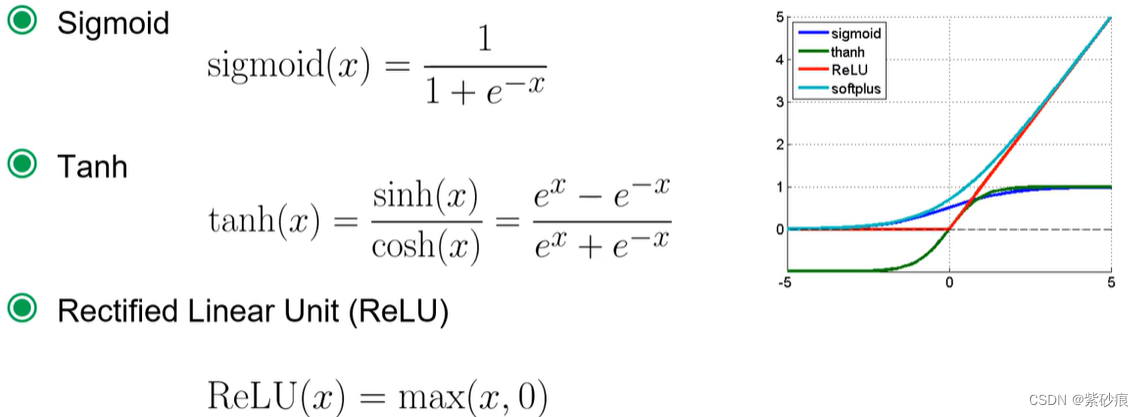
3.1 为啥要非线性激活函数?

4. 模型评估: Loss Function


cross entropy 的结果越低越好
对于分类问题来说,预测的输出可以看作是一个概率分布,真实的label 也是一个概率分布,计算这两者之间的cross entroy, 差异越大的话,代表模型越差
4. 优化:
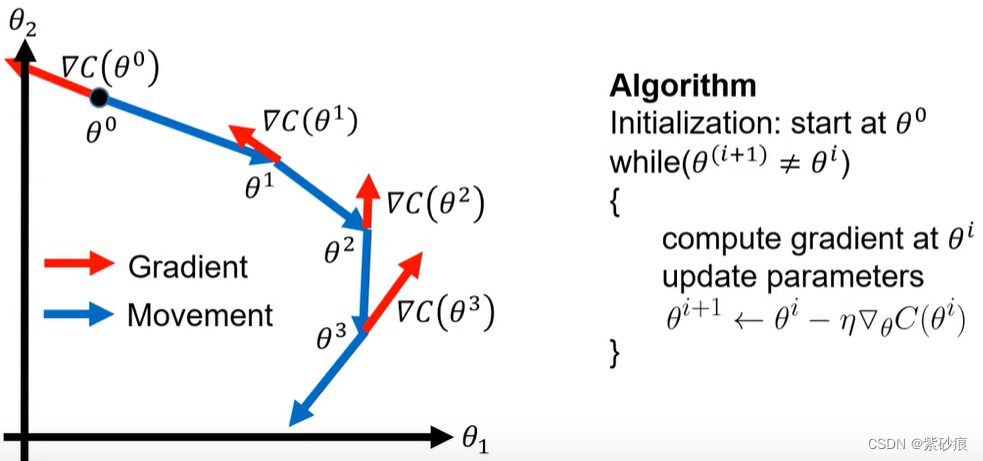
4.1 梯度下降
θ
\theta
θ 就是模型中所有参数变量集合
梯度下降的问题:
看完训练集中的所有数据集,再去更新梯度,训练速度会很慢

4.2 随机梯度下降(SGD)
所以 为了提升训练速度, 提出 随机梯度下降:
每看一个样本,都更新一次梯度
假设每个样本随机抽取的概率是一样的,服从均匀分布。


4.3 mini-batch SGD
每次挑选 batch_size个样本去更新梯度。


mini-batch SGD 训练的时候 的tips:
- 每一个epoch之间 shuffle一下 训练样本
- 每个epoch 都有相同的 batch_size
- 调整batch_size时 learning rate 也应做适量调整
(batch_size 变大时,每个epoch梯度更新的次数下降,那么也需要相应较大的learning rate。 有论文提到 K 倍的 batch_size, learning rate 应变成 K \sqrt K K倍数)
4.4 三者的比较
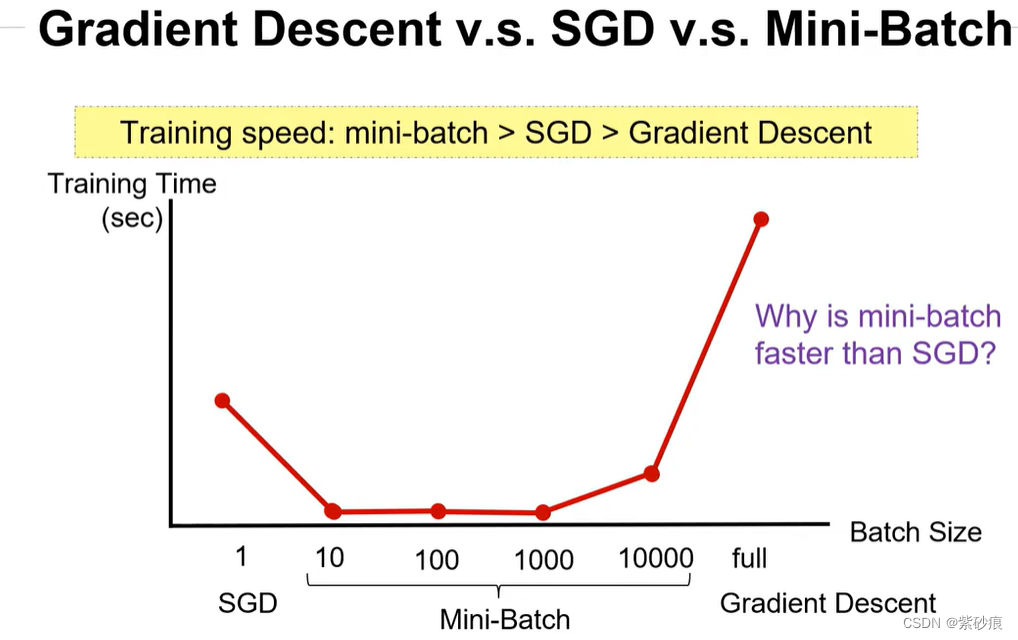
为什么mini-batch SGD 比SGD 训练更快
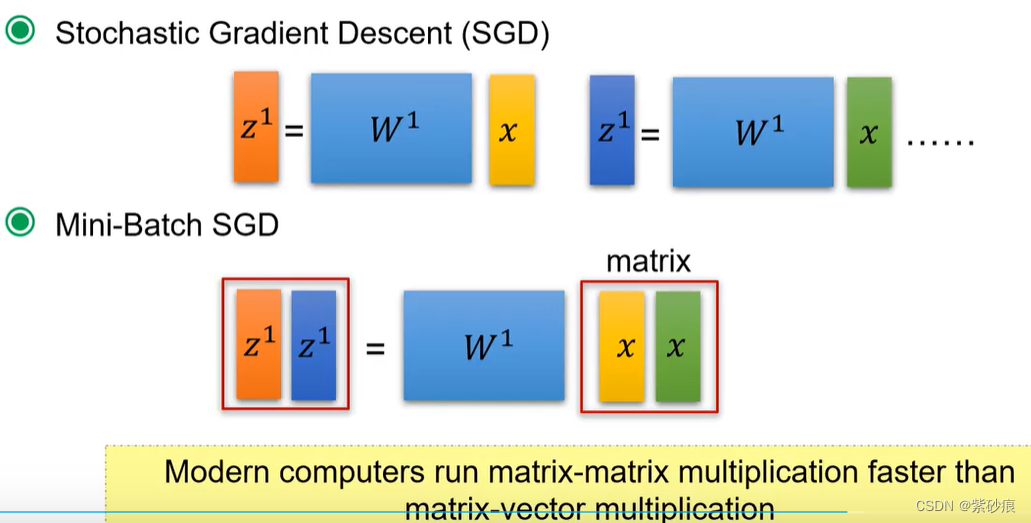
因为两次的matric-vector 的计算 比 一次 matric-matrix计算 耗时更长。
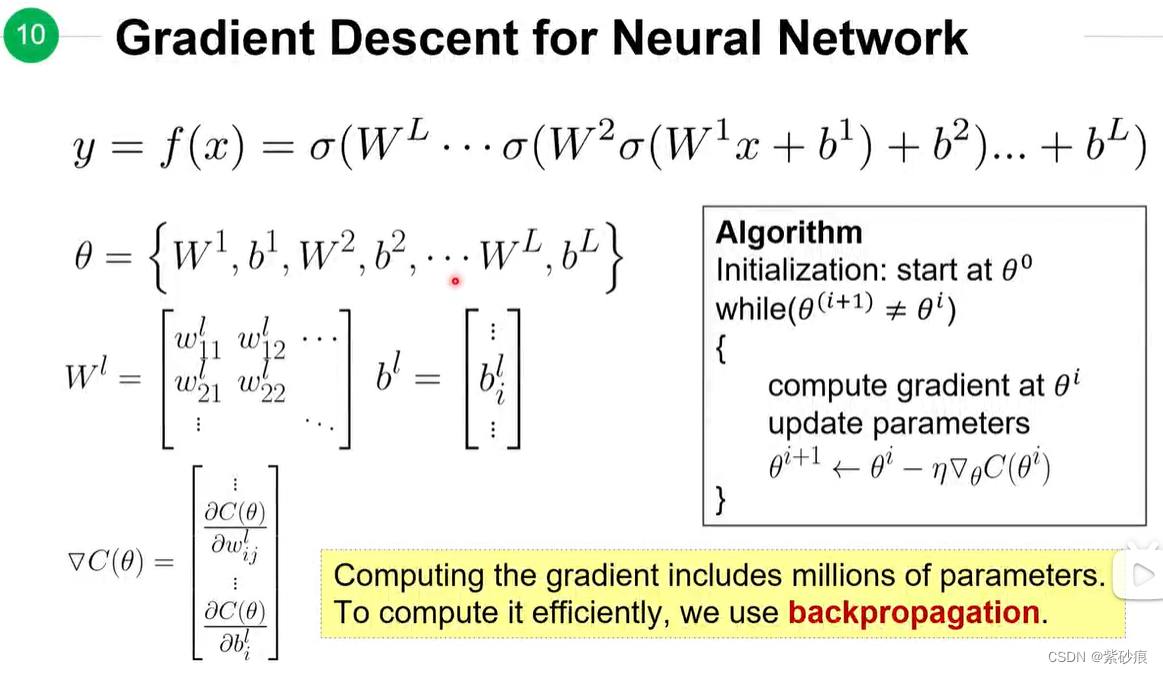
4.5 back propagation 反向传播
反向传播是为了用来快速计算梯度

举个例子:
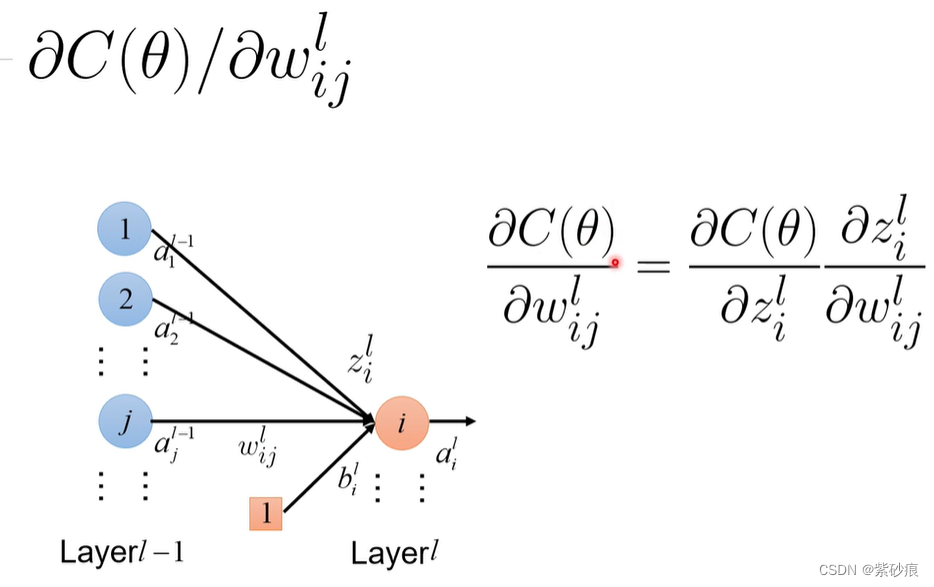
第一部分:
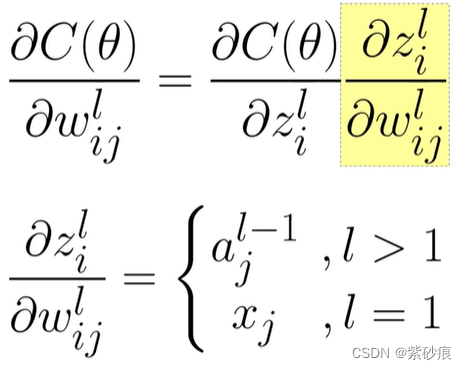
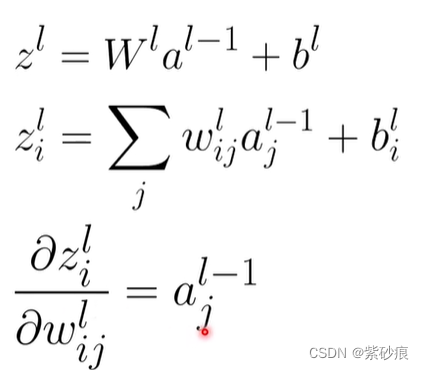
对于第一层来说,是这样:
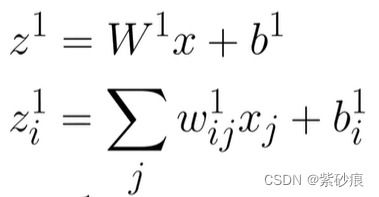
第二部分

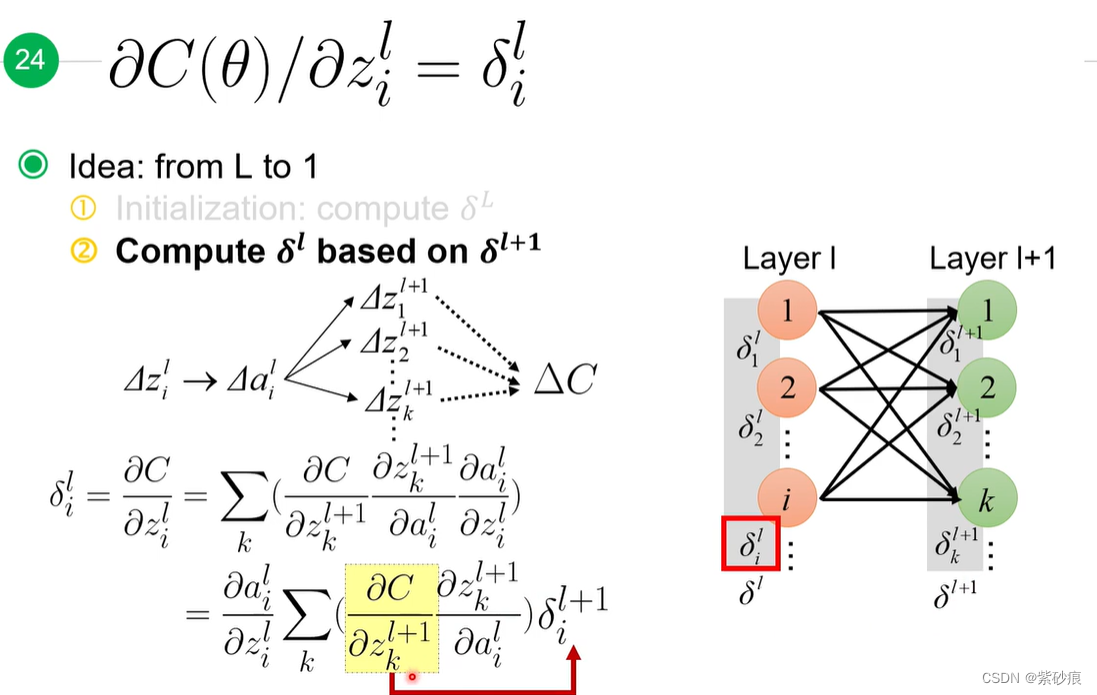
也就是
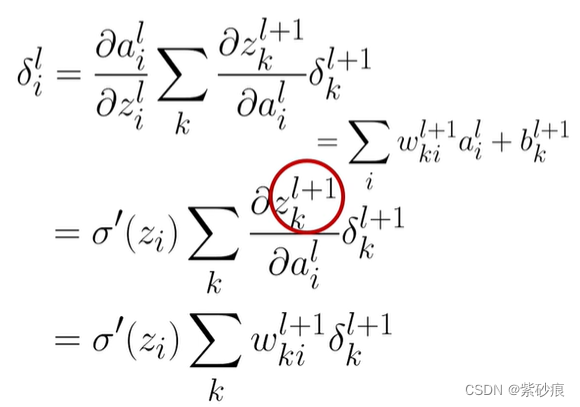
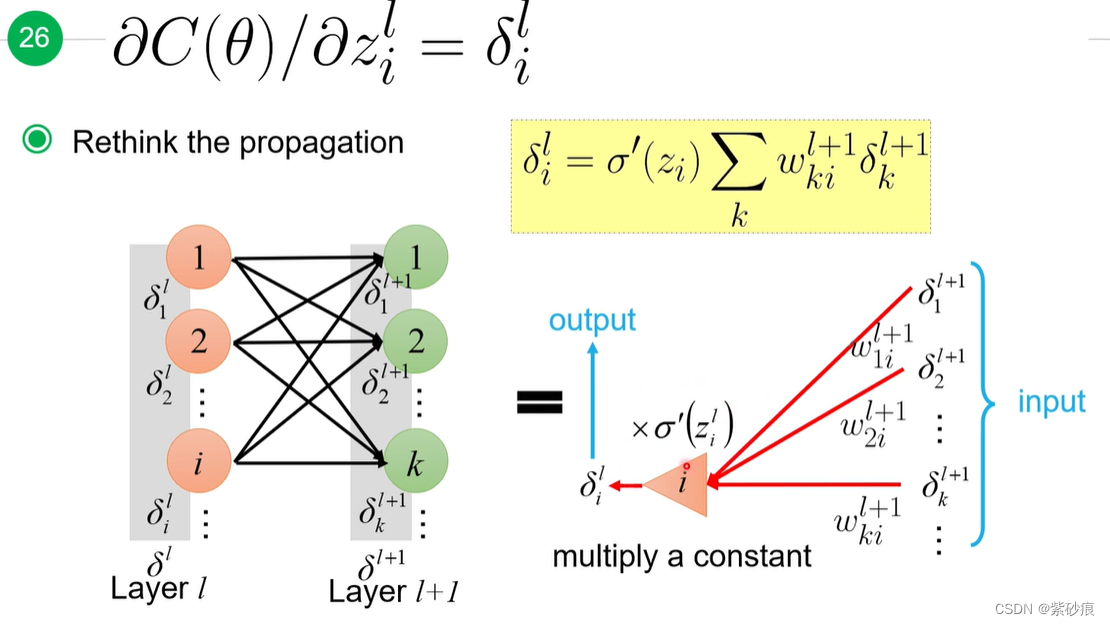

总结起来::
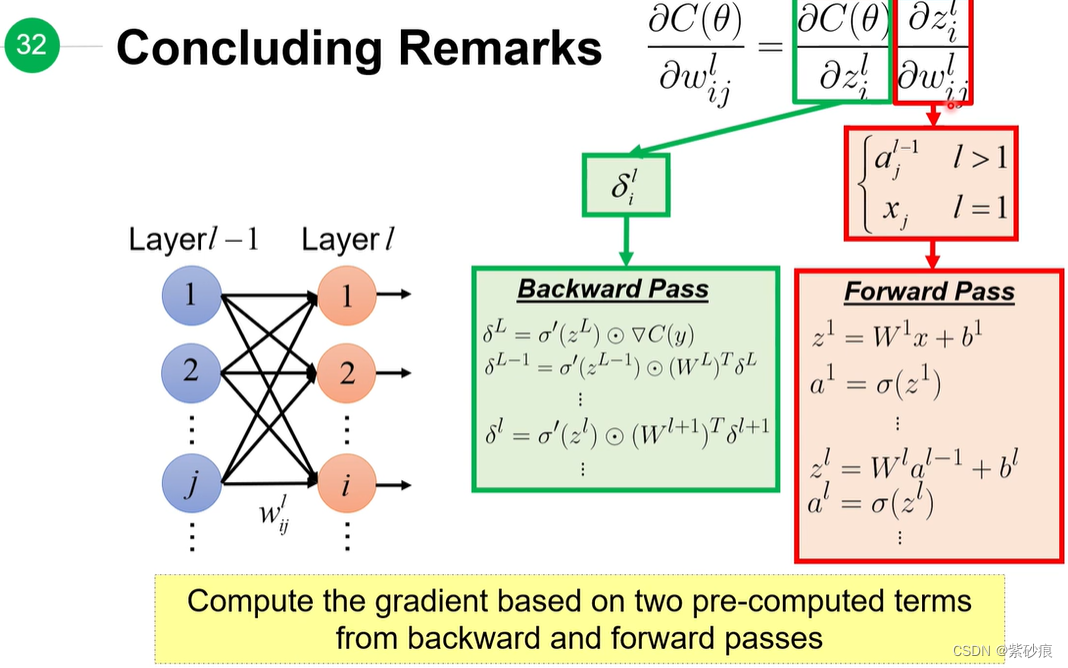
一次前向传播计算和一次后向传播计算,就可以把网络中的需要更新的参数都记录下来,提升速度
5 模型训练的tips
5.1 在训练集无法得到好的结果
- 陷入局部最优、 训练策略需要调整,调整learning_rate, 或者初始值
- 模型不好:重新构建模型结构

5.2 在训练集结果很好,但在validate集的结果不好
可能原因: overfitting了 过拟合了

解决方法:
- 增加训练数据
- dropout




![[Vulnhub] DC-2](https://img-blog.csdnimg.cn/6b3dc3cce27f44859f3c664bb9928495.png)