目录
一 动态范围量化
二 全整数量化
三 float16量化

通常,表示神经网络的数据类型是32位浮点数(float32),这种数据类型可以提供高精度的计算,但是在计算资源和存储空间有限的设备上运行神经网络时,会带来一定的挑战,因此可以对模型进行量化处理。Int8量化是一种将神经网络权重和激活值转换为8位整数(int8)表示的技术。TensorFlow Lite转换器将已训练的浮点 TensorFlow 模型转换为 TensorFlow Lite 格式后,可以完成对这个模型的量化。
查看网络结构:netron
技术有动态范围、全整数和Float16量化三种。

一 动态范围量化
训练后量化最简单的形式是仅将权重从浮点静态量化为整数(具有8位精度),推断时,权重从8位精度转换为浮点,并使用浮点内核进行计算。此转换会完成一次并缓存,以减少延迟。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()使用动态范围算子的加速小于全定点计算。
二 全整数量化
通过确保所有模型数学均为整数量化,进一步改善延迟,减少峰值内存用量,以及兼容仅支持整数的硬件设备或加速器。使用默认浮点输入/输出和仅整数(输入和输出在内的所有算子强制执行全整数量化)的实践如下:
① ResNet50_fp32.tflite模型
- 代码
import tensorflow as tf
model = tf.keras.applications.ResNet50(weights='imagenet')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 执行模型转换
tflite_model = converter.convert()
# 将转换后的模型保存为.tflite文件
with open("ResNet50_fp32.tflite", 'wb') as f:
f.write(tflite_model)
pass- 查看模型结构等信息
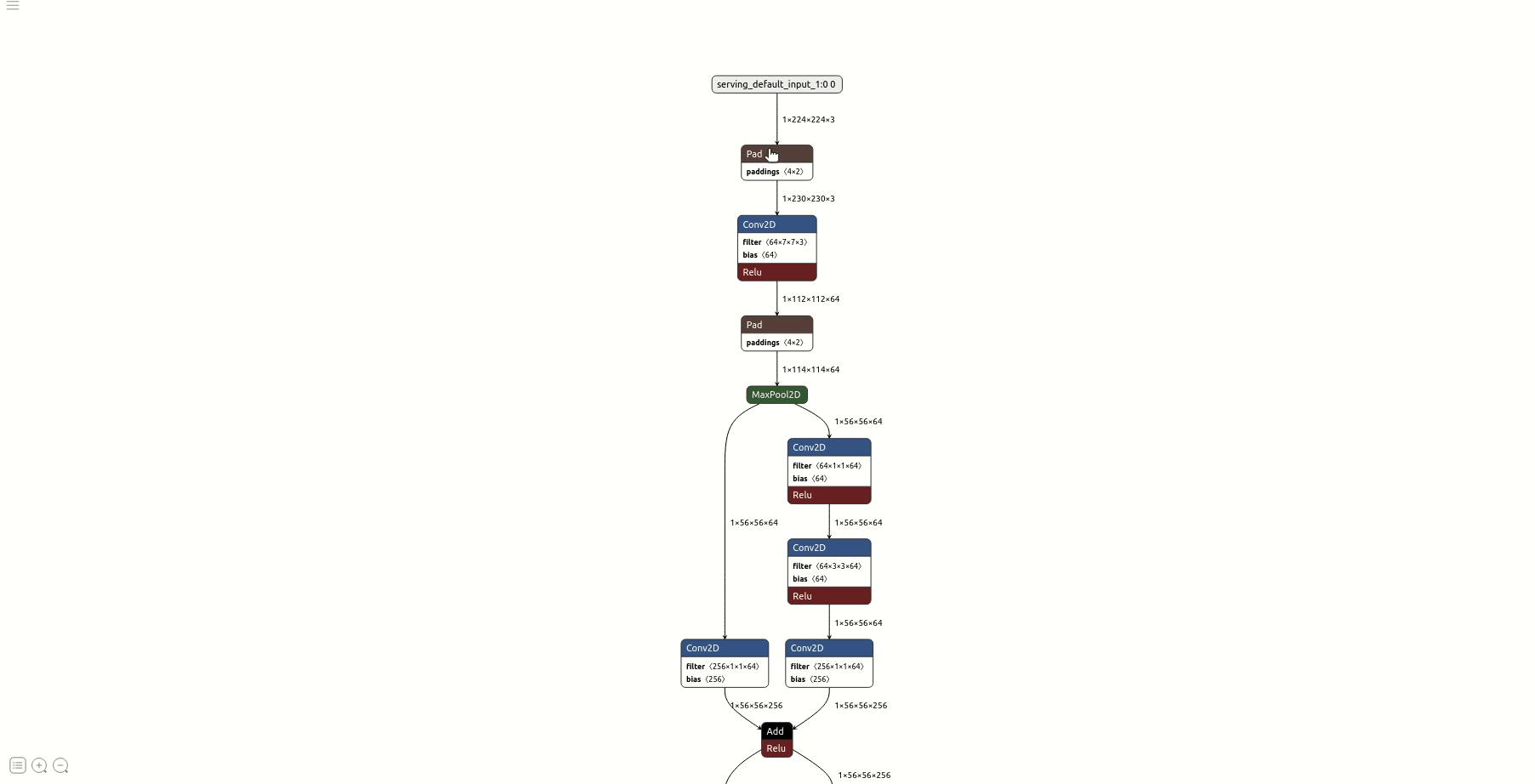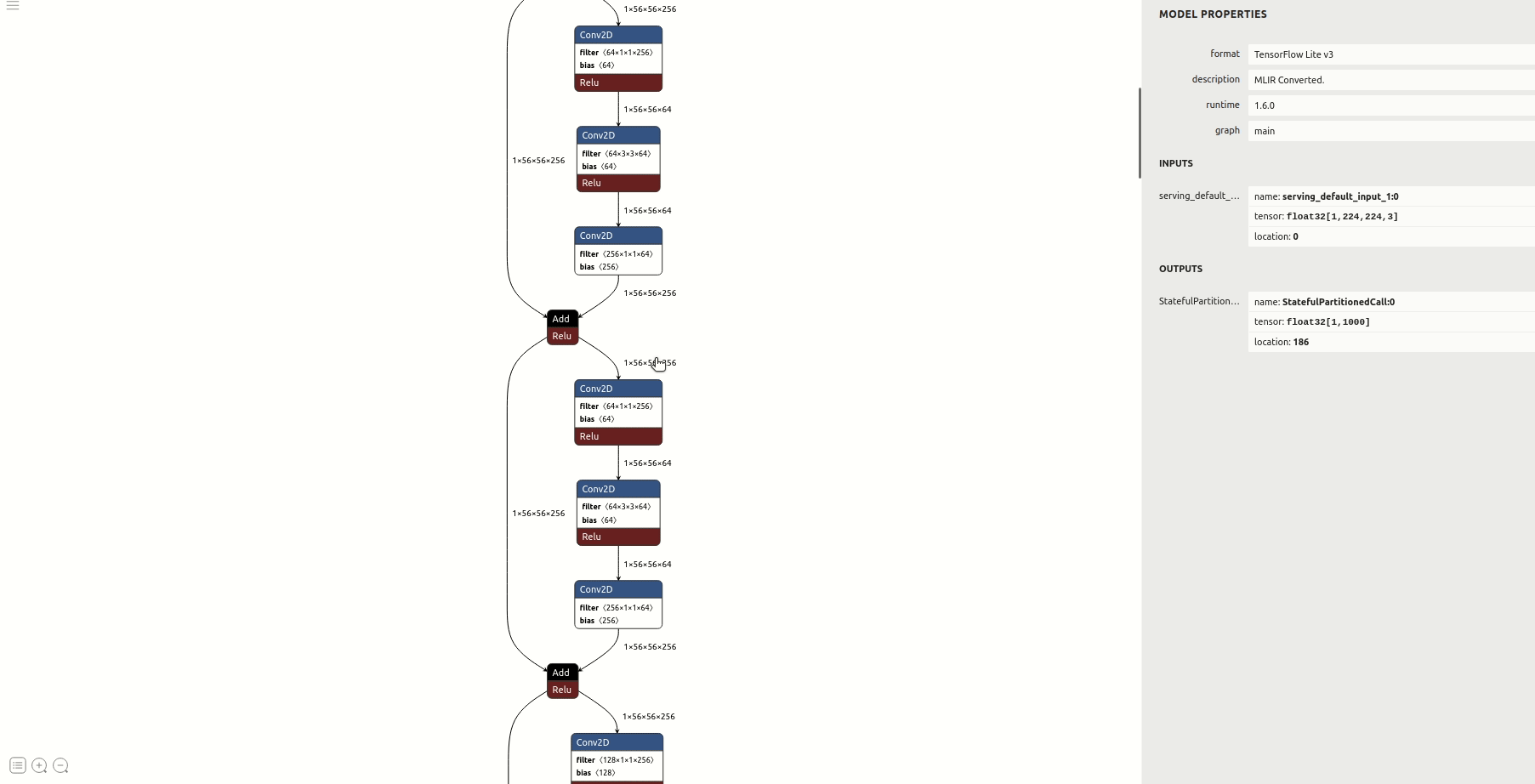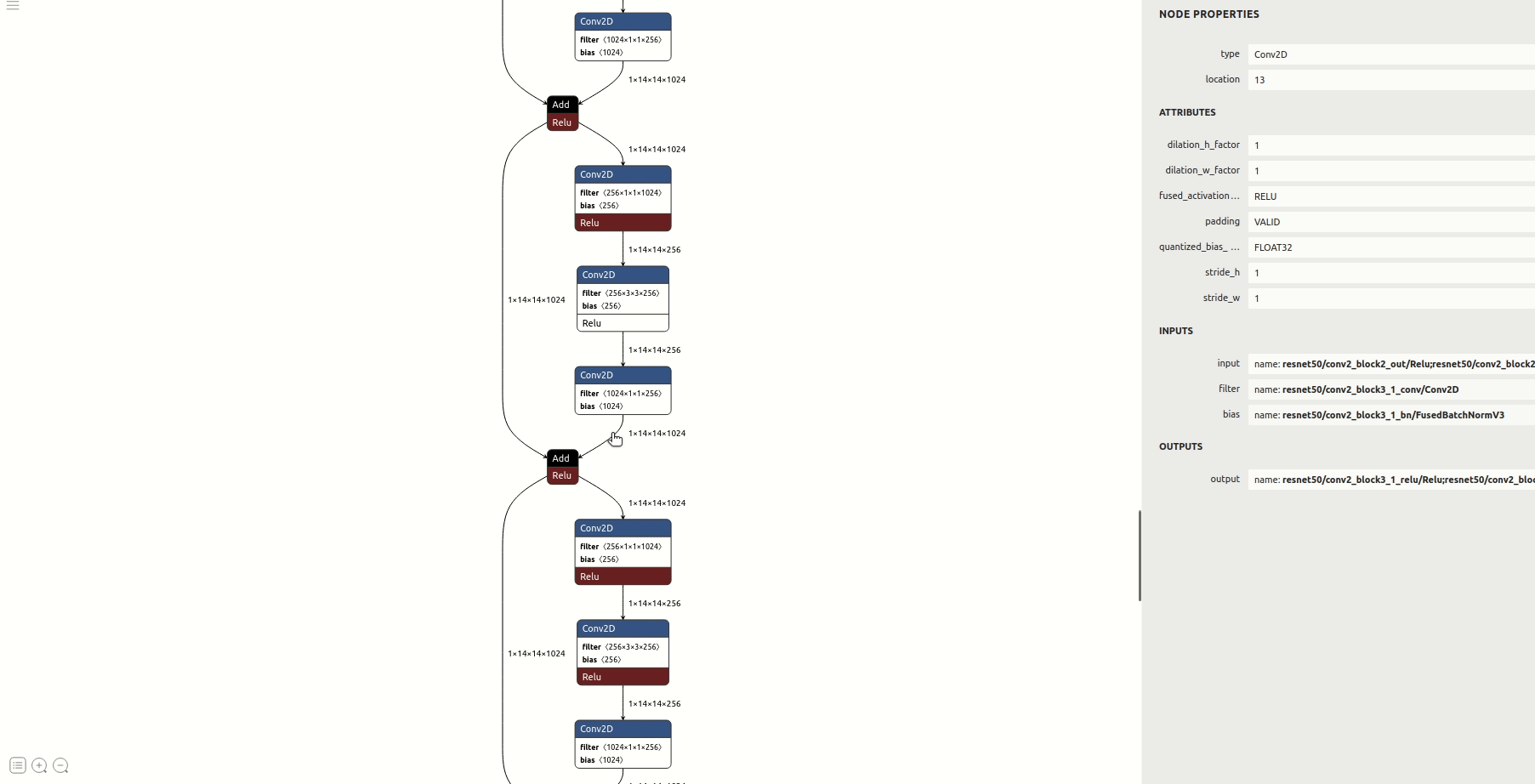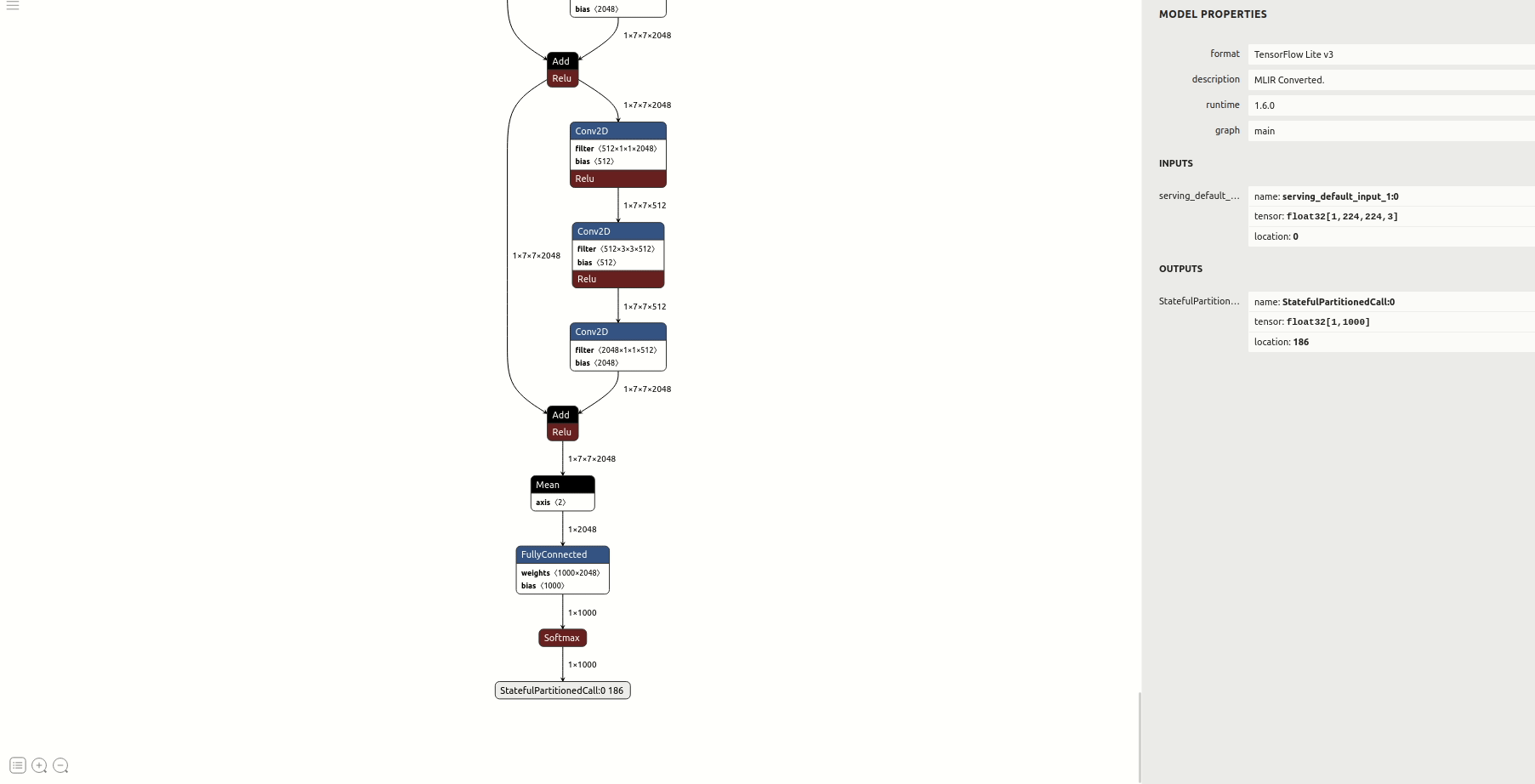
②使用默认浮点输入/输出
ResNet50_in8.tflite模型。为了与原始的全浮点模型具有相同的接口,此 tflite_quant_model 不兼容仅支持整数的设备和加速器,因为输入和输出仍为浮点。
- 代码
import tensorflow as tf
import numpy as np
# 出于测试目的,可以使用如下所示的虚拟数据集
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 224, 224, 3)
yield [data.astype(np.float32)]
model = tf.keras.applications.ResNet50(weights='imagenet')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
# 执行模型转换
tflite_model = converter.convert()
# 将转换后的模型保存为.tflite文件
with open('ResNet50_in8.tflite', 'wb') as f:
f.write(tflite_model)
pass- 查看模型结构等信息

③ 仅整数
ResNet50_in8_all.tflite模型,输入和输出在内的所有算子强制执行全整数量化。
- 代码
import tensorflow as tf
import numpy as np
# 出于测试目的,可以使用如下所示的虚拟数据集
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 224, 224, 3)
yield [data.astype(np.float32)]
model = tf.keras.applications.ResNet50(weights='imagenet')
# 输入和输出在内的所有算子强制执行全整数量化
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset
# 执行模型转换
tflite_model = converter.convert()
# 将转换后的模型保存为.tflite文件
with open('ResNet50_in8_all.tflite', 'wb') as f:
f.write(tflite_model)
pass- 查看模型结构等信息

④ MobileNet_fp32.tflite模型
- 代码
import tensorflow as tf
model = tf.keras.applications.MobileNet(weights='imagenet')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 执行模型转换
tflite_model = converter.convert()
# 将转换后的模型保存为.tflite文件
with open("MobileNet_fp32.tflite", 'wb') as f:
f.write(tflite_model)
pass- 查看模型结构等信息

⑤ 仅整数(MobileNet_in8.tflite模型)
- 代码
import tensorflow as tf
import numpy as np
# 出于测试目的,可以使用如下所示的虚拟数据集
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 224, 224, 3)
yield [data.astype(np.float32)]
model = tf.keras.applications.MobileNet(weights='imagenet')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset
# 执行模型转换
tflite_model = converter.convert()
# 将转换后的模型保存为.tflite文件
with open("MobileNet_int8_all.tflite", 'wb') as f:
f.write(tflite_model)
pass- 查看模型结构等信息

三 float16量化
可以通过将权重量化为 float16(16位浮点数的IEEE标准)来缩减浮点模型的大小。如果需要使用权重的float16量化,可以使用以下步骤:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()float16 量化的优点包括:
- 将模型的大小缩减一半,模型更小了;
- 实现最小的准确率损失;
- 支持可直接对 float16数据进行运算的部分委托,从而使执行速度比float32计算更快。
float16 量化的缺点包括:
- 延迟比对定点数学进行量化多;
- 通常,float16 量化模型在CPU上运行时会将权重值“反量化”为 float32。
- 注意:GPU 委托不会执行此反量化,因为它可以对 float16 数据进行运算。
具有 8 位权重的 16 位激活(实验性)与“仅整数”方案类似,根据激活的范围将其量化为16位,权重会被量化为8位整数。这种量化的优点是可以显著提高准确率,相比于全整数量化,会增加模型的大小。由于缺少优化的内核实现,目前的推断速度明显比8位全整数慢。目前它不兼容现有的硬件加速TFLite 委托。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8]
tflite_quant_model = converter.convert()如果模型中的部分算子不支持这一量化,模型仍然可以进行量化处理。但是,不受支持的算子会保留为浮点。要允许这一操作,将以下这个选项添加到 target_spec 中即可。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8,tf.lite.OpsSet.TFLITE_BUILTINS]
tflite_quant_model = converter.convert()量化





![[SWPUCTF 2021 新生赛]error](https://img-blog.csdnimg.cn/direct/b839b5328b0c40a0b3fef850e8bbcd14.png#pic_center)