温故而知新,可以为师矣!
一、参考资料
论文:A guide to convolution arithmetic for deep learning
github源码:Convolution arithmetic
bilibili视频:转置卷积(transposed convolution)
转置卷积(Transposed Convolution)
【keras/Tensorflow/pytorch】Conv2D和Conv2DTranspose详解
怎样通俗易懂地解释反卷积?
抽丝剥茧,带你理解转置卷积(反卷积)
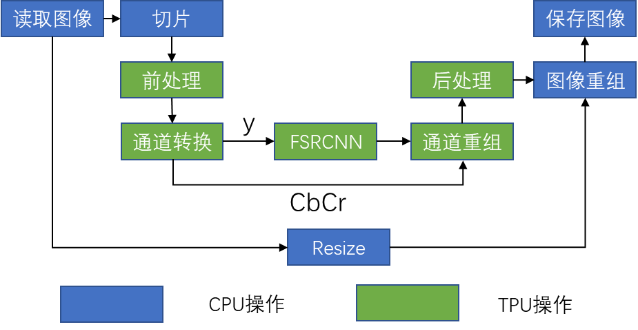
二、标准卷积(Conv2D)

1. Conv2D 计算公式
标准卷积计算公式有:
o
=
i
+
2
p
−
k
s
+
1
i
=
size
of
input
o
=
size
of
output
p
=
p
a
d
d
i
n
g
k
=
size
of
kernel
s
=
s
t
r
i
d
e
s
o=\frac{i+2p-k}s+1 \quad \begin{array}{l} \\i=\textit{size of input}\\o=\textit{size of output}\\p=padding\\k=\textit{size of kernel}\\s=strides\end{array}
o=si+2p−k+1i=size of inputo=size of outputp=paddingk=size of kernels=strides
以特征图的高度Height为例,经过卷积操作之后,输出特征图计算公式为:
H
o
u
t
=
H
i
n
+
2
p
−
k
s
+
1
(
1
)
H_{out}=\frac{H_{in}+2p-k}s+1\quad(1)
Hout=sHin+2p−k+1(1)
2. Conv2D中的步长stride
2.1 当步长stride=1,p=0,k=3

输入特征图(蓝色):
(
H
i
n
,
W
i
n
)
=
(
4
,
4
)
(H_{in},W_{in})=(4,4)
(Hin,Win)=(4,4)。
标准卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
)
=
3
,
s
t
r
i
d
e
(
s
)
=
1
,
p
a
d
d
i
n
g
=
0
kernel\_size(k)=3,stride(s)=1,padding=0
kernel_size(k)=3,stride(s)=1,padding=0。
输出特征图(绿色):
(
H
o
u
t
,
W
o
u
t
)
=
(
2
,
2
)
(H_{out},W_{out})=(2,2)
(Hout,Wout)=(2,2)。
代入
公式
(
1
)
公式(1)
公式(1)中,可得:
H
o
u
t
=
H
i
n
+
2
p
−
K
S
+
1
H
o
u
t
=
4
+
2
∗
0
−
3
1
+
1
=
2
H_{out}=\frac{H_{in}+2p-K}S+1\\ H_{out}=\frac{4+2*0-3}1+1=2
Hout=SHin+2p−K+1Hout=14+2∗0−3+1=2
2.2 当步长stride=2,p=1,k=3

输入特征图(蓝色):
(
H
i
n
,
W
i
n
)
=
(
5
,
5
)
(H_{in},W_{in})=(5,5)
(Hin,Win)=(5,5)。
标准卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
)
=
3
,
s
t
r
i
d
e
(
s
)
=
2
,
p
a
d
d
i
n
g
=
1
kernel\_size(k)=3,stride(s)=2,padding=1
kernel_size(k)=3,stride(s)=2,padding=1。
输出特征图(绿色):
(
H
o
u
t
,
W
o
u
t
)
=
(
3
,
3
)
(H_{out},W_{out})=(3,3)
(Hout,Wout)=(3,3)。
代入
公式
(
1
)
公式(1)
公式(1)中,可得:
H
o
u
t
=
H
i
n
+
2
p
−
k
s
+
1
H
o
u
t
=
5
+
2
∗
1
−
3
2
+
1
=
3
H_{out}=\frac{H_{in}+2p-k}s+1\\ H_{out}=\frac{5+2*1-3}2+1=3
Hout=sHin+2p−k+1Hout=25+2∗1−3+1=3
三、转置卷积(Conv2DTranspose)
1. 引言
对于很多生成模型(如语义分割、自动编码器(Autoencoder)、GAN中的生成器等模型),我们通常希望进行与标准卷积相反的转换,即执行上采样。对于语义分割,首先用编码器提取特征图,然后用解码器恢复原始图像大小,这样来分类原始图像的每个像素。
实现上采样的传统方法是应用插值方案或人工创建规则。而神经网络等现代架构则倾向于让网络自动学习合适的变换,无需人类干预。为了做到这一点,我们可以使用转置卷积。
2. 对转置卷积名称的误解
This operation is sometimes called “deconvolution” after (Zeiler et al., 2010), but is really the transpose (gradient) of atrous_conv2d rather than an actual deconvolution.
Deconvolutional Networks: Zeiler et al., 2010 (pdf)
转置卷积又叫反卷积(deconv or deconvolution)、逆卷积。然而,转置卷积是目前最为正规和主流的名称,因为这个名称更加贴切的描述了Conv2DTranspose 的计算过程,而其他的名字容易造成误导。在主流的深度学习框架中,如TensorFlow,Pytorch,Keras中的函数名都是 conv_transpose。所以,学习转置卷积之前,我们一定要弄清楚标准名称,遇到他人说反卷积、逆卷积也要帮其纠正,让不正确的命名尽早的淹没在历史的长河中。
我们先说一下为什么人们很喜欢将转置卷积称为反卷积或逆卷积。首先举一个例子,将一个4x4的输入通过3x3的卷积核在进行普通卷积(无padding, stride=1),将得到一个2x2的输出。而转置卷积将一个2x2的输入通过同样3x3大小的卷积核将得到一个4x4的输出,看起来似乎是普通卷积的逆过程。就好像是加法的逆过程是减法,乘法的逆过程是除法一样,人们自然而然的认为这两个操作似乎是一个可逆的过程。转置卷积不是卷积的逆运算(一般卷积操作是不可逆的),转置卷积也是卷积。转置卷积并不是正向卷积的完全逆过程(逆运算),它不能完全恢复输入矩阵的数据,只能恢复输入矩阵的大小(shape)。所以,转置卷积的名字就由此而来,而并不是“反卷积”或者是“逆卷积”,不好的名称容易给人以误解。
有些地方,转置卷积又被称作 fractionally-strided convolution或者deconvolution,但 deconvolution 具有误导性,不建议使用。因此,本文将会使用 Conv2DTranspose 和 fractionally-strided convolutions 两个名字,分别对应代码版和学术论文版。
I think
transpose_conv2dorconv2d_transposeare the cleanest names.
3. Conv2DTranspose的概念
转置卷积(Transposed Convolution) 在语义分割或者==对抗神经网络(GAN)==中比较常见,其主要作用是做上采样(UpSampling)。

4. Conv2D与Conv2DTranspose对比
转置卷积和标准卷积有很大的区别,直接卷积是用一个“小窗户”去看一个“大世界”,而转置卷积是用一个“大窗户”的一部分去看“小世界”。
标准卷积(大图变小图)中,输入(5,5),步长(2,2),输出(3,3)。

转置卷积操作中(小图变大图),输入(3,3)输出(5,5)。

5. Conv2DTranspose计算过程
转置卷积核大小为k,步长s,填充p,则转置卷积的计算步骤可以总结为三步:
- 第一步:计算新的输入特征图;
- 第二步:计算转置卷积核;
- 第三步:执行标准卷积操作。

5.1 第一步:计算新的输入特征图
对输入特征图 M M M 进行 插值(interpolation) 零元素,得到新的输入特征图 M ′ M^{\prime} M′ 。
以特征图的高度Height为例,输入特征图的Height高为
H
i
n
H_{in}
Hin ,中间有
(
H
i
n
−
1
)
(H_{in}-1)
(Hin−1) 个空隙。
两个相邻位置中间的插值零元素的个数:
s
−
1
s-1
s−1,
s
s
s 表示步长。
Height方向上总共插值零元素的个数:
(
H
i
n
−
1
)
∗
(
s
−
1
)
(H_{in}-1) * (s-1)
(Hin−1)∗(s−1)。
新的输入特征图大小:
H
i
n
′
=
H
i
n
+
(
H
i
n
−
1
)
∗
(
s
−
1
)
H_{in}^{\prime} = H_{in} + (H_{in}-1)*(s-1)
Hin′=Hin+(Hin−1)∗(s−1)。
5.2 第二步:计算转置卷积核
对标准卷积核 K K K进行上下、左右翻转,得到转置卷积核 K ′ K^{\prime} K′。
已知:
标准卷积核大小: k k k,
标准卷积核stride: s s s,
标准卷积核padding: p p p
- 转置卷积核大小: k ′ = k k^{\prime}=k k′=k。
- 转置卷积核stride: s ′ = 1 s^{\prime}=1 s′=1,该值永远为1。
- 转置卷积核padding:
p
′
=
k
−
p
−
1
p^{\prime} = k-p-1
p′=k−p−1。该公式是如何产生的,下文有解释。

5.3 第三步:执行标准卷积操作
用转置卷积核对新的输入特征图进行标准卷积操作,得到的结果就是转置卷积的结果。
根据标准卷积的计算公式可知:
H
o
u
t
=
(
H
i
n
′
+
2
p
′
−
k
′
)
s
′
+
1
(
2
)
\mathrm{H_{out}}=\frac{(\mathrm{H_{in}^{\prime}}+2\mathrm{p^{\prime}}-k^{\prime})}{\mathrm{s^{\prime}}}+1\quad(2)
Hout=s′(Hin′+2p′−k′)+1(2)
H ′ = H i n + ( H i n − 1 ) ∗ ( s − 1 ) H^{\prime} = H_{in} + (H_{in}-1)*(s-1) H′=Hin+(Hin−1)∗(s−1),
k ′ = k k^{\prime}=k k′=k,
s ′ = 1 s^{\prime}=1 s′=1,
p ′ = k − p − 1 p^{\prime} = k-p-1 p′=k−p−1。
将第一、二步中变换的结果代入上式,可得:
H
o
u
t
=
(
H
i
n
+
H
i
n
∗
s
−
H
−
s
+
1
)
+
2
∗
(
k
−
p
−
1
)
−
k
s
′
+
1
(
3
)
\text{H}_{out}=\frac{(\text{H}_{in}+\text{H}_{in}*s-\text{H}-\text{s}+1)+2*(\text{k}-\text{p}-1)-\text{k}}{\text{s}'}+1\quad(3)
Hout=s′(Hin+Hin∗s−H−s+1)+2∗(k−p−1)−k+1(3)
化简,可得:
H
o
u
t
=
(
H
i
n
−
1
)*s
+
k
−
2
p
−
1
s
′
+
1
(
4
)
\text{H}_{out}=\frac{(\text{H}_{in}-1\text{)*s}+\text{k}-2\text{p}-1}{\text{s}'}+1\quad(4)
Hout=s′(Hin−1)*s+k−2p−1+1(4)
上式中,分母步长
s
′
=
1
s^{\prime}=1
s′=1,则最终结果为:
H
o
u
t
=
(
H
i
n
−
1
)
∗
s
−
2
p
+
k
(
5.1
)
\mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}-2\text{p}+\mathrm{k}\quad(5.1)
Hout=(Hin−1)∗s−2p+k(5.1)
综上所述,可以求得特征图Height和Width两个方向上进行转置卷积计算的结果:
H
o
u
t
=
(
H
i
n
−
1
)
×
s
t
r
i
d
e
[
0
]
−
2
×
p
a
d
d
i
n
g
[
0
]
+
k
e
r
n
e
l
_
s
i
z
e
[
0
]
W
o
u
t
=
(
W
i
n
−
1
)
×
s
t
r
i
d
e
[
1
]
−
2
×
p
a
d
d
i
n
g
[
1
]
+
k
e
r
n
e
l
_
s
i
z
e
[
1
]
H_{out}=(H_{in}−1)×stride[0]−2×padding[0]+kernel\_size[0]\\ W_{out}=(W_{in}−1)×stride[1]−2×padding[1]+kernel\_size[1]
Hout=(Hin−1)×stride[0]−2×padding[0]+kernel_size[0]Wout=(Win−1)×stride[1]−2×padding[1]+kernel_size[1]
5.4 Conv2DTranspose示例

输入特征图
M
M
M :
H
i
n
=
3
H_{in}=3
Hin=3。
标准卷积核
K
K
K:
k
=
3
,
s
=
2
,
p
=
1
k=3,s=2, p=1
k=3,s=2,p=1。
新的输入特征图
M
′
M^{\prime}
M′ :
H
i
n
′
=
3
+
(
3
−
1
)
∗
(
2
−
1
)
=
3
+
2
=
5
H_{in}^{\prime}=3+(3−1)∗(2−1)=3+2=5
Hin′=3+(3−1)∗(2−1)=3+2=5。注意加上padding之后才是7。
转置卷积核
K
′
K^{\prime}
K′:
k
′
=
k
,
s
′
=
1
,
p
′
=
3
−
1
−
1
=
1
k^{\prime}=k,s^{\prime}=1,p^{\prime}=3−1−1=1
k′=k,s′=1,p′=3−1−1=1。
转置卷积计算的最终结果:
H
o
u
t
=
(
3
−
1
)
∗
2
−
2
∗
1
+
3
=
5
\mathrm{H_{out}}=(3-1)*2-2*1+3=5
Hout=(3−1)∗2−2∗1+3=5。

6. 证明 p ′ = k − p − 1 p^{\prime}=k-p-1 p′=k−p−1
变换
公式
(
5.1
)
公式(5.1)
公式(5.1) 可得:
H
i
n
=
H
o
u
t
+
2
p
−
k
s
+
1
(
5.2
)
H_{in}=\frac{H_{out}+2p-k}s+1\quad(5.2)
Hin=sHout+2p−k+1(5.2)
由
公式
(
5.2
)
公式(5.2)
公式(5.2)和
公式
(
1
)
公式(1)
公式(1)可以看出, Conv2D 和 Conv2DTranspose 在输入和输出大小互为逆(inverses)。
Note: torch.nn.ConvTranspose2d
The padding argument effectively addsdilation * (kernel_size - 1) - paddingamount of zero padding to both sizes of the input. This is set so that when a Conv2d and a ConvTranspose2d are initialized with same parameters, they are inverses of each other in regard to the input and output shapes.参数padding有效地将 d i l a t i o n ∗ ( k e r n e l _ s i z e − 1 ) − p a d d i n g dilation * (kernel\_size - 1) - padding dilation∗(kernel_size−1)−padding 零填充的填充量添加到两种大小的输入中。这样设置是为了当Conv2d和ConvTranspose2d用相同的参数初始化时,它们输入和输出的形状大小互为逆。
简单理解,参数padding的作用是,使得Conv2d和ConvTranspose2d输入输出的形状大小互为逆。
第二步中
p
′
=
k
−
p
−
1
p^{\prime} = k-p-1
p′=k−p−1 计算公式是如何产生的呢?其实就是根据“ Conv2d 和 ConvTranspose2d 输入输出的形状大小互为逆” 的条件推导(反推)得来的。可以简单证明:
已知条件:
H ′ = H i n + ( H i n − 1 ) ∗ ( s − 1 ) H^{\prime} = H_{in} + (H_{in}-1)*(s-1) H′=Hin+(Hin−1)∗(s−1),
k ′ = k k^{\prime}=k k′=k,
s ′ = 1 s^{\prime}=1 s′=1,
p ′ p^{\prime} p′未知待求。
将已知条件代入
公式
(
2
)
公式(2)
公式(2) 中,可得:
H
o
u
t
=
(
H
i
n
+
H
i
n
∗
s
−
H
−
s
+
1
)
+
2
∗
p
′
−
k
s
′
+
1
\text{H}_{out}=\frac{(\text{H}_{in}+\text{H}_{in}*s-\text{H}-\text{s}+1)+2*p^{\prime}-\text{k}}{\text{s}'}+1
Hout=s′(Hin+Hin∗s−H−s+1)+2∗p′−k+1
化简,可得:
H
o
u
t
=
(
H
i
n
−
1
)
∗
s
+
2
∗
p
′
−
k
+
2
(
6
)
\mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}+2*p^{\prime}-\mathrm{k}+2\quad(6)
Hout=(Hin−1)∗s+2∗p′−k+2(6)
根据“ Conv2d 和 ConvTranspose2d 输入输出的形状大小互为逆”,可得:
H
i
n
=
(
H
o
u
t
−
1
)
∗
s
+
2
∗
p
′
−
k
+
2
(
7
)
\mathrm{H}_{in}=(\mathrm{H}_{out}-1)*\text{s}+2*p^{\prime}-\mathrm{k}+2\quad(7)
Hin=(Hout−1)∗s+2∗p′−k+2(7)
变换公式可得:
H
o
u
t
=
(
H
i
n
−
2
∗
p
′
+
k
−
2
)
s
+
1
(
8
)
\mathrm{H_{out}}=\frac{(\mathrm{H_{in}}-2*\mathrm{p^{\prime}}+\mathrm{k}-2)}{\mathrm{s}}+1\quad(8)
Hout=s(Hin−2∗p′+k−2)+1(8)
由
公式
(
8
)
公式(8)
公式(8) 与
公式
(
1
)
公式(1)
公式(1) 可得:
2
p
−
k
=
−
2
∗
p
′
+
k
−
2
2p-k=-2*p^{\prime}+k-2
2p−k=−2∗p′+k−2
解得:
p
′
=
k
−
p
−
1
(
9
)
p^{\prime}=k-p-1\quad(9)
p′=k−p−1(9)
证闭。
7. Conv2DTranspose中的步长stride
下图展示了转置卷积中不同s和p的情况:
 |  |  |
|---|---|---|
| s=1, p=0, k=3 | s=2, p=0, k=3 | s=2, p=1, k=3 |
7.1 当步长stride=1,p=0,k=3
输入特征图(蓝色):
(
H
i
n
,
W
i
n
)
=
(
2
,
2
)
(H_{in},W_{in})=(2,2)
(Hin,Win)=(2,2)。
标准卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
)
=
3
,
s
t
r
i
d
e
(
s
)
=
1
,
p
a
d
d
i
n
g
(
p
)
=
0
kernel\_size(k)=3,stride(s)=1, padding(p)=0
kernel_size(k)=3,stride(s)=1,padding(p)=0。
新的输入特征图:
H
i
n
′
=
2
+
(
2
−
1
)
∗
(
1
−
1
)
=
2
H_{in}^{\prime} =2+(2-1)*(1-1)=2
Hin′=2+(2−1)∗(1−1)=2。如图上图所示,插值变换后得到的新的输入特征图为(2,2)。
转置卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
′
)
=
3
,
s
t
r
i
d
e
(
s
′
)
=
1
,
p
a
d
d
i
n
g
(
p
′
)
=
3
−
0
−
1
=
2
kernel\_size(k^{\prime})=3,stride(s^{\prime})=1, padding(p^{\prime})=3-0-1=2
kernel_size(k′)=3,stride(s′)=1,padding(p′)=3−0−1=2。如图上图所示,填充padding为2。
输出特征图(绿色):
(
H
o
u
t
,
W
o
u
t
)
=
(
4
,
4
)
(H_{out},W_{out})=(4,4)
(Hout,Wout)=(4,4)。
代入
公式
(
5
)
公式(5)
公式(5)中,可得:
H
o
u
t
=
(
H
i
n
−
1
)
∗
s
−
2
p
+
k
H
o
u
t
=
(
2
−
1
)
∗
1
−
2
∗
0
+
3
=
4
\mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}-2\text{p}+\mathrm{k}\\ \mathrm{H}_{out}=(2-1)*1-2*0+3=4
Hout=(Hin−1)∗s−2p+kHout=(2−1)∗1−2∗0+3=4
7.2 当步长stride=2,p=0,k=3
输入特征图(蓝色):
(
H
i
n
,
W
i
n
)
=
(
2
,
2
)
(H_{in},W_{in})=(2,2)
(Hin,Win)=(2,2)。
卷积核:
k
=
3
,
s
t
r
i
d
e
(
s
)
=
2
,
p
a
d
d
i
n
g
=
0
k=3,stride(s)=2, padding=0
k=3,stride(s)=2,padding=0。
新的输入特征图:
H
i
n
′
=
2
+
(
2
−
1
)
∗
(
2
−
1
)
=
3
H_{in}^{\prime} =2+(2-1)*(2-1)=3
Hin′=2+(2−1)∗(2−1)=3。如图上图所示,插值变换后得到的新的输入特征图为(3,3)。
转置卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
′
)
=
3
,
s
t
r
i
d
e
(
s
′
)
=
1
,
p
a
d
d
i
n
g
(
p
′
)
=
3
−
0
−
1
=
2
kernel\_size(k^{\prime})=3,stride(s^{\prime})=1, padding(p^{\prime})=3-0-1=2
kernel_size(k′)=3,stride(s′)=1,padding(p′)=3−0−1=2。如图上图所示,填充padding为2。
输出特征图(绿色):
(
H
o
u
t
,
W
o
u
t
)
=
(
5
,
5
)
(H_{out},W_{out})=(5,5)
(Hout,Wout)=(5,5)。
代入
公式
(
5
)
公式(5)
公式(5)中,可得:
H
o
u
t
=
(
H
i
n
−
1
)
∗
s
−
2
∗
p
+
k
H
o
u
t
=
(
2
−
1
)
∗
2
−
2
∗
0
+
3
=
5
\mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}-2*\text{p}+\mathrm{k}\\ \mathrm{H}_{out}=(2-1)*2-2*0+3=5
Hout=(Hin−1)∗s−2∗p+kHout=(2−1)∗2−2∗0+3=5
7.3 当步长stride=2,p=1,k=3
输入特征图(蓝色):
(
H
i
n
,
W
i
n
)
=
(
3
,
3
)
(H_{in},W_{in})=(3,3)
(Hin,Win)=(3,3)。
卷积核:
k
=
3
,
s
t
r
i
d
e
(
s
)
=
2
,
p
a
d
d
i
n
g
=
1
k=3,stride(s)=2, padding=1
k=3,stride(s)=2,padding=1。
新的输入特征图:
H
i
n
′
=
3
+
(
3
−
1
)
∗
(
2
−
1
)
=
5
H_{in}^{\prime} =3+(3-1)*(2-1)=5
Hin′=3+(3−1)∗(2−1)=5。如图上图所示,插值变换后得到的新的输入特征图为(5,5)。
转置卷积核:
k
e
r
n
e
l
_
s
i
z
e
(
k
′
)
=
3
,
s
t
r
i
d
e
(
s
′
)
=
1
,
p
a
d
d
i
n
g
(
p
′
)
=
3
−
1
−
1
=
1
kernel\_size(k^{\prime})=3,stride(s^{\prime})=1, padding(p^{\prime})=3-1-1=1
kernel_size(k′)=3,stride(s′)=1,padding(p′)=3−1−1=1。如图上图所示,填充padding为1。
输出特征图(绿色):
(
H
o
u
t
,
W
o
u
t
)
=
(
5
,
5
)
(H_{out},W_{out})=(5,5)
(Hout,Wout)=(5,5)。
代入
公式
(
5
)
公式(5)
公式(5)中,可得:
H
o
u
t
=
(
H
i
n
−
1
)
∗
s
−
2
∗
p
+
k
H
o
u
t
=
(
3
−
1
)
∗
2
−
2
∗
1
+
3
=
5
\mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}-2*\text{p}+\mathrm{k}\\ \mathrm{H}_{out}=(3-1)*2-2*1+3=5
Hout=(Hin−1)∗s−2∗p+kHout=(3−1)∗2−2∗1+3=5
8. 棋盘效应(Checkerboard Artifacts)
棋盘效应(Checkerboard Artifacts)
卷积操作总结(三)—— 转置卷积棋盘效应产生原因及解决
Deconvolution and Checkerboard Artifacts
棋盘效应是由于转置卷积的“不均匀重叠”(Uneven overlap)的结果,使图像中某个部位的颜色比其他部位更深。

9. 总结
Conv2D,特征图变换:
H o u t = H i n + 2 p − k s + 1 H_{out}=\frac{H_{in}+2p-k}s+1 Hout=sHin+2p−k+1
Conv2DTranspose,特征图变换:
H o u t = ( H i n − 1 ) ∗ s − 2 p + k \mathrm{H}_{out}=(\mathrm{H}_{in}-1)*\text{s}-2\text{p}+\mathrm{k} Hout=(Hin−1)∗s−2p+k
- 标准卷积核: s , p , k e r n e l _ s i z e ( k ) s,p,kernel\_size(k) s,p,kernel_size(k),转置卷积核: s = 1 , p ′ = k − p − 1 , k e r n e l _ s i z e ( k ′ ) = k e r n e l _ s i z e ( k ) s=1,p^{\prime}=k-p-1,kernel\_size(k^{\prime})=kernel\_size(k) s=1,p′=k−p−1,kernel_size(k′)=kernel_size(k)。
Conv2D和Conv2DTranspose输入输出的形状大小互为逆。- 标准卷积(大图变小图,(5,5)到(3,3)),转置卷积(小图变大图,(3,3)到(5,5))。
四、相关经验
tf.layers.Conv2DTranspose
TensorFlow函数:tf.layers.Conv2DTranspose
以 tensorflow2 框架的Conv2DTranspose为例,介绍转置卷积函数。
layers.Conv2DTranspose(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
output_padding=None,
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs,
)
Docstring:
Transposed convolution layer (sometimes called Deconvolution).
参数解释
filters:整数,输出空间的维数(即卷积中的滤波器数)。kernel_size:一个元组或2个正整数的列表,指定过滤器的空间维度;可以是单个整数,以指定所有空间维度的相同值。strides:一个元组或2个正整数的列表,指定卷积的步长;可以是单个整数,以指定所有空间维度的相同值。padding:可以是一个"valid"或"same"(不区分大小写)。data_format:一个字符串,可以是一个channels_last(默认)、channels_first,表示输入中维度的顺序。channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入。dilation_rate:。activation:激活功能,将其设置为“None”以保持线性激活。use_bias:Boolean,表示该层是否使用偏置。kernel_initializer:卷积内核的初始化程序。bias_initializer:偏置向量的初始化器,如果为None,将使用默认初始值设定项。kernel_regularizer:卷积内核的可选正则化器。bias_regularizer:偏置矢量的可选正则化器。activity_regularizer:输出的可选正则化函数。kernel_constraint:由Optimizer更新后应用于内核的可选投影函数(例如,用于实现层权重的范数约束或值约束);该函数必须将未投影的变量作为输入,并且必须返回投影变量(必须具有相同的形状);在进行异步分布式培训时,使用约束是不安全的。bias_constraint:由Optimizer更新后应用于偏置的可选投影函数。trainable:Boolean,如果为True,还将变量添加到图集合GraphKeys。TRAINABLE_VARIABLES中(请参阅参考资料tf.Variable)。name:字符串,图层的名称。
torch.nn.ConvTranspose2d
torch.nn.ConvTranspose2d
# 函数原型
CLASS torch.nn.ConvTranspose2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zeros',
device=None,
dtype=None)
参数解释
- in_channels (int) – Number of channels in the input image
- out_channels (int) – Number of channels produced by the convolution
- kernel_size (int or tuple) – Size of the convolving kernel
- stride (int or tuple, optional) – Stride of the convolution. Default: 1
- padding (int or tuple, optional) –
dilation * (kernel_size - 1) - paddingzero-padding will be added to both sides of each dimension in the input. Default: 0 - output_padding (int or tuple, optional) – Additional size added to one side of each dimension in the output shape. Default: 0. Note that
output_paddingis only used to find output shape, but does not actually add zero-padding to output. 在计算得到的输出特征图的高、宽方向各填充几行或列0(注意,这里只是在上下以及左右的一侧one side填充,并不是两侧都填充) - groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1. 当使用到组卷积时才会用到的参数,默认为1即普通卷积。
- bias (bool, optional) – If
True, adds a learnable bias to the output. Default:True - dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1. 当使用到空洞卷积(膨胀卷积)时才会使用该参数,默认为1即普通卷积。
代码示例(TensorFlow)
#创建生成器
def make_generator_model():
model = tf.keras.Sequential()#创建模型实例
#第一层须指定维度 #batch无限制
model.add(layers.Dense(7*7*BATCH_SIZE, use_bias=False, input_shape=(100,)))#Desne第一层可以理解为全连接层输入,它的秩必须小于2
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7,7,256)))
assert model.output_shape == (None,7,7,256)
#转化为7*7*128
model.add(layers.Conv2DTranspose(128,(5,5),strides=(1,1),padding='same',use_bias=False))
assert model.output_shape == (None,7,7,128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
#转化为14*14*64
model.add(layers.Conv2DTranspose(64,(5,5),strides=(2,2),padding='same',use_bias=False))
assert model.output_shape == (None,14,14,64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
#转化为28*28*1
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False,activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
代码示例(PyTorch)
下面使用Pytorch框架来模拟s=1, p=0, k=3的转置卷积操作:
在代码中transposed_conv_official函数是使用官方的转置卷积进行计算,transposed_conv_self函数是按照上面讲的步骤自己对输入特征图进行填充并通过卷积得到的结果。
import torch
import torch.nn as nn
def transposed_conv_official():
feature_map = torch.as_tensor([[1, 0],
[2, 1]], dtype=torch.float32).reshape([1, 1, 2, 2])
print(feature_map)
trans_conv = nn.ConvTranspose2d(in_channels=1, out_channels=1,
kernel_size=3, stride=1, bias=False)
trans_conv.load_state_dict({"weight": torch.as_tensor([[1, 0, 1],
[0, 1, 1],
[1, 0, 0]], dtype=torch.float32).reshape([1, 1, 3, 3])})
print(trans_conv.weight)
output = trans_conv(feature_map)
print(output)
def transposed_conv_self():
feature_map = torch.as_tensor([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 2, 1, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]], dtype=torch.float32).reshape([1, 1, 6, 6])
print(feature_map)
conv = nn.Conv2d(in_channels=1, out_channels=1,
kernel_size=3, stride=1, bias=False)
conv.load_state_dict({"weight": torch.as_tensor([[0, 0, 1],
[1, 1, 0],
[1, 0, 1]], dtype=torch.float32).reshape([1, 1, 3, 3])})
print(conv.weight)
output = conv(feature_map)
print(output)
def main():
transposed_conv_official()
print("---------------")
transposed_conv_self()
if __name__ == '__main__':
main()
输出结果
tensor([[[[1., 0.],
[2., 1.]]]])
Parameter containing:
tensor([[[[1., 0., 1.],
[0., 1., 1.],
[1., 0., 0.]]]], requires_grad=True)
tensor([[[[1., 0., 1., 0.],
[2., 2., 3., 1.],
[1., 2., 3., 1.],
[2., 1., 0., 0.]]]], grad_fn=<SlowConvTranspose2DBackward>)
---------------
tensor([[[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 2., 1., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]]])
Parameter containing:
tensor([[[[0., 0., 1.],
[1., 1., 0.],
[1., 0., 1.]]]], requires_grad=True)
tensor([[[[1., 0., 1., 0.],
[2., 2., 3., 1.],
[1., 2., 3., 1.],
[2., 1., 0., 0.]]]], grad_fn=<ThnnConv2DBackward>)
Process finished with exit code 0
DCGAN
论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks