Dropout 是一种能够有效缓解过拟合的正则化技术,被广泛应用于深度神经网络当中。但是被 dropout 所丢掉的位置都有助于缓解过拟合的吗?
中山大学 和 Meta AI 在 NeurIPS 2022 接收的论文在研究了注意力中的 dropout 后发现:不同注意力位置对过拟合的作用并不一致,如果丢弃了不恰当的位置甚至会加速过拟合。基于这一发现,我们提出了一种归因驱动的 Dropout(AD-DROP),该方法选择高归因的位置进行 Drop,从而实现更具针对性的 dropout。

论文标题:
AD-DROP: Attribution-Driven Dropout for Robust Language Model Fine-Tuning
论文链接:
https://arxiv.org/abs/2210.05883
代码链接:
GitHub - TaoYang225/AD-DROP: Source code of NeurIPS 2022 accepted paper "AD-DROP: Attribution-Driven Dropout for Robust Language Model Fine-Tuning"

介绍
本文涉及两个方面的背景知识:1)Dropout;2)归因分析(Attribution)。
- Dropout [1]:原始的 dropout 以一定的概率随机地从网络中选取部分神经元丢弃,使得神经元之间不能协同适应,从而提升网络的泛化性能,达到缓解过拟合的目的。在 dropout 的基础上,衍生了许多变体,如:Concrete Dropout,DropBlock,AutoDropout,Mixout,R-Drop 等。但是许多的工作都遵循了 dropout 的固有模式,即以一定的采样概率随机地采样子结构进行丢弃。
- Attribution [2]:归因是一种可解释的方法,旨在将模型的输出归结到输入特征上,为输入特征分配不同的分数,以衡量不同输入特征对模型最终预测的贡献程度。常见的归因方法包括基于扰动的 [3]、基于注意力的 [4]、基于梯度的。其中基于梯度的方法又包括:梯度本身 [5]、输入乘梯度 [6] 、积分梯度 [7] 等。
虽然随机采样的 dropout 被证明是一种能够有效缓解过拟合的手段,但是现有的工作缺乏深入地探究这些所丢弃的 units 对缓解过拟合的作用。在这项工作中,我们结合自注意力归因 [8] 来尝试研究这一问题。
前置实验
自注意力归因可以为注意力位置分配不同的归因分数(代表对预测的贡献程度,通常认为归因分数越高,对预测越重要)。那么一个自然而言的想法就是:如果按归因分数的大小来丢掉注意力位置,会发生什么?因此,我们在三个数据集(MRPC/SST-2/QNLI)上做了一个实验(附录B):
1. 首先微调好一个 roberta-base 模型;
2. 然后,在验证集上,计算注意力每个位置的归因分数(注意:为了计算方便,直接采用梯度本身,而非积分梯度,实验中发现积分梯度也有一致的现象;此外,采用真实标签对应的逻辑输出进行归因。)
3. 设置不同的比例,把注意力矩阵中每一行中的位置,按“归因分数低到高/归因分数高到低”的位置通过添加 attention mask 来 drop 掉,结果如下:
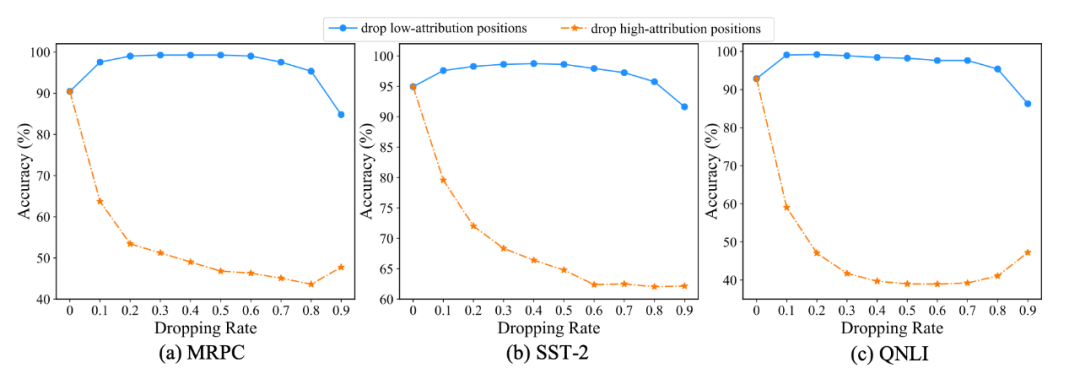
在三个数据集上,观察到了几乎一致的现象:
1. 从低到高 drop,一开始模型会快速拟合标签(接近 100% 准确率),随后趋势保持平稳,最后由于丢弃掉过多的信息准确率大幅度的下降;
2. 从高到低 drop,模型性能首先快速下降,随后趋势变缓,最后由于丢弃掉过多的信息可能存在一个上升趋势。可以理解:基于真实标签的梯度归因“泄露”了标签信息,从而使得丢弃掉归因分数“低/高”的位置可以快速“拟合/远离”真实标签。这一实验恰恰说明,不同注意力位置的作用是不一致的。
上述实验是基于微调好的模型做的,为了进一步验证这两种 mask 策略对模型训练的影响,我们在训练过程中也应用了两种 mask 策略,并与原始微调和随机 Dropout 比较(具体实现细节见论文 2.2 节),结果如下:
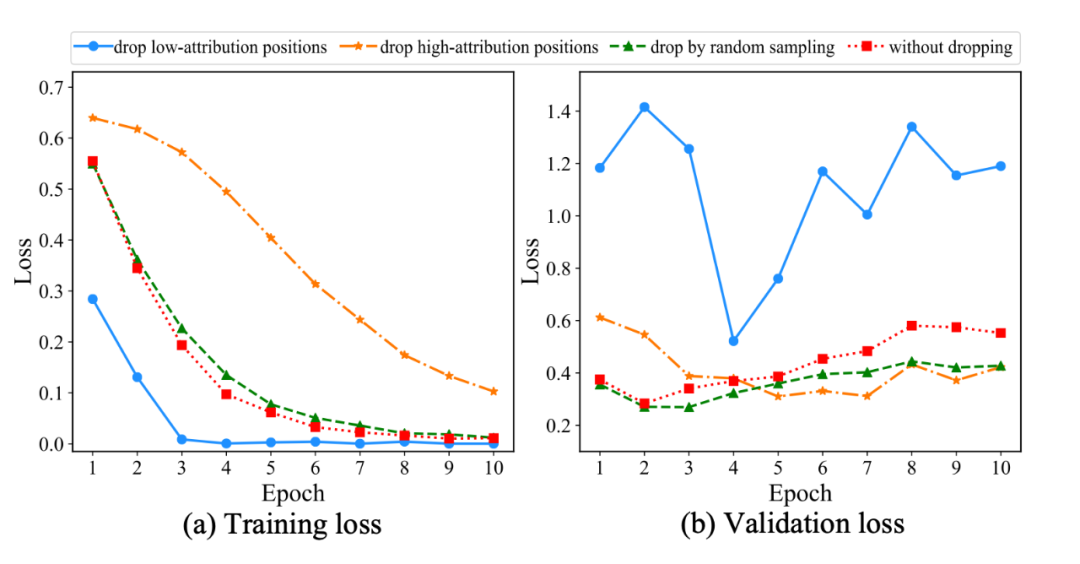
▲ MRPC中训练集与验证集的loss曲线,除红色线外,丢弃率设置为0.3
红色线代表不施加注意力的 dropout(原始微调)。绿色线为施加随机 dropout,与红色线相比,轻微缓解了过拟合,验证集的最小 loss 更低;蓝色线代表 drop 掉 30% 低归因的位置,可以看到模型快速过拟合训练集,但是在验证集上没有收敛(loss 震荡)。
黄色线代表 drop 掉 30% 高归因的位置,与红色线和绿色线相比,这种策略显著降低了模型的收敛速度,同时验证集能正常收敛,但是验证集最小 loss 要略高于红色线和绿色线(存在欠拟合)。上述实验说明:
- 不同注意力位置对过拟合的作用并不一致,如果丢弃了不恰当的位置甚至会加速过拟合;
- 缓解过拟合的方向是 drop 高归因的位置,但同时需要防止产生欠拟合。

方法
3.1 AD-DROP
基于上述发现,我们设计了一种新的 dropout 模式:AD-DROP(Attribution-Driven Dropout)。AD-DROP 与原生 dropout 的区别如下:
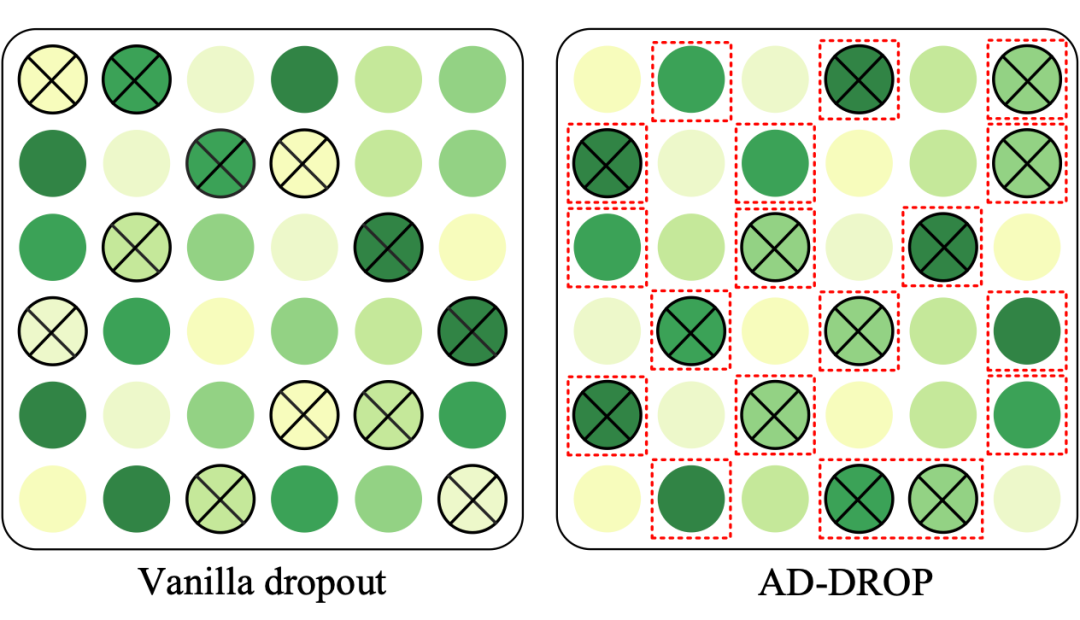
▲ 原生 dropout 与 AD-DROP 的注意力图比较,位置颜色越深代表归因分数越大,位置交叉的圆圈代表被 drop 的位置,红色框线代表高归因的候选丢弃区域(如Top-3)
原始 dropout 在每一行中随机的丢弃位置,高归因与低归因位置的丢弃率相同;而 AD-DROP 中,首先选定一个高归因分数的候选区域,然后从中再随机的 drop(施加随机的好处在于,不至于丢弃全部的高归因信息,导致缺乏必要的预测信息无法收敛)。AD-DROP 关注于 drop 高归因的区域,以达到缓解过拟合的目的,实现过程包含如下四个步骤:
▲ AD-DROP的实现步骤
- 在每一个 batch 中,对于输入 x ,首先经过第一次前向计算,得到模型的预测输出,将预测概率最大的类别作为伪标签。
- 计算伪标签对应的逻辑输出对每一个注意力矩阵的梯度/积分梯度,得到归因矩阵 。
- 在归因矩阵中,每一行选取归因分数最高的 p 部分(比例值)作为候选丢弃区域;然后以概率为 q 的随机 dropout 应用于候选丢弃区域,产生 mask 矩阵。
- 进行第二次前向计算,此时加入得到的 mask 矩阵,计算出 loss 用于最终的参数更新。
这里采用伪标签进行归因的原因有两点:1)如果采用真实标签归因会泄露标签信息,并导致训练和推理不一致;2)AD-DROP 的目的是抑制模型对当前预测而言高归因位置的依赖,可能能够纠正预测错误的样本。
3.2 交叉微调
我们进一步设计了一种交叉微调(Cross-tuning)策略,以防止在应用 AD-DROP 时,高归因的位置被过度丢弃,从而提升训练的稳定性。交叉微调策略即交替执行原始的微调 epoch 与带有 AD-DROP 的 epoch。算法如下:


实验和分析
我们主要在 GLUE 基准上验证了 AD-DROP 的有效性,并做了许多的消融分析实验。
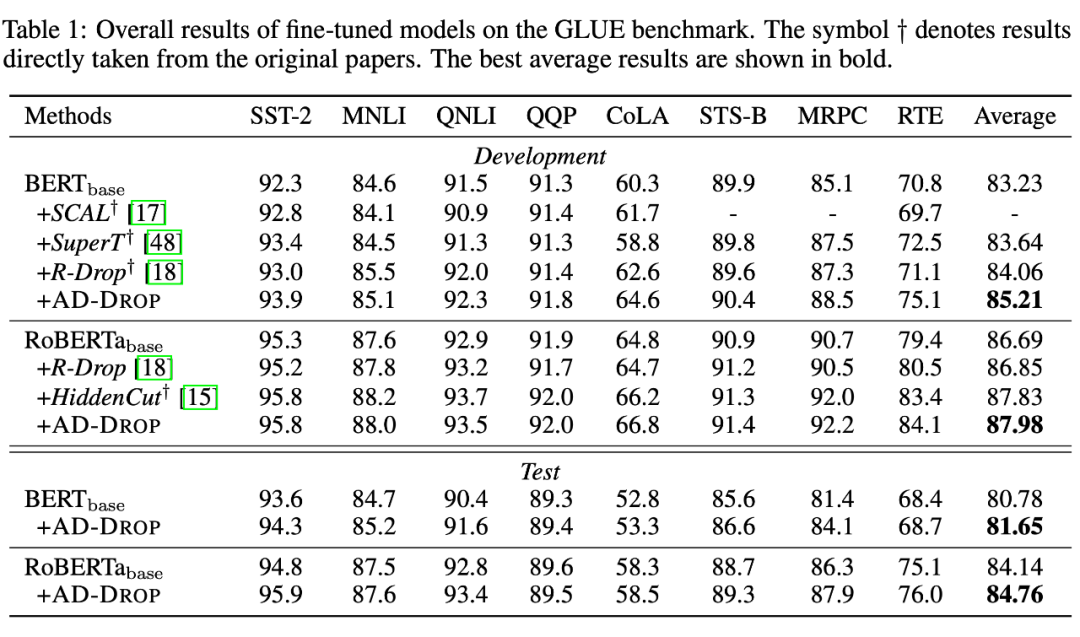
- 总体实验结果:在验证集上,AD-DROP 在 BERT 和 RoBERTa 上平均提升了 1.98 和 1.29 个点;在测试集上,AD-DROP 在 BERT 和 RoBERTa 上平均提升了 0.87 和 0.62 个点。
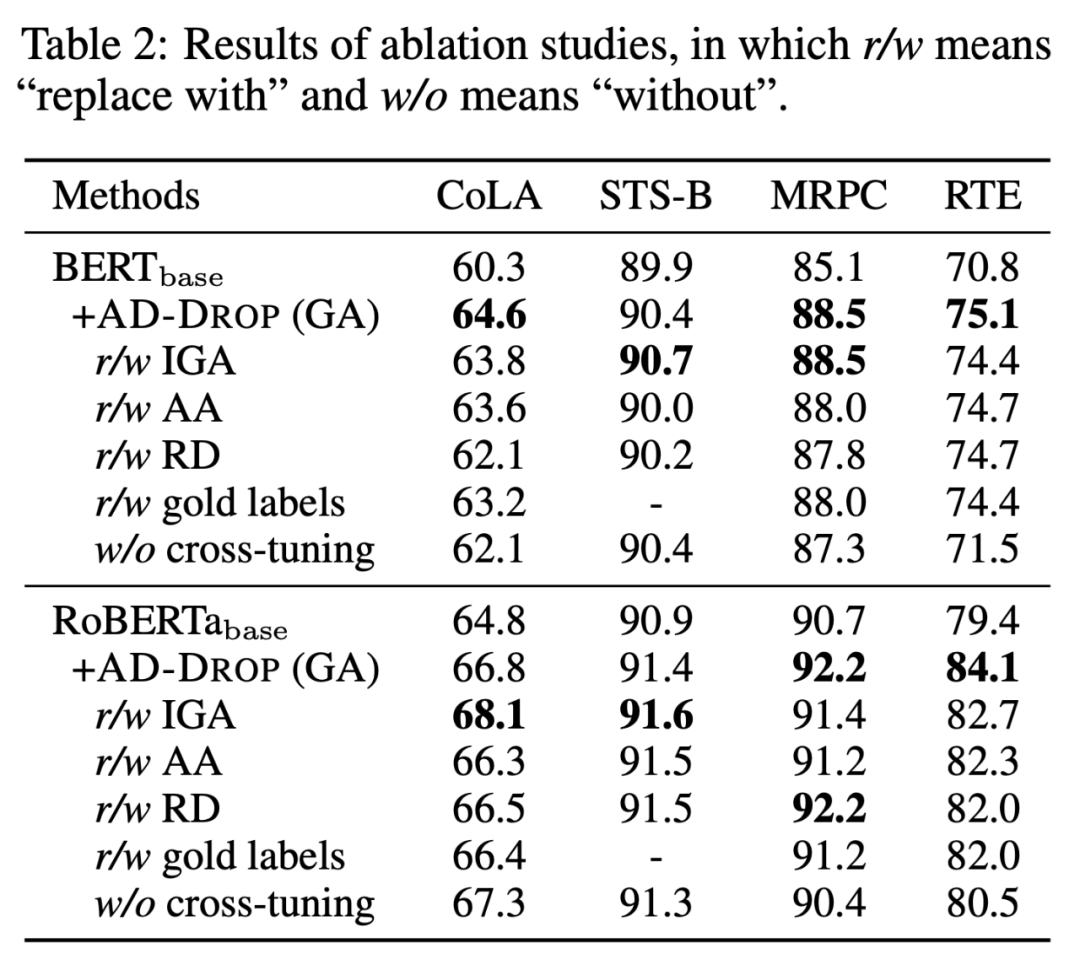
- 消融实验:对比了不同算归因的方式(梯度 GA、积分梯度 IGA、注意力 AA、随机 RA),发现梯度相关的归因要好于其他的方式;此外伪标签要好于真实标签;交叉微调要好于不加交叉微调。
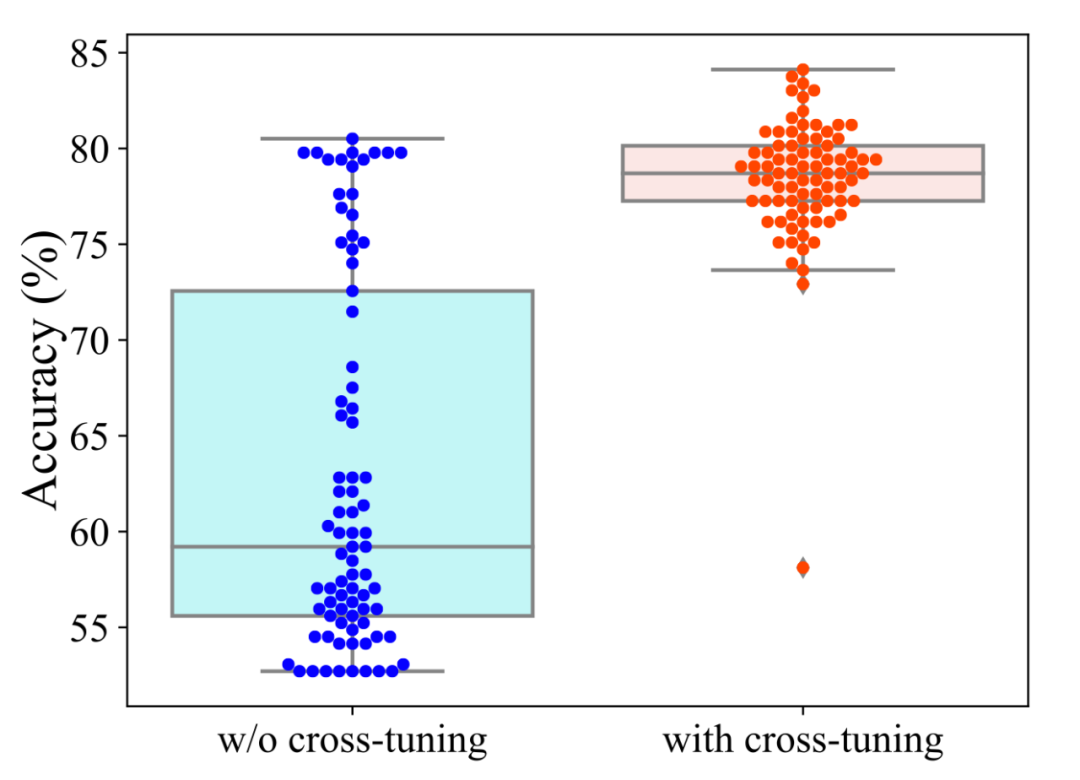
- 交叉微调的影响:在两个关键参数 p 和 q 的搜索范围 [0.1,0.9] 内,观察验证集结果的分布情况,交叉微调可以显著提升 AD-DROP 在不同参数下的有效性。
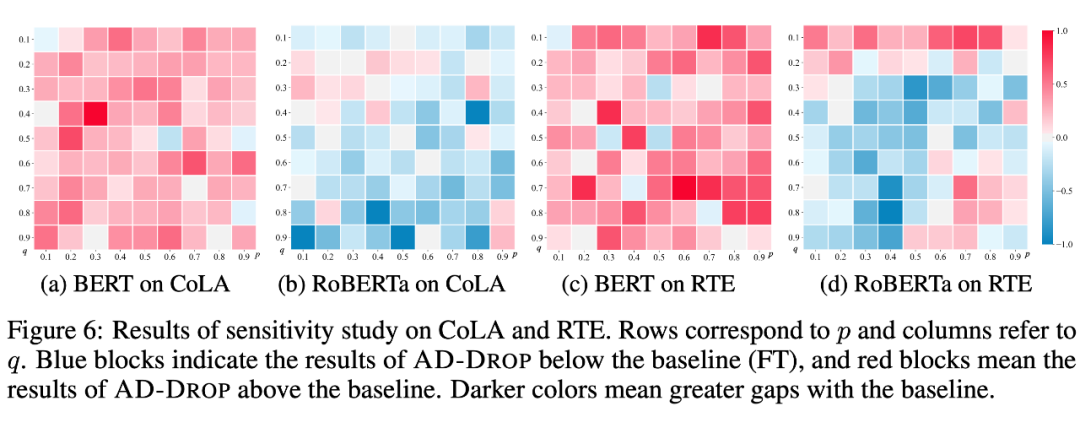
- 参数的敏感性分析:在搜索范围内,将 AD-DROP 对比原始微调结果的差异归一化后进行可视化,发现 AD-DROP 在 BERT 上对引入的两个超参数不敏感,大部分情况下都能 work,而在 RoBERTa 上则需要仔细的参数搜索,猜测原因可能是 RoBERTa 进行了更有效地预训练,更不容易产生过拟合。
此外还做了重复性实验、数据量的影响、小样本场景、大模型的影响等。这里就不一 一详细介绍了,感兴趣的朋友请移步原文查看。