📖 前言:在网络安全防护领域,防火墙是保护网络安全的一种最常用的设备。网络管理员希望通过在网络边界合理使用防火墙,屏蔽源于外网的各类网络攻击。但是,防火墙由于自身的种种限制,并不能阻止所有攻击行为。入侵检测(intrusion detection)通过实时收集和分析计算机网络或系统中的各种信息,来检查是否出现违反安全策略的行为和遭到攻击的迹象,进而达到预防、阻止攻击的目的,是防火墙的有力补充。而网络欺骗则是在网络中设置用来引诱入侵者的目标,将入侵者引向这些错误的目标来保护真正的系统,同时监控、记录、识别、分析入侵者的所有行为。本章主要介绍入侵检测和网络欺骗的基本概念和工作原理。

目录
- 🕒 1. 入侵检测概述
- 🕒 2. 入侵检测方法
- 🕘 2.1 特征检测
- 🕤 2.1.1 模式匹配法
- 🕤 2.1.2 专家系统法
- 🕤 2.1.3 状态迁移法
- 🕘 2.2 异常检测(误用检测)
- 🕤 2.2.1 统计分析法
- 🕤 2.2.2 人工免疫法
- 🕤 2.2.3 机器学习法
- 🕤 2.2.4 小结
- 🕒 3. Snort简介
- 🕒 4. 网络欺骗(Cyber Deception)
- 🕘 4.1 蜜罐
- 🕘 4.2 蜜网
- 🕘 4.3 防御
🕒 1. 入侵检测概述
定义:通过从计算机系统或网络的关键点收集信息并进行分析,从中发现系统或网络中是否有违反安全策略的行为和被攻击的迹象。
根据检测方法来分:
- 基于特征的入侵检测
- 基于异常的入侵检测
- 混合的入侵检测
根据数据源来分:
- 基于应用的入侵检测系统(Application-based IDS, AIDS)
- 基于主机的入侵检测系统(Host-based IDS, HIDS)
- 基于网络的入侵检测系统(Network-based IDS, NIDS)
- 混合的入侵检测系统(Hybrid IDS)
NIDS:
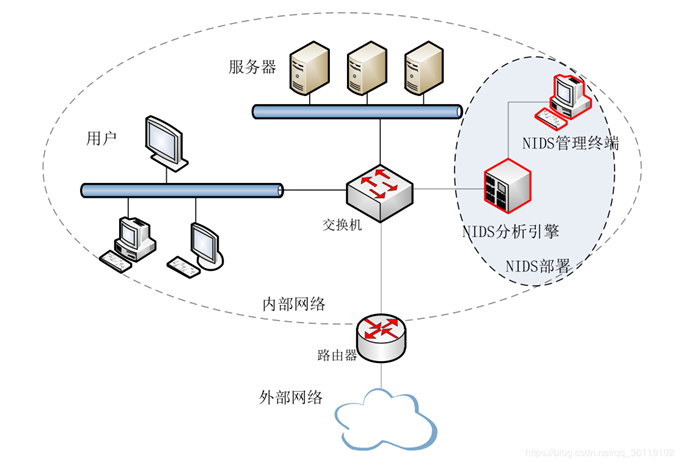
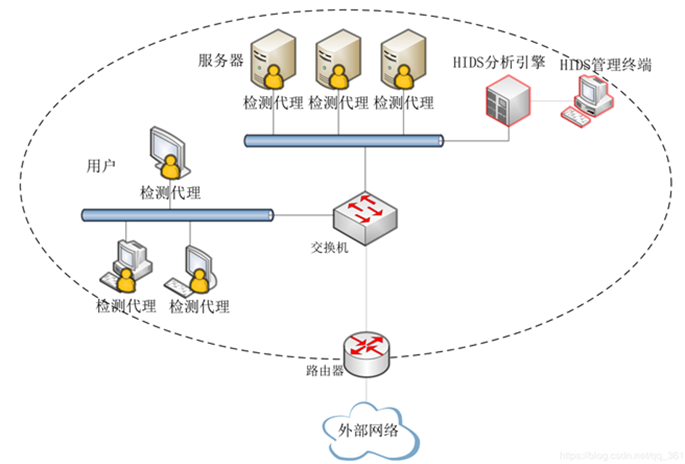
HIDS:
🕒 2. 入侵检测方法
🕘 2.1 特征检测
定义:收集非正常操作的行为特征(signature),建立相关的特征库,当监测的用户或系统行为与库中的记录相匹配时,系统就认为这种行为是入侵。
特征:
- 静态特征:如病毒或者木马的散列值、端口号、IP地址、域名等
- 动态特征:如网络统计数据、计算机或应用系统中的审计记录、日志、文件的异常变化、硬盘、内存大小的变化
- 特征描述:描述语言
特征检测针对的是已知攻击,检测率取决于:攻击特征库的正确性与完备性
🕤 2.1.1 模式匹配法
将收集到的入侵特征转换成模式,存放在模式数据库中。检测过程中将收集到的数据信息与模式数据库进行匹配,从而发现攻击行为。
模式匹配的具体实现手段多种多样,可以是通过字符串匹配寻找特定的指令数据,也可以是采用正规的数学表达式描述数据负载内容。技术成熟,检测的准确率和效率都很高
🕤 2.1.2 专家系统法
入侵活动被编码成专家系统的规则:“If 条件 Then 动作”的形式。入侵检测系统根据收集到的数据,通过条件匹配判断是否出现了入侵并采取相应动作。
实现上较为简单,其缺点主要是处理速度比较慢,原因在于专家系统采用的是说明性的表达方式,要求用解释系统来实现,而解释器比编译器的处理速度慢。另外,维护规则库也需要大量的人力精力,由于规则之间具有联系性,更改任何一个规则都要考虑对其他规则的影响。
🕤 2.1.3 状态迁移法
利用状态转换图描述并检测已知的入侵模式。入侵检测系统保存入侵相关的状态转换图表,并对系统的状态信息进行监控,当用户动作驱动系统状态向入侵状态迁移时触发入侵警告。
状态迁移法能够检测出多方协同的慢速攻击,但是如果攻击场景复杂的话,要精确描述系统状态非常困难。因此,状态迁移法通常与其他的入侵检测法结合使用。
🕘 2.2 异常检测(误用检测)
定义:首先总结正常操作应该具有的特征(用户轮廓),当用户活动与正常行为有重大偏离时即被认为是入侵。
行为:需要一组能够标识用户特征、网络特征或者系统特征的测量参数,如CPU利用率、内存利用率、网络流量等等。基于这组测量参数建立被监控对象的行为模式并检测对象的行为变化。
两个关键问题:
- 选择的各项测量参数能否反映被监控对象的行为模式。
- 如何界定正常和异常。
数据源评价
正常行为的学习依赖于学习数据的质量,但如何评估数据的质量呢?
可以利用信息论的熵、条件熵、相对熵和信息增益等概念来定量地描述一个数据集的特征,分析数据源的质量。
定义1:给定数据集合 X X X, 对任意 x ∈ C x x ∈C_x x∈Cx, 定义熵 H ( X ) H(X) H(X)为:
H ( X ) = ∑ x ∈ C x P ( x ) log 1 P ( x ) H(X)=\sum_{x \in C x} P(x) \log \frac{1}{P(x)} H(X)=x∈Cx∑P(x)logP(x)1
在数据集中,每个唯一的记录代表一个类,熵越小,数据也就越规则,根据这样的数据集合建立的模型的准确性越好。
定义2:定义条件熵
H
(
X
∣
Y
)
H(X | Y)
H(X∣Y)为:
H
(
X
∣
Y
)
=
∑
x
,
y
∈
C
x
,
C
y
P
(
x
,
y
)
log
1
P
(
x
∣
y
)
H(X \mid Y)=\sum_{x, y \in C_{x}, C_{y}} P(x, y) \log \frac{1}{P(x \mid y)}
H(X∣Y)=x,y∈Cx,Cy∑P(x,y)logP(x∣y)1
其中, P ( x , y ) P(x, y) P(x,y)为 x x x 和 y y y 的联合概率, P ( x ∣ y ) P(x | y) P(x∣y)为给定 y y y时 x x x 的条件概率。安全审计数据通常都具有时间上的序列特征,条件熵可以用来衡量这种特征,按照上面的定义,令 X = ( e 1 , e 2 , … , e n ) X=(e_1, e_2, …, e_n) X=(e1,e2,…,en),令 Y = ( e 1 , e 2 , … , e k ) Y=(e_1, e_2, …, e_k) Y=(e1,e2,…,ek),其中 k < n k<n k<n,条件熵 H ( X ∣ Y ) H(X | Y) H(X∣Y)可以衡量在给定 Y Y Y以后,剩下的 X X X的不确定性还有多少。条件熵越小,表示不确定性越小,从而通过已知预测未知的可靠性越大。
案例:系统调用系列与LSM监控点系列
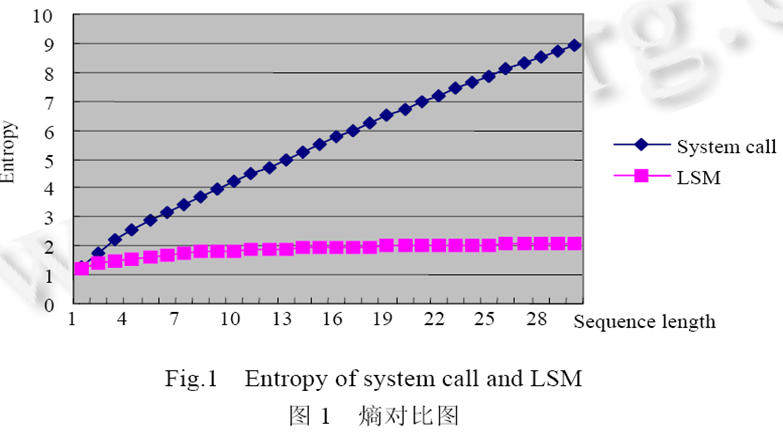
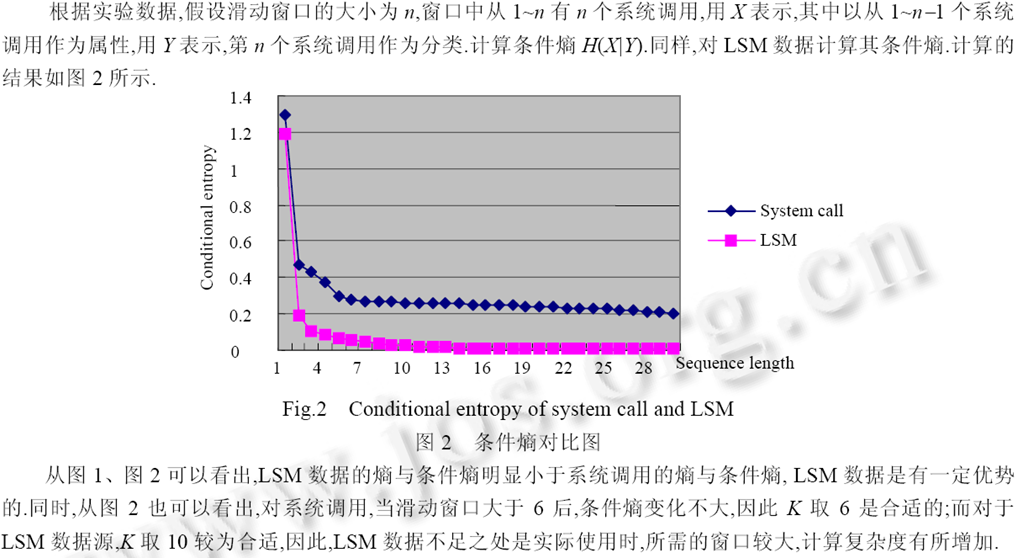
🔎 软件学报,2005, 16(6):张衡,卞洪流,吴礼发等,基于LSM的程序行为控制研究
🕤 2.2.1 统计分析法
以统计理论为基础建立用户或者系统的正常行为模式。主体的行为模式常常由测量参数的频度、概率分布、均值、方差等统计量来描述。抽样周期可以短到几秒钟长至几个月。
异常:将用户的短期特征轮廓与长期特征轮廓进行比较,如果偏差超过设定的阈值,则认为用户的近期活动存在异常。
入侵判定思路较为简单,但是在具体实现时误报率和漏报率都较高,此外,对于存在时间顺序的复杂攻击活动,统计分析法难以准确描述。
常用统计模型
- 操作模型,对某个时间段内事件的发生次数设置一个阈值,如果事件变量X出现的次数超过阈值,就有可能是异常;
- 平均值和标准差模型
- 巴尔科夫过程模型,状态迁移矩阵
统计分析法要解决四个问题
- 选取有效的统计数据测量点,生成能够反映主机特征的会话向量。
- 根据主体活动产生的审计记录,不断更新当前主体活动的会话向量。
- 采用统计方法分析数据,判断当前活动是否符合主体的历史行为特征。
- 随着时间变化,学习主体的行为特征,更新历史记录。
🕤 2.2.2 人工免疫法
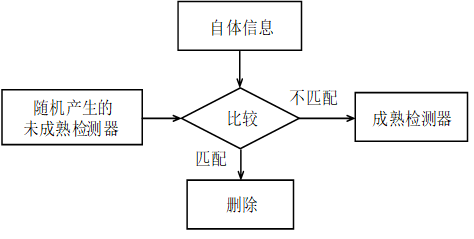
将非法程序及非法应用与合法程序、合法数据区分开来,与人工免疫系统对自体和非自体进行类别划分相类似。 Forrest采用监控系统进程的方法实现了Unix平台的人工免疫入侵检测系统。
🕤 2.2.3 机器学习法
机器学习异常检测方法通过机器学习模型或算法对离散数据序列进行学习来获得个体、系统和网络的行为特征,从而实现攻击行为的检测。
什么是异常?
- 在大多数异常检测场景里,异常指与大部分其他对象不同的对象
- 异常(离群点)可以分类三类:
- 全局离群点:指一个数据对象显著偏离数据集中的其余对象
- 情境离群点:对于某个特定情境,这个对象显著偏离其他对象
- 集体离群点:数据对象的一个子集作为整体显著偏离整个数据集
异常检测:指出给定的输入样本 { X i } i = 1 n \{X_i\}_{i=1}^{n} {Xi}i=1n中包含的异常值
- 有监督异常检测:如果是给定了带正常值或异常值标签的数据,异常检测可以看作是监督学习的分类问题。
- 无监督异常检测:不提供任何带标签数据
- 弱监督异常检测:在训练样本 { X i } i = 1 n \{X_i\}_{i=1}^{n} {Xi}i=1n中附加正常值样本集 { y j } j = 1 m \{y_j\}_{j=1}^{m} {yj}j=1m,进行更高精度的异常检测
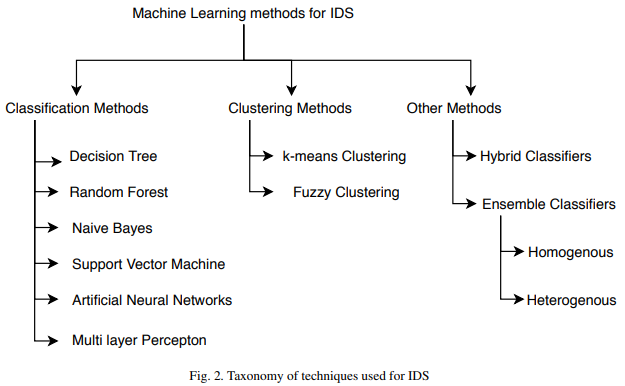
根据模型本身的特点进行分类,大致可以分为以下几种:
- 统计检验方法
- 基于深度的方法
- 基于偏差的方法
- 基于距离的方法
- 基于密度的方法
- 深度学习方法
🔎 A Review of the Advancement in Intrusion Detection Datasets
🕤 2.2.4 小结
异常检测(误用检测)
- 可以检测未知攻击!
- 不在预定义的合法行为集中,就一定是攻击吗?
- 检测率取决于:正常行为模式的正确性与完备性以及监控的频率
- 系统能针对用户行为的改变进行自我调整和优化,但随着检测模型的逐步精确,检测过程会消耗更多的系统资源
两种方法比较
- 检测的攻击类型:已知与未知
- 特征:已知攻击特征与已知正常行为特征
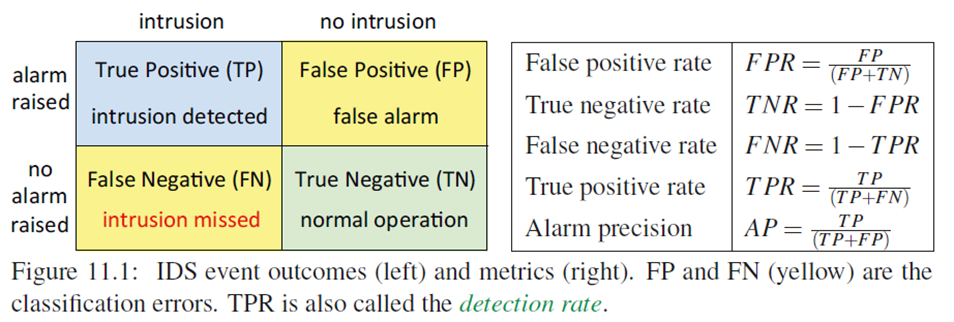
- 性能:误报率(rate of false positive)与漏报率(rate of false negative)
- 对每种方法,各在何种情况下发生误报、漏报?
| 特征检测 | 异常检测 |
|---|---|
| 通过进行上下文分析有效识别已知攻击 | 检测未知攻击和漏洞以及已知攻击 |
| 它依赖于系统软件和操作系统来识别攻击和漏洞 | 它较少依赖于操作系统,而是检查网络模式来识别攻击 |
| 攻击签名数据库应定期更新 | 它构建观察网络通信的档案以识别攻击模式 |
| 特征检测的IDS对协议的了解最少 | 异常检测的IDS执行协议分析以研究数据包详细信息 |
评价指标:
🕒 3. Snort简介

Snort是采用C语言编写的一款开源基于网络的入侵检测系统,具有小巧灵活、配置简便、功能强大、检测效率高等特点。Snort主要采用特征检测的工作方式,通过预先设置的检测规则对网络数据包进行匹配,发现各种类型的网络攻击
Snort由三个模块组成:数据包解析器、检测引擎、日志与报警子系统
- 网络数据包首先交给数据包解析器进行解析处理,处理结果提交给检测引擎与用户设定的检测规则进行匹配。在此基础上,检测引擎的输出交给日志与报警子系统处理,日志与报警子系统将依据系统设置,记录数据包信息或者发出警报。
在snort中有五种动作:alert、log、pass、activate和dynamic
- Alert:产生告警,然后记录数据包信息
- Log:记录数据包信息
- Pass:忽略数据包
- activate:报警并且激活另一条dynamic规则
- dynamic:保持空闲直到被一条activate规则激活,被激活后就作为一条log规则执行。
规则选项组成了Snort入侵检测引擎的核心
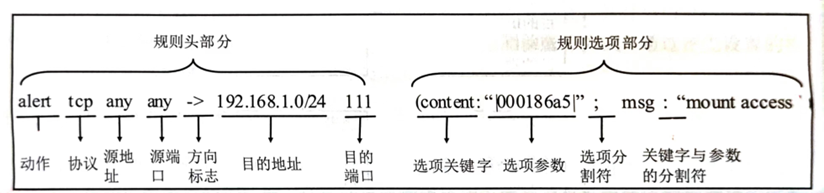
规则选项:
msg:在报警和包日志中打印一个消息
flags:检查tcp flags的值。
在snort中有8个标志变量:
- F- FIN
- S-SYN
- R-RST
- P-PSH
- A- ACK
- U-URG
- 2- Reserved bit 2
- 1 - Reserved bit
content:在包的净荷中搜索指定的样式。它可以包含混合的文本和二进制数据。
二进制数据一般包含在管道符号中|,表示为字节码。
所有的Snort规则选项用分号;隔开。规则选项关键字和它们的参数用冒号:分开。
🕒 4. 网络欺骗(Cyber Deception)
最早由美国普渡大学的 Gene Spafford 于1989年提出,它的核心思想是:采用引诱或欺骗战略,诱使入侵者相信网络与信息系统中存在有价值的、可利用的安全弱点,并具有一些可攻击窃取的资源(当然这些资源是伪造的或不重要的),进而将入侵者引向这些错误的资源,同时安全可靠地记录入侵者的所有行为,以便全面地了解攻击者的攻击过程和使用的攻击技术。
网络欺骗用途
- 吸引攻击流量,影响入侵者使之按照防护方的意志进行行动
- 检测入侵者的攻击并获知其攻击技术和意图,对入侵行为进行告警和取证,收集攻击样本
- 增加入侵拖延攻击者攻击真实目标者的工作量、入侵复杂度以及不确定性,为网络防护提供足够的信息来了解入侵者,这些信息可以用来强化现有的安全措施
🕘 4.1 蜜罐
蜜罐(Honeypot)是最早采用欺骗技术的网络安全系统。
定义:蜜罐是一种安全资源,其价值在于被探测、攻击或突破
目标:就是使它被扫描探测、攻击或被突破,同时能够很好地进行安全控制
按照实现方式可将蜜罐分为物理蜜罐和虚拟蜜罐
- 物理蜜罐:安装真实操作系统和应用服务的计算机系统,通过开放容易受攻击的端口、留下漏洞来诱惑攻击者
- 虚拟蜜罐:在物理主机上安装蜜罐软件使其模拟不同类型的系统和服务,一套物理主机可以由多个虚拟蜜罐
根据交互程度或逼真程度的高低可以分为低交互蜜罐、中交互蜜罐和高交互蜜罐
- 低交互蜜罐:一个低交互的蜜罐可以用来模拟一个标准的Linux服务器,运行FTP、SMTP和TELNET等服务。
- 通常使用一个交互脚本进行实现,按照交互脚本对攻击者的请求进行响应。
- 比如:攻击者可以通过远程连接到这个蜜罐,然后通过猜测或暴力破解进行登录尝试,攻击者与蜜罐的交互仅限于登录尝试,并不能登录到这个系统。
- 高交互蜜罐:提供真实的或接近真实的网络服务,还有一套安全监控系统,隐蔽记录攻击者的所有行为。
- 通常模拟一个网络服务的所有功能。如FTP蜜罐完整实现FTP协议,Telnet蜜罐完整地实现Telnet协议
- 中交互蜜罐:介于低交互蜜罐与高交互蜜罐之间。模拟实现一个网络服务或设备的大部分功能,包括漏洞模拟
低交互蜜罐的功能相对简单,一般包括:
- 攻击数据捕获与处理,在一个或多个协议服务端口上监听,当有攻击数据到来时捕获并处理这些攻击数据,必要的时候还需给出响应,将处理后的攻击数据记录到本地日志,同时向平台服务端(如果有的话)实时推送;
- 攻击行为分析,对攻击日志进行多个维度(协议维,时间维,地址维等)的统计分析,发现攻击行为规律,并用可视化方法展示分析结果
高交互蜜罐的功能相对复杂,一般包括:
- 网络欺骗:对蜜罐进行伪装,使它在被攻击者扫描时表现为网络上的真实主机
- 空间欺骗技术:伪装创建整个内网
- 网络流量仿真:伪造与其他主机交互,将内网流量复制重现或用一定规则自动生成流量
- 网络动态配置:配置动态的网络路由信息
- 多重地址转换:使用代理服务功能进行地址转换
- 创建组织信息欺骗:如邮件服务器伪造邮件往来
- 攻击捕获:采集攻击者对网络实施攻击的相关信息,通过分析捕获的信息,可以研究攻击者所利用的系统漏洞,获取新的攻击方式,甚至是0 day攻击。难点是要在防止被攻击者识破的情况下尽可能多地记录下系统状态信息,还有通信加密问题
- 数据控制:限制蜜罐向外发起的连接,确保蜜罐不会成为攻击者的跳板
- 数据分析:对蜜罐采集到的信息进行多个维度(协议维,时间维,地址维,代码维等)的统计分析,发现攻击行为规律,并用可视化方法展示分析结果
经过多年的发展,有很多商用或开源的蜜罐项目,如honeyd, The Honeynet Project, 狩猎女神,Specter, Mantrap等。开源软件平台gitbub上可以找到大量各种类型的蜜罐(https://github.com/paralax/awesome-honeypots/blob /master/ README_CN.md给出了一个比较完整的蜜罐资源列表及网络链接),如数据库类蜜罐(如HoneyMysql,MongoDB等)、Web类蜜罐(如Shadow Daemon,StrutsHoneypot, WebTrap等)、服务类蜜罐(如Honeyprint, SMB Honeypot, honeyntp, honeyprint等)、工业控制类蜜罐(如Conpot, Gaspot, SCADA Honeynet, gridpot)
🔎 如何发现蜜罐?
🕘 4.2 蜜网
蜜网(Honeynet)是由多个蜜罐组成的欺骗网络,蜜网中通常包含不同类型的蜜罐,可以在多个层面捕获攻击信息,以满足不同的安全需求
蜜网既可以用多个物理蜜罐来构建,也可以由多个虚拟蜜罐组成。目前,通过虚拟化技术(如VMware)可以方便地把多个虚拟蜜罐部署在单个服务器主机上
🕘 4.3 防御
网络欺骗防御是一种体系化的防御方法,它将蜜罐、蜜网、混淆等欺骗技术同防火墙、入侵检测系统等传统防护机制有机结合起来,构建以欺骗为核心的网络安全防御体系
Garter对网络欺骗防御(Cyber Deception Defense)的定义为:使用骗局或者假动作来阻挠或者推翻攻击者的认知过程,扰乱攻击者的自动化工具,延迟或阻断攻击者的活动,通过使用虚假的响应、有意的混淆、假动作、误导等伪造信息达到“欺骗”的目的
根据网络空间欺骗防御的作用位置不同,可以将其分为不同的层次,包括:
- 网络层欺骗
- 终端层欺骗
- 应用层欺骗
- 数据层欺骗
国内外已有一些网络欺骗防御产品:
- TrapX Security的DeceptionGrid
- DARPA的Prattle
- 美国Sandia国家实验室的Hades
- 长亭科技2016年推出基于欺骗伪装技术的内网威胁感知系统谛听(D-Sensor)
- 幻阵是我国默安科技研发的一款基于攻击混淆与欺骗防御技术的威胁检测防御系统
🔎 智能蜜罐DeepDig:把黑客变成免费渗透测试服务人员
🔎 用蜜罐检测 Kerberoasting 攻击
OK,以上就是本期知识点“入侵检测与网络欺骗”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页