机器学习笔记之条件随机场——学习任务介绍
- 引言
- 回顾:条件随机场求解边缘概率分布
- 场景设计
- 前向后向算法
- 关于条件随机场的学习任务
- 关于模型参数 λ \lambda λ求解梯度
- 梯度求解
- 梯度的简化过程
- 总结
引言
上一节介绍了使用前向后向算法求解基于链式条件随机场中某隐状态的边缘概率分布,本节将介绍条件随机场中模型参数的学习任务。
回顾:条件随机场求解边缘概率分布
场景设计
条件随机场使用的数据集合是一个序列信息。以词性标注为例,已知数据集合
X
\mathcal X
X以及对应的序列标注标签
Y
\mathcal Y
Y表示如下:
其中
T
T
T表示序列长度。
X
=
{
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
N
)
}
Y
=
{
y
(
1
)
,
y
(
2
)
,
⋯
,
y
(
N
)
}
x
(
i
)
,
y
(
i
)
∈
R
T
;
i
=
1
,
2
,
⋯
,
N
\begin{aligned} \mathcal X = \{x^{(1)},x^{(2)},\cdots,x^{(N)}\} \\ \mathcal Y = \{y^{(1)},y^{(2)},\cdots,y^{(N)}\} \\ x^{(i)},y^{(i)} \in \mathbb R^T;i=1,2,\cdots,N \end{aligned}
X={x(1),x(2),⋯,x(N)}Y={y(1),y(2),⋯,y(N)}x(i),y(i)∈RT;i=1,2,⋯,N
推断任务中的边缘概率分布的求解问题即:模型给定的条件下,对于陌生样本序列
x
1
:
T
x_{1:T}
x1:T,求解其词性标注序列某一时刻结果
y
t
y_t
yt的条件概率:
这里设定隐状态的取值是‘离散型随机变量’,如[名词,动词,形容词,副词,...],它的取值集合用
K
\mathcal K
K表示。
P
(
y
t
=
j
∣
x
1
:
T
)
{
t
∈
{
1
,
2
,
⋯
T
}
j
∈
K
=
{
1
,
2
,
⋯
,
K
}
\mathcal P(y_t=j \mid x_{1:T}) \begin{cases} t \in \{1,2,\cdots T\} \\ j \in \mathcal K = \{1,2,\cdots,\mathcal K\} \end{cases}
P(yt=j∣x1:T){t∈{1,2,⋯T}j∈K={1,2,⋯,K}
前向后向算法
前向后向算法(Forward-Backward Algorithm)对应概率图模型描述表示如下:
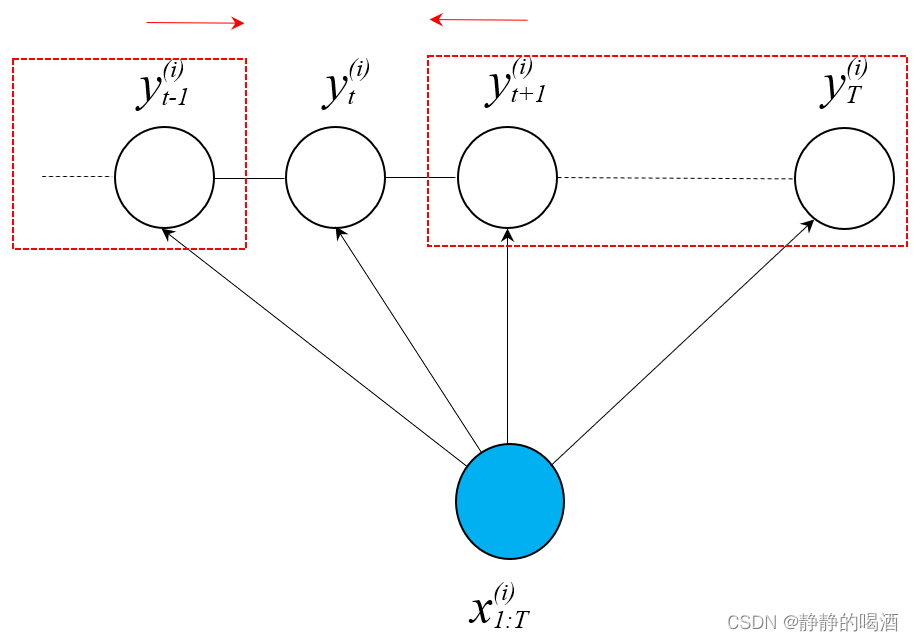
将
P
(
y
t
∣
x
1
:
T
)
\mathcal P(y_t \mid x_{1:T})
P(yt∣x1:T)的因子分解求解过程划分为两部分:
其中
Z
\mathcal Z
Z表示配分函数~
P
(
y
t
∣
x
1
:
T
)
=
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
+
1
,
⋯
,
y
T
1
Z
∏
t
=
1
T
−
1
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
)
=
1
Z
[
∑
y
1
,
⋯
y
t
−
1
∏
i
=
1
t
−
1
ψ
i
(
y
i
,
y
i
+
1
,
x
1
:
T
)
]
⋅
[
∑
y
t
+
1
,
⋯
,
y
T
∏
i
=
t
T
−
1
ψ
i
(
y
i
,
y
i
+
1
,
x
1
:
T
)
]
=
1
Z
Δ
l
e
f
t
⋅
Δ
r
i
g
h
t
\begin{aligned} \mathcal P(y_t \mid x_{1:T}) & = \sum_{y_1,\cdots,y_{t-1}} \sum_{y_{t+1},\cdots,y_T}\frac{1}{\mathcal Z} \prod_{t=1}^{T-1} \psi_t(y_t,y_{t+1},x_{1:T}) \\ & = \frac{1}{\mathcal Z} \left[\sum_{y_1,\cdots y_{t-1}} \prod_{i=1}^{t-1}\psi_i(y_i,y_{i+1},x_{1:T})\right] \cdot \left[\sum_{y_{t+1},\cdots,y_T} \prod_{i=t}^{T-1} \psi_i(y_i,y_{i+1},x_{1:T})\right] \\ & = \frac{1}{\mathcal Z} \Delta_{left} \cdot \Delta_{right} \end{aligned}
P(yt∣x1:T)=y1,⋯,yt−1∑yt+1,⋯,yT∑Z1t=1∏T−1ψt(yt,yt+1,x1:T)=Z1[y1,⋯yt−1∑i=1∏t−1ψi(yi,yi+1,x1:T)]⋅[yt+1,⋯,yT∑i=t∏T−1ψi(yi,yi+1,x1:T)]=Z1Δleft⋅Δright
对于链式条件随机场,无论前向还是后向,它们都可以用变量消去法(Variable Elimination,VE)的方式进行化简:
Δ
l
e
f
t
=
α
t
(
k
)
=
∑
y
t
−
1
ψ
t
−
1
(
y
t
−
1
,
y
t
=
k
,
x
1
:
T
)
⋯
∑
y
2
ψ
2
(
y
2
,
y
3
,
x
1
:
T
)
∑
y
1
ψ
1
(
y
1
,
y
2
,
x
1
:
T
)
Δ
r
i
g
h
t
=
β
t
(
m
)
=
∑
y
t
+
1
ψ
t
(
y
t
=
m
,
y
t
+
1
,
x
1
:
T
)
∑
y
t
+
2
ψ
t
+
1
(
y
t
+
1
,
y
t
+
2
,
x
1
:
T
)
⋯
∑
y
T
ψ
T
−
1
(
y
T
−
1
,
y
T
,
x
1
:
T
)
\begin{aligned} \Delta_{left} = \alpha_t(k) & = \sum_{y_{t-1}} \psi_{t-1}(y_{t-1},y_t = k,x_{1:T}) \cdots \sum_{y_2}\psi_2(y_2,y_3,x_{1:T})\sum_{y_1}\psi_1(y_1,y_2,x_{1:T}) \\ \Delta_{right} = \beta_t(m) & = \sum_{y_{t+1}} \psi_t(y_t = m,y_{t+1},x_{1:T}) \sum_{y_{t+2}} \psi_{t+1}(y_{t+1},y_{t+2},x_{1:T})\cdots \sum_{y_T} \psi_{T-1}(y_{T-1},y_T,x_{1:T}) \end{aligned}
Δleft=αt(k)Δright=βt(m)=yt−1∑ψt−1(yt−1,yt=k,x1:T)⋯y2∑ψ2(y2,y3,x1:T)y1∑ψ1(y1,y2,x1:T)=yt+1∑ψt(yt=m,yt+1,x1:T)yt+2∑ψt+1(yt+1,yt+2,x1:T)⋯yT∑ψT−1(yT−1,yT,x1:T)
关于条件随机场的学习任务
在条件随机场要解决的任务中介绍了学习任务本质是求解最优模型参数
θ
^
\hat {\theta}
θ^,而判别标准是
P
(
Y
∣
X
)
\mathcal P(\mathcal Y\mid \mathcal X)
P(Y∣X):
集合
X
,
Y
\mathcal X,\mathcal Y
X,Y中的各样本均服从‘独立同分布’。
θ
^
=
arg
max
θ
P
(
Y
∣
X
)
=
arg
max
θ
∏
i
=
1
N
P
(
y
(
i
)
∣
x
(
i
)
)
\begin{aligned} \hat {\theta} & = \mathop{\arg\max}\limits_{\theta} \mathcal P(\mathcal Y \mid \mathcal X) \\ & = \mathop{\arg\max}\limits_{\theta} \prod_{i=1}^{N} \mathcal P(y^{(i)} \mid x^{(i)}) \end{aligned}
θ^=θargmaxP(Y∣X)=θargmaxi=1∏NP(y(i)∣x(i))
在建模对象的表示中,模型参数
θ
\theta
θ共包含两个部分:
λ
,
η
\lambda,\eta
λ,η。它门分别表示转移特征函数
s
(
y
t
+
1
,
y
t
,
x
1
:
T
)
s(y_{t+1},y_t,x_{1:T})
s(yt+1,yt,x1:T)和状态特征函数
g
(
y
t
,
x
1
:
T
)
g(y_t,x_{1:T})
g(yt,x1:T)的参数信息。
θ
=
(
λ
,
η
)
T
=
(
λ
1
,
⋯
,
λ
M
,
η
1
,
⋯
,
η
L
)
T
\begin{aligned} \theta & = (\lambda,\eta)^T & = (\lambda_1,\cdots,\lambda_{\mathcal M},\eta_1,\cdots,\eta_{\mathcal L})^T \end{aligned}
θ=(λ,η)T=(λ1,⋯,λM,η1,⋯,ηL)T
对应建模对象
P
(
y
∣
x
)
\mathcal P(y \mid x)
P(y∣x)表示如下:
其中
P
(
y
∣
x
)
\mathcal P(y \mid x)
P(y∣x)中
x
,
y
x,y
x,y分别表示数据集合
X
\mathcal X
X中的任意样本以及对应标注信息,这里
x
x
x和
x
1
:
T
x_{1:T}
x1:T等价。
P
(
y
∣
x
)
=
1
Z
(
x
1
:
T
,
λ
,
η
)
exp
[
λ
T
∑
t
=
1
T
−
1
s
(
y
t
,
y
t
+
1
,
x
1
:
T
)
+
η
T
∑
t
=
1
T
g
(
y
t
,
x
1
:
T
)
]
\mathcal P(y \mid x) = \frac{1}{\mathcal Z(x_{1:T},\lambda,\eta)} \exp \left[\lambda^T \sum_{t=1}^{T-1} s(y_{t},y_{t+1},x_{1:T}) + \eta^T \sum_{t=1}^Tg(y_t,x_{1:T})\right]
P(y∣x)=Z(x1:T,λ,η)1exp[λTt=1∑T−1s(yt,yt+1,x1:T)+ηTt=1∑Tg(yt,x1:T)]
对最优参数
θ
^
\hat {\theta}
θ^进行细分,并将
x
(
i
)
,
y
(
i
)
x^{(i)},y^{(i)}
x(i),y(i)代入有:
在展开过程中加入一个
l
o
g
log
log,和极大似然估计的思路相同,
l
o
g
log
log函数不影响函数的单调性,因而不影响最优参数的选择。
θ
^
⇒
λ
^
,
η
^
=
arg
max
λ
,
η
∏
i
=
1
N
P
(
y
(
i
)
∣
x
(
i
)
)
⇒
arg
max
λ
,
η
[
log
∏
i
=
1
N
P
(
y
(
i
)
∣
x
(
i
)
)
]
=
arg
max
λ
,
η
∑
i
=
1
N
log
P
(
y
(
i
)
∣
x
(
i
)
)
=
arg
max
λ
,
η
∑
i
=
1
N
log
{
1
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
exp
[
λ
T
∑
t
=
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
+
η
T
∑
t
=
1
T
g
(
y
t
(
i
)
,
x
1
:
T
(
i
)
)
]
}
\begin{aligned} \hat {\theta} \Rightarrow \hat \lambda,\hat {\eta} & = \mathop{\arg\max}\limits_{\lambda,\eta} \prod_{i=1}^N \mathcal P(y^{(i)} \mid x^{(i)}) \\ & \Rightarrow \mathop{\arg\max}\limits_{\lambda,\eta} \left[\log \prod_{i=1}^N \mathcal P(y^{(i)} \mid x^{(i)})\right] \\ & = \mathop{\arg\max}\limits_{\lambda,\eta} \sum_{i=1}^N \log \mathcal P(y^{(i)} \mid x^{(i)}) \\ & = \mathop{\arg\max}\limits_{\lambda,\eta} \sum_{i=1}^N \log\left\{\frac{1}{\mathcal Z(x_{1:T}^{(i)},\lambda,\eta)} \exp \left[\lambda^T\sum_{t=1}^{T-1}s(y_t^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) + \eta^T \sum_{t=1}^T g(y_t^{(i)},x_{1:T}^{(i)})\right]\right\} \end{aligned}
θ^⇒λ^,η^=λ,ηargmaxi=1∏NP(y(i)∣x(i))⇒λ,ηargmax[logi=1∏NP(y(i)∣x(i))]=λ,ηargmaxi=1∑NlogP(y(i)∣x(i))=λ,ηargmaxi=1∑Nlog{Z(x1:T(i),λ,η)1exp[λTt=1∑T−1s(yt(i),yt+1(i),x1:T(i))+ηTt=1∑Tg(yt(i),x1:T(i))]}
继续对上式进行展开,有:
log
\log
log和
exp
\exp
exp消掉了~
λ
^
,
η
^
=
arg
max
λ
,
η
∑
i
=
1
N
[
log
1
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
+
log
exp
(
λ
T
∑
t
=
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
+
η
T
∑
t
=
1
T
g
(
y
t
(
i
)
,
x
1
:
T
(
i
)
)
)
]
=
arg
max
λ
,
η
∑
i
=
1
N
[
−
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
+
λ
T
∑
t
=
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
+
η
T
∑
i
=
1
T
g
(
y
t
(
i
)
,
x
1
:
T
(
i
)
)
]
\begin{aligned} \hat {\lambda},\hat {\eta} & = \mathop{\arg\max}\limits_{\lambda,\eta} \sum_{i=1}^N \left[\log \frac{1}{\mathcal Z(x_{1:T}^{(i)},\lambda,\eta)} + \log \exp \left(\lambda^T\sum_{t=1}^{T-1} s(y_t^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) + \eta^T\sum_{t=1}^T g(y_t^{(i)},x_{1:T}^{(i)})\right)\right]\\ & = \mathop{\arg\max}\limits_{\lambda,\eta} \sum_{i=1}^N\left[-\log \mathcal Z\left(x_{1:T}^{(i)},\lambda,\eta\right) + \lambda^T \sum_{t=1}^{T-1} s(y_t^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) + \eta^T \sum_{i=1}^T g(y_t^{(i)},x_{1:T}^{(i)}) \right] \end{aligned}
λ^,η^=λ,ηargmaxi=1∑N[logZ(x1:T(i),λ,η)1+logexp(λTt=1∑T−1s(yt(i),yt+1(i),x1:T(i))+ηTt=1∑Tg(yt(i),x1:T(i)))]=λ,ηargmaxi=1∑N[−logZ(x1:T(i),λ,η)+λTt=1∑T−1s(yt(i),yt+1(i),x1:T(i))+ηTi=1∑Tg(yt(i),x1:T(i))]
定义目标函数
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\mathcal J(\lambda,\eta,x_{1:T}^{(i)})
J(λ,η,x1:T(i))表示如下:
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
=
∑
i
=
1
N
[
−
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
+
λ
T
∑
t
=
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
+
η
T
∑
i
=
1
T
g
(
y
t
(
i
)
,
x
1
:
T
(
i
)
)
]
λ
^
,
η
^
=
arg
max
λ
,
η
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\mathcal J(\lambda,\eta,x_{1:T}^{(i)}) = \sum_{i=1}^N\left[-\log \mathcal Z\left(x_{1:T}^{(i)},\lambda,\eta\right) + \lambda^T \sum_{t=1}^{T-1} s(y_t^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) + \eta^T \sum_{i=1}^T g(y_t^{(i)},x_{1:T}^{(i)}) \right] \\ \hat {\lambda},\hat \eta = \mathop{\arg\max}\limits_{\lambda,\eta} \mathcal J(\lambda,\eta,x_{1:T}^{(i)})
J(λ,η,x1:T(i))=i=1∑N[−logZ(x1:T(i),λ,η)+λTt=1∑T−1s(yt(i),yt+1(i),x1:T(i))+ηTi=1∑Tg(yt(i),x1:T(i))]λ^,η^=λ,ηargmaxJ(λ,η,x1:T(i))
针对 最大化问题,常用的方法:梯度上升(Gradient Ascent)。
- 需要针对目标函数
J
\mathcal J
J关于
λ
,
η
\lambda,\eta
λ,η求解梯度:
∇ λ J ( λ , η , x 1 : T ( i ) ) , ∇ η ( λ , η , x 1 : T ( i ) ) \begin{aligned} \nabla_{\lambda} \mathcal J(\lambda,\eta,x_{1:T}^{(i)}),\nabla_{\eta}(\lambda,\eta,x_{1:T}^{(i)}) \end{aligned} ∇λJ(λ,η,x1:T(i)),∇η(λ,η,x1:T(i)) - 模型参数在迭代过程中向梯度方向变化,从而逼近最优解:
λ ( k + 1 ) = λ k + d λ ⋅ ∇ λ J ( λ ( k ) , η ( k ) , x 1 : T ( i ) ) η ( k + 1 ) = η k + d η ⋅ ∇ η J ( λ ( k ) , η ( k ) , x 1 : T ( i ) ) \begin{aligned} \lambda^{(k+1)} = \lambda^{k} + d_{\lambda} \cdot \nabla_{\lambda} \mathcal J(\lambda^{(k)},\eta^{(k)},x_{1:T}^{(i)}) \\ \eta^{(k+1)} = \eta^{k} + d_{\eta} \cdot \nabla_{\eta} \mathcal J(\lambda^{(k)},\eta^{(k)},x_{1:T}^{(i)}) \end{aligned} λ(k+1)=λk+dλ⋅∇λJ(λ(k),η(k),x1:T(i))η(k+1)=ηk+dη⋅∇ηJ(λ(k),η(k),x1:T(i))
关于模型参数 λ \lambda λ求解梯度
以求解 λ \lambda λ为例,求解步骤如下:
梯度求解
求解梯度
∇
λ
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\nabla_{\lambda}\mathcal J(\lambda,\eta,x_{1:T}^{(i)})
∇λJ(λ,η,x1:T(i)):
观察
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\mathcal J(\lambda,\eta,x_{1:T}^{(i)})
J(λ,η,x1:T(i)),其中
∑
i
=
1
T
η
T
g
(
y
t
(
i
)
,
x
1
:
T
(
i
)
)
\sum_{i=1}^T \eta^Tg(y_t^{(i)},x_{1:T}^{(i)})
∑i=1TηTg(yt(i),x1:T(i))与
λ
\lambda
λ无关。同理,对
η
\eta
η求解梯度
∇
η
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\nabla_{\eta}\mathcal J(\lambda,\eta,x_{1:T}^{(i)})
∇ηJ(λ,η,x1:T(i))过程中,
∑
t
=
1
T
−
1
λ
T
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
\sum_{t=1}^{T-1} \lambda^Ts(y_t^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)})
∑t=1T−1λTs(yt(i),yt+1(i),x1:T(i))与
η
\eta
η无关,本文仅对
λ
\lambda
λ进行梯度求解。
∇
λ
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
=
∑
i
=
1
N
[
∑
t
−
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
−
∇
λ
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
\begin{aligned} \nabla_{\lambda}\mathcal J(\lambda,\eta,x_{1:T}^{(i)}) = \sum_{i=1}^N \left[\sum_{t-1}^{T-1} s(y_{t}^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) - \nabla_{\lambda} \log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] \end{aligned}
∇λJ(λ,η,x1:T(i))=i=1∑N[t−1∑T−1s(yt(i),yt+1(i),x1:T(i))−∇λlogZ(x1:T(i),λ,η)]
其中
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)
logZ(x1:T(i),λ,η)被称作对数配分函数(log Partition Function)。最早在指数族分布介绍中出现的概念。在指数族分布——充分统计量与模型参数关系中介绍了 对数配分函数的导数与充分统计量之间的关联关系:
A
′
(
η
)
=
∂
A
(
η
)
∂
η
=
∫
x
1
e
A
(
η
)
⋅
h
(
x
)
e
η
T
ϕ
(
x
)
⋅
ϕ
(
x
)
d
x
=
∫
x
P
(
x
∣
η
)
⋅
ϕ
(
x
)
d
x
=
E
P
(
x
∣
η
)
[
ϕ
(
x
)
]
\begin{aligned} \mathcal A'(\eta) = \frac{\partial \mathcal A(\eta)}{\partial \eta} & = \int_{x} \frac{1}{e^{\mathcal A(\eta)}} \cdot h(x)e^{\eta^T \phi(x)} \cdot \phi(x) dx \\ & = \int_{x} \mathcal P(x \mid \eta) \cdot \phi(x) dx \\ & = \mathbb E_{\mathcal P(x \mid \eta)}[\phi(x)] \end{aligned}
A′(η)=∂η∂A(η)=∫xeA(η)1⋅h(x)eηTϕ(x)⋅ϕ(x)dx=∫xP(x∣η)⋅ϕ(x)dx=EP(x∣η)[ϕ(x)]
其中,
A
(
η
)
\mathcal A(\eta)
A(η)表示对数配分函数;
ϕ
(
x
)
\phi(x)
ϕ(x)表示样本
x
x
x的充分统计量;
P
(
x
∣
η
)
\mathcal P(x\mid \eta)
P(x∣η)(也有写作
P
(
x
;
η
)
\mathcal P(x;\eta)
P(x;η)) 表示
x
x
x服从的概率分布。
需要注意的是:
在条件随机场的学习任务中将‘对数配分函数’写成log Z ( x 1 : T ( i ) , λ , η ) \log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta) logZ(x1:T(i),λ,η)的形式,但实际上,x 1 : T ( i ) x_{1:T}^{(i)} x1:T(i)仅表示已知的观测变量(样本数据),并不是‘对数配分函数’的变量,变量只有λ , η \lambda,\eta λ,η两个。在‘建模对象’P ( y ( i ) ∣ x ( i ) ) \mathcal P(y^{(i)} \mid x^{(i)}) P(y(i)∣x(i))中,某一具体样本x ( i ) x^{(i)} x(i)的充分统计量该如何表示?回顾‘建模对象’P ( y ∣ x ) \mathcal P(y \mid x) P(y∣x)的展开式:
P ( y ∣ x ) = 1 Z ( x 1 : T , λ , η ) exp [ λ T ∑ t = 1 T − 1 s ( y t , y t + 1 , x 1 : T ) + η T ∑ t = 1 T g ( y t , x 1 : T ) ] = { 1 Z ( x 1 : T , λ , η ) exp [ λ T ( ∑ t = 1 T − 1 s ( y t , y t + 1 , x 1 : T ) ) ] } ⋅ exp [ η T ∑ t = 1 T g ( y t , x 1 : T ) ] \begin{aligned} \mathcal P(y \mid x) & = \frac{1}{\mathcal Z(x_{1:T},\lambda,\eta)} \exp \left[\lambda^T \sum_{t=1}^{T-1} s(y_{t},y_{t+1},x_{1:T}) + \eta^T \sum_{t=1}^Tg(y_t,x_{1:T})\right] \\ & = \left\{\frac{1}{\mathcal Z(x_{1:T},\lambda,\eta)} \exp \left[\lambda^T \left(\sum_{t=1}^{T-1} s(y_{t},y_{t+1},x_{1:T})\right)\right]\right\} \cdot \exp \left[\eta^T\sum_{t=1}^T g(y_t,x_{1:T})\right] \end{aligned} P(y∣x)=Z(x1:T,λ,η)1exp[λTt=1∑T−1s(yt,yt+1,x1:T)+ηTt=1∑Tg(yt,x1:T)]={Z(x1:T,λ,η)1exp[λT(t=1∑T−1s(yt,yt+1,x1:T))]}⋅exp[ηTt=1∑Tg(yt,x1:T)]
观察,由于条件随机场依然使用‘最大熵模型’作为底层逻辑,因此能够看出,{ \{ {大括号} \} }中的项就是‘最大熵模型’的描述形式。而最大熵模型的定义式就是从‘指数族分布’的定义式演化而来。详见最大熵定理与指数族分布的关系。因此,充分统计量就是∑ t = 1 T − 1 s ( y t , y t + 1 , x 1 : T ) \sum_{t=1}^{T-1} s(y_{t},y_{t+1},x_{1:T}) ∑t=1T−1s(yt,yt+1,x1:T).即便找到了充分统计量,并没有结束。因为我们要找的是x 1 : T ( i ) x_{1:T}^{(i)} x1:T(i)这个样本的充分统计量。在这里自然是对‘隐状态’y t , y t + 1 y_t,y_{t+1} yt,yt+1进行统计。看看y t , y t + 1 y_t,y_{t+1} yt,yt+1具体代表什么:
y t = ( y t ( 1 ) , y t ( 2 ) , ⋯ , y t ( N ) ) T y t + 1 = ( y t + 1 ( 1 ) , y t + 1 ( 2 ) , ⋯ , y t + 1 ( N ) ) T y_t = \left(y_t^{(1)},y_t^{(2)},\cdots,y_t^{(N)}\right)^T \\ y_{t+1} = \left(y_{t+1}^{(1)},y_{t+1}^{(2)},\cdots,y_{t+1}^{(N)}\right)^T yt=(yt(1),yt(2),⋯,yt(N))Tyt+1=(yt+1(1),yt+1(2),⋯,yt+1(N))T
通过上式,可以发现,统计的对象就是‘所有样本’在t , t + 1 t,t+1 t,t+1时刻的‘离散取值结果’,并进行统计。具体是怎么统计的,这并不是我们关注的重点。x 1 : T ( i ) x_{1:T}^{(i)} x1:T(i)样本的‘充分统计量’表示如下:
ϕ ( x 1 : T ( i ) ) = ∑ t = 1 T − 1 s ( y t , y t + 1 , x 1 : T ( i ) ) \phi(x_{1:T}^{(i)}) = \sum_{t=1}^{T-1}s(y_t,y_{t+1},x_{1:T}^{(i)}) ϕ(x1:T(i))=t=1∑T−1s(yt,yt+1,x1:T(i))
说了这么多,这里最重要的点即:y t , y t + 1 y_t,y_{t+1} yt,yt+1右上角没有样本编号,它表示所有样本t , t + 1 t,t+1 t,t+1时刻的隐状态集合,它和上面‘建模对象中的’y t , y t + 1 y_t,y_{t+1} yt,yt+1不是一个东西。建模对象的y t , y t + 1 y_t,y_{t+1} yt,yt+1中的y y y表示样本集合X \mathcal X X任意一个样本x x x对应的标注序列。
将对数配分函数的导数结果带入,有:
个人理解:在整个隐状态分布下求解期望。
∇
λ
[
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
=
E
Y
[
∑
t
=
1
T
−
1
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
Y
=
(
y
1
,
⋯
,
y
T
)
T
\nabla_{\lambda} \left[\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] = \mathbb E_{\mathcal Y}\left[\sum_{t=1}^{T-1}s(y_t,y_{t+1},x_{1:T}^{(i)})\right] \quad \mathcal Y = (y_1,\cdots,y_T)^T
∇λ[logZ(x1:T(i),λ,η)]=EY[t=1∑T−1s(yt,yt+1,x1:T(i))]Y=(y1,⋯,yT)T
接下来对上述期望结果进行求解:
E
Y
[
∑
t
=
1
T
−
1
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
=
∑
Y
P
(
Y
∣
x
1
:
T
(
i
)
)
[
∑
t
=
1
T
−
1
f
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
\begin{aligned} \mathbb E_{\mathcal Y}\left[\sum_{t=1}^{T-1}s(y_t,y_{t+1},x_{1:T}^{(i)})\right] = \sum_{\mathcal Y} \mathcal P(\mathcal Y \mid x_{1:T}^{(i)}) \left[\sum_{t=1}^{T-1}f(y_{t},y_{t+1},x_{1:T}^{(i)})\right] \end{aligned}
EY[t=1∑T−1s(yt,yt+1,x1:T(i))]=Y∑P(Y∣x1:T(i))[t=1∑T−1f(yt,yt+1,x1:T(i))]
观察一下计算该式的时间复杂度:
Y
\mathcal Y
Y包含
y
1
,
⋯
,
y
T
y_1,\cdots,y_T
y1,⋯,yT,并且每一个隐状态
y
t
(
t
=
1
,
2
,
⋯
,
T
)
y_t(t=1,2,\cdots,T)
yt(t=1,2,⋯,T)包含
∣
K
∣
|\mathcal K|
∣K∣个取值,因此时间复杂度为:
O
(
∣
K
∣
T
)
⋅
O
(
T
−
1
)
=
O
[
(
T
−
1
)
∣
K
∣
T
]
O(|\mathcal K|^T) \cdot O(T-1) = O[(T-1)|\mathcal K|^T]
O(∣K∣T)⋅O(T−1)=O[(T−1)∣K∣T]
可以看出,这个复杂度是指数级别的,极难求解。
梯度的简化过程
观察上式,
Y
\mathcal Y
Y和单个的
t
t
t无关,因此将
∑
Y
P
(
Y
∣
x
1
:
T
(
i
)
)
\sum_{\mathcal Y}\mathcal P(\mathcal Y \mid x_{1:T}^{(i)})
∑YP(Y∣x1:T(i))看成整体,
∑
t
=
1
T
−
1
\sum_{t=1}^{T-1}
∑t=1T−1提到前面:
∇
λ
[
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
=
∑
t
=
1
T
−
1
[
∑
Y
P
(
Y
∣
x
1
:
T
(
i
)
)
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
\nabla_{\lambda}\left[\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] = \sum_{t=1}^{T-1} \left[\sum_{\mathcal Y} \mathcal P(\mathcal Y \mid x_{1:T}^{(i)}) s(y_{t},y_{t+1},x_{1:T}^{(i)})\right]
∇λ[logZ(x1:T(i),λ,η)]=t=1∑T−1[Y∑P(Y∣x1:T(i))s(yt,yt+1,x1:T(i))]
将
∑
Y
\sum_{\mathcal Y}
∑Y拆成三部分:
∑
Y
=
∑
y
1
,
⋯
,
y
T
=
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
,
y
t
+
1
∑
y
t
+
2
,
⋯
,
y
T
\sum_{\mathcal Y} = \sum_{y_1,\cdots,y_T} = \sum_{y_1,\cdots,y_{t-1}} \sum_{y_{t},y_{t+1}} \sum_{y_{t+2},\cdots,y_{T}}
Y∑=y1,⋯,yT∑=y1,⋯,yt−1∑yt,yt+1∑yt+2,⋯,yT∑
交换一下顺序,最终结果表示如下:
其中,中括号中的项可以使用‘概率密度积分’的方式积分掉
Y
\mathcal Y
Y中的
y
1
,
⋯
,
y
t
−
1
,
y
t
+
2
,
⋯
,
y
T
y_1,\cdots,y_{t-1},y_{t+2},\cdots,y_T
y1,⋯,yt−1,yt+2,⋯,yT,只剩下
y
t
,
y
t
+
1
y_{t},y_{t+1}
yt,yt+1两项:
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
+
2
,
⋯
,
y
T
P
(
Y
∣
x
1
:
T
(
i
)
)
=
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
+
2
,
⋯
,
y
T
P
(
y
1
,
y
2
,
⋯
,
y
T
∣
x
1
:
T
(
i
)
)
=
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
\begin{aligned} \sum_{y_1,\cdots,y_{t-1}}\sum_{y_{t+2},\cdots,y_{T}}\mathcal P(\mathcal Y\mid x_{1:T}^{(i)}) & = \sum_{y_1,\cdots,y_{t-1}}\sum_{y_{t+2},\cdots,y_{T}}\mathcal P(y_1,y_2,\cdots,y_T\mid x_{1:T}^{(i)}) \\ & = \mathcal P(y_{t},y_{t+1} \mid x_{1:T}^{(i)}) \end{aligned}
y1,⋯,yt−1∑yt+2,⋯,yT∑P(Y∣x1:T(i))=y1,⋯,yt−1∑yt+2,⋯,yT∑P(y1,y2,⋯,yT∣x1:T(i))=P(yt,yt+1∣x1:T(i))
此时发现,化简后的结果就是关于
y
t
,
y
t
+
1
y_t,y_{t+1}
yt,yt+1的边缘概率分布(
x
1
:
T
(
i
)
x_{1:T}^{(i)}
x1:T(i)不是变量,是已知信息)。
∇
λ
[
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
=
∑
t
=
1
T
−
1
∑
y
t
,
y
t
+
1
[
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
+
2
,
⋯
,
y
T
P
(
Y
∣
x
1
:
T
(
i
)
)
⋅
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
=
∑
t
=
1
T
−
1
∑
y
t
,
y
t
+
1
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
⋅
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
\begin{aligned} \nabla_{\lambda}\left[\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] & = \sum_{t=1}^{T-1} \sum_{y_{t},y_{t+1}} \left[\sum_{y_1,\cdots,y_{t-1}}\sum_{y_{t+2},\cdots,y_{T}}\mathcal P(\mathcal Y\mid x_{1:T}^{(i)}) \cdot s(y_{t},y_{t+1},x_{1:T}^{(i)})\right] \\ & = \sum_{t=1}^{T-1} \sum_{y_{t},y_{t+1}} \mathcal P(y_t,y_{t+1} \mid x_{1:T}^{(i)}) \cdot s(y_{t},y_{t+1},x_{1:T}^{(i)}) \end{aligned}
∇λ[logZ(x1:T(i),λ,η)]=t=1∑T−1yt,yt+1∑[y1,⋯,yt−1∑yt+2,⋯,yT∑P(Y∣x1:T(i))⋅s(yt,yt+1,x1:T(i))]=t=1∑T−1yt,yt+1∑P(yt,yt+1∣x1:T(i))⋅s(yt,yt+1,x1:T(i))
观察上式,上式已经被化简成只包含
y
t
,
y
t
+
1
y_t,y_{t+1}
yt,yt+1两个变量的式子。
s
s
s是定义的特征函数,可求;
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
\mathcal P(y_t,y_{t+1} \mid x_{1:T}^{(i)})
P(yt,yt+1∣x1:T(i))使用前向后向算法进行求解。对应概率图表示如下:
由于求解两个隐状态整体的边缘分布,需要空出一个团来。
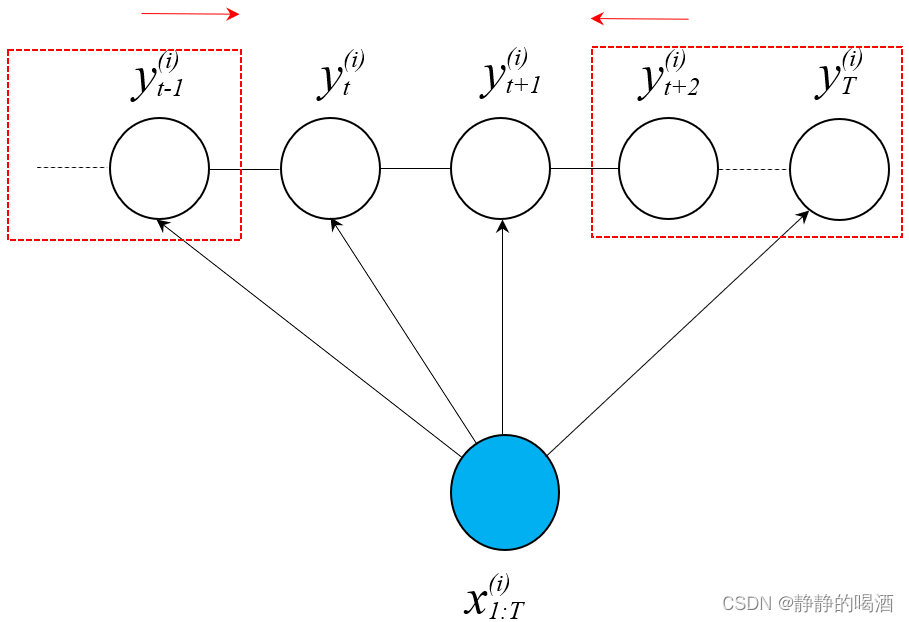
对应公式表示如下:
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
=
∑
y
1
,
⋯
,
y
t
−
1
∑
y
t
+
2
,
⋯
,
y
T
1
Z
∏
t
=
1
T
−
1
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
=
1
Z
{
[
∑
y
1
,
⋯
,
y
t
−
1
ψ
1
(
y
1
,
y
2
,
x
1
:
T
(
i
)
)
⋯
ψ
t
−
1
(
y
t
−
1
,
y
t
,
x
1
:
T
(
i
)
)
]
⋅
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
⋅
[
∑
y
t
+
2
,
⋯
,
y
T
ψ
t
+
1
(
y
t
+
1
,
y
t
+
2
,
x
1
:
T
(
i
)
)
⋯
ψ
T
−
1
(
y
T
−
1
,
y
T
,
x
1
:
T
(
i
)
)
]
}
=
1
Z
(
Δ
l
e
f
t
⋅
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
⋅
Δ
r
i
g
h
t
)
{
Δ
l
e
f
t
=
∑
y
1
ψ
1
(
y
1
,
y
2
,
x
1
:
T
(
i
)
)
⋯
∑
y
t
−
1
ψ
t
−
1
(
y
t
−
1
,
y
t
,
x
1
:
T
(
i
)
)
Δ
r
i
g
h
t
=
∑
t
t
+
2
ψ
t
+
1
(
y
t
+
1
,
y
t
+
2
,
x
1
:
T
(
i
)
)
⋯
∑
y
T
ψ
T
−
1
(
y
T
−
1
,
y
T
,
x
1
:
T
(
i
)
)
\begin{aligned} & \mathcal P(y_t,y_{t+1} \mid x_{1:T}^{(i)}) \\ & = \sum_{y_1,\cdots,y_{t-1}} \sum_{y_{t+2},\cdots,y_T} \frac{1}{\mathcal Z} \prod_{t=1}^{T-1}\psi_t(y_t,y_{t+1},x_{1:T}^{(i)}) \\ & = \frac{1}{\mathcal Z}\left\{\left[\sum_{y_1,\cdots,y_{t-1}} \psi_1(y_1,y_2,x_{1:T}^{(i)}) \cdots \psi_{t-1}(y_{t-1},y_t,x_{1:T}^{(i)})\right] \cdot \psi_{t}(y_t,y_{t+1},x_{1:T}^{(i)}) \cdot \left[\sum_{y_{t+2},\cdots,y_T}\psi_{t+1}(y_{t+1},y_{t+2},x_{1:T}^{(i)}) \cdots \psi_{T-1}(y_{T-1},y_{T},x_{1:T}^{(i)})\right]\right\} \\ & = \frac{1}{\mathcal Z} \left(\Delta_{left} \cdot \psi_{t}(y_t,y_{t+1},x_{1:T}^{(i)}) \cdot \Delta_{right}\right) \begin{cases} \Delta_{left} = \sum_{y_1}\psi_1(y_1,y_2,x_{1:T}^{(i)})\cdots \sum_{y_{t-1}} \psi_{t-1}(y_{t-1},y_t,x_{1:T}^{(i)}) \\ \Delta_{right} = \sum_{t_{t+2}} \psi_{t+1}(y_{t+1},y_{t+2},x_{1:T}^{(i)}) \cdots\sum_{y_{T}} \psi_{T-1}(y_{T-1},y_T,x_{1:T}^{(i)}) \end{cases} \end{aligned}
P(yt,yt+1∣x1:T(i))=y1,⋯,yt−1∑yt+2,⋯,yT∑Z1t=1∏T−1ψt(yt,yt+1,x1:T(i))=Z1{[y1,⋯,yt−1∑ψ1(y1,y2,x1:T(i))⋯ψt−1(yt−1,yt,x1:T(i))]⋅ψt(yt,yt+1,x1:T(i))⋅[yt+2,⋯,yT∑ψt+1(yt+1,yt+2,x1:T(i))⋯ψT−1(yT−1,yT,x1:T(i))]}=Z1(Δleft⋅ψt(yt,yt+1,x1:T(i))⋅Δright){Δleft=∑y1ψ1(y1,y2,x1:T(i))⋯∑yt−1ψt−1(yt−1,yt,x1:T(i))Δright=∑tt+2ψt+1(yt+1,yt+2,x1:T(i))⋯∑yTψT−1(yT−1,yT,x1:T(i))
设置
α
t
(
k
)
=
Δ
l
e
f
t
(
y
t
=
k
)
,
β
t
+
1
(
j
)
=
Δ
r
i
g
h
t
(
y
t
+
1
=
j
)
\alpha_t(k) = \Delta_{left}(y_t = k),\beta_{t+1}(j) = \Delta_{right}(y_{t+1} = j)
αt(k)=Δleft(yt=k),βt+1(j)=Δright(yt+1=j),则有:
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
=
1
Z
α
t
(
k
)
⋅
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
⋅
β
t
+
1
(
j
)
\mathcal P(y_t,y_{t+1} \mid x_{1:T}^{(i)}) = \frac{1}{\mathcal Z}\alpha_t(k) \cdot \psi_{t}(y_t,y_{t+1},x_{1:T}^{(i)}) \cdot\beta_{t+1}(j)
P(yt,yt+1∣x1:T(i))=Z1αt(k)⋅ψt(yt,yt+1,x1:T(i))⋅βt+1(j)
至此,关于
λ
\lambda
λ的梯度结果
∇
λ
[
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
\nabla_{\lambda}\left[\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right]
∇λ[logZ(x1:T(i),λ,η)]求解过程没有障碍:
∇
λ
[
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
=
∑
t
=
1
T
−
1
∑
y
t
,
y
t
+
1
P
(
y
t
,
y
t
+
1
∣
x
1
:
T
(
i
)
)
⋅
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
=
1
Z
∑
t
=
1
T
−
1
∑
y
t
,
y
t
+
1
α
t
(
k
)
⋅
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
⋅
β
t
+
1
(
j
)
⋅
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
\begin{aligned} \nabla_{\lambda}\left[\log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] & = \sum_{t=1}^{T-1} \sum_{y_{t},y_{t+1}} \mathcal P(y_t,y_{t+1} \mid x_{1:T}^{(i)}) \cdot s(y_{t},y_{t+1},x_{1:T}^{(i)}) \\ & = \frac{1}{\mathcal Z}\sum_{t=1}^{T-1} \sum_{y_t,y_{t+1}} \alpha_t(k) \cdot \psi_{t}(y_t,y_{t+1},x_{1:T}^{(i)}) \cdot\beta_{t+1}(j) \cdot s(y_{t},y_{t+1},x_{1:T}^{(i)}) \end{aligned}
∇λ[logZ(x1:T(i),λ,η)]=t=1∑T−1yt,yt+1∑P(yt,yt+1∣x1:T(i))⋅s(yt,yt+1,x1:T(i))=Z1t=1∑T−1yt,yt+1∑αt(k)⋅ψt(yt,yt+1,x1:T(i))⋅βt+1(j)⋅s(yt,yt+1,x1:T(i))
最终关于模型参数
λ
\lambda
λ的梯度
∇
λ
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
\nabla_{\lambda}\mathcal J(\lambda,\eta,x_{1:T}^{(i)})
∇λJ(λ,η,x1:T(i))结果表示如下:
∇
λ
J
(
λ
,
η
,
x
1
:
T
(
i
)
)
=
∑
i
=
1
N
[
∑
t
−
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
−
∇
λ
log
Z
(
x
1
:
T
(
i
)
,
λ
,
η
)
]
=
∑
i
=
1
N
[
∑
t
−
1
T
−
1
s
(
y
t
(
i
)
,
y
t
+
1
(
i
)
,
x
1
:
T
(
i
)
)
−
1
Z
∑
t
=
1
T
−
1
∑
y
t
,
y
t
+
1
α
t
(
k
)
⋅
ψ
t
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
⋅
β
t
+
1
(
j
)
⋅
s
(
y
t
,
y
t
+
1
,
x
1
:
T
(
i
)
)
]
\begin{aligned} \nabla_{\lambda}\mathcal J(\lambda,\eta,x_{1:T}^{(i)}) & = \sum_{i=1}^N \left[\sum_{t-1}^{T-1} s(y_{t}^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) - \nabla_{\lambda} \log \mathcal Z(x_{1:T}^{(i)},\lambda,\eta)\right] \\ & = \sum_{i=1}^N \left[\sum_{t-1}^{T-1} s(y_{t}^{(i)},y_{t+1}^{(i)},x_{1:T}^{(i)}) - \frac{1}{\mathcal Z}\sum_{t=1}^{T-1} \sum_{y_t,y_{t+1}} \alpha_t(k) \cdot \psi_{t}(y_t,y_{t+1},x_{1:T}^{(i)}) \cdot\beta_{t+1}(j) \cdot s(y_{t},y_{t+1},x_{1:T}^{(i)})\right] \end{aligned}
∇λJ(λ,η,x1:T(i))=i=1∑N[t−1∑T−1s(yt(i),yt+1(i),x1:T(i))−∇λlogZ(x1:T(i),λ,η)]=i=1∑N[t−1∑T−1s(yt(i),yt+1(i),x1:T(i))−Z1t=1∑T−1yt,yt+1∑αt(k)⋅ψt(yt,yt+1,x1:T(i))⋅βt+1(j)⋅s(yt,yt+1,x1:T(i))]
确定了模型参数
λ
\lambda
λ的迭代方向,可以通过迭代逼近最优解:
这里就不复述
η
\eta
η的求解过程了。有感兴趣的小伙伴留言交流。
λ
(
k
+
1
)
=
λ
k
+
d
λ
⋅
∇
λ
J
(
λ
(
k
)
,
η
(
k
)
,
x
1
:
T
(
i
)
)
\lambda^{(k+1)} = \lambda^{k} + d_{\lambda} \cdot \nabla_{\lambda} \mathcal J(\lambda^{(k)},\eta^{(k)},x_{1:T}^{(i)})
λ(k+1)=λk+dλ⋅∇λJ(λ(k),η(k),x1:T(i))
总结
回顾求解模型参数的流程:
- 将原问题转化为最大化目标函数问题,使用梯度上升法;
- 在求解梯度的过程中,利用了对数函数求导;
- 在最终求解边缘概率分布过程中,再次使用了前向后向算法;
至此,条件随机场的相关信息介绍完毕,下一节将返回高斯分布,介绍一些关于高斯分布的基础逻辑。
相关参考:
机器学习-条件随机场(8)-CRF模型-Learning-参数估计


![[附源码]SSM计算机毕业设计ssm新冠疫苗预约接种信息管理JAVA](https://img-blog.csdnimg.cn/87412e0ed30c486cab9d82c7d2d3de56.png)

![[附源码]SSM计算机毕业设计“拥抱爱心”公益网站管理系统JAVA](https://img-blog.csdnimg.cn/67c82e489d3d490d8720a5c32e3c6757.png)