在本章中,我们将学习如何分配和使用纹理内存(Texture Memory)。和常量内存一样,纹理内存是另一种类型的只读内存,在特定的访问模式中,纹理内存同样能够提升性能并减少内存流量。虽然纹理内存最初是针对传统的图形处理应用程序而设计的,但在某些 GPU 计算应用程序中同样非常有用。
文章目录
- 纹理内存简介
- 热传导模型
- 简单的传热模型
- 温度更新的计算
- 模拟过程动态演示
- 使用纹理内存
- 使用二维纹理内存
- 遇到的问题及解决方案
纹理内存简介
纹理内存是在CUDA C程序中可以使用的另一种只读内存。虽然NVIDIA为OpenGL和DirectX等的渲染流水线都设计了纹理单元,但纹理内存具备的一些属性使其在计算中变得非常有用。
与常量内存类似的是,纹理内存同样缓存在芯片上,因此在某些情况中,它能够减少对内存的请求并提供更高效的内存带宽。纹理缓存是专门为那些在内存访问模式中存在大量空间局部性(Spatial Locality)的图形应用程序而设计的。在某个计算应用程序中,这意味着一个线程读取的位置可能与邻近线程读取的位置"非常接近",如下图所示:

从数学角度来看,图中的四个地址并非连续的,在一般的CPU缓存模式中,这些地址将不会缓存。但由于GPU纹理缓存是专门为了加速这种访问模式而设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会活得性能提升。事实上,这种访问在通用计算中并非罕见,我们稍后将会看到。
热传导模型
物理模拟问题或许是在计算上最具挑战性的问题之一。这类问题通常在计算精度与计算复杂性上存在着某种权衡。近年来,计算机模拟正变得越来越重要,这在很大程度上要归功于计算精度的不断提高,而这正是并行计算革命带来的好处。由于许多物理模拟计算都可以很容易地并行化,因此我们将在这个示例中看到一种非常简单的模拟模型。
简单的传热模型
为了说明一种可以有效使用纹理内存的情况,我们将构造一个简单的二维热传导模拟。首先假设有一个矩形房间,将其分成一个格网。在格网中随机散布一些"热源",它们有着不同的固定温度,下图给出这个房间的示意图。

在给定了矩形格网以及热源分布后,我们可以计算格网中每个单元的温度随时间的变化情况。为了简单,热源单元本身的温度将保持不变。在时间递进的每个步骤中,我们假设热量在某个单元及其邻接单元之间“流动”。如果某个单元的邻接单元的温度更高,那么热量将从邻接单元传导到该单元。相反地,如果某个单元的温度比邻接单元的温度高,那么它将变冷。下图给出了这种热量流动示意图

在热传导模型中,我们对单元中新温度的集散方法为,将单元与邻接单元的温差相加起来,然后加上原有温度,计算公式如下
T N E W = T O L D + ∑ N E I G H B O R S k ( T N E I G H B O R − T O L D ) T_{NEW}=T_{OLD}+\sum_{NEIGHBORS}^{}k(T_{NEIGHBOR}-T_{OLD}) TNEW=TOLD+∑NEIGHBORSk(TNEIGHBOR−TOLD)
在上面计算单元温度的等式中,常量 k 表示模拟过程中热量的流动速率。k 值越大,表示系统会更快地达到稳定温度,而 k 值越小,则温度梯度将存在更长的时间。由于我们只考虑 4 个邻接单元(上,下,左,右) 并且等式中的 k 和 T O L D T_{OLD} TOLD 都是常数,因此将上式展开后如下所示
T N E W = T O L D + k ( T T O P + T B O T T O M + T L E F T + T R I G H T − 4 T O L D ) T_{NEW}=T_{OLD}+k(T_{TOP}+T_{BOTTOM}+T_{LEFT}+T_{RIGHT}-4T_{OLD}) TNEW=TOLD+k(TTOP+TBOTTOM+TLEFT+TRIGHT−4TOLD)
温度更新的计算
首先给出更新流程的基本介绍:
- 给定一个包含初始输入温度的格网,将其中作为热源的单元温度值复制到格网相应的单元中。这将覆盖这些单元之前计算出的温度,因此也就确保了 “加热单元将保持恒温” 这个条件。这个复制操作是在
copy_const_kernel()中执行的。 - 给定一个输入温度格网,根据之前推出的更新公式计算输出温度格网。这个更新操作是在
blend_kernel()中执行的。 - 将输入温度格网和输出温度格网交换,为下一个步骤的计算做好准备。当模拟下一个时间步时,在步骤 2 中计算得到的输出温度格网将称为步骤 1 中的输入温度格网。
在开始模拟之前,我们假设已经获得了一个格网。格网中大多数单元的温度值都是 0,但有些单元包含了非 0 的温度值,这些单元就是拥有固定温度的热源。在模拟过程中,缓冲区中这些常量值不会发生变化,并且在每个时间步中读取。
根据我们对热传导的建模方式,首先获得前一个时间步的输出温度格网并将其作为当前时间步的输入温度格网。然后,根据步骤 1,将作为热源的单元的温度值复制到输出格网中,从而覆盖该单元之前计算出的温度值。这么做是因为我们已经假设这些热源单元的温度将保持不变。通过以下核函数将格网中的热源单元复制到输入格网中:
__global__ void copy_const_kernel(float* iptr, const float* cptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if (cptr[offset] != 0) iptr[offset] = cptr[offset];
}
前两行代码将线程的 threadIdx 和 blockIdx 转换为 x 坐标和 y 坐标。第三行代码计算在输入缓冲区中的线性偏移。最后一行把 cptr[] 中的热源温度复制到 iptr[] 的输入单元中。注意,只有当格网中单元的温度值非 0 时,才会执行复制操作。我们这么做是为了维持非热源单元在上一个时间步中计算得到的温度值。热源单元在 cptr[] 中对应的元素为非零值,因此调用这个复制核函数后,热源单元的温度值在不同的时间步中将保持不变。
算法步骤 2 中包含的计算最多。为了执行这些更新操作,可以在模拟过程中让每个线程负责计算一个单元。每个线程都将读取对应单元及其邻接单元的温度值,执行前面给出的更新运算,然后用计算得到的新值更新它的温度。
__global__ void blend_kernel(float* outSrc, const float* inSrc) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0) left++;
if (x == DIM - 1) right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0) top += DIM;
if (y == DIM - 1) bottom -= DIM;
outSrc[offset] = inSrc[offset] + SPEED * (inSrc[top] + inSrc[bottom] + inSrc[left] + inSrc[right] - inSrc[offset] * 4);
}
注意,代码的开头与生成输出图像示例的开头是一样的,只是此时线程不是计算像素的颜色值,而是计算模拟单元中的温度值。首先,代码将 threadIdx 和 blockIdx 转换为 x,y 和 offset。
接下来,代码会计算出上,下,左,右四个邻接单元的偏移并读取这些单元的温度。我们需要这些值来计算当前单元中的已更新温度。这里唯一需要注意的地方就是需要调整边界的索引,从而在边缘的单元上不会回卷。最后的代码行中执行了之前推出公式的更新运算,将原来的温度与该单元温度和邻接单元的温度的温差相加。
模拟过程动态演示
剩下的代码主要是设置好单元,然后显示热量的动画输出,代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#include <stdio.h>
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// 更新函数中需要的全局变量
struct DataBlock {
unsigned char* output_bitmap;
float* dev_inSrc;
float* dev_outSrc;
float* dev_constSrc;
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
void anim_gpu(DataBlock* d, int ticks) {
HANDLE_ERROR(cudaEventRecord(d->start, 0));
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = d->bitmap;
for (int i = 0; i < 90; i++) {
copy_const_kernel << <blocks, threads >> > (d->dev_inSrc, d->dev_constSrc);
blend_kernel << <blocks, threads >> > (d->dev_outSrc, d->dev_inSrc);
swap(d->dev_inSrc, d->dev_outSrc);
}
float_to_color << <blocks, threads >> > (d->output_bitmap, d->dev_inSrc);
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(d->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(d->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.lf ms\n", d->totalTime/d->frames);
}
void anim_exit(DataBlock* d) {
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
在代码中加入了基于事件的计时功能。由于我们希望提高算法的执行速度,因此在代码中添加了测量性能的机制从而确保成功提升了性能。
动画框架的每一帧都将调用函数 anim_gpu()。这个函数的参数是一个指向 DataBlock 的指针,以及动画以及经历的时间 ticks。在动画示例中,每个线程块中包含了 256 个线程,构成了一个 16 x 16 的二维单元。anim_gpu() 中 for() 循环的每次迭代都将计算模拟过程的一个时间步。由于 DataBlock 包含了表示热源的常量缓冲区,以及在上一个时间步中计算得到的输出值,因此能够表示动画的完整状态,因而 anim_gpu() 实际上并不需要用到 ticks 的值。
在计算了 90 个时间步后,anim_gpu() 就已经准备好将当前动画的位图帧复制回 CPU。由于 for() 循环会交换输入和输出,因此我们首先交换输入缓冲区和输出缓冲区,这样在输出缓冲区中实际上将包含第 90 个时间步的输出。我们通过核函数 float_to_color() 将温度转换为颜色,然后将结果图像通过 cudaMemcpy() 复制回 CPU,并将复制的方向指定为 cudaMemcpyDeviceToHost。最后,为了准备下一系列时间步,我们将输出缓冲区交换到输入缓冲区以便作为下一个时间步的输入。
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.output_bitmap, bitmap.image_size()));
//假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
float* temp = (float*)malloc(bitmap.image_size());
for (int i = 0; i < DIM * DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))anim_gpu, (void(*)(void*))anim_exit);
return 0;
}
完整代码如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#include <stdio.h>
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// 更新函数中需要的全局变量
struct DataBlock {
unsigned char* output_bitmap;
float* dev_inSrc;
float* dev_outSrc;
float* dev_constSrc;
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
__global__ void copy_const_kernel(float* iptr, const float* cptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if (cptr[offset] != 0) iptr[offset] = cptr[offset];
}
__global__ void blend_kernel(float* outSrc, const float* inSrc) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0) left++;
if (x == DIM - 1) right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0) top += DIM;
if (y == DIM - 1) bottom -= DIM;
outSrc[offset] = inSrc[offset] + SPEED * (inSrc[top] + inSrc[bottom] + inSrc[left] + inSrc[right] - inSrc[offset] * 4);
}
void anim_gpu(DataBlock* d, int ticks) {
HANDLE_ERROR(cudaEventRecord(d->start, 0));
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = d->bitmap;
for (int i = 0; i < 90; i++) {
copy_const_kernel << <blocks, threads >> > (d->dev_inSrc, d->dev_constSrc);
blend_kernel << <blocks, threads >> > (d->dev_outSrc, d->dev_inSrc);
swap(d->dev_inSrc, d->dev_outSrc);
}
float_to_color << <blocks, threads >> > (d->output_bitmap, d->dev_inSrc);
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(d->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(d->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.lf ms\n", d->totalTime/d->frames);
}
void anim_exit(DataBlock* d) {
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.output_bitmap, bitmap.image_size()));
//假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
float* temp = (float*)malloc(bitmap.image_size());
for (int i = 0; i < DIM * DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))anim_gpu, (void(*)(void*))anim_exit);
return 0;
}
结果如下

使用纹理内存
在温度更新计算的内存访问模式中存在着巨大的内存空间局部性。这种访问模式可以通过GPU纹理内存来加速。
首先,需要将输入的数据声明为 texture 类型的引用。我们使用浮点类型纹理的引用,因为温度数值是浮点类型的。
// 这些变量将位于GPU上
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
下一个需要注意的问题是,在为这三个缓冲区分配了 GPU 内存后,需要通过 cudaBindTexture() 将这些变量绑定到内存缓冲区。这相当于告诉 CUDA 运行时两件事情:
- 我们希望将指定的缓冲区作为纹理来使用
- 我们希望将纹理引用作为纹理的”名字“
在热传导模拟中分配了这三个内存后,需要将这三个内存绑定到之前声明的纹理引用(texConstSrc、texIn、texOut)。
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
HANDLE_ERROR(cudaBindTexture(NULL, texConstSrc, data.dev_constSrc, imageSize));
HANDLE_ERROR(cudaBindTexture(NULL, texIn, data.dev_inSrc, imageSize));
HANDLE_ERROR(cudaBindTexture(NULL, texOut, data.dev_outSrc, imageSize));
此时,纹理变量已经设置好了,现在可以启动核函数。然而,当读取核函数中的纹理时,需要通过特殊的函数来告诉 GPU 将读取请求转发到纹理内存而不是标准的全局内存。因此,当读取内存时不再使用方括号从缓冲区中读取,而是将 blend_kernel() 改为使用 tex1Dfetch()。
此外,在全局内存和纹理内存的使用上还存在另一个差异。虽然 tex1Dfetch() 看上去像一个函数,但它其实是一个编译器内置函数(Intrinsic)。由于纹理引用必须声明为文件作用域内的全局变量,因此我们不再将输入缓冲区作为参数传递给 blend_kernel(),因为编译器需要在编译时知道 tex1Dfetch() 应该对哪些纹理采样。我们不是像前面那样传递指向输入缓冲区和输出缓冲区的指针,而是将一个布尔标志 dstOut 传递给 blend_kernel(),这个标志会告诉我们使用哪个缓冲区作为输入,以及那个缓冲区作为输出。下面是对 blend_kernel() 的修改:
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0) left++;
if (x == DIM - 1) right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0) top += DIM;
if (y == DIM - 1) bottom -= DIM;
float t, l, c, r, b;
if (dstOut) {
t = tex1Dfetch(texIn, top);
l = tex1Dfetch(texIn, left);
c = tex1Dfetch(texIn, offset);
r = tex1Dfetch(texIn, right);
b = tex1Dfetch(texIn, bottom);
}
else {
t = tex1Dfetch(texOut, top);
l = tex1Dfetch(texOut, left);
c = tex1Dfetch(texOut, offset);
r = tex1Dfetch(texOut, right);
b = tex1Dfetch(texOut, bottom);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
由于核函数 copy_const_kernel() 将读取包含热源位置和温度的缓冲区,因此同样需要修改为从纹理内存而不是从全局内存中读取:
__global__ void copy_const_kernel(float* iptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex1Dfetch(texConstSrc, offset);
if (c != 0)
iptr[offset] = c;
}
由于 blend_kernel() 的函数原型被修改为接收一个标志,并且这个标志表示在输入缓冲区与输出缓冲区之间的切换,因此需要对 anim_gpu() 函数进行相应的修改。现在,不是交换缓冲区,而是在每组调用之后通过设置 dstOut = !dstOut 来进行切换:
void anim_gpu(DataBlock* d, int ticks) {
HANDLE_ERROR(cudaEventRecord(d->start, 0));
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = d->bitmap;
// 由于tex是全局并且有界的,因此我们必须通过一个标志来
// 选择每次迭代中哪个是输入/输出
volatile bool dstOut = true;
for (int i = 0; i < 90; i++) {
float* in, * out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
}
else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel << <blocks, threads >> > (in);
blend_kernel << <blocks, threads >> > (out, dstOut);
dstOut = !dstOut;
}
float_to_color << <blocks, threads >> > (d->output_bitmap, d->dev_inSrc);
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(d->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(d->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.lf ms\n", d->totalTime / d->frames);
}
对热传导函数的最后一个修改就是在应用程序运行结束后的清理工作。不仅要释放全局缓冲区,还需要清除与纹理的绑定:
void anim_exit(DataBlock* d) {
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
完整代码如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include "cuda_texture_types.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#include <stdio.h>
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// 这些变量将位于GPU上
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
// 更新函数中需要的全局变量
struct DataBlock {
unsigned char* output_bitmap;
float* dev_inSrc;
float* dev_outSrc;
float* dev_constSrc;
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
__global__ void copy_const_kernel(float* iptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex1Dfetch(texConstSrc, offset);
if (c != 0)
iptr[offset] = c;
}
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0) left++;
if (x == DIM - 1) right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0) top += DIM;
if (y == DIM - 1) bottom -= DIM;
float t, l, c, r, b;
if (dstOut) {
t = tex1Dfetch(texIn, top);
l = tex1Dfetch(texIn, left);
c = tex1Dfetch(texIn, offset);
r = tex1Dfetch(texIn, right);
b = tex1Dfetch(texIn, bottom);
}
else {
t = tex1Dfetch(texOut, top);
l = tex1Dfetch(texOut, left);
c = tex1Dfetch(texOut, offset);
r = tex1Dfetch(texOut, right);
b = tex1Dfetch(texOut, bottom);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
void anim_gpu(DataBlock* d, int ticks) {
HANDLE_ERROR(cudaEventRecord(d->start, 0));
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = d->bitmap;
// 由于tex是全局并且有界的,因此我们必须通过一个标志来
// 选择每次迭代中哪个是输入/输出
volatile bool dstOut = true;
for (int i = 0; i < 90; i++) {
float* in, * out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
}
else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel << <blocks, threads >> > (in);
blend_kernel << <blocks, threads >> > (out, dstOut);
dstOut = !dstOut;
}
float_to_color << <blocks, threads >> > (d->output_bitmap, d->dev_inSrc);
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(d->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(d->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.lf ms\n", d->totalTime / d->frames);
}
void anim_exit(DataBlock* d) {
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.output_bitmap, bitmap.image_size()));
//假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
long imageSize = bitmap.image_size();
HANDLE_ERROR(cudaBindTexture(NULL, texConstSrc, data.dev_constSrc, imageSize));
HANDLE_ERROR(cudaBindTexture(NULL, texIn, data.dev_inSrc, imageSize));
HANDLE_ERROR(cudaBindTexture(NULL, texOut, data.dev_outSrc, imageSize));
float* temp = (float*)malloc(bitmap.image_size());
for (int i = 0; i < DIM * DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))anim_gpu, (void(*)(void*))anim_exit);
return 0;
}
使用二维纹理内存
这里热传导模型是在二维空间中的,所以可以使用二维纹理内存。下面看看如何将热传导应用程序修改为使用二维纹理。
首先,需要修改纹理引用的声明。如果没有具体说明,默认的纹理引用都是一维的,因此我们增加了代表维数的参数 2,这表示声明的是一个二维纹理引用。
texture<float, 2> texConstSrc;
texture<float, 2> texIn;
texture<float, 2> texOut;
二维纹理将简化 blend_kernel() 方法的实现。虽然我们需要将 tex1Dfetch() 调用修改为 tex2D() 调用,但却不再需要使用通过线性化 offset 变量以计算 top、left、right 和 bottom 等偏移。当使用二维纹理时,可以直接通过 x 和 y 来访问纹理。
而且,当使用 tex2D() 时,我们不再需要担心发生溢出问题。如果 x 或 y 小于 0,那么 tex2D() 将返回 0 处的值。同理,如果某个值大于宽度,那么 tex2D() 将返回位于宽度处的值。
这样简化带来的好处之一就是,核函数的代码将变得更加简单。
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float t, l, c, r, b;
if (dstOut) {
t = tex2D(texIn,x, y-1);
l = tex2D(texIn, x-1, y);
c = tex2D(texIn, x, y);
r = tex2D(texIn, x+1, y);
b = tex2D(texIn, x, y+1);
}
else {
t = tex2D(texOut, x, y-1);
l = tex2D(texOut, x-1, y);
c = tex2D(texOut, x, y);
r = tex2D(texOut, x+1, y);
b = tex2D(texOut, x, y+1);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
由于所以之前对 tex1Dfetch() 的调用都需要修改为对 tex2D() 的调用,因此我们需要在 copy_const_kernel() 中进行相应的修改。与核函数 blend_kernel() 类似的是,我们不再需要通过 offset 来访问纹理,而只需使用 x 和 y 来访问热源的常量数量:
__global__ void copy_const_kernel(float* iptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex2D(texConstSrc, x, y);
if (c != 0)
iptr[offset] = c;
}
在使用一维纹理的热传导模拟版本中还剩下一些最后的修改,它们与之前的修改是类似的。在 main() 中需要对纹理绑定调用进行修改,并告诉运行时:缓冲区将被视为二维纹理而不是一维纹理。
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
HANDLE_ERROR(cudaBindTexture2D(NULL, texConstSrc, data.dev_constSrc, desc, DIM, DIM, sizeof(float) * DIM));
HANDLE_ERROR(cudaBindTexture2D(NULL, texIn, data.dev_inSrc, desc, DIM, DIM, sizeof(float) * DIM));
HANDLE_ERROR(cudaBindTexture2D(NULL, texOut, data.dev_outSrc, desc, DIM, DIM, sizeof(float) * DIM));
当绑定二维纹理时, CUDA 运行时要求提供一个 cudaChannelFormatDesc。在上面的代码中包含了一个对通道格式描述符 (Channel Format Descriptor) 的声明。在这里可以使用默认的参数,并且只要指定需要的是一个浮点描述符。然后,我们通过 cudaBindTexture2D(),纹理的维数(DIMxDIM) 以及通道格式描述符(desc)将这三个输入缓冲区绑定为二维纹理。main() 函数的其他部分保持不变。
无论是一维纹理还是二维纹理,都可以通过 cudaUnbindTexture() 来取消纹理的绑定。所以,执行释放操作的函数可以保持不变。
void anim_exit(DataBlock* d) {
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
完整代码如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include "cuda_texture_types.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#include <stdio.h>
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
texture<float, 2> texConstSrc;
texture<float, 2> texIn;
texture<float, 2> texOut;
// 更新函数中需要的全局变量
struct DataBlock {
unsigned char* output_bitmap;
float* dev_inSrc;
float* dev_outSrc;
float* dev_constSrc;
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
__global__ void copy_const_kernel(float* iptr) {
// 将 threadIdx/BlockIdx 映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex2D(texConstSrc, x, y);
if (c != 0)
iptr[offset] = c;
}
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将 threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float t, l, c, r, b;
if (dstOut) {
t = tex2D(texIn,x, y-1);
l = tex2D(texIn, x-1, y);
c = tex2D(texIn, x, y);
r = tex2D(texIn, x+1, y);
b = tex2D(texIn, x, y+1);
}
else {
t = tex2D(texOut, x, y-1);
l = tex2D(texOut, x-1, y);
c = tex2D(texOut, x, y);
r = tex2D(texOut, x+1, y);
b = tex2D(texOut, x, y+1);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
void anim_gpu(DataBlock* d, int ticks) {
HANDLE_ERROR(cudaEventRecord(d->start, 0));
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = d->bitmap;
// 由于tex是全局并且有界的,因此我们必须通过一个标志来
// 选择每次迭代中哪个是输入/输出
volatile bool dstOut = true;
for (int i = 0; i < 90; i++) {
float* in, * out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
}
else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel << <blocks, threads >> > (in);
blend_kernel << <blocks, threads >> > (out, dstOut);
dstOut = !dstOut;
}
float_to_color << <blocks, threads >> > (d->output_bitmap, d->dev_inSrc);
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(), d->output_bitmap, bitmap->image_size(), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(d->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(d->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.lf ms\n", d->totalTime / d->frames);
}
void anim_exit(DataBlock* d) {
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
HANDLE_ERROR(cudaEventDestroy(d->start));
HANDLE_ERROR(cudaEventDestroy(d->stop));
}
int main()
{
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.output_bitmap, bitmap.image_size()));
//假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
HANDLE_ERROR(cudaBindTexture2D(NULL, texConstSrc, data.dev_constSrc, desc, DIM, DIM, sizeof(float) * DIM));
HANDLE_ERROR(cudaBindTexture2D(NULL, texIn, data.dev_inSrc, desc, DIM, DIM, sizeof(float) * DIM));
HANDLE_ERROR(cudaBindTexture2D(NULL, texOut, data.dev_outSrc, desc, DIM, DIM, sizeof(float) * DIM));
float* temp = (float*)malloc(bitmap.image_size());
for (int i = 0; i < DIM * DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))anim_gpu, (void(*)(void*))anim_exit);
return 0;
}
无论使用二维纹理还是一维纹理,热传导模拟应用程序的性能基本相同。因此,基于性能来选择使用一维纹理还是二维纹理可能没有太大的意义。对于这个应用程序来说,当使用二维纹理时,代码会更简单一些,因为模拟的问题刚好是二维的。但通常来说,如果问题不是二维的,那么究竟选择一维纹理还是二维纹理要视具体情况而定。
遇到的问题及解决方案
运行上面的热传导模型案例会发现,使用纹理内存居然比不使用纹理内存还慢了10倍左右。
不使用纹理内存结果

一维纹理内存结果
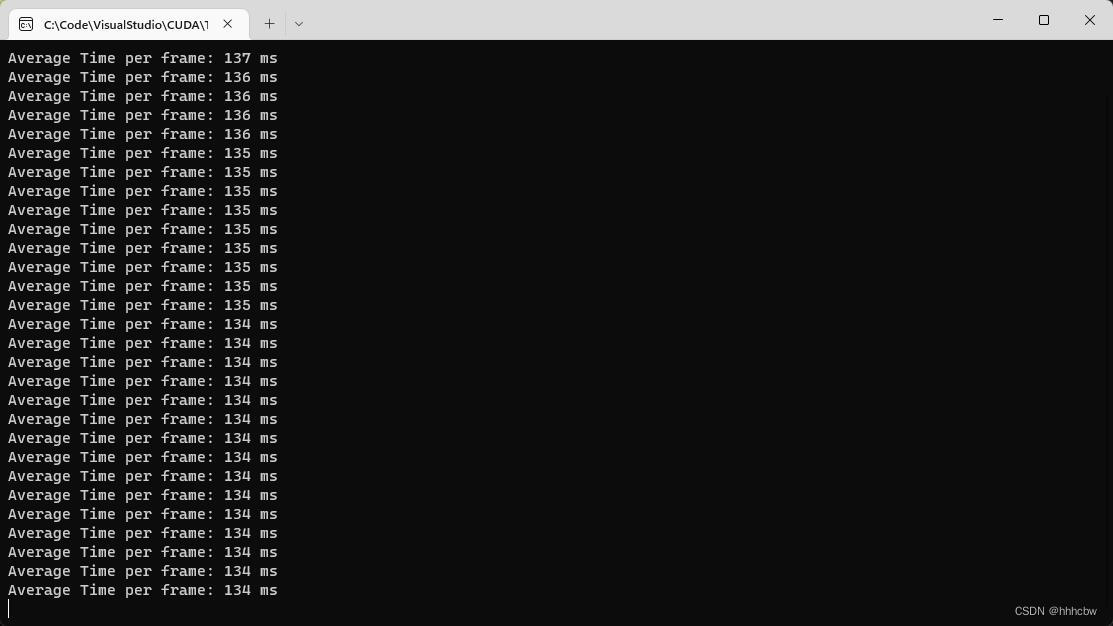
二维纹理内存结果

通过查阅相关资料,发现纹理缓存基本上已经被淘汰了。由于在计算能力为 1.x 的硬件上根本没有高速缓存,因此,每个 SM 上的 6 ~ 8KB 的纹理内存为此设备提供了唯一真正缓存数据的方法。然而,随着费米架构的硬件出现,一级缓存最大可达 48KB,共享二级缓存最大可达 768KB,使得纹理缓存的这项属性基本被淘汰。费米架构的设备依然保留着纹理缓存以保证对旧式硬件上的代码兼容。
纹理缓存通常用来做局部优化,即它希望数据提供给连续的线程进行操作。这与费米架构设备上一级缓存的缓存机制基本相同。除非你是为了使用纹理内存其他方面的特性,否则在费米架构设备上,对纹理内存大量编程并不会获得很高的收益。
在我的理解,纹理缓存的速度是没有一级缓存的速度快的,所以最终会导致程序运行变慢。





![[附源码]java毕业设计景区门票系统](https://img-blog.csdnimg.cn/efdec7a504974840b882621a2e376ae9.png)