文章目录
- 一、数据集介绍
- 1.1、简介
- 1.2 详细介绍
- 1、数据量
- 2、标注量
- 3. 标注类别
- 4.数据下载
- 5.数据集解读
- 二、读取、加载数据集
- 1、pytorch 自带库函数
- 2、通过重构Dataset类读取特定的MNIST数据或者制作自己的MNIST数据集
- 三、模型构建
- 四、 run
- train
- test
- 评估模型的性能
- 检查点的持续训练
一、数据集介绍
1.1、简介
MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。
该数据集的收集目的是希望通过算法,实现对手写数字的识别。
MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的。
MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。
1.2 详细介绍
1、数据量
训练集60000张图像,其中30000张来自NIST的Special Database 3,30000张来自NIST的Special Database 1。
测试集10000张图像,其中5000张来自NIST的Special Database 3,5000张来自NIST的Special Database 1。
2、标注量
每张图像都有标注。
3. 标注类别
共10个类别,每个类别代表0~9之间的一个数字,每张图像只有一个类别。
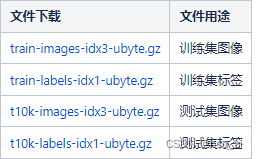
4.数据下载
官网上提供了数据集的下载,主要包括四个文件:
5.数据集解读
训练集和测试集的标签文件的格式(train-labels-idx1-ubyte和t10k-labels-idx1-ubyte)
idx1-ubtype的文件数据格式如下:
[offset] [type] [value] [description]
0000 32 bit integer
0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
- 第0 ~ 3字节,是32位整型数据,取值为0x00000801(2049),即用幻数2049记录文件数据格式,这里的格式为文本格式。
- 第4~7个字节,是32位整型数据,取值为60000(训练集时)或10000(测试集时),用来记录标签数据的个数;
- 第8个字节 ~ ),是一个无符号型的数,取值为对应0~9 之间的标签数字,用来记录样本的标签
训练集和测试集的图像文件的格式(train-images-idx3-ubyte和t10k-images-idx3-ubyte)
idx3-ubtype的文件数据格式如下:
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
-
第0 ~ 3字节,是32位整型数据,取值为0x00000803(2051),即用幻数2051记录文件数据格式,这里的格式为图片格式。
-
第4~7个字节,是32位整型数据,取值为60000(训练集时)或10000(测试集时),用来记录图片数据的个数;
-
第8~11个字节,是32位整型数据,取值为28,用来记录图片数据的高度;
-
第12~15个字节,是32位整型数据,取值为28,用来记录图片数据的宽度;
-
第16个字节 ~ ),是一个无符号型的数,取值为0~255之间的灰度值,用来记录图片按行展开后得到的灰度值数据,其中0表示背景(白色),255表示前景(黑色)
二、读取、加载数据集
导入PyTorch的两个核心库torch和torchvision,这两个库基本包含了PyTorch会用到的许多方法和函数,其他库为下面所需要的一些辅助库。
import gzip
import os
import torch
import torchvision
import numpy as np
from PIL import Image
from matplotlib import pyplot as plt
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
1、pytorch 自带库函数
TorchVision提供了许多方便的转换,比如裁剪或标准化。
train_data = datasets.MNIST(
root="./data/",
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(
root="./data/",
train=False,
transform=transforms.ToTensor(),
download=True)
其中:
- root 指定MNIST数据集存放的路径
- train 设置为True表示导入的是训练集合,否则为测试集合
- transform 指定导入数据集时需要进行何种变换操作.
此处ToTensor()将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可 - download 设置为True表示当root参数指定的数据集存放的路径下没有数据时,则自动从网络上下载MNIST数据集,否则就不自动下载
注意: 返回值为一个二元组(data,target),一般是与torch.utils.data.DataLoader配合使用,也可自己对数据进行处理,见二、2。
加载MNIST数据集代码:
train_data_loader = torch.utils.data.DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
drop_last=True)
test_data_loader = torch.utils.data.DataLoader(
dataset=test_data,
batch_size=64,
shuffle=False,
drop_last=False)
其中:
- dataset 指定欲装载的MNIST数据集
- batch_size 设置了每批次装载的数据图片为64个(自行设置)
- shuffle 设置为True表示在装载数据时随机乱序,常用于进行多批次的模型训练
- drop_last 设置为True表示当数据集size不能整除batch_size时,则删除最后一个batch_size,否则就不删除
直接构建数据集方式
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)) # 归一化,softmax归一化指数函数,其中0.1307是mean均值和0.3081是std标准差
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
在加载完成后,可以选取其中一个批次的数据进行预览:
********************
images, labels = next(iter(train_data_loader)) # images:Tensor(64,1,28,28)、labels:Tensor(64,)
********************
img = torchvision.utils.make_grid(images) # 把64张图片拼接为1张图片
# pytorch网络输入图像的格式为(C, H, W),而numpy中的图像的shape为(H,W,C)。故需要变换通道才能有效输出
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print(labels)
plt.imshow(img)
plt.show()
下图展示的是一个batch数据集(64张图片)的显示:
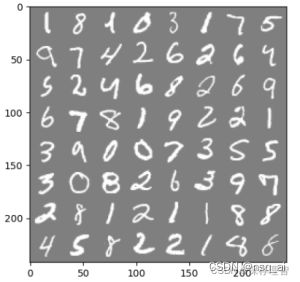
对其中某一个图片进行像素化展示:
# images:Tensor(64,1,28,28)、labels:Tensor(64,)
images, labels = next(iter(train_data_loader)) #(1,28,28)表示该图像的 height、width、color(颜色通道,即单通道)
images = images.reshape(64, 28, 28)
img = images[0, :, :] # 取batch_size中的第一张图像
np.savetxt('img.txt', img.cpu().numpy(), fmt="%f", encoding='UTF-8') # 将像素值写入txt文件,以便查看
img = img.cpu().numpy() #转为numpy类型,方便有效输出
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
val = round(img[x][y], 2) if img[x][y] !=0 else 0
ax.annotate(str(val), xy=(y, x),
horizontalalignment='center',
verticalalignment='center',
color='white' if img[x][y] < thresh else 'black')
plt.show()

2、通过重构Dataset类读取特定的MNIST数据或者制作自己的MNIST数据集
定义一个子类,继承Dataset类, 重写 len(),getitem() 方法。
- getitem 是获取样本对,模型直接通过这一函数获得一对样本对{ x:y }
- len 是指数据集长度
① 读取MNIST文件夹下processed文件中的training.pt、test.pt数据集
class Data_Loader(Dataset):
def __init__(self, root, transform=None):
self.data, self.targets = torch.load(root) #采用torch.load进行读取,读取之后的结果为torch.Tensor形式
self.transform = transform
def __getitem__(self, index):
img, target = self.data[index], int(self.targets[index])
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
img = transforms.ToTensor()(img)
return img, target
def __len__(self):
return len(self.data)
接下来,调用我们自定义的Data_Loader类来读取数据集:
# root 为training.pt、test.pt文件所在的绝对路径
train_data = Data_Loader(root='./mnist/MNIST/processed/training.pt', transform= None)
test_data = Data_Loader(root='./mnist/MNIST/processed/test.pt', transform= None)
再使用torch.utils.data.DataLoader对train_data和test_data进行加载,展示。
② 读取MNIST文件夹下raw文件中的数据集
class Data_Loader(Dataset):
def __init__(self, folder, data_name, label_name, transform=None):
(train_set, train_labels) = load_data(folder, data_name, label_name)
self.train_set = train_set
self.train_labels = train_labels
self.transform = transform
def __getitem__(self, index):
img, target = self.train_set[index], int(self.train_labels[index])
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.train_set)
def load_data(data_folder, data_name, label_name):
with gzip.open(os.path.join(data_folder, label_name), 'rb') as lbpath: # rb表示的是读取二进制数据
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(os.path.join(data_folder, data_name), 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
return x_train, y_train
接下来,调用我们自定义的Data_Loader类来读取数据集:
# folder:MNIST数据集中raw文件的绝对路径
# 读取MNIST数据集中的训练集
train_data = Data_Loader('./MNIST/MNIST/raw', "train-images-idx3-ubyte.gz",
"train-labels-idx1-ubyte.gz", transform=transforms.ToTensor())
# 读取MNIST数据集中的测试集
test_data = Data_Loader('./MNIST/MNIST/raw', "t10k-images-idx3-ubyte.gz",
"t10k-labels-idx1-ubyte.gz", transform=transforms.ToTensor())
再使用torch.utils.data.DataLoader对train_data和test_data进行加载,展示。
三、模型构建
开始始建立网络。将使用两个2d卷积层,然后是两个全连接(或线性)层。作为激活函数,选择整流线性单元(简称ReLUs),作为正则化的手段,使用两个dropout层。
在PyTorch中,构建网络的一个好方法是希望构建的网络创建一个新类。
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
初始化网络和优化器。
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
四、 run
train
首先,我们要确保我们的网络处于训练模式。然后,每个epoch对所有训练数据进行一次迭代。加载单独批次由DataLoader处理
我们需要使用optimizer.zero_grad()手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度。然后,我们生成网络的输出(前向传递),并计算输出与真值标签之间的负对数概率损失。
现在,我们收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数。有关PyTorch自动渐变系统内部工作方式的详细信息,请参阅autograd的官方文档(强烈推荐)。
我们还将使用一些打印输出来跟踪进度。为了在以后创建一个良好的培训曲线,我们还创建了两个列表来节省培训和测试损失。在x轴上,我们希望显示网络在培训期间看到的培训示例的数量
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
在开始训练之前,我们将运行一次测试循环,看看仅使用随机初始化的网络参数可以获得多大的精度/损失
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx*64) + ((epoch-1)*len(train_loader.dataset)))
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
神经网络模块以及优化器能够使用.state_dict()保存和加载它们的内部状态。
这样,如果需要,我们就可以继续从以前保存的状态dict中进行训练——只需调用.load_state_dict(state_dict)。
test
进入测试循环。在这里,我们总结了测试损失,并跟踪正确分类的数字来计算网络的精度
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
评估模型的性能
就是这样。仅仅经过3个阶段的训练,我们已经能够达到测试集97%的准确率!我们开始使用随机初始化的参数,正如预期的那样,在开始训练之前,测试集的准确率只有10%左右。
我们来画一下训练曲线。
test() 不加这个,后面画图就会报错:x and y must be the same size
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
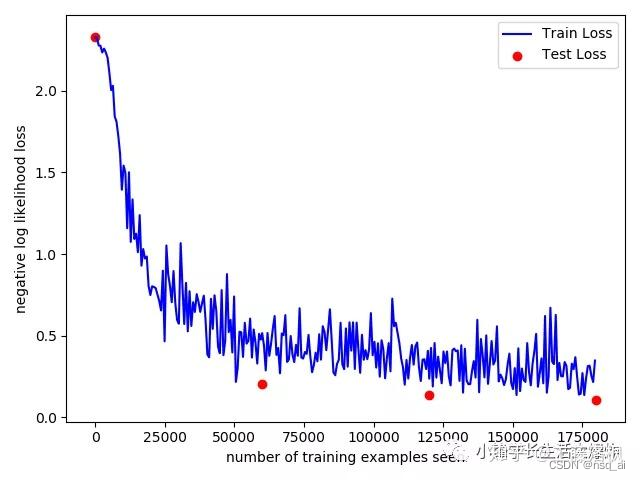
从训练曲线来看,看起来我们甚至可以继续训练几个epoch!
但在此之前,让我们再看看几个例子,正如我们之前所做的,并比较模型的输出。
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()

检查点的持续训练
现在让我们继续对网络进行训练,或者看看如何从第一次培训运行时保存的state_dicts中继续进行训练。我们将初始化一组新的网络和优化器。
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
使用.load_state_dict(),我们现在可以加载网络的内部状态,并在最后一次保存它们时优化它们。
network_state_dict = torch.load('model.pth')
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load('optimizer.pth')
continued_optimizer.load_state_dict(optimizer_state_dict)
同样,运行一个训练循环应该立即恢复我们之前的训练。为了检查这一点,我们只需使用与前面相同的列表来跟踪损失值。由于我们为所看到的训练示例的数量构建测试计数器的方式,我们必须在这里手动添加它。
# 注意不要注释前面的“for epoch in range(1, n_epochs + 1):”部分,
# 不然报错:x and y must be the same size
# 为什么是“4”开始呢,因为n_epochs=3,上面用了[1, n_epochs + 1)
for i in range(4, 9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()
参考文献:
- https://blog.csdn.net/Iron802/article/details/121826385
- https://blog.csdn.net/OpenDataLab/article/details/125716623
- https://nextjournal.com/gkoehler/pytorch-mnist
- https://blog.csdn.net/qq_45588019/article/details/120935828
- https://blog.csdn.net/ali1174/article/details/130294224
完整代码如下:
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed)
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
# print(example_targets)
# print(example_data.shape)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
train_losses.append(loss.item())
train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
train(1)
test() # 不加这个,后面画图就会报错:x and y must be the same size
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
# ----------------------------------------------------------- #
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
network_state_dict = torch.load('model.pth')
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load('optimizer.pth')
continued_optimizer.load_state_dict(optimizer_state_dict)
# 注意不要注释前面的“for epoch in range(1, n_epochs + 1):”部分,
# 不然报错:x and y must be the same size
# 为什么是“4”开始呢,因为n_epochs=3,上面用了[1, n_epochs + 1)
for i in range(4, 9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()