Doris是一款由百度开发的开源数据仓库查询引擎,它能够帮助用户高效地查询和分析大规模数据。Doris具有高性能、易用性强、可扩展性高等特点,让数据分析变得更加简单。
二、场景:
Doris适用于各种数据仓库场景,无论是大数据分析、报表生成,还是实时数据查询,都可以用它来实现。
三、特色功能:
简单易用:两个进程,没有其他依赖关系;集群在线扩缩容,副本自动恢复;兼容MySQL协议,使用标准SQL。
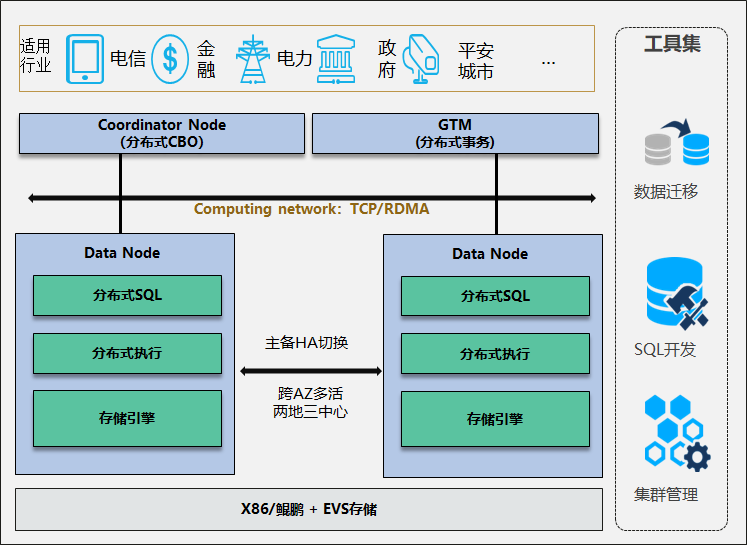
高性能:通过列式存储引擎、现代 MPP 架构、矢量化查询引擎、预聚合物化视图和数据索引,为低延迟和高吞吐量查询提供极快的性能。
单一统一:单个系统即可支持实时数据服务、交互式数据分析和离线数据处理场景。
联合查询:支持Hive、Iceberg、Hudi等数据湖和MySQL、Elasticsearch等数据库的联合查询。
多种数据导入方式:支持从 HDFS/S3 批量导入和从 MySQL Binlog/Kafka 流导入;支持通过HTTP接口进行微批量写入,在JDBC中使用Insert进行实时写入。
丰富的生态:Spark 使用 Spark Doris Connector 读写 Doris;Flink Doris Connector 使 Flink CDC 能够实现对 Doris 的一次性数据写入;提供 DBT Doris Adapter,用于使用 DBT 转换 Doris 中的数据。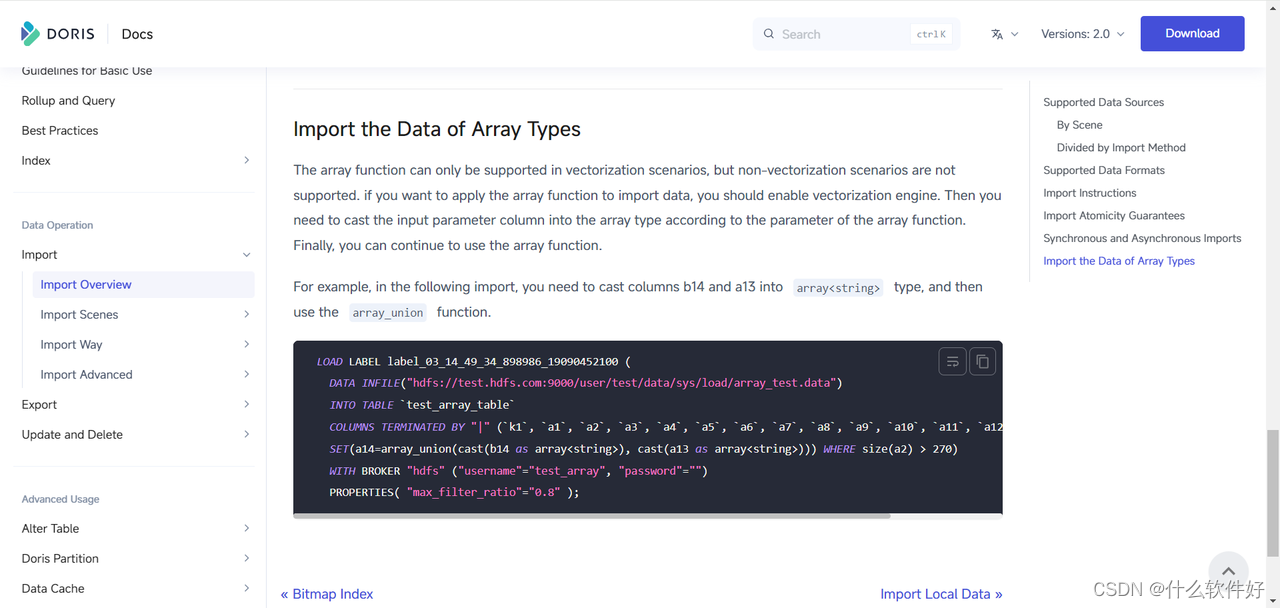
四、适用人群:
Doris适合的人群主要是数据分析师和开发人员。对于数据分析师来说,它能够提供高性能的查询引擎,帮助用户快速分析数据,提升工作效率。而对于开发人员来说,Doris提供了丰富的API接口和扩展性,使得开发者能够方便地集成到自己的项目中。
五、总结:
总的来说,Doris是一款强大的数据仓库查询引擎,它不仅能够帮助用户高效地查询和分析大规模数据,还提供了丰富的功能和扩展性,让数据分析变得更加简单。如果你正在寻找一款好的数据仓库查询引擎,那么Doris绝对是你的不二之选。