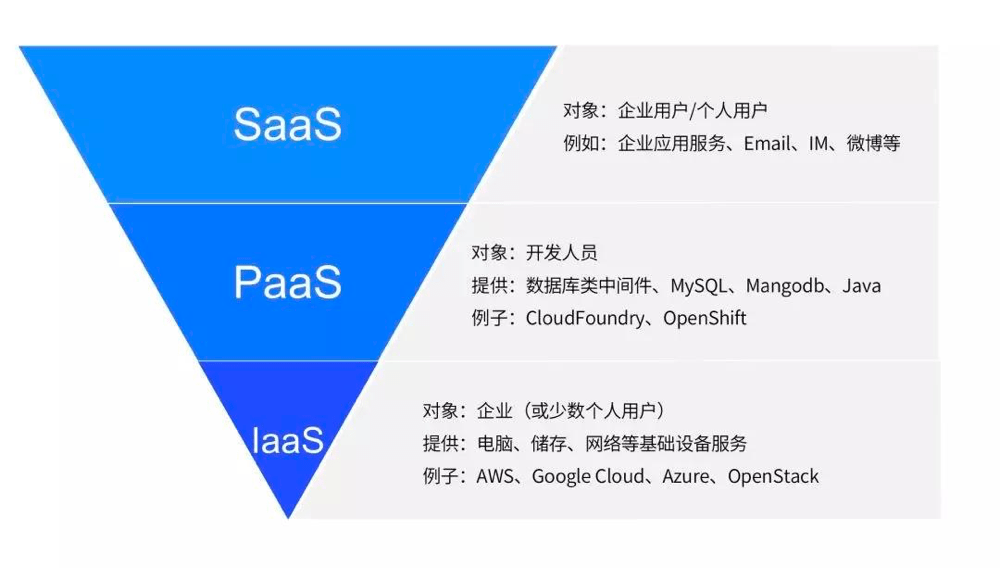
这个Dispatcher是一个事件分发模型,通过这个模型,就能够检测对应的文件描述符的事件的时候,可以使用epoll/poll/select,前面说过三选一。另外不管是哪一个底层的检测模型,它们都需要使用一个数据块,这个数据块就叫做DispatcherData。除此之外,还有另外一个部分,因为在这个反应堆模型里边对应一系列的文件描述符,都属于epoll/poll/select,但是这些文件描述符,它们不是固定的。
- 可能我们和客户端新建立了一个连接,那么就需要把某个节点就是某个文件描述符添加到这个Dispatcher模型上边
- 或者说服务器和客户端断开连接了,对应的这个文件描述符,就需要从Dispatcher对应的检测集合中删除
- 还有一种情况就是要修改Dispatcher检测的这些文件描述符对应的事件

对于刚才描述的这三种情况,不管是哪一个,都可以把它们称为任务。既然是任务,如果产生了多个这样的任务,就需要把这些任务存储起来,所以对应的就需要有一个任务队列。在C语言里边是没有所谓现成的任务队列可直接拿来使用.C++中就有list,可以直接拿一个队列来直接用,或者说拿一个list来直接用,在C语言里边,我们只能自己写了。
既然它是一个任务队列,也就意味着这个队列里边的节点的个数是不固定的,所以我们就需要一个动态的模型,可以实现一个链表。这个链表的节点是什么类型的?是ChannelElement类型.所谓ChannelElement类型。它里边主要其实是一个Channel,还有下一个节点的指针。通过指向下一个节点的指针,就可以把每一个节点连接起来了。当这个任务队列里边有了任务之后,我们就需要通过一个循环,把链表里边所有的节点都读出来。
- 如果这是一个添加事件的节点,那么我们就把这个文件描述符添加到Dispatcher对应的检测集合中。
- 如果它是删除的,那么我们就把这个文件描述符从Dispatcher的检测集合中删除。
- 如果它是修改事件,那么我们就把这个节点在Dispatcher中的事件做一个修改。
这个EventLoop里边有一个任务队列,可以说这个EventLoop它是一个生产者和消费者模型,
- 消费者是谁呢?
- 就是这个Dispatcher。
- 生产者是谁呢?
- 生产者有可能是其他的线程,比如说主线程和客户端建立了连接,剩下的事就是通信。如果要通信,就对应一个通信的文件描述符。主线程就把这个任务添加到了子线程对应的这个EventLoop里边。此时在taskQueue里边就多出来了一个节点。在遍历这个任务队列的时候,读到这个节点之后,就需要把当前的这个节点添加到Dispatcher对应的检测模型里边。
另外,在这个EventLoop里边,还有一个ChannelMap,这个ChannelMap也是我们实现的,是通过一个数组来实现的。基于这个ChannelMap,就能够通过一个文件描述符得到对应的那个channel,为什么要得到那个channel呢?因为在这个channel里边有文件描述符,它的读事件和写事件对应的回调函数,就是事件触发之后,执行什么样的处理动作。
【思考】什么时候用到了这个ChannelMap了呢?
在实现epoll/select/poll的时候,分别调用了epoll_wait函数/select函数/poll函数,通过遍历内核传出来的这个集合,就得到了触发对应事件的那个文件描述符。但我们现在处理不了,因为得不到对应的channel,我们可以通过EventLoop里边提供的这个ChannelMap就能够得到对应的Channel指针,这个Channel指针就可以调用事件对应的处理函数了。
这三大块之外,还有一些其他的数据成员,比如threadID。因为在当前的服务器里边有多个EventLoop,每个EventLoop都属于一个线程。所以我们可以记录一下这个EventLoop它所对应的那个子线程的线程ID。关于子线程的这个名字肯定是我们给它起的,因为子线程创建出来之后,它只有一个ID,这是系统分配的。关于它的名字,操作系统是没有告诉我们的。
ThreadCondition是条件变量,可用于阻塞线程
【思考】ThreadMutex这个互斥锁它保护的是什么?
其实它保护的是这个任务队列。为什么要保护任务队列呢?对于这个EventLoop来说,它能够被多少个线程操作呢?
- 如果是主线程的EventLoop,那就是一个。
- 如果是子线程的EventLoop,那就有可能是两个,为什么是两个呢?
- 当前,线程在执行这个EventLoop的时候,它肯定要遍历这个taskQueue吧,也就是当前线程需要读这个任务队列。
- 除此之外,如果主线程和客户端建立了一个连接,主线程是有可能要把一个任务添加到这个EventLoop,对应的任务队列里边,就是额外的另一个线程了。
- 如果涉及到两个线程操作,同一块共享资源,那么我们是要通过互斥锁来保护这个共享资源的。如果不保护,肯定就会出现数据混乱。

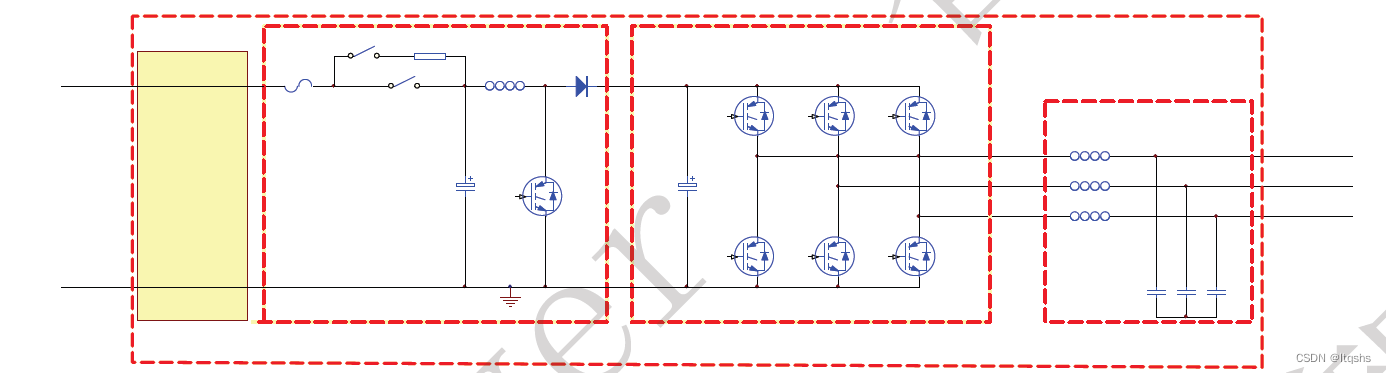
整个项目的结构,在当前这个多反应堆模型的服务器程序里边,它是有多个EventLoop模型的。首先,在主线程里边就有一个EventLoop主线程的,这个EventLoop去检测客户端有没有新的连接到达。如果有新连接,就建立新连接。之后,主线程把这个通信的任务给到线程池里边,把主线程的那个EventLoop也传进来。一定要注意这个EventLoop和主线程的EventLoop是同一个实例。也就是说,线程池里边的这个MainEventLoop和外边这个MainEventLoop它们对应的是同一块内存地址。
另外,在线程池里边还有若干个子线程,每个子线程里边都对应一个EventLoop。每个子线程里边的EventLoop它们主要是处理通信的文件描述符相关的操作。这些都是在子线程里边来完成的:
- 比如说要把一个通信的文件描述符添加到EventLoop里边。
- 如果服务器和客户端断开连接了,那么就需要把通信的文件描述符从EventLoop里边删除或者要修改这个通信的文件描述符检测的事件
【思考】那么,为什么右侧的TcpConnection里边也有一个EventLoop呢?
关于这个TcpConnection,其实它是封装了用于通信的文件描述符,在这个模块里边,是把子线程里边那个EventLoop的地址传递给了TcpConnection。
在每个线程里边,都有一个EventLoop,也就是说EventLoop是属于线程的,不管是主线程还是子线程,里边都有一个EventLoop。然后在这个TcpConnection里边,也有一个EventLoop,但是不是说EventLoop属于TcpConnection,而是TcpConnection属于EventLoop。
如果TcpConnection,它属于EventLoop,那么这个TcpConnection就属于对应的某一个子线程。EventLoop属于哪个子线程,这个TcpConnection它就属于哪个子线程。它对应的那些任务处理就是和客户端通信,接收数据以及发送数据的操作就在哪个子线程里边来完成。在线程池里边传进来了一个主线程EventLoop,主线程的EventLoop也是一个反应堆实例。
【思考】为什么要把主线程的反应堆实例传递给线程池呢?
是因为我们在给线程池做初始化的时候,如果指定线程池的子线程个数为0,此时线程池就没有了,不能工作。
为了能够保证线程池能够工作,也就传进来了一个主线程的反应堆实例,在没有子线程的情况下,那么就借用主线程的反应堆实例来完成对应的这一系列的任务处理。在此时,客户端和服务器建立连接之后,得到了用于通信的文件描述符,这个通信的文件描述符被TcpConnection封装起来了。我们就需要把这个TcpConnection放到一个反应堆模型里边,就是放到主线程的EventLoop里边,这样客户端和服务器的通信操作也就能实现了。这种比较极端的情况,对于程序来说,它就是一个单反应堆模型。
- 如果在创建线程池的时候指定这个子线程的个数大于0,那么就是一个多反应堆的服务器模型。
- 如果在创建线程池的时候指定线程的个数等于0,此时就是一个单反应堆的服务器模型。
>>总结
(1)反应堆模型中的EventLoop介绍
- 详细介绍了反应堆模型中的EventLoop,包括它的主要作用、如何被多个线程操作,以及它与任务队列和Dispatcher检测模型的关系。对于理解反应堆模型的工作原理至关重要。
(2)主线程与子线程的交互过程
- 主线程与子线程通过任务队列进行交互,子线程处理通信相关的文件描述符操作。
- 主线程它只能负责和客户端建立连接,如果这个连接建立好了,剩下的事情都是需要由这个子线程来完成的。所以主线程肯定不会给你去处理任务队列里边的节点。在主线程里边,其实它是有一个反应堆模型的,在当前的这个子线程里边也有一个反应堆模型。每个反应堆模型里边都有一个Dispatcher。关于这个Dispatcher就是epoll、poll、或者select,所以主线程去处理的话,这个任务就放到主线程的那个Dispatcher里边了,这样很显然是不对的。故在子线程的任务队列里边有了任务之后,还需要交给子线程的Dispatcher去处理。
- 因此这个节点的处理,还需要判断当前线程到底是什么线程。如果它是主线程不能让它去处理,如果是子线程,直接让它去处理。
(3)EventLoop与任务队列的关系
- 当任务队列中有任务时,会通过循环遍历链表,将任务添加到Dispatcher对应的检测模型中。
(4)文件描述符的管理
- 新连接建立或断开时,或要修改Dispatcher检测的这些文件描述符对应的事件时,文件描述符的添加、删除和修改操作都与EventLoop紧密相关。
未完待续~