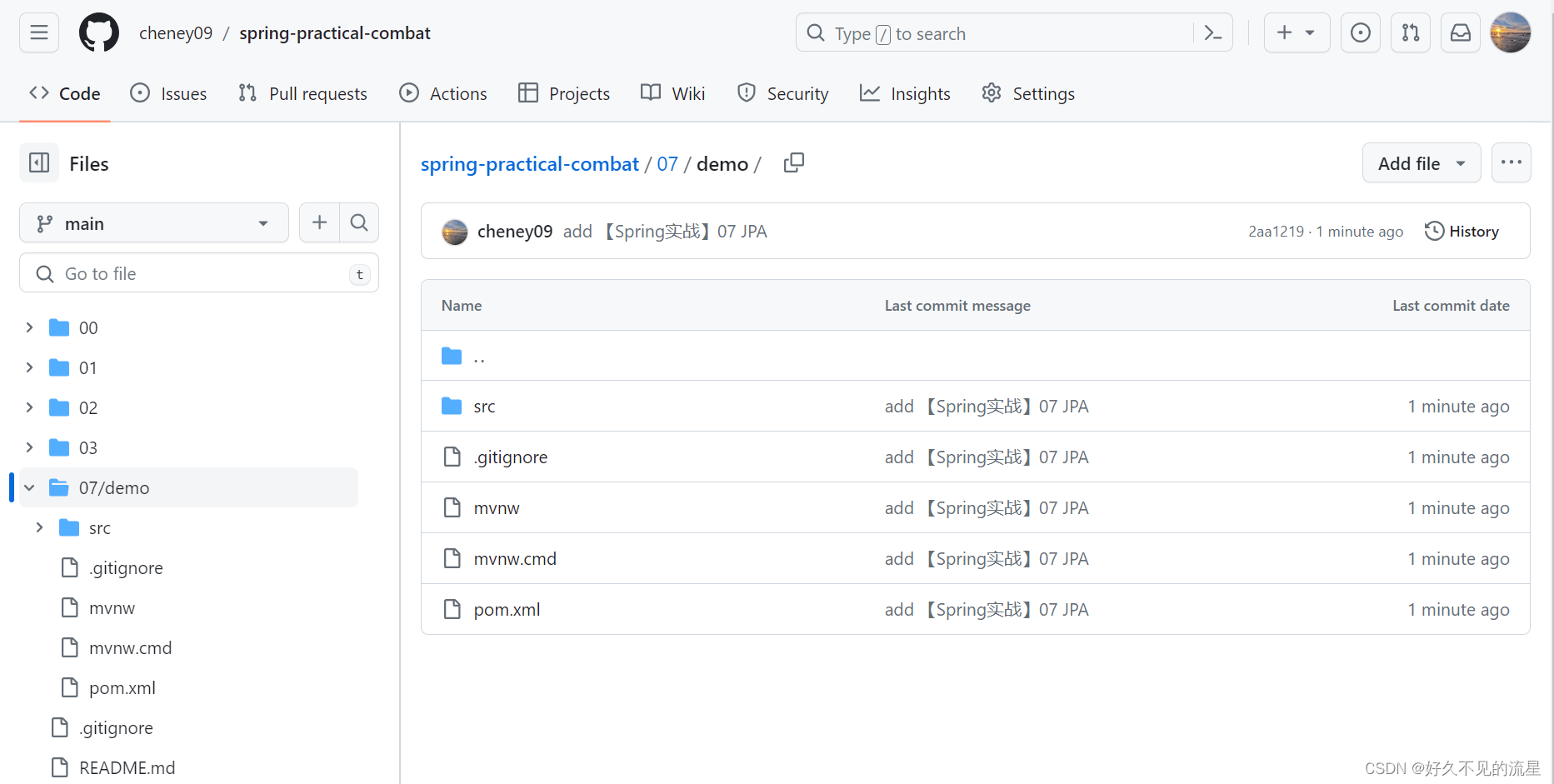
目录
一、Kurbernetes
1.2、K8S的特性:
1.3、docker和K8S:
1.4、K8S的作用:
1.5、K8S的特性:
二、K8S集群架构与组件:
三、K8S的核心组件:
一、master组件:
1、kube-apiserver:
2、kube-controller-manager:
3、kube-scheduler:
4、ETCD组件:
二、node组件:
1、kubelet:
2、kube-proxy:
3、docker:
4、pod:
5、deployment:
6、replicaset:
7、daemonset:
8、statefulset:
9、job:
10、cronjob:
11、service:
12、label:
13、ingress:
14、namespace:
一、Kurbernetes
1.1 简介
K8S:kubernets中间8个字母省略就是K8S
K8S是负责自动化运维管理多个容器化程序的集群,是一个功能强大的容器编排工具。可以以分布式和集群化的方式进行容器管理
能提供自动部署,自动扩展和管理容器化部署的应用程序的一个开源的系统
K8S是Google研发的borg系统作为原型,后期经go语言编写的开源软件
Kubernetes 官网
GitHub - kubernetes/kubernetes: Production-Grade Container Scheduling and Management 源码包
市面上的版本:
1.15、1.18、1.20
我们使用的是1.20
1.2、K8S的特性:
1、强大的容器编排能力
作为容器编排管理平台,拥有强大的容器编排能力。
Kubernetes 与 Docker 共同发展并且深度集成了 Docker,因此适应容器的特点,比如容器组合、标签选择和服务发现等,可以满足企业级的需求,具体表现如下:
以 Pod(容器组)为基本的编排和调度单元以及声明式的对象配置模型(控制器、configmap、secret 等)
资源配额与分配管理
健康检查、自愈、伸缩与滚动升级
2、轻量级
轻量级,对微服务架构有很好的支撑。
微服务架构的核心是将一个巨大的单体应用分解为很多小的互相连接的微服务,一个微服务可能由多个实例副本支撑,副本的数量可以随着系统的负荷变化进行调整。
整个系统划分出各个功能独立的组件,组件之间边界清晰、部署简单,以及很多功能实现了插件化,可以非常方便地进行扩展和替换:
服务发现、服务编排与内部路由支持
服务快速部署和自动负载均衡
提供对“有状态”服务的支持
3、便携性
无论公有云、私有云、混合云还是多云架构都全面支持,可以随时随地地将系统整体进行“搬迁”。
Kubernetes 架构方案中屏蔽了底层网络的细节,基于服务的虚拟 IP 地址的设计方式让架构和底层硬件无关,无需改变配置文件就可以将系统从物理机迁移到公有云上,并且谷歌云(GCE)、华为云(CCE)、阿里云(ACK)和腾讯云(TKE)都支持 Kubernetes 集群。
1.3、docker和K8S:
docker微服务,可以满足微服务使用,那么为什么还要使用K8S呢
- 传统的部署方式:一般意义上的二进制部署,安装-运行-运行维护,需要专业的人员,如果出了故障还需要人工重新拉起来。而且如果业务量增大,只能水平的进行拓展,再部署一台
- 容器化,我们可以用dockerfile编写好我们自定义的容器,随时基于镜像都可以运行。数量少还能管的过来。数量一旦太多,管理起来太复杂。而且docker一般是单机运行,没有高可用
1.4、K8S的作用:
简单,高效的部署容器化应用
- 解决了docker的单机部署和无法集群化的特点
- 解决了随着容器数量的增加,对应增加的管理成本
- 容器的高可用,提供容器的自愈机制
- 解决了容器没有预设模版,以及无法快速、大规模部署。以及大规模的容器调度
- K8S提供了集中化配置管理的中心
- 解决了容器的生命周期的管理工具
- 提供了图形化工具,可以用图形化工具对容器进行管理
K8S是基于开源的容器集群管理系统,在docker容器技术的基础之上,为容器化的集群提供部署、运行、资源调度、服务发现、动态伸缩等一系列完整的功能(大规模容器)
- 对docker等容器技术从应用的包——部署——运行——停止——销毁,全生命周期管理
- 集群方式运行,可以跨机器管理容器
- 解决docker的跨机器运行的网络问题
- K8S可以自动修复,使得整个容器集群可以在用户期待的状态下运行。
1.5、K8S的特性:
- 弹性伸缩,基于命令,或者图形化界面,以及CPU的使用情况,自动的对部署的程序进行扩容和缩容。以最小的成本来运行服务
- 自我修复:节点故障时,他可以自动的重新启动失败的容器,替换和重新部署
- 服务发现和负载均衡(自带的):K8S为多个容器提供一个统一的访问入口(内部地址和内部DNS名称),自动负载均衡关联的所有容器
- 自动发布和回滚:K8S采用滚动的更新策略来更新应用。如果更新过程中出现问题,可以根据回滚点来进行回滚
- 集中化的配置管理和秘钥管理:K8S集群中的各个组件都是要进行密钥对验证的。但是K8S得安全性还是不够,核心的组件不建议部署(mysql和nginx不建议),适合部署自定义应用
- 存储编排
·自动化的把容器部署在节点上
·也可以通过命令行或者yml文件(自定义pod)来实现指定节点部署
·也可以通过网络存储,NFS GFS
任务进行批次处理。提供一次性的任务,提供定时任务,满足需要批量处理和分析的场景
二、K8S集群架构与组件:
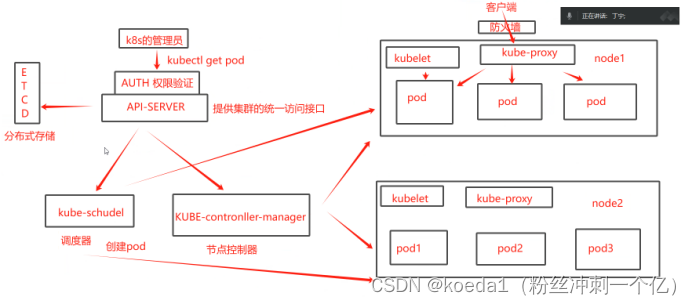
三、K8S的核心组件:
Kubernetes 采用主从分布式架构,节点在角色上分为 Maste 和 Node。
Kubernetes Master 是控制节点,负责k8s集群的调度、管理等运维工作,组件有apiserver、controller-manager、scheduler、etcd。
Kubernetes Node 是运行节点,负责运行工作负载,即容器应用,组件有kubelet、kuber-proxy、容器引擎/容器运行时(docker、containerd)等。
一、master组件:
1、kube-apiserver:
K8S集群之中每个组件都是要靠密钥对进行验证,组件之间通信靠apiserver,API是应用接口服务,K8S的所有资源请求和调用操作都是kube-apiserver来完成,所有对象资源的增、删、改、查和监听的操作都是kubu-apiserver处理完之后交给etcd来进行
apiserver是K8S所有请求的入口服务,apiserver负责接收K8S的所有请求(命令行、图形化界面),然后根据用户的具体请求,通知对应的组件展示或者运行命令
apiserver相当于整个集群的大脑
2、kube-controller-manager:
运行管理控制器。是K8S集群中处理常规任务的后台线程。是集群中所有资源对象的自动化控制中心。一个资源对应一个控制器,controller-manager负责管理这些控制器
·node controller(节点控制器):负责节点的发现以及节点故障的发现和响应
·replication controller(副本控制器):控制关联pod的副本数,可以随时扩缩容
·endpoints controller(端点控制器):监听service和对应pod的副本变化。端点就是一个服务暴露出的访问点。要访问这个服务,必须要知道他的endpoints。就是每个服务的IP地址+端口
·service account和roken controller(服务账户和令牌控制):为命名空间创建默认账户和api访问令牌。访问不同的namespace命名空间
·resourcequota controller(资源控制器):可以对命名空间的资源使用进行控制,也可以对pod的资源进行控制
·namespace controller(命名空间控制器):管理命名空间的生命周期
·service controller(服务节点控制器):K8S集群和外部的主机之间的接口控制器。
3、kube-scheduler:
资源调度组件,根据调度的算法为新创建的pod选择一个合适的node节点
可以理解为K8S的所有node节点的调度器,部署和调度node
预先策略:人工定制,指定node节点上部署
优先策略:有限制条件。根据调度算法选择一个合适的node,node节点的资源情况,node节点的资源控制的情况等等,选一个资源最富裕,负载最小的node来部署
4、ETCD组件:
是K8S的存储服务,etcd是分布式键值存储系统(key:value),存储K8S的关键配置和用户配置,先通过apiserver调用etcd当中的存储信息,然后再实施。在整个集群中,能对etcd存储进行读写权限的,只有apiserver
一般来说四大核心组件都部署在主节点上
二、node组件:
1、kubelet:
node节点的监视器,以及与master节点的通信器,也可以理解为master安装在node节点上的监控眼线。
kubelet会定时向api server汇报自己的node上运行服务的状态,api server会把节点状态保存在etcd存储中
能够接收来自master节点的调度命令。如果发现自己的状态和master节点的状态不一致,调用docker的接口,同步数据。
对接点上的生命周期进行管理,保证节点上的镜像不会占满磁盘空间,退出容器的资源,进行回收
2、kube-proxy:
实现每个node节点上pod的网络代理。负责节点上的网络规划和四层负载均衡工作。负责写入iptables(快淘汰了)、ipvs实现服务映射
kube-proxy:本身不直接给pod提供网络代理,proxy只是service资源的载体

访问:192.168.233.91:34943——10.299.96.10:80(proxy代理)——最后到每个集群nginx节点ip(负载均衡轮询)
kube-proxy:实际上代理的是pod的集群网络(虚拟网络)
K8S的每个node节点上都有一个kube-proxy组件
3、docker:
容器引擎,运行容器,负责本机的容器创建和管理
pod不是容器,是基于容器创建的pod
K8S要创建pod时,kube-scheduler调度到节点上(node节点),节点上的kubelet指示docker启动特定的容器。kubelet把容器的信息收集,发送给主节点。只需要在主节点发布指令,节点上的kubelet就会指示docker对容器进行拉取镜像、启动、停止容器
4、pod:
也是运行在节点上的。是K8S中创建部署的最小的也是最简单的基本单位,一个pod只代表集群上正在运行的进程。
同一个pod内每个容器就像是一颗颗豌豆子,pod就是豌豆
pod是由一个或多个容器组成,pod中的容器共享网络,存储和计算资源。可以部署在不同的docker主机上
一个pod里面可以运行多个容器,也可以是一个容器
在生产环境中,一般是单个容器或者具有关联关系的多个容器组成一个pod
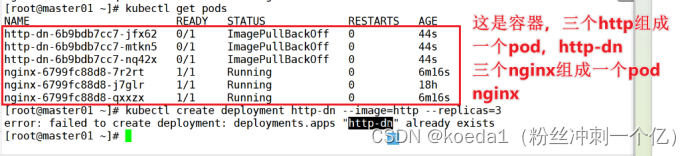
容器是容器,pod是pod。pod是基于容器创建的
5、deployment:
无状态应用部署,作用就是管理和控制pod以及他的replicaset(副本数,表示运行几个容器)管控他的运行状态
6、replicaset:
保证pod的副本数据量,受控于deployment。
在K8S中部署服务,实际上就是pod,deployment部署的服务就是pod,replicaset就是来定义pod的容器数量
可以保证pod的不可重复性。在当前命名空间不能重复。不同命令空间名称可以重复
官方推荐使用deployment进行服务部署
7、daemonset:
确保所有节点运行同一类的pod
8、statefulset:
有状态应用部署。
9、job:
可以给pod中设置一个一次性任务,运行完即退出
10、cronjob:
一直在运行的周期性任务,默认就是cronjob
11、service:
在K8S集群中,创建一个pod之后,都会将其中运行的容器分配一个集群内的IP地址,由于业务的变更,容器可能会发生变化,IP地址也会发生变化,service的作用就是提供整个pod对外统一的IP地址(cluster-ip)
可以将service理解成一个网关(路由器),通过访问service就可以访问pod内部的容器集群
service能实现负载均衡和代理——kube-proxy——来实现负载均衡
service是K8S微服务的核心,屏蔽了服务的细节,统一的对外暴露的端口,真正实现了“微服务”
service的流量调度:userspace(用户空间,已经废弃了),iptables(即将废弃),ipvs(目前1.20都用ipvs来实现流量调度)
12、label:
标签,K8S的特色管理方式,分类管理资源对象
node pod service namespace
label标签可以用户自定义
lable选择器:等于,不等于,使用定义的标签名
13、ingress:
K8S集群对外暴露提供访问的接口
ingress在第七层属于应用层,七层代理,转发的是http请求,http/https。
service是四层转发,转发的是流量
https://www.test.com:80——>ingress——>service——pod——容器
14、namespace:
K8S上可以通过namespace命名空间的方式来实现资源隔离、项目隔离
通过namespace可以把集群划分为多个资源不可共享的虚拟集群组
不同命令空间里面的资源,名称可以重复