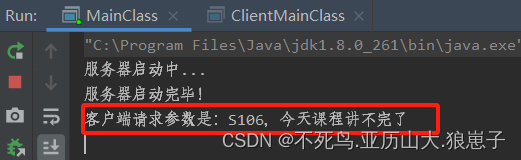
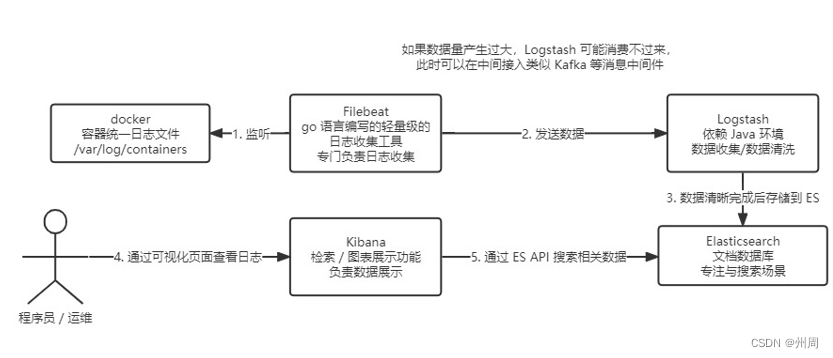
首先查看总体流程
首先创建namespace
apiVersion: v1
kind: Namespace
metadata:
name: kube-logging一、首先创建es.yaml
---
apiVersion: v1 #kubernetes API版本,采用最新版本v1
kind: Service #资源类型定义为Service
metadata:
name: elasticsearch-logging # 服务名称elasticsearch-logging
namespace: kube-logging #命名空间为kube-logging
labels: #标签,用于服务选择器匹配
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Elasticsearch"
spec:
# 定义用于访问 Elasticsearch 的端口
ports:
- port: 9200
protocol: TCP
targetPort: db
# 定义用于标识应属于此服务的 Pod 的选择器
selector:
k8s-app: elasticsearch-logging
---
# RBAC authn and authz
apiVersion: v1
# ServiceAccount 定义用于 Elasticsearch 日志记录
kind: ServiceAccount
metadata:
name: elasticsearch-logging
namespace: kube-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
#用于授予用户对集群中的所有资源的访问权限,Role只对命名空间级别
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
#resources 字段指定了规则适用于哪些资源类型
resources:
- "services"
- "namespaces"
- "endpoints"
#verbs 字段指定了规则允许执行的操作
verbs:
- "get"
---
#ClusterRoleBinding 用于将 ClusterRole 绑定到用户或组
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: kube-logging
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
#以下说明给ServiceAccount授予在ClusterRole中定义的权限
subjects:
- kind: ServiceAccount #指定角色绑定的实体类型
name: elasticsearch-logging
namespace: kube-logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: elasticsearch-logging
apiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1
kind: StatefulSet #使用statefulset创建Pod
metadata:
name: elasticsearch-logging #pod名称,使用statefulSet创建的Pod是有序号有顺序的
namespace: kube-logging #命名空间
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
srv: srv-elasticsearch
spec:
serviceName: elasticsearch-logging #与svc相关联,这可以确保使用以下DNS地址访问Statefulset中的每个pod (es-cluster-[0,1,2].elasticsearch.elk.svc.cluster.local)
replicas: 1 #副本数量,单节点
#selector用于指定 StatefulSet 的 Pod 选择器,只有拥有k8s-app的labels才能被匹配
selector:
matchLabels:
k8s-app: elasticsearch-logging #和pod template配置的labels相匹配
template:
metadata:
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
spec:
#表示这个pod使用serviceAccount的名字
serviceAccountName: elasticsearch-logging
containers:
- image: docker.io/library/elasticsearch:7.9.3
name: elasticsearch-logging
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 100m
memory: 500Mi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: elasticsearch-logging
mountPath: /usr/share/elasticsearch/data/ #挂载点
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "discovery.type" #定义单节点类型
value: "single-node"
- name: ES_JAVA_OPTS #设置Java的内存参数,可以适当进行加大调整
value: "-Xms512m -Xmx2g"
volumes:
- name: elasticsearch-logging
hostPath:
path: /data/es/
nodeSelector: #如果需要匹配落盘节点可以添加 nodeSelect
es: data
tolerations:
- effect: NoSchedule
operator: Exists
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
initContainers: #容器初始化前的操作
- name: elasticsearch-logging-init
image: alpine:3.6
command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"] #添加mmap计数限制,太低可能造成内存不足的错误
securityContext: #仅应用到指定的容器上,并且不会影响Volume
privileged: true #运行特权容器
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"] #修改文件描述符最大数量
securityContext:
privileged: true
- name: elasticsearch-volume-init #es数据落盘初始化,加上777权限
image: alpine:3.6
command:
- chmod
- -R
- "777"
- /usr/share/elasticsearch/data/
volumeMounts:
- name: elasticsearch-logging
mountPath: /usr/share/elasticsearch/data/
二、创建logstach.yaml
---
apiVersion: v1
kind: Service #指定了资源的类型,这里是 Service,用于定义服务的属性
metadata: #包含资源的元数据,如名称、命名空间等。
name: logstash
namespace: kube-logging
spec: #包含服务的规格,定义了如何创建和运行服务。
ports: #指定了服务暴露的端口
- port: 5044 #服务监听的端口号
targetPort: beats #将服务请求转发到的 Pod 的端口。
selector: #指定了 Pod 的标签选择器,用于匹配需要访问该服务的 Pod
type: logstash #匹配的标签。
clusterIP: None #设置为 None 表示这是一个无头服务(Headless Service),它不会创建一个虚拟 IP,而是直接将流量转发到匹配的 Pod
---
apiVersion: apps/v1
kind: Deployment #定义了一个 Deployment,用于管理 Pod 的生命周期和副本数。
metadata: #包含 Deployment 的元数据
name: logstash
namespace: kube-logging
spec:
selector:
matchLabels:
type: logstash
template:
metadata:
labels:
type: logstash
srv: srv-logstash
spec:
containers:
- image: docker.io/kubeimages/logstash:7.9.3 #该镜像支持arm64和amd64两种架构
name: logstash
ports:
- containerPort: 5044
name: beats
command:
- logstash
- '-f'
- '/etc/logstash_c/logstash.conf'
env:
- name: "XPACK_MONITORING_ELASTICSEARCH_HOSTS"
value: "http://elasticsearch-logging:9200"
volumeMounts:
- name: config-volume
mountPath: /etc/logstash_c/
- name: config-yml-volume
mountPath: /usr/share/logstash/config/
- name: timezone
mountPath: /etc/localtime
resources: #logstash一定要加上资源限制,避免对其他业务造成资源抢占影响
limits:
cpu: 1000m
memory: 2048Mi
requests:
cpu: 512m
memory: 512Mi
volumes:
- name: config-volume
configMap:
name: logstash-conf
items:
- key: logstash.conf
path: logstash.conf
- name: timezone
hostPath:
path: /etc/localtime
- name: config-yml-volume
configMap:
name: logstash-yml
items:
- key: logstash.yml
path: logstash.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-conf
namespace: kube-logging
labels:
type: logstash
data:
logstash.conf: |-
input {
beats {
port => 5044
}
}
filter {
# 处理 ingress 日志
if [kubernetes][container][name] == "nginx-ingress-controller" {
json {
source => "message"
target => "ingress_log"
}
if [ingress_log][requesttime] {
mutate {
convert => ["[ingress_log][requesttime]", "float"]
}
}
if [ingress_log][upstremtime] {
mutate {
convert => ["[ingress_log][upstremtime]", "float"]
}
}
if [ingress_log][status] {
mutate {
convert => ["[ingress_log][status]", "float"]
}
}
if [ingress_log][httphost] and [ingress_log][uri] {
mutate {
add_field => {"[ingress_log][entry]" => "%{[ingress_log][httphost]}%{[ingress_log][uri]}"}
}
mutate {
split => ["[ingress_log][entry]","/"]
}
if [ingress_log][entry][1] {
mutate {
add_field => {"[ingress_log][entrypoint]" => "%{[ingress_log][entry][0]}/%{[ingress_log][entry][1]}"}
remove_field => "[ingress_log][entry]"
}
} else {
mutate {
add_field => {"[ingress_log][entrypoint]" => "%{[ingress_log][entry][0]}/"}
remove_field => "[ingress_log][entry]"
}
}
}
}
# 处理以srv进行开头的业务服务日志
if [kubernetes][container][name] =~ /^srv*/ {
json {
source => "message"
target => "tmp"
}
if [kubernetes][namespace] == "kube-logging" {
drop{}
}
if [tmp][level] {
mutate{
add_field => {"[applog][level]" => "%{[tmp][level]}"}
}
if [applog][level] == "debug"{
drop{}
}
}
if [tmp][msg] {
mutate {
add_field => {"[applog][msg]" => "%{[tmp][msg]}"}
}
}
if [tmp][func] {
mutate {
add_field => {"[applog][func]" => "%{[tmp][func]}"}
}
}
if [tmp][cost]{
if "ms" in [tmp][cost] {
mutate {
split => ["[tmp][cost]","m"]
add_field => {"[applog][cost]" => "%{[tmp][cost][0]}"}
convert => ["[applog][cost]", "float"]
}
} else {
mutate {
add_field => {"[applog][cost]" => "%{[tmp][cost]}"}
}
}
}
if [tmp][method] {
mutate {
add_field => {"[applog][method]" => "%{[tmp][method]}"}
}
}
if [tmp][request_url] {
mutate {
add_field => {"[applog][request_url]" => "%{[tmp][request_url]}"}
}
}
if [tmp][meta._id] {
mutate {
add_field => {"[applog][traceId]" => "%{[tmp][meta._id]}"}
}
}
if [tmp][project] {
mutate {
add_field => {"[applog][project]" => "%{[tmp][project]}"}
}
}
if [tmp][time] {
mutate {
add_field => {"[applog][time]" => "%{[tmp][time]}"}
}
}
if [tmp][status] {
mutate {
add_field => {"[applog][status]" => "%{[tmp][status]}"}
convert => ["[applog][status]", "float"]
}
}
}
mutate {
rename => ["kubernetes", "k8s"]
remove_field => "beat"
remove_field => "tmp"
remove_field => "[k8s][labels][app]"
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch-logging:9200"]
codec => json
index => "logstash-%{+YYYY.MM.dd}" #索引名称以logstash+日志进行每日新建
}
}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-yml
namespace: kube-logging
labels:
type: logstash
data:
logstash.yml: |-
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: http://elasticsearch-logging:9200
三、创建filebeat.yaml
---
apiVersion: v1
kind: ConfigMap #定义了一个 ConfigMap,用于存储 Filebeat 的配置文件
metadata: #包含 ConfigMap 的元数据
name: filebeat-config
namespace: kube-logging
labels:
k8s-app: filebeat #用于标识 ConfigMap 的标签。
data:
filebeat.yml: |- #Filebeat 的配置文件内容
filebeat.inputs: #定义了 Filebeat 的输入源
- type: container #输入类型为容器
enable: true #启用容器输入
paths:
- /var/log/containers/*.log #这里是filebeat采集挂载到pod中的日志目录
processors:
- add_kubernetes_metadata: #添加k8s的字段用于后续的数据清洗
host: ${NODE_NAME} #使用节点名称作为主机名
matchers:
- logs_path:
logs_path: "/var/log/containers/" #指定日志路径
#output.kafka: #如果日志量较大,es中的日志有延迟,可以选择在filebeat和logstash中间加入kafka
# hosts: ["kafka-log-01:9092", "kafka-log-02:9092", "kafka-log-03:9092"]
# topic: 'topic-test-log'
# version: 2.0.0
output.logstash: #因为还需要部署logstash进行数据的清洗,因此filebeat是把数据推到logstash中
hosts: ["logstash:5044"] #Logstash 服务的地址和端口
enabled: true #启用 Logstash 输出
---
apiVersion: v1
kind: ServiceAccount #定义了一个 ServiceAccount,用于运行 Filebeat Pod
metadata: #包含 ServiceAccount 的元数据
name: filebeat
namespace: kube-logging
labels: #用于标识 ServiceAccount 的标签。
k8s-app: filebeat
---
apiVersion: rbac.authorization.k8s.io/v1 #定义了一个 ClusterRole,用于授予 ServiceAccount 权限。
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules: #定义了 ClusterRole 的规则。
- apiGroups: [""] # "" indicates the core API group
resources: #指定资源
- namespaces
- pods
verbs: ["get", "watch", "list"] #指定操作
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding #将 ClusterRole 绑定到 ServiceAccount
metadata:
name: filebeat
subjects: #定义了 ClusterRoleBinding 的主体。
- kind: ServiceAccount #主体类型为 ServiceAccount
name: filebeat
namespace: kube-logging
roleRef:
kind: ClusterRole #引用了 ClusterRole
name: filebeat #引用的 ClusterRole 名称
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: DaemonSet #定义了一个 DaemonSet,用于确保在每个节点上运行一个 Filebeat Pod。
metadata:
name: filebeat #包含 DaemonSet 的元数据。
namespace: kube-logging
labels:
k8s-app: filebeat #用于标识 DaemonSet 的标签
spec: #包含 DaemonSet 的规格
selector: #定义了 DaemonSet 的选择器。
matchLabels:
k8s-app: filebeat
template: #定义了 Pod 的模板。
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: docker.io/kubeimages/filebeat:7.9.3 #该镜像支持arm64和amd64两种架构
args: [
"-c", "/etc/filebeat.yml",
"-e","-httpprof","0.0.0.0:6060"
]
#ports:
# - containerPort: 6060
# hostPort: 6068
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: ELASTICSEARCH_HOST
value: elasticsearch-logging
- name: ELASTICSEARCH_PORT
value: "9200"
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 1000Mi
cpu: 1000m
requests:
memory: 100Mi
cpu: 100m
volumeMounts:
- name: config #挂载的是filebeat的配置文件
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data #持久化filebeat数据到宿主机上
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers #这里主要是把宿主机上的源日志目录挂载到filebeat容器中,如果没有修改docker或者containerd的runtime进行了标准的日志落盘路径,可以把mountPath改为/var/lib
mountPath: /var/lib
readOnly: true
- name: varlog #这里主要是把宿主机上/var/log/pods和/var/log/containers的软链接挂载到filebeat容器中
mountPath: /var/log/
readOnly: true
- name: timezone
mountPath: /etc/localtime
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath: #如果没有修改docker或者containerd的runtime进行了标准的日志落盘路径,可以把path改为/var/lib
path: /var/lib
- name: varlog
hostPath:
path: /var/log/
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
- name: data
hostPath:
path: /data/filebeat-data
type: DirectoryOrCreate
- name: timezone
hostPath:
path: /etc/localtime
tolerations: #加入容忍能够调度到每一个节点
- effect: NoExecute
key: dedicated
operator: Equal
value: gpu
- effect: NoSchedule
operator: Exists
四、创建kibana.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-logging
name: kibana-config
labels:
k8s-app: kibana
data: #包含 ConfigMap 中的数据。
kibana.yml: |- #Kibana 的配置文件内容
server.name: kibana
server.host: "0" #允许 Kibana 监听所有网络接口
i18n.locale: zh-CN #设置默认语言为中文
elasticsearch:
hosts: ${ELASTICSEARCH_HOSTS} #es集群连接地址,由于我这都都是k8s部署且在一个ns下,可以直接使用service name连接
---
apiVersion: v1
kind: Service #用于公开 Kibana 服务。
metadata:
name: kibana
namespace: kube-logging
labels:
k8s-app: kibana
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Kibana"
srv: srv-kibana
spec: #包含 Service 的规格。
type: NodePort #Service 类型为 NodePort,允许外部通过节点的 IP 和端口访问服务
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector: #定义了 Service 的选择器。
k8s-app: kibana
---
apiVersion: apps/v1
kind: Deployment #定义了一个 Deployment,用于管理 Kibana Pod 的生命周期和副本数。
metadata:
name: kibana
namespace: kube-logging
labels:
k8s-app: kibana
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
srv: srv-kibana
spec: #包含 Deployment 的规格
replicas: 1
selector:
matchLabels:
k8s-app: kibana
template: #定义了 Pod 的模板。
metadata:
labels:
k8s-app: kibana
spec:
containers:
- name: kibana
image: docker.io/kubeimages/kibana:7.9.3 #该镜像支持arm64和amd64两种架构
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_HOSTS
value: http://elasticsearch-logging:9200
ports:
- containerPort: 5601
name: ui
protocol: TCP
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
volumes:
- name: config
configMap:
name: kibana-config
---
apiVersion: networking.k8s.io/v1
kind: Ingress #定义了一个 Ingress,用于将外部 HTTP/HTTPS 流量路由到内部服务。
metadata:
name: kibana
namespace: kube-logging
spec:
ingressClassName: nginx
rules:
- host: kibana.wolfcode.cn
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kibana
port:
number: 5601


![[C/C++]数据结构 希尔排序](https://img-blog.csdnimg.cn/direct/78cd6c968f3e4f21af9b09874b8bb830.png)