目录
摘要
Abstract
文献阅读:锂离子电池RUL预测的SA-LSTM
现有问题
提出方法
提出方法的结构
SA-LSTM预测模型的结构
研究实验
研究贡献
注意力机制
Self-Attention(自注意力机制)
注意力与自注意力
代码实现attention、self-attention和multi-head attention
摘要
这周阅读的文献提出了一种自适应自我注意长短期记忆(SA-LSTM)预测模型,用于预测锂离子电池的剩余使用寿命(RUL)。结合了LSTM和SA的优点,在基于LSTM的时间序列预测模型中引入掩面多头自注意模块,捕获序列中的关键信息,提高预测性能。注意力机制主要是引入了注意力机制这个概念,借助查询者Q找到权重。自注意力机制主要是根据两两之间的关系来引入权重,在通道、空间两个层面,通过计算每个单元通道与通道之间、像素点与像素点之间的值,来加强两两之间的联系,进而提高精确度语义分割。
Abstract
This week's article presents an Adaptive Self-attention Long Short-term memory (SA-LSTM) prediction model for predicting the remaining useful life (RUL) of lithium-ion batteries. Combining the advantages of LSTM and SA, the masked multi-head self-attention module is introduced into the LSTM-based time series prediction model to capture the key information in the series and improve the prediction performance. The attention mechanism mainly introduces the concept of the attention mechanism, and finds the weight with the help of the interrogator Q. The self-attention mechanism mainly introduces the weight according to the relationship between the two pairs, and strengthens the connection between the two pairs by calculating the value between each unit channel and channel and between pixel and pixel at the two levels of channel and space, thus improving the precision semantic segmentation.
文献阅读:锂离子电池RUL预测的SA-LSTM
Adaptive self-attention LSTM for RUL prediction of lithium-ion batteries
Redirecting
现有问题
电池退化是一个未知的、全面的非线性动态过程,受内部电化学反应和外部工作条件复杂相互作用的影响。这种非线性动态过程导致电池在运行过程中出现了复杂的退化现象,如电池寿命中期到后期的加速退化(AD)和电池静止阶段的局部再生现象(CRP)。因此,必须建立一个合适的模型来准确地描述lib的降解模式和动力学,这是一个具有挑战性的问题。此外,电池的寿命通常达到数百甚至数千次循环,满足了长寿命和高存储的实际要求。长寿命对电池退化过程的长期依赖关系建模提出了挑战。此外,作为RUL预测最常用的直接指标,电池容量和电阻不能在线测量,而只能在实验室中使用特定的测量设备或操作条件。
提出方法
为了准确预测锂离子电池的剩余使用寿命(RUL),提出了一种自适应自我注意长短期记忆(SA-LSTM)预测模型。创新之处包括:
- 采用优化的局部切空间对齐算法,从充电数据中提取能精确描述电池退化的间接健康指标(HI)。提取的HI与标准容量具有较高的相关性,从而便于RUL的估计。
- 在基于LSTM的时间序列预测模型中引入掩面多头自注意模块,捕获序列中的关键信息,提高预测性能。
- 设计了神经网络权值和偏差的在线自调整机制,以纠正长期预测中的累积估计误差,减少局部波动和再生的影响。
这种新的预测方法考虑了锂离子电池降解的特征和长期预测模型的构建,从而可以实现对锂离子电池的准确RUL预测。
提出方法的结构
在提出的自适应深度学习方法用于锂离子电池的剩余使用寿命(RUL)预测方法中,首先使用具有最优邻居域的改进LTSA从电池监测数据中自动提取描述电池退化的间接健康指标(HI)作为预测模型的输入。随后,构建了一个具有自调整机制的自适应自注意长短期记忆(SALSTM)神经网络,对未来HI值和RUL进行长期预测。
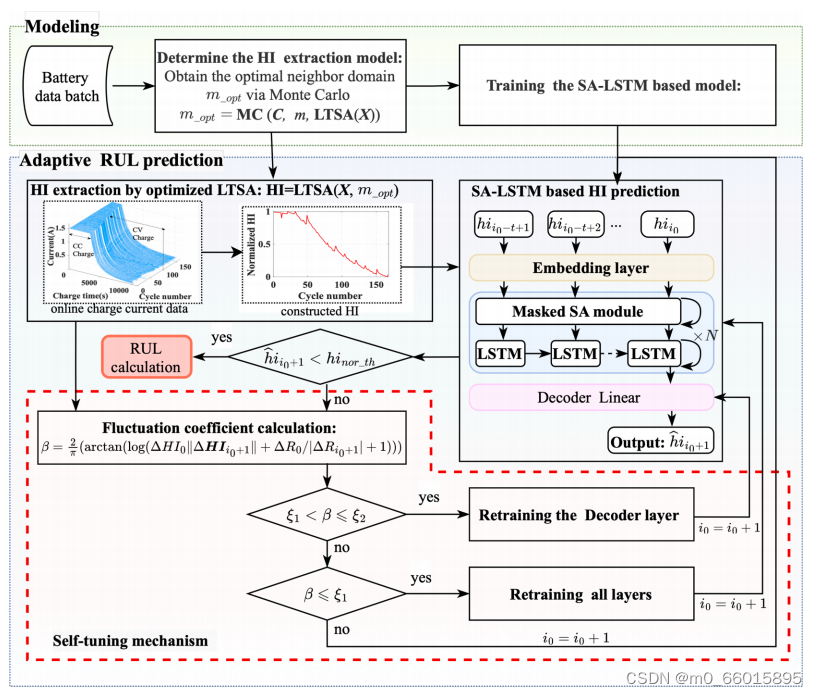
基于自适应SA-LSTM神经网络的lib规则预测框架
在建模阶段,需要锂离子电池的离线数据来确定LTSA的关键参数并建立SA-LSTM模型。LTSA用于将原始电荷电流数据映射到HI序列,从而实现从三维空间(即电流-电荷时间周期空间)到二维空间(即HI周期空间)的降维。LTSA的有效性很大程度上依赖于局部低维子空间,但是,本地子空间的大小通常是事先手动指定的。为了克服这一问题,采用MC算法根据实验室条件或工厂测试中获得的历史数据(包括充电电流和容量)搜索最优邻居域。
随后,建立了基于SA-LSTM神经网络的预测模型,并根据预测开始周期(PSC)从第一个充电周期到前一个充电周期的历史HI时间序列流进行预训练。一般来说,可以使用互补方法组合重建具有良好性能的增强神经网络体系结构。然而,单纯的叠加模型会造成参数探索和收敛困难,降低预测精度。因此将掩面多头自注意(MHA)模块和LSTM组合成一个块,从而使神经网络能够捕获HI序列中的有价值信息,并提高长期预测性能在自适应RUL预测阶段,SA-LSTM模型采用一步向前的方法迭代估计未来HI值,直到估计的HI达到其失效阈值,然后预测电池RUL。
值得注意的是,在对锂离子电池进行一步超前预测时,随着预测周期的增加,预测误差逐渐增大,这也被称为误差积累现象。出现这种现象是因为静态预测模型在电池在线运行时,特别是在局部波动和再生发生时,无法捕捉电池退化的动态特性。为了缓解HI序列预测中的频繁波动和局部再生问题,本文提出了一种基于在线自调整机制的SA-LSTM模型进行自适应HI预测。如图1所示,根据HI波动的强度及时更新模型参数,以适应当前的局部再生。因此,所设计的自适应预测模型可以减小迭代预测过程中积累的误差,达到满意的预测精度。
SA-LSTM预测模型的结构
1、Masked Multi-head Self-Attention(掩码多头自注意力)
MHA被提出作为标准Transformer体系结构的关键模块,用于捕捉任何历史序列中的重要特征而不考虑距离。多头结构通过将多个自注意模块与不同状态子空间的特征学习相结合,可以显著提高长期依赖的学习性能。从本质上讲,MHA通过每个头部的相互作用可以获得更好的预测性能,而单头部结构只强调了某些阶段的重要特征而忽略了其他阶段。此外,为了解决时间序列预测问题,在MHA中引入了一个额外的掩码机制,以防止将未来的值添加到计算中。
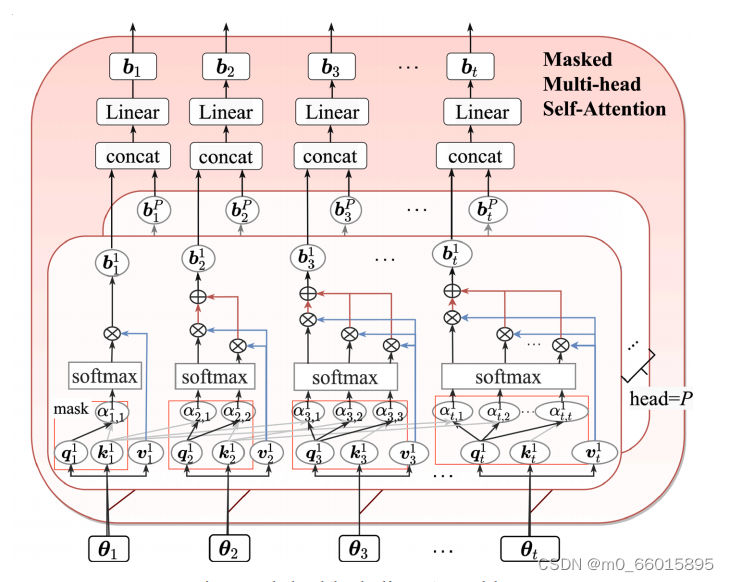
掩蔽多头自注意模块

2、LSTM
LSTM是一种典型的RNN,可以克服梯度爆炸和梯度消失的问题。通过引入记忆细胞和门控机制,在管理长期序列方面特别有利。单层LSTM的结构如图所示。
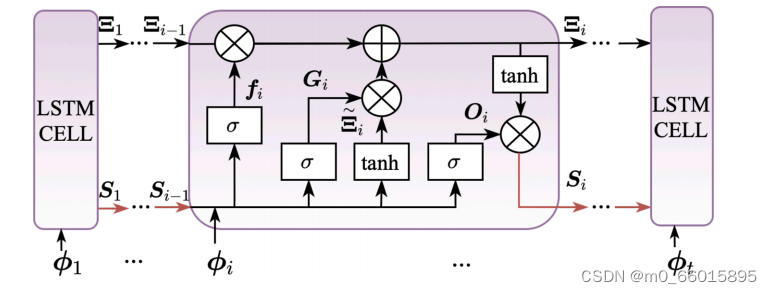
LSTM结构
3、SA-LSTM(自注意长短期记忆神经网络)
结合LSTM和SA的优点,提出了一种改进的长期依赖序列建模体系,提高了RUL预测的性能。为了获得更好的联合模型框架,将被屏蔽的MHA模块与标准LSTM级联成一个新的块,即SA-LSTM,可以将其视为预测模型中的一个集成组件。在SA-LSTM块内部,在被掩蔽的MHA和LSTM层周围利用了一个残余连接。随后,将SA-LSTM块堆叠N块形成编码器,这是锂离子电池RUL预测模型的主要结构。此外,在编码器之前加入嵌入层,在编码器之后使用密集线性连接进行回归预测,称为解码器。
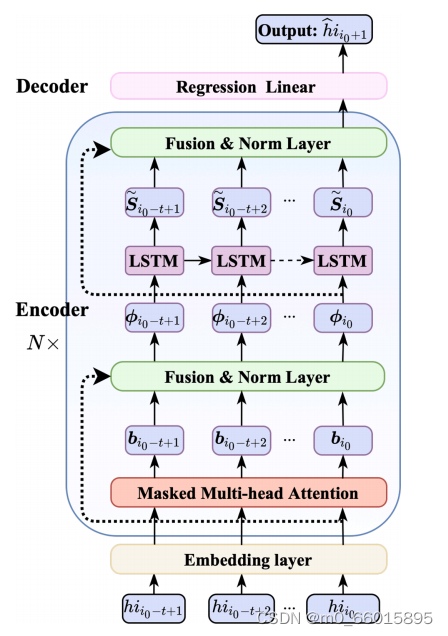
SA-LSTM结构
在Embedding layer(嵌入层)中,首先将输入序列中的每个值转换成维度为
的向量,转换结果可以表示为
。接下来,根据输出矩阵
的序列顺序引入位置嵌入,将上述两个矩阵相加得到嵌入层的输出,即
在SA-LSTM编码器中:

在解码器层:由于在预测模型中只期望编码器在最后一个时间步长的输出值进行回归预测,因此需要一个密集的线性连接。
研究实验
为了证明所设计的RUL预测算法的优势,将实验结果与常用的神经网络(包括标准LSTM、门控循环单元(GRU)和Transformer)的结果进行了比较。其中,GRU是一种参数更少、计算成本更低的简化LSTM,Transformer是一种深度学习算法,具有多头自关注编码器和解码器。
基于预测起始周期为81,4个电池HI退化预测结果如图所示,预测结果的定量统计见表。用均方根误差(RMSE)、决定系数(R-square)和RUL预测的AVE对结果进行评价。如图所示,提出的自适应SA-LSTM方法在存在频繁波动和局部再生的情况下,对未来HI值和RUL的预测效果最好。这得益于基于LSTM的预测模型引入了掩码MHA模块和在线自调优机制。它们可以通过以下方式提高预测性能,实验结果表明了该预测方法的有效性和优越性。
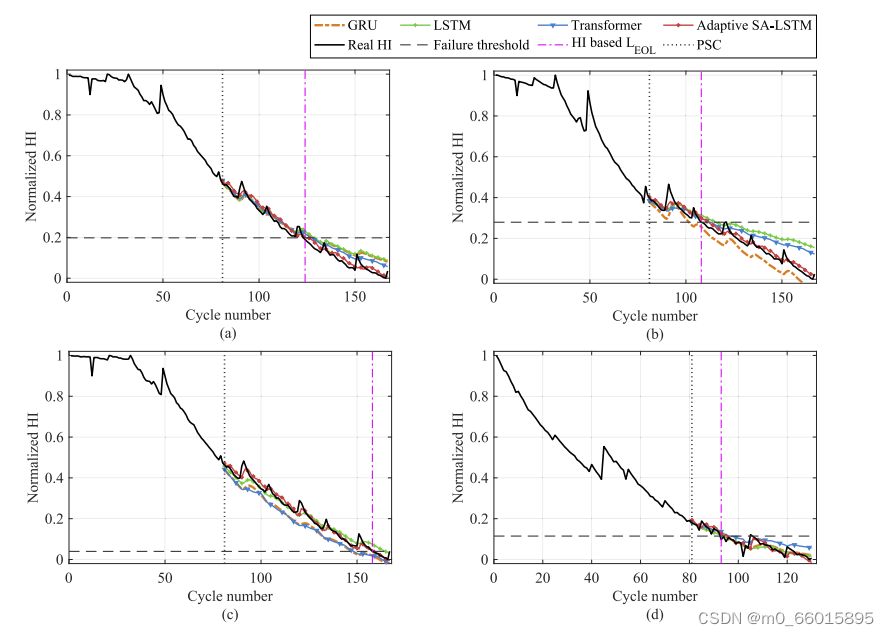
四种预测模型对HI的预测结果
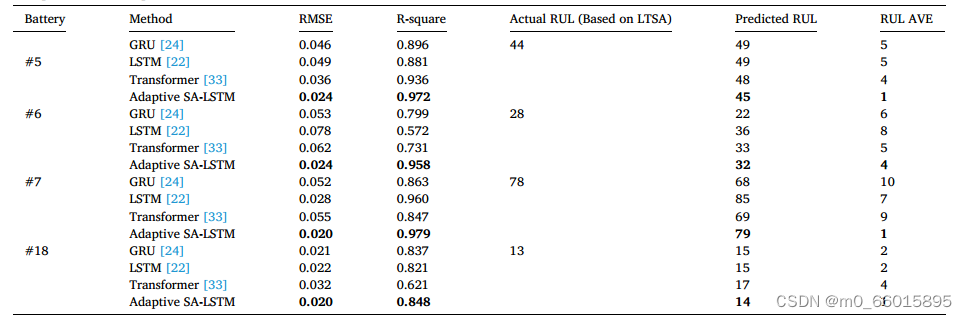
强调重要特征并自适应修正神经网络权值和偏差。对于其他三种神经网络,由于缺乏在线自调整机制,预测误差随着预测周期的增加而逐渐累积。这导致了对局部再生动态的不满意的预测结果和对RUL估计的不利影响。此外,由于缺乏自关注机制,LSTM和GRU在预测过程中不能突出重要的退化信息,因此,预测精度不能令人满意。虽然Transformer包含一个注意模块,但编码器中简单的自注意应该更有效。与上述方法相比,LSTM与自注意相结合可以显著提高HI估计。因此,除了在线自调优机制之外,还可以实现更好的锂离子电池规则预测。
研究贡献
- 开发了一个系统的数据驱动的锂离子电池规则学习预测框架,该框架包括间接HI提取和基于自适应深度学习的预测模型。利用所提出的预测框架,仅使用可测量的电荷数据就可以保证RUL预测的准确性、鲁棒性和可行性。
- 引入参数优化LTSA算法提取间接描述电池退化的间接健康指标(HI)。通过基于蒙特卡罗(Monte Carlo, MC)算法的邻点数量优化,可以使间接HI与标准容量特征之间具有较高的相关性,从而提供更准确的RUL预测。
- 提出了一种新的SA-LSTM网络结构,用于HIs的长期预测。通过将掩蔽多头自注意(MHA)模块与LSTM相结合,预测网络能够成功捕获特征序列中的重要性,保留有利于预测结果的长期特征,同时抑制不太有用的特征。
- 提出了预测模型的在线自调整机制,用于解决HI序列中固有的动态降解特性(即AD和CRP)。自整定机制持续监测HIs和估计精度的变化,然后根据现有的更新规则调整网络参数。以上优点使预测网络能够同时减少长期迭代预测中的累积预测误差和缓解局部波动的影响。
注意力机制
注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
对于一个模型(例如CNN、LSTM)而言,很难决定什么重要什么不重要,因此诞生了注意力机制,帮助模型判断重要信息。在注意力机制中,Q(Query)为查询对象,V(Value)为被查询对象(都是向量)。例如一个人查看一张图片,那么这个人就是查询对象,该图为被查询对象,这个人就会判断图片中哪些信息对他来说重要,哪些信息不重要,即需要计算Q和V之间事物的重要度,重要度的计算,可以近似为计算相似度。注意力机制可分为三阶段,其中
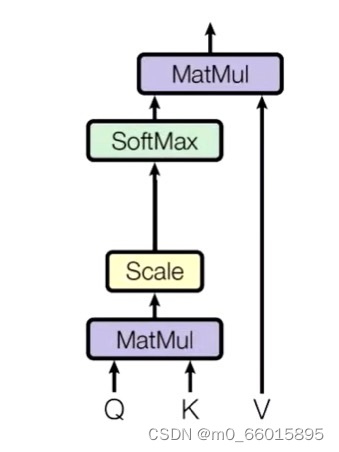
第一阶段:计算K和Q的相似度。一般,在Transform里面可以
,但是K和V之间一定是具有某种联系的,这样的QK点乘才能指导V得到更重要的信息。相似度的计算方式有四种:
- 点乘(即内积)(Transform使用):
,即下图中
- 权重:
- 拼接权重:
- 感知器:
第二阶段:归一化求概率。做一层归一化就可以得到n个概率值,即
,进而就可以找出哪个块对Q而言更重要。
第三阶段:汇总。将V乘上上一阶段得到的概率,即
。当我们利用查询对象Q找出V中的重要信息后,此时Q就失去了使用价值不再需要它了,而这时的
已经不是原始的
,而是在原始的基础上多了一些信息即知道哪些更重要哪些不重要,然后使用
代替V。

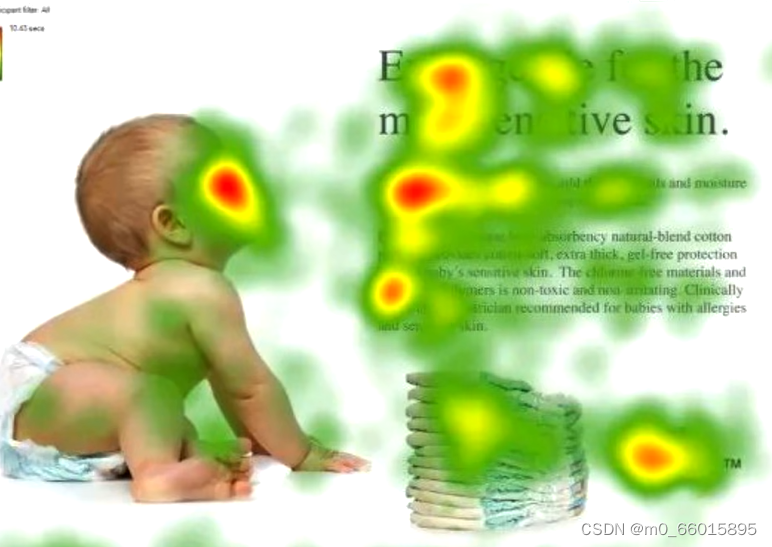
例如对于一张图片,原始图片是没有任何标注的,通过注意力机制我们可以得到如下的图片,图片中多了热点标注,其中红色部分代表关注会聚焦的地方。
在Q和K求相似度之后需要做一个scale(缩放),避免下一步做softmax的时候出现极端情况。
假设两个相似度值:
例如51和49,softmax之后可能得到0.51和0.49
如果是80和20,那么得到的概率可能是0.99999和0.00001,相似度差额越大,得到的概率就越离谱与现实不符,如果进行scale,比如都除以8,即80/8=10和20/8=3,得到的概率可能为0.9和0.1。
新的向量表示了K=V,然后这种表示还暗含了Q的信息(对于Q来说,K里面重要的信息),即挑出了K里面的关键点。 最后得到的注意力值其实是V的另一种形式的表示。
Self-Attention(自注意力机制)
Self-Attention的关键在于不仅仅是,并且这三者来自同一个X,类似于X与X求相似度,通过X求X里面的关键点。
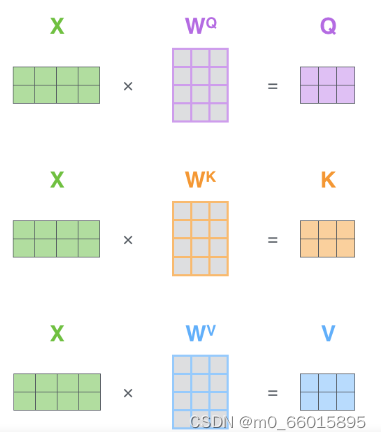
1、Q、K、V的获取,输入单词表示向量,比如可以是词向量,把输入向量映射到q、k、v三个变量,如下图:
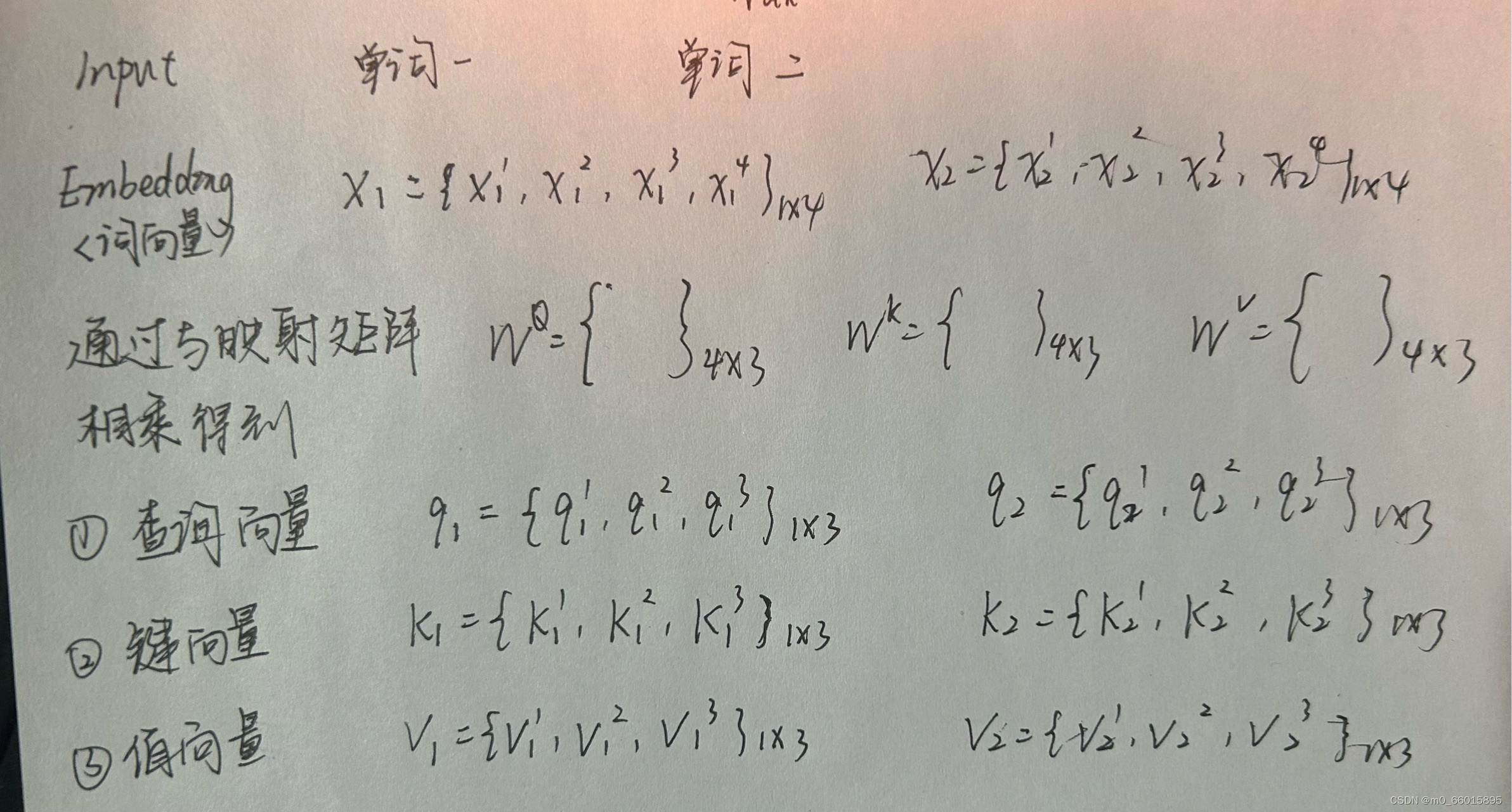
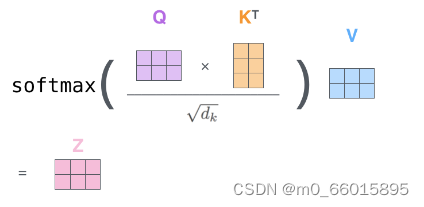
2、计算Attention score,即某个单词的查询向量和各个单词对应的键向量的匹配度,匹配度可以通过加法或点积得到。如下图:
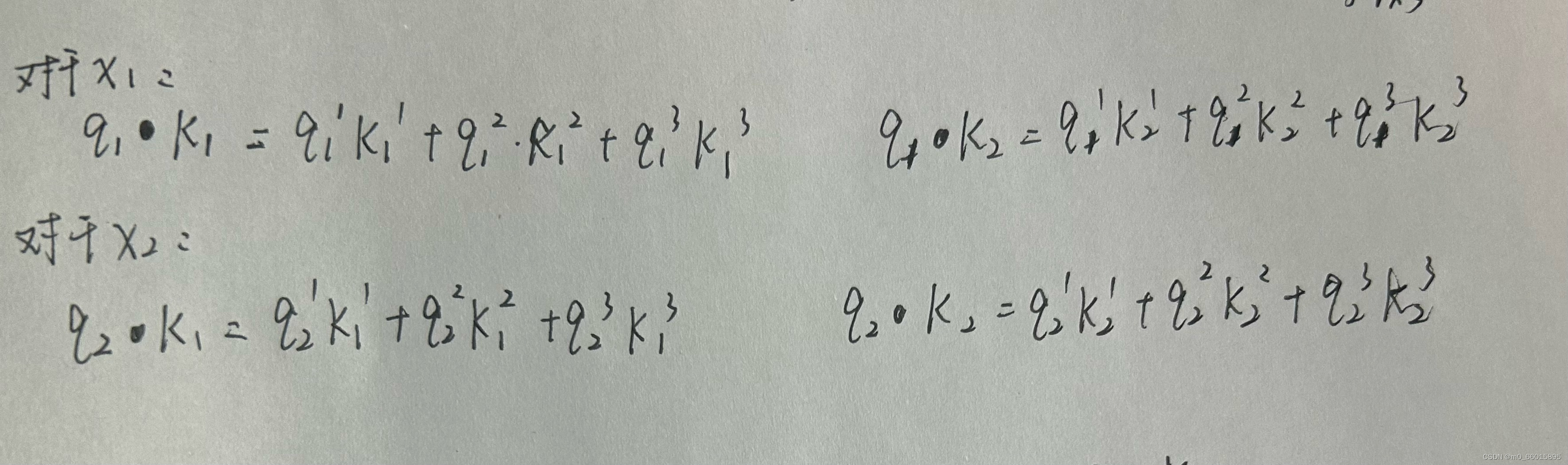
3、通过做scale(除以8)减小score,并通过softmax将score转换为权重。
4、权重乘以v,并求和。最终的结果就是
这个单词的Attention向量,
就是
这个单词的Attention向量。

当同时计算所有单词的Attention时,图示如下:
注意力与自注意力
注意力机制发生在Target的元素和Source中的所有元素之间,简单讲就是说注意力机制中的权重的计算需要Target来参与。即在Encoder-Decoder 模型中,Attention权值的计算不仅需要Encoder中的隐状态而且还需要Decoder中的隐状态。
Self-Attention不是输入语句和输出语句之间的Attention机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的Attention机制。例如在Transformer中在计算权重参数时,将文字向量转成对应的KQV,只需要在Source处进行对应的矩阵操作,用不到Target中的信息。
注意力机制的定义比较广泛,QKV相乘就是注意力,它没有规定QKV怎么来,只规定了QKV怎么做,Q可以是任何一个东西,V也可以是任何一个东西,K往往是等同于V(同源)。而自注意力机制的定义更加狭隘,它属于注意力机制,本质上QKV可以看作是相等的,对于一个词向量,乘上不同的参数矩阵(参数矩阵通过反向传播学出来的),其实做的是空间上的对应,得到的QKV依然代表词向量X。
也就是说,self-attention比attention约束条件多了两个:
1. Q=K=V(同源,即QKV从同一个矩阵获得)
2. Q,K,V需要遵循attention的做法
代码实现attention、self-attention和multi-head attention
1、attention
def attention(query, key, value):
"""
计算Attention的结果。
这里其实传入的是Q,K,V,而Q,K,V的计算是放在模型中的,请参考后续的MultiHeadedAttention类。
这里的Q,K,V有两种Shape,如果是Self-Attention,Shape为(batch, 词数, d_model),
例如(1, 7, 128),即batch_size为1,一句7个单词,每个单词128维
但如果是Multi-Head Attention,则Shape为(batch, head数, 词数,d_model/head数),
例如(1, 8, 7, 16),即Batch_size为1,8个head,一句7个单词,128/8=16。
这样其实也能看出来,所谓的MultiHead其实就是将128拆开了。
在Transformer中,由于使用的是MultiHead Attention,所以Q,K,V的Shape只会是第二种。
"""
# 获取d_model的值。之所以这样可以获取,是因为query和输入的shape相同,
# 若为Self-Attention,则最后一维都是词向量的维度,也就是d_model的值。
# 若为MultiHead Attention,则最后一维是 d_model / h,h为head数
d_k = query.size(-1)
# 执行QK^T / √d_k
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 执行公式中的Softmax
# 这里的p_attn是一个方阵
# 若是Self Attention,则shape为(batch, 词数, 次数),例如(1, 7, 7)
# 若是MultiHead Attention,则shape为(batch, head数, 词数,词数)
p_attn = scores.softmax(dim=-1)
# 最后再乘以 V。
# 对于Self Attention来说,结果Shape为(batch, 词数, d_model),这也就是最终的结果了。
# 但对于MultiHead Attention来说,结果Shape为(batch, head数, 词数,d_model/head数)
# 而这不是最终结果,后续还要将head合并,变为(batch, 词数, d_model)。不过这是MultiHeadAttention
# 该做的事情。
return torch.matmul(p_attn, value)
2、self-attention
class SelfAttention(nn.Module):
def __init__(self, input_vector_dim: int, dim_k=None, dim_v=None):
"""
初始化SelfAttention,包含如下关键参数:
input_vector_dim: 输入向量的维度,对应上述公式中的d,例如你将单词编码为了10维的向量,则该值为10
dim_k: 矩阵W^k和W^q的维度
dim_v: 输出向量的维度,即b的维度,例如如果想让Attention后的输出向量b的维度为15,则定义为15,若不填,默认取取input_vector_dim
"""
super(SelfAttention, self).__init__()
self.input_vector_dim = input_vector_dim
# 如果 dim_k 和 dim_v 为 None,则取输入向量的维度
if dim_k is None:
dim_k = input_vector_dim
if dim_v is None:
dim_v = input_vector_dim
"""
实际写代码时,常用线性层来表示需要训练的矩阵,方便反向传播和参数更新
"""
self.W_q = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_k = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_v = nn.Linear(input_vector_dim, dim_v, bias=False)
# 这个是根号下d_k
self._norm_fact = 1 / np.sqrt(dim_k)
def forward(self, x):
"""
进行前向传播:
x: 输入向量,size为(batch_size, input_num, input_vector_dim)
"""
# 通过W_q, W_k, W_v矩阵计算出,Q,K,V
# Q,K,V矩阵的size为 (batch_size, input_num, output_vector_dim)
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# permute用于变换矩阵的size中对应元素的位置,
# 即,将K的size由(batch_size, input_num, output_vector_dim),变为(batch_size, output_vector_dim,input_num)
# 0,1,2 代表各个元素的下标,即变换前,batch_size所在的位置是0,input_num所在的位置是1
K_T = K.permute(0, 2, 1)
# bmm是batch matrix-matrix product,即对一批矩阵进行矩阵相乘
# bmm详情参见:https://pytorch.org/docs/stable/generated/torch.bmm.html
atten = nn.Softmax(dim=-1)(torch.bmm(Q, K_T)) * self._norm_fact
# 最后再乘以 V
output = torch.bmm(atten, V)
return output3、Multi-Head Attention
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model):
"""
h: head的数量
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
# 定义W^q, W^k, W^v和W^o矩阵。
# 如果你不知道为什么用nn.Linear定义矩阵,可以参考该文章:
# https://blog.csdn.net/zhaohongfei_358/article/details/122797190
self.linears = [
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
]
def forward(self, x):
# 获取Batch Size
nbatches = x.size(0)
"""
1. 求出Q, K, V,这里是求MultiHead的Q,K,V,所以Shape为(batch, head数, 词数,d_model/head数)
1.1 首先,通过定义的W^q,W^k,W^v求出SelfAttention的Q,K,V,此时Q,K,V的Shape为(batch, 词数, d_model)
对应代码为 `linear(x)`
1.2 分成多头,即将Shape由(batch, 词数, d_model)变为(batch, 词数, head数,d_model/head数)。
对应代码为 `view(nbatches, -1, self.h, self.d_k)`
1.3 最终交换“词数”和“head数”这两个维度,将head数放在前面,最终shape变为(batch, head数, 词数,d_model/head数)。
对应代码为 `transpose(1, 2)`
"""
query, key, value = [
linear(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for linear, x in zip(self.linears, (x, x, x))
]
"""
2. 求出Q,K,V后,通过attention函数计算出Attention结果,
这里x的shape为(batch, head数, 词数,d_model/head数)
self.attn的shape为(batch, head数, 词数,词数)
"""
x = attention(
query, key, value
)
"""
3. 将多个head再合并起来,即将x的shape由(batch, head数, 词数,d_model/head数)
再变为 (batch, 词数,d_model)
3.1 首先,交换“head数”和“词数”,这两个维度,结果为(batch, 词数, head数, d_model/head数)
对应代码为:`x.transpose(1, 2).contiguous()`
3.2 然后将“head数”和“d_model/head数”这两个维度合并,结果为(batch, 词数,d_model)
"""
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
# 最终通过W^o矩阵再执行一次线性变换,得到最终结果。
return self.linears[-1](x)