3.关联规则
-
经典案例 : 尿布与啤酒的故事;
基本概念 :
-
设I = {i1,i2,....im}是项(Item)的集合。
-
D 是 事务(transaction)的集合(事务数据库)。
-
事务T是项的集合,且对每个事务具有唯一的标识: 事务号,记作TID;
-
设A是I中的一个项集,如果A属于T,那么事务T包含A;
-
关联规则 : 关联规则是形如A->B的逻辑蕴含式,其中A,B都不为空,且A⸦I, B⸦I,并且A and B= NUll。
支持度 : 描述了A和B这两个物品集在所有的事务中同时出现的概率有多大;
-
规则A->b在数据库D中具有支持度S,及概率P(AB),即S(A->B) = P(AB) = |AB| / |D|;
-
n其中|D|表示数据库D的事物总数,|AB|表示A、B两个项集同时发生的事物个数。
置信度 :
-
置信度就是指在出现了物品集A的事物T中,物品集B也同时出现的概率。
-
规则A->B具有置信度C,表示C是包含A项集的同时也包含B项集的概率,即P(B|A),所以
C(A->B) = P(B|A) = |AB| / |A|
-
其中|A|表示数据库中包含项集A的事务个数。
规则的支持度和置信度是规则兴趣度的两种度量。支持度是对关联规则重要性的衡量,置信度是对关联规则的准确度的衡量,支持度说明了这条规则在所有事务中有多大代表性。
显然支持度越大,关联规则越重要。有些关联规则置信度虽然很高,但支持度却很低,说明该关联规则实用的机会很小,因此也不重要。
-
强关联规则 :
D 在 I 上满足最小支持度和最小可信度的关联规则称为强关联规则。
-
提升度Lift
提升度表示A项集的出现,对B项集的出现有多大影响。
I(A->B) = P(AB) / P(A)P(B);
公式反映了项集A和项集B的相关程度。
n若I(A->B)=1 即P(AB)=P(A)P(B),说明项集A和项集B是相互独立的。
n若I(A->B)<1 说明项集A和项集B是负相关的。
n若I(A->B)>1 说明项集A和项集B是正相关的。
关联规则挖掘
概念 : 关联规则挖掘问题就是根据用户指定的最小支持度和最小置信度来寻找强关联规则。
频繁项集 : 满足最小支持度的项集称为频繁项集。频繁k-项集的集合通常记作Lk。
-
关联规则挖掘问题可以划分成两个子问题:
-
发现频繁项目集:通过用户给定最小支持度,寻找所有频繁项目集或者最大频繁项目集。
-
生成关联规则:通过用户给定最小可信度,在频繁项目集中,寻找关联规则。
-
Aprori算法
-
项目集格空间理论 :
定理:设X , Y是数据集D中的项集:
(1)若X⊆Y,则 Support(X) >= Support(Y)。
(2)若X⊆Y,如果X是非频繁项集,则Y也是非频繁项集。
(3)若X⊆Y,如果Y是频繁项集,则X也是频繁项集。
性质:
1.任何频繁项集的子集都是频繁项集。
2.任何非频繁项集的超集都为非频繁项集。
3.任何频繁k项集都是由频繁k−1项集组合生成的
4.频繁k项集的所有k−1项子集一定都是频繁k−1项集
-
频繁闭项集 :
所谓闭项集,就是指一个项集X,它的直接超集的支持度计数都不等于它本身的支持度计数。如果闭项集同时是频繁的,也就是它的支持度大于等于最小支持度阈值,那它就称为频繁闭项集。
Apriori算法 : 只适用于稀疏的数据集;
频繁项集 : 只由最小支持度决定;
步骤 :
1.产生频繁项集
特点 :
-
逐层进行 :
-
它使用产生和测试策略发现频繁相机,每次迭代后的候选项集都由上一次迭代发生的频繁项集产生;
降低时间复杂度 :
-
减少候选项集的数目 : 利用先验性质原理
-
减少比较次数 : 利用更高级的数据结构
定理 :
-
先验性质 : 频繁项集的所有非空子集一定是频繁的;
-
反单调性 : 如果项集I是非频繁的,加上新项集A后,这个新的项集{IUA}一定是非频繁的,
2.由频繁项集产生关联规则
由频繁项集产生关联规则 --> 找出所有频繁项集中满足置信度的所有可能;
4.聚类分析
机器学习 :
机器学习根据学习的方式可以分为有监督学习和无监督学习
1)有监督学习(supervised learning) 从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标,训练集中的目标是由人标注的。有监督学习就是最常见的分类问题。
2)无监督学习(unsupervised learning) 输入的数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行聚类,试图使类内差距最小化,类间差距最大化。无监督学习就是最常见的聚类问题。
概念 :
-
聚类 : 数据对象的集合;
-
聚类是一种无指导的学习 : 没有预定义的类编号;
-
聚类的准则 : 使属于同一类的个体之间的距离尽可能小,使得不同类之间的个体间距离尽可能大;
-
常用的聚类分析算法 :
-
基于划分的聚类算法 : k-means , k-medoids算法;
-
基于的层次聚类算法
缺点 : 只能发现球状的簇,难以发现任意形状的簇;
-
BIRCH(利用层次方法的平衡迭代规约和聚类)
-
AGNES(凝聚式层次聚类)
-
DLANA(分裂式层次聚类)
-
-
基于的密度聚类算法 : 只要临近区域的密度(对象或数据点的数目)超过某个临界值,就继续聚类。
优点 : 可以过滤掉噪声和离群点,发现任意形状的簇;
常见算法 :
-
DBSCAN(具有噪声的基于密度的聚类方法)
-
OPTICS(通过点排序识别聚类结构)
-
-
基于的概率聚类算法
-
基于的网络和图聚类算法
-
层次聚类算法
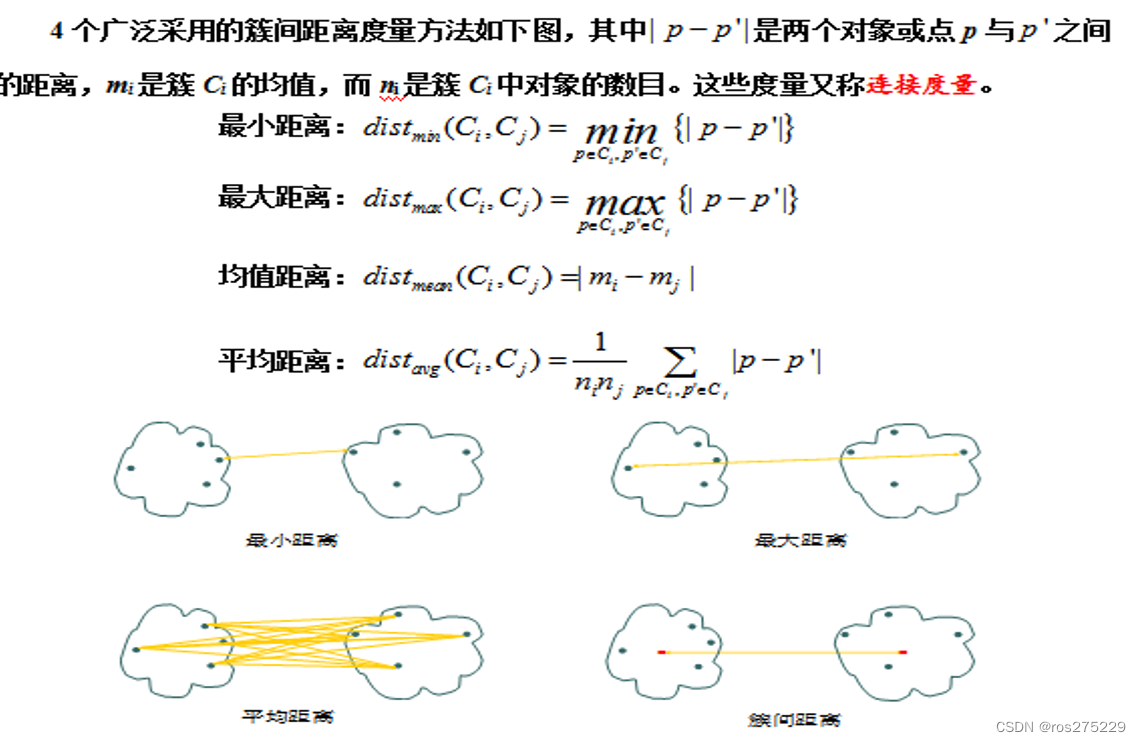
层次方法创建给定数据对象集的层次分解。根据层次分解如何形成,层次方法可以分为凝聚的或分裂的方法。
无论是使用凝聚方法还是分裂方法,一个核心的问题就是度量两个簇之间的距离 ,其中每个簇一般是一个对象集;
一些常见的距离计算 :
基于划分的聚类方法 :
划分方法是将数据对象划分成不重叠的子集(簇),使得每个数据对象恰在一个子集中。给定一个n个对象集合,划分方法构建数据的k个分区,其中每个分区表示一个簇,并且k≤n。也就是说,把数据划分为k个组,使得每个组至少包含一个对象。也就是说划分方法在数据集上进行
k-means算法
特点 : 对初始的聚类中心比较敏感,相似度计算方式会影响聚类的划分;
常见的相似度计算方法 :
-
欧式距离(Euclidean Distance)
-
余弦相似度(Cosine)
-
皮尔逊相关系数(Pearson)
-
修正余弦相似度(Adjusted Cosine)
-
汉明距离(Hamming Distance)
-
曼哈顿距离(Manhattan Distance)
输入:簇的数目k和包含n个对象的数据库D
输出:k个簇,使平方误差准则最小。
算法步骤:
1.为每个聚类确定一个初始聚类中心,这样就有K 个初始聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类。
3.使用每个聚类中的样本均值作为新的聚类中心。
4.重复步骤2,3直到聚类中心不再变化。
5.结束,得到K个聚类。
5.分类算法
概念
分类的目的是得到一个分类器(也称为分类模型),通过得到的分类器能够将测试集中的测试数据映射到给定分类中的每个类别;
-
分类器 : 分类的关键是找到一个合适的分类器,也就是分类函数或者分类模型。分类的过程是依据已知的样本数据构造一个分类函数或者分类模型,该分类函数或分类模型能够把数据库中的数据对象映射到某个给定的模型中,从而确定数据对象的类别;
-
训练集 : 分类的样本数据,是构造分类器的基础,训练集中的数据对象的所属类别已知;
过程
分类算法的过程 :
-
建立模型 :
通过分析训练集中的数据,为类标号属性建立反映其特征的分类模型。训练集是已知类别的数据,因此该步骤也称为有监督的学习(从例子中学习);
-
使用模型对数据进行分类
评估模型为可接受的之后,通过模型来预测未知类别的对象所属类别;
常用的分类算法有 :
-
单一的分类算法包括 :
决策树 , 贝叶斯 , 人工神经网络,KNN , SVM等;
-
用于组合单一分类的集成学习算法 :
如Bagging 和 Boosting , adaboost等;
KNN
KNN的全称就是K Nearest Neighbors,意思是K个最近的邻居;
概念 :
根据距离函数计算待分类样本X和每个训练样本的距离(作为相似度),选择与待分类样本距离最小的K个样本作为X的K个最邻近,最后以X的K个最邻近中的大多数所属的类别作为X的类别。
KNN是一种直接的来分类未知数据的方法。
KNN算法的计算步骤 :
-
计算距离 : 计算测试对象与每个训练样本直接的距离;
-
寻找邻居 : 圈定距离最近的k个训练样本,作为测试的对象;
-
进行分类 : 根据这k个近邻归属的主要类别,对测试对象进行分类;
K值的选取 :
从小的开始,不断增加K的值, 然后计算验证集合的方差,最终找到一个比较适合的K值;

当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。
简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑出离这个数据最近的K个点,看看这K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
KNN的优点 :
(1)简单,易于理解,易于实现,无需估计参数,无需训练;
(2)适合对稀有事件进行分类;
(3)特别适合于多分类问题。
缺点 :
-
分类速度慢
-
各属性的权重相同,影响了准确率
-
样本库容量依赖性较强
-
K值不好确定;
Bayes算法
Bayes是一个基于概率统计的分类预测算法,在先验概率和类条件概率已知的情况下,计算给定样本属于特定类的概率;
计算公式 : P(A|B)=P(AB)/P(B)


决策树算法
决策树分类算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据进行归纳分类;
熵
任何系统存在一个状态函数,把它定义为熵。泛指某些物质系统状态的一种度量。熵越大,表示系统越混乱。
信息熵被认为是系统有序化程度的一个度量,信息熵的计算公式为 :

其中,S为训练集,类标号属性有n个不同的取值,将S划分为子集{S1 , S2 , S3 , S4,....,Sn},则Pi表示子集Si在说有样本中出现的概率。
划分信息熵 :
假设用属性A来划分S中的数据,计算属性A对集合S的划分信息熵entropy(A),属性的划分信息熵的计算公式 :

分裂信息熵

过拟合
为了得到一致假设而使假设变得过度复杂称为过拟合。想像某种学习算法产生了一个过拟合的分类器,这个分类器能够百分之百的正确分类样本数据(即再拿样本中的文档来给它,它绝对不会分错),但也就为了能够对样本完全正确的分类,使得它的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档,它全都认为不属于这个类别。
ID3算法

复习分析综合
极大极小规范化
消除量纲的影响;
方法 :
v′= ( v−min / max−min ) * (new_max−new_min) + new_min
最大最小规范化的方法 1、 将属性的值映射到0至1的范围内 2、将属性的值映射到0至100的范围内 3、将属性的值映射到60至100的范围内
将属性的值映射到0至1的范围内 假设属性收入的最大最小值分别是11000元和91000元,利用最大最小规范化的方法将属性的值映射到0至1的范围内,对属性收入的52000元将被转化为: A、52000/(91000-11000)=0.65 B、(52000-11000)/(91000-11000)=0.5121 C、(91000-11000)/91000=0.8791 D、(91000-52000)/(91000-11000)=0.4875 答案:B
将属性的值映射到0至100的范围内 乘以100
将属性的值映射到60至100的范围内 乘以40,加上60
常见·的·相似度计算方法 :
-
欧式距离(Euclidean Distance)
-
余弦相似度(Cosine)
-
皮尔逊相关系数(Pearson)
-
修正余弦相似度(Adjusted Cosine)
-
汉明距离(Hamming Distance)
-
曼哈顿距离(Manhattan Distance)
1.欧氏距离 :
欧式距离全称是欧几里距离,是最易于理解的一种距离计算方式,源自欧式空间中两点间的距离公式。

-
多维 :
n样本xi和xj之间的相似度通常用它们之间的距离d(xi,xj)来表示,距离越小,样本xi和xj越相似,差异度越小;距离越大,样本xi和xj越不相似,差异度越大。欧式距离公式如下:

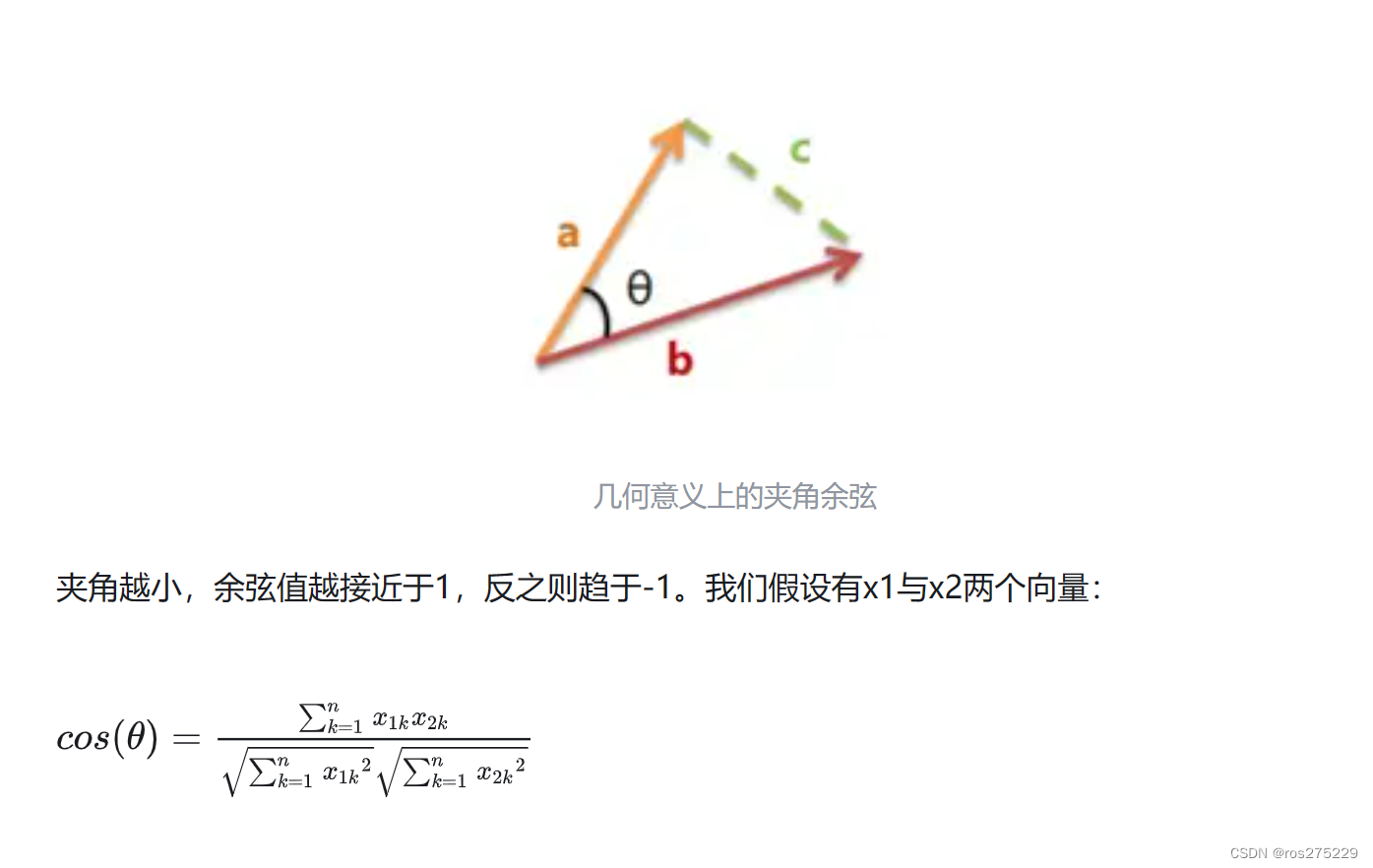
2.余弦相似度
首先,样本数据的夹角余弦并不是真正几何意义上的夹角余弦,只不过是借了它的名字,实际是借用了它的概念变成了是代数意义上的“夹角余弦”,用来衡量样本向量间的差异。
3.皮尔逊相关系数
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。从知友的回答可以明白,皮尔逊相关函数是余弦相似度在维度缺失上面的一种改进方法。
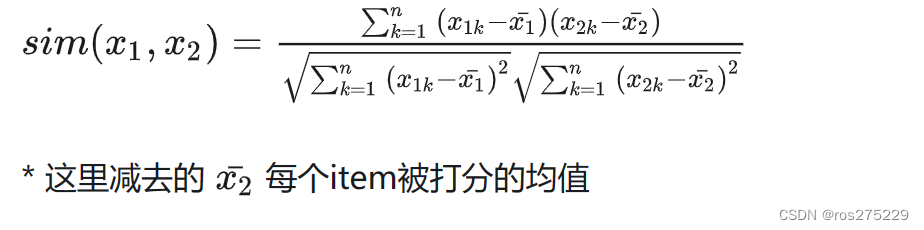
4.汉明距离
汉明距离表示的是两个字符串(相同长度)对应位不同的数量。比如有两个等长的字符串 str1 = "11111" 和 str2 = "10001" 那么它们之间的汉明距离就是3(这样说就简单多了吧。哈哈)。汉明距离多用于图像像素的匹配(同图搜索)。
5.曼哈顿距离
曼哈顿距离是最简单的距离计算方法 ,就是算不同维度下差的绝对值之和:
d = |x1-x2| + |y1 - y2|


![[机器人-3]:开源MIT Min cheetah机械狗设计(三):嵌入式硬件设计](https://img-blog.csdnimg.cn/img_convert/1d14f7d5981ce07a7f3fcd1811fc45e8.webp?x-oss-process=image/format,png)