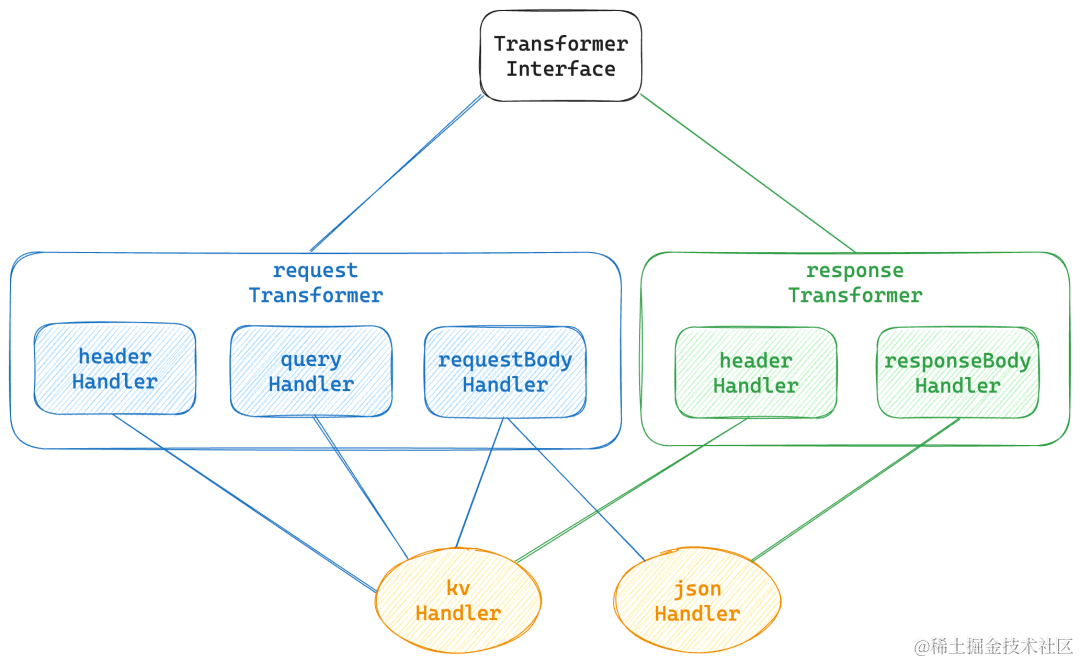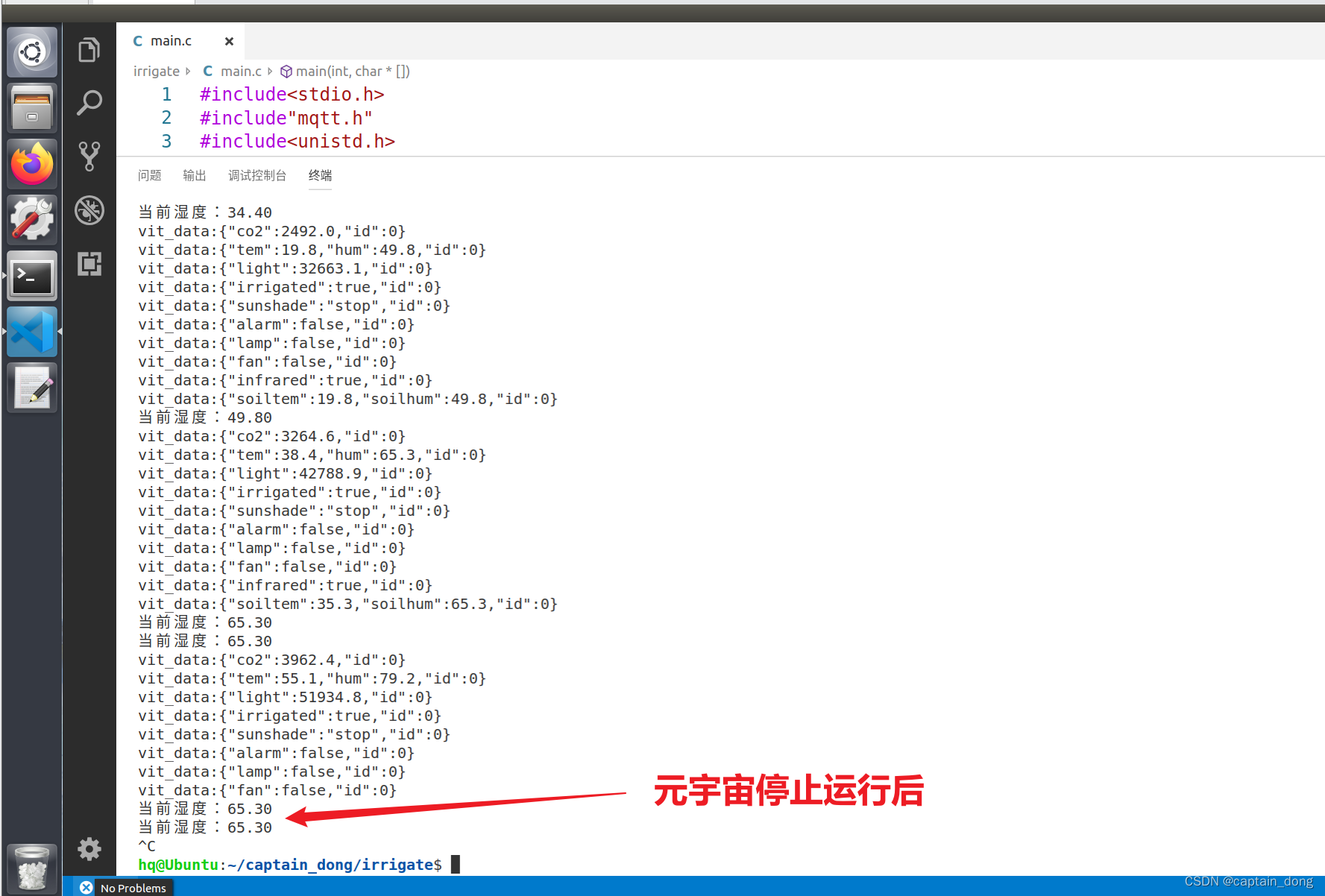
在我之前写的<<使用langchain与你自己的数据对话>>系列博客中,我们介绍了利用大型语言模型LLM来检索文档时的过程和步骤,如下图所示:
我们在检索文档之前,通常需要对文档进行切割,然后将其存入向量数据库如下图所示:

当我们在使用langchain框架做文档切割时传统的做法是使用像CharacterTextSplitter, RecursiveCharacterTextSplitter这样的文档分割器将文档按指定的块大小(chunk_size)来均匀的切割文档,然后将每个文档块做向量化处理(Embedding)后将其保存到向量数据库中,而当我们在做文档检索时,会将用户的问题转换成的向量与向量数据库中的文档块的向量做相似度计算,并从中获取k个与用户问题向量相似度最高的文档块(也就是和用户问题相关的文档块),然后我们会把用户的问题以及相关的文档块一起发送给llm, 最后LLM会给出一个对用户友好的回复。这就是一般的传统文档检索的方法。
传统检索方法其实存在一定的局限性,这是因为文档块的大小会影响和用户问题的匹配度,也就是说当我们切割的文档块越大时,它与用户问题的匹配度就会越低,当文档块越小时,它与用户问题的匹配度会越高,这是因为较大的文档块可能会包含较多的内容,当它被转换成一个固定维度的向量时,该向量可能不能够准确反应出该文档块中的所有内容,因而对用户问题的匹配度就会降低,而小的文档块包含的内容较少,当它被转换成一个固定维度的向量时,该向量基本能够准确反应出该文档块中的内容,因此它与用户问题的匹配度会教高,但是较小的文档块可能因为所包含的信息量较少,因而它可能不是一个全面且正确的答案。为了解决这些问题我们今天来介绍Langchain中的父文档检索器,它能够有效的解决文档块大小与用户问题匹配的问题。
由于我们在利用大模型进行文档检索的时候,常常会有相互矛盾的需求,比如:
- 你可能希望得到较小的文档块,以便它们Embedding以后能够最准确地反映出文档的含义,如果文档块太大,Embedding就失去了意义。
- 你可能希望得到较大的文档块以保留教多的内容,然后将它们发送给LLM以便得到全面且正确的答案。
面对这样矛盾的需求,Langchain的父文档检索器为我们提供了两种有效的解决方案:检索完整文档、检索较大的文档块。在开始下面的实验之前我们需要先做一些环境配置的准备工作:
一、环境配置
接下来我们需要安装如下python包:
pip install langchain二、检索完整文档
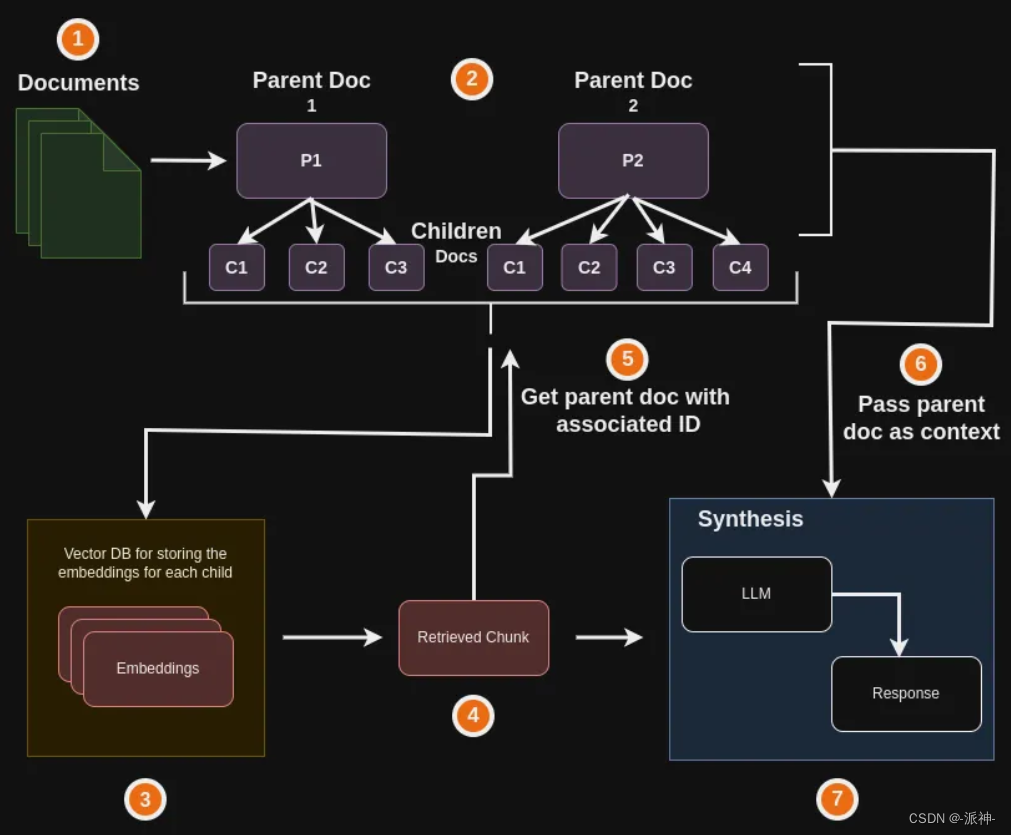
所谓检索完整文档是指将原始文档均匀的切割成若干个较小的文档块,然后将它们与用户的问题进行匹配,最后将匹配到的文档块所在原始文档和用户问题一起发送给llm后由llm生成最终答案,如下图所示:

接下来我们来测试一下检索完整文档的方法,首先准备两个较小的文档(txt文件),然后对文档进行切割:
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.document_loaders import TextLoader
#创建BAAI的embedding
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
#创建loaders
loaders = [
TextLoader("./docs/台积电2nm没对手.txt",encoding='utf8'),
TextLoader("./docs/小米汽车SU7.txt",encoding='utf8'),
]
docs = []
for loader in loaders:
docs.extend(loader.load())这里我们使用的是BAAI的embedding,关于为什么要使用BAAI的embedding请参考我上一篇博客:高级RGA(一):Embedding模型的选择 ,除此之外我们加载了文档均为txt文件,接下来我们查看一下docs里面的文档数量以及文档的内容:
len(docs)![]()
print(docs[0].page_content)
print(docs[1].page_content)
这里我们看到文档集docs里存放的是2个文档,并且这两个文档的内容都比较短。接下来我们来创建父文档检索器:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# 创建文档分割器,设置块大小为200
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)
# 创建向量数据库对象
vectorstore = Chroma(
collection_name="full_documents", embedding_function=bge_embeddings
)
# 创建内存存储对象
store = InMemoryStore()
#创建父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
#添加文档集
retriever.add_documents(docs, ids=None)这里我们首先创建了一个子文档分割器child_splitter,它用来对每个原始文档进行切割,并且设置为块大小chunk_size为200,即按200个字符大小来切割文档,然后我们又创建了向量数据库对象vectorstore,和内存存储对象store, store用来存储每个被切割的小文档块所属的原始文档及其索引Id,这样就可以通过子文档块来找到它所属的原始文档。接下来我们又创建了一个父文档检索器retriever,它包含了如下三个参数:
- vectorstore:指定所使用的向量数据库
- docstore: 原始文档存储器
- child_splitter:子文档分割器
最后执行了retriever.add_documents完成添加原始文档的工作,一旦完成添加原始文档的工作以后,所有的原始文档就会被child_splitter切割成一个个小的文档块,并且为小文档块与原始文档建立了索引关系,即通过小文档块的Id便能找到其对于的原始文档。下面我们查看一下store中存储的原始文档的Id:
list(store.yield_keys())
这里我们看到store中存储的两个原始文档的Id, 下面我们来搜索与用户问题相似度较高的子文档块:
sub_docs = vectorstore.similarity_search("小米SU7有几个版本?")
print(sub_docs[0].page_content)
这里我们通过向量数据库的similarity_search方法搜索出来的是与用户问题相关的子文档块的内容。下面我们使用检索器的get_relevant_documents的方法来对这个问题进行检索:
retrieved_docs = retriever.get_relevant_documents("小米SU7有几个版本?")
print(retrieved_docs[0].page_content)
这里我们通过检索器检索出来的是原始文档的内容,也就是说检索器每次检索时都会返回与问题相关的那个原始文档的全部内容,由此我们可以推断出检索器在执行检索任务时首先将用户问题的向量与向量数据库中的子文档块向量进行相似度的计算,在找到与用户问题最相似的子文档块以后,返回该子文档块所属的原始文档的全部内容。下面我们再测试一些问题:
sub_docs = vectorstore.similarity_search("台积电总裁是谁?")
print(sub_docs[0].page_content)
retrieved_docs = retriever.get_relevant_documents("台积电总裁是谁?")
print(retrieved_docs[0].page_content) 
接下来我们来实现文档检索最后的步骤,即让llm根据检索出来的相关文档来回答用户问题,这里我们还是借助LangChain的表达式语言(LCEL)来创建chain, 如果对LCEL不熟悉的朋友可以查看我之前写的这篇博客:LangChain的表达式语言(LCEL):
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langchain.schema.output_parser import StrOutputParser
from langchain.chat_models import ChatOpenAI
# from langchain_google_genai import ChatGoogleGenerativeAI
#创建gemini model
# model = ChatGoogleGenerativeAI(model="gemini-pro")
#创建openai model
model = ChatOpenAI()
#创建prompt模板
template = """请根据下面给出的上下文来回答问题:
{context}
问题: {question}
"""
#由模板生成prompt
prompt = ChatPromptTemplate.from_template(template)
#创建chain
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | StrOutputParser()这里我们可以选择openai的chatgpt, 或者时谷歌的gemini-pro作为我们的model, 我这里选择了openai的chatgpt,因为我测试下来发现langchain的ChatGoogleGenerativeAI这个包似乎存在一些bug,所以我还是选择了ChatGpt作为我的model,下面我们来测试一下实际检索的效果:
response = chain.invoke({"question": "台积电总裁是谁?"})
print(response)![]()
response = chain.invoke({"question": "台积电的2nm和Intel 18A哪个更先进?"})
print(response)![]()
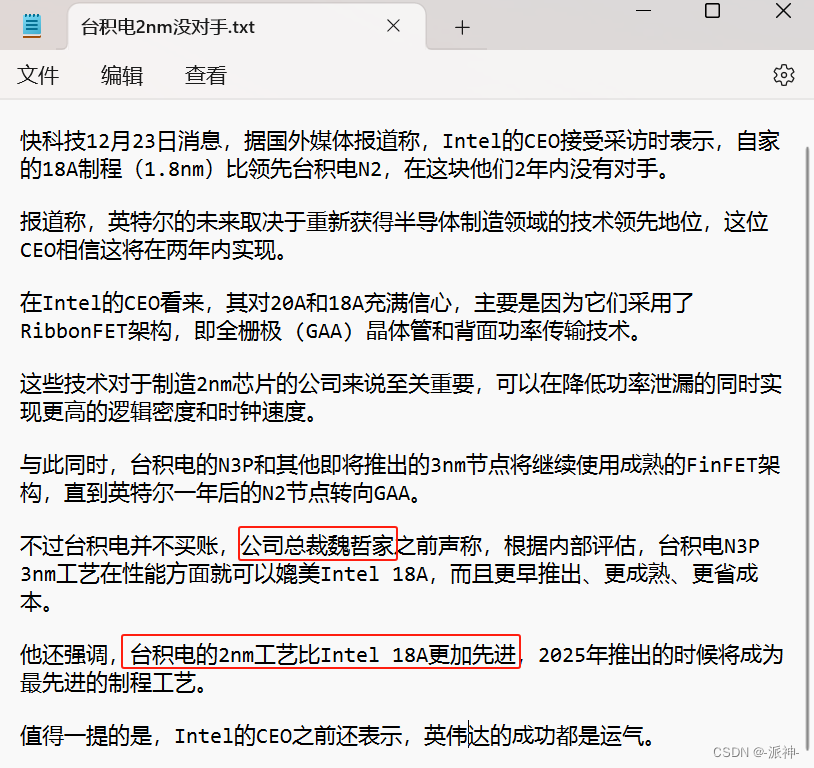
这里我们发现llm返回的结果都是从原始文档中提炼而成的,如下图所示:
response = chain.invoke({"question": "小米SU7有几个版本?"})
print(response)![]()
response = chain.invoke({"question": "华为问界M9什么时候上市?"})
print(response)![]()
三、检索较大的文档块
前面我们介绍了“检索完整文档”,这里的 检索完整文档 指的是每次检索的时候都会将某个原始文档的全部内容发送给LLM, 这样对于小文档问题不大,但是对于大文档(如几十页的pdf文档)就不可行了,因为一般的大模型llm对用户的输入语句的长度或者说叫token数是有限制的,如果文档过大极有可能在调用llm时产生异常报错,为此Langchain还提供了另外一种父文档分割的方法叫:检索较大的文档块。如下图所示:
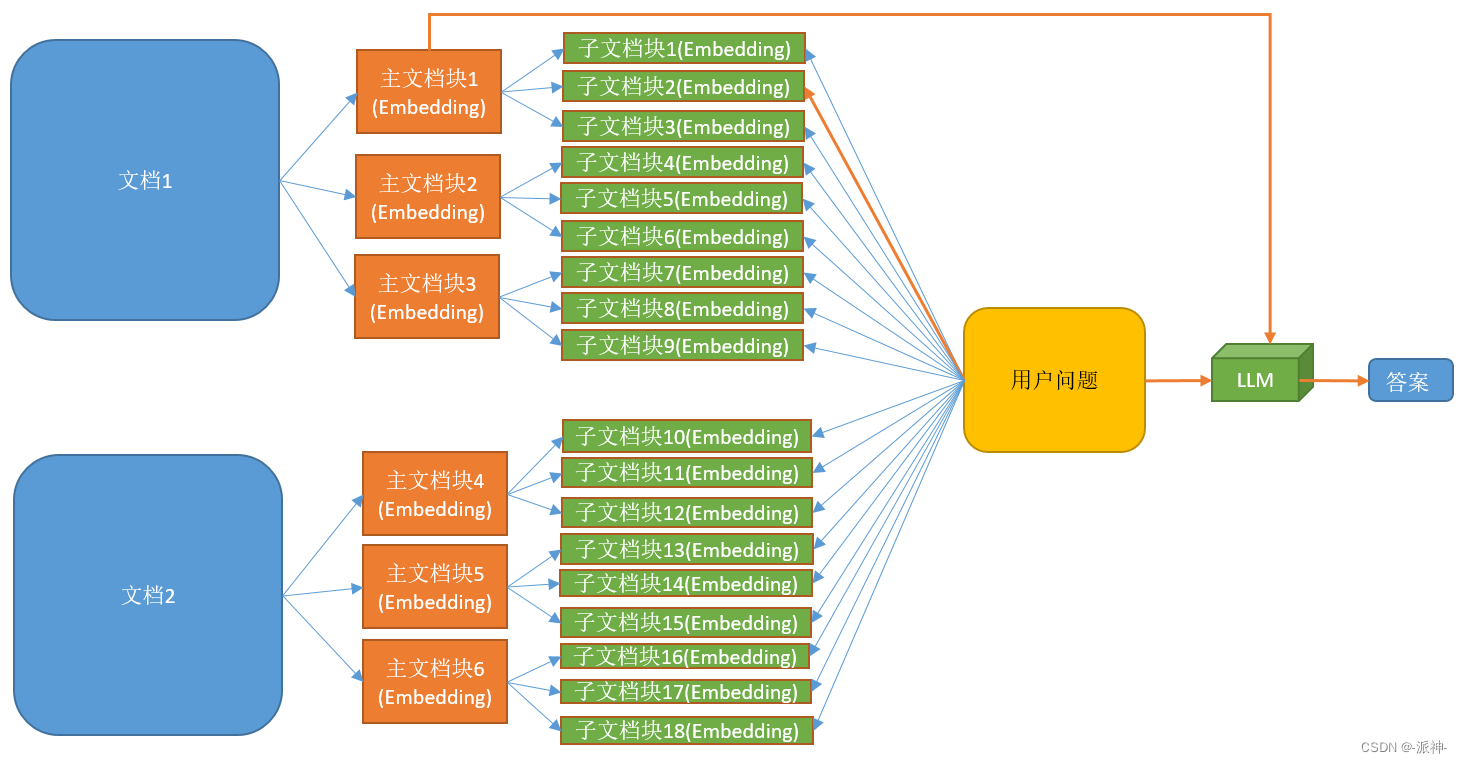
当我们的原始文档比较大时,我们需要将原始文档按照两个层级进行切割,即切割成主文档块和子文档块,而用户的问题会与所有的子文档块进行匹配(相似度比较) ,当匹配到特定的子文档块后,将该子文档块所属的主文档块的全部内容以及用户问题发送给llm,最后由llm来生成答案。下面我们从百度百科上来抓取两篇文章作为我们的文档素材:
from langchain.document_loaders import WebBaseLoader
urls = [
"https://baike.baidu.com/item/ChatGPT/62446358",
"https://baike.baidu.com/item/恐龙/139019"
]
loader = WebBaseLoader(urls)
docs = loader.load()这里我们从百度百科上抓取了两篇科技文章,一篇关于ChatGPT,一篇关于恐龙,大家可以从上面的代码中获取文章的链接,另外langchain的WebBaseLoader其实就是一个爬虫工具,它可以爬取网页的内容。下面我们查看一下这两篇文章的长度:
len(docs[0].page_content)![]()
len(docs[1].page_content)![]()
这里我们看到这两篇文章的长度都比较大,第一篇有10594个字,第二片有23249个字,这么长的文章将无法使用之前介绍的“检索完整文档”的方式来检索文档。我们需要将这两篇文章按照两个层级来进行文档分割:
#创建主文档分割器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
#创建子文档分割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 创建向量数据库对象
vectorstore = Chroma(
collection_name="split_parents", embedding_function = bge_embeddings
)
# 创建内存存储对象
store = InMemoryStore()
#创建父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
search_kwargs={"k": 1}
)
#添加文档集
retriever.add_documents(docs)这里我们创建了两个文档分割器即主文档分割器parent_splitter,和子文档分割器child_splitter ,parent_splitter设置的块大小为1000,child_splitter设置的块大小为400,也就是说在一个块大小为1000的主文档块中内再次进行切割且切割出来的子文档块的大小为400,下面我们看一下切割出来的主文档块的数量:
len(list(store.yield_keys()))![]()
这里我们看到被切割出来的主文档块有43个。 下面我们来搜索与用户问题相似度较高的子文档块:
sub_docs = vectorstore.similarity_search("恐龙是冷血动物吗?")
print(sub_docs[0].page_content)
这里我们通过向量数据库的similarity_search方法搜索出来的是与用户问题相关的子文档块的内容,下面我们使用检索器的get_relevant_documents的方法来对这个问题进行检索,它会返回该子文档块所属的主文档块的全部内容:
retrieved_docs = retriever.get_relevant_documents("恐龙是冷血动物吗?")
print(retrieved_docs[0].page_content)
这里由于我们主文档块的大小设置为1000,而子文档块的大小设置为400,所以一个主文档块最多包含2个子文档块,上图红线处开始就是通过vectorstore.similarity_search方法检索到的子文档块的内容。接下来我们来实现文档检索最后的步骤,即让llm根据检索出来的相关文档来回答用户问题:
#创建openai model
model = ChatOpenAI()
#创建prompt模板
template = """请根据下面给出的上下文来回答问题:
{context}
问题: {question}
"""
#由模板生成prompt
prompt = ChatPromptTemplate.from_template(template)
#创建chain
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | StrOutputParser()下面我们来测试一下llm对实际问题的回答:
response = chain.invoke({"question": "恐龙是冷血动物吗?"})
print(response)
关于恐龙是否是冷血动物的网页原文如下:

response = chain.invoke({"question": "诽谤诉讼是怎么回事?"})
print(response)
关于诽谤诉讼的网页原文如下:

四、总结
今天我们学习了langchain的父文档检索器,父文档检索器有两种工作方式即检索完整文档,和检索较大的文档块,其中检索完整文档的前提条件是原始文档的大小不能超过大模型llm对输入文本长度的限制条件,因此我们的原始文档不能太长。但是对于“检索较大的文档块”则没有这个限制,它会将原始文档按照主文档块和子文档块两个层级进行切割,所以不受文档长度的限制条件,我在实际测试中发现有时候无法检索到相关内容时,这可以通过调节主文档块,和子文档块的大小即chunk_size的大小可以获得,当检索不到相关内容时,我们可以减小子文档块的chunk_size,而llm回答不够全面时我们可以增大主文档块的chunk_size,通过这样的调节可以获得满意的检索结果。