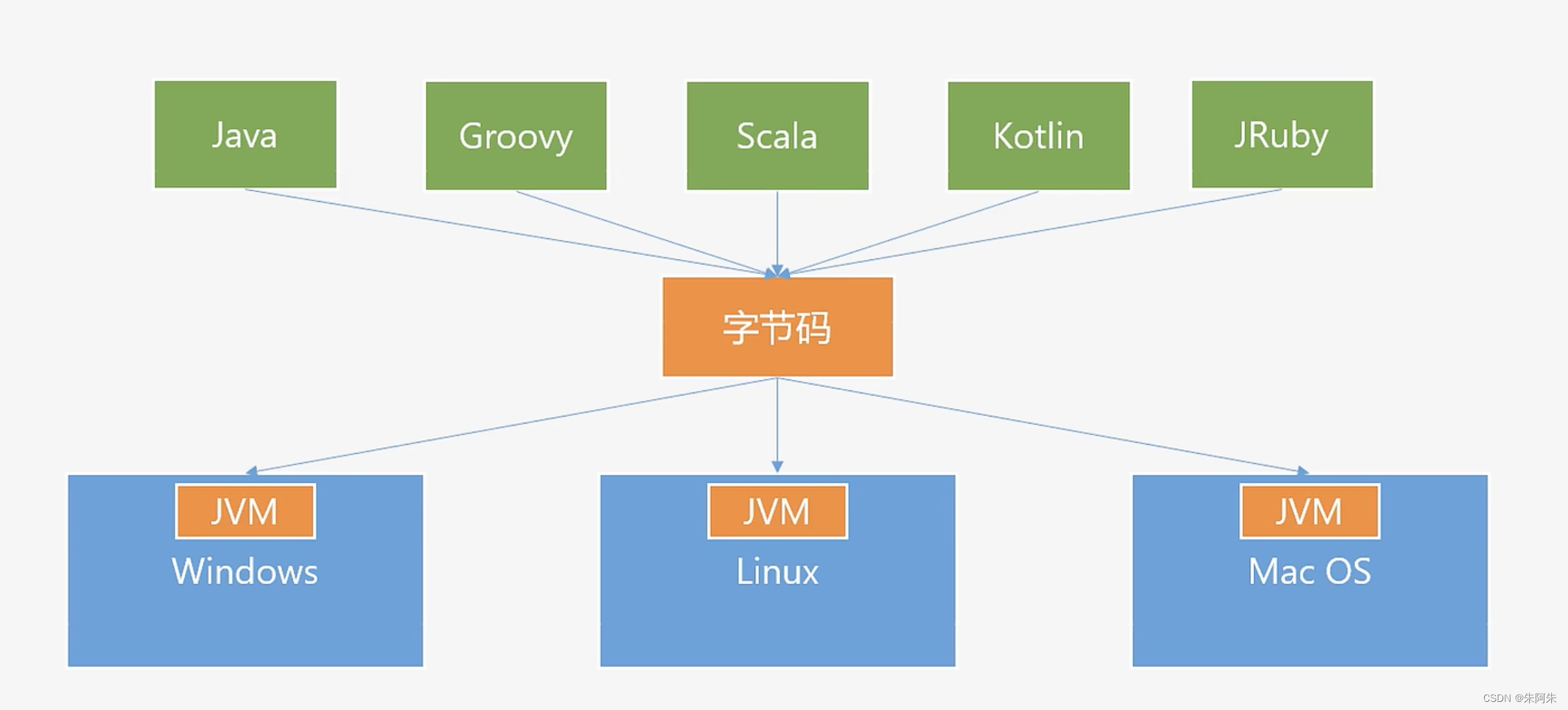
jvm与字节码
jvm只需关注字节码文件
jvm由哪些部分构成
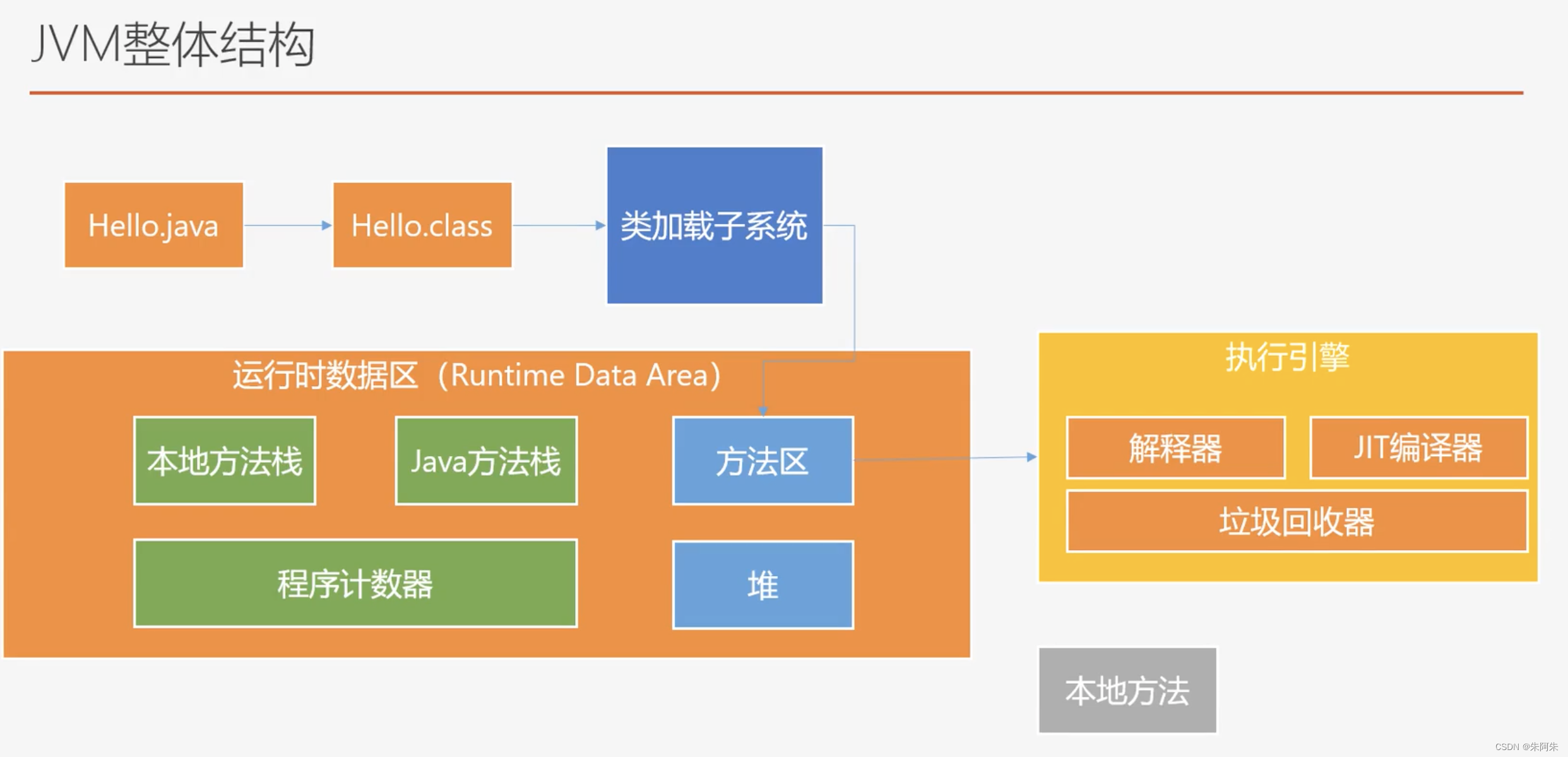
1.类加载子系统,将磁盘中的字节码文件加载到方法区的内存空间中
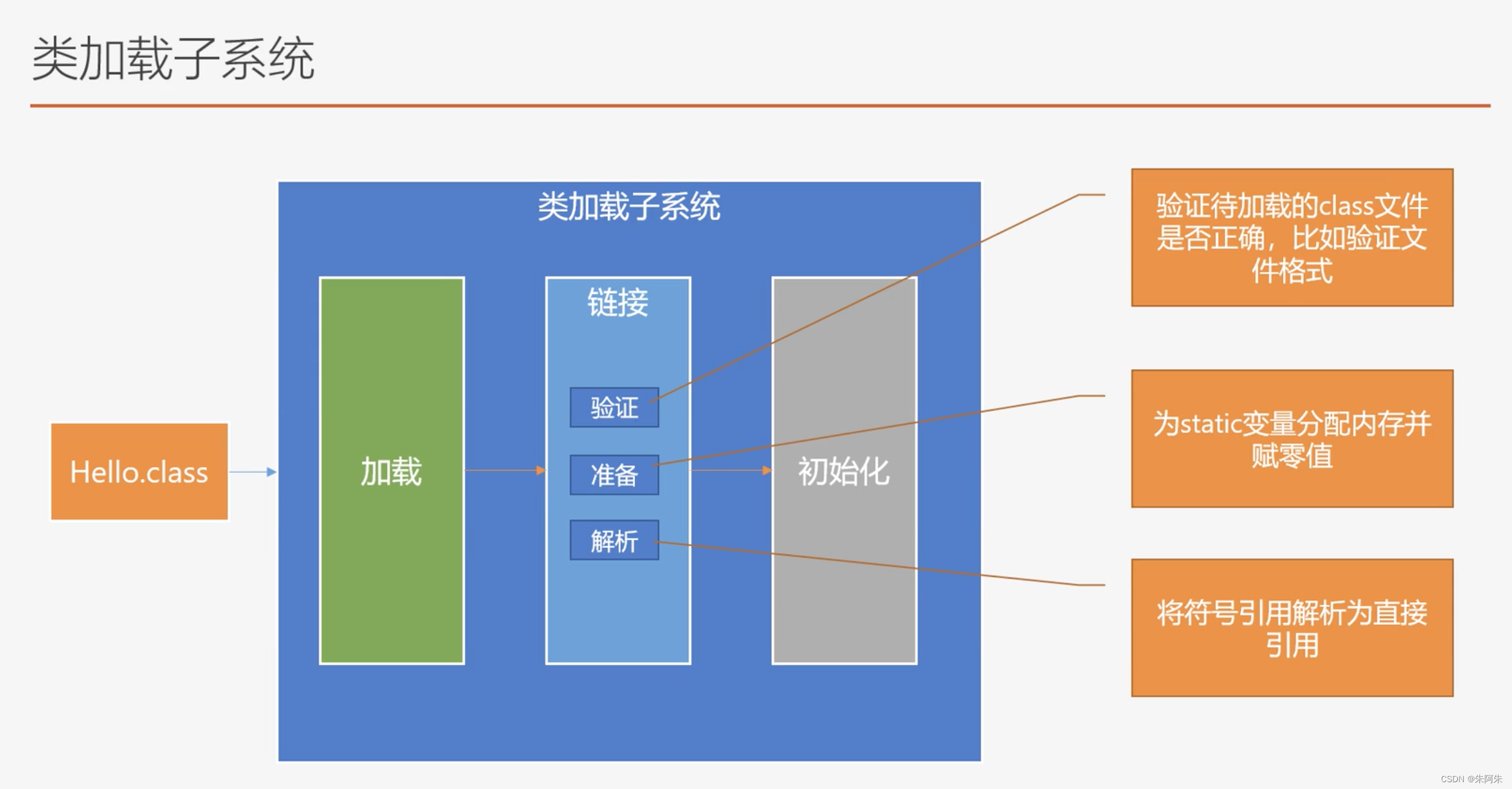
类加载器分两种:引导类加载器是jvm底层中用C和C++语言写的
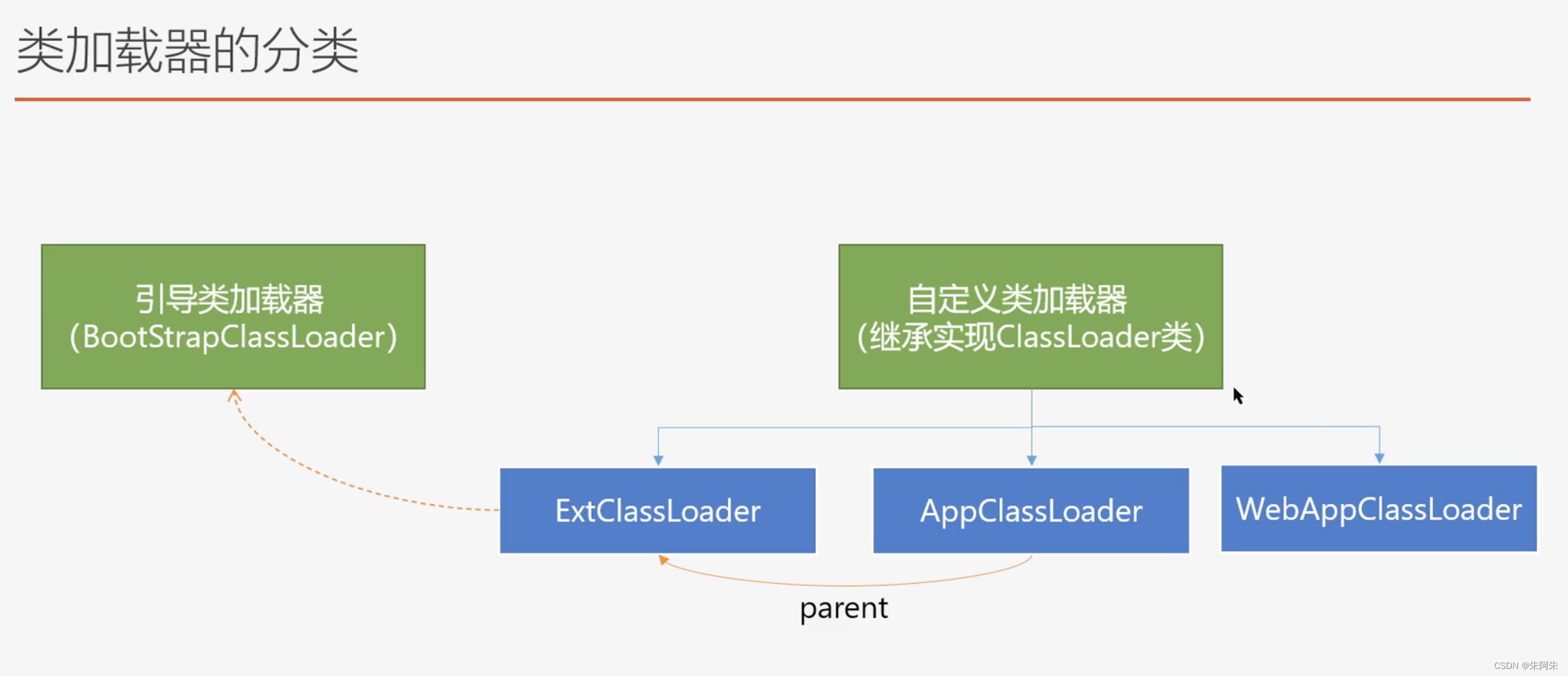
各个默认的类加载器的不同区别在于 各自默认负责要加载的类的目录不一样
比如
BootStrapClassLoader:负责jre/lib 目录下
ExtClassLoader:负责jre/lib/ext 目录下
AppClassLoader:负责 classpath目录下
什么是双亲委派 和 双亲委派的两大作用
- 避免类的重复加载
- 防止核心API被篡改
什么是双亲委派机制
双亲委派机制(Parent Delegation Mechanism)是Java中的一种类加载机制。在Java中,类加载器负责加载类的字节码并创建对应的Class对象。双亲委派机制是指当一个类加载器收到类加载请求时,它会先将该请求委派给它的父类加载器去尝试加载。只有当父类加载器无法加载该类时,子类加载器才会尝试加载。
这种机制的设计目的是为了保证类的加载是有序的,避免重复加载同一个类。Java中的类加载器形成了一个层次结构,根加载器(Bootstrap ClassLoader)位于最顶层,它负责加载Java核心类库。其他加载器如扩展类加载器(Extension ClassLoader)和应用程序类加载器(Application ClassLoader)都有各自的加载范围和职责。通过双亲委派机制,可以确保类在被加载时,先从上层的加载器开始查找,逐级向下,直到找到所需的类或者无法找到为止。
这种机制的好处是可以避免类的重复加载,提高了类加载的效率和安全性。同时,它也为Java提供了一种扩展机制,允许开发人员自定义类加载器,实现特定的加载策略。
双亲委派机制的原理
双亲委派机制是Java中的一种类加载机制。其原理如下:
-
当Java程序需要加载一个类时,首先会委托给当前类加载器的父类加载器进行加载。
-
父类加载器会按照相同的方式尝试加载该类。如果父类加载器能够成功加载该类,则加载过程结束。
-
如果父类加载器无法加载该类,则会将加载请求再次委托给它的父类加载器,直到达到顶层的引导类加载器。
-
引导类加载器是Java虚拟机内置的类加载器,它负责加载核心类库,如java.lang包下的类。
-
如果引导类加载器也无法加载该类,则会回到初始的类加载器,尝试使用自身的加载机制加载该类。
-
如果自身的加载机制仍然无法加载该类,则会抛出ClassNotFoundException异常。
通过这种双亲委派的机制,Java实现了类加载的层次结构。它可以确保类的加载是有序的,避免了重复加载和类的冲突。同时,它也提供了一种安全机制,防止恶意代码的加载和执行。
主要实现在ClassLoader里的loadClass方法
双亲委派主要体现在 ClassLoader#loadClass() 方法中:
PS:每个 ClassLoader 都有如下三个基础方法:
- loadClass()
- 入口,定义了 加载/寻找 Class 的策略。比如双亲委派,或者其他形式
- 调用 findClass() 读入 class 文件,并生成 Class 对象
- findClass()
- 根据 class 名,在当前 ClassLoader 能处理路径中查找,如果能找到就将 class 文件读入
- 调用 defineClass 生成 Class 对象
- defineClass()
- native 方法
- 将字节数组生成 Class 对象
// resolve = false 不进行解析
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 查看该类是否被加载过
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 获取当前类父类的加载器
if (parent != null) {
// 使用父类的加载器加载!!!
// 递归
c = parent.loadClass(name, false);
} else {
// 如果 parent 为 null,说明父类加载器为引导类加载器
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
}
// 当前类的加载器父类加载器未加载此类 or 当前类的加载器未加载此类
if (c == null) {
long t1 = System.nanoTime();
// 调用当前 Classloader 的 findClass
// 注:可能当前 classloader 无法处理要加载的这个类的路径,这时返回 null
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
// 根据入参决定是否解析
if (resolve) {
resolveClass(c);
}
return c;
}
}
如何自定义类加载器,下面是一个自定义 ClassLoader 示例,直接继承 ClassLoader 类,然后重写 findClass 方法就行了(采用双亲委派)
public class MyClassLoader extends ClassLoader{
// 指定的要加载 class 文件的目录
private File classPathFile;
public MyClassLoader(String absolutePath) {
this.classPathFile = new File(absolutePath);
}
@Override
// 根据类名将指定类加载进 JVM
// 注:该 class 必修在指定的 absolutePath 下
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 拼接全类名
String className = MyClassLoader.class.getPackage().getName() + "." + name;
if(classPathFile != null){
// 根据绝对路径,以及 class 文件名,拿到 class 文件
// 注意全类名的情况
File classFile = new File(classPathFile,name.replaceAll("\\.","/") + ".class");
// 如果 class 文件存在
if(classFile.exists()){
// 将 class 文件读入内存,暂存到一个字节数组中
FileInputStream in = null;
ByteArrayOutputStream out = null;
try{
in = new FileInputStream(classFile);
out = new ByteArrayOutputStream();
byte [] buff = new byte[1024];
int len;
while ((len = in.read(buff)) != -1){
out.write(buff,0,len);
}
// 构造类的 Class 对象!!!
// 注:defineClass() 是一个 native 方法
return defineClass(className, out.toByteArray(), 0, out.size());
}catch (Exception e){
e.printStackTrace();
}
}
}
return null;
}
}
运行时数据区
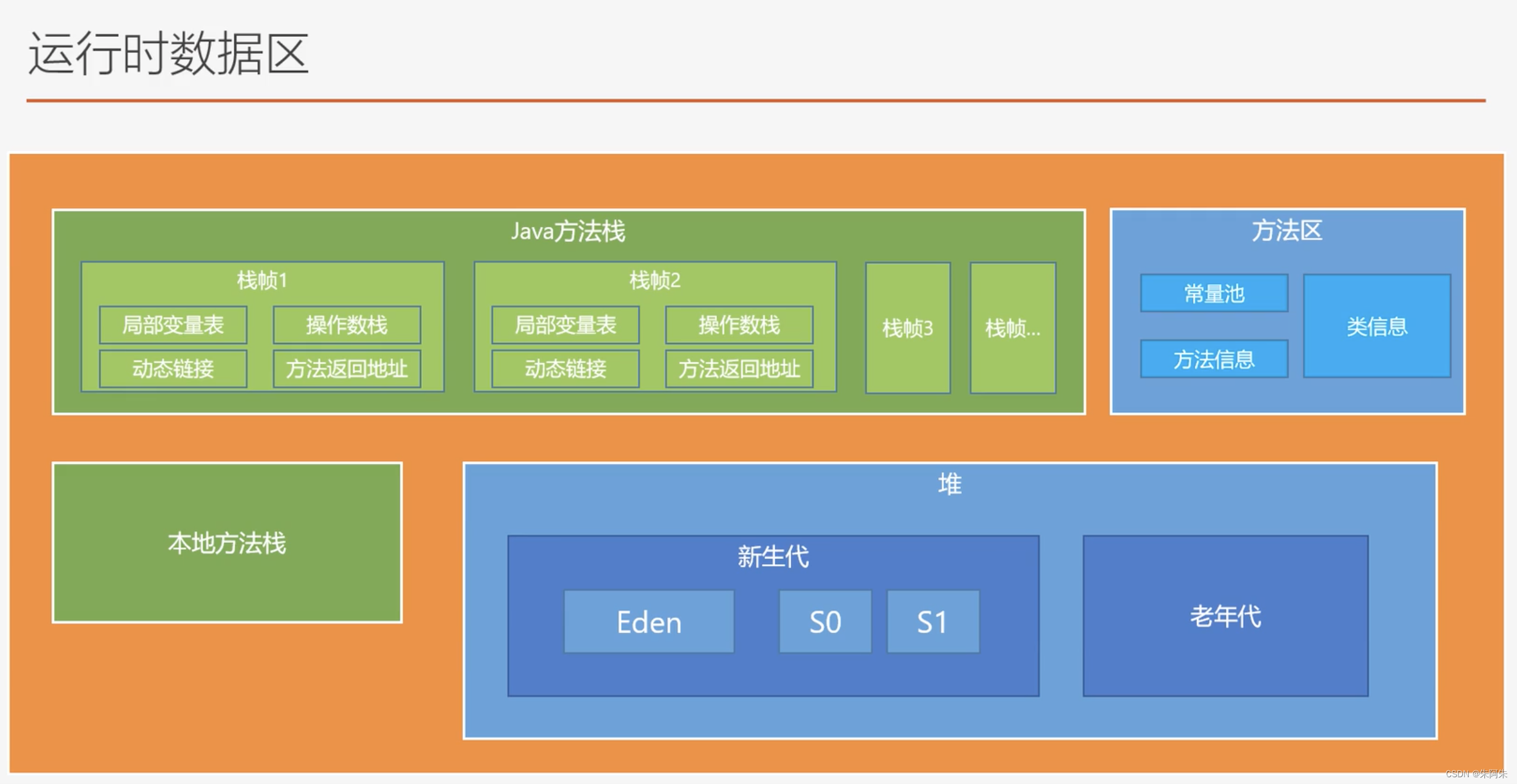
程序计数器

Java方法栈
一个方法对应一个栈帧,方法内有其他方法就会依次入栈,执行完的方法对应的栈帧会出栈
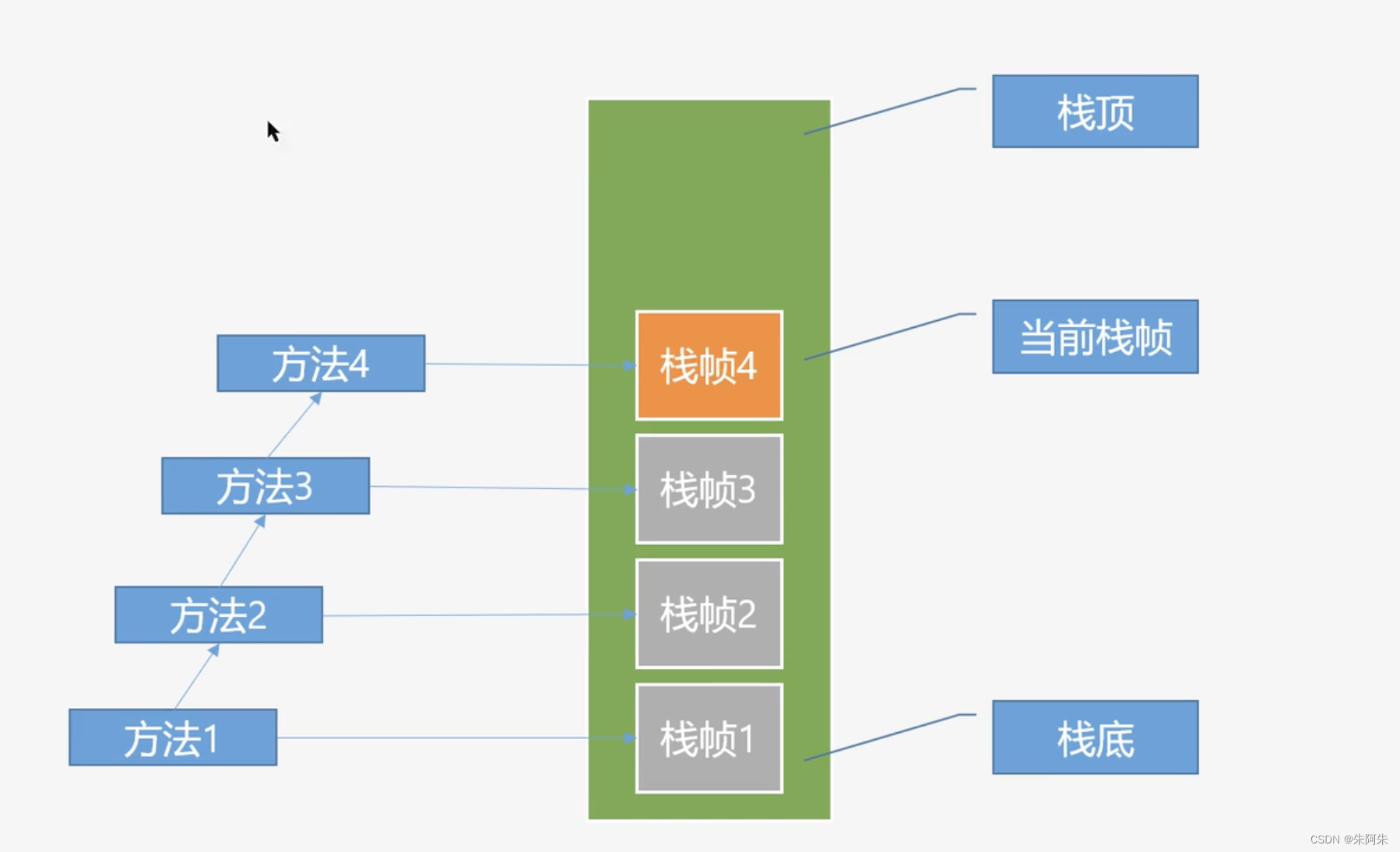
OOM是内存不够, StackOverflowError 是方法调用层次太多
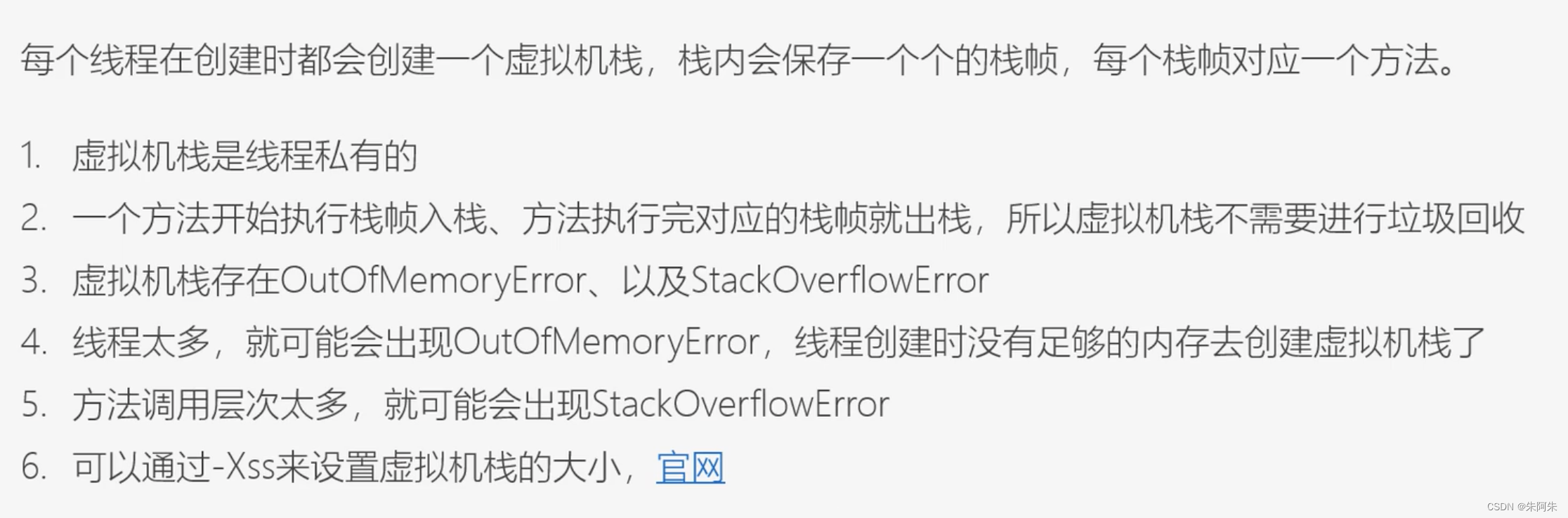
栈帧
局部变量表
slot 代表各个方法内的局部变量
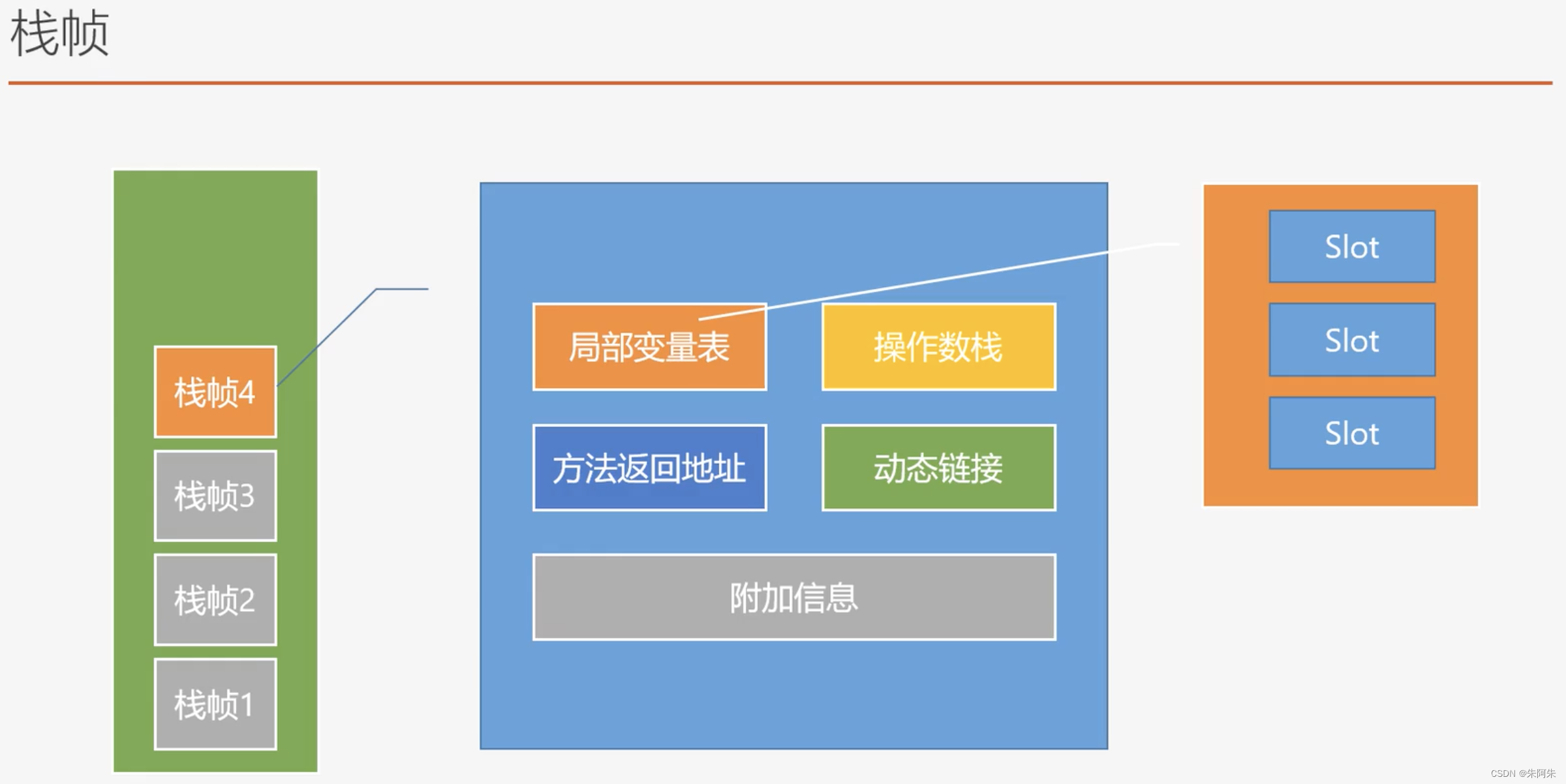
操作数栈

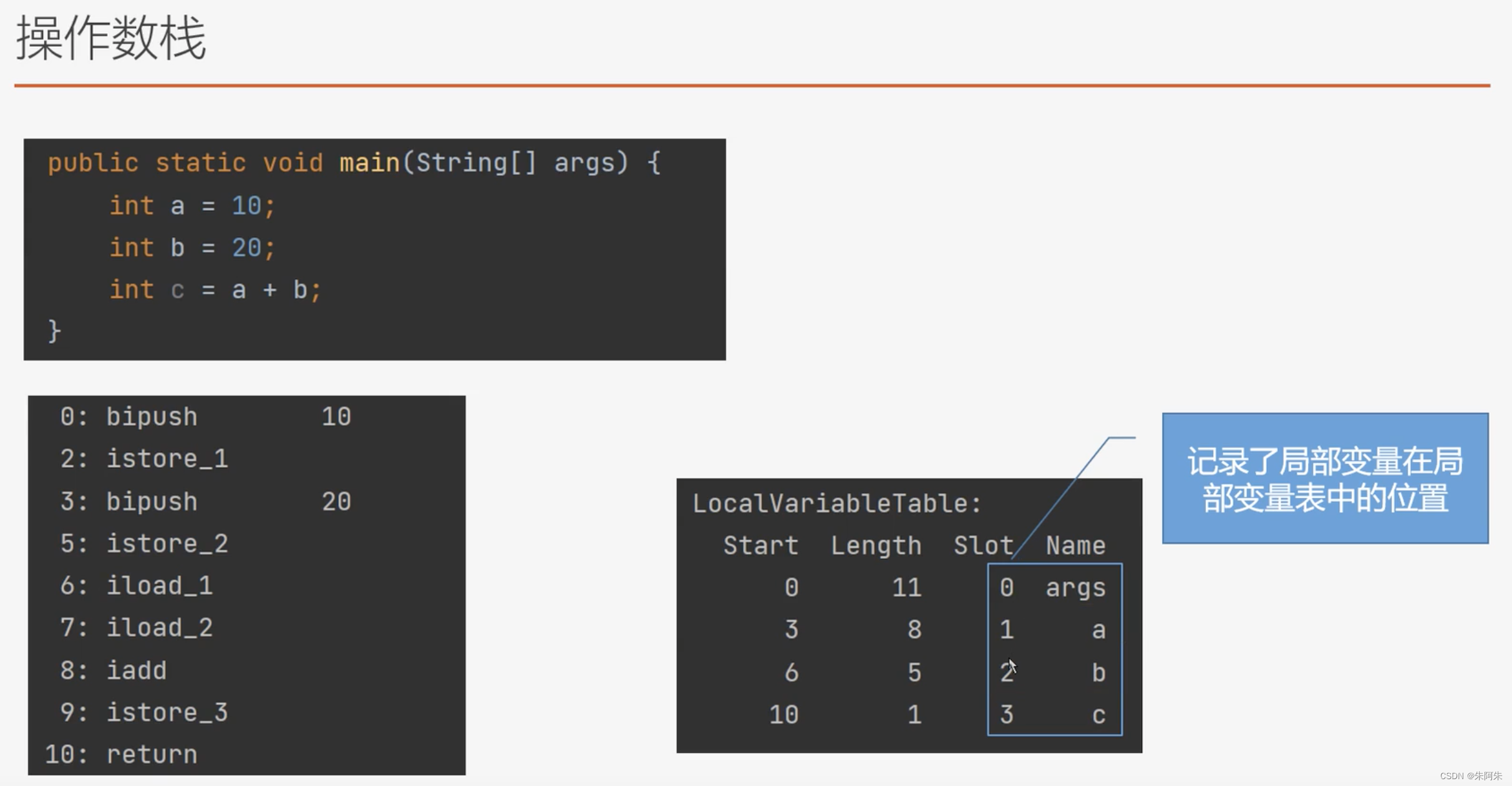
执行步骤
10压入操作数栈- 将 10 放入局部变量表 2
- 将20 压入操作数栈
- 将20 放入局部变量表2
- iload1 将 局部变量表1放入操作数栈 iload2 将 局部变量表2放入操作数栈
- iadd 操作数栈中相加,得到的值放入局部变量3
本地方法栈

堆




Java对象在各个区域的流转情况
对象首先来到Eden区,Eden满了后进行一次GC,没被清理的对象来到S0区计数加一,Eden迎接新对象,每次GC存活对象计数加一,计数达到阈值进入老年代,如果有大对象(文件上传对象)S0和S1放不下直接进入老年代
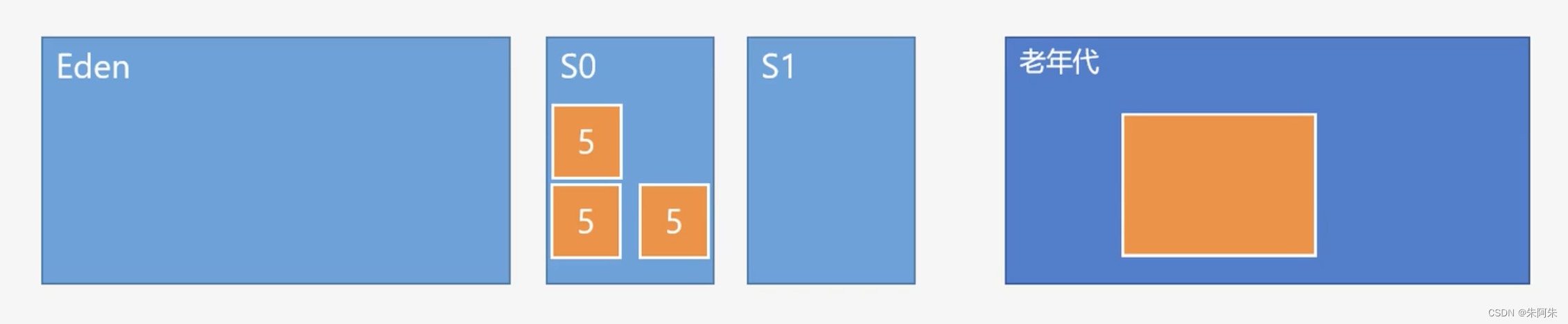
各个GC的区别
老年代只有一个CMS专门回收

为什么要进行垃圾回收

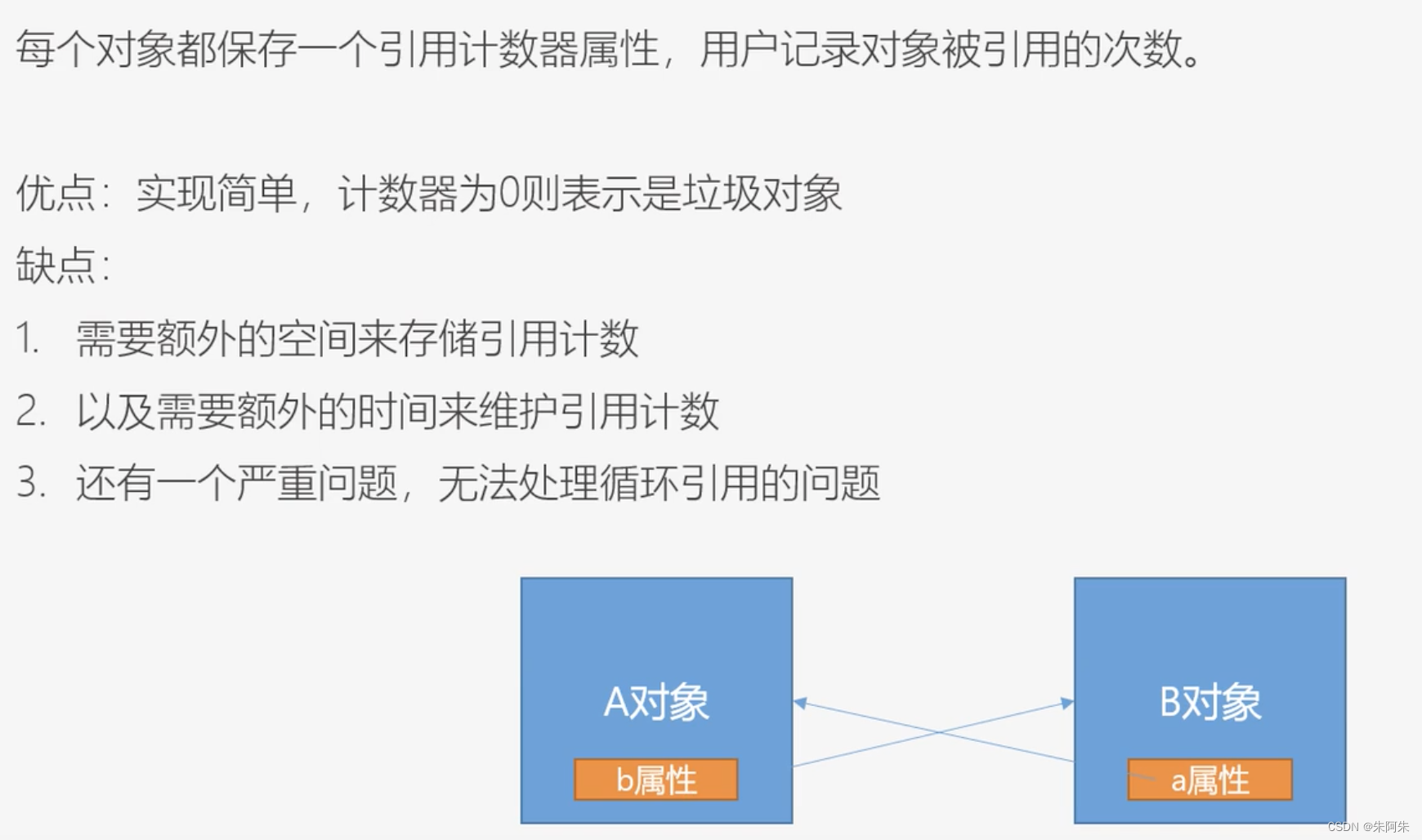
垃圾标记阶段,如何标记垃圾

引用计数法
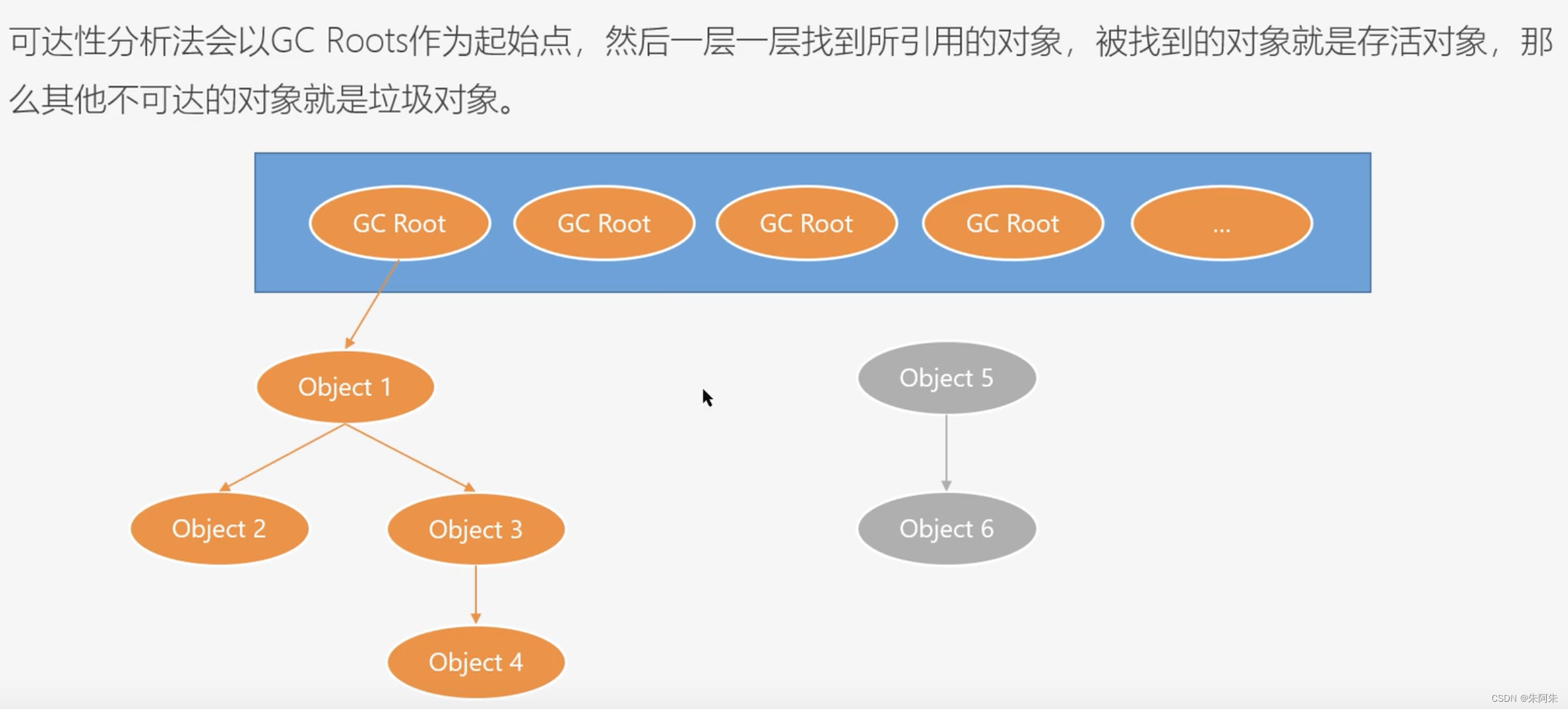
可达性分析法
GCRoots包括哪些

虚拟机栈和本地方法栈中的方法参数和局部变量存储的是对象的地址值
GC算法
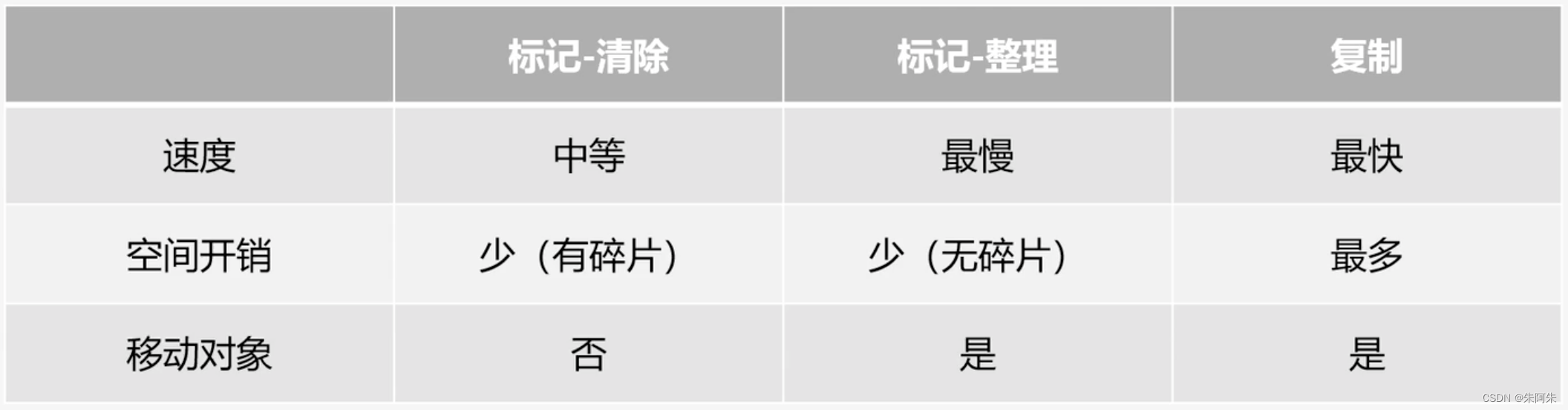
标记清除算法
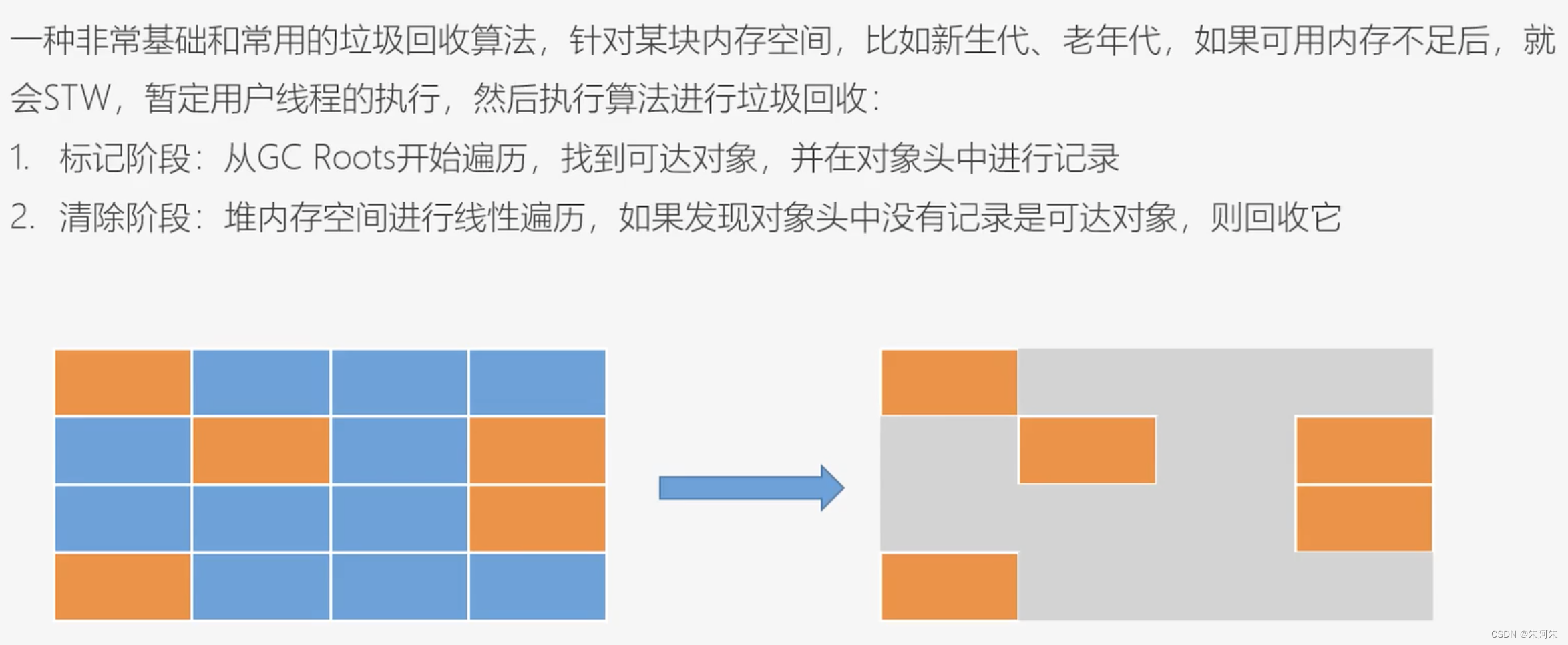
- 缺点
- 效率不高
- 会产生内存碎片
- 优点
- 简单
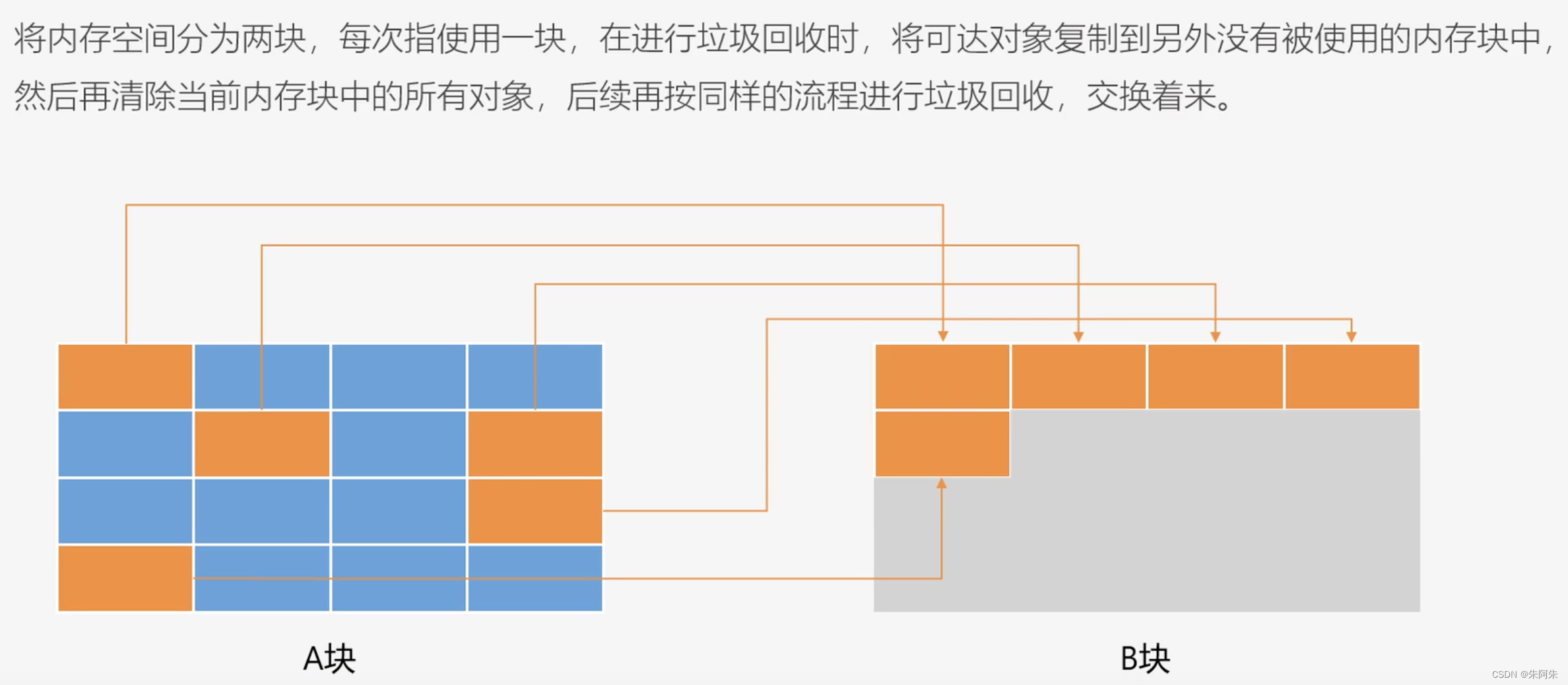
复制算法
利用空间换时间,适合垃圾对象比较多,非垃圾对象少,这样复制成本就低效率就高。
新生代适合用复制算法,因为对象朝生夕死

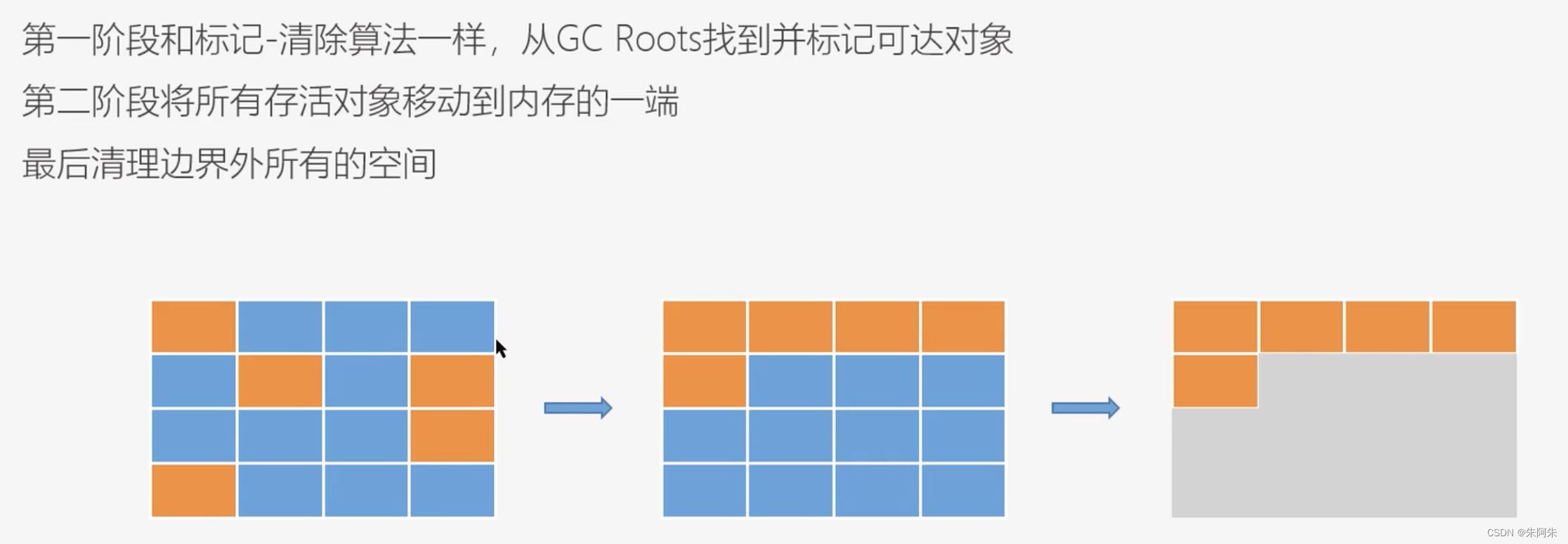
标记整理算法

算法总结
一种GC算法的使用理念
算法按需使用,用到最适合他的地方

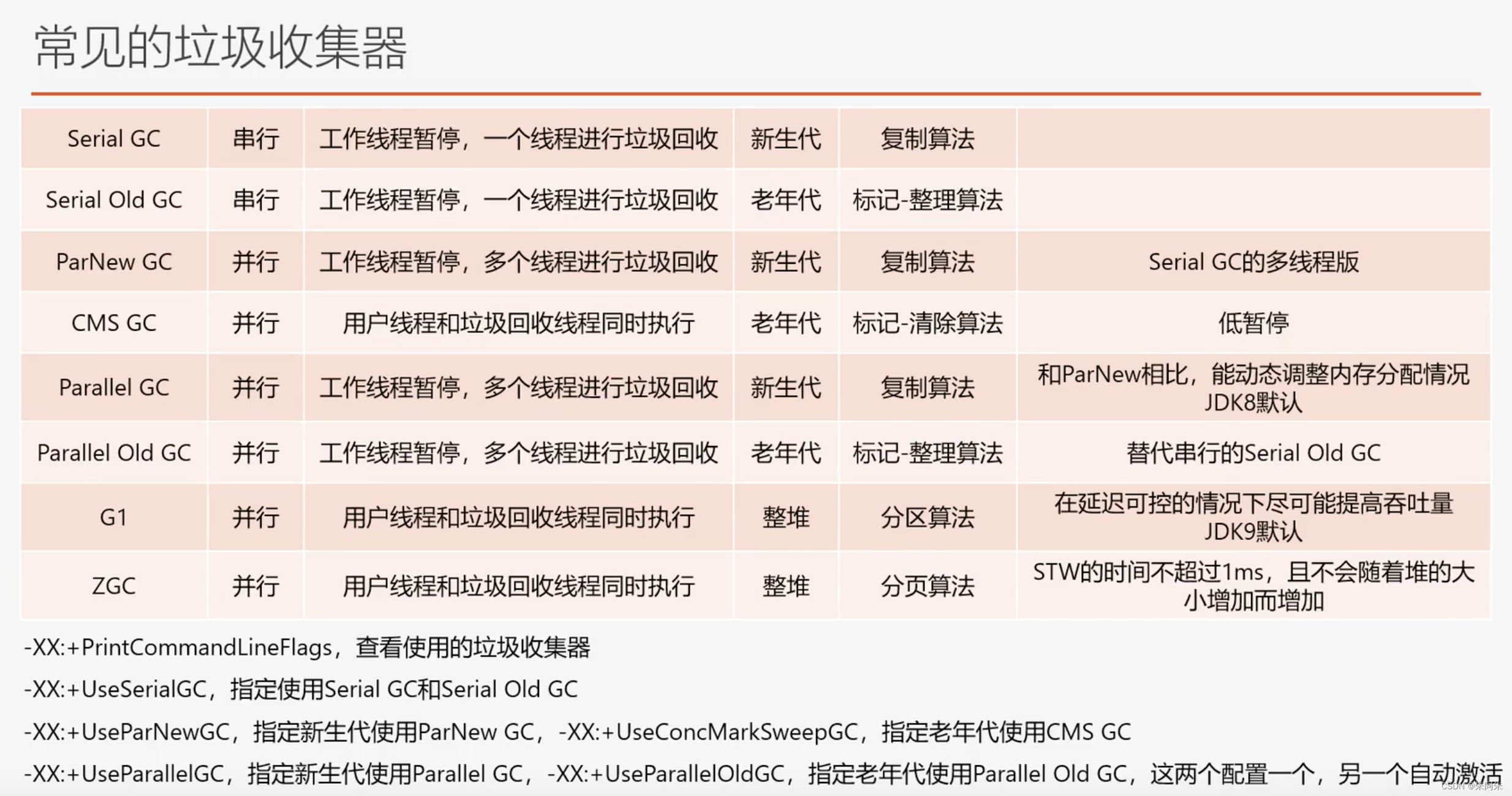
常见的垃圾收集器
CMS 如何工作
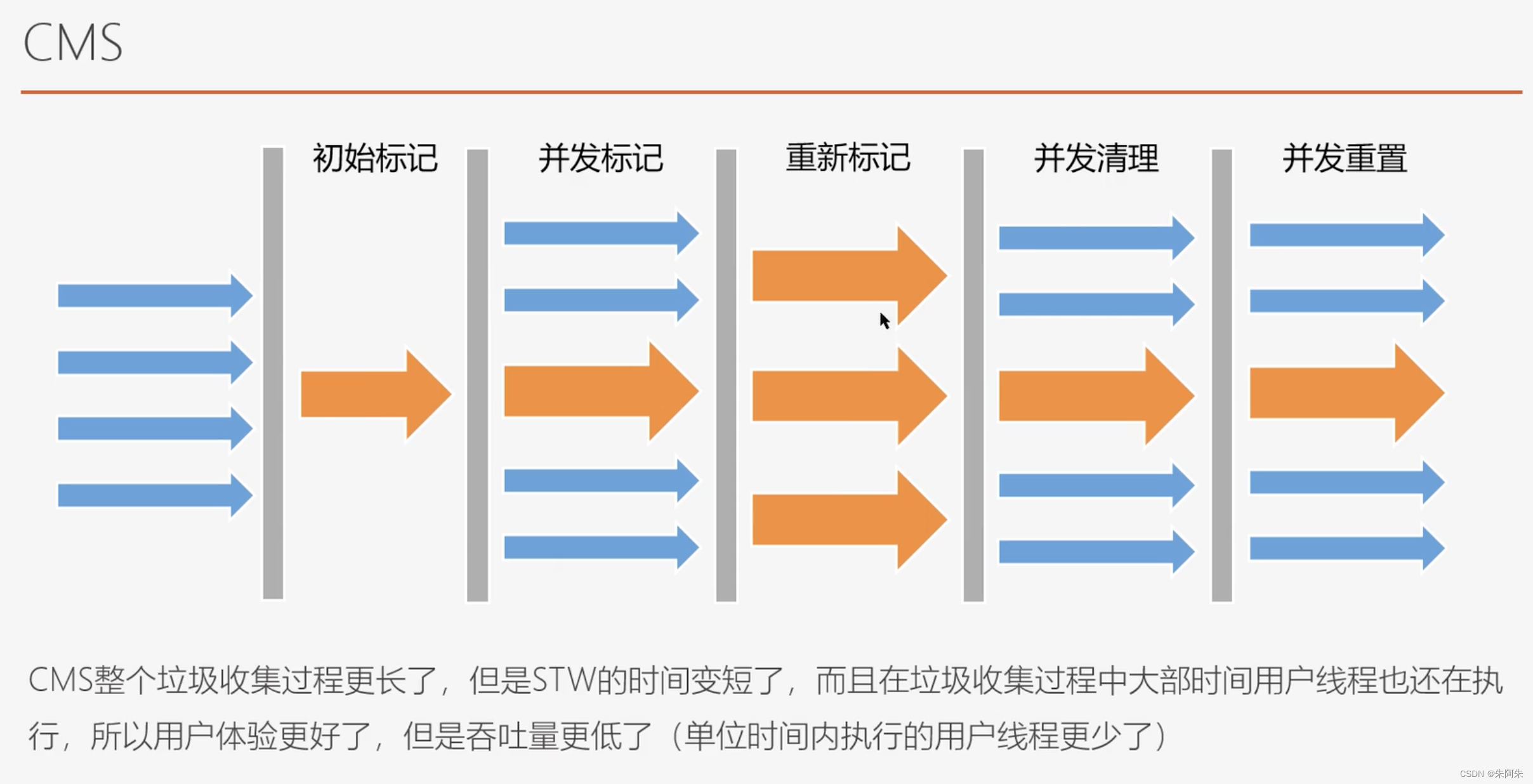
并发标记清除算法,特点低暂停,STW时间短,执行过程长,工作线程暂停时间短影响小,所以用户体验好,但是吞吐量变低

-
阶段一 初始标记:
- STW暂停所有工作线程
- 标记出GCRoots能直接可达对象(以GCRoots为起点的第一层引用对象,不再向下标记)
- 一旦标记,就回复工作线程继续执行
- 这个阶段比较短,所以STW时间短
-
阶段二 并发标记(最费时的阶段,但是不STW不影响工作线程工作):

因为工作线程也在运行中,标记垃圾可能会有误差,因为程序在运行就有可能产生垃圾对象,但是误差不大 -
阶段三和阶段四 重新标记短暂STW后并发清理

CMS存在的问题

G1是如何工作的
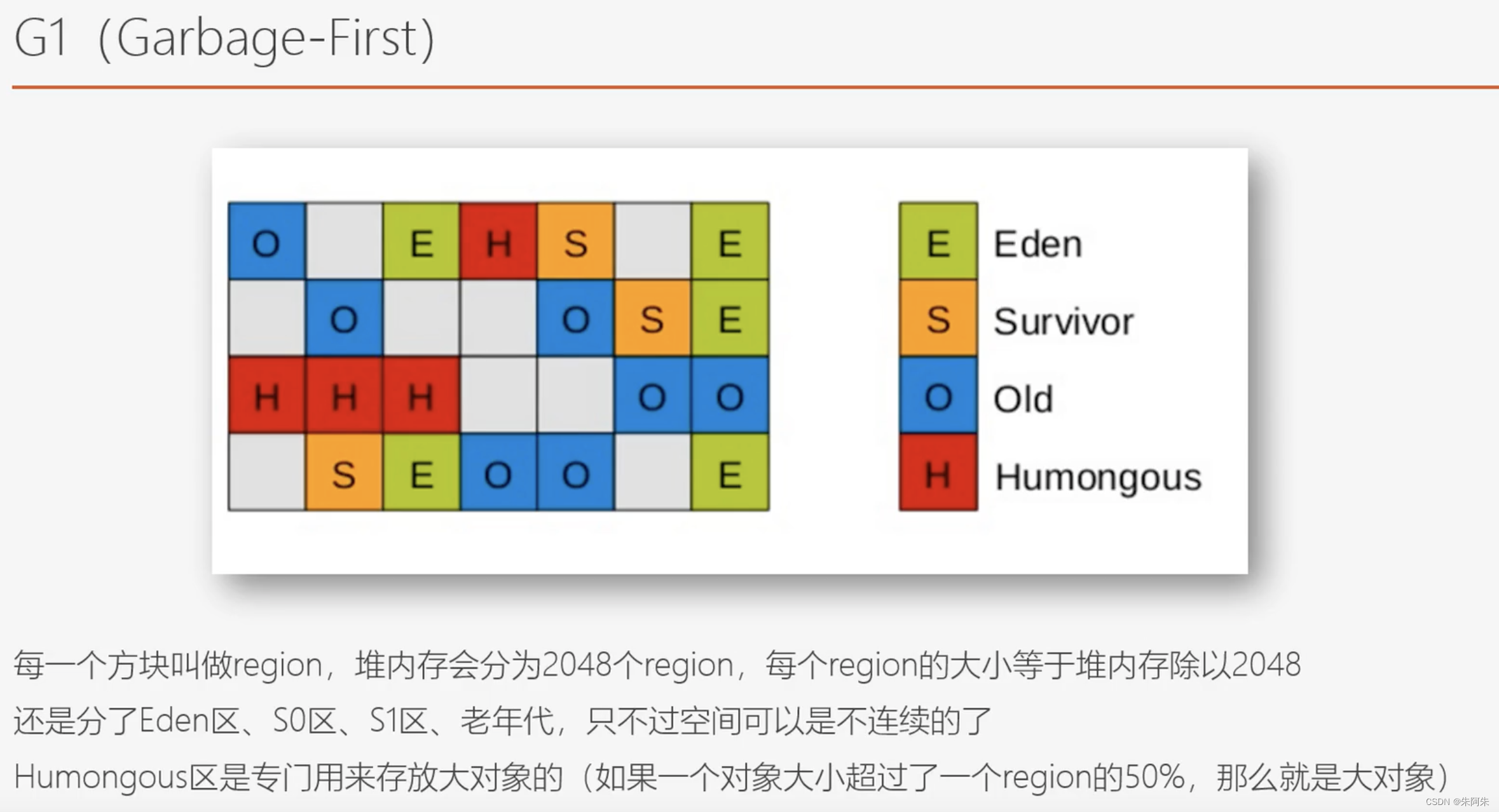
G1垃圾回收器下,堆空间不再是其他回收器那样的各个代之间层次分明,而是把堆空间分成2048个Region进行管理,各个代空间逻辑上连续,但是物理上不再连续
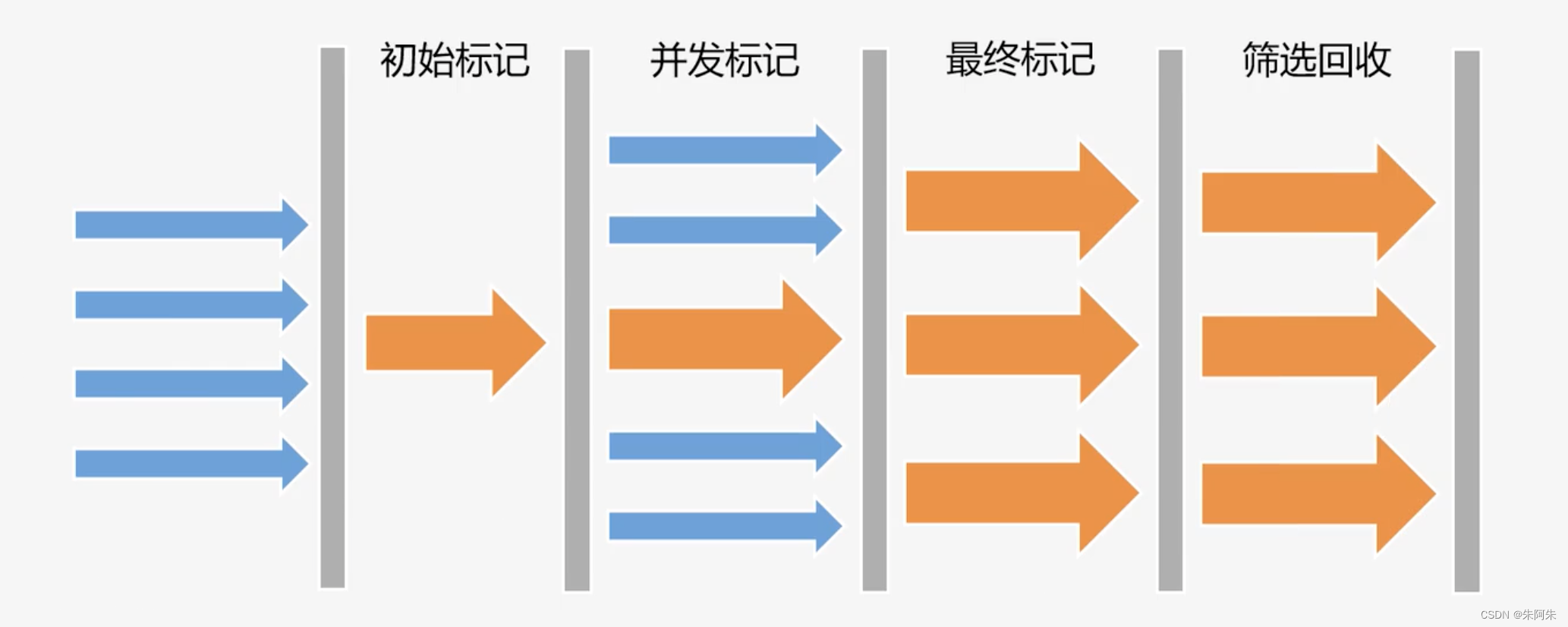
G1的初始标记和并发标记与CMS相同

G1和CMS最大区别在最后一步,CMS是清除算法,G1是复制算法,复制到空闲的region

G1的筛选回收
可以指定GC的STW停顿时间,CMS的STW时间是不确定的,相较于CMS的清除算法,G1是把需要清理的Region中的非垃圾对象复制到空闲的Region区域