AlsoEasy-RecognitionTranslator
- 需求分析
- 系统分析
- 功能拆解
- 工程语言选择
- 技术可行性分析
- 具体实现
需求分析
见上篇[从零开始]用python制作识图翻译器·一
上篇分析了该产品的需求以及市场上的可行性(没有被吊打的竞品)。而本篇将着重于分析如何实现。
系统分析
功能拆解
我们将一整个流程细化分成以下几个步骤,并分析每步涵盖的技术,一步步探索其可行性。
-
划定屏幕固定区域(用qq截图演示效果)

作 用:通过鼠标点击和松开确定识别区域的对角线坐标;
相关技术:GUI、鼠标事件、键盘热键。 -
获取固定区域图像(用qq截图演示效果)

作 用:获取区域的图像以进行后续的识别操作;
相关技术:GUI、PIL、屏幕截图。 -
识别图中文字(用qq截图演示效果)
 作 用:将区域的图像中的文字识别出来,作为翻译的源文字;
作 用:将区域的图像中的文字识别出来,作为翻译的源文字;
相关技术:文字识别。 -
将该文字翻译成目标语言的文字(用百度翻译演示效果)
 作 用:将识别的到的文字翻译为目标语言的文字;
作 用:将识别的到的文字翻译为目标语言的文字;
相关技术:机器翻译。 -
显示在某一区域(用qq截图演示效果)
 作 用:将翻译的结果反馈到屏幕上;
作 用:将翻译的结果反馈到屏幕上;
相关技术:GUI、文本框。
工程语言选择
因为项目可能含有“文本识别”、“机器翻译”等人工智能方向的功能,所以选择python作为基础编程语言,后续的技术选择和分析会更有偏向性。
技术可行性分析
在将功能拆解以后,整个产品的制作方式就变得非常清晰了,现在我们只用从下至上一步步验证实现技术的可行性就行了。(从上到下发现最后一步翻译的技术难如登天的话那也太蛋疼了)
-
文字显示
稍微搜索就会发现用GUI就能实现。python的GUI有:wxPython、pyQt、Tkinter……前端思维就是新建一个显示特定文字的box,实现起来没什么难度。 -
机器翻译
机器翻译也是有很多种的,比较古早的是基于符号系统的,现在的主流方向都是人工智能方向,网上有一些公开的模型,一些大公司也对外开放了免费翻译API。百度的就很好用,使用教程见:python调用百度通用翻译API进行翻译。测试效果如下:
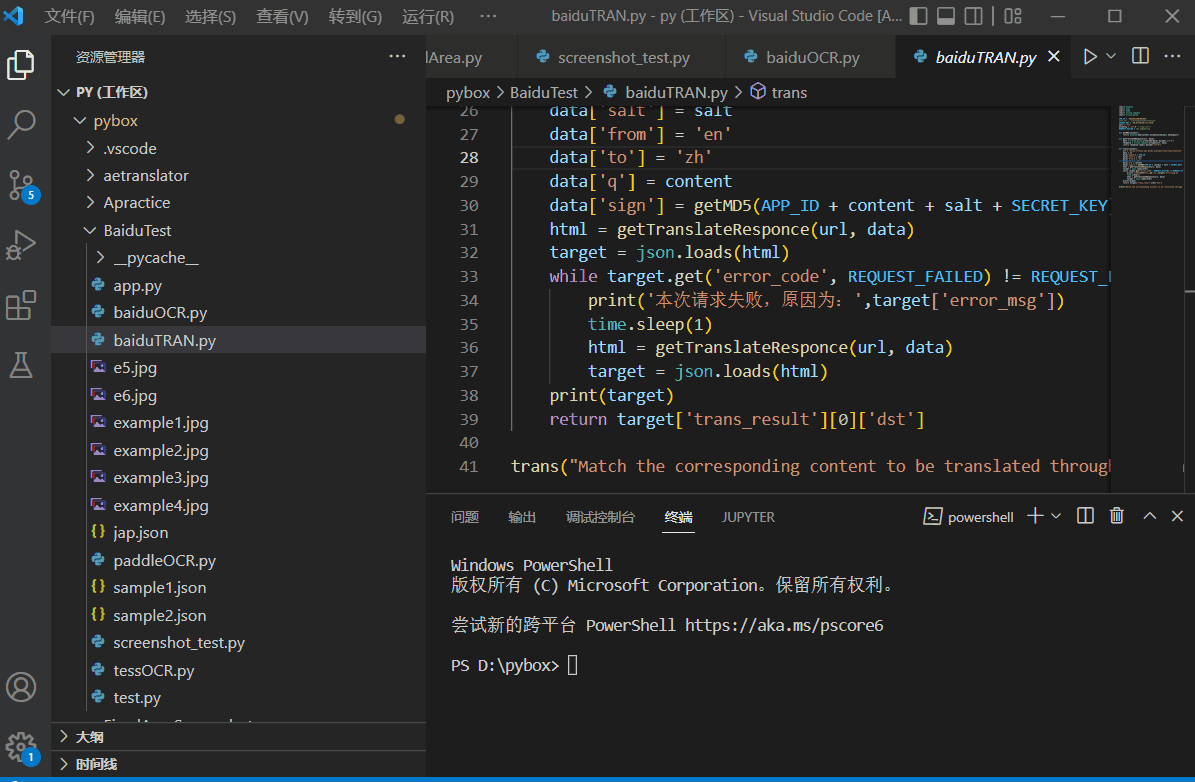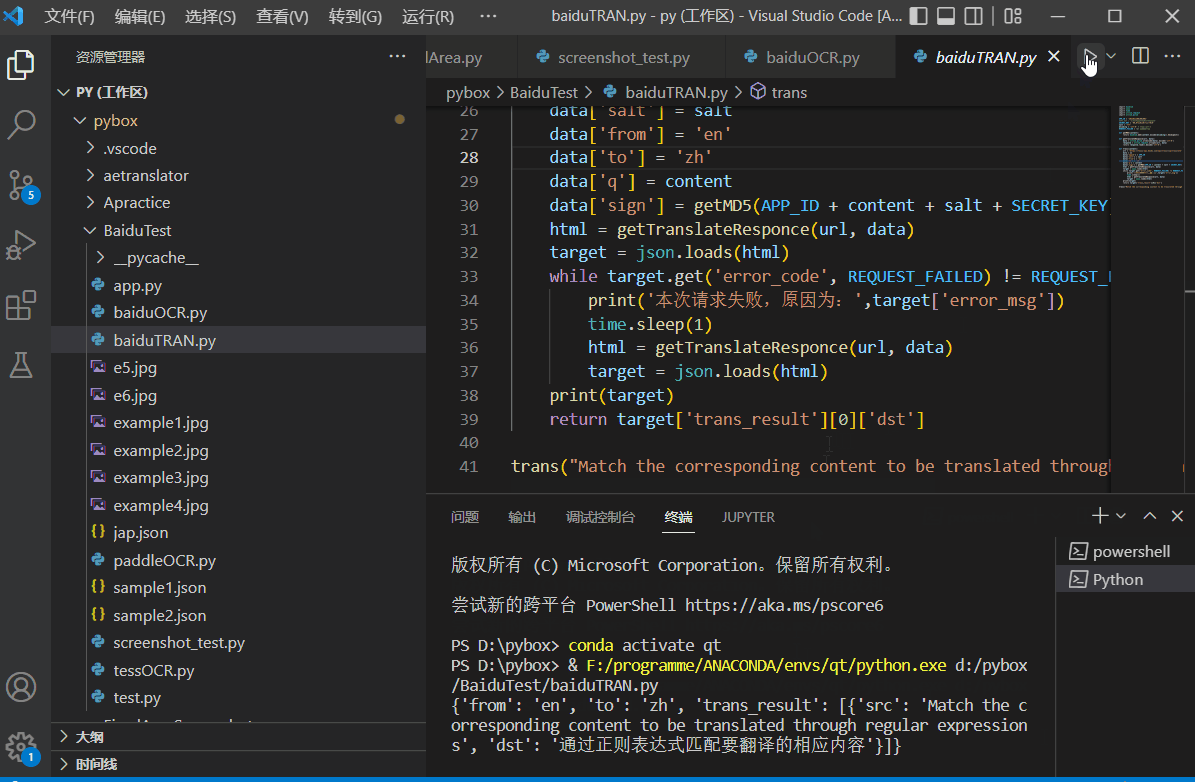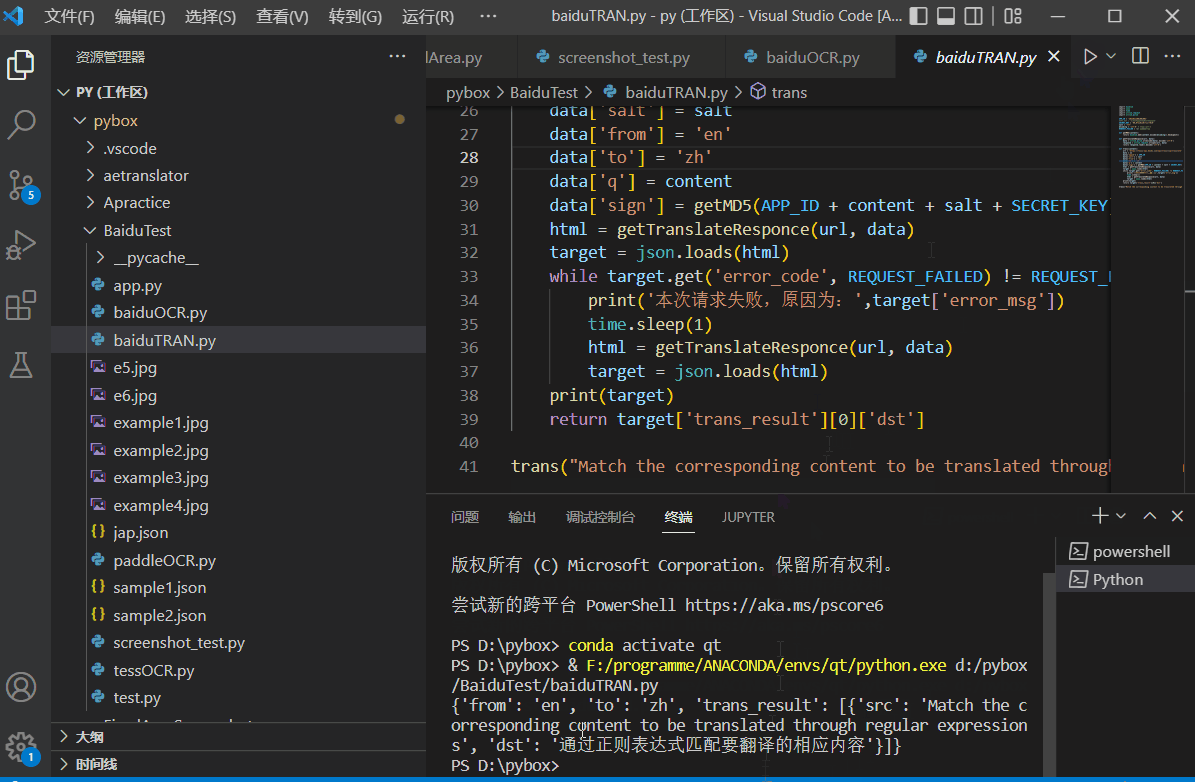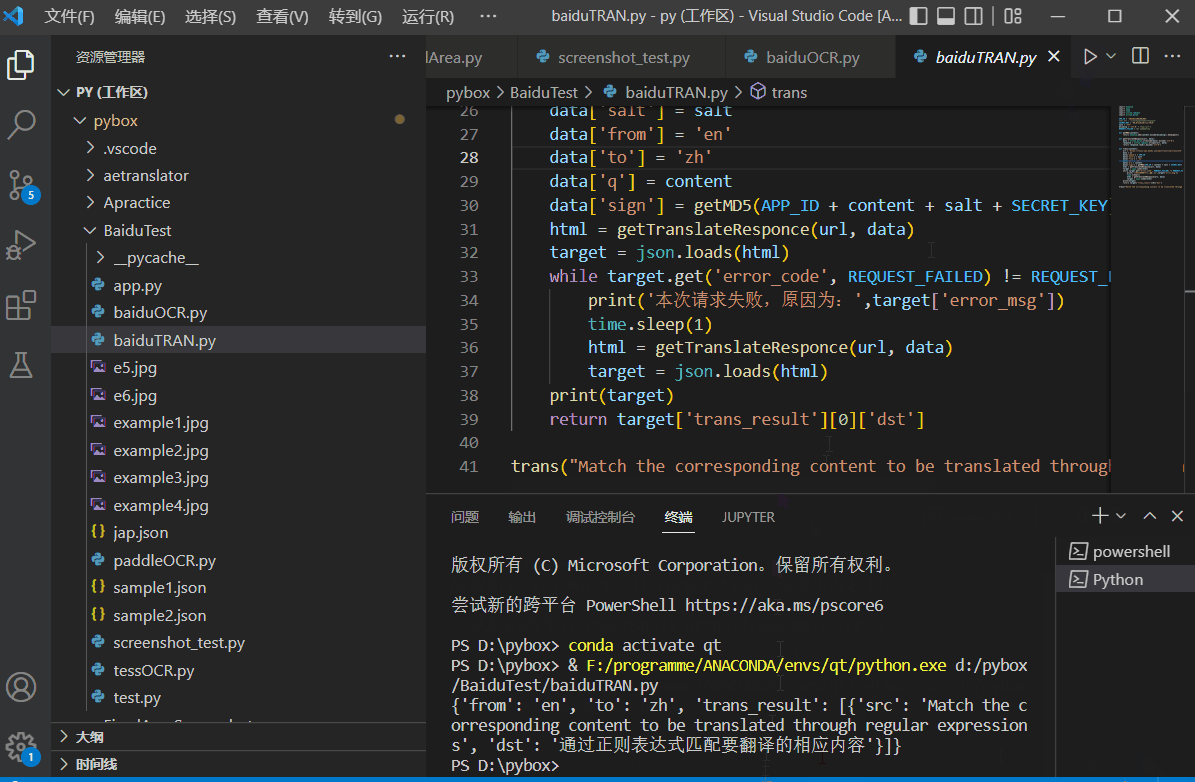
-
文字识别
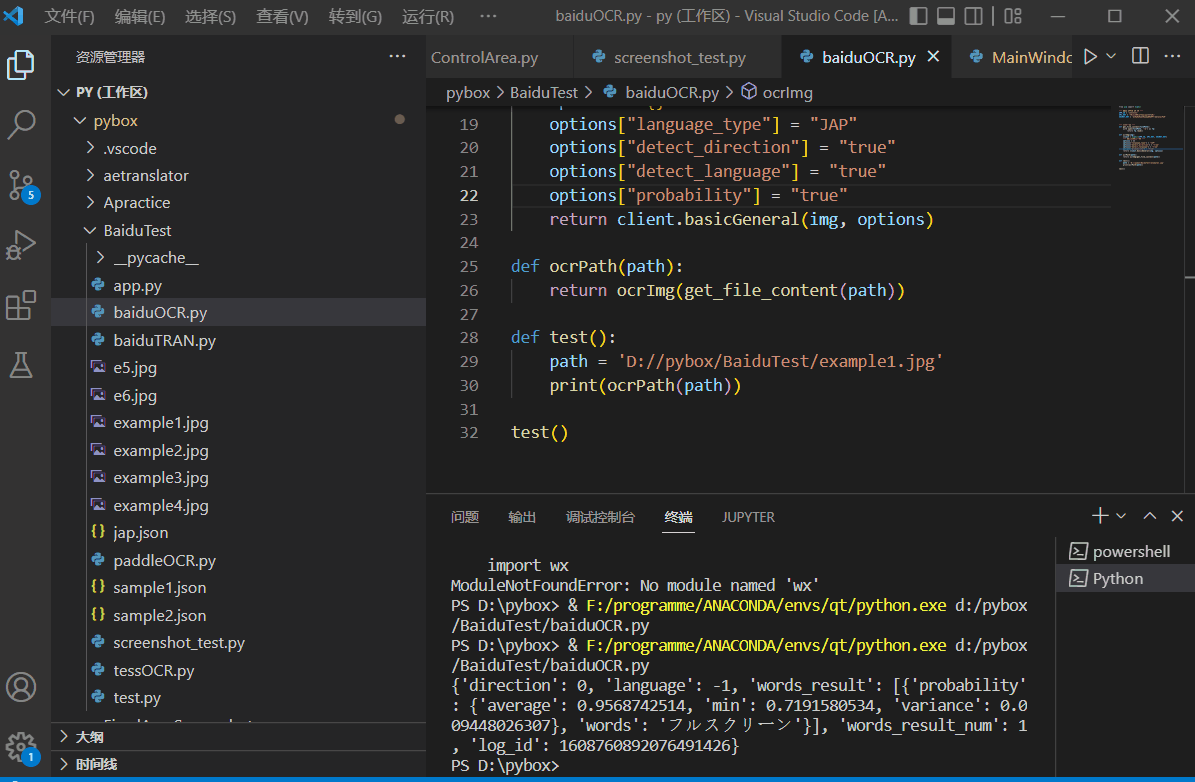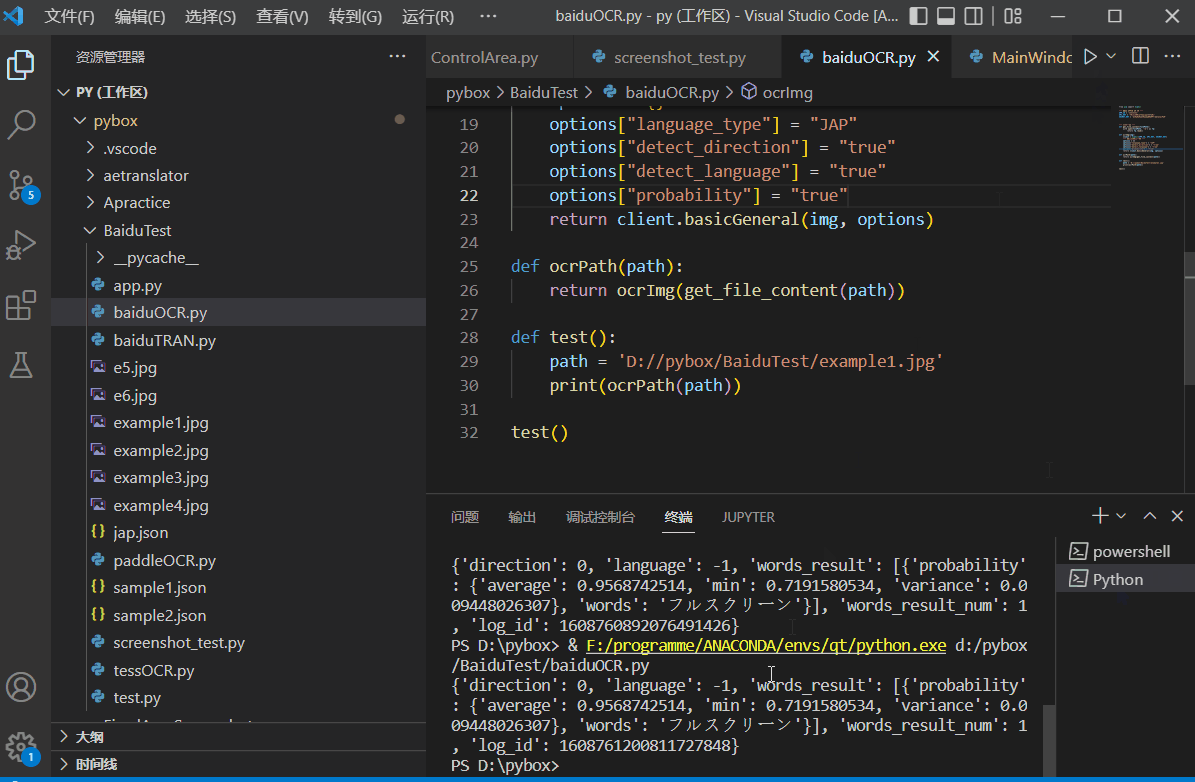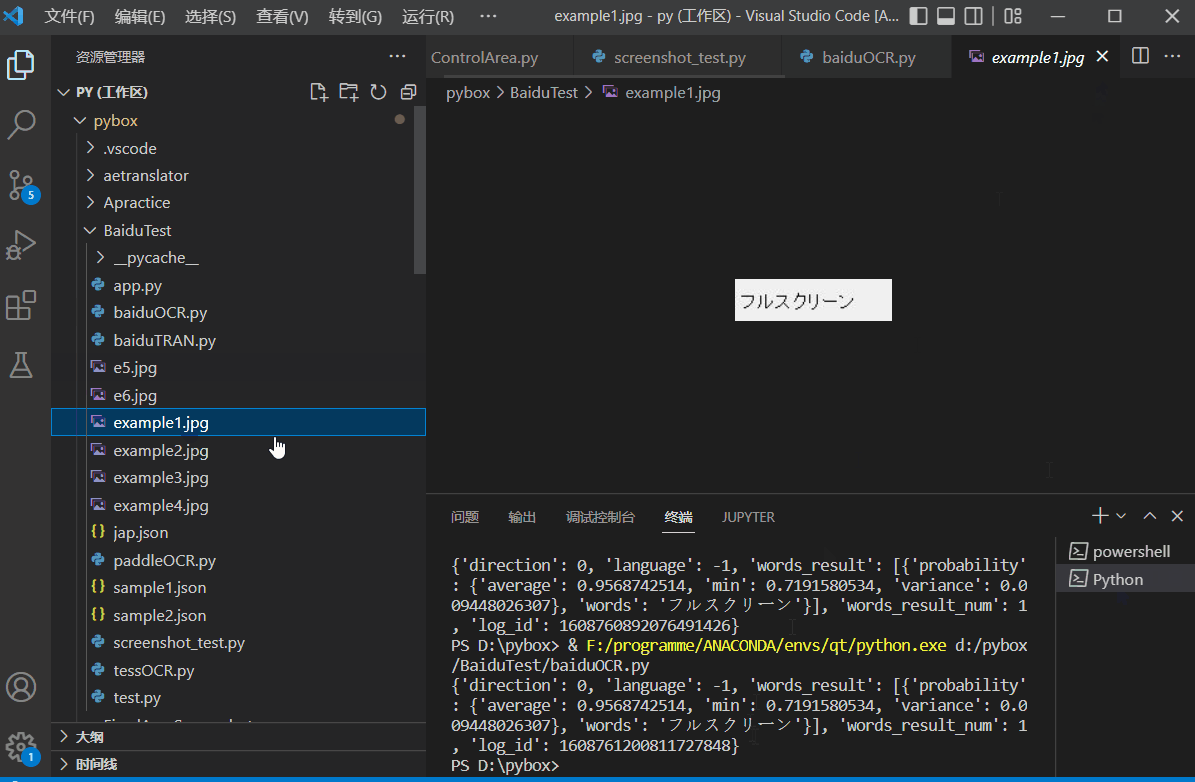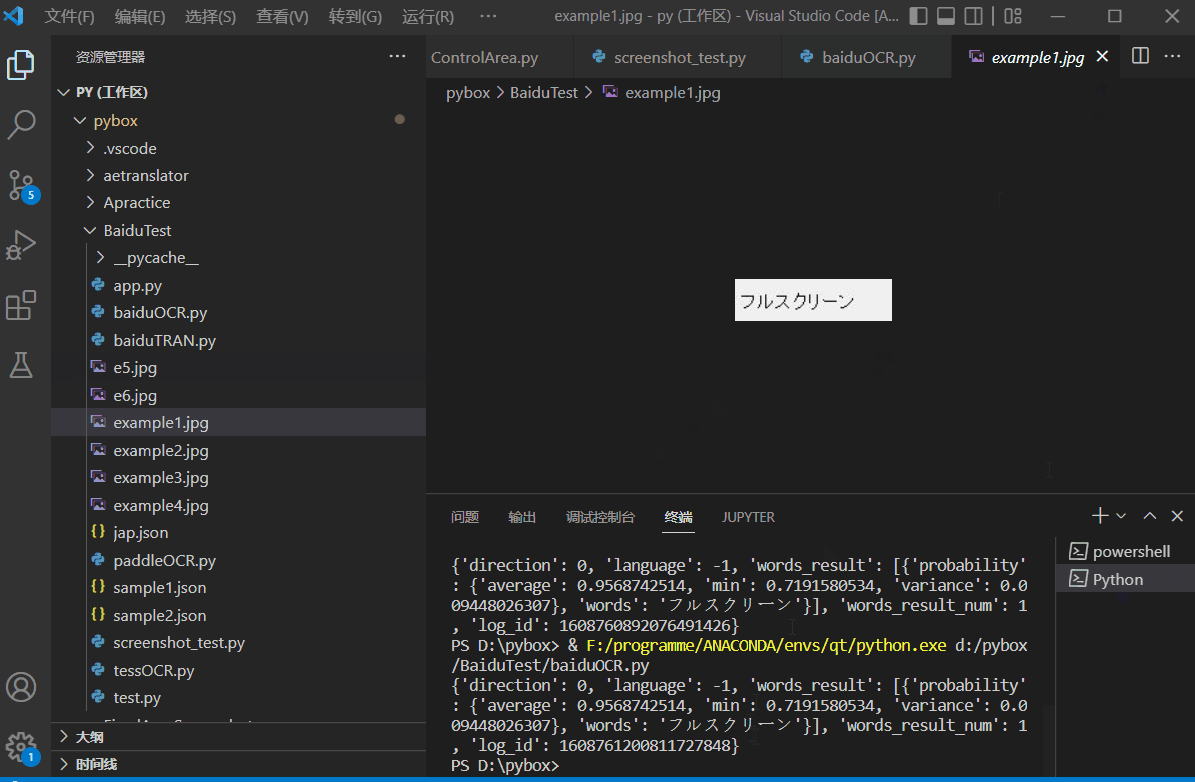
文字识别技术和机器翻译一样,现在的主流方向都是人工智能方向了,识别率高,识别速度快,网上同样有丰富的开源资源,如:TesseractOCR、EasyOCR、BaiduOCR、PaddleOCR……其中飞桨的PaddleOCR甚至提供了详细的模型训练的教程:这是PaddleOCR在gitee上的代码仓库,其中附带了详细的训练教程。测试效果如下:
-
截图
用python中PIL库的ImageGrab.grab方法即可获取指定位置,指定大小的矩形区域截图(当然必须是最顶层窗口的,我没找到像腾讯会议那种直接获取进程窗口句柄的方法)。测试效果如下:
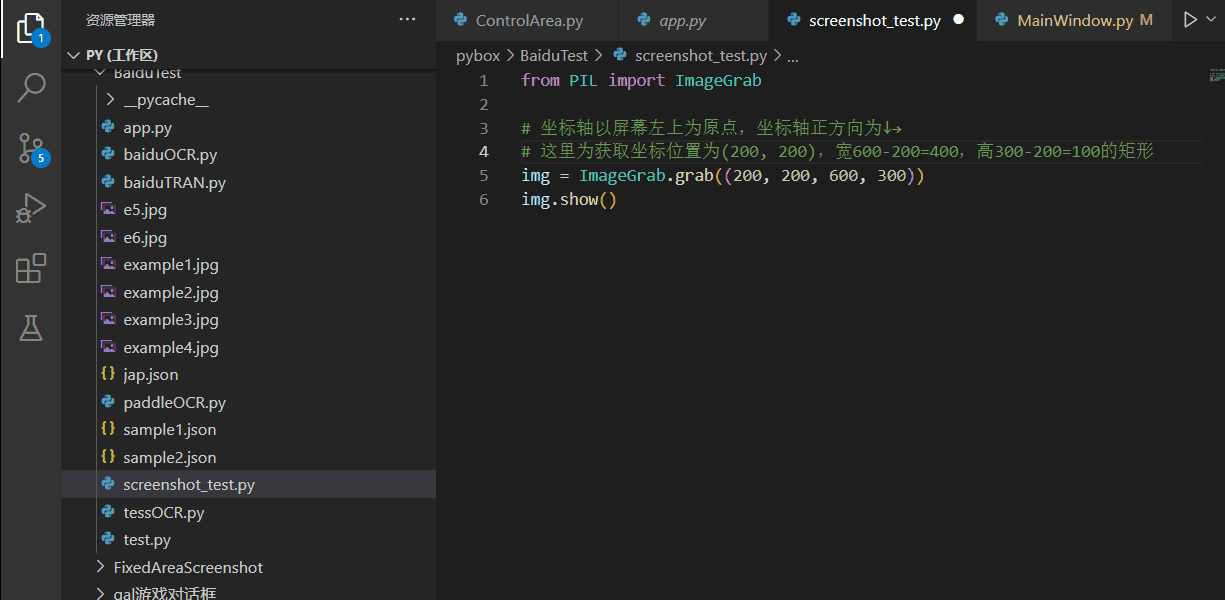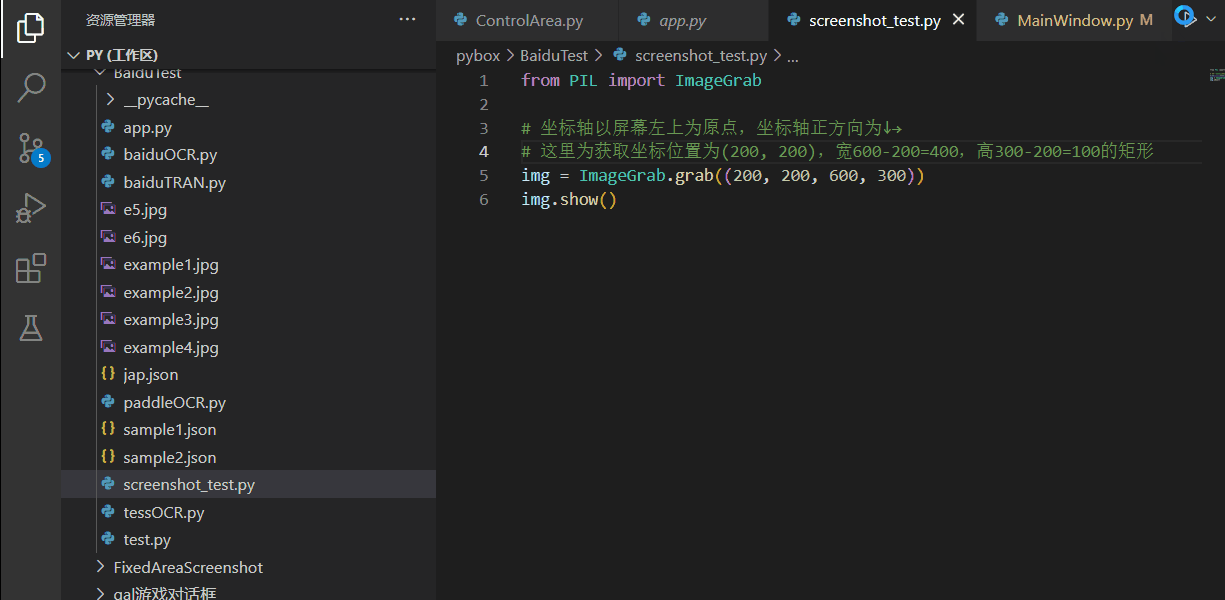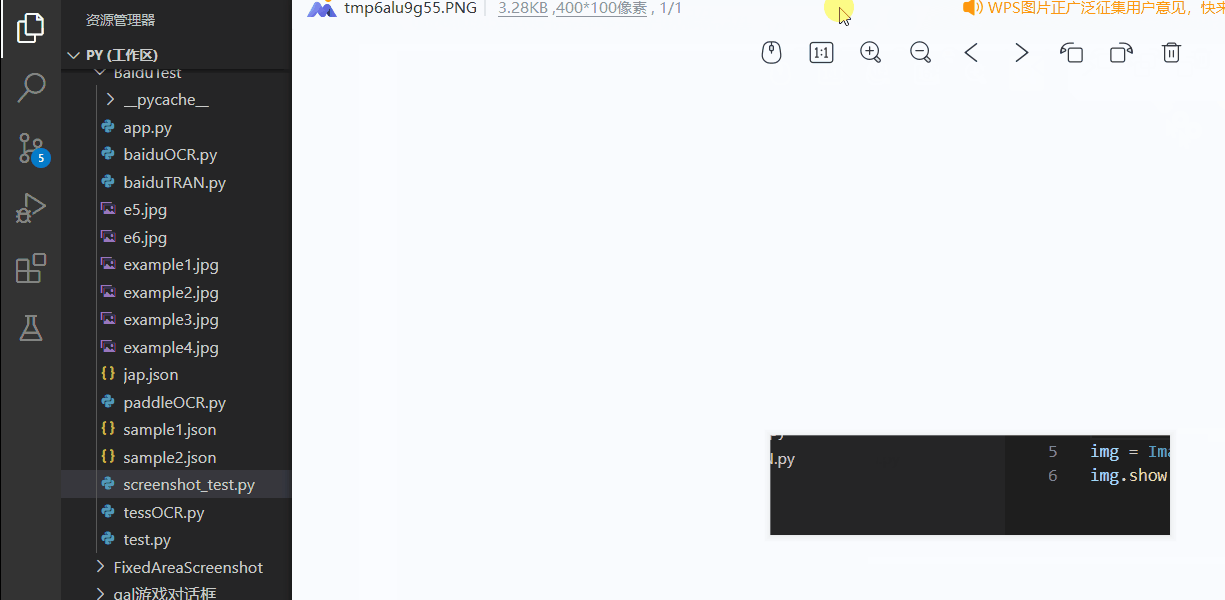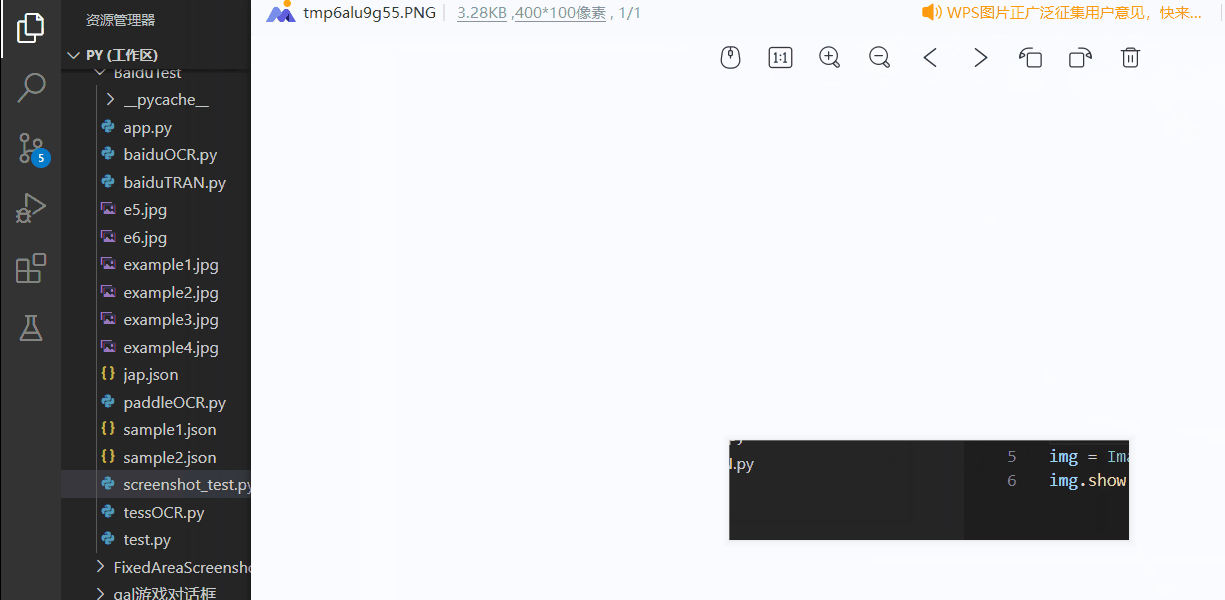
-
确定矩形对角线
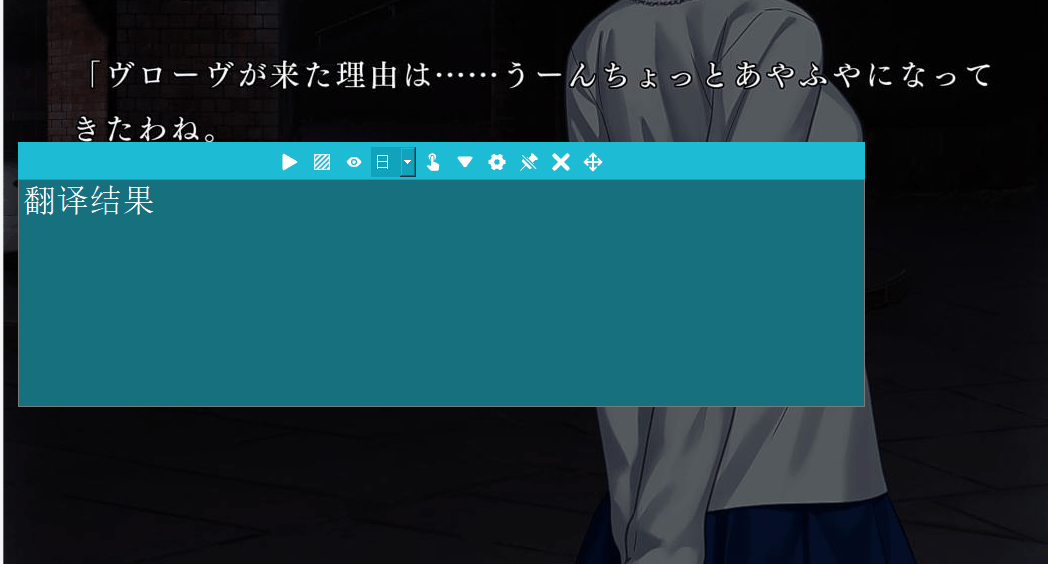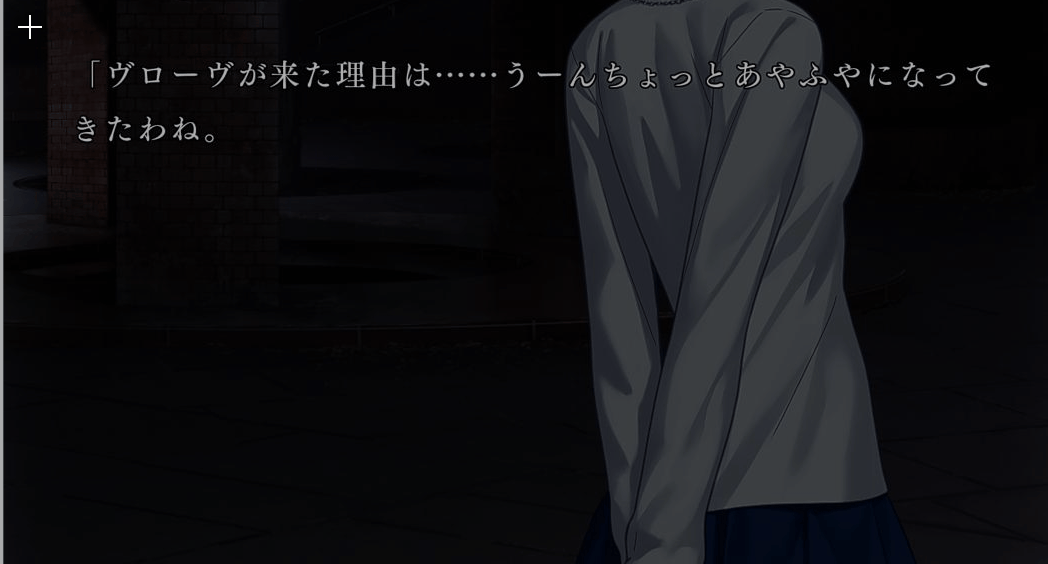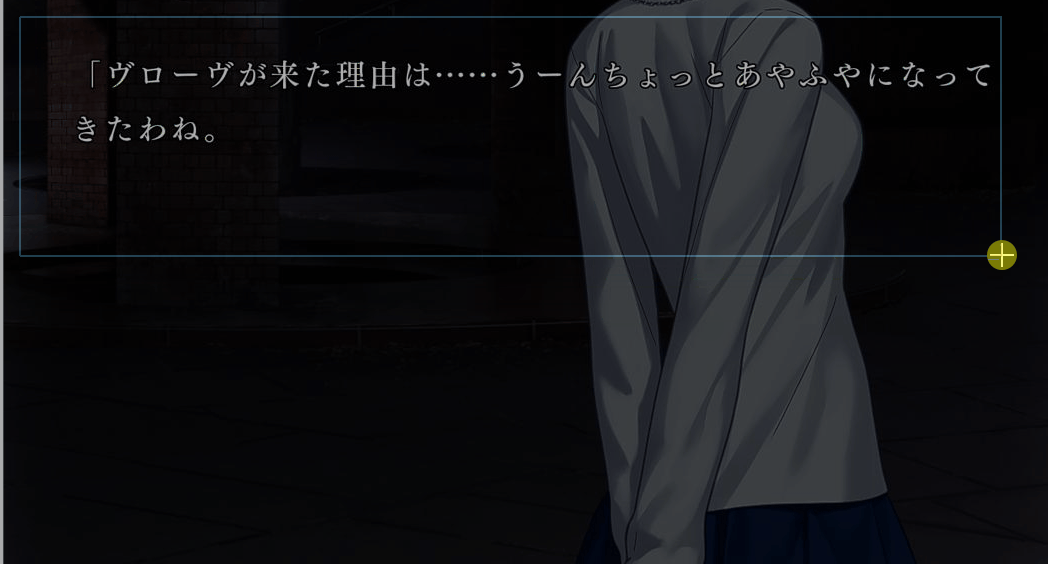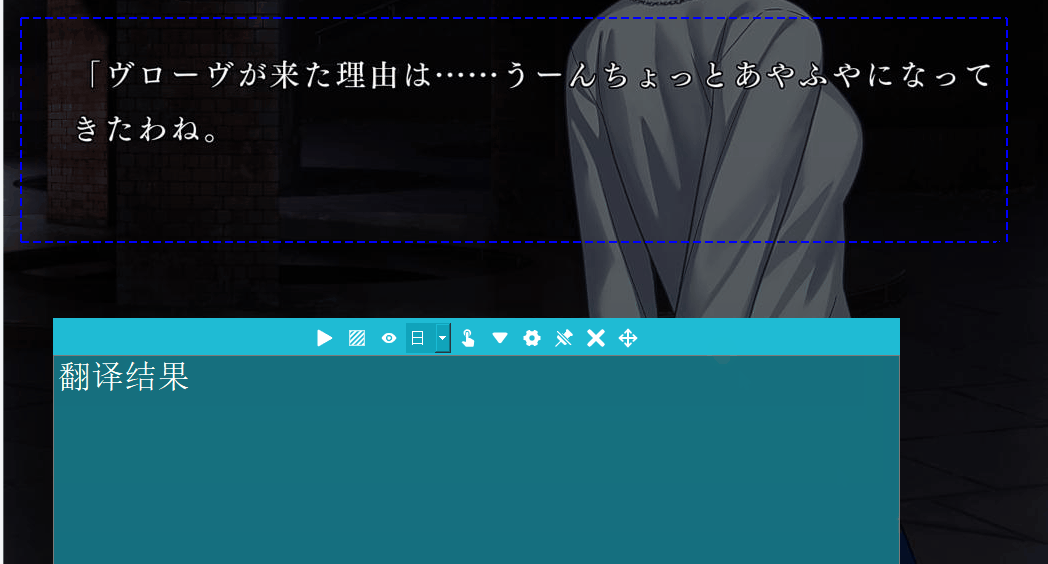
没想到这一步才是让我反复碰壁的。以前端思想,就是在按快捷键后监听鼠标的按压和松开事件,分别获取发生两个事件时的鼠标坐标就能确定要截图的矩形区域了。但是,python中鼠标事件的库pyhook的版本2因安全性问题用不了了,而pyhook3的python版本要求3.10以上,和PaddleOCR要求的版本冲突了,总之就是用不了。后面我想到一个办法,可以利用GUI轻松实现:在触发快捷键后,直接生成一个覆盖全屏并置顶的半透明窗口,通过点击这个矩形可以轻松获取当时的鼠标位置。测试效果如下:
以上,我们通过简单的测试确认了每一步的关键技术是可行的,接下来只用着重于将各个模块实现并组合在一起即可。
具体实现
见下期:[从零开始]用python制作识图翻译器·三。