摘要及声明
1:本文主要对捕获能力指标进行改进,并且利用改进的指标进行实证检验;
2:本文主要为理念的讲解,模型也是笔者自建,文中假设与观点是基于笔者对模型及数据的一孔之见,若有不同见解欢迎随时留言交流;
3:笔者原则是只做干货的分享,后续将更新更多内容,但工作学习之余的闲暇时间有限,更新速度慢还请谅解;
4:本文数据来自Choice金融数据库,模型实现基于python3.8;
目录
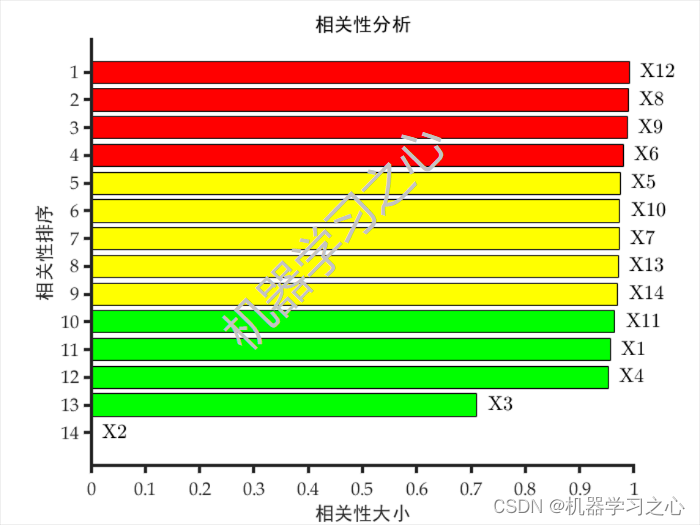
1. 捕获比
2. 捕获比的优缺点
2.1 优点
2.2 缺点
3. 改进方案
4. 实证检验
4.1 不符合传统CR计算要求的基金有多少
4.2 公募和私募捕获能力的区别
5. 代码实现
6. 总结
7. 往期精选
8. 引用
1. 捕获比
捕获比(Capture Ratio)是一种用来衡量组合在市场上行和下行时期收益获取能力的指标,这一指标被广泛应用于基金管理人业绩评估中,很多知名基金公司和基金评级机构(如晨星,贝莱德等)也会使用捕获比率以帮助投资者评估基金的业绩表现。从定义不难看出,捕获比按照市场涨跌划分了上行和下行两种状态(Pak, 2011),上行(下行)捕获比率,度量了市场在上涨(下跌)时基金收益相对基准收益的比值。Marlo和Stark认为捕获比可以有效衡量基金业绩,特定市场环境下捕获比的持续性较好且可以在随后的市场中识别出表现较优秀的基金。但是也有不少反驳的观点,例如Gottesman和Morey(2021)认为该指标的作用被明显高估了,捕获比率只是捕捉了业绩的β值,并且该指标在长周期上对管理人的预测能力不佳。
很多文章把捕获比的指标写的非常复杂,实际上就是个简单的分段函数:
记为管理人(Manager)的回报时间序列,
为比较基准(Benchmark)的回报时间序列;
1):上行捕获能力(Upside Capture, 记作UC)
2):下行捕获能力(Downside Capture, 记作DC)
3):捕获比(Capture Ratio, 记作CR)
不同的文章对R的计算方法不尽相同,笔者写的公式是直接取的平均数
,有的是算区间回报率,还有的用对数回报率,类似晨星在计算时还带上的%号,因此算出的结果数量级上也有不同。总之不管怎样都是函数的映射罢了,不会改变性质。
2. 捕获比的优缺点
捕获能力用一句简单的话来说就是看市场上涨阶段组合业绩相对于市场的表现,下跌阶段组合业绩相对市场的表现,如果比较基准上涨阶段组合涨得更多则UC>1,反之则DC>1;如果比较基准上涨阶段组合涨得更少则UC<1,反之则DC<1。因此一般情况下CR指标越大,则代表UC>DC,即组合相对于比较基准具有涨多跌少的特征。
2.1 优点
1)首先是十分便于理解,相比起回归和其它复杂的指标,该指标十分直白;
2)该指标分成上涨和下跌两种市场情形,相比于传统β的线性假设,捕获比更强调非线性特征,对组合业绩的刻画也更为细致,这一优点在评估强α能力的组合时尤为突出。如图一所示,当CR较大时,其曲线呈现较大凸度,每向上变动1个单位,
的变动呈现边际递增的趋势;
每向下变动1个单位,
的变动呈现边际递减的趋势,即涨多跌少。

图一:大凸度组合涨多跌少的特征
而根据线性回归得到的传统β假设组合在所有市场状态下都有且仅有一个线性相关关系。但需要注意的是当UC和DC都完全等于1时,组合表现大概率会直接呈现出线性特征,这时CR的作用并不会比β更好。
3):相比于拟合回归,CR的计算纯粹基于组合的回报情况,不需要考虑拟合效果带来的偏差,也不会陷入虚假回归的问题。
2.2 缺点
1):该指标最为诟病的缺点就是大量运用了除法,相除就意味着分母是不能为0的,且在负数和正数两个区间上可能会导致该指标呈现完全相反的特性,即CR要求组合与比较基准同涨同跌。例如图二,同样UC的两个组合A和B,但组合A的DC为正数,B的DC为负数,此时虽然组合A算出来的CR在数值上大于组合B,但组合B的表现实际上是要远好于组合A的,因为比较基准在下跌时(),同期的组合B却在上涨(
),且同期的组合B上涨的绝对值要大于比较基准下跌的绝对值(
);
虽然出现组合与比较基准反向涨跌的情况较为少见,但如果遇到类似组合AB这种情况,CR指标的判断条件(越大越好)就失效了。

图二:除法的运用会使得CR在不同值域上出现相反的结论
2):CR仅仅考虑了市场上涨和下跌两种状态,实际的组合表现可能因为止损等因素导致在多个区间内呈现更为复杂的特征,如果需要衡量更为细节的表现,例如尾部风险等,CR就显得相形见绌了;
3):CR只反应过去一段时间的总体情况,中途加杠杆等更为复杂的行为,可能会导致在对组合业绩进行横向比较时,CR的衡量效果出现偏差;
至于很多论文中检验的优缺点,这就是仁者见仁智者见智的了。笔者认为要放在论文实证检验的背景上具体看,CR的预测能力或者衡量业绩好坏的能力可能因为不同的市场和不同的时期产生变化。
3. 改进方案
CR最为诟病的缺点就是组合与比较基准的回报出现反向涨跌的情况,笔者改进的思路其实很简单,将涨跌幅映射到值域为大于0的函数上,且不能改变原有的数值大小关系,只要使得回报率无论在什么取值范围都为正数,那么在进行除法运算时就不会导致指标呈现出相反的特征。笔者选择自然指数函数进行映射, 自然指数函数有很多不错的特性,例如连续可导,导数还是它本身,值域也大于0,刚好满足需要。
于是原来的比率就可以写成:
1):上行捕获能力
2):下行捕获能力, 由于映射到为正的连续增函数区间,原先越小越好的下行捕获比就变成了越大越好,为了保持CR的特性不变,这里需要将原先DC指标的分子分母调换一下,取倒数;
3):捕获比
当然,还能继续带e进去化简,但是因为涉及到上行和下行两种情况,下标太多会让式子变得很难读懂,就这样干干净净的挺好。
4. 实证检验
由于文献几乎都是海外的实证研究,但笔者想对国内管理人,尤其是私募基金进行更加清晰的刻画。笔者希望通过实证检验分析两个问题:1)不符合传统CR计算要求的基金有多少;2)公募和私募的捕获能力是否有区别;
数据方面笔者选择了Choice金融数据库,为了统一口径,笔者均采用沪深300为比较基准进行计算。公募基金使用2006年至今所有的股票型开放式基金的日频净值数据,共计1023家;私募基金数据使用2009年至今市场分类为股票型的私募基金的月度净值数据, 共计71435支产品。因为笔者力求反应市场总体状况,因此并未刻意进行数据清洗,只剔除部分净值完整度过低,公募基金数据量短于半年,私募基金数据量短于1年的产品。
4.1 不符合传统CR计算要求的基金有多少
首先是不符合传统CR计算要求的基金有多少,根据表一的统计结果,仅有0.21%和0.31%的公募基金在UC和DC上出现异常,反而是私募的UC和DC异常率为10.36%和15.013%,异常指标均远高于公募。原因其实也很好理解,私募业绩本身就较强,跑赢市场的比例也更多,因此CR所要求的与基准同涨同跌似乎在私募上并不是很适用。
| 分类 | 指标 | 异常率(%) |
| 公募 | UC | 0.208 |
| DC | 0.312 | |
| 私募 | UC | 10.357 |
| DC | 15.013 |
表一:捕获指标异常值比例
4.2 公募和私募捕获能力的区别
下面所采用的指标均为笔者改进后的捕获能力指标。
1)公募基金统计情况
为了明确历史走势,采用250个交易日为移动窗口,取窗口内所有基金的捕获能力指标的均值,设置步长为60个交易日进行滚动,最后将历史捕获能力走势图和沪深300走势图进行比较得到图三。从历史走势上不难看出,捕获能力和市场呈现一定程度上的正相关性。

图三:公募基金捕获能力走势
从表二的相关性矩阵可以看出,公募基金的上行捕获和下行捕获能力之间呈现了较高的正相关关系,相关系数为0.7。简单来说就是市场上行时,上行捕获能力和下行捕获能力也同时上行。
| 相关性矩阵 | UC | DC | 指数净值 |
| UC | 1 | 0.704 | 0.199 |
| DC | 0.704 | 1 | 0.059 |
| 指数净值 | 0.199 | -0.059 | 1 |
表二:公募基金捕获能力及指数走势相关性矩阵
最后从相关统计指标看分布特点,由于采用了步长为60的移动平均,下面的历史数据样本量为68。从分布情况来看,公募基金的上行捕获能力并没有与下行捕获能力产生明显差异。另外,公募基金的上行捕获和下行捕获分布都非常集中,且均值与1并无显著差异。
| 指标 | UC | DC |
| 样本量 | 68 | 68 |
| 均值 | 0.997 | 0.996 |
| 标准差 | 0.003 | 0.002 |
| 最小值 | 0.991 | 0.991 |
| 25% | 0.996 | 0.995 |
| 50% | 0.997 | 0.997 |
| 75% | 0.999 | 0.998 |
| 最大值 | 1.010 | 1.000 |
表三:公募基金分布指标

图四:公募基金捕获能力分布频率图
1)私募基金统计情况
和公募统计方法类似,不过私募基金按3(月频数据)为移动窗口。将历史捕获能力走势图和沪深300走势图进行比较得到图五。从历史走势较难看出捕获能力和市场表现之间有明显关系。不过图上有个很有意思现象,自2023年8月份以来,私募的DC数据出现了非常明显的上翘,并且这是基于3万个大样本量统计的结果。笔者认为这种现象应该不是偶然,因为与之对应的是UC走势的下滑,UC下滑DC上升,最后得出的CR指标表现会变差,换句话说最近几个月私募的超额有非常明显的下滑,并且这种下滑主要是由于跌得比市场猛导致的。值得注意的是,2009年到2010年左右DC指标出现过一段很低的时期,笔者认为这段时期有些难以说明问题,毕竟有效的样本数量仅有十几家。但是从UC和DC变化大趋势来看,私募基金的超额能力确实有较为明显的下滑。
当然这仅仅是笔者从单一指标上看图说话,本期主要内容还是谈捕获能力,笔者就不在这点上进行过多展开了。

图五:私募基金捕获能力走势
与公募基金不同,私募基金的上行捕获和下行捕获能力并没有呈现较高的正相关关系,反而是上行捕获能力与市场走势呈现一定程度的负相关关系,相关系数为-0.31。市场上行时,上行捕获能力会出现一定程度的下行,简单来说就是市场涨的时候私募基金其实不一定能完全跟上。
| 相关性矩阵 | UC | DC | 指数净值 |
| UC | 1 | -0.077 | -0.313 |
| DC | -0.077 | 1 | 0.001 |
| 指数净值 | -0.313 | 0.001 | 1 |
表四:私募基金捕获能力及指数走势相关性矩阵
最后从分布情况来看,私募基金的上行捕获能力与下行捕获能力产生了一定的差异,下行捕获DC整体分布在一定程度上位于上行捕获能力UC的左边。最后,虽然私募基金的DC均值较小,但在90%的置信度水平下也并没有显著度的低于1。
| 指标 | UC | DC |
| 样本量 | 57 | 57 |
| 均值 | 0.995 | 0.960 |
| 标准差 | 0.028 | 0.037 |
| 最小值 | 0.934 | 0.818 |
| 25% | 0.976 | 0.951 |
| 50% | 0.9936 | 0.962 |
| 75% | 1.003 | 0.984 |
| 最大值 | 1.072 | 1.054 |
表五:私募基金分布指标

图六:私募基金捕获能力分布频率图
5. 代码实现
由于私募基金没有公开的数据,只能通过数据库获取。并且,虽然笔者使用的数据来源是Choice,但本期所需的数据量很大,即便是Choice的机构高权限账号也很容易就触及上限,更不用说万德这些了。笔者主要是通过下载的方式,将数据库数据导入到本地数据库,需要的时候直接从本地数据库调用。这样每次只需要维护一下,更新最新月份的数据就可以了。数据导入部分笔者就略过了,毕竟不是本期的重点。
先导入需要的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime加载完成的数据有两份,下面就用公募基金数据为例进行演示。公募基金的数据库比较全,包含到1999年的:
nav_table
000041.OF 000043.OF 000044.OF 000193.OF 000309.OF 000326.OF 000409.OF 000411.OF 000418.OF 000471.OF ... 850788.OF 850799.OF 900029.OF 900030.OF 920002.OF 920003.OF 920922.OF 920923.OF 970041.OF 970042.OF
nav_date
19991105 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
19991112 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
19991119 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
19991126 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
19991203 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
20231127 0.000328 0.000000 -0.000324 0.0 0.017480 -0.007805 -0.003337 0.010340 0.003601 -0.000470 ... 0.003505 0.003411 -0.001722 -0.001771 0.000123 0.001252 0.000063 0.001190 -0.000925 -0.000926
20231128 -0.000328 0.000834 0.001297 0.0 -0.002917 0.007962 0.001339 0.006579 0.004613 0.007049 ... 0.005746 0.005780 0.006684 0.006763 0.010020 0.005862 0.009999 0.005884 0.006364 0.006430
20231129 -0.006225 -0.003056 -0.001619 0.0 -0.002276 -0.008946 -0.006352 -0.000726 0.000510 -0.003266 ... -0.004257 -0.004169 -0.005890 -0.005947 -0.003043 -0.003508 -0.003032 -0.003544 -0.005921 -0.005928
20231130 -0.000110 -0.002229 -0.001946 0.0 -0.011404 -0.005282 -0.005047 0.000000 0.003060 0.002809 ... -0.005401 -0.005431 -0.001831 -0.001773 -0.002320 -0.004657 -0.002296 -0.004657 -0.002949 -0.003011
20231201 0.000000 0.000000 0.000000 0.0 0.016480 -0.002221 -0.007778 0.011628 -0.003050 -0.003735 ... 0.002715 0.002617 0.001295 0.001221 -0.002264 0.002395 -0.002302 0.002354 0.004698 0.004762
4586 rows × 1023 columns
hs_300 # 比较基准
trade_date close
20050104 982.7940
20050105 992.5640
20050106 983.1740
20050107 983.9580
20050110 993.8790
... ...
20231113 3579.4141
20231114 3582.0584
20231115 3607.2454
20231116 3572.3641
20231117 3568.0685
4586 rows × 1 columns进行传统的CR统计,看看有多少是不符合要求的,计算出即是表二数据:
abnormal_uc = []
abnormal_dc = []
tick_out = 0 # 记录不满足要求的净值数量
hs_300["pct_chg"] = hs_300["close"].pct_change() # 计算指数涨跌幅
for col in nav_table.columns:
data = pd.concat([hs_300["pct_chg"]/100, nav_table.loc[:, col]], axis = 1, join = "inner")
# data = data[(data.index > "20180101") & (data.index < "2020101")]
data.dropna(inplace=True)
if len(data) < 250: # 数据量少于250的剔除
tick_out += 1 # 剔除数量加1
else:
data.columns = ["指数", "基金"]
uc = data[data["指数"] > 0].apply(lambda x: x.mean(), axis = 0)
dc = data[data["指数"] <= 0].apply(lambda x: x.mean(), axis = 0)
uc = uc["基金"] / uc["指数"]
dc = dc["基金"] / dc["指数"]
if uc < 0:
abnormal_uc.append(col) # UC<0,不满足指标条件
elif dc < 0:
abnormal_dc.append(col) # DC<0,不满足指标条件
print(len(abnormal_uc) / (len(nav_table.columns)-tick_out))
print(len(abnormal_dc) / (len(nav_table.columns)-tick_out))接下来进行历史走势统计:
ratio = []
index_close = hs_300[["pct_chg"]]/100
for mover in range(250, len(hs_300.index), 60):
start = hs_300.index[mover - 250]
end = hs_300.index[mover]
nav_by_dates = nav_table[(nav_table.index >= start) & (nav_table.index <= end)]
nav_by_dates.dropna(axis = 1, how="all", inplace=True)
for i in range(len(nav_by_dates.columns)):
uc_lst = []
dc_lst = []
col = nav_by_dates.columns[i]
sub_nav = nav_by_dates[[col]].dropna()
print("{}完成{},第{}个\r".format(end, col, i), end = "")
if len(sub_nav) < 125:
pass
else:
start = sub_nav.index.values[0]
end = sub_nav.index.values[-1]
sub_data = index_close.loc[(hs_300.index >= start) & (hs_300.index <= end)]
sub_data.loc[:, col] = sub_nav[col]
if len(sub_data) / len(sub_data.dropna()) < 0.9:
print("净值完整度低", col)
else:
sub_data = sub_data.dropna()
sub_data = np.exp(sub_data) # 采用函数映射
sub_data.columns = ["指数", "基金"]
uc = sub_data[sub_data["指数"] > 1].apply(lambda x: x.mean(), axis = 0) # 映射后原来的0会变成1,因此这里把1作为判断条件
dc = sub_data[sub_data["指数"] <= 1].apply(lambda x: x.mean(), axis = 0) # 映射后原来的0会变成1
uc = uc["基金"] / uc["指数"]
dc = dc["指数"] / dc["基金"] # 这是映射修改的新公式
uc_lst.append(col)
dc_lst.append(col)
ratio.append({"date":hs_300.index[mover],"num_fund":[i], "uc": uc.mean(), "dc": dc.mean()})
print("\n")将数据与沪深300表格合并,算算净值:
capture_result = pd.DataFrame(ratio)
capture_result.set_index("date", inplace=True)
capture_result["index"] = hs_300["close"]
capture_result["index_nav"] = (1+capture_result["index"].pct_change()).cumprod()
capture_result = capture_result.dropna()画出走势图,这里用了一个双轴图就可以得到图三:
fig = plt.figure(figsize=(12,5))
ax1 = fig.add_subplot(111)
ax1.plot(capture_result.index.values, capture_result["uc"].values, label = "uc")
ax1.plot(capture_result.index.values, capture_result["dc"].values, label = "dc")
plt.xlabel("日期", fontsize=15)
plt.ylabel("比率", fontsize=15)
plt.legend(loc="upper right", fontsize=15)
ax2 = ax1.twinx()
ax2.plot(capture_result.index.values, capture_result["index_nav"].values, label = "指数(右轴)", color = "r", linestyle="--")
plt.ylabel("净值", fontsize=15)
plt.xticks(capture_result.index.values[::5])
plt.legend(fontsize=15)
plt.show()
进行统计指标的输出:
print(capture_result.corr())
print(capture_result["dc"].describe())
print(capture_result["uc"].describe())最后是联合分布图,运行即是图四:
sns.distplot(capture_result["uc"], label = "UC")
sns.distplot(capture_result["dc"], label = "DC")
plt.xlabel("比率")
plt.legend()
plt.show()私募基金的代码解构也是一样的,只是需要按月度数据进行匹配,这里就不作讲解了。
6. 总结
本文通过函数映射的方式对捕获指标进行改进,改进后的指标具有更好的可比性。通过实证检验发现,公募基金的上行捕获能力和下行捕获能力有较高的相关性,这意味着随着上行捕获能力提升,其下行捕获能力则会下降,于是对CR的提升造成较大的限制。私募基金上行捕获能力和下行捕获能力的相关性则非常低,但市场上行时,私募基金上行捕获能力会出现一定程度的下行,也就是说市场涨的时候私募基金其实不一定能完全跟上。从历史统计来看,不管是公募还是私募,其捕获能力都没有显著的不等于1。从数据分布来看,公募基金的上行捕获和下行捕获几乎完全重合,但私募基金则有着更好的下行捕获表现,这意味着私募的超额很大一部分因素来自于跌得比市场少。最后,从该指标的历史走势上看,私募行业的超额是出现一定程度下滑的。
本文对指标的改进是存在一定缺陷的,首先自然指数函数本身就具有一定的凸度,映射后的数据天然带有一定的凸性。其次,本文只对截面数据的均值进行了历史走势的分析比较,并没有进一步分析截面数据的分布特征。
7. 往期精选
| 往期精选 | ||
| 系列 | 文章传送门 | 实现方式 |
| 金融杂谈 | 多目标最优化的资产配置 | Python |
| 基于均值方差最优化资产配置的模型特性 | Python | |
| 基金市场的冷热传递什么信号? | Python | |
| 券商金股哪家强——信息比率 | Python | |
| 从指数构建原理看待A股的三千点魔咒 | Python | |
| 决策树学习基金持仓并识别公司风格类型 | R | |
| 垃圾公司对回报率计算的影响几何 | Python | |
| 市场预测美联储加息的有效性几何 | Python | |
| 市场风险分析 | Python | |
8. 引用
Gottesman, A. & Morey, M. 2021. "What Do Capture Ratios Really Capture in Mutual Fund Performance?". The Journal of Investing. https://www.pm-research.com/content/iijinvest/30/6/99
Marlo, T. & Stark, J. 2019. "Capture Ratios: Seizing Market Gains, Avoiding Losses, and Attracting Investors’ Funds". The Journal of Investing. https://www.scilit.net/publications/5dc4d5c8f449b1fee3ba2e04433c83d0
Pak, E. 2011. "Introducing Upside and Downside Capture Ratios". Morningstar. https://www.morningstar.com/articles/374386/introducing-upside-and-downside-capture-ratios