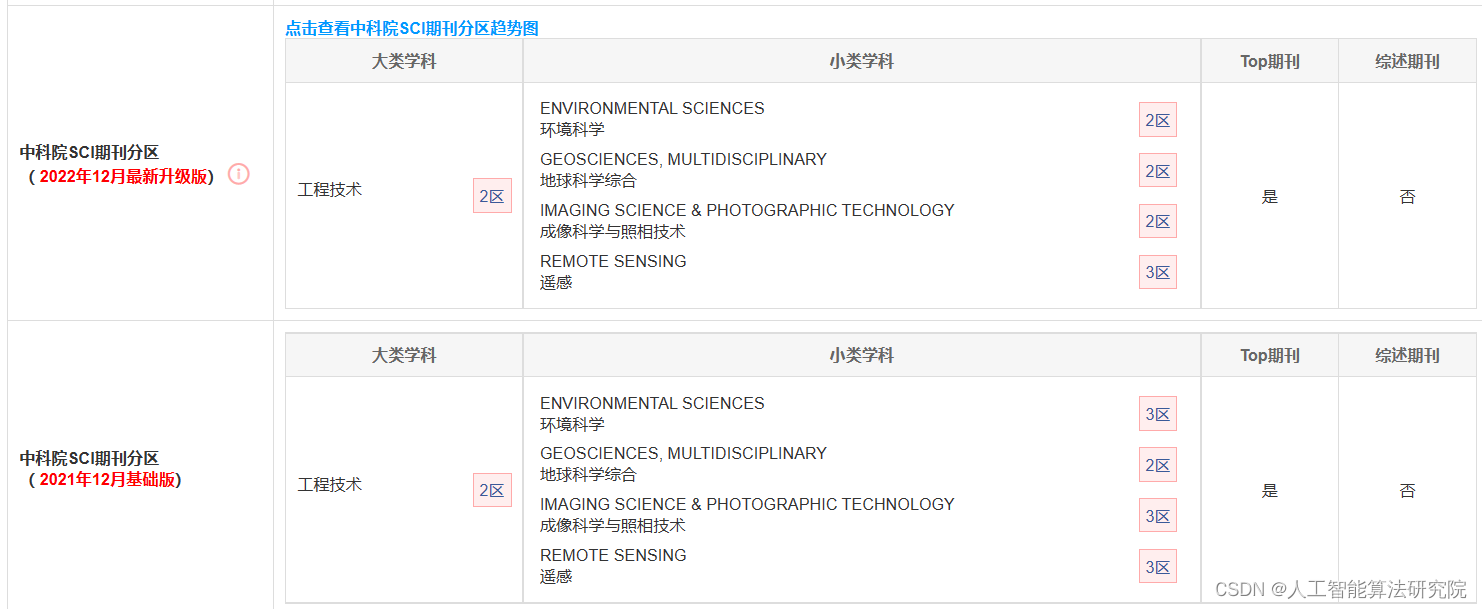
目录
实现思路
索引模块
预处理
对文档进行分词
搜索模块
实现思路
索引构建模块 + 搜索模块 + 数据库模块

索引模块
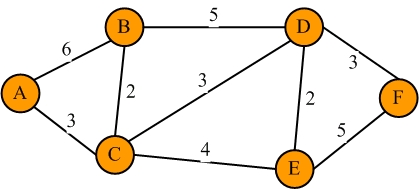
对于搜索一个东西,我们很自然的能想到遍历去查找。比如我要查找一本书叫 《红楼梦》,那么我直接在所有结果中进行遍历查找,当我们找到书名为《红楼梦》的结果时,就代表我们查找到了。但是这样有一个很致命的缺点就是当数据量很大的时候,查找的效率实在太过低下。这种遍历搜索的时间复杂度为O(n),对于搜索引擎这种实时性要求很高的工具来说太慢了
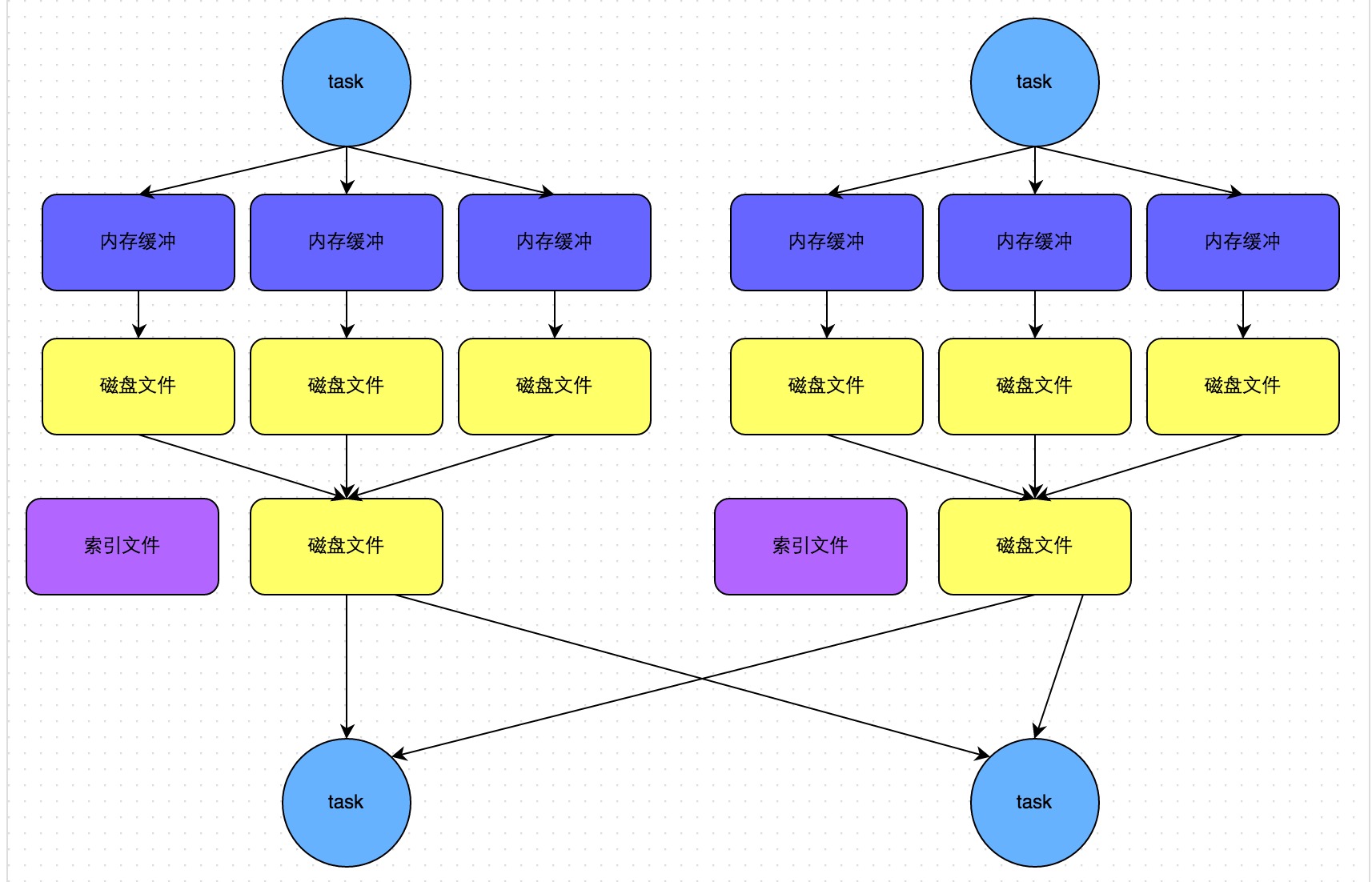
因此,标准的解决方案是使用倒排索引和正排索引。正排索引就是一个资源 id 与资源内容的映射。由于我们是针对jdk的文档做一个搜索,所以是文档 id 与 文档的映射。我们维护一个 key -value 结构,如图所示:

倒排索引就是告诉我们文中的一个词出现在哪些文章中,文章id是多少。我们维护的也是一个key-value结构,key是一个词,value是一个集合,集合中是包含这个词的文章id,还会包含一些其他东西,由于我们要对搜索结果进行排序,还需要加入权重属性。如图所示

然后我们将计算出来的正排索引和倒排索引保存到数据库中,当我们在前端浏览器界面输入一个关键词时,就可以先通过倒排索引得到docId,再根据docId得到相应的文档内容,最终显示再浏览器界面上。
预处理
扫描根目录下的所有 html 文件,分别拿到每个文件中的 title ,content 和 path 。由于 html 文件中除了我们想要的内容还包含了很多标签,例如 script 标签,html 标签等,因此我们需要按照一定的规则将这些标签全部去除,只保留我们想要的文字信息。

例如上图就有 div 标签 ,code 标签等。
标签都是成对出现的,形如<...>...</...>。根据这个规律,我们可以使用正则表达式进行匹配和替换。
对文档进行分词
在搜索引擎中,对文档进行分词是很重要的,因为构建正排索引和倒排索引首先需要拿到一个单词。分词是一个很复杂的工作,我们这里采用第三方库去进行分词,虽然准确度可能有所欠缺,但是整体上还是能满足要求的。
在对html文档进行了预处理的基础上,采用ansj进行分词,需要在pom.xml中引入依赖,依赖如下:
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>分词库会分析语句的词性,内容等最终得到一个结果集。得到了结果集之后我们就可以对当前文档进行统计,得到 单词集 和 单词出现数量的集合。基于上面两个集合,我们就可以根据权重计算公式计算出当前文档中所有单词的权重,最终得到一个 Map (单词 -> 权重)最后就可以插入数据库了。
搜索模块
前端界面提供一个搜索框,在搜索框中输入搜索词。后端对输入进行分词处理,如果只有一个词,那么可以直接执行数据库查询操作,将查询结果以 JSON 格式 返回给前端,前端使用 thmeleaf 模板能够方便的显示查询结果列表。如果有多个查询词,需要对每个词进行数据库的查询操作再进行聚合操作,再计算一遍整体的权重。
针对搜索,我们可以观察到,如果我们直接进行线性的查找,性能会很差。当数量级达到百万时,O(n) 的时间复杂度是不可接受的,尤其是对于搜索引擎这种实时性要求很高的工具。我们可以使用索引来对查询进行优化。即用一定的空间换时间。我们只需再数据库中构建一次索引,之后的查询就可以以O(logn)的时间复杂度进行查询。将原来的百万级别讲到十位数级别。
在倒排索引中,词 和 权重 都可以被索引优化。因为我们有两个需求即 找到包含查询词的文档 和 对所有包含查询词的文档根据权重进行排序。在索引优化之后,我们避免了每次查询都进行遍历查找和排序从而提高性能。