druid支持过滤器,可以在获取连接或者调用连接对象的方法时,先调用过滤器,之后再执行底层方法,比如DruidDataSource的getConnection()方法:
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
init();
//先执行过滤器
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}
除了在连接对象之上加过滤器,还可以对ResultSet、Statement、PreparedStatement、CallableStatement、ResultSetMetaData对象上加过滤器。通过FilterChainImpl类的方法前缀可以很明显的看出哪些可以加过滤器的对象。
目录
- 一、如何设置过滤器
- 二、druid提供了哪些过滤器
- 1、StatFilter
- 2、EncodingConvertFilter
- 3、ConfigFilter
- 4、日志过滤器
- 三、自定义过滤器
一、如何设置过滤器
我们可以在环境变量或者启动参数(通过-D设置)中设置参数“druid.filters”的值,格式为“过滤器名A,过滤器名B,…”(中间以逗号分隔),除了通过参数“druid.filters”设置之外,还可以在连接url中通过“filters=”设置过滤器,值的格式也是一样的。
DruidDataSource启动的时候,会读取参数值,然后进行解析得到过滤器名,之后根据名字查找过滤器。那么过滤器名和过滤器之间的对应关系在哪维护?我们通过FilterManager.loadFilterConfig()方法看到,druid启动的时候,加载了META-INF/druid-filter.properties文件,这个文件里面就存放了过滤器名与过滤器之间的对应关系。该文件的内容如下图:
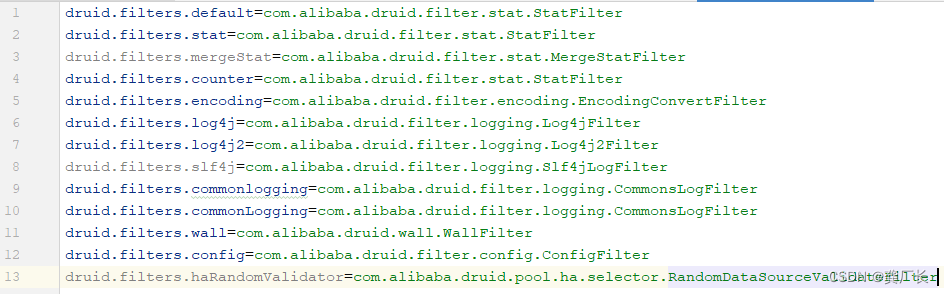
上图中druid.filters后面的就是过滤器名,等号之后的内容就是过滤器的全限定类名。启动时,FilterManager首先解析该文件,将名字与类名放入一个Map对象中,之后druid解析我们设置的过滤器参数,得到过滤器名字,然后根据名字从Map中得到类名,之后druid创建过滤器对象,最后将过滤器对象放入到DruidAbstractDataSource.filters集合中。
当调用一些对象的方法时,druid创建FilterChainImpl对象,该对象持有所有的过滤器,FilterChainImpl会先遍历所有的过滤器,最后调用底层方法,比如上面的getConnection()方法。
二、druid提供了哪些过滤器
通过上面的图,我们就可以看到druid提供了哪些过滤器。下面对部分过滤器进行介绍。
1、StatFilter
该过滤器用于统计监控信息,比如可以统计事务提交次数,SQL语句执行次数,总SQL执行时间等。
除了统计功能之外,它还具备慢SQL监控功能,这要求我们设置slowSqlMillis和logSlowSql两个属性,slowSqlMillis表示毫秒数,如果SQL的执行时间大于slowSqlMillis,则表示SQL执行慢,logSlowSql表示是否打印慢SQL,默认是false,不打印。执行SQL的时候,StatFilter计算SQL的执行时间,如果时间大于slowSqlMillis并且logSlowSql=true,那么StatFilter会将SQL语句、参数及执行时间一起打印出来,日志以“slow sql ”开头。
其他信息大家可以参考文档:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
2、EncodingConvertFilter
该过滤器用于对SQL语句、数据库返回值进行编码转换。我们可以设置属性“ali.charset.converter”的值,当执行SQL语句时,该过滤器将SQL语句进行编码,编码为指定的格式,数据库返回值也是一样,不过这要求返回值必须是String或者Reader对象。
3、ConfigFilter
从名字上能够看出来,该过滤器与配置有关。其作用有:
- 从配置文件中读取配置
- 从远程http文件中读取配置
- 为数据库密码提供加密功能
下面详细分析下该类的init()方法,当druid加载完过滤器对象之后,就会调用各个过滤器的init()方法,这就意味着当执行init()方法时,druid还没有创建数据库连接:
public void init(DataSourceProxy dataSourceProxy) {
DruidDataSource dataSource = (DruidDataSource) dataSourceProxy;
Properties connectionProperties = dataSource.getConnectProperties();
//获得属性druid.config.file的值,该属性值表示配置文件的位置,
//该值如果以file://开头,表示文件从本地磁盘加载;
//如果以http://或者https://开头,表示从网路加载;
//如果以classpath:开头,表示从类路径加载;
//如果什么都不配置,那么表示从本地磁盘加载
Properties configFileProperties = loadPropertyFromConfigFile(connectionProperties);
// 判断是否需要解密,如果需要就进行解密行动
//获取config.decrypt属性的值,如果配置了config.decrypt=true,那么表示密码需要解密
boolean decrypt = isDecrypt(connectionProperties, configFileProperties);
if (configFileProperties == null) {
if (decrypt) {
decrypt(dataSource, null);//对密码解密
}
return;
}
if (decrypt) {
decrypt(dataSource, configFileProperties);
}
try {
//将密码和配置设置到数据源对象中,之后数据源对象就可以创建数据库连接了
DruidDataSourceFactory.config(dataSource, configFileProperties);
} catch (SQLException e) {
throw new IllegalArgumentException("Config DataSource error.", e);
}
}
其他信息大家可以参考文档:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter
4、日志过滤器
druid提供了四种日志过滤器,它们都继承自LogFilter,这四个过滤器分别是Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter,从过滤器名字上就可以看出,它们分别对应了不同的日志工具。
该类的作用是:
- 打印执行的SQL语句;
- 打印SQL语句的执行时间。
其他信息大家可以参考文档:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_LogFilter
三、自定义过滤器
我们也可以自定义过滤器。
一般过滤器都是继承自FilterAdapter,之后改写其中的部分方法,然后将过滤器名与类名配置到类路径下文件META-INF/druid-filter.properties中,之后在参数“druid.filters”上增加我们自定义的过滤器名就可以了。