1.简介
HashMap ,是一种散列表,用于存储 key-value 键值对的数据结构,一般翻译为“哈希表”,提供平均时间复杂度为 O(1) 的、基于 key 级别的 get/put 等操作。
2.哈希表结构
哈希表结构为数组,链表和红黑树。如图
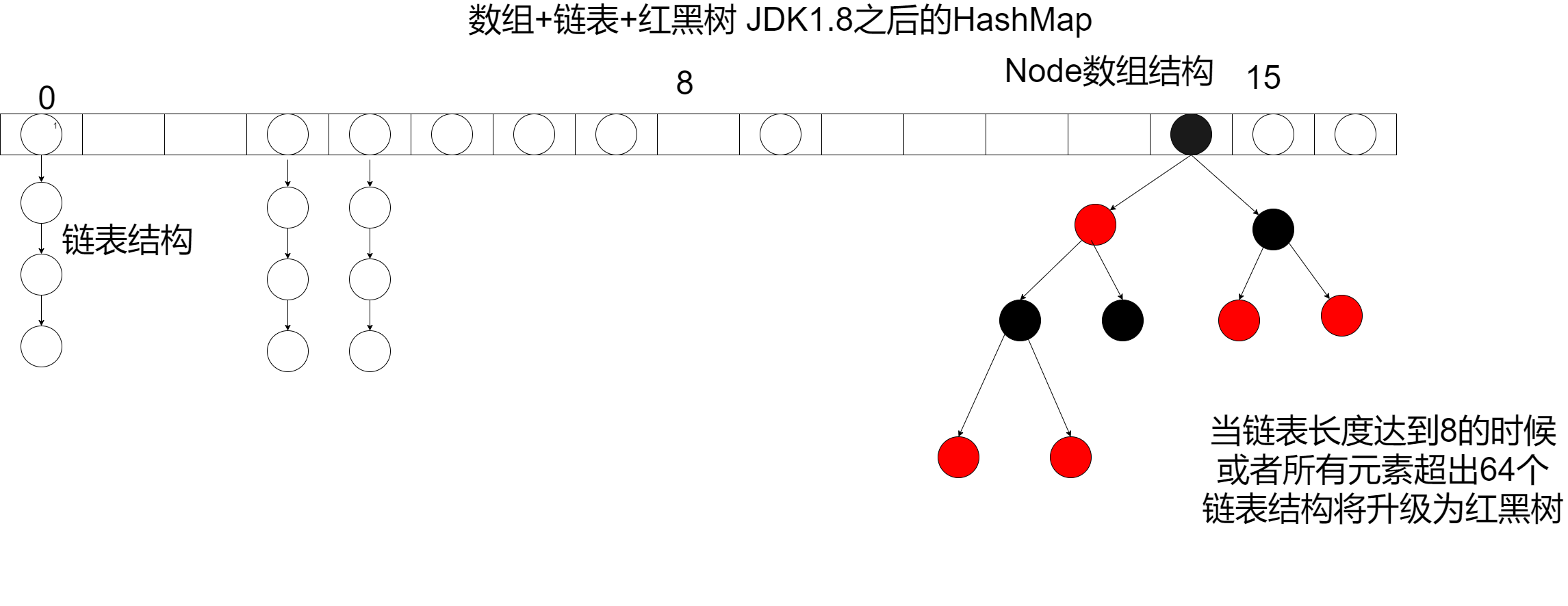
哈希表渴望实现O1的查找时间复杂度,因此采用数组作为基础结构,通过哈希函数,计算key的哈希值,哈希表指示存储数组的下标,但是会出现不同key对应同一个哈希值,则称作哈希碰撞,采取拉链法解决,将同一下标的所有节点链接为链表。但是当链表长度过长,hash表便也失去了平均o1的特性。因此在一定条件下,链表将树化为红黑树,jdk1.7之前只有拉链,1.8加入红黑树特性。
3.什么是Hash
Hash也称散列、哈希,对应的英文都是Hash。基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。
- 1.从Hash值不可以反向推导出原始数据
- 2.输入数据的微小变化会得到完全不同的Hash值相同的数据一定可以得到相同的值
- 3.哈希算法的执行效率要高效,长的文本也能快速计算Hash值
- 4.Hash算法的冲突概率要小
由于Hash原理就是将输入空间映射成Hash空间,而Hash空间远远小于输入空间,根据抽屉原理,一定存在不同输出有相同的映射
抽屉原理: 桌子上有10个苹果,将其放在9个抽屉里面,那必有一个抽屉不少于2个苹果
4.HashMap源码理解
HashMap结构
内部类
-
1)Node:存储基本的哈希值和键值对
Node结构static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; .... } -
2)KeySet:所有Key的哈希集合
与node数组共享key,对key的操作是互相影响的。并且只支持删除操作
-
3)Values: :所有value的哈希集合,同理keySet
-
4)EntrySet:所有node的哈希集合,同理keySet
-
5)HashIterator: 迭代器,遍历node使用
-
6)KeyIterator: 迭代器实现
-
7)EntryIterator: 迭代器实现
-
8)ValueIterator: 迭代器实现
-
9)HashMapSpiterator :切割node数组,供并行使用
-
10)KeySpiterator:切割器实现
-
11)ValueSpiterator:切割器实现
-
12)EntrySpiterator: 切割器实现
-
13)TreeNode:红黑树node节点
成员变量
//默认初始化容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大的数组容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认负载系数
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表长度树化为红黑树的阈值
static final int TREEIFY_THRESHOLD = 8;
//红黑树退化为链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
//最小树化的节点数量阈值
static final int MIN_TREEIFY_CAPACITY = 64;
//存放节点的数组,懒加载创建
transient Node<K,V>[] table;
//key_value哈希集合,懒加载创建
transient Set<Map.Entry<K,V>> entrySet;
//数组实际节点数量
transient int size;
//node节点的增加删除次数,不包括更新
transient int modCount;
//下次进行扩容的阈值 容量*负载因子
int threshold;
//负载因子
final float loadFactor;
成员方法,挑体现核心思想的方法
-
初始化

-
查找node
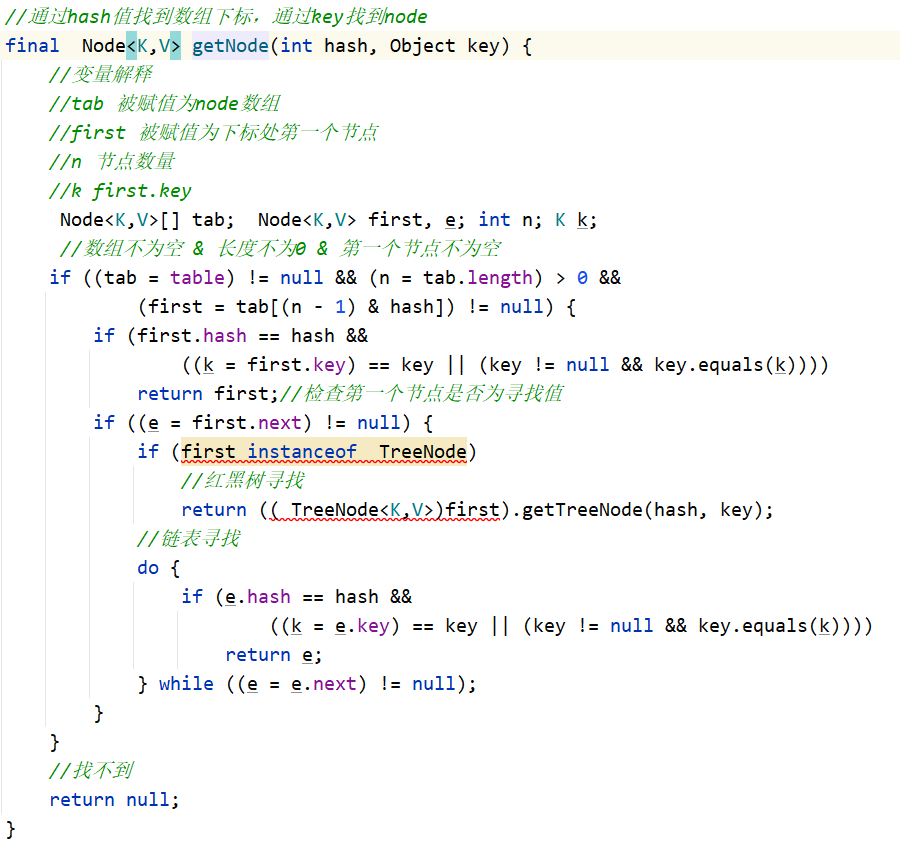
-
插入/更新
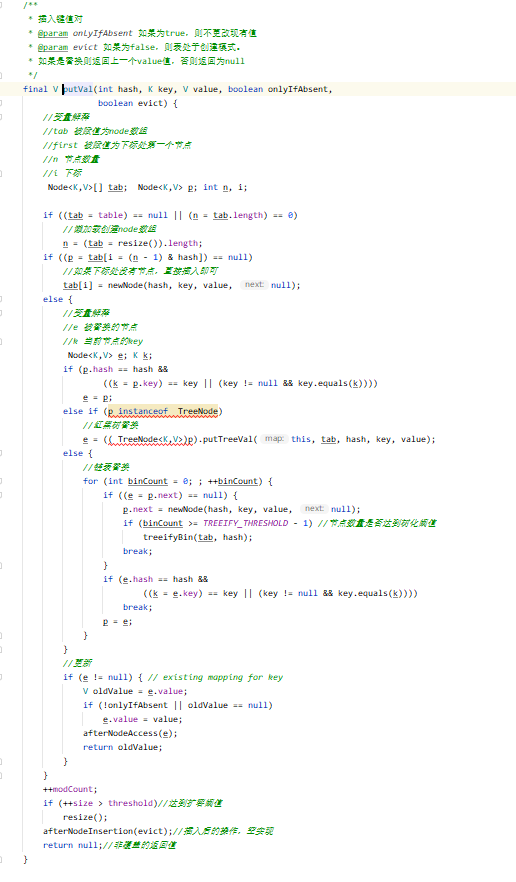
-
删除
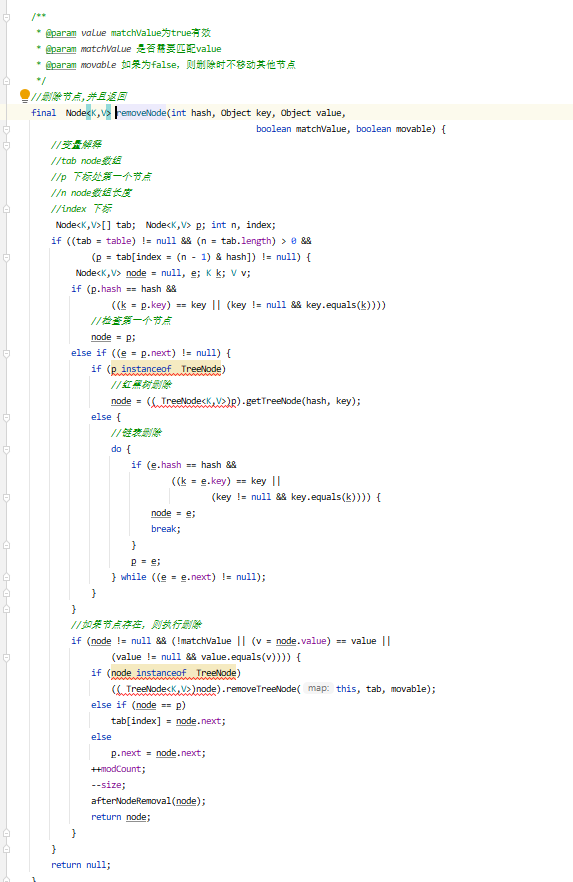
下面是我阅读源码添加的注释,注释待补充完整
package my;
import java.io.IOException;
import java.io.InvalidObjectException;
import java.io.Serializable;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Consumer;
import java.util.function.Function;
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
//默认初始化容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大的数组容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认负载系数
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表长度树化为红黑树的阈值
static final int TREEIFY_THRESHOLD = 8;
//红黑树退化为链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
//最小树化的节点数量阈值
static final int MIN_TREEIFY_CAPACITY = 64;
//基础节点 存放key,value,hash,下一个node指针
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
//静态方法
//计算key的哈希值
/*
how: key的hash值的前16位异或后16位
why: 通过混合哈希码的高位和低位,使得hash值更加分散,这种做法称作扰动
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* Returns x's Class if it is of the form "class C implements
* Comparable<C>", else null.
*/
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
/**
* Returns k.compareTo(x) if x matches kc (k's screened comparable
* class), else 0.
*/
@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
//do: 获取一个恰好大于输入值的2的次方数,在小于最大数组容量下
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
/* ---------------- 成员 -------------- */
//存放节点的数组,懒加载创建
transient Node<K,V>[] table;
//key_value哈希集合,懒加载创建
transient Set<Map.Entry<K,V>> entrySet;
//数组实际节点数量
transient int size;
//node节点的增加删除次数,不包括更新
transient int modCount;
//下次进行扩容的阈值 容量*负载因子
int threshold;
//负载因子
final float loadFactor;
/* ---------------- 对外操作 -------------- */
//输出初始化容量,负载因子进行 初始化 容量,负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)//容量非法
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)//最大容量
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))//负载因子非法
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);//2的次方容量
}
//调用 HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//初始化负载因子为0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 所有其他的值都为默认
}
//创建特定的map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
//实现Map.putAll和Map构造函数
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
//返回node节点数量
public int size() {
return size;
}
//node节点是否等于0
public boolean isEmpty() {
return size == 0;
}
//通过key获取value,如果不存在则返回为空,调用getNode(int hash, Object key)实现
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//通过hash值找到数组下标,通过key找到node
final Node<K,V> getNode(int hash, Object key) {
//变量解释
//tab 被赋值为node数组
//first 被赋值为下标处第一个节点
//n 节点数量
//k first.key
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//数组不为空 & 长度不为0 & 第一个节点不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;//检查第一个节点是否为寻找值
if ((e = first.next) != null) {
if (first instanceof TreeNode)
//红黑树寻找
return (( TreeNode<K,V>)first).getTreeNode(hash, key);
//链表寻找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//找不到
return null;
}
//是否包含key
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
//插入键值对。如果是替换则返回上一个value值,否则返回为null
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* 插入键值对
* @param onlyIfAbsent 如果为true,则不更改现有值
* @param evict 如果为false,则表处于创建模式。
* 如果是替换则返回上一个value值,否则返回为null
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//变量解释
//tab 被赋值为node数组
//first 被赋值为下标处第一个节点
//n 节点数量
//i 下标
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//懒加载创建node数组
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//如果下标处没有节点,直接插入即可
tab[i] = newNode(hash, key, value, null);
else {
//变量解释
//e 被替换的节点
//k 当前节点的key
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//红黑树替换
e = (( TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//链表替换
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) //节点数量是否达到树化阈值
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//更新
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//达到扩容阈值
resize();
afterNodeInsertion(evict);//插入后的操作,空实现
return null;//非覆盖的返回值
}
//初始化节点数组或者扩容数组使得新数组容量的两倍(容量,阈值)
final Node<K,V>[] resize() {
//变量解释
//oldTab 被赋值为node原数组
//oldCap 被赋值为原容量
//oldThr 原扩容阈值
//newCap 新容量 newThr 新扩容阈值
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//非空数组
if (oldCap >= MAXIMUM_CAPACITY) {
//如果容量已经最大,那么设置阈值为int的最大值后不再处理
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//容量增大为原来的两倍,如果原来的容量已经大于默认容量(16),那么扩容阈值也增大原来的两倍
newThr = oldThr << 1;
}
//空数组
else if (oldThr > 0) //容量变为原来的扩容阈值
newCap = oldThr;
else {
//阈值为0表示使用默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//对应352
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = ( Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//遍历每一个桶
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;//GC
if (e.next == null)
//一个节点直接计算hash值域插入
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//红黑树扩容
(( TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//链表扩容
//由于hash计算机制,同一下标的节点在新节点hash计算得到结果的下标 只可能保持或者移动向右移动扩大原容量位移
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
//hash对应桶树化
final void treeifyBin( Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
//map合并
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
//删除
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* @param value matchValue为true有效
* @param matchValue 是否需要匹配value
* @param movable 如果为false,则删除时不移动其他节点
*/
//删除节点,并且返回
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
//变量解释
//tab node数组
//p 下标处第一个节点
//n node数组长度
//index 下标
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//检查第一个节点
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
//红黑树删除
node = (( TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//链表删除
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//如果节点存在,则执行删除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
(( TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
//清空所有节点
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
//检查map中是否有value
//没看到红黑树的遍历为啥?
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
//返回所有key
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
//可以对key进行删除,不支持增加。map集合进行增加删除node时,迭代操作将不可执行,显示为未定义
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
//todo 为什么这个clear这样做
public final void clear() { this.clear(); }
//返回key的迭代器
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
//todo Spliterator
public final Spliterator<K> spliterator() {
return new KeySpliterator<>( this, 0, -1, 0, 0);
}
//迭代遍历
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
//检测map是否修改了map的keyset集合
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
//返回所有value集合
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new Values();
values = vs;
}
return vs;
}
//如果有任意节点的value值在迭代时进行修改,那么迭代将失败
final class Values extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { this.clear(); }
public final Iterator<V> iterator() { return new ValueIterator(); }
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return new ValueSpliterator<>( this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
//返回所有node的set集合,懒加载
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return new EntrySpliterator<>( this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
// jdk8重写方法
//获取某个key的值,无则返回默认值
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}
//插入值,需要key值不存在,也就是不进行覆盖操作
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}
//删除节点,key-value都匹配
@Override
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
//覆盖key-value都匹配
@Override
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
//空实现
afterNodeAccess(e);
return true;
}
return false;
}
//覆盖匹配key
@Override
public V replace(K key, V value) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;
e.value = value;
//空实现
afterNodeAccess(e);
return oldValue;
}
return null;
}
//如果 key 对应的 value 不存在,则使用获取 mappingFunction 重新计算后的值,并保存为该 key 的 value,否则返回 value。
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
if (mappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = ( TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
V oldValue;
if (old != null && (oldValue = old.value) != null) {
afterNodeAccess(old);
return oldValue;
}
}
V v = mappingFunction.apply(key);
if (v == null) {
return null;
} else if (old != null) {
old.value = v;
afterNodeAccess(old);
return v;
}
else if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
return v;
}
//如果 key 对应的 value 不存在,则返回该 null,如果存在,则返回通过 remappingFunction 重新计算后的值。
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
Node<K,V> e; V oldValue;
int hash = hash(key);
if ((e = getNode(hash, key)) != null &&
(oldValue = e.value) != null) {
V v = remappingFunction.apply(key, oldValue);
if (v != null) {
e.value = v;
afterNodeAccess(e);
return v;
}
else
removeNode(hash, key, null, false, true);
}
return null;
}
//对 hashMap 中指定 key 的值进行重新计算。
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = ( TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
V oldValue = (old == null) ? null : old.value;
V v = remappingFunction.apply(key, oldValue);
if (old != null) {
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
}
else if (v != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return v;
}
//先判断指定的 key 是否存在,如果不存在,则添加键值对到 hashMap 中。
//如果 key 对应的 value 不存在,则返回该 value 值,如果存在,则返回通过 remappingFunction 重新计算后的值。
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (value == null)
throw new NullPointerException();
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = ( TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
if (old != null) {
V v;
if (old.value != null)
v = remappingFunction.apply(old.value, value);
else
v = value;
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
return v;
}
if (value != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, value);
else {
tab[i] = newNode(hash, key, value, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return value;
}
//迭代
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
//全部替换,使用传入的函数
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Node<K,V>[] tab;
if (function == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next) {
e.value = function.apply(e.key, e.value);
}
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
/* ----------------------克隆和序列化---------------------------- */
//浅克隆,键值对没有被可能,todo 仍然共享数据
@SuppressWarnings("unchecked")
@Override
public Object clone() {
java.util.HashMap<K,V> result;
try {
result = (java.util.HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
result.reinitialize();
result.putMapEntries(this, false);
return result;
}
//序列化HashSet时也使用这些方法
final float loadFactor() { return loadFactor; }
final int capacity() {
return (table != null) ? table.length :
(threshold > 0) ? threshold :
DEFAULT_INITIAL_CAPACITY;
}
//将HashMap实例的状态保存到流中(即序列化)。无顺序
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
//阈值,负载因子和任何内容
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}
//从流中重新构造HashMap实例(即反序列化)。
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException {
//阈值,负载因子和任何内容
s.defaultReadObject();
reinitialize();
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
s.readInt(); // Read and ignore number of buckets
int mappings = s.readInt(); // Read number of mappings (size)
if (mappings < 0)
throw new InvalidObjectException("Illegal mappings count: " +
mappings);
else if (mappings > 0) { // (if zero, use defaults)
// Size the table using given load factor only if within
// range of 0.25...4.0
float lf = Math.min(Math.max(0.25f, loadFactor), 4.0f);
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = ( Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}
/* ------------------------迭代器------------------------- */
abstract class HashIterator {
Node<K,V> next; // 下一个实体
Node<K,V> current; // 现在的实体
int expectedModCount; // 用于快速失败
int index; // 当前下标
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
/* ---------------------切割卡槽,并行使用----------------------------- */
// 切割器
static class HashMapSpliterator<K,V> {
final java.util.HashMap<K,V> map;
Node<K,V> current; // current node
int index; // current index, modified on advance/split
int fence; // one past last index
int est; // size estimate
int expectedModCount; // for comodification checks
HashMapSpliterator(java.util.HashMap<K,V> m, int origin,
int fence, int est,
int expectedModCount) {
this.map = m;
this.index = origin;
this.fence = fence;
this.est = est;
this.expectedModCount = expectedModCount;
}
final int getFence() { // initialize fence and size on first use
int hi;
if ((hi = fence) < 0) {
java.util.HashMap<K,V> m = map;
est = m.size;
expectedModCount = m.modCount;
Node<K,V>[] tab = m.table;
hi = fence = (tab == null) ? 0 : tab.length;
}
return hi;
}
public final long estimateSize() {
getFence(); // force init
return (long) est;
}
}
static final class KeySpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<K> {
KeySpliterator(java.util.HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public KeySpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new KeySpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super K> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
java.util.HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p.key);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super K> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
K k = current.key;
current = current.next;
action.accept(k);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT;
}
}
static final class ValueSpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<V> {
ValueSpliterator(java.util.HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public ValueSpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new ValueSpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super V> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
java.util.HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p.value);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super V> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
V v = current.value;
current = current.next;
action.accept(v);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0);
}
}
static final class EntrySpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<Map.Entry<K,V>> {
EntrySpliterator(java.util.HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public EntrySpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new EntrySpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super Map.Entry<K,V>> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
java.util.HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super Map.Entry<K,V>> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
Node<K,V> e = current;
current = current.next;
action.accept(e);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT;
}
}
/* -------------------LinkedHashMap支持-------------------------- */
/*
* 以下方法旨在
被LinkedHashMap覆盖,但不被任何其他子类覆盖。
几乎所有其他内部方法都受到包保护
但声明为final,因此可以由LinkedHashMap、view classes和HashSet。
*/
// Create a regular (non-tree) node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
// For conversion from TreeNodes to plain nodes
Node<K,V> replacementNode( Node<K,V> p, Node<K,V> next) {
return new Node<>(p.hash, p.key, p.value, next);
}
// Create a tree bin node
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
return new TreeNode<>(hash, key, value, next);
}
// For treeifyBin
TreeNode<K,V> replacementTreeNode( Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
/**
* Reset to initial default state. Called by clone and readObject.
*/
void reinitialize() {
table = null;
entrySet = null;
keySet = null;
values = null;
modCount = 0;
threshold = 0;
size = 0;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess( Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval( Node<K,V> p) { }
// Called only from writeObject, to ensure compatible ordering.
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for ( Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}
/* -------------------------红黑树--------------------------- */
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
//返回包含调用节点的树的根。
final TreeNode<K,V> root() {
for ( TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
/**
* Ensures that the given root is the first node of its bin.
*/
static <K,V> void moveRootToFront( Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = ( TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
(( TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
/**
* Calls find for root node.
*/
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
/**
* Tie-breaking utility for ordering insertions when equal
* hashCodes and non-comparable. We don't require a total
* order, just a consistent insertion rule to maintain
* equivalence across rebalancings. Tie-breaking further than
* necessary simplifies testing a bit.
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
/**
* Forms tree of the nodes linked from this node.
* @return root of tree
*/
final void treeify( Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for ( TreeNode<K,V> x = this, next; x != null; x = next) {
next = ( TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for ( TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
/**
* Returns a list of non-TreeNodes replacing those linked from
* this node.
*/
final Node<K,V> untreeify(java.util.HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for ( Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
/**
* Tree version of putVal.
*/
final TreeNode<K,V> putTreeVal(java.util.HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for ( TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
(( TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
/**
* Removes the given node, that must be present before this call.
* This is messier than typical red-black deletion code because we
* cannot swap the contents of an interior node with a leaf
* successor that is pinned by "next" pointers that are accessible
* independently during traversal. So instead we swap the tree
* linkages. If the current tree appears to have too few nodes,
* the bin is converted back to a plain bin. (The test triggers
* somewhere between 2 and 6 nodes, depending on tree structure).
*/
final void removeTreeNode(java.util.HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
if (tab == null || (n = tab.length) == 0)
return;
int index = (n - 1) & hash;
TreeNode<K,V> first = ( TreeNode<K,V>)tab[index], root = first, rl;
TreeNode<K,V> succ = ( TreeNode<K,V>)next, pred = prev;
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
if (first == null)
return;
if (root.parent != null)
root = root.root();
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
if (pl != null && pr != null) {
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
if (s == pr) { // p was s's direct parent
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
root = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
if (replacement == p) { // detach
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
if (movable)
moveRootToFront(tab, r);
}
/**
* Splits nodes in a tree bin into lower and upper tree bins,
* or untreeifies if now too small. Called only from resize;
* see above discussion about split bits and indices.
*
* @param map the map
* @param tab the table for recording bin heads
* @param index the index of the table being split
* @param bit the bit of hash to split on
*/
final void split(java.util.HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for ( TreeNode<K,V> e = b, next; e != null; e = next) {
next = ( TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
/* ------------------------------------------------------------ */
// Red-black tree methods, all adapted from CLR
static <K,V> TreeNode<K,V> rotateLeft( TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) {
if ((rl = p.right = r.left) != null)
rl.parent = p;
if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
else if (pp.left == p)
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
return root;
}
static <K,V> TreeNode<K,V> rotateRight( TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
static <K,V> TreeNode<K,V> balanceInsertion( TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for ( TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
static <K,V> TreeNode<K,V> balanceDeletion( TreeNode<K,V> root,
TreeNode<K,V> x) {
for ( TreeNode<K,V> xp, xpl, xpr;;) {
if (x == null || x == root)
return root;
else if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (x.red) {
x.red = false;
return root;
}
else if ((xpl = xp.left) == x) {
if ((xpr = xp.right) != null && xpr.red) {
xpr.red = false;
xp.red = true;
root = rotateLeft(root, xp);
xpr = (xp = x.parent) == null ? null : xp.right;
}
if (xpr == null)
x = xp;
else {
TreeNode<K,V> sl = xpr.left, sr = xpr.right;
if ((sr == null || !sr.red) &&
(sl == null || !sl.red)) {
xpr.red = true;
x = xp;
}
else {
if (sr == null || !sr.red) {
if (sl != null)
sl.red = false;
xpr.red = true;
root = rotateRight(root, xpr);
xpr = (xp = x.parent) == null ?
null : xp.right;
}
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red;
if ((sr = xpr.right) != null)
sr.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateLeft(root, xp);
}
x = root;
}
}
}
else { // symmetric
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
if (xpl == null)
x = xp;
else {
TreeNode<K,V> sl = xpl.left, sr = xpl.right;
if ((sl == null || !sl.red) &&
(sr == null || !sr.red)) {
xpl.red = true;
x = xp;
}
else {
if (sl == null || !sl.red) {
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ?
null : xp.left;
}
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
x = root;
}
}
}
}
}
/**
* Recursive invariant check
*/
static <K,V> boolean checkInvariants( TreeNode<K,V> t) {
TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,
tb = t.prev, tn = ( TreeNode<K,V>)t.next;
if (tb != null && tb.next != t)
return false;
if (tn != null && tn.prev != t)
return false;
if (tp != null && t != tp.left && t != tp.right)
return false;
if (tl != null && (tl.parent != t || tl.hash > t.hash))
return false;
if (tr != null && (tr.parent != t || tr.hash < t.hash))
return false;
if (t.red && tl != null && tl.red && tr != null && tr.red)
return false;
if (tl != null && !checkInvariants(tl))
return false;
if (tr != null && !checkInvariants(tr))
return false;
return true;
}
}
}
参考资料
https://www.bilibili.com/video/BV1LJ411W7dP/?p=8&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=f6a308f875296edd5f437b68e0c3253a
https://www.runoob.com/java/java-hashmap.html