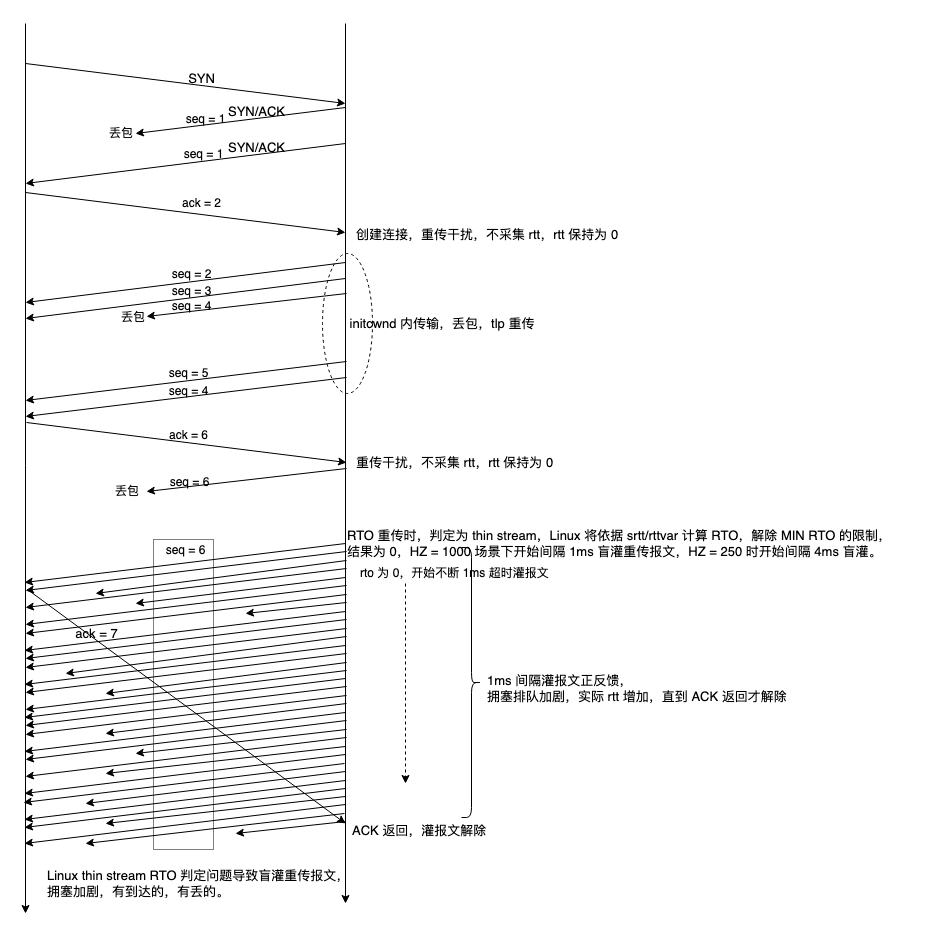
概述
- TDNN(Time Delay Neural Network,时延神经网络)是用于处理序列数据的,比如:一段语音、一段文本
- 将TDNN和统计池化(Statistics Pooling)结合起来,正如x-vector的网络结构,可以处理任意长度的序列
- TDNN出自Phoneme recognition using time-delay neural networks
- x-vector出自X-Vectors: Robust DNN Embeddings for Speaker Recognition
- 此外,TDNN还演化成了ECAPA-TDNN,而ECAPA-TDNN则是当前说话人识别领域,在VoxCeleb1数据集的三个测试集VoxCeleb1 (cleaned)、VoxCeleb1-H (cleaned)、VoxCeleb1-E (cleaned)上的最强模型,因此学习TDNN还是很有必要的
x-vector的网络结构
- x-vector是用于文本无关的说话人识别的,因此需要处理任意长度的序列,其网络结构如下图所示:
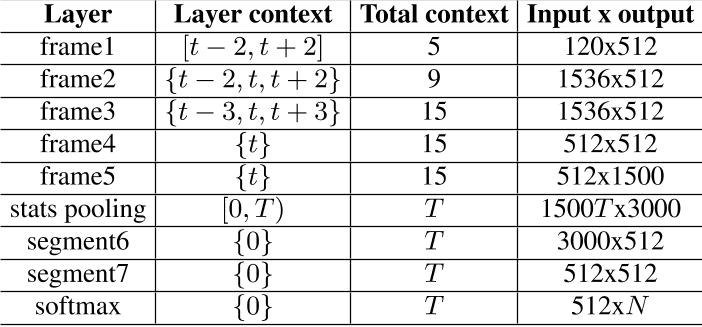
- 上图的迷惑性其实非常大,有必要好好讲解一下,现在我给出从frame1到frame4层(frame5与frame4本质上是一样的,只不过卷积核数量不同)的可视化结果

- 输入:每个特征图表示一帧,特征图的通道数为24,表示一帧的特征数(原文是24维fbank特征),特征图的分辨率是1,在这里需要明确:语音是1维数据,因此特征图并不是二维图,而是一个值,24个特征图堆叠起来构成24维fbank特征
- frame1
- frame1的特征图经过1维卷积得到,卷积核大小 i n c h a n n e l s × k e r n e l s i z e × o u t c h a n n e l s = 24 × 5 × 512 inchannels \times kernelsize \times outchannels=24\times5\times512 inchannels×kernelsize×outchannels=24×5×512
- frame1的每个特征图下面连接的5条线,表示卷积核。这5条线不是5根细线,而是5根麻花线,每根麻花线由
i
n
c
h
a
n
n
e
l
s
=
24
inchannels=24
inchannels=24根细线组成,每根细线连接一个特征。每根细线的权重都是一样的,每根麻花线的权重不一样

- k e r n e l s i z e = 5 kernelsize=5 kernelsize=5,对应闭区间 [ t − 2 , t + 2 ] [t-2,t+2] [t−2,t+2]一共5帧的上下文,也可以表示为 { t − 2 , t − 1 , t , t + 1 , t + 2 } \left \{ t-2,t-1,t,t+1,t+2 \right \} {t−2,t−1,t,t+1,t+2},之所以表格说frame1的输入是120,是因为将5帧上下文的特征都计算进去了 5 × 24 = 120 5\times24=120 5×24=120
- o u t c h a n n e l s = 512 outchannels=512 outchannels=512,表示卷积核的厚度是512,可以理解为5根麻花线堆叠了512次,每次堆叠都得到新的5根麻花线,都符合“每根细线的权重都是一样的,每根麻花线的权重不一样”。5根麻花线同时运算,得到一个值,从而frame1的每个特征图其实也是一个值,且通道数为512,对应表格中的frame1的输出是512
- frame2
- frame2的特征图经过1维膨胀卷积得到,卷积核大小 i n c h a n n e l s × k e r n e l s i z e × o u t c h a n n e l s = 512 × 3 × 512 inchannels \times kernelsize \times outchannels=512\times3\times512 inchannels×kernelsize×outchannels=512×3×512
- 不要被膨胀卷积吓到了,膨胀卷积的 k e r n e l s i z e = 3 kernelsize=3 kernelsize=3,表示3根麻花线中,第2根麻花线连接第t帧,第1根麻花线连接第t-2帧,第3根麻花线连接第t+2帧,对应表格中的 { t − 2 , t , t + 2 } \left \{ t-2,t,t+2 \right \} {t−2,t,t+2}共3帧的上下文,这就是膨胀卷积和标准卷积的不同之处,隔帧连接
- 在PyTorch中,1维卷积的api为
t o r c h . n n . C o n v 1 d ( i n c h a n n e l s , o u t c h a n n e l s , k e r n e l s i z e , s t r i d e = 1 , p a d d i n g = 0 , d i l a t i o n = 1 , g r o u p s = 1 , b i a s = T r u e , p a d d i n g m o d e = ′ z e r o s ′ , d e v i c e = N o n e , d t y p e = N o n e ) torch.nn.Conv1d(inchannels, outchannels, kernelsize, stride=1, padding=0, dilation=1, groups=1, bias=True, paddingmode='zeros', device=None, dtype=None) torch.nn.Conv1d(inchannels,outchannels,kernelsize,stride=1,padding=0,dilation=1,groups=1,bias=True,paddingmode=′zeros′,device=None,dtype=None)
其中, d i l a t i o n = 1 dilation=1 dilation=1表示标准卷积,frame2的膨胀卷积需要设置 d i l a t i o n = 2 dilation=2 dilation=2 - 在这里我们也发现一点:TDNN其实是卷积的前身,后世提出的膨胀卷积,在TDNN里已经有了雏形,只不过TDNN是用于1维数据的
- frame3、frame4没有引进新的运算。frame3需要设置 d i l a t i o n = 3 dilation=3 dilation=3,而frame4的卷积核大小 i n c h a n n e l s × k e r n e l s i z e × o u t c h a n n e l s = 512 × 1 × 512 inchannels \times kernelsize \times outchannels=512\times1\times512 inchannels×kernelsize×outchannels=512×1×512,因为 k e r n e l s i z e = 1 kernelsize=1 kernelsize=1,所以与MLP(dense layer)没有本质区别,卷积核通过在每一帧上移动,实现全连接,因此可以看到有些代码实现用 k e r n e l s i z e = 1 kernelsize=1 kernelsize=1的卷积替代全连接
- 从frame1到frame5,每次卷积的步长 s t r i d e stride stride都等于1,从而对每一帧都有对应的输出,也就是说,对于任意长度的帧序列,frame5的输出也是一个同等长度的序列,长度记为 T T T,而由于frame5的 o u t c h a n n e l s = 1500 outchannels=1500 outchannels=1500,所以表格中统计池化的输入是 1500 × T 1500 \times T 1500×T
- 统计池化的原理颇为简单,本质是在序列长度 T T T这一维度求均值和标准差,然后将均值和标准差串联(concatenate)起来,所以池化后,序列长度 T T T这一维度消失了,得到了 1500 1500 1500个均值和 1500 1500 1500个标准差,串联起来就是长度为 3000 3000 3000的向量
- segment6、segment7和Softmax都是标准的MLP,不再赘述
- 最后segment6输出的
512
512
512长度的向量,被称为x-vector,用于训练一个PLDA模型,进行说话人识别,可以计算一下,提取x-vector所需的参数
f r a m e 1 + f r a m e 2 + f r a m e 3 + f r a m e 4 + f r a m e 5 + s e g m e n t 6 = 120 × 512 + 1536 × 512 + 1536 × 512 + 512 × 512 + 512 × 1500 + 3000 × 512 = 420 , 0448 \begin{aligned} &frame1+frame2+frame3+frame4+frame5+segment6 \\ =&120 \times 512 + 1536 \times 512 + 1536 \times 512 + 512 \times 512 + 512 \times 1500 + 3000 \times 512 \\ =&420,0448 \end{aligned} ==frame1+frame2+frame3+frame4+frame5+segment6120×512+1536×512+1536×512+512×512+512×1500+3000×512420,0448 - 参数量并不能代表计算量,因为输入网络的是任意长度的帧序列