对于一个发展初期的系统来说,不太确定商业模型到底行不行,最好的办法是按照最小可行产品方法进行产品验证,因此,刚开始的功能会比较少,是一个大的单体应用,一般按照三层架构进行设计开发,使用单数据库,缓存也是可选组件,而应用系统和数据库也很可能部署在同一台物理机上,如下图所示。

对于这样一个系统,随着产品使用的用户越来越多,网站的流量会增加,最终单台服务器无法处理那么大的流量,此时就需要用分而治之的思想来解决问题。
第一步是尝试通过简单扩容来解决。
第二步,如果简单扩容搞不定,就需要水平拆分和垂直拆分数据/应用来提升系统的伸缩性,即通过扩容提升系统负载能力。
第三步,如果通过水平拆分/垂直拆分还是搞不定,那就需要根据现有系统特性,从架构层面进行重构甚至是重新设计,即推倒重来。
对于系统设计,理想的情况下应支持线性扩容和弹性扩容,即在系统瓶颈时,只需要增加机器就可以解决系统瓶颈,如降低延迟提升吞吐量,从而实现扩容需求。
如果你想扩容,则支持水平/垂直伸缩是前提。
在进行拆分时,一定要清楚知道自己的目的是什么,拆分后带来的问题如何解决,拆分后如果没有得到任何收益就不要为了拆而拆,即不要过度拆分,要适合自己的业务。
单体应用垂直扩容
有些时候,如果能通过硬件快速解决,而且成本不高,应该首先通过硬件扩容来解决问题。
硬件扩容包括升级现有服务器,比如CPU由原来的32核升级到64核。
内存从64GB升级到256GB(有的缓存服务器CPU利用率很低,但是内存不够用,就通过扩容内存来提升单机容量)。
磁盘扩容,比如系统有大量的随机读写,因此把HDD换成SSD,还有将原来单机1TB扩容为2TB,原来硬盘做了RAID10,现在直接拆为裸盘使用,通过架构层面提升数据可靠性。
此外,核心数据库可以使用PCle SSD或NVMe SSD,千兆网卡可以升级为万兆网卡。
不管怎么扩容,单机总会是瓶颈,而分布式技术是提升系统扩容能力的更好方法。
单体应用水平扩容
单体系统水平扩容是通过部署更多的镜像来实现的。
如下图所示,原来通过一个系统实例对外提供服务,通过扩容到更多实例后,用户访问时不可能提供多个域名/IP入口,应该提供统一入口,此时就需要负载均衡机制来实现。
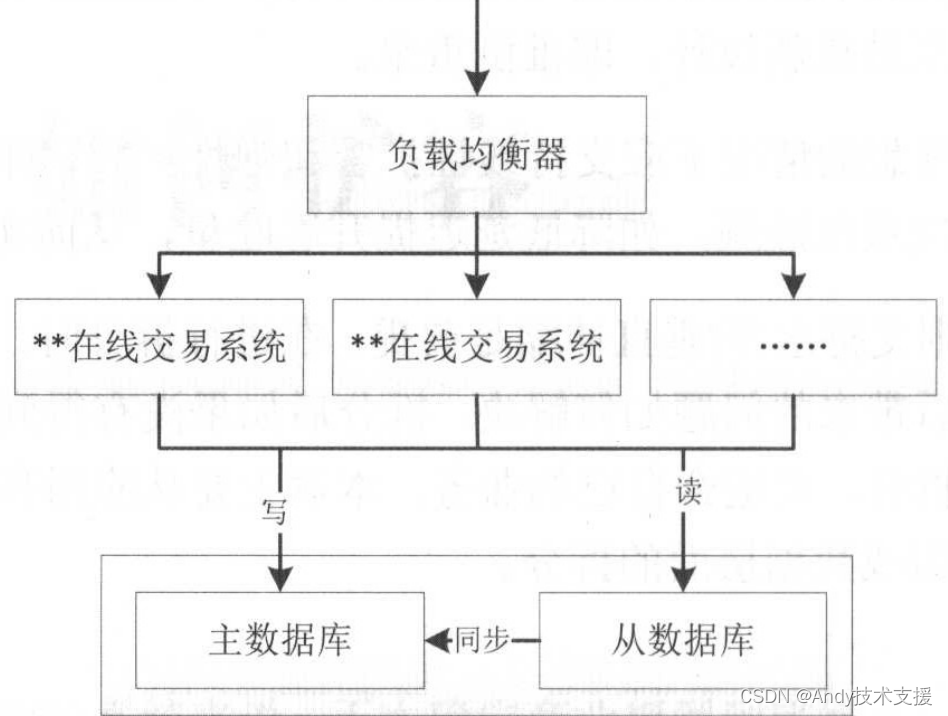
如果用户会话数据分散在应用系统,就需要在负载均衡器开启会话黏滞特性。
如果数据库的瓶颈是读造成的,则此时可以通过主从数据库架构将读的流量分散到更多的从服务器上,写数据时写到主数据库,读数据时读取从数据库。
经过单体应用的垂直/水平扩容,如果系统还是有瓶颈,则此时只有通过拆分应用来解决。
应用拆分
对于单体应用来说,随着业务量的增加,一个大系统就会有很多人维护,这就造成修改代码会出现冲突,上线必须大家一起上线,而且风险较大,导致需求实现速度缓慢。
因此单体应用发展到一定地步时,会按照业务进行拆分。
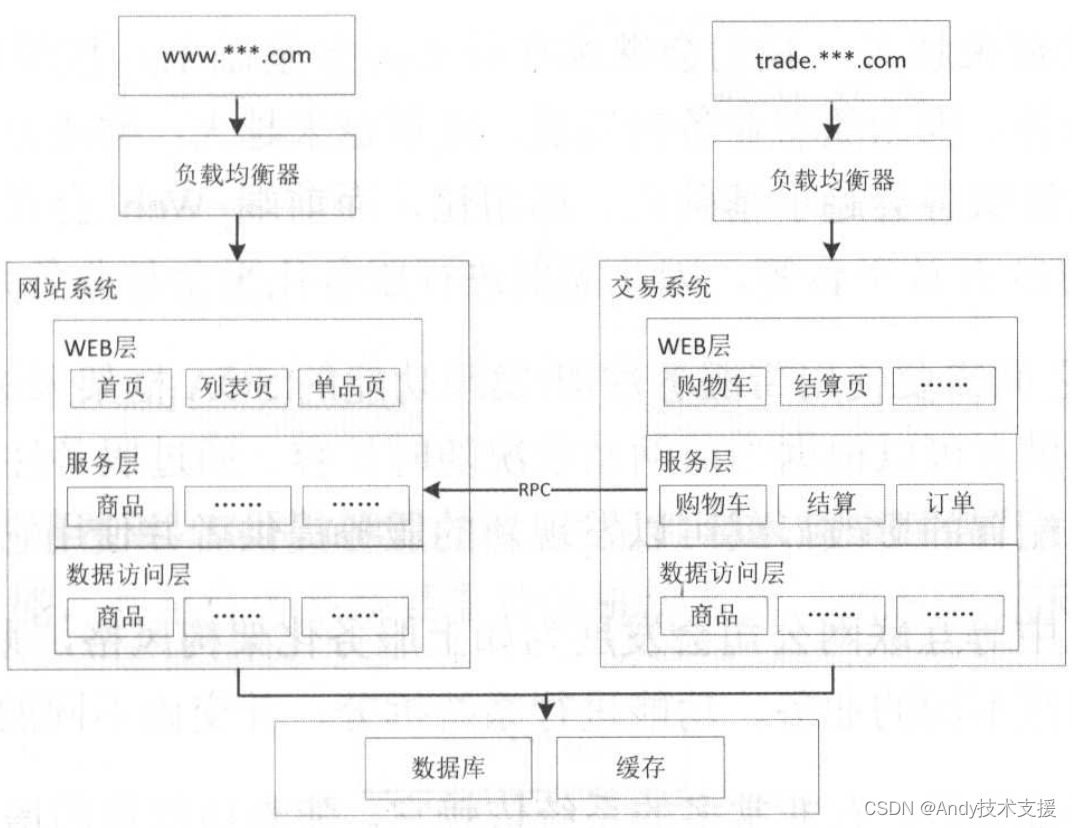
如上图所示,我们按照业务将一个大系统拆分为多个子系统,比如网站系统和交易系统。拆分时要进行业务代码解耦,将功能分离到不同系统上。
拆分后系统之间是物理隔离的,应用层面原来是直接进程内方法调用,现在需要改成远程方法调用,比如通过WebService、RMI等。
通过拆分,可以由两个团队分别维护网站和交易系统,相互之间的更新是不冲突的。
但是目前也存在一些问题,比如,我们使用RMI机制,需要使用方维护一个服务方IP列表。因此下一个方向是SOA化,如下图所示。
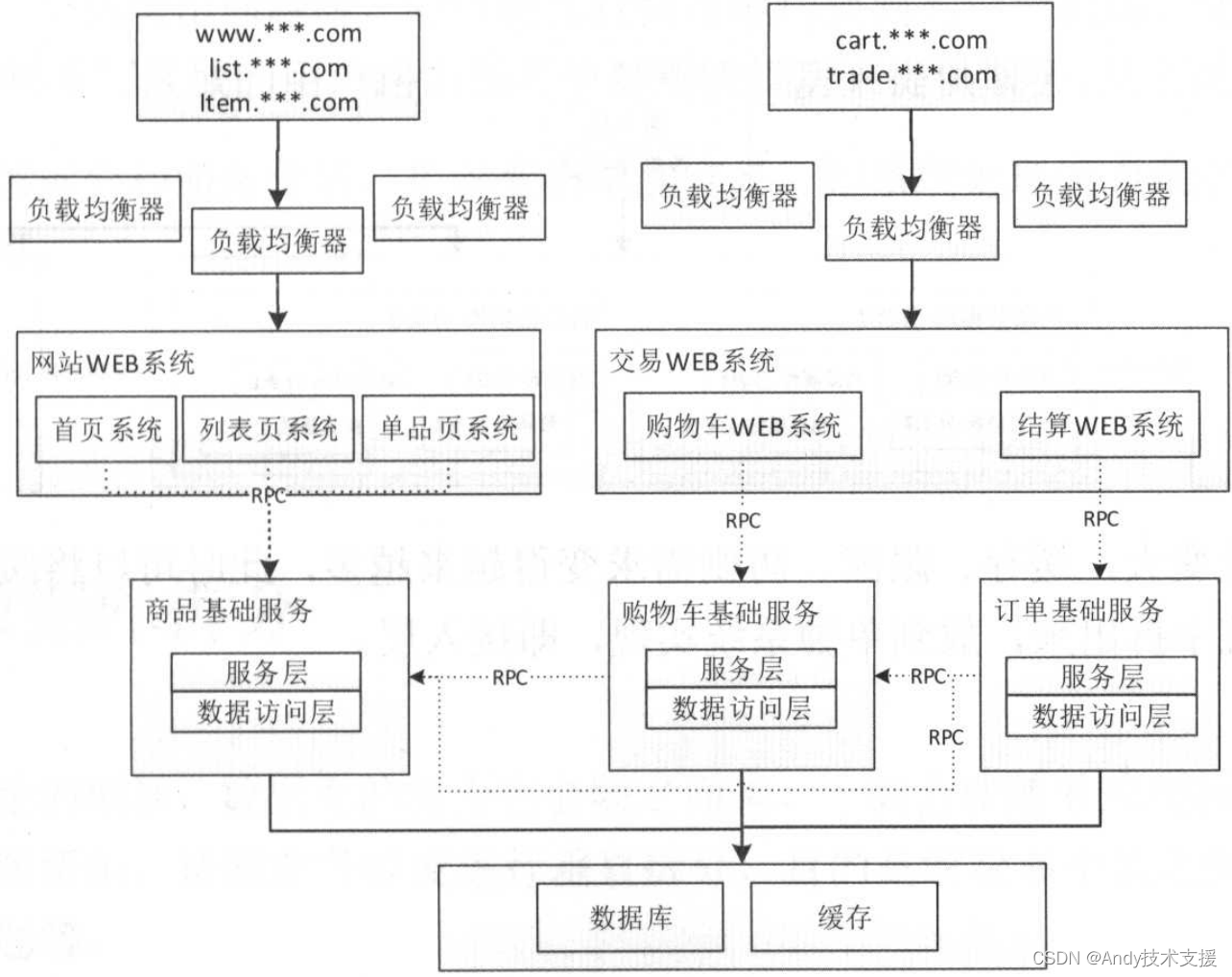
随着系统流量越来越大,我们会继续在业务拆分基础上,按照功能域拆分为前端Web系统和基础服务。
因为随着业务的发展,流量越来越大,解决方案越来越复杂。
像商品、购物车、结算服务会趋于基础化、通用化,而前端Web会有各种各样的版本和需求,如PC/APP/H5/开放平台等,因此需要进行服务化平台与业务系统的拆分。
拆分后,系统之间需要使用带服务注册/发现功能的SOA框架来进行交互,如Dubbo。
服务化后,服务提供者可以根据当前网站状况随时扩容。
通过服务注册中心,服务消费者不需要进行任何配置的更改,就可以发现新的服务提供者并使用它。
一般情况下,中等互联网公司会发展为如上服务化架构风格,系统之间通过SOA服务进行互动,按照不同的业务、功能进行系统拆分,并交由不同的团队维护。
像商品这种基础服务,有非常多的系统依赖它。
随着访问量的增加,尤其像单个读/单个写/条件查询这类访问,会因为某一种操作出现异常造成其他操作不可用。因此,我们需要把这些操作进行拆分,拆分到不同的服务中,从而使写出现问题时不会影响到读。
另外,因为进行了系统拆分,主数据库向缓存/ES同步时会有一定的延迟,如果需要强一致性的读,那么直接读主库吧。
但是,不是所有的系统都需要读主库,要做出限制。
随着应用部署数量的增多,数据库连接也会成为瓶颈,一般会通过主从架构提升连接数。
也可以使用MyCat/Corbar这种数据库中间件提升连接数。
所有应用只调用读/写服务中间件,由读/写服务中间件访问数据库,减少整体的连接数。
然后通过MQ异构数据,从而不访问有瓶颈的数据库。
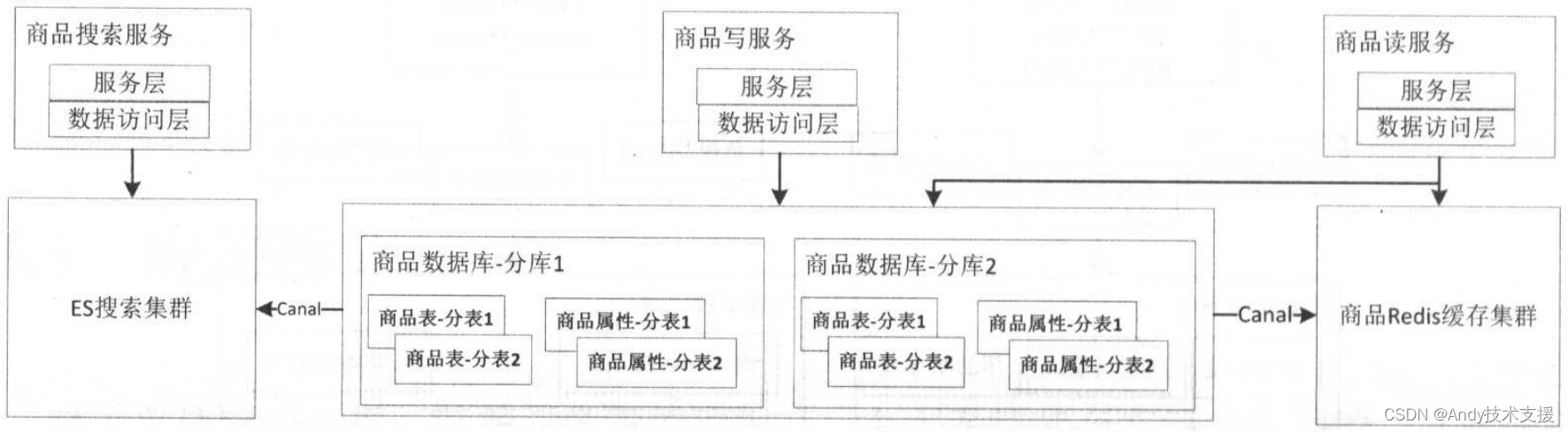
随着流量变大,缓存、限流、防刷需求变得越来越多,此时可以将缓存/限流/防刷从各应用系统中拆出来,放到单独系统实现,即接入层。
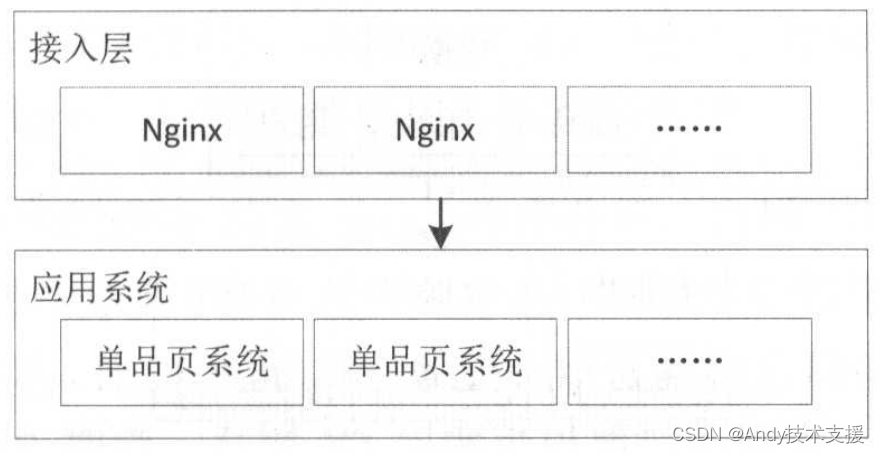
随着网站发展,对网站的性能、可用性要求越来越高,对于前端页面型应用需要引进CDN功能,并且业务系统要支持多机房多活,如下图所示。
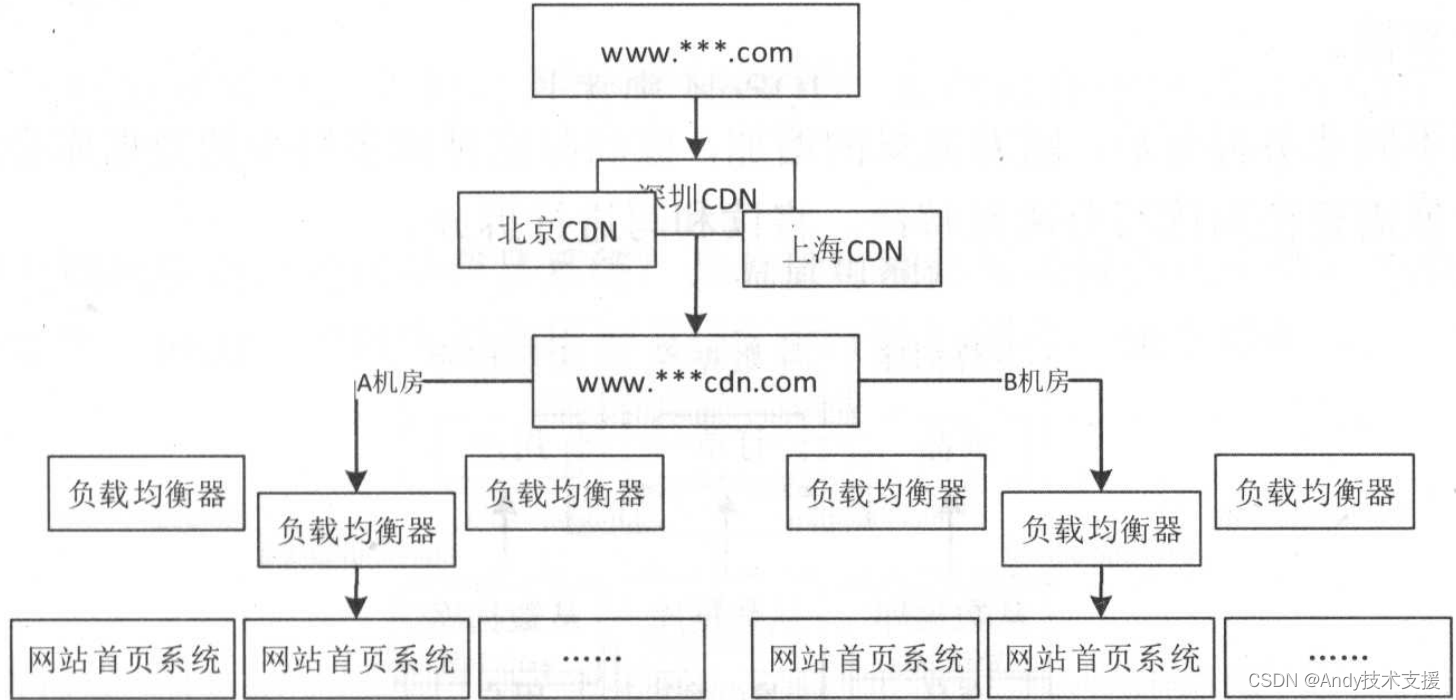
当其中一个机房出问题时,应该能比较快速地切换到另一个机房。
使用BIND可以根据用户IP将不同区域的用户路由到离他最近的机房来提供服务,从而减少访问延迟。
通过应用拆分和服务化后,扩容变得更加容易,如系统处理能力跟不上,只需要增加服务器即可。
数据库拆分
随着流量的增加,数据库的压力也会随之而来,一般会伴随着应用拆分进行数据库拆分。
如下图所示,按照业务维度进行垂直拆分,目的是解决多个表之间的IO竞争、单机容量问题等。
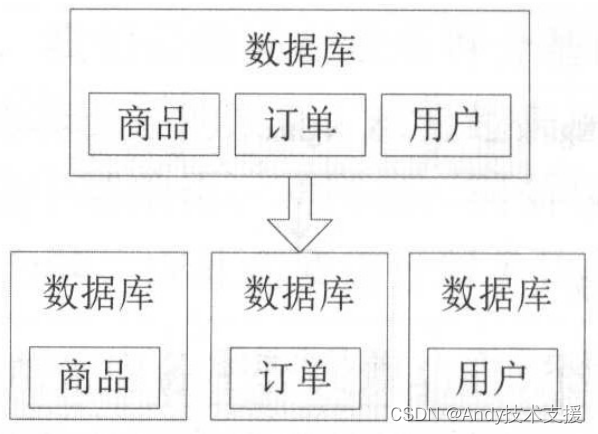
拆分后会出现,原来可以进行单库join查询,现在不可以了,需要解决跨库join,还要解决分布式事务等问题。
跨库join可以考虑通过如全局表、ES搜索等异构数据机制来实现。
数据库垂直拆分中还存在一种宽表拆多个小表的场景,不过一般在设计时就会做这件事情。
按照不同业务拆分后,随着流量的增加,像商品这种读多写少的数据库会遇到读瓶颈,此时就需要使用读写分离来解决,将读和写进行拆分。
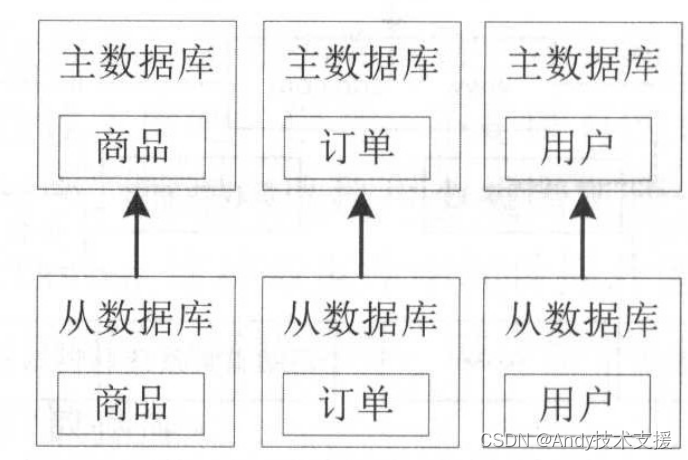
随着流量和数据量的增加,单库单表会遇到容量和磁盘/带宽IO瓶颈,单表会随着数据量增长出现性能瓶颈,此时就需要分库、分表,或者分库分表。
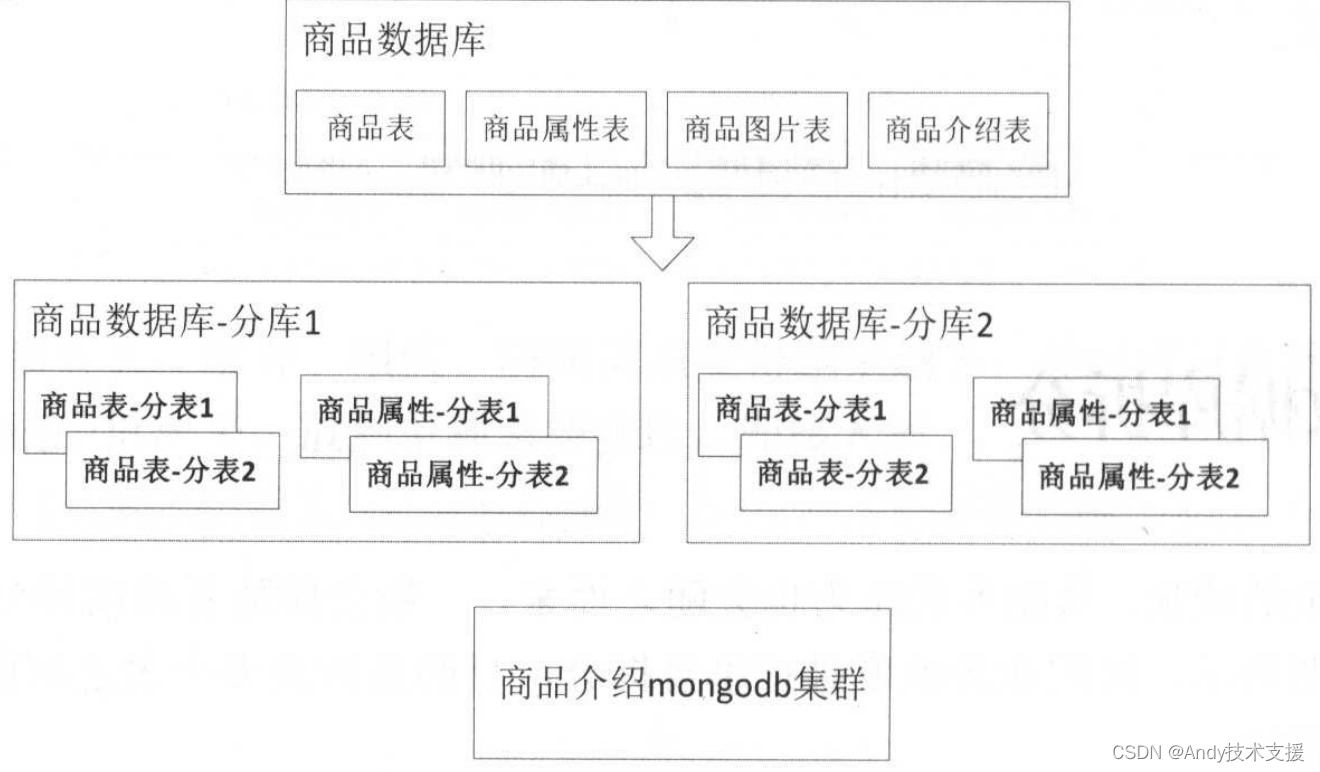
分库分表是一种水平数据拆分,会按照如ID、用户、时间等维度进行数据拆分,拆分算法可以是取模、哈希、区间或者使用数据路由表等。
这也导致了前文中说的跨库/跨表join、排序分页、自增ID、分布式事务等问题。
对于跨库/跨表join和排序分页,可以对所有表进行扫描然后做聚合,或者生成全局表、进行查询维度的数据异构(比如,订单库按照查询维度异构出商家订单库、用户订单库),再或者将数据同步到ES搜索。自增ID问题可以通过不同表、不同自增步长或分布式ID生成器解决。而分布式事务可以考虑事务表、补偿机制(执行/回滚)、TCC模式(预占/确认/取消)、Sagas模式(拆分事务+补偿机制)等,业务应尽量设计为最终一致性,而不是强一致性。
对于一些特殊数据,我们可以考虑NoSQL,如商品介绍很适合存储在mongodb集群中。
对于互联网应用,尤其是商品系统,读流量可能是写流量的几十倍,而单个商品的查询会非常多,此时,可以考虑使用如Redis进行数据缓存,如下图所示。
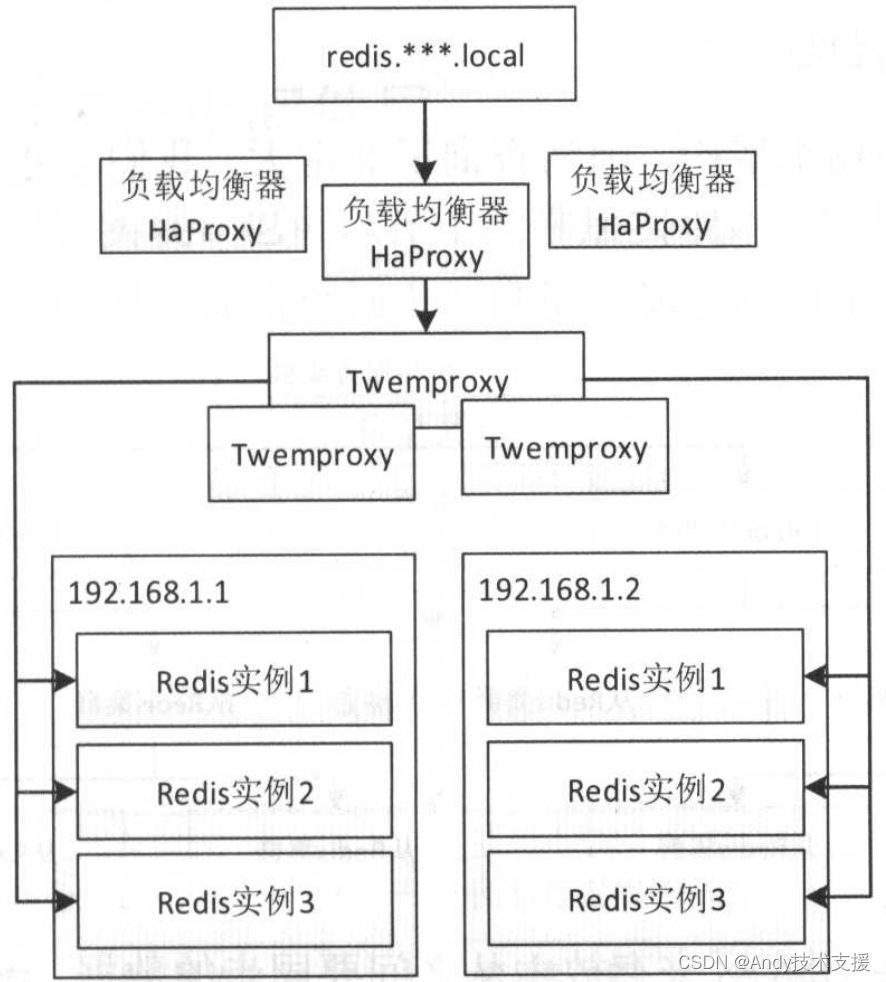
部署多个Redis实例,通过Twemproxy并使用一致性哈希算法进行分片,先通过HaProxy进行Twemproxy的负载均衡,然后通过内网域名进行访问。
还有如购物车数据,是用户维度数据,我们完全可以全量存储到KV存储中,如使用Redis进行存储。为了数据的安全性,我们采用了双写架构,如下图所示。
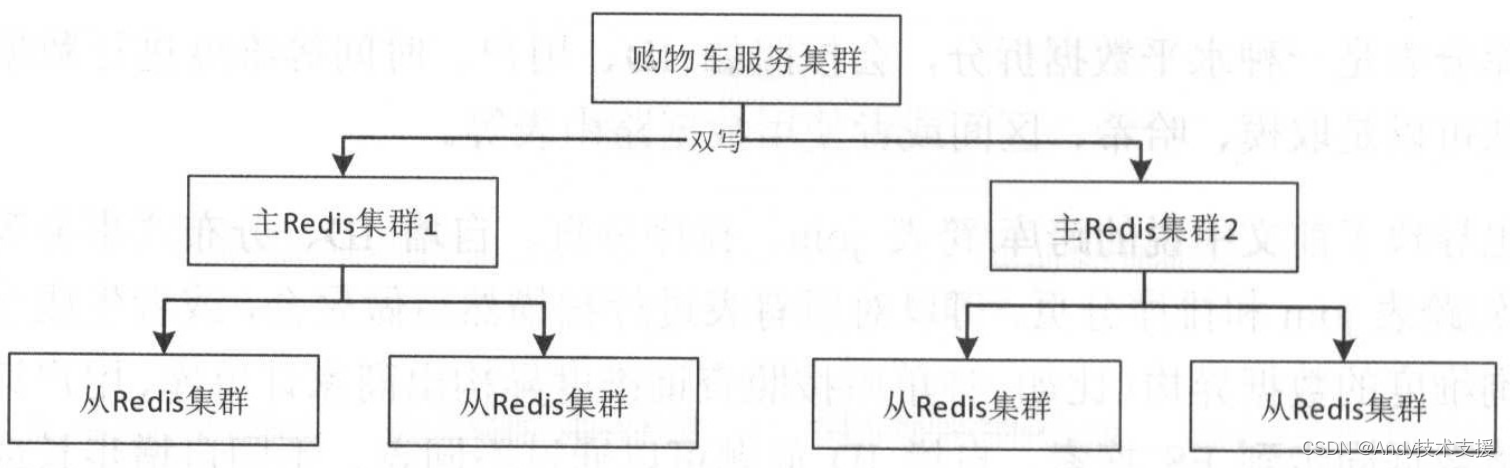
最简单的办法是在多个集群间通过主从来解决,不过主从切换比较麻烦,当主从断开后需要全量更新时恢复较慢。
也可以使用程序双写,实现逻辑比较简单且切换方便。程序双写可以是程序同步双写,写失败其中一个就都失败。这种方式性能差,不适合多机房同步写,也不适合同步写多个集群。
还可以使用异步双写,首先把变更发布到数据总线(如通过MQ实现),然后订阅数据总线变更,异步写其他集群。
这种方式的优点是性能好,缺点是异步同步有一定的时延,数据一致性差一些,应考虑使用一致性哈希把用户调度到同一个集群,防止用户刷新多次看到不一样的数据。
实时价格类似于购物车架构,因为查询量非常大,我们会通过挂更多的从来扩展读的能力,如下图所示。
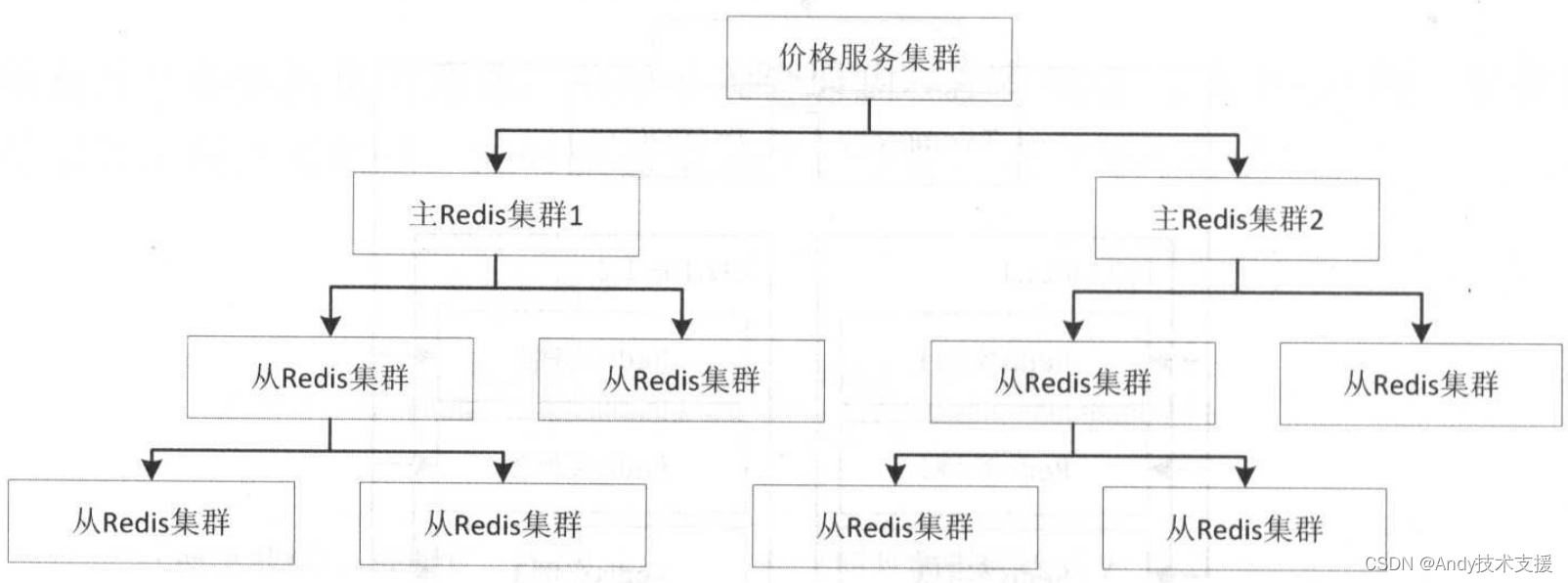
Redis使用内存复制缓存区来存放主从之间要同步的数据。
当主从断开时间较长时,复制缓冲区达到阈值,此时旧缓存数据会被丢弃,此时断开的主从进行同步时将会全量复制。Redis也没有提供类似于mysql binlog的机制。
到此应用拆分和数据库拆分就介绍完了。应用扩容可以通过部署更多的应用实例来解决,无法部署更多的实例时,就需要考虑系统拆分或者重新架构。
而数据库扩容首先是硬件层面,然后按照业务进行垂直拆分,接着进行水平拆分,最后根据流量场景进行读写分离,还可以将读流量分流到NoSQL上。
数据库分库分表示例
数据库分库分表后就会涉及如何写入和读取数据的问题,应用开发人员主要关心如下几个问题。
- 是否需要在应用层做改造来支持分库分表,即是在应用层进行支持,还是通过中间件层呢?
- 如果需要应用层做支持,那么分库分表的算法是什么?
- 分库分表后,join是否支持,排序分页是否支持,事务是否支持。
应用层还是中间件层
分库分表可以在应用层实现,也可以在中间件层实现,中间件层实现的好处是对应用透明,应用就像查单库单表一样去查询中间件层,如下图所示。
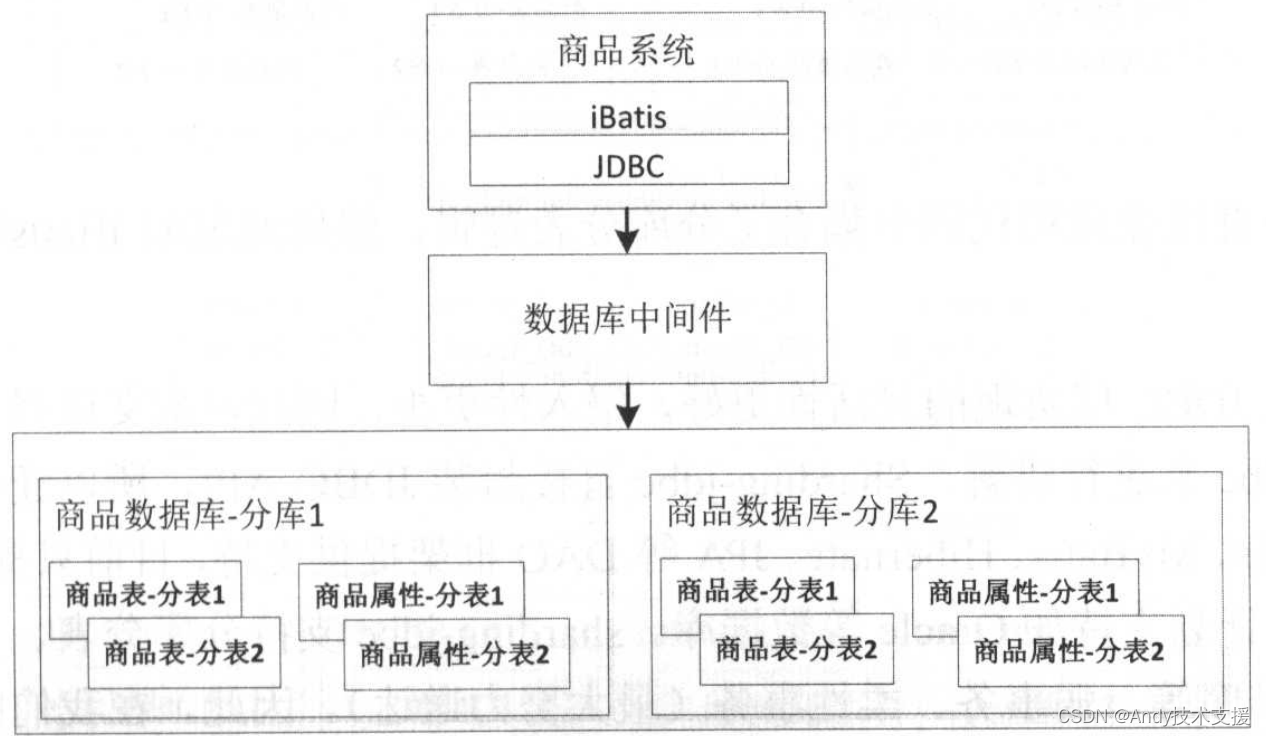 使用数据库中间件层还有一个好处是可以支持多种编程语言,而不受限于特定的语言。使用数据库中间件层可以减少应用的总数据库连接数,从而避免因为应用过多导致数据库连接不够用。
使用数据库中间件层还有一个好处是可以支持多种编程语言,而不受限于特定的语言。使用数据库中间件层可以减少应用的总数据库连接数,从而避免因为应用过多导致数据库连接不够用。
缺点是除了维护中间件外,还要考虑中间件的HA/负载均衡等,增加了部署和维护的困难,因此,还是要看当前阶段有没有必要使用中间件和有没有人维护该中间件。
目前开源的数据库中间件有基于MySQL-Proxy开发的奇虎360的Atlas、阿里的Cobar、基于Cobar开发的Mycat等。
京东内部也有很多分库分表实现,还有如JProxy分布式数据库实现,截止本书出版前暂未开源。
Atlas只支持分表或分库(sharding版本)、读写分离等,不支持跨库分表(如分3个库每个库3张表),sharding版本不支持跨库操作(跨库事务/跨库join等)。
Cobar支持分库不支持分表(如每个库3个表),不支持跨库join/分页/排序等。
Mycat支持分库分表、读写分离、跨库弱事务支持,对跨库join等有限支持(内存聚合)。
这些中间件目前主要支持MySQL,但MyCat也提供了对Oracle等数据库的支持。
而应用层可以在JDBC驱动层、DAO框架层,如iBatis/Mybatis/Hibernate/JPA上完成。如当当的sharding-jdbc是JDBC驱动层实现,而阿里的cobar-client是基于DAO框架iBatis实现,如下图所示。
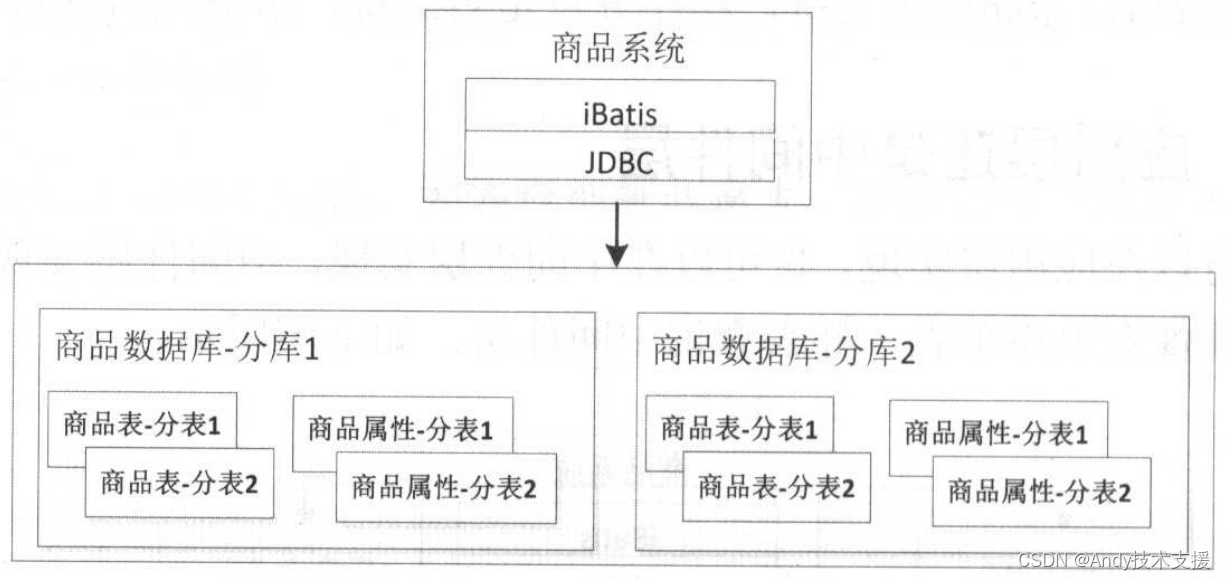
应用系统直接在应用代码中耦合了分库分表逻辑,然后通过如iBatis/JDBC直接分库分表实现。
相对来说JDBC层实现的灵活性更好,侵入性更少,因此,本文选择了开源的当当的Sharding-jdbe来进行讲解。Shardingjdbc直接封装JDBC API,所以迁移成本很低,可以对如iBatis、MyBatis、Hibernate、JPA等DAO框架提供支持,目前只提供了MySQL的支持,未来计划支持如Oracle等数据库。
shardingjdbc支持分库分表、读写分离、跨库join/分页/排序等、弱事务、柔性事务(最大努力送达)。因此,在我们的场景中需要使用的分库分表/弱事务功能它都有。
分库分表策略
分库分表策略是指按照什么算法或规则进行存储,它会影响数据的写入和读取,比如,按照订单ID分库分表,那么就很难按照客户维度进行订单查询。
因此,在进行分库分表时需要慎重考虑使用什么策略。常见的策略有取模、分区、路由表等。
取模
我们可以按照数值型主键取模来进行分库分表,也可以按照字符串主键哈希取模进行分库分表,常见的如订单表按照订单ID分库分表,用户订单表按照用户ID分库分表,产品表按照产品ID分库分表。
取模的优点是数据热点分散,缺点是按照非主键维度进行查询时需要跨库/跨表查询,扩容需要建立新集群并进行数据迁移。
如果想减少扩容时带来的麻烦,可以在初期规划时冗余足够数量的分库分表,比如一年规划只需要分2个库4个表,可以冗余设计为4个库8个表,0-1库在机器1,2-3库在机器2,如果遇到性能问题时可以把1、3库移到新的机器上。如果遇到容量问题,则可以按照如下步骤进行扩容。
每台物理机上有两个数据库实例,当遇到数据库性能瓶颈时首先可以通过升级硬件解决,如HDD换成SATA SSD、SATA SSD换成PCle SSD或NVMe SSD;升级硬件之后,瓶颈可能是磁盘空间或者网卡带宽。
如果还是不能解决性能问题,接着通过扩容物理机来解决性能瓶颈。
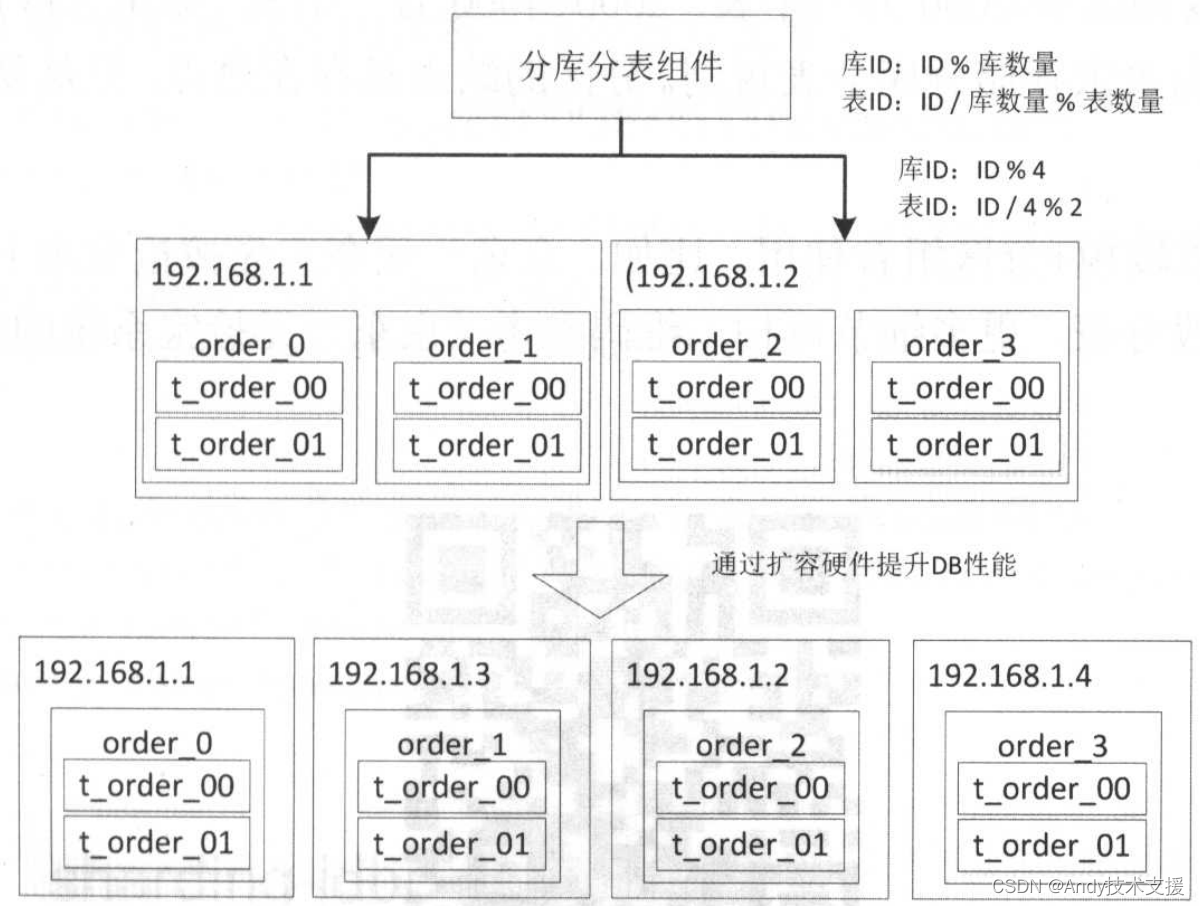
当通过扩容物理机无法解决性能问题或者当单表容量遇到瓶颈,可以进行成倍扩容,4个库扩容为8个库,如下图所示。
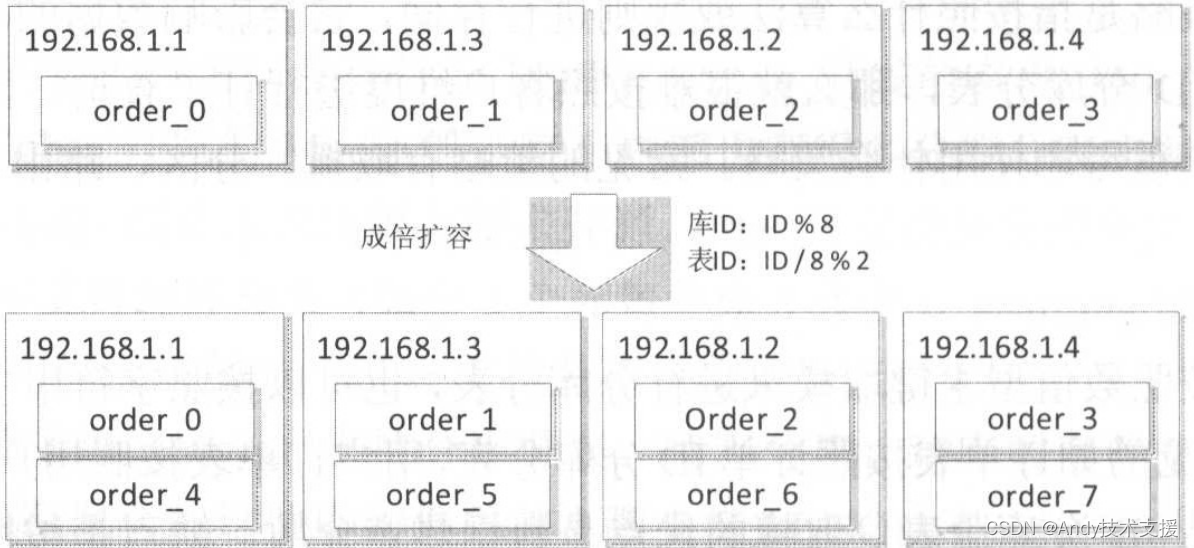
成倍扩容后的数据迁移可以这样实现,先挂数据库主从(order_4–>order_0),当数据库主从同步完成后,停应用写数据库并等待一段时间以保证主从同步完成,接着更新分库分表规则并启动应用进行写库,最后删除各个库的冗余数据即可。
分库数量不是越多越好,分库太多会导致消耗更多的数据库连接,并且应用会创建更多的线程。这种情况下数据代理中间件会是更好的选择。
分区
可按照时间分区、范围分区进行分库分表,时间分区规则如一个月一个表、一年一个库。
范围分区规则0-2000万一个表,2000-4000万一个表。如果分区规则很复杂,则可以有一个路由表来存储分库分表规则。
分区的缺点是存在热点,但是易于水平扩展,能避免数据迁移。
另外,也可以取模+分区组合使用。比如,京东一元夺宝先按抢宝项Hash分库,然后按抢宝期区间段分表。
数据异构
分库分表后将带来很多问题,如跨库join、非分库分表维度的条件查询、分页排序等。
前面我们提到了可以扫描全部表通过内存聚合、数据异构(全局表、ES搜索、异构表)等来实现。
数据异构主要按照不同查询维度建立表结构,这样就可以按照这种不同维度进行查询。数据异构有查询维度异构、聚合数据异构等。
在数据量和访问量双高时使用数据异构是非常有效的,但增加了架构的复杂度。异构时可以通过订阅MQ或者binlog并解析实现。
查询维度异构
比如对于订单库,当对其分库分表后,如果想按照商家维度或者按照用户维度进行查询,那么是非常困难的,因此可以通过异构数据库来解决这个问题。可以采用下图的架构。
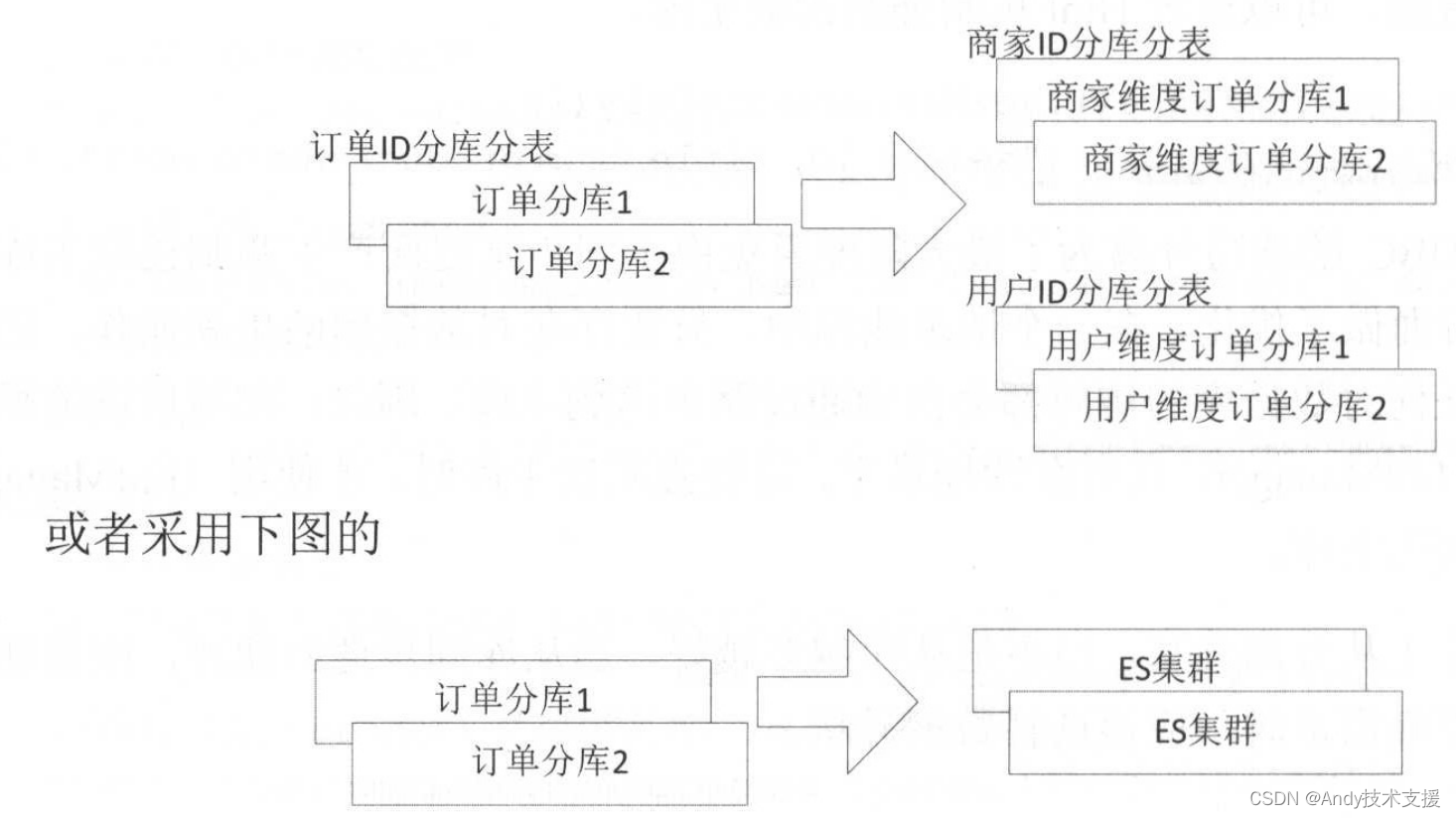
异构数据主要存储数据之间的关系,然后通过查询源库查询实际数据。不过,有时可以通过数据冗余存储来减少源库查询量或者提升查询性能。
聚合据异构
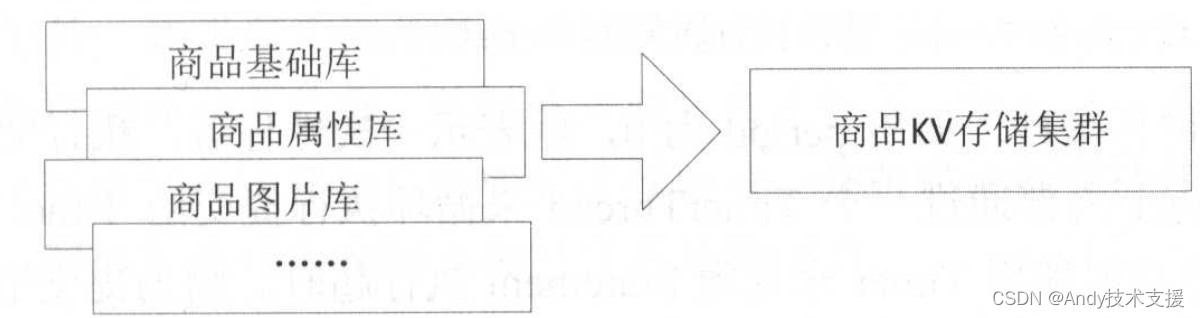
商品详情页中一般包括商品基本信息、商品属性、商品图片,在前端展示商品详情页时,是按照商品ID维度进行查询,并且需要查询3个甚至更多的库才能查到所有展示数据。
此时,如果其中一个库不稳定,就会导致商品详情页出现问题,因此,我们把数据聚合后异构存储到KV存储集群(如存储JSON),这样只需要一次查询就能得到所有的展示数据。
这种方式也需要系统有了一定的数据量和访问量时再考虑。京东商品详情页就是采用这种异构机制。
任务系统扩容
在开发系统时,有时需要在特定的时间点执行一些任务,或者周期性地执行一些任务。
比如,每天凌晨删除过期的垃圾消息、每天凌晨进行报表统计、每天凌晨进行数据结转,或者每隔10分钟处理一次超时未支付的订单、每隔10秒删除过期的活动等。
对于一般单实例任务,使用如Thread、Timer、ScheduledExecutor、Quartz单机版就足够了,如果需要高可用或分布式版本,则可以选择Quartz集群版、tbschedule、elastic-job等。
简单任务
在一般情况下,我们使用Thread就能满足需求,如第15章中使用EventPublishThread线程抓取任务并交给Disruptor处理。
即使用Thread,一般都是死循环抓取并处理任务,如果没有任务,则可以休眠一下,然后继续尝试抓取任务,为了保证任务能及时被处理,休眠时间非常短,一般为几毫秒到几秒。
比如要获取任务表中状态为未处理的任务并进行处理,处理成功后将状态更新为已处理,则可以使用如上介绍的Thread方式。
分布式任务
使用上述机制进行单实例任务处理时是单点作业,如果实例失效了,那么任务可能得不到执行,另外,如果单实例任务处理遇到瓶颈,则不太容易做到动态扩容。
因此,我们需要任务高可用和动态扩容,此时就需要分布式任务。
使用分布式任务后,当一个实例失效,则可以将任务转移到其他实例进行处理。
分布式任务支持任务分片,当任务处理遇到瓶颈,可以扩充任务实例来提升任务处理能力。
Quartz支持任务的集群调度,如果一个实例失效,则可以漂移到其他实例进行处理,但是其不支持任务分片。
tbschedule和elastic-job除了支持集群调度特性,还支持任务分片,从而可以进行动态扩容/缩容。
任务分片
任务如果并行处理或者分布式处理,则需要使用任务分片,即把任务拆成N个子任务。
比如,我们需要遍历某张数据库表,现在有1台服务器,为了实现多线程处理,此时可以将数据分片为10份,如id%10,那么会有10个线程并发处理这些任务,从而提升了处理性能。
如果有两台服务器,并且还将数据分片为10份,如id%10,那么机器1会处理1,3,5,7,9;机器2会处理0,2,4,6,8;每台机器是5个线程并发处理任务。
通过任务分片可以实现任务并发处理,通过增加机器可以实现动态扩容/缩容。