目录
一:JS开销以及如何缩短解析时间
二:配合V8有效优化代码
2.1.抽象语法树
2.2.V8优化机制
三:函数优化
四:对象优化
4.1.以相同顺序初始化对象成员,避免隐藏类的调整
4.2.实例化后避免添加新属性
4.3.尽量使用 Array 代替 array-like 对象
4.4.避免读取超过数组的长度
4.5.避免元素类型转换
五:HTML优化
六:CSS优化
一:JS开销以及如何缩短解析时间
JS 开销在哪
除了必要的加载外,还有解析编译以及代码的执行

在资源大小相同的情况下,JS 开销更高

以Reddit网站为例,在总共的网络加载过程中,已经压缩后的 1.4 M JS 在整个网络加载耗时中占 1/3

解决方案:
-
Code Splitting:代码拆分,按需加载
当前路径需要哪些资源就加载哪些资源,不需要的延迟加载或访问需要它的页面再加载
-
Tree Shaking:代码减重
形象来说就是摇一棵树,树上枯萎的叶子就会掉下来。即如果有代码用不到,就不打包进来
从JS的解析和执行来看,减少主线程工作量:
-
避免长任务
-
避免超过 1KB 的行间脚本
行间脚本是一个优化策略,比如要加快首屏加载时间,可以把 JS 和 CSS 都行间化,其余通过 Web 文件加载
-
使用 rAF 和 rAC进行调度
Progressive Bootstrapping(渐进式启动):
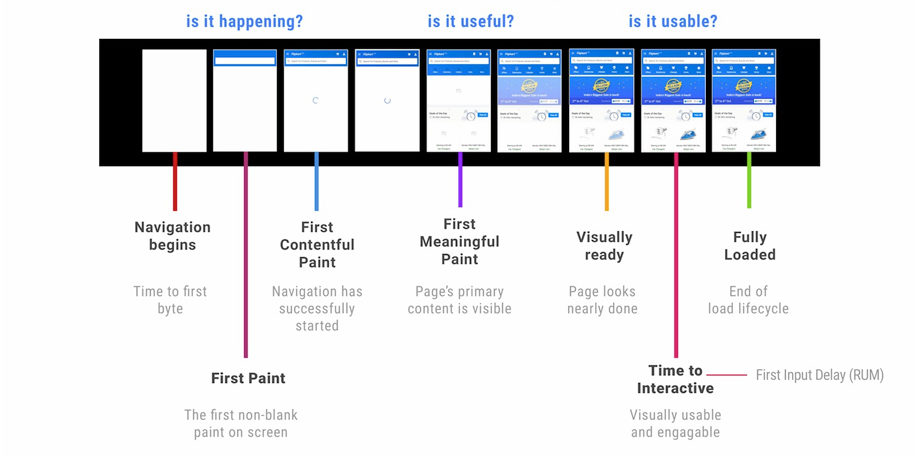
主要关注三部分:网站是否加载?是否出现有用的信息?是否可交互?
二:配合V8有效优化代码
V8是Chrome浏览器的JS引擎,也是目前做的最好、效率最高的一个引擎,node.js也是采用了这一引擎。
当 Chrome 或 Node 要执行一段 JS 代码时,首先会进行解析(Parse it),并将其翻译成一个抽象语法树(AST),之后把文本识别成字符,然后把重要信息提取出来,变成一些节点存储在一定的数据结构里(Interpreter)。最后把代码编成机器码之前,编译器会进行优化工作(Optimize Compiler),但是有时它自动优化工作并不一定合适(逆优化),所以我们需要在代码层面做的优化尽量满足它的优化条件,之后按照它的期望代码去写即可

2.1.抽象语法树
- 源码 -> 抽象语法数 -> 字节码 Bytecode -> 机器码
- 编译过程进行优化
- 运行时可能发生反优化
比如下面这个例子,是否注释掉add(num1, 's') 各执行一次来观察 duration 持续时间。在执行函数时,发现参数类型发生变化,运行时不能用已经做过的优化逻辑了,就会把刚做的优化撤销,会造成一定的延时
const { performance, PerformanceObserver } = require('perf_hooks')
const add = (a, b) => a + b
const num1 = 1
const num2 = 2
performance.mark('start')
for (let i = 0; i < 10000000; i++) {
add(num1, num2)
}
// add(num1, 's')
for (let i = 0; i < 10000000; i++) {
add(num1, num2)
}
performance.mark('end')
const observer = new PerformanceObserver(list => {
console.log(list.getEntries()[0])
})
observer.observe({ entryTypes: ['measure'] })
performance.measure('测量', 'start', 'end')
/*
// 没注释 add(num1, 's')
PerformanceEntry {
name: '测量',
entryType: 'measure',
startTime: 30.1886,
duration: 50.1463
}
// 注释 add(num1, 's')
PerformanceEntry {
name: '测量',
entryType: 'measure',
startTime: 27.3498,
duration: 19.102599
}
*/
如果想进一步了解 V8 做了什么优化,可以利用 Node 的两个参数(trace-opt、trace-deopt)
node --trace-opt --trace-deopt test.js
2.2.V8优化机制
脚本流
脚本正常情况要先进行下载再进行解析最后再执行的过程,Chrome 在这里做了优化,在下载过程中可以同时进行解析就可以加快这个过程。当下载一个超过 30 KB 的脚本时,可以先对这 30 KB 内容进行解析,会单独开一个线程去给这段代码进行解析,等整个都下载完在完成时再进行解析合并,最后就可以执行,效率就大大提高了,这是流式处理的一个特点
字节码缓存
有些东西使用频率比较高,可以把它进行缓存,再次进行访问时就可以加快访问。源码被翻译成字节码之后,发现有一些不仅在当前页面有使用,在其他页面也会有使用的片段,就可以把这些片段对应的字节码缓存起来,在其他页面再次进行访问相同逻辑时,直接从缓存去取即可,不需要再进行翻译过程,效率就大大提高了
懒解析
对于函数而言,虽然声明了这个函数,但是不一定会马上用它,默认情况下会进行懒解析(先不去解析函数内部的逻辑,当使用时再去解析函数内部逻辑),效率就大大提高了
三:函数优化
lazy parsing 懒解析与 eager parsing 饥饿解析
对于函数而言,默认情况下会进行懒解析。但是在实际情况下,有时我们需要它立即执行,这样函数由原来的懒解析快速变为饥饿解析,这样效率反而会降低了一些
其实,只是加一对括号 () 即可把懒解析变为饥饿解析
const add = (a, b) => a*b // lazy parsing
const add = ((a, b) => a*b) // eager parsing但是当我们使用 某些工具进行代码压缩时,这对括号会被去掉,这样就导致本来想做的事情,没办法通知到解析器,这时就可以使用Optimize.js工具来恢复括号
四:对象优化
目的:迎合 V8 引擎进行解析,把你的代码进行优化。因为它也是用代码写的,所做的优化其实也是代码实现的规则,如果我们的代码迎合了这些规则,就可以帮你去做优化,代码效率可以得到提升。下面分成几部分分别进行说明
4.1.以相同顺序初始化对象成员,避免隐藏类的调整
JS 是弱类型语言,写的时候不会声明和强调它变量的类型,但是对于编辑器而言,实际上还是需要知道确定的类型。在解析时,它根据自己的推断,会给这些变量赋一个具体的类型,通常管这些类型叫隐藏类型HC(hidden class),之后所做的优化都是基于隐藏类型进行的
隐藏类型底层会以描述的数组进行存储,数组里会去强调所有属性声明的顺序,或者说索引,索引的位置
class RectArea { // HC0
constructor(l, w) {
this.l = l // HC1
this.w = w // HC2
}
}
// 当我们声明了矩形面积类之后,创建第一个HC0
const rect1 = new RectArea(3, 4)
// 接下来再创建实例时,还能按照这个复用所有隐藏类
const rect2 = new RectArea(5, 6)
//下面举一个反例
// car1声明对象的时候会创建一个隐藏类 HC0
const car = { color: 'red' }
// 追加属性会再创建个隐藏类型 HC1
car1.seats = 4
// car2声明时,HC0的属性是关于color的属性,car2声明的是关于seats的属性,所以没办法复用,只能再创建 HC2
const car2 = { seats: 2 }
// HC1是包含了color和seats两个属性,所以没有可复用的隐藏类,创建 HC3
car2.color = 'blue'
4.2.实例化后避免添加新属性
// In-Object属性
const car = { color: 'red' }
// Normal/Fast属性,存储property store里,需要通过描述数组间接查找
car1.seats = 4
4.3.尽量使用 Array 代替 array-like 对象
array-like 对象:JS 里都有一个 arguments 对象,包含了函数参数变量的信息,本身是一个对象,但是可以通过索引去访问里面的属性,它还有 length 属性,像是一个数组,但又不是数组,不具备数组上面的方法,比如:forEach
V8 引擎会对数组能极大性能优化,目前有 21 种不同的元素类型,最好是把类数组转成数组再进行遍历,这样会比不去转成数组直接遍历效率高
// 不如在真实数组上效率高
Array.prototype.forEach.call(arrObj, (val, index) => {
console.log(`${index}:${value}`)
})
//转换的代价比优化的影响要小
const arr = Array.prototype.slice.call(arrObj, 0)
arr.forEach((value, index) => {
console.log(`${index}:${value}`)
})
4.4.避免读取超过数组的长度
越界比较会造成原型链额外的查找,性能相差 6 倍
function foo(arr) {
// <= 目的:把超过边界的值也比较进来
//如果在数组对象里找不到,会沿着原型链向上找,所以会进行额外的开销
Array.prototype['3'] = 10000
for (let i = 0; i <= arr.length; i++) {
if (arr[i] > 1000) {
console.log(arr[i])
}
}
}
foo([10, 100, 1000])
4.5.避免元素类型转换
JavaScript 是不区分整数、浮点数和双精度,它们都是数字,但是在编辑器里会对这个做出精确的区分,如果使数组里面类型发生变化,就会造成额外的开销,效率就不高了
const arr = [3, 2, 1] // PACKED_SMI_ELEMENTS
arr.push(4.4) // PACKED_DOUBLE_ELEMENTS
V8 之所以做这个区别是因为 PACKED 数组的操作比在 HOLEY 数组上的操作更利于进行优化。对于 PACKED 数组,大多数操作可以有效执行。相比之下, HOLEY 数组的操作需要对原型链进行额外的检查和昂贵的查找。
V8 将这个变换系统实现为格(数学概念)。这是一个简化的可视化,仅显示最常见的元素种类:
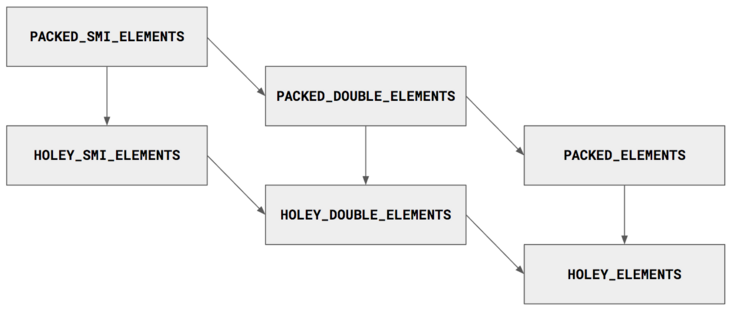
只能通过格子向下过渡。一旦将单精度浮点数添加到 Smi 数组中,即使稍后用 Smi 覆盖浮点数,它也会被标记为 DOUBLE。类似地,一旦在数组中创建了一个洞,它将被永久标记为有洞 HOLEY,即使稍后填充它也是如此。
一般来说,更具体的元素种类可以进行更细粒度的优化。元素类型的在格子中越是向下,该对象的操作越慢。为了获得最佳性能,请避免不必要的不具体类型 - 坚持使用符合您情况的最具体的类型。
五:HTML优化
减少 iframes 使用:
额外添加了文档,需要加载的过程,也会阻碍父文档的加载过程,也就是说如果它加载不完成,父文档本身的 onload 事件就不会触发,一直等着它。在 iframe 里创建的元素,比在父文档创建同样的元素,开销要高出很多
如果非得用 iframe,可以做个延时加载
<iframe id="iframe"></iframe>
<script>
document.getElementById('iframe').setAttribute('src', url)
</script>
压缩空白符、删除无用注释:
编程时,为了方便阅读,会留空行和换行,最后打包要把空白符去掉
避免节点深层次嵌套:
嵌套越深消耗越高,节点越多最后生成 DOM 树占用内存会比较高
避免使用 table 布局:
table 布局本身有很多问题,使用起来没有那么灵活,造成的开销比较大
CSS&JavaScript尽量外链:
容易造成HTML文件过大,后期引擎也不好去做优化。例外:首屏优化时需要考虑使用外链
删除元素默认属性:
本身默认那些值,没必要写出来,写出来就添加了额外的字符,造成了不必要的浪费
借助工具:
html-minifier
六:CSS优化
利用 DevTools 测量样式计算开销
在谷歌开发者工具的Performance性能卡里,Recalculate Style即为样式计算所开销的时间
降低 CSS 对渲染的阻塞
要尽早完成对CSS的下载,尽早完成解析;降低CSS的大小,先加载有用的部分
利用 GPU 完成动画
不进行回流重绘,只需要进行复合
使用 font-display 属性
可以帮助我们让文字更早显示在页面上,减轻文字闪动
使用 contain 属性
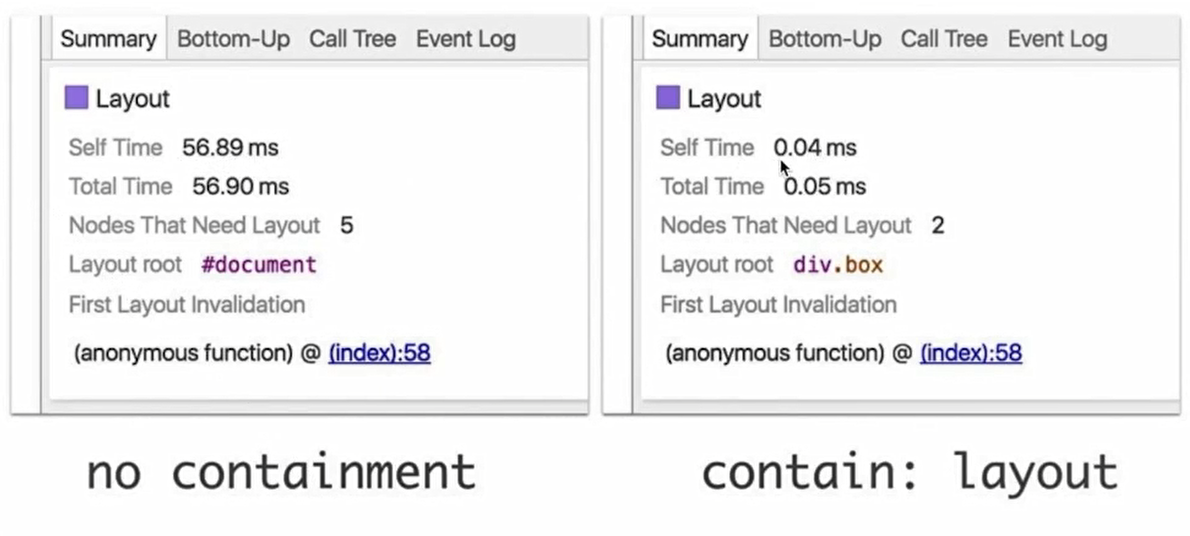
contain 是开发者和浏览器进行沟通的一个属性,通过contain:layout 告诉浏览器,盒子里所有的子元素和盒子外面的元素之间没有任何布局上的关系。这样浏览器就可以对盒子里面的元素进行单独处理,不需要管理页面上其他的部分,这样就可以大大减少回流计算



![[Kettle] CSV文件输入](https://img-blog.csdnimg.cn/42ff45cb36974447a7c2ac6503bea87b.png)