1 背景
传统训练的 GPT 模型只能根据前文内容预测后文内容,但有些应用比如代码生成器,需要我们给出上文和下文,使模型可以预测中间的内容,传统训练的 GPT 就不能完成这类任务。
传统训练的 GPT 只能根据上文预测下文
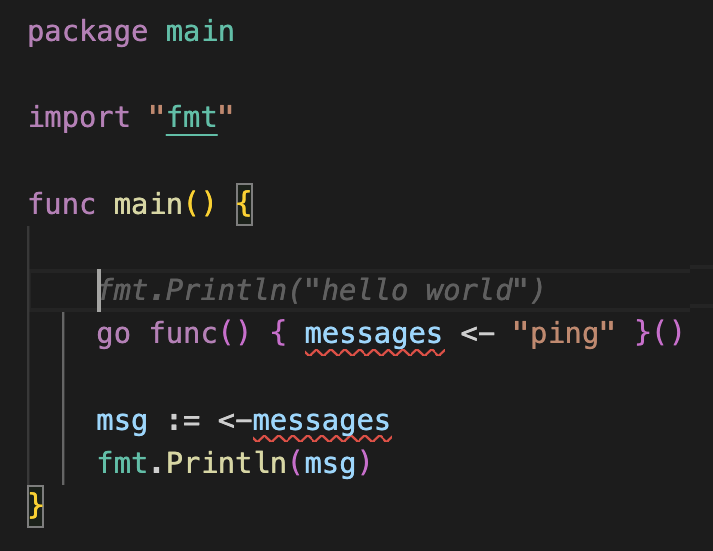
使用 FIM 训练的能够正确填充中间部分
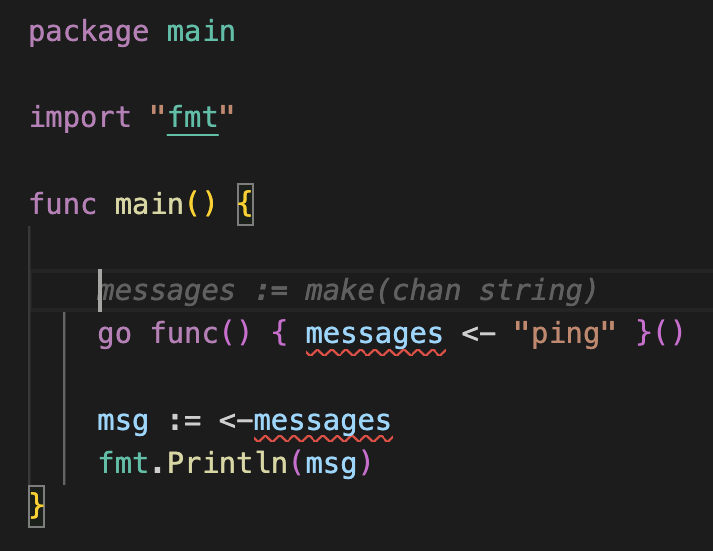
FIM 是一种新的训练技巧,使得 GPT 类模型能够根据上下问填充中间部分。
2 原理
通过添加特殊 token, 使得训练数据包含上下文内容
原文


调换 suffix 与 middle 位置,此为 PSM 模式
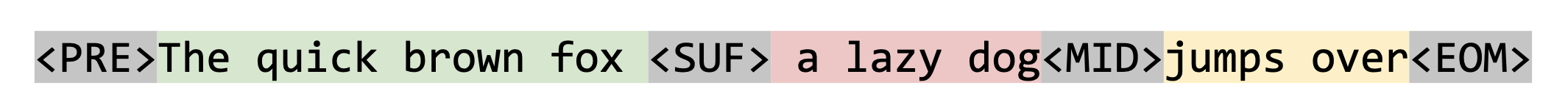
另外还有 SPM 模型。
3 代码
import os
import random
import numpy as np
import torch
import numpy as np
import tiktoken
## Adapted from https://github.com/bigcode-project/Megatron-LM/blob/6c4bf908df8fd86b4977f54bf5b8bd4b521003d1/megatron/data/gpt_dataset.py
def permute(
sample,
np_rng,
suffix_tok_id,
prefix_tok_id,
middle_tok_id,
pad_tok_id,
fim_rate=0.5,
fim_spm_rate=0.5,
truncate_or_pad=False,
):
"""
Take in a sample (list of tokens) and perform a FIM transformation on it with a probability of fim_rate, using two FIM modes:
PSM and SPM (with a probability of fim_spm_rate).
"""
if np_rng.binomial(1, fim_rate): # 二项分布,以 fim_rate 的概率生成 1, 1-fim_rate的概率生成 0
boundaries = list(np_rng.randint(low=0, high=len(sample) + 1, size=2)) # 随机生成两个位置索引, 数值中间部分为 middle
boundaries.sort()
# 分割前、中、后
prefix = np.array(sample[: boundaries[0]], dtype=np.int64)
middle = np.array(sample[boundaries[0] : boundaries[1]], dtype=np.int64)
suffix = np.array(sample[boundaries[1] :], dtype=np.int64)
if truncate_or_pad:
new_length = suffix.shape[0] + prefix.shape[0] + middle.shape[0] + 3
diff = new_length - len(sample)
if diff > 0:
if suffix.shape[0] <= diff: # suffix 后缀长度小于 diff/3, 原样返回
return sample, np_rng
suffix = suffix[: suffix.shape[0] - diff] # 裁剪后缀使sample长度保持不变
elif diff < 0:
suffix = np.concatenate([suffix, np.full((-1 * diff), pad_tok_id)]) # (-1 * diff) 负负得正
# 内部以 fim_spm_rate 的概率做 spm 变换,以 1-fim_spm_rate 的概率做 PSM 变换
if np_rng.binomial(1, fim_spm_rate):
# SPM (variant 2 from FIM paper)
new_sample = np.concatenate(
[
[prefix_tok_id, suffix_tok_id],
suffix,
[middle_tok_id],
prefix,
middle,])
else:
# PSM
new_sample = np.concatenate(
[
[prefix_tok_id],
prefix,
[suffix_tok_id],
suffix,
[middle_tok_id],
middle,])
else:
# 不做任何改变。 don't do FIM preproc
new_sample = sample
return list(new_sample), np_rng
# 特殊字符
FIM_PREFIX = "<fim-prefix>"
FIM_MIDDLE = "<fim-middle>"
FIM_SUFFIX = "<fim-suffix>"
FIM_PAD = "<fim-pad>"
# bpe分词器
tokenizer = tiktoken.get_encoding("gpt2")
# In production, load the arguments directly instead of accessing private attributes
# See openai_public.py for examples of arguments for specific encodings
enc = tiktoken.Encoding(
# If you're changing the set of special tokens, make sure to use a different name
# It should be clear from the name what behaviour to expect.
name="cl100k_base_im",
pat_str=tokenizer._pat_str,
mergeable_ranks=tokenizer._mergeable_ranks,
special_tokens={
**tokenizer._special_tokens,
# 添加特殊字符
FIM_PREFIX: 50300,
FIM_MIDDLE: 50400,
FIM_SUFFIX: 50500,
FIM_PAD: 50600,
})
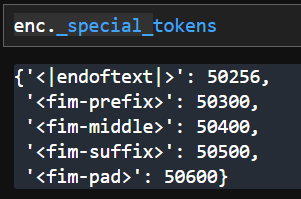
# 获取特殊符号id
suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id = (enc._special_tokens[tok] for tok in [FIM_SUFFIX, FIM_PREFIX, FIM_MIDDLE, FIM_PAD])
np_rng = np.random.RandomState(seed=0) # rng state for FIM
# 测试
sample = list(np.random.randint(0 , 100, (10, )))
_list = []
for i in range(10):
tmp = permute(
sample,
np_rng,
suffix_tok_id,
prefix_tok_id,
middle_tok_id,
pad_tok_id,
fim_rate=0.5,
fim_spm_rate=0.5,
truncate_or_pad=True,)
_list.append(tmp[0])
参考:
Efficient Training of Language Models to Fill in the Middle
loubnabnl/santacoder-finetuning
gpt_dataset.py
tiktoken/core.py
Code Llama — A Comprehensive Overview
Why your AI Code Completion tool needs to Fill in the Middle








![[学习笔记]SQL Server中批量查找所有符合Where条件的记录](https://img-blog.csdnimg.cn/direct/a585ee4b154f4444bed4f7055de6c679.png)