Brooks T, Holynski A, Efros A A. Instructpix2pix: Learning to follow image editing instructions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 18392-18402.
InstructPix2Pix 所做的任务是根据用户指令编辑图像。InstructPix2Pix 先使用预训练的 LLM 和 T2I 模型生成大量的训练样本,然后使用生成的样本训练一个条件 diffusion 模型。训练完成的 InstructPix2Pix 可以按用户指令的要求对输入图像进行编辑,包括替换元素、改变风格和背景等。由于图像编辑是发生在 diffusion 的正向过程中,因此训练完成的 InstructPix2Pix 可以在几秒内完成图像编辑,速度非常快。

目录
- 一. 研究思路
- 二. 生成多模态训练数据
- 1. GPT-3 微调
- 2. Stable Diffusion 修改
- 三. 训练 InstructPix2Pix 模型
- 四. 图像生成
- 五. 总结
- 六. 复现
一. 研究思路
InstructPix2Pix 的目的是按照人为指令进行图像编辑,因此模型只需要输入待编辑的图像和编辑指令,不需要其他任何描述或额外图像,训练完成后进行推理时也不需要额外的微调。但由于缺少训练数据,需要先自行生成大量(原始图像,编辑指令,编辑图像)对以供训练。
二. 生成多模态训练数据
InstructPix2Pix 将大语言模型 GPT-3 和文生图模型 Stable Diffusion 相结合,生成可用于训练的编辑指令和图像:
- 使用 GPT-3 生成原始图像标题 (Input Caption)、编辑指令 (Instruction) 和编辑图像标题 (Edited Caption);
- 使用 Stable Diffusion 根据原始图像和编辑图像的标题生成原始图像和编辑图像;
- 将原始图像、编辑指令和编辑图像打包,就得到了可用于训练的数据。

1. GPT-3 微调
使用 GPT-3 生成(原始图像标题,编辑指令,编辑图像标题)时,需要对 GPT-3 进行微调以达到生成 triplets 的目的:
- 在 LAION-Aesthetics V2 6.5+ 数据集上采样 700 个图像标题作为原始图像标题,然后人为标注对应的编辑指令和编辑图像标题;
- 使用这 700 组数据对 GPT-3 进行微调;
- 使用微调后的 GPT-3 生成 454445 组(原始图像标题,编辑指令,编辑图像标题);

如图所示,图中 Input LAION caption 一列都是取自 LAION,第二列和第三列的前一半是人工标注的,后一半浅绿色高亮的是 GPT-3 生成的。
2. Stable Diffusion 修改
使用 Stable Diffusion 根据(原始图像标题,编辑图像标题)生成(原始图像,编辑图像)时,最棘手的问题就是相似的标题描述可能会生成相差较大的图像,下图为 Stable Diffusion 分别根据 “photograph of a girl riding a horse” 和 “photograph of a girl riding a dragon” 生成的图像:

这显然不适合用于 InstructPix2Pix 的训练,因为编辑前后的背景、人物也完全不一样。于是引入了 Prompt-to-Prompt 1,通过在某些逆扩散过程中共享交叉注意力权重,使得 diffusion 生成相似的图像。
不仅如此,Prompt-to-Prompt 还可以调节逆扩散共享交叉注意力权重的系数 p p p,以达到不同编辑对图像变化大小的控制。但图像变化大小的控制很难直接从图像标题中得出,因此在实际应用中对 p ∼ U ( 0.1 , 0.9 ) p \sim \mathcal{U}(0.1,0.9) p∼U(0.1,0.9) 采样,生成 100 组图像再用 CLIP 进行筛选。
三. 训练 InstructPix2Pix 模型
InstructPix2Pix 初始化为预训练的 Stable Diffusion,使用生成的(原始图像,编辑指令,编辑图像)数据对进行训练:

因为 InstructPix2Pix 的输入同时包含原始图像和编辑指令,因此需要在 Stable Diffusion 文本条件 (text condition) 的基础上加上图像条件 (image condition),记文本条件为 c T c_T cT,图像条件为 c I c_I cI。 c T c_T cT 直接传入 text condition 的输入口即可; c I c_I cI 则在编码器 E E E 的压缩后与隐变量 z t z_t zt 拼接,因此需要在模型的第一个卷积层中增加额外的条件输入通道。
为了进一步提高图像生成效果以及模型对输入条件的遵循程度,InstructPix2Pix 还引入了 Classifier-free 引导策略。详见 UC伯克利提出AIGC图像编辑新利器InstructPix2Pix,AI模型P图更加精细。
四. 图像生成
在推理阶段,输入原始图像和编辑指令,InstructPix2Pix 就可以输出编辑后的图像:

五. 总结
InstructPix2Pix 借助 GPT-3 和 Stable Diffusion 生成大规模训练样本,再使用这些训练样本继续训练 Stable Diffusion,从而构建出一个具有更高智能的图像编辑模型 InstructPix2Pix。正因为 InstructPix2Pix 是在大规模数据中训练得到的,所以这是一个通用的图像编辑模型,使用前不需要根据特定任务再做微调,而可以在短暂的几秒内完成图像的编辑。InstructPix2Pix 的出现解决了此前图像编辑方法中存在的编辑指令不直接、不确定的问题,大大推进了 AIGC 的发展进程。
经过实验还发现,InstructPix2Pix 的应用局限于风格和背景的调整,对于局部元素的编辑、增加或删除,效果有待提高。
六. 复现
InstructPix2Pix 的训练需要先使用 GPT-3 和 Stable Diffusion 生成数百个 G 的数据集,再在 8 张 40GB NVIDIA A100 GPU 上训练 25.5 个小时。如果时间经费有限,建议直接使用开源的预训练模型做下游任务,README 中的 quickstart 写的相当简洁清晰,创建环境后下载预训练模型即可。
- 平台:AutoDL
- 显卡:A100-PCIE-40GB 40GB
- 镜像:PyTorch 2.0.0、Python 3.8(ubuntu20.04)、Cuda 11.8
- 源码:https://github.com/timothybrooks/instruct-pix2pix
实验记录:
- 一开始使用 RTX 3090,编辑图像时一直报错显示 GPU 驱动版本过低,升级驱动 也没成功。后来换成 A100,配有 535.129.03 版本驱动,就可以了;

- 创建完
ip2p虚拟环境后,使用conda activate指令无法激活环境,改为source activate即可; - 下载预训练模型时经常发生中断,如图所示还有没有读完的 bytes:

如果没有完全下载完成就执行任务,会出现RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory报错:

如下图没有 Left time 才是下载完成,下载完成后才可以执行图像编辑任务:

- 如果
bash scripts/download_checkpoints.sh总是下载中断,也可以手动执行脚本内指令,下载到本地再用 FillZilla 上传至 checkpoints 文件夹; - 第一次执行时需要下载模型文件和加载管道组件,费时较长,耐心等待即可。以后每次调用就可以直接加载;

实验结果:




可以看到,InstructPix2Pix 的主要应用场景还是图像风格和背景的编辑,对于元素替换以及增减这样的局部调整,效果有待提高:


Prompt-to-Prompt:基于 cross-attention 控制的图像编辑技术 ↩︎

![[学习笔记]SQL Server中批量查找所有符合Where条件的记录](https://img-blog.csdnimg.cn/direct/a585ee4b154f4444bed4f7055de6c679.png)



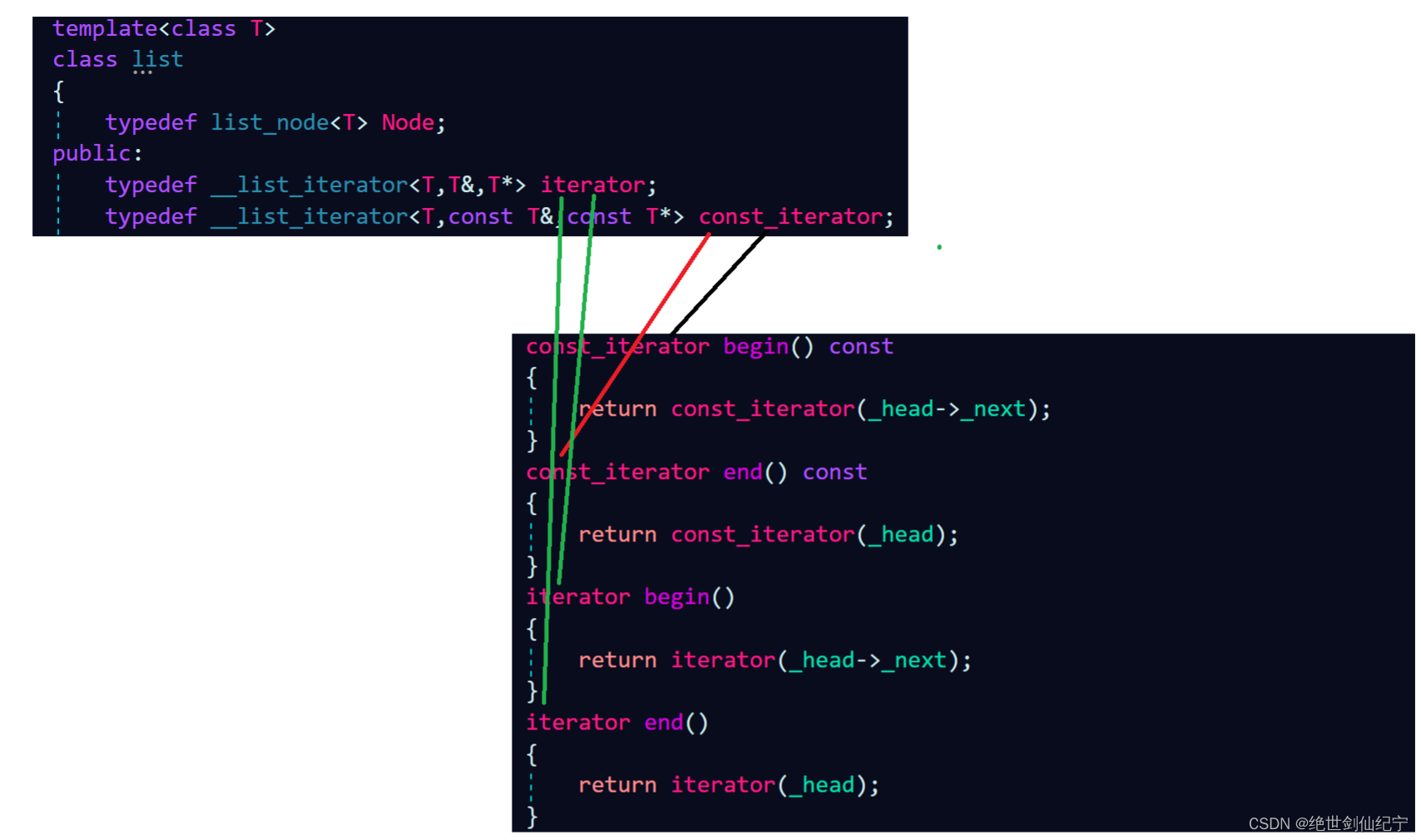
![力扣:77. 组合(回溯, path[:]的作用)](https://img-blog.csdnimg.cn/direct/65368cdafeb848ce8c20f426f1f5cc24.png)