本文介绍如何使用Langchain-Chatchat构建论文知识库和文件对话。
关于Langchain-Chatchat:
🤖️ 一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
💡 受 GanymedeNil 的项目 document.ai 和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。本项目的最新版本中通过使用 FastChat 接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
✅ 依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
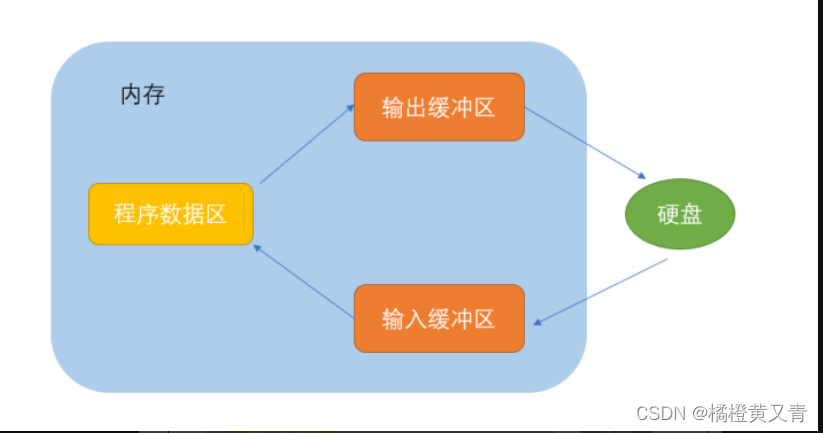
⛓️ 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
在按照本教程操作前,请确保完成Langchain-Chatchat的安装,其安装过程可以参考:
【大模型实践】Langchain-Chatchat安装体验(一)
一、新建知识库
点击新建知识库:

设置名字和介绍,点击新建:

上传论文(我这里上传了目标检测的几篇论文):

点击添加文件到知识库(这个步骤比较慢,请耐心等待):

后台正在处理PDF,比较慢:

知识库创建成功了:

二、知识库问答
回到对话页面,选择知识库问答:

从知识库列表选择新建的知识库:

现在可以提问了:

三、文件对话
选择文件对话模式:

上传文件:

选择文件:

基于文件进行对话:

本文介绍了langchain-chatchat的相关使用,使用的大模型是Chatglmv3-6b。
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。

![力扣:77. 组合(回溯, path[:]的作用)](https://img-blog.csdnimg.cn/direct/65368cdafeb848ce8c20f426f1f5cc24.png)





![[c]用指针进行四个数排序](https://img-blog.csdnimg.cn/direct/b4028fb131c54e56a1782b4141abe17c.png)