背景
为什么同样是男人,但有的男人'🧔♂️'.length === 5,有的男人'🧔♂'.length === 4呢?
这二者都是JS中的字符串,要理解本质原因,你需要明白JS中字符串的本质,你需要理解 String Unicode UTF8 UTF16 的关系。本文,深入二进制,带你理解它!
从 ASCII 说起
各位对这张 ASCII 表一定不陌生:

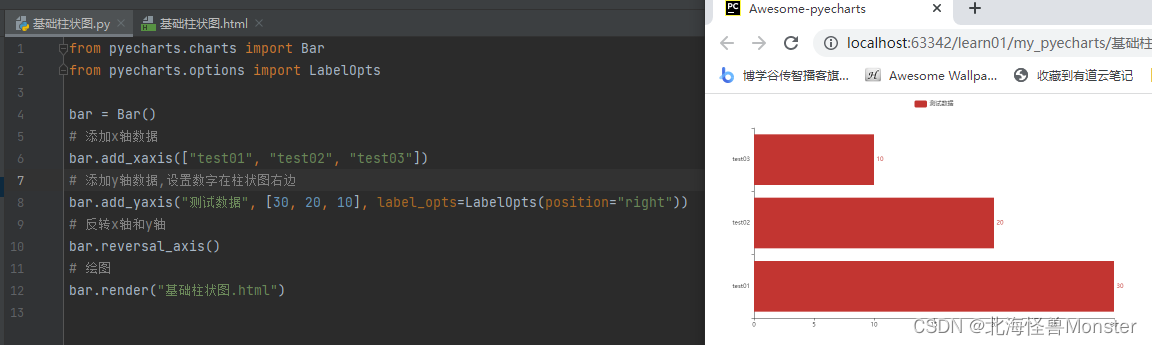
因为计算机只能存储0和1,如果要让计算机存储字符串,还是需要把字符串转成二进制来存。ASCII就是一直延续至今的一种映射关系:把8位二进制(首位为0)映射到了128个字符上。
从多语言到Unicode
但是世界上不止有英语和数字,还有各种各样的语言,计算机也应该能正确的存储、展示它们。
这时候,ASCII的128个字符,就需要被扩充。有诸多扩充方案,但思路都是一致的:把一个语言符号映射到一个编号上。有多少个语言符号,就有多少个编号。
至今,Unicode 已经成为全球标准。
The Unicode Consortium is the standards body for the internationalization of software and services. Deployed on more than 20 billion devices around the world, Unicode also provides the solution for internationalization and the architecture to support localization.
Unicode 联盟是软件和服务国际化的标准机构。 Unicode 部署在全球超过 200 亿台设备上,还提供国际化解决方案和支持本地化的架构。
Unicode是在ASCII的128个字符上扩展出来的。
例如,英文「z」的Unicode码是7A(即十进制的122,跟ASCII一致)。
Unicode中80(即128号)字符是,这是ASCII的128个字符(0-127)的后一个字符。
汉字「啊」的Unicode码是554A。
Emoji「🤔」的Unicode码是1F914。
从Unicode到Emoji
随着时代发展,人们可以用手机发短信聊天了,常常需要发送表情,于是有人发明了Emoji。Emoji其实也是一种语言符号,所以Unicode也收录了进来。

Unicode一共有多少
现在,Unicode已经越来越多了,它的编码共计111万个!(有实际含义的编码并没这么多)
目前的Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536(即2^4^4=2^16)个代码点。目前只用了少数平面。
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称TIP |
| 4号平面 至 13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) | Private Use Area-A,简称PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区) | Private Use Area-B,简称PUA-B |
以前只有ASCII的时候,共128个字符,我们统一用8个二进制位(因为log(2)128=7,取整得8),就一定能存储一个字符。
现在,Unicode有16*65536=1048576个字符,难道必须用log(2)1048576=20 向上取整24位(3个字节)来表示一个字符了吗?
那样的话,字母z就是00000000 00000000 01111010了,而之前用ASCII的时候,我们用01111010就可以表示字母z。也就是说,同样一份纯英文文件,换成Unicode后,扩大了3倍!1GB变3GB。而且大部分位都是0。这太糟糕了!
因此,Unicode只是语言符号和一些自然数的映射,不能直接用它做存储。
UTF8如何解决「文本大小变3倍问题」
答案就是:「可变长编码」,之前我在文章《太卷了!开发象棋,为了减少40%存储空间,我学了下Huffman Coding》提到过。
使用「可变长编码」,每个字符不一定都要用统一的长度来表示,针对常见的字符,我们用8个二进制位,不常见的字符,我们用16个二进制位,更不常见的字符,我们用24个二进制位。
这样,能够减少大部分场景的文件体积。这也是哈夫曼编码的思想。
要设计一套高效的「可变长编码」,你必须满足一个条件:它是「前缀码」。即通过前缀,我就能知道这个字符要占用多少字节。
而UTF8,就是一种「可变长编码」。
UTF8的本质
- UTF8可以把
2^21=2097152个数字,映射到1-4个字节(这个范围能够覆盖所有Unicode)。 - UTF8完全兼容ASCII。也就是说,在UTF8出现之前的所有电脑上存储的老的ASCII文件,天然可以被UTF8解码。
具体映射方法:
- 0-127,用
0xxxxxxx表示(共7个x) - 128-
2^11-1,用110xxxxx 10xxxxxx表示(共11个x) 2^11-2^16-1,用1110xxxx 10xxxxxx 10xxxxxx表示(共16个x)2^16-2^21-1,用11110xxx 10xxxxxx 10xxxxxx 10xxxxxx表示(共21个x)
不得不承认,UTF8确实有冗余,还有压缩空间。但考虑到存储不值钱,而且考虑到解析效率,它已经是最优解了。
UTF16的本质
回到本文开头的问题,为什么'🧔♂️'.length === 5,但'🧔♂'.length === 4呢?
你需要知道在JS中,字符串使用了UTF16编码(其实本来是UCS-2,UTF16是UCS-2的扩展)。
为什么JS的字符串不用UTF8?
因为JS诞生(1995)时,UTF8还没出现(1996)。
UTF16不如UTF8优秀,因为它用16个二进制位或32个二进制位映射一个Unicode。这就导致:
- 它涉及到大端、小端这种字节序问题。
- 它不兼容ASCII,很多老的ASCII文件都不能用了。
UTF16的具体映射方法:
| 16进制编码范围(Unicode) | UTF-16表示方法(二进制) | 10进制码范围 | 字节数量 |
|---|---|---|---|
| U+0000 - U+FFFF | xxxxxxxx xxxxxxxx (一共16个x) | 0-65535 | 2 |
| U+10000 - U+10FFFF | 110110xx xxxxxxxx 110111xx xxxxxxxx (一共20个x) | 65536-1114111 | 4 |
细心的你有没有发现个Bug?UTF16不是前缀码? 遇到
110110xx xxxxxxxx 110111xx xxxxxxxx,怎么判断它是1个大的Unicode字符、还是2个连续的小的Unicode字符呢?答案:其实,在
U+0000 - U+FFFF范围内,110110xx xxxxxxxx和110111xx xxxxxxxx都不是可见字符。也就是说,在UTF16中,遇到110110一定是4字节UTF16的前2字节的前缀,遇到110111一定是4字节UTF16的后2字节的前缀,其它情况,一定是2字节UTF16。这样,通过损失了部分可表述字符,UTF16也成为了「前缀码」。
JS中的字符串
在JS中,'🧔♂️'.length算的就是这个字符的UTF16占用了多少个字节。
我开发了个工具,用于解析字符串,把它的UTF8二进制和UTF16二进制都展示了出来。
工具地址:tool.hullqin.cn/string-pars…
我把2个男人,都放进去,检查一下他们的Unicode码:


发现区别了吗?
长度为4的,是1F9D4 200D 2642;长度为5的,是1F9D4 200D 2642 FE0F。
都是一个Emoji,但是它对应了多个Unicode。这是因为200D这个零宽连字符,一些复杂的emoji,就是通过200D,把不同的简单的emoji组合起来,展示的。当然不是任意都能组合,需要你字体中定义了那个组合才可以。
标题中的Emoji,叫man: beard,是胡子和男人的组合。
末尾的FE0F是变体选择符,当一个字符一定是emoji而非text时,它其实是可有可无的。
于是,就有的'🧔♂️'长,有的'🧔♂'短了。

![[附源码]Python计算机毕业设计 社区老人健康服务跟踪系统](https://img-blog.csdnimg.cn/f19c1b23ca474c379f53e7c74376e327.png)