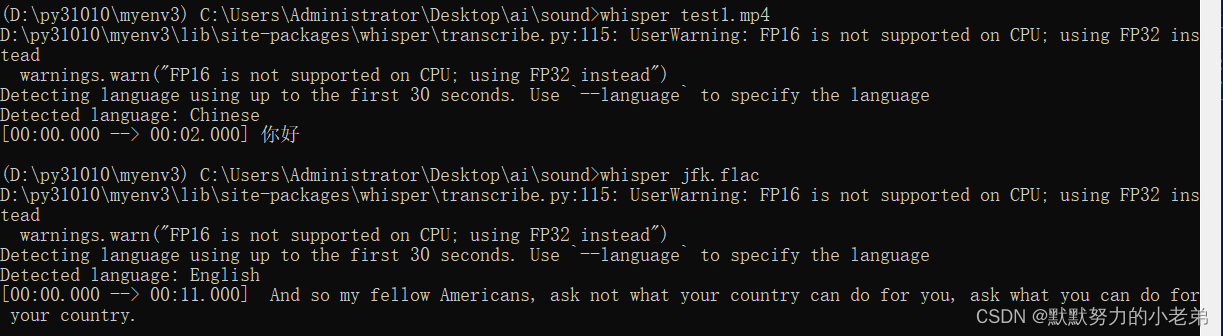
DDPM详解
参考 https://www.bilibili.com/video/BV1pa411u7G3/ 系列
DDPM 可以分为 Diffusion 和 Reverse 两个阶段。其中 Diffusion 阶段通过不断地对真实图片添加噪声,最终得到一张噪声图片。而 Reverse 阶段,模型需要学习预测出一张噪声图片中的噪声部分,然后减掉该噪声部分,即:去噪。随机采样一张完全噪声图片,通过不断地去噪,最终得到一张符合现实世界图片分布的真实图片。以下分别介绍两个阶段的具体原理与公式推导。
Diffusion 阶段
Diffusion 阶段就是不断地给真实图片加噪声,经过
T
T
T 步加噪之后,得到一张完全噪声图片。要理解 diffusion 阶段,首先要理解每一步噪声是如何加的。即:单步扩散的过程,即从
x
t
−
1
x_{t-1}
xt−1 到
x
t
x_t
xt 的加噪声过程。这里,我们记真实图片为
x
0
x_0
x0,中间过程的噪声图片为
x
1
,
.
.
.
x
T
−
1
x_1,...x_{T-1}
x1,...xT−1 ,最终的完全噪声图片为
x
T
x_T
xT 。则有,单步扩散过程公式:
x
t
=
1
−
β
t
x
t
−
1
−
β
t
z
t
z
t
∼
N
(
0
,
I
)
x_t=\sqrt{1-\beta_t}x_{t-1}-\sqrt{\beta_t}z_t\ \ \ z_t\sim\mathcal{N}(0,I)
xt=1−βtxt−1−βtzt zt∼N(0,I)
可以看到,就是在输入图像的基础上加一个高斯噪声
z
t
z_t
zt。其中
β
1
…
T
\beta_{1\dots T}
β1…T 是超参数,在 DDPM 原文 中,
β
1
…
T
\beta_{1\dots T}
β1…T 从
1
0
−
4
10^{-4}
10−4 到
2
×
1
0
−
2
2\times 10^{-2}
2×10−2 线性增加。

训练时,这样单步单步地加噪声效率太低了。想要提高训练效率。需要实现从原图 x 0 x_0 x0 一步到位得到 t t t 步的扩散结果 x t x_t xt,即我们现在已知的是 x t = f ( x t − 1 ) x_t=f(x_{t-1}) xt=f(xt−1) ,想要的是 x t = f ( x 0 ) x_t=f(x_0) xt=f(x0)
首先,记
α
t
=
1
−
β
t
\alpha_t=1-\beta_t
αt=1−βt ,则有:
x
t
=
α
t
x
t
−
1
+
1
−
α
t
z
t
x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}z_t
xt=αtxt−1+1−αtzt
将
x
t
−
1
x_{t-1}
xt−1 代换为
x
t
−
2
x_{t-2}
xt−2,将
x
t
−
2
x_{t-2}
xt−2 代换为
x
t
−
3
x_{t-3}
xt−3 ,直到
x
0
x_0
x0 ,推导如下:
x
t
=
α
t
x
t
−
1
+
1
−
α
t
z
t
=
α
t
(
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
t
−
1
)
+
1
−
α
t
z
t
=
α
t
α
t
−
1
x
t
−
2
+
α
t
−
α
t
α
t
−
1
z
t
−
1
+
1
−
α
t
z
t
\begin{aligned} x_t&=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}z_t \\ &=\sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}z_{t-1})+\sqrt{1-\alpha_t}z_t \\ &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{\alpha_t-\alpha_t\alpha_{t-1}}z_{t-1}+\sqrt{1-\alpha_t}z_t \end{aligned}
xt=αtxt−1+1−αtzt=αt(αt−1xt−2+1−αt−1zt−1)+1−αtzt=αtαt−1xt−2+αt−αtαt−1zt−1+1−αtzt
由于
z
t
z_t
zt、
z
t
−
1
z_{t-1}
zt−1 是两次独立的对
N
(
0
,
I
)
\mathcal{N}(0,I)
N(0,I) 的采样,因此有:
α
t
−
α
t
α
t
−
1
z
t
−
1
∼
N
(
0
,
(
α
t
−
α
t
α
t
−
1
)
I
)
1
−
α
t
z
t
∼
N
(
0
,
(
1
−
α
t
)
I
)
α
t
−
α
t
α
t
−
1
z
t
−
1
+
1
−
α
t
z
t
∼
N
(
0
,
(
1
−
α
t
α
t
−
1
)
I
)
\sqrt{\alpha_t-\alpha_t\alpha_{t-1}}z_{t-1}\sim\mathcal{N}(0,(\alpha_t-\alpha_t\alpha_{t-1})I) \\ \sqrt{1-\alpha_t}z_t\sim\mathcal{N}(0,(1-\alpha_t)I) \\ \sqrt{\alpha_t-\alpha_t\alpha_{t-1}}z_{t-1}+\sqrt{1-\alpha_t}z_t\sim\mathcal{N}(0,(1-\alpha_t\alpha_{t-1})I)
αt−αtαt−1zt−1∼N(0,(αt−αtαt−1)I)1−αtzt∼N(0,(1−αt)I)αt−αtαt−1zt−1+1−αtzt∼N(0,(1−αtαt−1)I)
再结合重参数化技巧,有:
x
t
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
z
,
z
∼
N
(
0
,
I
)
x_t=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}z,\ \ \ \ z\sim\mathcal{N}(0,I)
xt=αtαt−1xt−2+1−αtαt−1z, z∼N(0,I)
推到
x
0
x_0
x0,有:
x
t
=
α
t
α
t
−
1
…
α
1
x
0
+
1
−
α
t
α
t
−
1
…
α
1
z
,
z
∼
N
(
0
,
I
)
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
,
记
α
ˉ
t
=
∏
i
=
1
T
α
i
\begin{aligned} x_t&=\sqrt{\alpha_t\alpha_{t-1}\dots\alpha_1}x_0+\sqrt{1-\alpha_t\alpha_{t-1}\dots\alpha_1}z,\ \ \ \ \ z\sim\mathcal{N}(0,I) \\ &=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}z,\ \ \ \ \ \ 记\bar{\alpha}_{t}=\prod_{i=1}^T\alpha_i \end{aligned}
xt=αtαt−1…α1x0+1−αtαt−1…α1z, z∼N(0,I)=αˉtx0+1−αˉtz, 记αˉt=i=1∏Tαi
diffusion 阶段总结:
-
单步扩散 ( x t − 1 → x t x_{t-1}\rightarrow x_t xt−1→xt): x t = α t x t − 1 + 1 − α t z t x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}z_t xt=αtxt−1+1−αtzt
-
一步到位 ( x 0 → x t x_0\rightarrow x_t x0→xt): x t = α ˉ t x t − 1 + 1 − α ˉ t z x_t=\sqrt{\bar\alpha_t}x_{t-1}+\sqrt{1-\bar\alpha_t}z xt=αˉtxt−1+1−αˉtz
reverse阶段
如下图所示,我们先简单看下 diffusion 训练的过程。假设一个 batch size 为 4,最大时间步 T = 1000 T=1000 T=1000 。首先从均匀分布 U ( 1 , 1000 ) U(1,1000) U(1,1000) 中采样出 4 个对应的时间步 t t t。然后使用我们的一步到位加噪公式得到噪声图。训练一个神经网络(通常是 UNet)得到预测噪声 z ~ \tilde{z} z~,计算其与实际添加噪声 z z z 的损失 l o s s ( z , z ~ ) loss(z,\tilde{z}) loss(z,z~) ,反传梯度,更新网络权重。

在训练完成后,采样推理生图时,该怎么做呢?直觉上,我们已经有噪声的估计值
z
~
\tilde{z}
z~ ,那么根据一步到位公式(式 (6)),可以直接算出真实图片
x
0
x_0
x0 :
x
0
=
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
~
)
x_0=\frac{1}{\sqrt{\bar\alpha_t}}(x_t-\sqrt{1-\bar\alpha_t}\tilde{z})
x0=αˉt1(xt−1−αˉtz~)
但实际上,这种一步到位 reverse 的生图效果很差。在生图时,我们最好还是按照 diffusion 过程原始的定义,单步去噪。即由
x
T
x_T
xT 估计出
x
T
−
1
x_{T-1}
xT−1,再到
x
T
−
2
x_{T-2}
xT−2,一直单步到
x
0
x_0
x0 。为了完成这种单步 reverse 的过程,我们需要推导出根据
x
t
x_t
xt 和预测出的噪声
z
~
\tilde{z}
z~ 如何计算
x
t
−
1
x_{t-1}
xt−1,即
x
t
−
1
=
f
(
x
t
,
z
~
)
x_{t-1}=f(x_t,\tilde{z})
xt−1=f(xt,z~) 。即下图红线所示

我们要推的是
x
t
→
x
t
−
1
x_{t}\rightarrow x_{t-1}
xt→xt−1 的过程,即条件概率
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt),根据贝叶斯公式,有:
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
)
q
(
x
t
)
q(x_{t-1}|x_t)=\frac{q(x_t|x_{t-1})q(x_{t-1})}{q(x_t)}
q(xt−1∣xt)=q(xt)q(xt∣xt−1)q(xt−1)
注意
q
(
x
t
∣
x
t
−
1
)
q(x_t|x_{t-1})
q(xt∣xt−1) 和
q
(
x
t
∣
x
0
)
q(x_t|x_0)
q(xt∣x0) 分别就是我们前向 diffusion 过程中的单步扩散和一步到位的公式,它们都可以写成高斯分布的形式,即分别有:
x
t
=
α
t
x
t
−
1
−
1
−
α
t
z
t
∼
N
(
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
∼
N
(
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
x_t=\sqrt{\alpha_t}x_{t-1}-\sqrt{1-\alpha_t}z_t\sim\mathcal{N}(\sqrt{\alpha_t}x_{t-1},\ \ (1-\alpha_t)I)\\ x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}z\sim\mathcal{N}(\sqrt{\bar{\alpha}_t}x_0,\ \ (1-\bar{\alpha}_t)I)
xt=αtxt−1−1−αtzt∼N(αtxt−1, (1−αt)I)xt=αˉtx0+1−αˉtz∼N(αˉtx0, (1−αˉt)I)
然后,$q(x_{t-1}|x_t) $ 式中的三项可分别写为:
q
(
x
t
∣
x
t
−
1
)
∼
N
(
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
,
式
9
(
1
)
单步扩散
q
(
x
t
)
∼
N
(
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
,
式
9
(
2
)
一步到位
q
(
x
t
−
1
)
∼
N
(
α
ˉ
t
−
1
x
0
,
(
1
−
α
ˉ
t
−
1
)
I
)
,
式
9
(
2
)
一步到位
q(x_t|x_{t-1})\sim\mathcal{N}(\sqrt{\alpha_t}x_{t-1},\ \ (1-\alpha_t)I), \ \ \ 式9(1)单步扩散\\ q(x_t)\sim\mathcal{N}(\sqrt{\bar{\alpha}_t}x_0,\ \ (1-\bar{\alpha}_t)I), \ \ \ 式9(2)一步到位\\ q(x_{t-1})\sim\mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0,\ \ (1-\bar{\alpha}_{t-1})I), \ \ \ 式9(2)一步到位
q(xt∣xt−1)∼N(αtxt−1, (1−αt)I), 式9(1)单步扩散q(xt)∼N(αˉtx0, (1−αˉt)I), 式9(2)一步到位q(xt−1)∼N(αˉt−1x0, (1−αˉt−1)I), 式9(2)一步到位
而在已知高斯分布的均值和方差时,有正比关系:
N
(
μ
,
σ
2
)
∝
exp
(
−
1
2
(
x
−
μ
)
2
σ
2
)
N(\mu,\sigma^2)\propto\text{exp}(-\frac{1}{2}\frac{(x-\mu)^2}{\sigma^2})
N(μ,σ2)∝exp(−21σ2(x−μ)2), 将上面几个高斯分布的均值和方差分别代入,有:
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
)
q
(
x
t
)
∝
exp
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
1
−
α
t
+
(
x
t
−
1
−
α
t
−
1
x
0
)
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
t
x
0
)
2
1
−
α
ˉ
t
)
)
\begin{aligned} q(x_{t-1}|x_t)&=\frac{q(x_t|x_{t-1})q(x_{t-1})}{q(x_t)} \\ &\propto\text{exp}(-\frac{1}{2} (\frac{(x_t-\sqrt{\alpha_t}x_{t-1})^2}{1-\alpha_t}+\frac{(x_{t-1}-\sqrt{\alpha_{t-1}}x_0)^2}{1-\bar{\alpha}_{t-1}}-\frac{(x_t-\sqrt{\alpha_t}x_0)^2}{1-\bar{\alpha}_{t}})) \end{aligned}
q(xt−1∣xt)=q(xt)q(xt∣xt−1)q(xt−1)∝exp(−21(1−αt(xt−αtxt−1)2+1−αˉt−1(xt−1−αt−1x0)2−1−αˉt(xt−αtx0)2))
注意,我们的目标是求分布
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) ,我们也将其形式化为一个高斯分布。可以观察到,目前我们推导的结果是一个
x
t
−
1
x_{t-1}
xt−1 的二次式,将其配方,找到我们关心的
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) 的均值和方差。 配方有:
q
(
x
t
−
1
∣
x
t
)
∝
exp
(
−
1
2
[
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
]
x
t
−
1
2
−
2
[
α
t
x
t
β
t
+
α
ˉ
t
−
1
x
0
1
−
α
ˉ
t
−
1
]
x
t
−
1
+
?
)
∝
exp
(
−
1
2
A
x
t
−
1
2
+
B
x
t
−
1
+
C
)
∝
exp
(
−
1
2
⋅
A
(
x
t
−
1
+
B
2
A
)
2
+
?
)
\begin{aligned} q(x_{t-1}|x_t)&\propto\text{exp}(-\frac{1}{2}[\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar\alpha_{t-1}}]x^2_{t-1}-2[\frac{\sqrt{\alpha_t}x_t}{\beta_t}+\frac {\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_{t-1}}]x_{t-1}+?) \\ &\propto\text{exp}(-\frac{1}{2}Ax^2_{t-1}+Bx_{t-1}+C) \\ &\propto\text{exp}(-\frac{1}{2}\cdot A(x_{t-1}+\frac{B}{2A})^2+?) \end{aligned}
q(xt−1∣xt)∝exp(−21[βtαt+1−αˉt−11]xt−12−2[βtαtxt+1−αˉt−1αˉt−1x0]xt−1+?)∝exp(−21Axt−12+Bxt−1+C)∝exp(−21⋅A(xt−1+2AB)2+?)
别忘了
α
t
=
1
−
β
t
\alpha_t=1-\beta_t
αt=1−βt 。
C
C
C 的具体值是多少我们不关心,这样我们就得到均值和方差:
μ
=
−
B
2
A
,
σ
2
=
1
A
\mu=-\frac{B}{2A},\ \ \ \sigma^2=\frac{1}{A}
μ=−2AB, σ2=A1
其中,
A
=
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
,
B
=
−
2
(
α
t
x
t
β
t
+
α
ˉ
t
−
1
x
0
1
−
α
ˉ
t
−
1
)
A=\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}},\ \ \ B=-2(\frac{\sqrt{\alpha_t}x_t}{\beta_t}+\frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_{t-1}})
A=βtαt+1−αˉt−11, B=−2(βtαtxt+1−αˉt−1αˉt−1x0)
整理得方差:
σ
2
=
1
A
=
1
/
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
=
1
/
(
α
t
−
α
t
α
t
−
1
+
β
t
β
t
(
1
−
α
ˉ
t
−
1
)
)
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
\begin{aligned} \sigma^2&=\frac{1}{A}=1/(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}) \\ &=1/(\frac{\alpha_t-\alpha_t\alpha_{t-1}+\beta_t}{\beta_t(1-\bar{\alpha}_{t-1})}) \\ &=\frac{1-\bar{\alpha}_{t-1}}{1-\bar\alpha_t}\beta_t \end{aligned}
σ2=A1=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αtαt−1+βt)=1−αˉt1−αˉt−1βt
均值:
μ
=
−
B
2
A
=
(
α
t
x
t
β
t
+
α
ˉ
t
−
1
x
0
1
−
α
ˉ
t
)
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
=
α
t
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
\begin{aligned} \mu&=-\frac{B}{2A}=(\frac{\sqrt{\alpha_t}x_t}{\beta_t}+\frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_t})\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t \\ &=\sqrt{\alpha_t}\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 \end{aligned}
μ=−2AB=(βtαtxt+1−αˉtαˉt−1x0)1−αˉt1−αˉt−1βt=αt1−αˉt1−αˉt−1xt+1−αˉtαˉt−1βtx0
我们发现,
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) 的方差完全由
α
,
β
\alpha,\beta
α,β 计算得出,这是设定好的超参数。而
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) 的均值是
x
t
x_t
xt 和
x
0
x_0
x0 的线性组合。目前其中
x
t
x_t
xt 是已知的,而
x
0
x_0
x0 也是未知的,我们还是把一步到位的 diffusion 过程的公式转换而来的式 (7) 代换
x
0
x_0
x0,则有:
μ
=
α
t
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
⋅
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
~
)
\mu=\sqrt{\alpha_t}\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}x_t+\frac{\sqrt{\bar\alpha_{t-1}}\beta_t}{1-\bar\alpha_t}\cdot\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t-\sqrt{1-\bar{\alpha}_t}\tilde{z})
μ=αt1−αˉt1−αˉt−1xt+1−αˉtαˉt−1βt⋅αˉt1(xt−1−αˉtz~)
到这里,我们发现
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) 的均值由已知的
x
t
x_t
xt 和模型预测出的噪声
z
~
\tilde{z}
z~ 组成,而
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt) 的方差则由超参数计算得出。从而我们就得到了想要的
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt)。
继续整理一下:
μ
=
x
t
α
t
⋅
α
t
−
α
ˉ
t
+
β
t
1
−
α
ˉ
t
−
z
~
α
t
⋅
β
t
1
−
1
−
α
ˉ
t
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
~
)
\begin{aligned} \mu&=\frac{x_t}{\sqrt{\alpha_t}}\cdot\frac{\alpha_t- \bar\alpha_t+\beta_t}{1-\bar\alpha_t}-\frac{\tilde{z}}{\sqrt{\alpha_t}}\cdot\frac{\beta_t}{1-\sqrt{1-\bar\alpha_t}} \\ &=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\tilde{z}) \end{aligned}
μ=αtxt⋅1−αˉtαt−αˉt+βt−αtz~⋅1−1−αˉtβt=αt1(xt−1−αˉtβtz~)
即最终有:
q
(
x
t
−
1
∣
x
t
)
∼
N
(
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
~
)
,
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
I
)
q(x_{t-1}|x_t)\sim\mathcal{N}(\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\tilde{z}),\ \ \frac{1-\bar{\alpha}_{t-1}}{1-\bar\alpha_t}\beta_tI)
q(xt−1∣xt)∼N(αt1(xt−1−αˉtβtz~), 1−αˉt1−αˉt−1βtI)
最终,我们得到 reverse 过程的公式
x
t
−
1
=
f
(
x
t
,
z
~
)
x_{t-1}=f(x_t,\tilde{z})
xt−1=f(xt,z~):
x
t
−
1
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
~
)
+
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
z
z
~
=
UNet
(
x
t
,
t
)
,
z
∼
N
(
0
,
I
)
x_{t-1}=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\tilde{z})+\sqrt{\frac{1-\bar{\alpha}_{t-1}}{1-\bar\alpha_t}\beta_t}\ z \\ \tilde{z}=\text{UNet}(x_t,t),\ \ \ z\sim\mathcal{N}(0,I)
xt−1=αt1(xt−1−αˉtβtz~)+1−αˉt1−αˉt−1βt zz~=UNet(xt,t), z∼N(0,I)
这里有个问题:为什么每次计算上一步
x
t
−
1
x_{t-1}
xt−1 时,还要额外采样一个高斯噪声
z
z
z 加上去呢?其实,这是为了给 reverse 的过程带来一定的随机性,就像 LLM 每次采样也不一定是采概率最高的 token 一样,这也是对布朗运动的一种模拟。
总结
diffusion 过程
单步扩散:
x
t
=
α
t
x
t
−
1
+
1
−
α
t
z
t
x
t
∼
N
(
α
t
x
t
−
1
,
(
1
−
α
t
)
I
)
x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}z_t \\ x_t\sim\mathcal{N}(\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I)
xt=αtxt−1+1−αtztxt∼N(αtxt−1,(1−αt)I)
一步到位:
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
x
t
∼
N
(
α
ˉ
t
x
0
,
1
−
α
ˉ
t
z
)
x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}z \\ x_t\sim\mathcal{N}(\sqrt{\bar{\alpha}_t}x_0,\sqrt{1-\bar{\alpha}_t}z)
xt=αˉtx0+1−αˉtzxt∼N(αˉtx0,1−αˉtz)
diffusion 的过程就是一个退化的过程,不断地给真实图片加噪声,直到得到完全的高斯噪声图片。其中每一步都是在上一步的基础上加了一定量的噪声,这个 “量” 由一系列超参数
β
1...
T
\beta_{1...T}
β1...T 控制。
在训练时,每次都单步扩散得到下一步的噪声图效率较低。结合高斯分布的性质,我们可以通过一步到位的方法获取第 t t t 步的噪声图。
由于这两种表示中, x t x_t xt 都中都包含一个高斯分布项 z / z t z/z_t z/zt ,所以 x t x_t xt 也可以写为高斯分布的形式。
reverse过程
x t − 1 ∼ N ( μ , σ 2 I ) x_{t-1}\sim\mathcal{N}(\mu,\sigma^2I) xt−1∼N(μ,σ2I)
其方差和均值分别为:
σ
2
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
μ
=
α
t
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
~
)
\sigma^2=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t \\ \begin{aligned} \mu&=\sqrt{\alpha_t}\frac{1-\bar{\alpha}_{t-1}}{1- \bar{\alpha}_t}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 \\ &=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar\alpha}_t}\tilde{z}) \end{aligned}
σ2=1−αˉt1−αˉt−1βtμ=αt1−αˉt1−αˉt−1xt+1−αˉtαˉt−1βtx0=αt1(xt−1−αˉtβtz~)
从而有:
x
t
−
1
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
~
)
+
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
z
x_{t-1}=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\tilde{z})+\sqrt{\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t}\ z
xt−1=αt1(xt−1−αˉtβtz~)+1−αˉt1−αˉt−1βt z
reverse 的过程,虽然我们可以直接根据 diffusion 过程中一步到位的公式,从
x
T
x_T
xT 一步到
x
0
x_0
x0 。但从一个完全高斯分布一步到真实图片无疑是很困难的,这样得到的生图效果并不好。因此我们这里一步一步
x
T
,
x
T
−
1
,
…
,
x
0
x_T,x_{T-1},\dots,x_0
xT,xT−1,…,x0 ,从
x
T
x_T
xT 到
x
0
x_0
x0。
这就需要我们推导出从后到前相邻两步的关系,即 q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q(xt∣xt−1) ,或者表达成 x t − 1 = f ( x t , z ~ ) , z ~ = UNet ( x t , t ) x_{t-1}=f(x_t,\tilde{z}),\ \ \tilde{z}=\text{UNet}(x_t,t) xt−1=f(xt,z~), z~=UNet(xt,t) 。这里我们将 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt) 描述为一个高斯分布,然后分别推导出其方差和均值。其方差就是完全由超参数 α , β \alpha,\beta α,β 组成的一个式子。
而其均值可以写作两种形式,第一种是写成 x t x_t xt 和 x 0 x_0 x0 的线性组合的形式,注意这里的 x 0 x_0 x0 当然不是真实的 x 0 x_0 x0 (真实的 x 0 x_0 x0 是我们的终极目标),而是我们通过倒腾一步到位 diffusion 公式,根据 x t x_t xt 和 UNet 的预测值 z ~ \tilde{z} z~ 计算得到。也就是说,这里的 x 0 x_0 x0 是当前步的估计值。从这个角度来看,每一步都会估计一个 x 0 x_0 x0 ,然后乘上权重,到最后我们估计的 x 0 x_0 x0 就是每一步估计 x 0 ( t ) x_{0(t)} x0(t) 的加权和。当然,越靠近最终结果( t t t 越小)的时候,噪声越小,我们估计得越准,其权重也越大。
如果我们对该形式进一步整理,就可以得到第二种形式,为 x t x_t xt 和噪声估计值 z ~ \tilde{z} z~ 的加权和的形式。从这个角度来看,符合我们对去噪过程的直观理解,从 x t x_t xt 中减去当前步的预测噪声 z ~ \tilde{z} z~ 。
当然,我们将 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt) 作为高斯分布的均值方差求出之后,也能将它写成一个高斯分布的式子,即式 (25)。

最后,我们对照一下 DDPM 原文中给出的训练和采样公式。可以看到,和我们上面推导的结果是一致的。
这里有个点提一下,在采样过程中,每一步都会加一个额外的噪声 σ t z \sigma_tz σtz ,这里的 σ t \sigma_t σt 就是我们上面推导出的 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt) 的标准差。我们之前提到,这是为了给采样过程带来一点随机性,所以注意在采样算法中,最后一步 x 0 x_0 x0 是不加噪声的,因为 x 0 x_0 x0 就已经是我们最终要的生图结果。另外,在实际采样中,这个 σ t \sigma_t σt 是噪声方差的一个上界,这个值也不必完全与推导结果加的一样,比他小甚至为 0,也是可以的。