数据湖hudi的表类型定义了数据在DFS上如何组织布局,同时实现一些timeline等操作(表类型定定义数据是如何写入的);查询类型则是定义如何读取DFS上的数据。
| Table type | query type |
| Copy-On-Write | 快照查询; 增量查询; 增量CDC; 时间旅行; |
| Merge-On-Read | 快照查询; 增量查询; 读取优化查询; 时间旅行; |
表类型
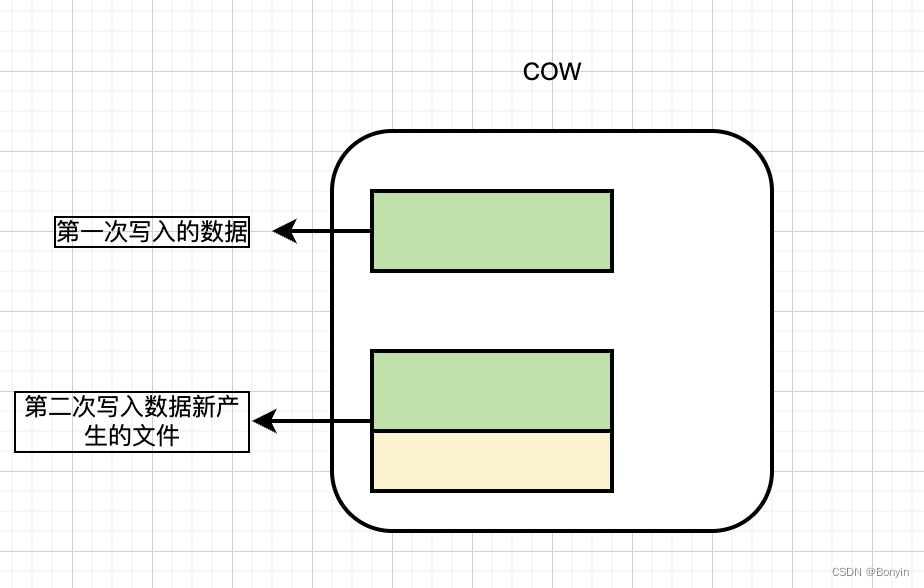
1.copy-on-write
使用列存储格式parquet组织数据,产生新版本的数据文件,是通过在写入期间执行同步合并重新产生新文件。
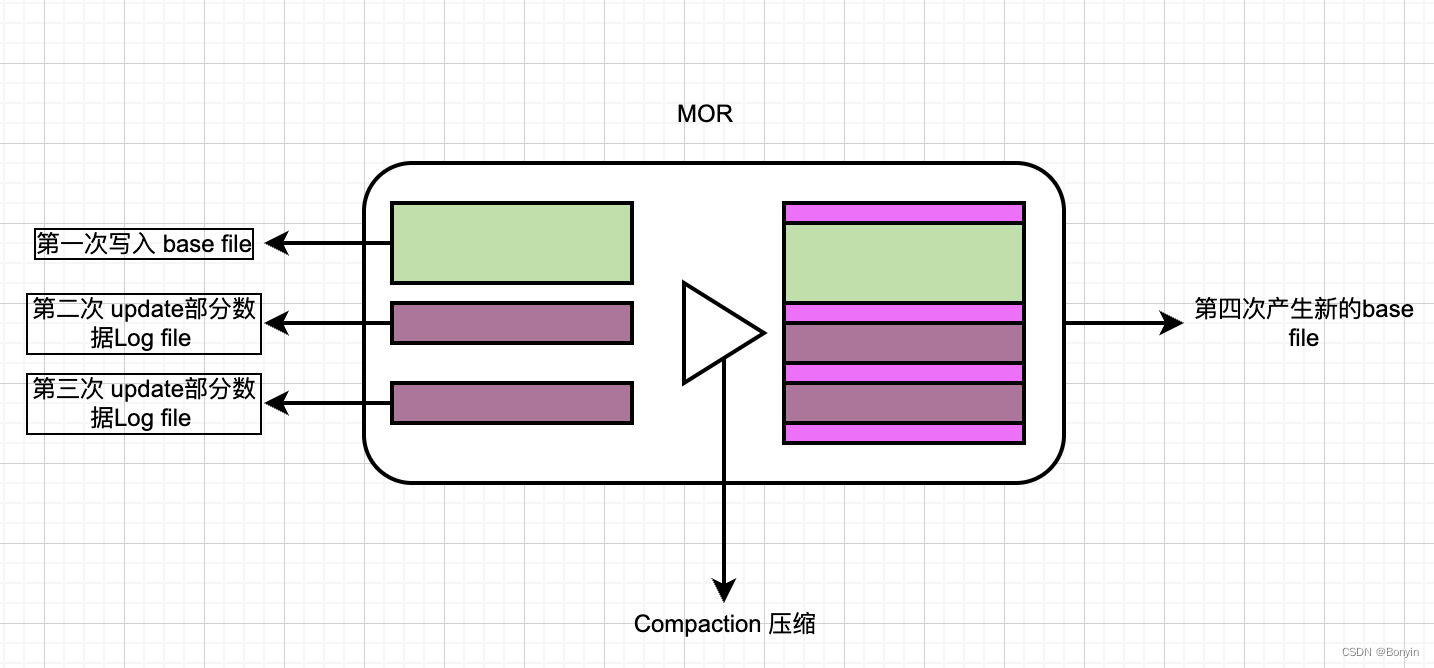
2.merge-On-Read
使用列加行的格式来组织数据,更新的数据写入到增量文件中,在将增量的数据压缩以同步或者异步的方式生成新的版本文件。
查询类型
Hudi支持以下查询:
快照查询:查询查看给定提交或压缩操作时表的最新快照。在读取表上合并的情况下,它通过合并公开近乎实时的数据(几分钟) 实时最新文件切片的基本文件和增量文件。对于写表复制,它提供了现有镶木地板表的直接替代品,同时提供更新插入/删除和其他写入端功能。
增量查询:查询仅查看自给定提交/压缩以来写入表的新数据。 这有效地提供了变更流以启用增量数据管道。默认情况下,这会生成最新的 自时间线中给定点以来的更改快照。
增量查询(CDC):这些是增量查询的子类型,其中查询会查看自此以来所有更改的数据 给定的提交/压缩,而不是更改数据的最新状态。这支持完整的 cdc 风格查询用例 允许查看更改前后的图像以及导致更改的操作。
读取优化查询:查询查看给定提交/压缩操作时表的最新快照。仅公开最新文件切片中的基础/列文件并保证 与非 hudi 列式表相比,列式查询性能相同。
时间旅行查询:查询截至时间轴中给定时间戳的表快照。









![文件包含 [SWPUCTF 2021 新生赛]include](https://img-blog.csdnimg.cn/direct/c0c2f37afd4344b285956b3bc7fabea1.png)