文章目录
- rk3568-1.6.0
- 1.在任一个ubuntu系统上安装RKNN-Toolkit2
- 1.1 下载
- 1.2 安装
- 2.在机器端(板端)查看 RKNPU2的驱动
- 3.RKNN使用说明
- 3.1 模型转换
- a. RHKNN初始化和释放
- b. RKNN config
- c. 加载模型
- d. 构建模型
- e. 导出模型
- f.转换工具
- 3.2 python 代码示例导出模型, 下载的仓库里面优很多示例可以参考
- 4.c++部署
- 5.其他待研究
rk3568-1.6.0
1.在任一个ubuntu系统上安装RKNN-Toolkit2
1.1 下载
新建 Projects 文件夹
mkdir Projects
进入该目录
cd Projects
下载 RKNN-Toolkit2 仓库
git clone https://github.com/airockchip/rknn-toolkit2.git --depth 1
下载 RKNN Model Zoo 仓库
git clone https://github.com/airockchip/rknn_model_zoo.git --depth 1
注意:
1.参数 --depth 1 表示只克隆最近一次 commit
2.如果遇到 git clone 失败的情况,也可以直接在 github 中下载压缩包到本地,然后解压至该目录
1.2 安装
首先安装依赖库
pip install -r doc/requirements_cpxx.txt
然后安装rknn-toolkit2
pip install packages/rknn_toolkit2-x.x.x+xxxxxxxx-cpxx-cpxxlinux_x86_64.whl
验证安装是否成功,进入 Python 交互模式
python
然后
from rknn.api import RKNN
2.在机器端(板端)查看 RKNPU2的驱动
dmesg | grep -i rknp

uname -a查看系统架构
3.RKNN使用说明
3.1 模型转换
RKNN-Toolkit2 提供了丰富的功能,包括模型转换、性能分析、部署调试等。本节将重点介绍 RKNN-Toolkit2 的模型转换功能。模型转换是 RKNN-Toolkit2 的核心功能之一,它允许用户将各种深度学习模型从不同的框架转换为 RKNN 格式以在 RKNPU 上运行,用户可以参考模型转换流程图以帮助理解如何进行模型转换。
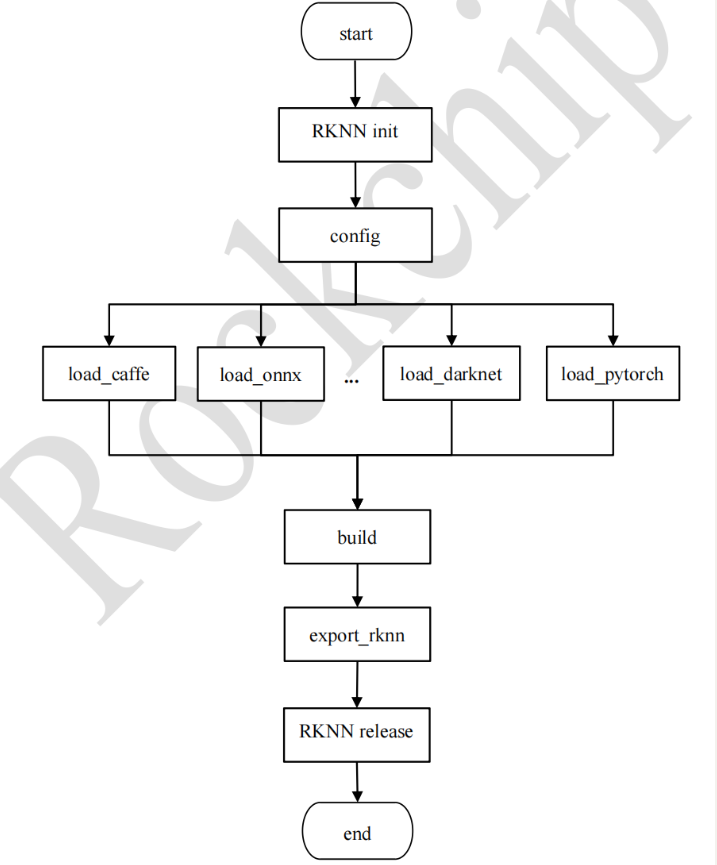
支持pytorch , tensorflow , caffe, onnx 模型转换为rknn格式。
a. RHKNN初始化和释放
rknn = RKNN(verbose=True, verbose_file=‘./mobilenet_build.log’)
rknn.release()
b. RKNN config
rknn.config(
mean_values=[[103.94, 116.78, 123.68]],
std_values=[[58.82, 58.82, 58.82]],
quant_img_RGB2BGR=False,
target_platform='rk3566')
mean_values 和 std_values 用于设置输入的均值和归一化值。这些值在量化过程中使用,
且 C API 推理阶段图片不需再做均值和归一化值减小布署耗时。
因此这里需要注意,这些值不仅是归一化用途,还要用在量化上。
quant_img_RGB2BGR 用于控制量化时加载量化校正图像时是否需要先进行 RGB 到BGR 的转换,默认值为 False。该配置只在量化数据集时生效,实际部署模型时,模型 推 理 阶 段 不 会 生 效 , 需 要 用 户 在 输 入 前 处 理 里 预 先 处 理 好 。 注 :
quant_img_RGB2BGR = True 时 模 型 的 推 理 顺 序 为 先 做 RGB2BGR 转 换 再 做
mean_values 和 std_values 操作,详细注意事项请见 10.3 章节
target_platform 用于指定 RKNN 模型的目标平台,支持 RK3568、RK3566、RK3562、
RK3588、RV1106 和 RV1103
quantized_algorithm 用于指定计算每一层的量化参数时采用的量化算法,可以选择
normal、mmse 或 kl_divergence,默认算法为 normal,详细说明见 3.1.7、6.1 和 6.2 章
节
quantized_method 支持 layer 或 channel,用于每层的权重是否共享参数,默认为
channel,详细说明见 3.1.7、6.1 和 6.2 章节。
optimization_level 通过修改模型优化等级,可以关掉部分或全部模型转换过程中使用
到的优化规则。该参数的默认值为 3,打开所有优化选项,值为 2 或 1 时关闭一部分
可能会对部分模型精度产生影响的优化选项,值为 0 时关闭所有优化选项。
这一部分很关键,而且转换后的模型和C代码也有很大关系。
c. 加载模型
ret = rknn.load_onnx(model=‘./arcface.onnx’)
d. 构建模型
用户加载原始模型后,下一步就是通过 rknn.build()接口构建 RKNN 模型。构建模型时,
用户可以选择是否进行量化,量化助于减小模型的大小和提高在 RKNPU 上的性能。
rknn.build()接口参数如下:
do_quantization 参数控制是否对模型进行量化,建议设置为 True。
dataset 参数用于提供用于量化校准的数据集,数据集的格式是文本文件。
dataset.txt 示例: ./imgs/ILSVRC2012_val_00000665.JPEG
./imgs/ILSVRC2012_val_00001123.JPEG
./imgs/ILSVRC2012_val_00001129.JPEG
./imgs/ILSVRC2012_val_00001284.JPEG
./imgs/ILSVRC2012_val_00003026.JPEG
./imgs/ILSVRC2012_val_00005276.JPEG
示例代码:
ret = rknn.build(do_quantization=True, dataset=‘./dataset.txt’)
e. 导出模型
rknn.export_rknn()接口将RKNN 模型保存为一个文件(.rknn 后缀),以便后续模型的部署。rknn.export_rknn()接口参数如下:
export_path 导出模型文件的路径。
cpp_gen_cfg 可以选择是否生成 C++ 部署示例。
ret = rknn.export_rknn(export_path=‘./mobilenet_v1.rknn’)
f.转换工具

3.2 python 代码示例导出模型, 下载的仓库里面优很多示例可以参考
import numpy as np
import cv2
from rknn.api import RKNN
import os
def export_pytorch_model():
import torch
import torchvision.models as models
net = models.quantization.resnet18(pretrained=True, quantize=True)
net.eval()
trace_model = torch.jit.trace(net, torch.Tensor(1, 3, 224, 224))
trace_model.save('./resnet18_i8.pt')
def show_outputs(output):
index = sorted(range(len(output)), key=lambda k : output[k], reverse=True)
fp = open('./labels.txt', 'r')
labels = fp.readlines()
top5_str = 'resnet18\n-----TOP 5-----\n'
for i in range(5):
value = output[index[i]]
if value > 0:
topi = '[{:>3d}] score:{:.6f} class:"{}"\n'.format(index[i], value, labels[index[i]].strip().split(':')[-1])
else:
topi = '[ -1]: 0.0\n'
top5_str += topi
print(top5_str.strip())
def show_perfs(perfs):
perfs = 'perfs: {}\n'.format(perfs)
print(perfs)
def softmax(x):
return np.exp(x)/sum(np.exp(x))
def torch_version():
import torch
torch_ver = torch.__version__.split('.')
torch_ver[2] = torch_ver[2].split('+')[0]
return [int(v) for v in torch_ver]
if __name__ == '__main__':
if torch_version() < [1, 9, 0]:
import torch
print("Your torch version is '{}', in order to better support the Quantization Aware Training (QAT) model,\n"
"Please update the torch version to '1.9.0' or higher!".format(torch.__version__))
exit(0)
model = './resnet18_i8.pt'
if not os.path.exists(model):
export_pytorch_model()
input_size_list = [[1, 3, 224, 224]]
# Create RKNN object
rknn = RKNN(verbose=True)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[123.675, 116.28, 103.53], std_values=[58.395, 58.395, 58.395], target_platform='rk3566')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn('./resnet_18.rknn')
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread('./space_shuttle_224.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.expand_dims(img, 0)
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img], data_format=['nhwc'])
np.save('./pytorch_resnet18_qat_0.npy', outputs[0])
show_outputs(softmax(np.array(outputs[0][0])))
print('done')
rknn.release()
4.c++部署
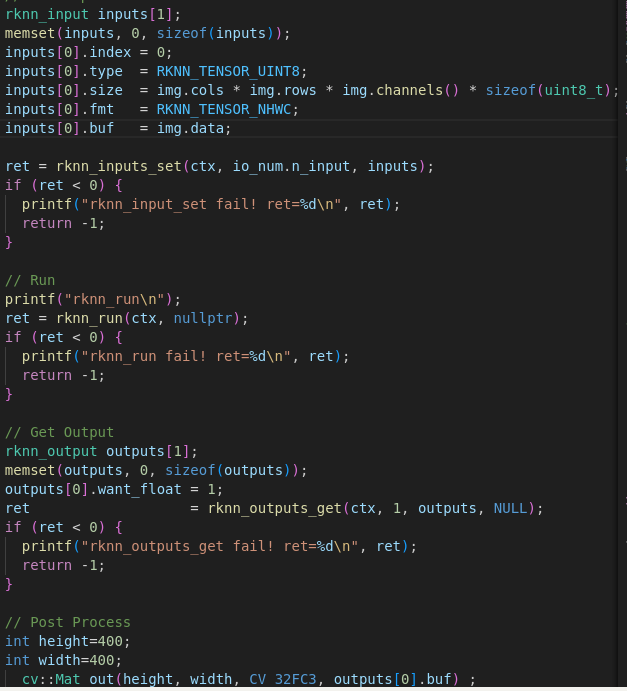
比如降噪模型,输入是 uint8图片, 利用零拷贝 api
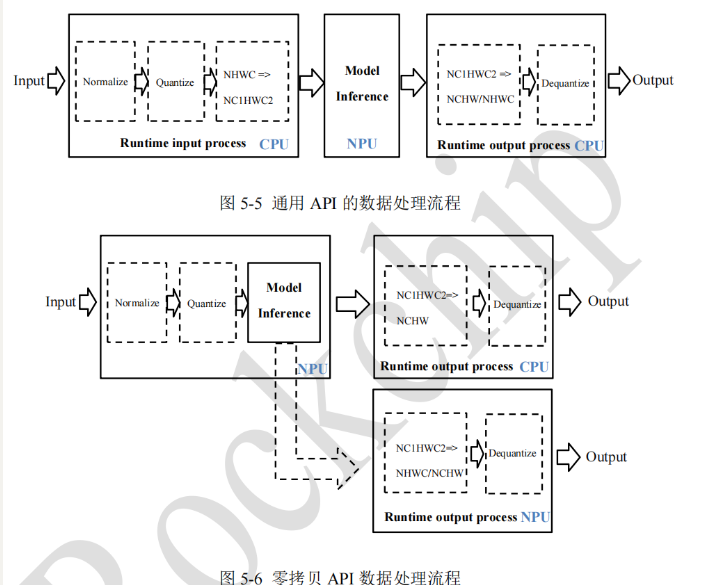
因此 在利用python代码进行模型格式转换的时候设置了 mean = [0,0,0], std=[255,255,255]相当于做了归一化,且自动在c++模型推理时应用, 包括归一化,量化,反量化等,c++代码里不需要再加入归一化相关代码。
因此如下图,输入的 uint8的image data, 然后归一化到0-1,因为设置了 outputs[0].want_float=1,然后model infer 得到 float data,范围 0-1. 以上全在 npu中进行,也就是全在rknn_run中进行,因为使用的时零拷贝 api.
最后cpu再 nchw -> hwc, 0-1 -> 0-255 uint8, 即可保存图像。
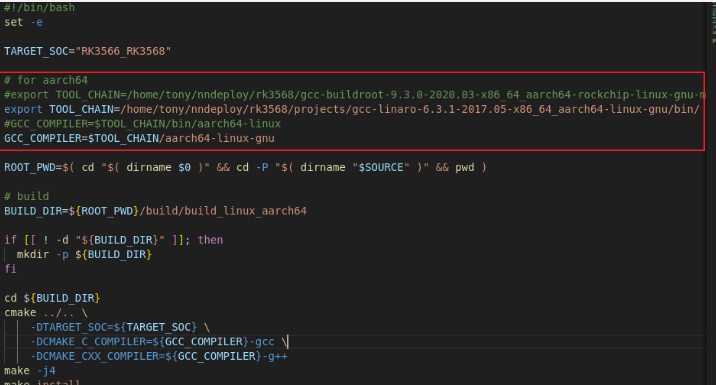
buildxxx.sh 中需要设置 gcc,g++交叉编译器, 注意 CMakeLists.txt,这样编译的程序可以在 rk3568平台使用
5.其他待研究
量化
多核
效果评估,
时间和空间评估
提高推理速度
等内容需要进一步测试。
以上内容在仓库 /doc/xx.pdf 中有详细的官方说明,尽量参考官方说明。