查询优化器是提升查询效率非常重要的手段,本文将主要介绍AntDB-T数据库查询优化的相关设计。AntDB-T数据库是一款企业级通用分布式关系型数据库,而查询是AntDB-T数据库管理系统中最关键、最吸引人的功能之一。每个生产数据库系统每天都需要处理大量的查询,为了使这些查询运行得更快、更好,AntDB-T数据库管理系统的查询优化器中融入了大量的优化技术。这些优化技术是众多研究者和技术人员数十年来的精华总结。
AntDB-T查询优化原理
(一)AntDB-T查询优化是什么
查询优化是数据库管理系统中的一个关键模块,如图 1 所示,橙色模块为查询优化所处的位置,当一条SQL进来之后,可以看到会经过Parser → Analyzer → Rewriter → Planner → Executor这一系列步骤:
1.SQL进行Parser处理,它会对SQL进行语法分析并生成语法解析树。
2.SQL进行Analyzer处理,它主要对SQL进行语义分析并生成查询树。
3.若SQL是DDL语句且是非分布式时的无需进行优化若SQL是DDL语句且是分布式时需要针对某些场景做特殊处理。
4.满足步骤3条件的到Executor进行处理,并结束。不满足步骤3条件的,即对于SQL是DML则需要按照完整的流程进行处理。
5.SQL进入到Rewriter进行查询重写处理。
6.SQL进入到Planner并对其进行逻辑等价变换和物理执行路径筛选,最终选择最优的执行路径,生成执行计划。简单来说,查询优化器输入的是查询树,输出的是查询执行计划。
7.将步骤6产生的执行计划传递给Executor数据库执行器模块,并结束。
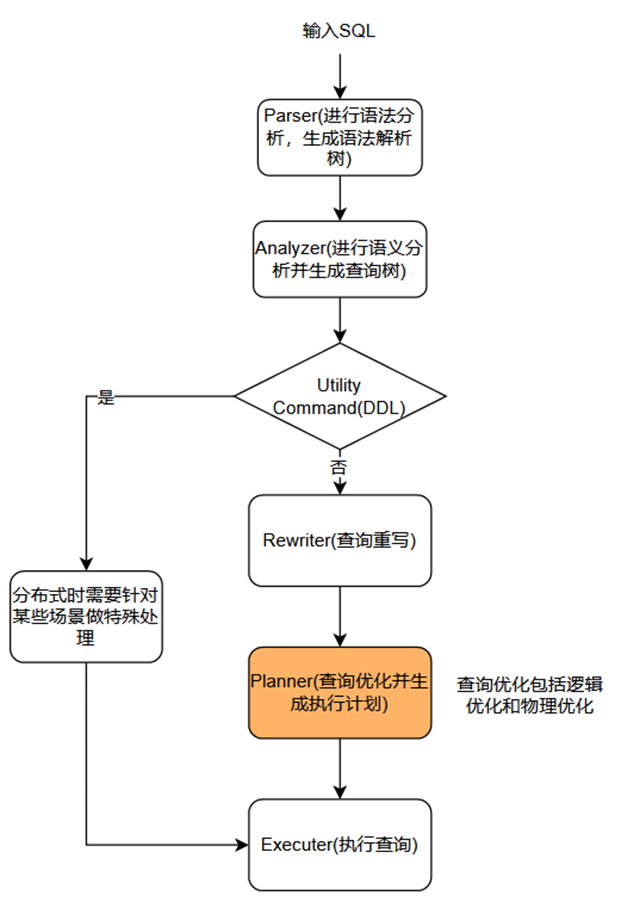
图1:SQL的执行过程
AntDB-T数据库的查询优化方法分为两个层次:
1)基于规则的查询优化(逻辑优化, Rule Based Optimization ,简称 RBO )。
2)基于代价的查询优化 (物理优化,Cost Based Optimization,简称 BO )。
逻辑优化是建立在关系代数基础上的优化,关系代数中有一些等价的逻辑变换规则,通过对关系代数表达式进行逻辑上的等价变换,可能会获得执行性能比较好的等式,这样就能提高查询的性能。
而物理优化则是在建立物理执行路径的过程中进行优化,关系代数中虽然指定了两个关系如何进行连接操作,但是这时的连接操作符属于逻辑运算符,它没有指定以何种方式实现这种逻辑连接操作,而查询执行器是不“认识”关系代数中的逻辑连接操作的,我们需要生成多个物理连接路径来实现关系代数中的逻辑连接操作,并且根据查询执行器的执行步骤,建立代价计算模型,通过计算所有的物理连接路径的代价,从中选择出“最优”的路径。
(二)AntDB-T为什么要引入查询优化
一般数据库的使用者在书写 SQL 语句的时候也经常会考虑到查询的性能,但是一个应用程序可能要写大量的SQL 语句,而有些 SQL语句的逻辑极为复杂,数据库应用开发人员很难面面俱到地写出“极好的”语句,而AntDB-T查询优化相对于数据库应用开发人员而言,具有一些独特的优势,比如:AntDB-T查询优化在优化的过程中会参考数据库统计模块自动产生的统计信息、查询优化器和数据库用户之间的计算能力不同等。
AntDB-T查询优化是一项至关重要的功能,其职责是生成最理想的查询执行计划。AntDB-T查询优化可以提高数据库查询的性能和响应时间;提升用户体验;识别和优化复杂的查询,使查询更容易理解和维护。此外,还可以改进查询性能,减少系统资源的使用,提高系统的可用性和可扩展性。
AntDB-T查询优化实现方式
(一)AntDB-T查询优化实现路径
AntDB-T数据库的查询优化方法分为逻辑优化和物理优化,如图 2所示。
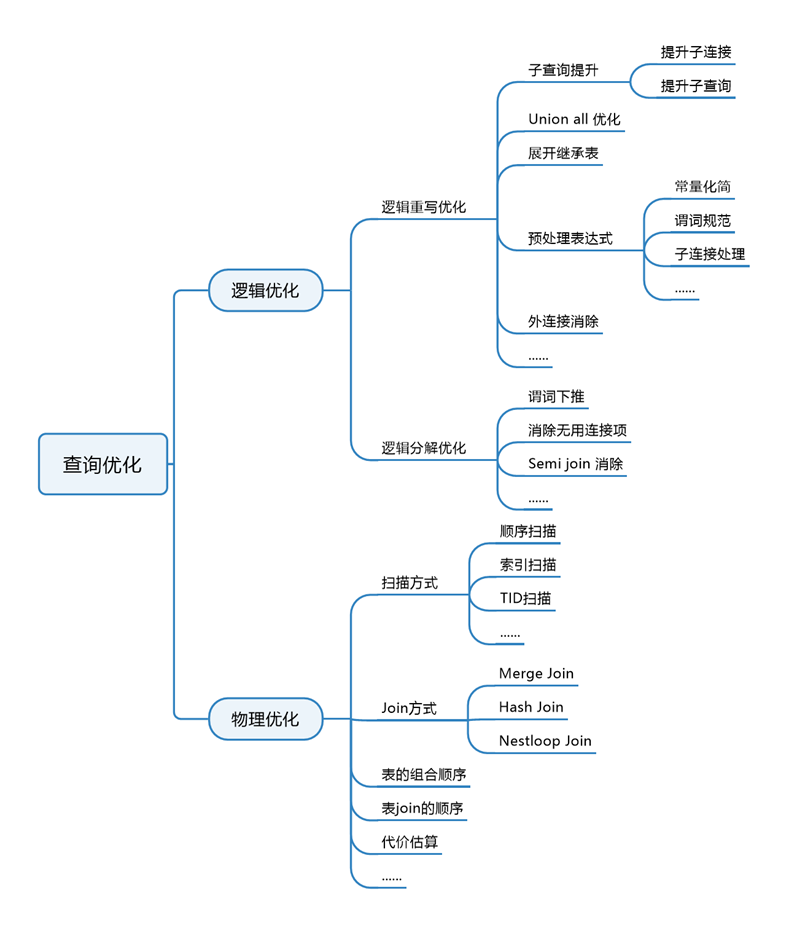
图2:查询优化的方法
1.逻辑优化
逻辑优化分为逻辑重写优化和逻辑分解优化。
(1)逻辑重写优化
在逻辑重写优化阶段主要还是对查询树进行“重写”,也就是说在查询树上进行改造,改造之后还是颗查询树,而在逻辑分解阶段,会将查询树打散,重新建立等价于查询树的逻辑关系。逻辑重写优化主要包含子查询提升、Union all 优化、展开继承表、预处理表达式、外连接消除等等。
(2)逻辑分解优化
而逻辑分解优化是逻辑优化的一部分,主要开始和物理优化产生了紧密的联系。在逻辑分解阶段则将约束条件(查询树里面的裸表达式)用RestrictInfo结构体来进行封装,这样就可以扩展表达式的内容,比如在RestrictInfo结构体中还记录了约束条件在物理优化过程中需要的变量。在查询树(Query)中,约束条件(表达式)存放的位置就是它原始的语法位置,在逻辑分解的过程中,会对这些约束条件尝试下推,RestrictInfo结构体的出现也是为了在下推的时候能够更好地和RelOptInfo结构体结合。逻辑分解优化主要包含谓词下推、消除无用连接项、Semi join消除等等。
2.物理优化
那物理优化是什么呢?简单说就是对于一条SQL,数据库可以有多种方式去执行,条条大路通罗马,比如顺序扫描、索引扫描,多表连接的话又有nestloop、hashjoin、mergejoin等,举个通俗的例子,我要从杭州出差去北京,我可以选择坐飞机,也可以坐高铁,也可以坐轮船,甚至可以骑车去也行,无外乎效率(money)的问题,AntDB-T数据库也是如此,需要有一种机制告诉它如何去选择一条最优的方式去生成执行计划,这就是物理优化。物理优化主要包含表的扫描方式选择、表的join方式、表join的顺序等等。
(二)AntDB-T查询优化实现方式
下面将针对查询优化进行代码简要说明。本次以AntDB-T的代码为例,来解析查询优化的实现方式。
1.AntDB-T数据库查询优化模块的主入口函数是planner函数。这个函数会检查当前库是否定义了自定义的优化方法(planner_hook)。如果没有自定义的优化方法(即planner_hook为空),那么就会调用standard_planner函数如图3所示,这是AntDB-T数据库查询优化的标准函数。

图3:查询优化的主入口函数
2.standard_planner函数中又包含了许多重要的函数如下图4所示,其中subquery_planner是查询优化主要实现函数。
3.subquery_planner函数下面的grouping_planner函数之前的部分属于逻辑重写优化,而grouping_planner函数中的一部分属于逻辑分解优化,另一部分则是属于物理优化。
4.调用完函数subquery_planner后,会调用 fetch_upper_rel、get_cheapest_fractional_path获取到经过物理优化生成的最优的路径。
5.调用create_plan函数转换成执行计划。
6.调用SS_finalize_plan函数,它会对这个执行计划中的Param节点进行最后的处理。
经过这一系列步骤之后,最终产生了执行计划,这个执行计划会被传递给查询执行模块进行SQL的执行操作。
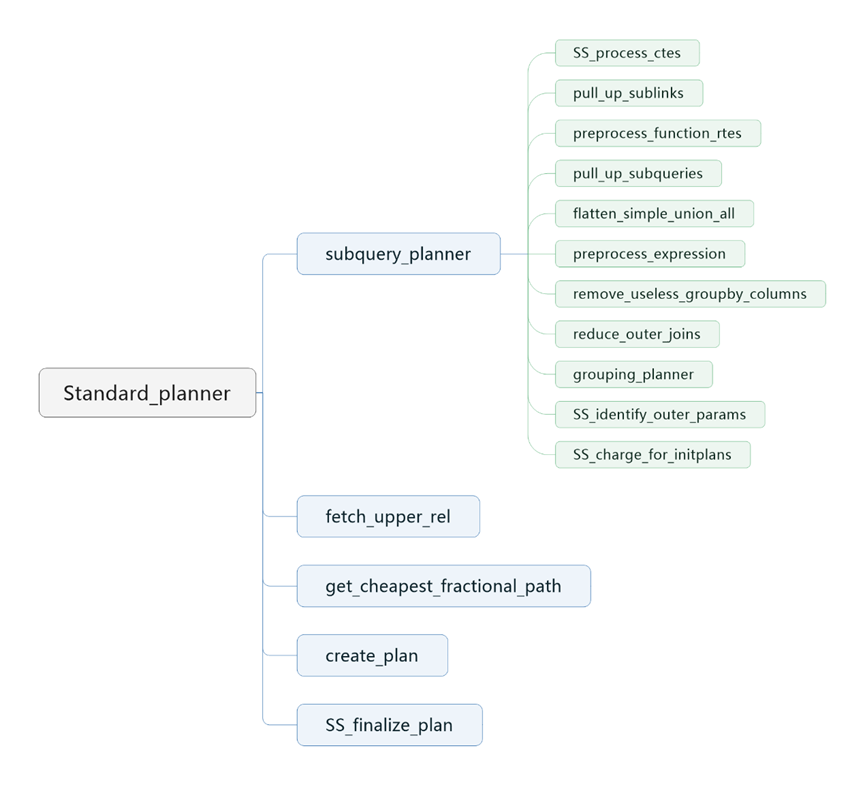
图4:查询优化函数调用图
为便于更好地了解查询优化预处理表达式中的常量化简这一优化方法,下面以具体的SQL为例展开分析:
首先是建表,接着构造数据,然后建立索引,再收集统计信息,如下图5所示:

图5:构造数据
最后查看带有常量表达式的SQL的执行计划,如下图6所示:

图6:常量化简的执行计划
可以看到,在此例中,AntDB-T数据库将谓词id = 8 + 9转化成了 id = 17,这样SQL语句就可以使用索引扫描,这种扫描方法提高了扫描表的效率;而原来优化前使用的是顺序扫描。这便是常量化简这一查询优化的原理。
常量化简这个优化代码的实现在preprocess_expression->eval_const_expressions 这个函数中实现,这个函数递归调用了
eval_const_expressions_mutator函数, eval_const_expressions_mutator函数针对不同的表达式比如函数表达式、操作符表达式、布尔表达式等分别做不同的优化处理。
此例中id = 8 + 9转成id = 17这个步骤主要是调用eval_const_expressions_mutator->simplify_function-> evaluate_function函数来实现的,通过调用evaluate_function-> evaluate_expr函数执行8+9 这个操作 得出结果是17。
常量化简的主要的优化点有参数常量化、函数常量化、约束条件常量化3个方面,参数的常量化是通过遍历参数的表达式实现的,如果发现参数表达式中全部为常量,则对参数执行预先求值。
(三)AntDB-T查询计划评估
前面介绍了查询优化是怎么实现的,下面来看看如何查看生成好的执行计划。
在AntDB-T数据库中查看执行计划使用Explain命令,Explain命令显示每个给定的DML语句选中的执行计划的预计开销,使用Explain 命令时,ANALYZE 选项将导致语句的执行,也将会显示实际执行时间。生成的执行计划阅读方式是自下而上的,每行信息代表一个节点。
1.Explain命令语法:
Explain命令的语法如下:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
这里option可选项如下:
-
ANALYZE [ boolean ]
-
VERBOSE [ boolean ]
-
COSTS [ boolean ]
-
SETTINGS [ boolean ]
-
BUFFERS [ boolean ]
-
WAL [ boolean ]
-
TIMING [ boolean ]
-
SUMMARY [ boolean ]
-
FORMAT { TEXT | XML | JSON | YAML }
可选项的含义:
-
ANALYZE:真正执行实际的SQL,会修改数据库结构,可以把EXPLAIN ANALYZE放到事务中,执行完成后再回滚;
-
VERBOSE:显示有关计划的其他信息。具体而言,包括计划树中每个节点的输出列列表、模式限定表和函数名称,始终使用其范围表别名标记表达式中的变量,并始终打印显示统计信息的每个触发器的名称。此参数默认为FALSE。
-
COSTS:包括每个计划节点的启动成本和总成本信息,以及估计的行数和每行的估计宽度。此参数默认为TRUE。
-
SETTINGS:包括有关配置参数的信息。具体来说,包括影响查询计划的选项,其值与内置默认值不同。此参数默认为FALSE。
-
BUFFERS:包括缓冲区使用的信息。特别是:共享块命中、读取、标记为脏和写入的次数、本地块命中、读取、标记为脏和写入的次数、以及临时块读取和写入的次数。只有当ANALYZE也被启用时,这个参数才能使用。它的默认被设置为FALSE。
-
WAL:包括WAL记录生成信息。具体来说,包括记录的数量等。此参数只能在同时启用ANALYZE时使用。默认为FALSE。
-
TIMING:在输出中包括实际启动时间和在每个节点上花费的时间。此参数只能在同时启用ANALYZE时使用。它默认为TRUE。
-
SUMMARY:在查询计划之后包括摘要信息(例如,总计时间信息)。使用ANALYZE时,默认情况下会包含摘要信息,但在其他情况下,默认情况不会包含摘要信息。但可以使用此选项启用摘要信息。EXPLAIN EXECUTE中的计划时间包括从缓存中获取计划所需的时间以及重新计划所需(如有必要)的时间。
-
FORMAT:指定输出格式,可以是TEXT、XML、JSON或YAML。非文本输出包含与文本输出格式相同的信息,但程序更容易解析。此参数默认为TEXT。
2.Explain相关参数
执行计划的代价计算采用的是假定的单位,与以下数据库参数有关(cost 值描述一个SQL执行的代价),可以根据主机的实际情况,调整参数值:
| 系统参数名 | 说明 | 默认值 |
| seq_page_cost | 顺序扫描page的成本 | 默认1.0,为基准 |
| random_page_cost | 随机扫描page的成本 | 默认4.0,以1.0为基准,4.0表示慢四倍 |
| cpu_tuple_cost | 处理一个数据行(元组)的CPU成本 | 默认0.01,以1.0为基准,0.01表示快100倍 |
| cpu_index_tuple_cost | 处理一个索引行(元组)的CPU成本 | 默认0.005,以1.0为基准,0.005表示快200倍 |
| cpu_operator_cost | 执行一次操作符或函数的CPU成本 | 默认0.0025,以1.0为基准,0.0025表示快400倍 |
| parallel_tuple_cost | 并行执行,从一个worker传输一个元组到另一个worker的成本 | 默认0.1
|
| parallel_setup_cost | 构建并行执行环境的成本 | 默认1000.0 |
上面的这些数据库参数越大表示越慢,查询优化就会选择其他更快的执行计划,比如走索引扫描路径。
3.执行计划解读
下面以一个具体的SQL例子来解读下执行计划:

图7:Explain执行计划
cost=0.29..8.30 第一个0.29 表示估计的启动成本,即返回第一行需要多少cost值,后面一个8.30 表示估计所有的行都被搜索到时的总成本,即返回所有数据的成本。
rows=1 估计执行完成时输出的行数,即返回多少行。
width=8 估计在该计划结点输出的平均行宽度(以bytes为单位)。
actual time=0.017..0.019 第一个0.017表示返回第一行实际花费的时间,后面一个0.019表示返回所有数据的实际花费的时间。
rows=1 估计执行完成时输出的行数,即返回多少行。
loops=1 表示循环的次数。
Planning Time: 0.439 ms 表示生成执行计划的时间。
Execution Time: 0.036 ms 表示执行执行计划的时间。
Index Scan using test_optimize_const_idx on public.test_optimize_const 表示使用了索引扫描方式,使用的是表public.test_optimize_const的索引,索引名字是test_optimize_const_idx。Output: id, rel_id表示查询输出的字段,Index Cond: (test_optimize_const.id = 8) 表示索引的条件。
总结
AntDB-T查询优化至为关键,其为提升数据库查询效能之关键所在。通过正确的查询优化,数据库能够更为迅速地查找到所需要的数据并返回结果,进而提高响应速度以及吞吐量。同时也能减少服务器资源消耗,降低运营成本。此外,良好的查询性能也可以提高用户体验,增加系统可用性和稳定性。
本文主要讲述了AntDB-T查询优化的概念、引入查询优化带来的性能提升、查询优化的原理以及如何查看查询优化后的执行计划。限于篇幅,查询优化的子查询提升、外连接消除、谓词下推等相关内容未能一一举例说明,感兴趣的小伙伴请持续关注AntDB数据库公众号。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔电信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。