allow_failure
我们知道,流水线作业在运行时如果失败了,就会停止运行,但allow_failure可以让我们自由的控制当前作业失败时,是否还需要继续运行。
- 要让管道继续运行后续作业,请使用allow_failure: true
- 要停止管道运行后续作业,请使用allow_failure: false
示例
失败后不运行
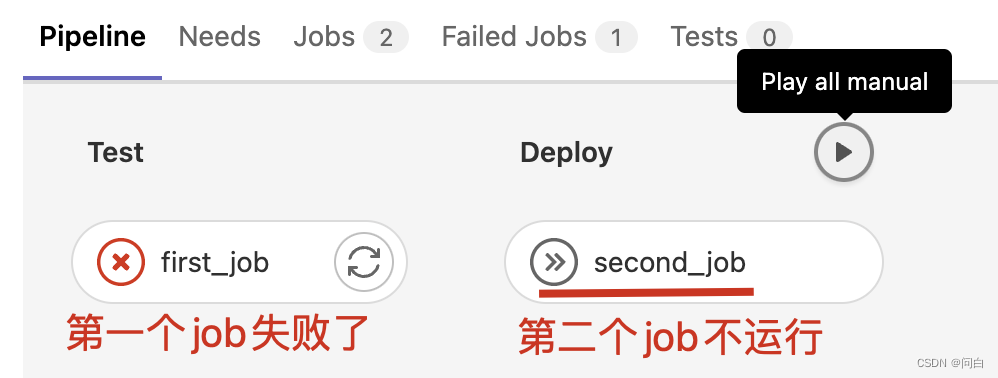
下面两个job,第一个Job是在test阶段,第二个job是在deploy阶段,如果第一个job运行失败了,那么第二个job就不会执行
first_job:
stage: test
script:
- NRM = "https://www.xxx.xx"
- echo "output variable in before_script ${NRM}"
allow_failure: false
second_job:
stage: deploy
script:
- echo "this is second job"
效果如下所示:
允许允许失败
first_job:
stage: test
script:
- NRM = "https://www.xxx.xx"
- echo "output variable in before_script ${NRM}"
allow_failure: true
second_job:
stage: deploy
script:
- echo "this is second job"
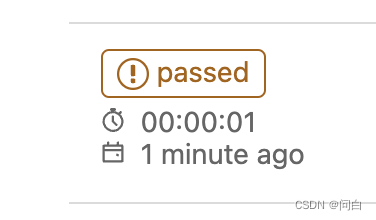
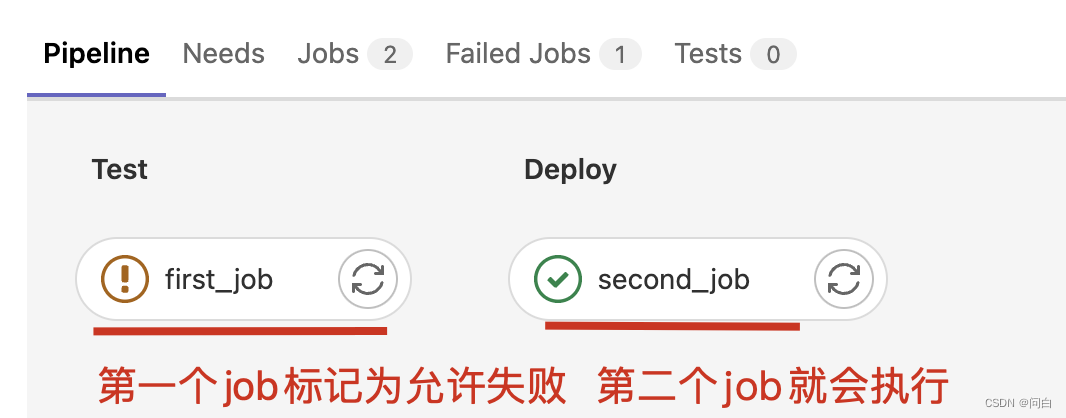
此时第一个job即便是失败了,第二个job也会执行
此时整个流水线的状态是一个橙色的感叹号,如下:
artifacts
artifacts 用于在流水线执行过程中将作业的产物(制品)附加到项目的指定路径下。
一般情况下仅针对成功作业收集制品。并且如果制品的大小小于Gitlab的最大文件大小,那就可以在Gitlab UI中下载制品。
示例
artifacts:paths
用于指定制品的路径,只能是项目内的。
my_job:
stage: test
script:
- echo "there is artifacts in pipeline"
artifacts:
paths:
- lint/
- eslint-report.json
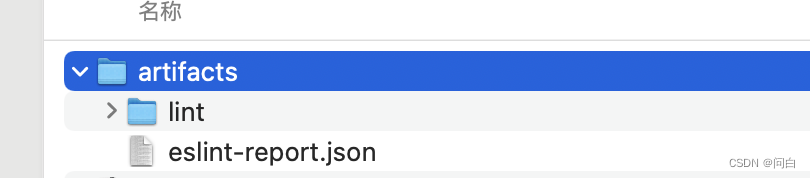
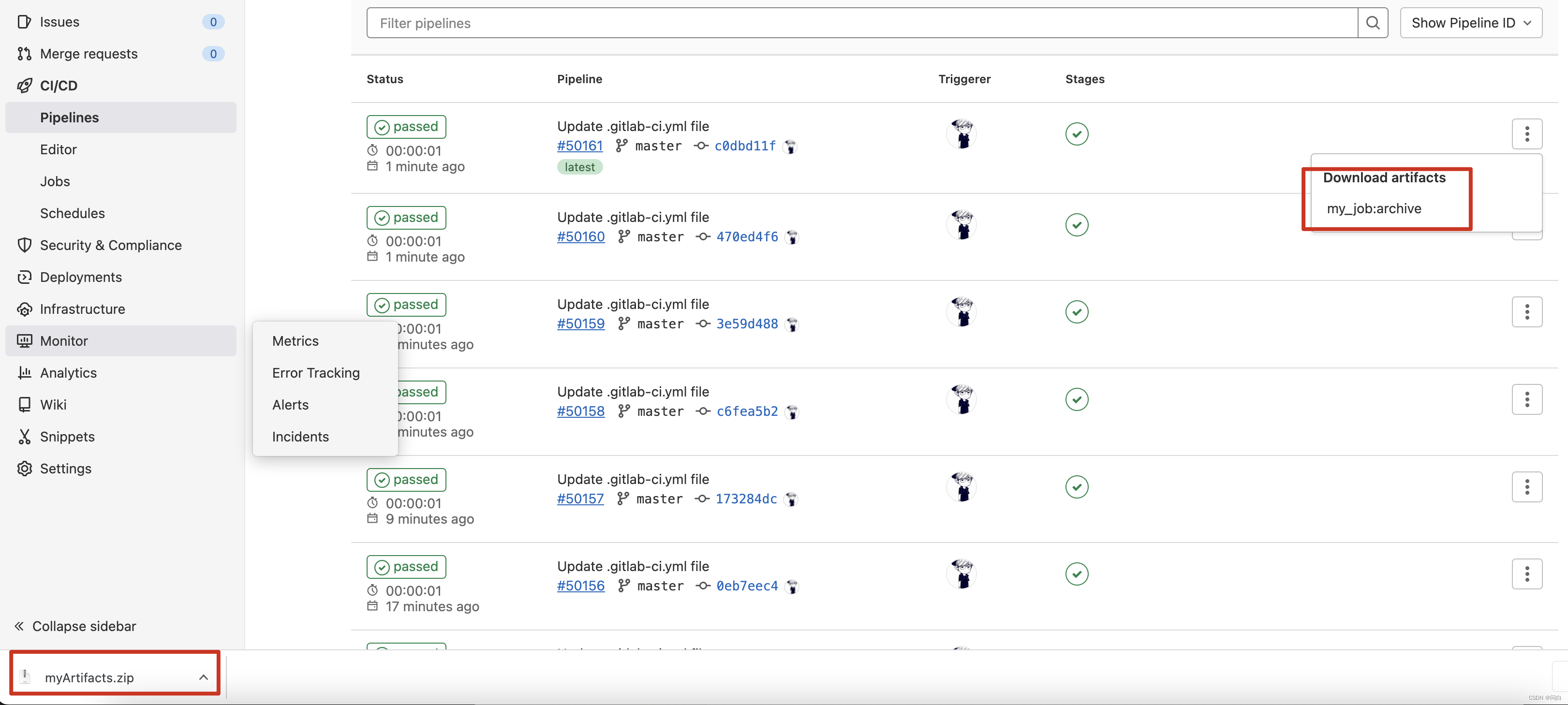
上述流水线任务指定了一个目录和一个文件作为流水线的制品。流水线执行完之后,可以在Gitlab UI 中下载他们。实际工作中的场景一般是在执行流水线任务时会执行各种各样的脚本,有时这些脚本会产生一些文件,比如单测,单测运行完之后会有一个报告,这个报告就可以作为制品提供出来。然后分析这份报告,进而得出此次单测运行的结果如何。

点击下载之后可以看到压缩包中有两个制品。一个是指定目录一个是指定的文件
artifacts:expire_in
expire_in用于指定作业制品存储多长时间。过期后,工件默认每小时删除一次(使用 cron 作业),并且无法再访问。如果单位未提供,默认为秒
一些值的示例
- ‘42’
- 42 seconds
- 3mins 4sec
- 2 hrs 20 min
- 2h20min
- 6 mos 1 day
- 3 weeks and 2 days
- never
my_job:
stage: test
script:
- echo "there is artifacts in pipeline"
artifacts:
paths:
- lint/
- eslint-report.json
expire_in: 1 mins 10 sec

artifacts:name
使用artifacts:name关键字定义创建制品的名称。如果不定义,默认名称为artifacts,下载时变为artifacts.zip。
my_job:
stage: test
script:
- NAME="report"
- echo "there is artifacts in pipeline"
artifacts:
name: "myArtifacts"
paths:
- lint/
- eslint-report.json
cache
使用cache用于在作业至极爱你缓存文件和目录。
最常见的一种情况比如在job1中npm i 安装了该项目的依赖,到job2的时候,是一个新的执行环境此时 node_module就没有了。那依赖于node_modules的一些命令或者环境也就在job2中没法用了,此时我们就可以将node_module 缓存。这样就无需在后续作业中再次安装依赖了。
或者是job1产生了一些结果需要传递给job2。又或者是某些配置/变量需要在不同job中用到,此一类的情况我们都可以使用cache来实现
示例
cache:paths
使用cache:paths关键字选择要缓存的文件或目录。
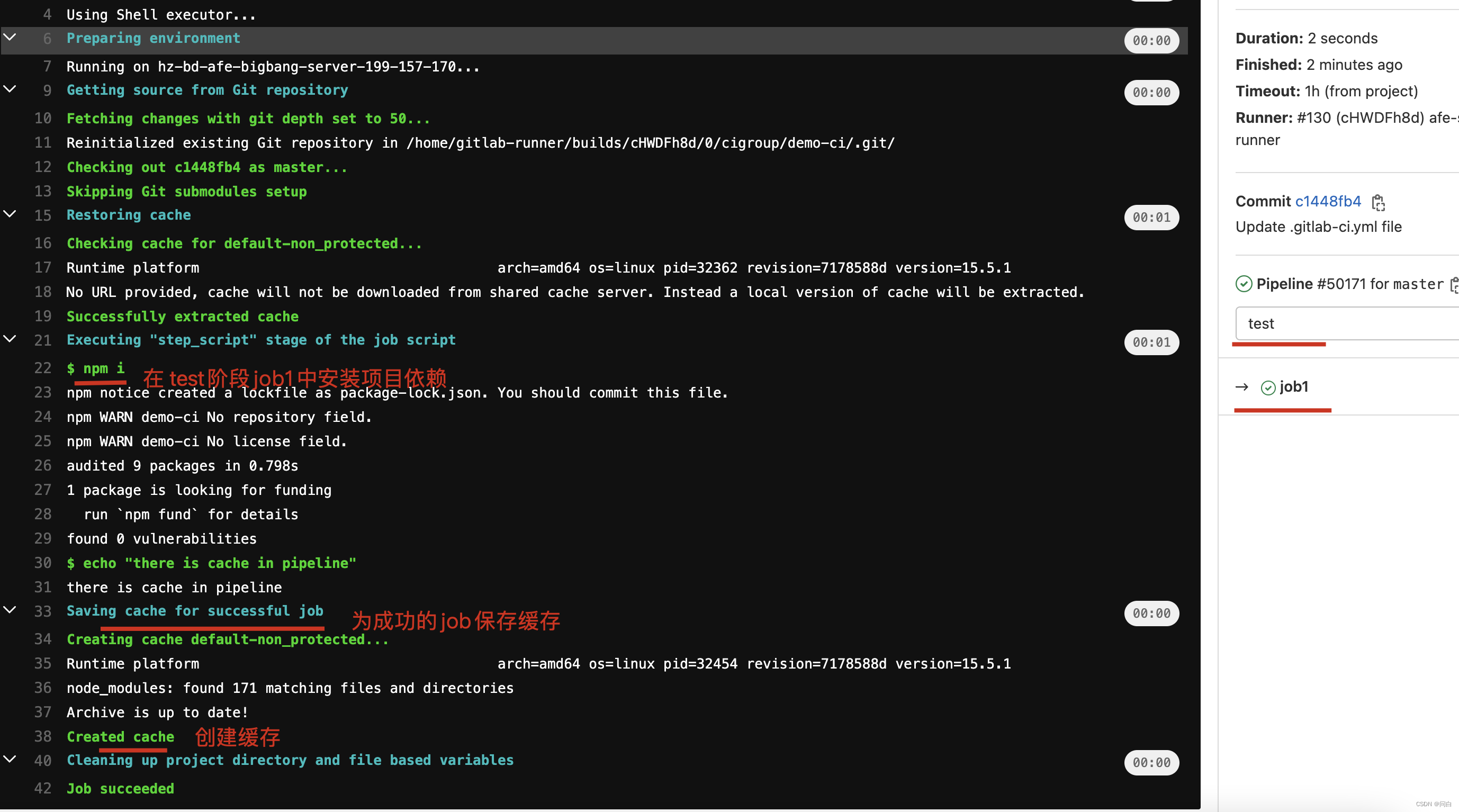
下面的脚本是在job1中安装了项目依赖,然后将node_modules作为缓存传递至job2中。
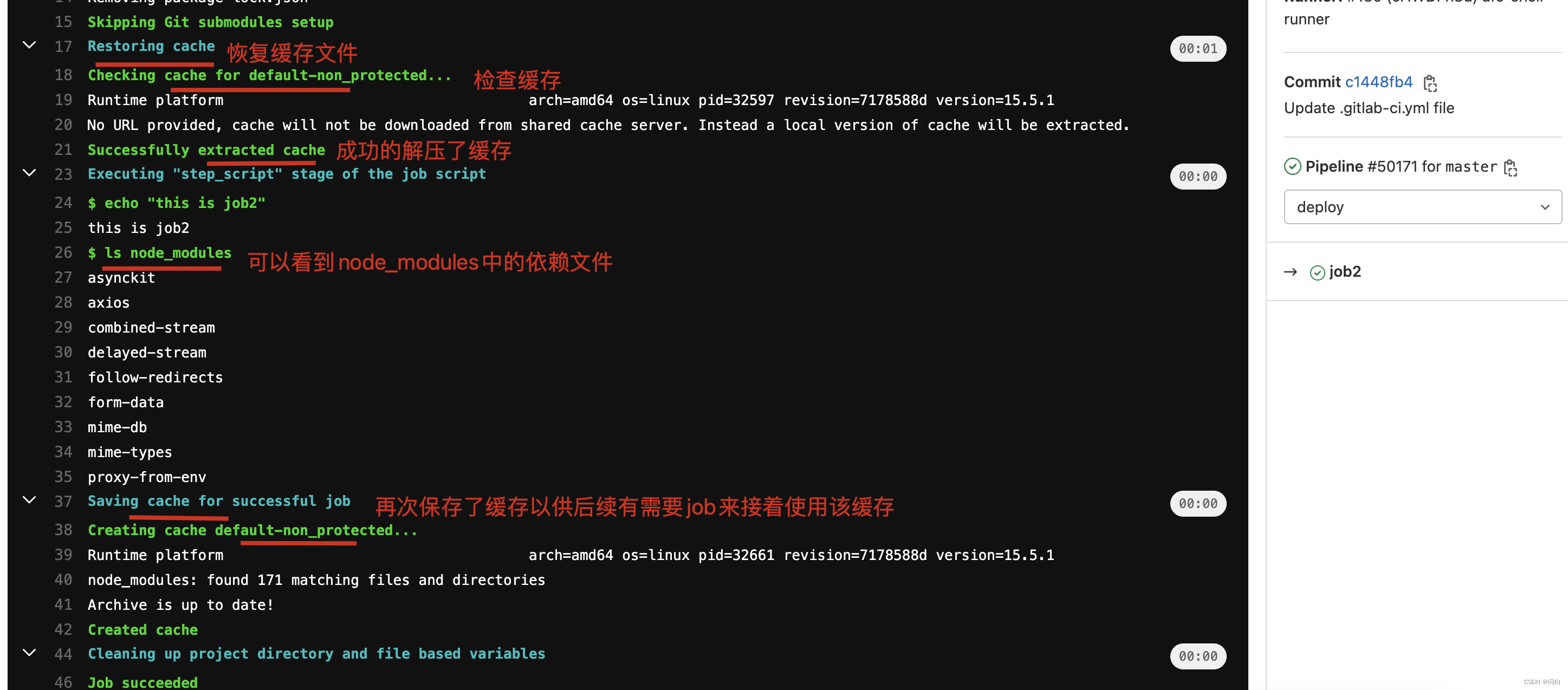
然后再job2中可以看到node_modules 中有哪些文件依赖
job1:
stage: test
script:
- npm i
- echo "there is cache in pipeline"
cache:
paths:
- node_modules
job2:
stage: deploy
cache:
paths:
- node_modules
script:
- echo "this is job2"
- ls node_modules
cache:key
很自然的,一旦我们的流水线复杂之后,有可能有很多的缓存,而不同阶段的不同job之间可能需要某些特定的缓存。
此时就需要使用cache:key来为每个缓存提供唯一的标识键。使用相同缓存键的所有作业都使用相同的缓存,包括在不同的管道中。
如果未设置,则默认键为default. 所有带有cache关键字但不cache:key共享default缓存的作业。可以看到上面的示例中创建cache的都是default-xxx开头的
使用缓存的job必须与 一起使用cache: paths,否则不缓存任何内容。
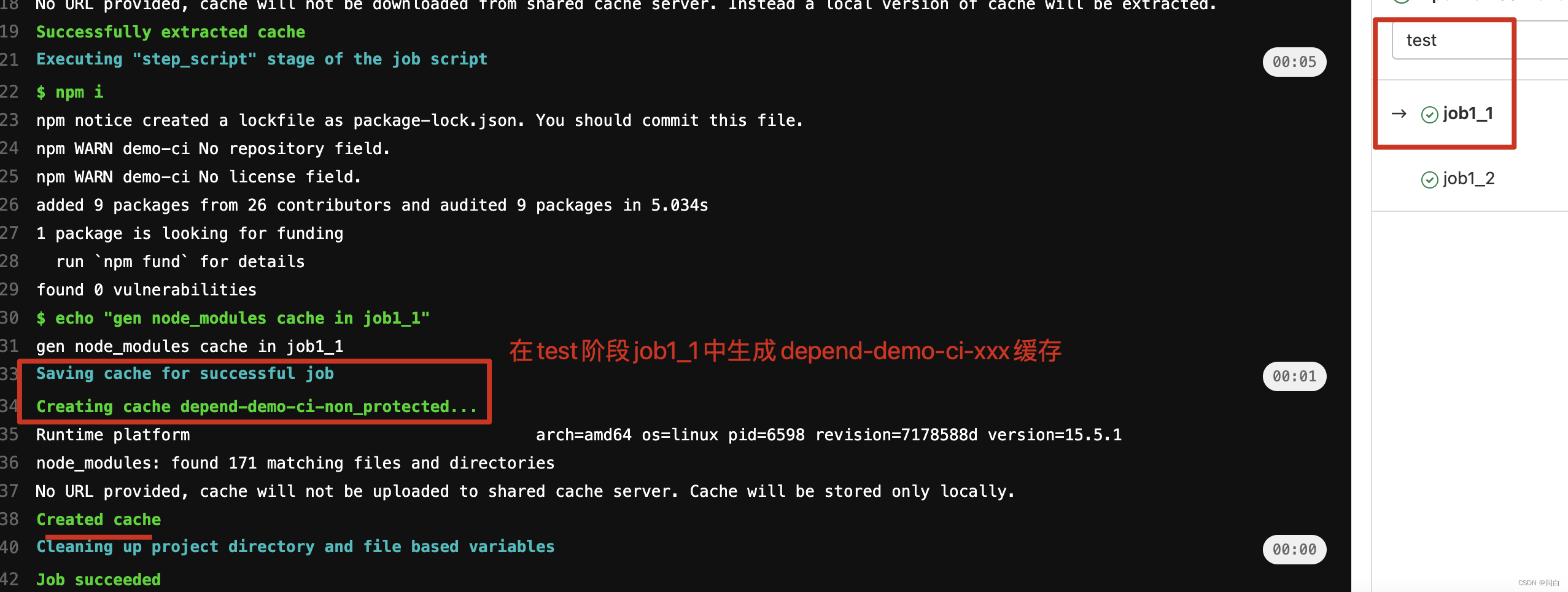
job1_1:
stage: test
script:
- npm i
- echo "gen node_modules cache in job1_1"
cache:
key: depend-$CI_PROJECT_NAME
paths:
- node_modules
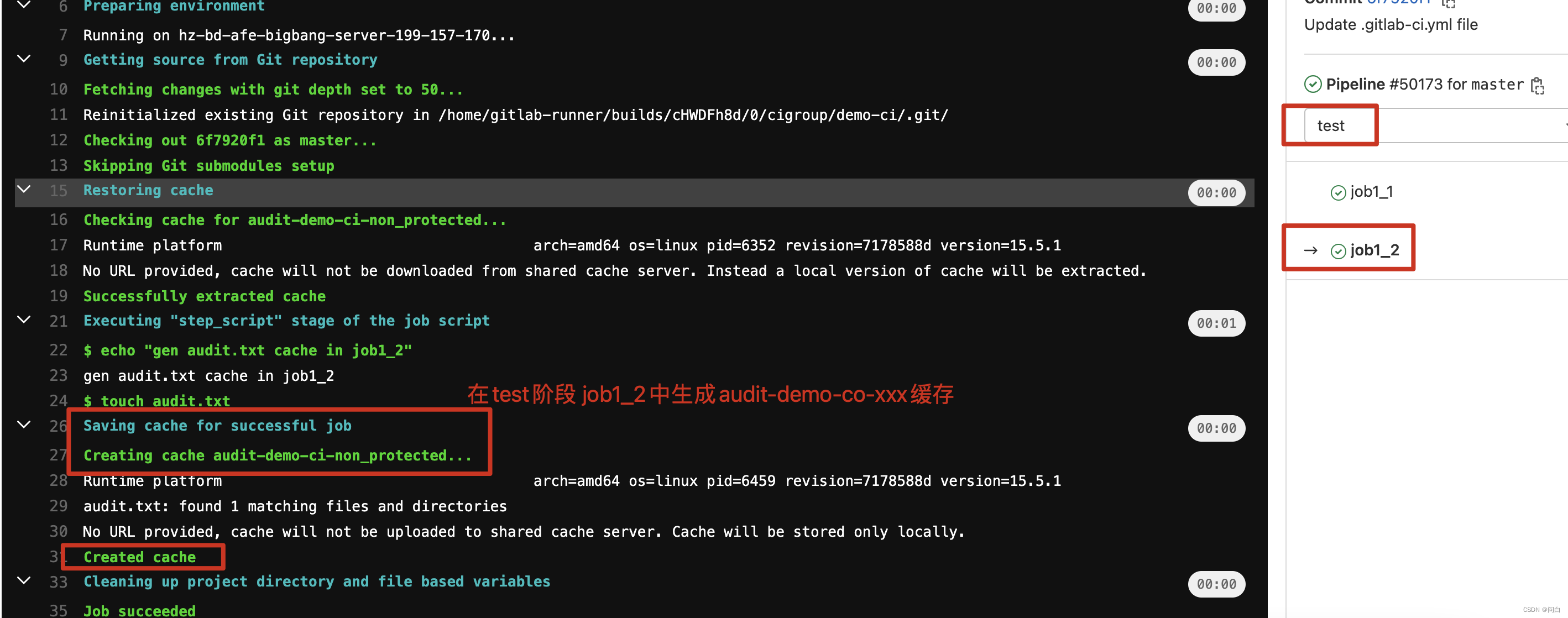
job1_2:
stage: test
script:
- echo "gen audit.txt cache in job1_2"
- touch audit.txt
cache:
key: audit-$CI_PROJECT_NAME
paths:
- audit.txt
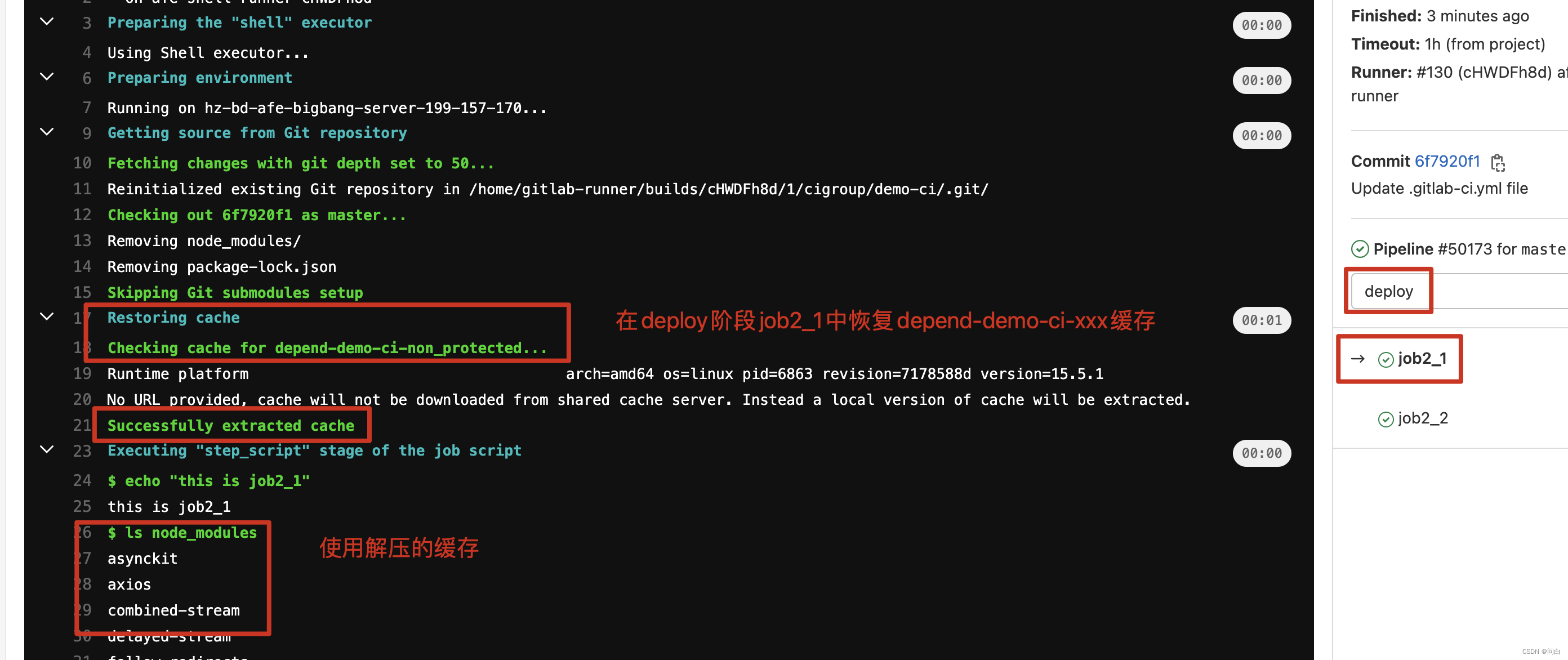
job2_1:
stage: deploy
cache:
key: depend-$CI_PROJECT_NAME
paths:
- node_modules
script:
- echo "this is job2_1"
- ls node_modules
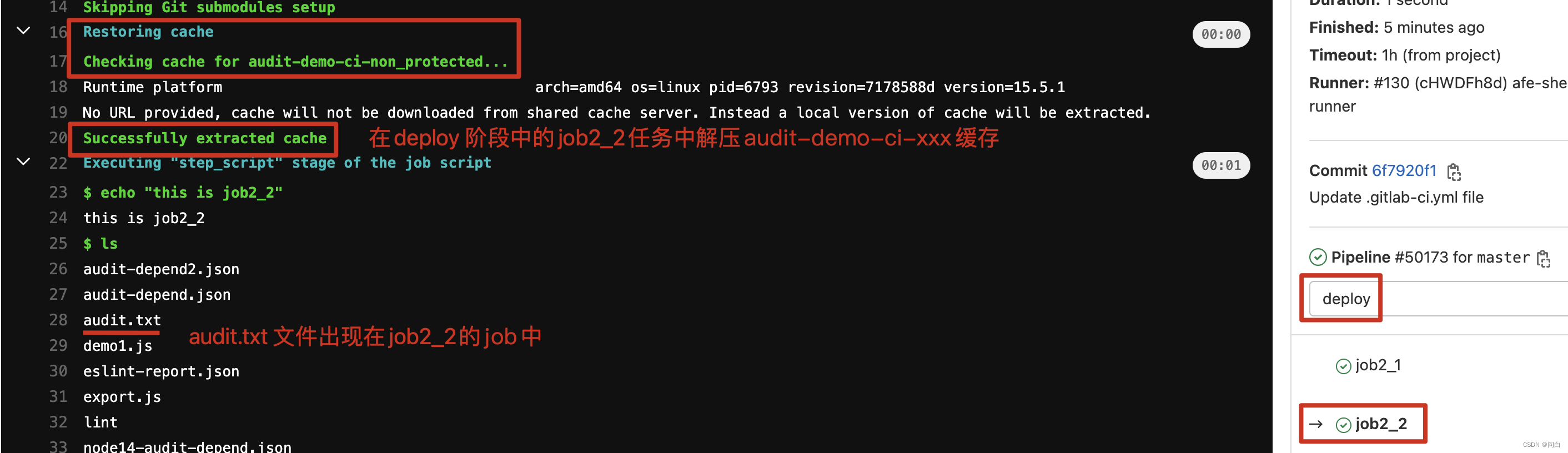
job2_2:
stage: deploy
cache:
key: audit-$CI_PROJECT_NAME
paths:
- audit.txt
script:
- echo "this is job2_2"
- ls