LRU 缓存机制_题解(一道经典的数据结构算法题)
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 10^5
最多调用 2 * 10^5 次 get 和 put
首先,让我们来理解一下本道题的思维逻辑

接下来,让我们来模拟一下本题示例的数据变化过程:









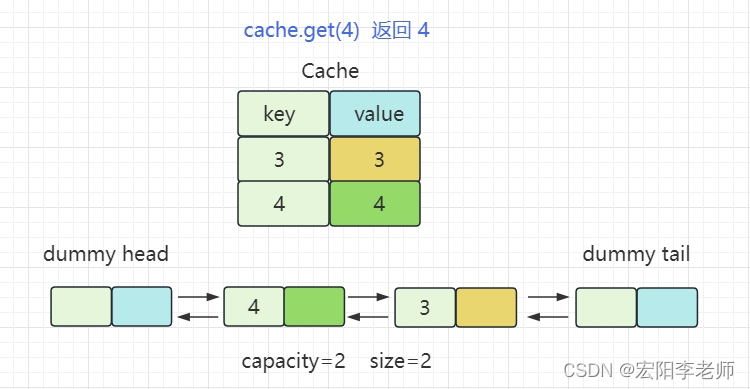
实现本题的两种操作,需要用到一个哈希表和一个双向链表。在 Python 语言中,有一种结合了哈希表与双向链表的数据结构 OrderedDict,看可以很方便的就完成本题。
'''
这里通过继承collections.OrderedDict来实现LRU缓存,
OrderedDict是一个有序字典,可以按照元素插入的顺序进行迭代。
通过调用move_to_end方法,可以将指定键移到字典的末尾,表示最近访问过。
'''
class LRUCache(collections.OrderedDict): # 创建一个继承自OrderedDict的LRU缓存类
def __init__(self, capacity: int): # 初始化函数,接受缓存容量作为参数
super().__init__() # 调用父类OrderedDict的初始化函数
self.capacity=capacity # 设置缓存容量
def get(self, key: int) -> int: # 获取缓存中指定键的值
if key not in self: # 如果指定键不在缓存中
return -1 # 返回-1
self.move_to_end(key) # 将指定键移到最后,表示最近访问过
return self[key] # 返回指定键对应的值
def put(self, key: int, value: int) -> None: # 向缓存中插入键值对
if key in self: # 如果指定键已经存在于缓存中
self.move_to_end(key) # 将指定键移到最后,表示最近访问过
self[key]=value # 设置指定键对应的值为新值
if len(self)>self.capacity: # 如果缓存中的键值对数量超过了容量限制
self.popitem(last=False) # 删除最久未使用的键值对(即最前面的键值对)
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)但是,在一般的考试或面试中,考官一般会期望读者能够自己实现一个简单的双向链表,而不是使用语言自带的、封装好的数据结构。Python实现过程如下:
class DLinkedNode: # 双向链表节点类
def __init__(self,key=0,value=0): # 初始化函数,接受键和值作为参数
self.key=key # 节点的键
self.value=value # 节点的值
self.pre=None # 前一个节点的指针
self.next=None # 后一个节点的指针
class LRUCache: # LRU缓存类
def __init__(self, capacity: int): # 初始化函数,接受缓存容量作为参数
self.cache=dict() # 使用字典存储缓存中的键值对
self.head=DLinkedNode() # 创建虚拟头节点
self.tail=DLinkedNode() # 创建虚拟尾节点
self.head.next=self.tail # 头节点的后继指针指向尾节点
self.tail.pre=self.head # 尾节点的前驱指针指向头节点
self.capacity=capacity # 缓存容量
self.size=0 # 缓存当前大小
def get(self, key: int) -> int: # 获取缓存中指定键的值
if key not in self.cache: # 如果指定键不在缓存中
return -1 # 返回-1
node=self.cache[key] # 获取缓存中的节点
self.moveToHead(node) # 将该节点移动到链表头部,表示最近访问过
return node.value # 返回节点的值
def put(self, key: int, value: int) -> None: # 向缓存中插入键值对
if key not in self.cache: # 如果指定键不在缓存中
node=DLinkedNode(key,value) # 创建一个新的节点
self.cache[key]=node # 将节点添加到缓存中
self.addTohead(node) # 将节点添加到链表头部
self.size+=1 # 缓存大小加1
if self.size>self.capacity: # 如果缓存大小超过了容量限制
removed=self.removeTail() # 删除链表尾部的节点(即最久未使用的节点)
self.cache.pop(removed.key) # 从缓存中删除对应的键值对
self.size-=1 # 缓存大小减1
else: # 如果指定键已经存在于缓存中
node=self.cache[key] # 获取缓存中的节点
node.value=value # 更新节点的值为新值
self.moveToHead(node) # 将该节点移动到链表头部,表示最近访问过
def addTohead(self,node): # 将节点添加到链表头部
node.pre=self.head # 设置节点的前驱指针为头节点
node.next=self.head.next # 设置节点的后继指针为原来头节点的后继指针
self.head.next.pre=node # 设置原来头节点的后继节点的前驱指针为新节点
self.head.next=node # 设置头节点的后继指针为新节点
def removeNode(self,node): # 删除链表中的指定节点
node.pre.next=node.next # 将节点的前驱节点的后继指针指向节点的后继节点
node.next.pre=node.pre # 将节点的后继节点的前驱指针指向节点的前驱节点
def moveToHead(self,node): # 将节点移动到链表头部
self.removeNode(node) # 先将节点从链表中删除
self.addTohead(node) # 再将节点添加到链表头部
def removeTail(self): # 删除链表尾部的节点
node=self.tail.pre # 获取尾节点的前驱节点
self.removeNode(node) # 删除尾节点的前驱节点
return node # 返回被删除的节点以下代码使用C++ STL 解决 速度会比上述Python代码快一些
class LRUCache {
int capacity_; // 缓存容量
list<int> keyList_; // 存储缓存中的键的双向链表
unordered_map<int,pair<int,list<int>::iterator>> hashMap_; // 存储键值对的哈希表,键是缓存中的键,值是键对应的值和在keyList_中的迭代器
void Insert(int key,int value){ // 辅助函数,将键值对插入到缓存中
keyList_.push_back(key); // 将键插入到keyList_的末尾
hashMap_[key]=make_pair(value,--keyList_.end()); // 在hashMap_中插入键值对,值为键对应的值和keyList_中末尾元素的迭代器
}
public:
LRUCache(int capacity) { // 构造函数,初始化缓存容量
capacity_=capacity;
}
int get(int key) { // 获取缓存中指定键的值
auto it=hashMap_.find(key); // 在hashMap_中查找指定键
if(it!=hashMap_.end()){ // 如果找到了
keyList_.erase(it->second.second); // 将该键对应的迭代器指向的元素从keyList_中删除
keyList_.push_back(key); // 将该键插入到keyList_的末尾
hashMap_[key].second=(--keyList_.end()); // 更新hashMap_中该键对应的迭代器为keyList_的末尾元素的迭代器
return it->second.first; // 返回该键对应的值
}
return -1; // 如果没有找到,则返回-1
}
void put(int key, int value) { // 向缓存中插入键值对
if(get(key)!=-1){ // 如果该键已经存在于缓存中
hashMap_[key].first=value; // 更新该键对应的值为新值
return;
}
if(hashMap_.size()<capacity_){ // 如果缓存未满
Insert(key,value); // 直接插入键值对到缓存中
}else{ // 如果缓存已满
int removeKey=keyList_.front(); // 获取keyList_中最久未使用的键
keyList_.pop_front(); // 将最久未使用的键从keyList_中删除
hashMap_.erase(removeKey); // 将最久未使用的键从hashMap_中删除
Insert(key,value); // 插入新的键值对到缓存中
}
}
};
以下使用Java 实现的代码,超奈斯,运算速度秒杀以上所有代码。
class Node{
public int key,val;
public Node next,prev;
public Node(int k,int v){
this.key=k;
this.val=v;
}
}
class DoubleList{
private Node head,tail;//申请头尾虚节点
private int size;//链表元素个数
public DoubleList(){ //初始化双向链表
head=new Node(0,0);
tail=new Node(0,0);
head.next=tail;
tail.prev=head;
size=0;
}
public void addLast(Node x){//在尾部插入一个节点x
x.prev=tail.prev;
x.next=tail;
tail.prev.next=x;
tail.prev=x;
size++;
}
public void remove(Node x){//删除节点x(x一定存在)
x.prev.next=x.next;
x.next.prev=x.prev;
size--;
}
public Node removeFirst(){//删除链表中的第一个节点 并返回该节点
if(head.next==tail) return null;
Node first=head.next;
remove(first);
//size--;
return first;
}
public int size(){//返回节点个数
return size;
}
}
class LRUCache {
private HashMap<Integer,Node> map;
private DoubleList cache;
private int cap;
public LRUCache(int capacity) {
this.cap=capacity;
map=new HashMap<>();
cache= new DoubleList();
}
private void makeRecently(int key){//将某个key提升为最近使用
Node x=map.get(key);//取得
cache.remove(x);//删除
cache.addLast(x);//队尾插入
}
private void addRecently(int key,int val){//添加最近使用的元素
Node x=new Node(key,val);//申请节点
cache.addLast(x);//队尾插入
map.put(key,x);//添加映射
}
private void deleteKey(int key){//删除某一个key
Node x=map.get(key);//取得
cache.remove(x);//链表删除
map.remove(key);//map删除
}
private void removeLeastRecently(){//删除久未使用的元素
Node delateNode=cache.removeFirst();//取得并删除链表头部元素
int delateKey=delateNode.key;//取得该元素的key
map.remove(delateKey);//从map中删除
}
public int get(int key) {
if(!map.containsKey(key)) return -1;
makeRecently(key);//将该数据提升为最近使用
return map.get(key).val;
}
public void put(int key, int value) {
if(map.containsKey(key)){
deleteKey (key);//删除旧数据
addRecently(key, value);//插入新数据
return;
}
if(cap==cache.size()){
removeLeastRecently();//删除最久未使用的元素
}
addRecently(key, value);//添加为最近使用的元素
}
}